视频地址:尚硅谷大数据Spark教程从入门到精通_哔哩哔哩_bilibili
- 尚硅谷大数据技术Spark教程-笔记01【Spark(概述、快速上手、运行环境、运行架构)】
- 尚硅谷大数据技术Spark教程-笔记02【SparkCore(核心编程、案例实操)】
- 尚硅谷大数据技术Spark教程-笔记03【SparkSQL(概述、核心编程、项目实战)】
- 尚硅谷大数据技术Spark教程-笔记04【SparkStreaming(概述、Dstream入门、DStream创建)】
- 尚硅谷大数据技术Spark教程-笔记05【SparkStreaming(DStream转换、DStream输出、优雅关闭、SparkStreaming案例实操)】
目录
01_尚硅谷大数据技术之SparkCore
第01章-Spark概述
P001【001.尚硅谷_Spark框架 - 简介】04:54
P002【002.尚硅谷_Spark框架 - Vs Hadoop】07:49
P003【003.尚硅谷_Spark框架 - 核心模块 - 介绍】02:24
第02章-Spark快速上手
P004【004.尚硅谷_Spark框架 - 快速上手 - 开发环境准备】05:46
P005【005.尚硅谷_Spark框架 - 快速上手 - WordCount - 案例分析】07:57
P006【006.尚硅谷_Spark框架 - 快速上手 - WordCount - Spark环境】07:07
P007【007.尚硅谷_Spark框架 - 快速上手 - WordCount - 功能实现】11:56
P008【008.尚硅谷_Spark框架 - 快速上手 - WordCount - 不同的实现】08:31
P009【009.尚硅谷_Spark框架 - 快速上手 - WordCount - Spark的实现】04:24
P010【010.尚硅谷_Spark框架 - 快速上手 - WordCount - 日志和错误】03:50
第03章-Spark运行环境
P011【011.尚硅谷_Spark框架 - 运行环境 - 本地环境 - 基本配置和操作】08:11
P012【012.尚硅谷_Spark框架 - 运行环境 - 本地环境 - 提交应用程序】03:10
P013【013.尚硅谷_Spark框架 - 运行环境 - 独立部署环境 - 基本配置和操作】06:13
P014【014.尚硅谷_Spark框架 - 运行环境 - 独立部署环境 - 提交参数解析】03:08
P015【015.尚硅谷_Spark框架 - 运行环境 - 独立部署环境 - 配置历史服务】04:08
P016【016.尚硅谷_Spark框架 - 运行环境 - 独立部署环境 - 配置高可用】05:51
P017【017.尚硅谷_Spark框架 - 运行环境 - Yarn环境 - 基本配置 & 历史服务】06:42
P018【018.尚硅谷_Spark框架 - 运行环境 - Windows环境 & 总结】11:06
第04章-Spark运行架构
P019【019.尚硅谷_Spark框架 - 核心组件 - 介绍】03:33
P020【020.尚硅谷_Spark框架 - 核心概念 - Executor & Core & 并行度】03:31
P021【021.尚硅谷_Spark框架 - 核心概念 - DAG & 提交流程 & Yarn两种部署模式】07:00
01_尚硅谷大数据技术之SparkCore
制作不易,大家记得点个关注,一键三连呀【点赞、投币、收藏】感谢支持~ 众所期待,隆重推出!大数据领域中杀手级的应用计算框架:Spark视频教程。 本套视频教程基于Scala 2.12版本,对Spark 3.0版本的核心模块进行了详尽的源码级讲解,授课图文并茂,资料详实丰富,带你领略不一样的技术风景线。课程内容涉及方方面面,函数式编程,你熟悉吗?认知心理学,你知道吗?工程化代码框架,你了解吗?在这套Spark视频教程中,你想要的这些全都有!
第01章-Spark概述
P001【001.尚硅谷_Spark框架 - 简介】04:54
Spark 出现的时间相对较晚,并且主要功能主要是用于数据计算,所以其实 Spark 一直被认为是 Hadoop 框架的升级版。
P002【002.尚硅谷_Spark框架 - Vs Hadoop】07:49
spark将计算结果放到了内存中为下一次计算提供了更加便利的方式。
选择spark而非hadoop与MapReduce的原因:spark计算快,内存计算策略、先进的调度机制,spark可以更快地处理相同的数据集。
spark面对的问题:spark若部署在共享的集群中可能会遇到资源不足的问题,spark占用的资源更多一些,所以spark不适合与hadoop堆栈等组件一起使用。
Spark 和Hadoop的根本差异是多个作业之间的数据通信问题:Spark多个作业之间数据通信是基于内存,而Hadoop是基于磁盘。
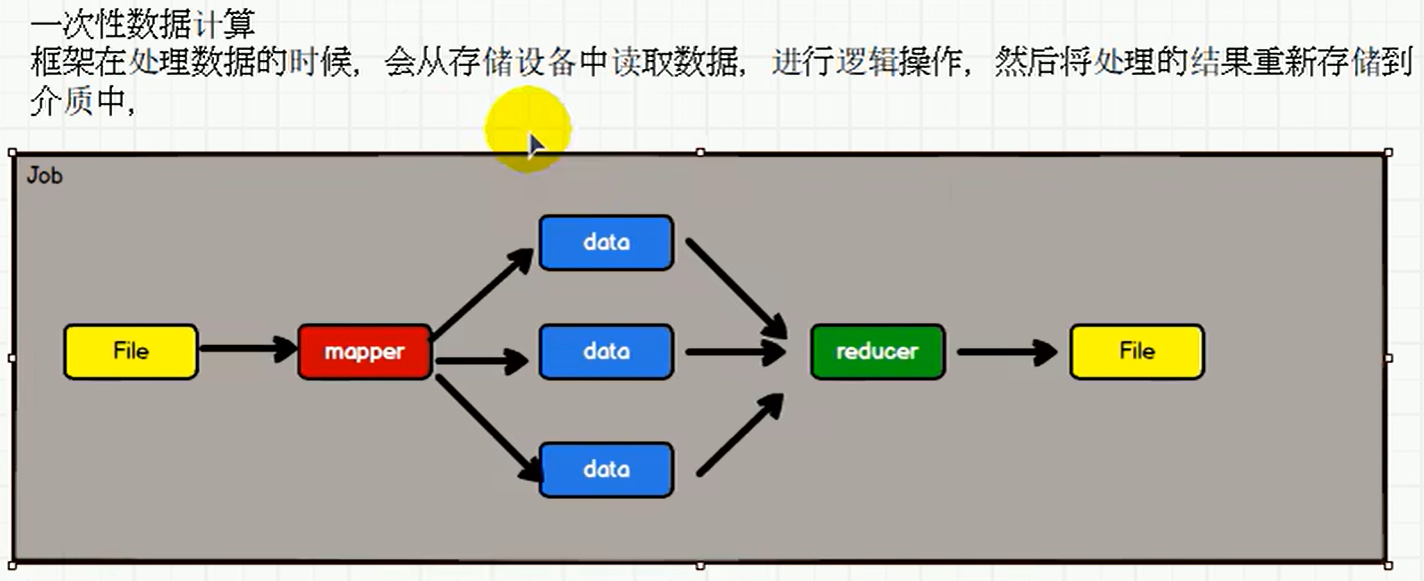
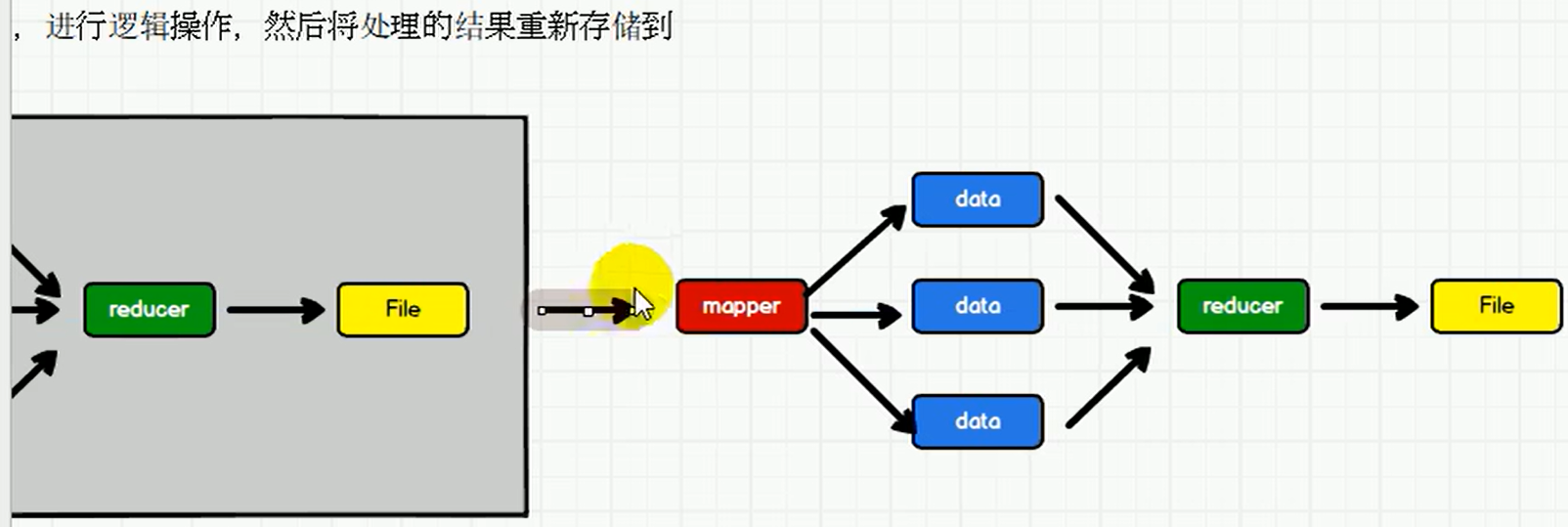
P003【003.尚硅谷_Spark框架 - 核心模块 - 介绍】02:24
1.4 核心模块
- 【Spark Core】Spark Core 中提供了Spark最基础与最核心的功能,Spark 其他的功能如:Spark SQL, Spark Streaming,GraphX, MLlib 都是在 Spark Core 的基础上进行扩展的
- 【Spark SQL】Spark SQL 是Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用 SQL或者Apache Hive 版本的 SQL 方言(HQL)来查询数据。
- 【Spark Streaming】Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。
- 【Spark MLlib】MLlib 是 Spark 提供的一个机器学习算法库。MLlib不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语。
- 【Spark GraphX】GraphX 是 Spark 面向图计算提供的框架与算法库。

第02章-Spark快速上手
P004【004.尚硅谷_Spark框架 - 快速上手 - 开发环境准备】05:46
第2章 Spark快速上手
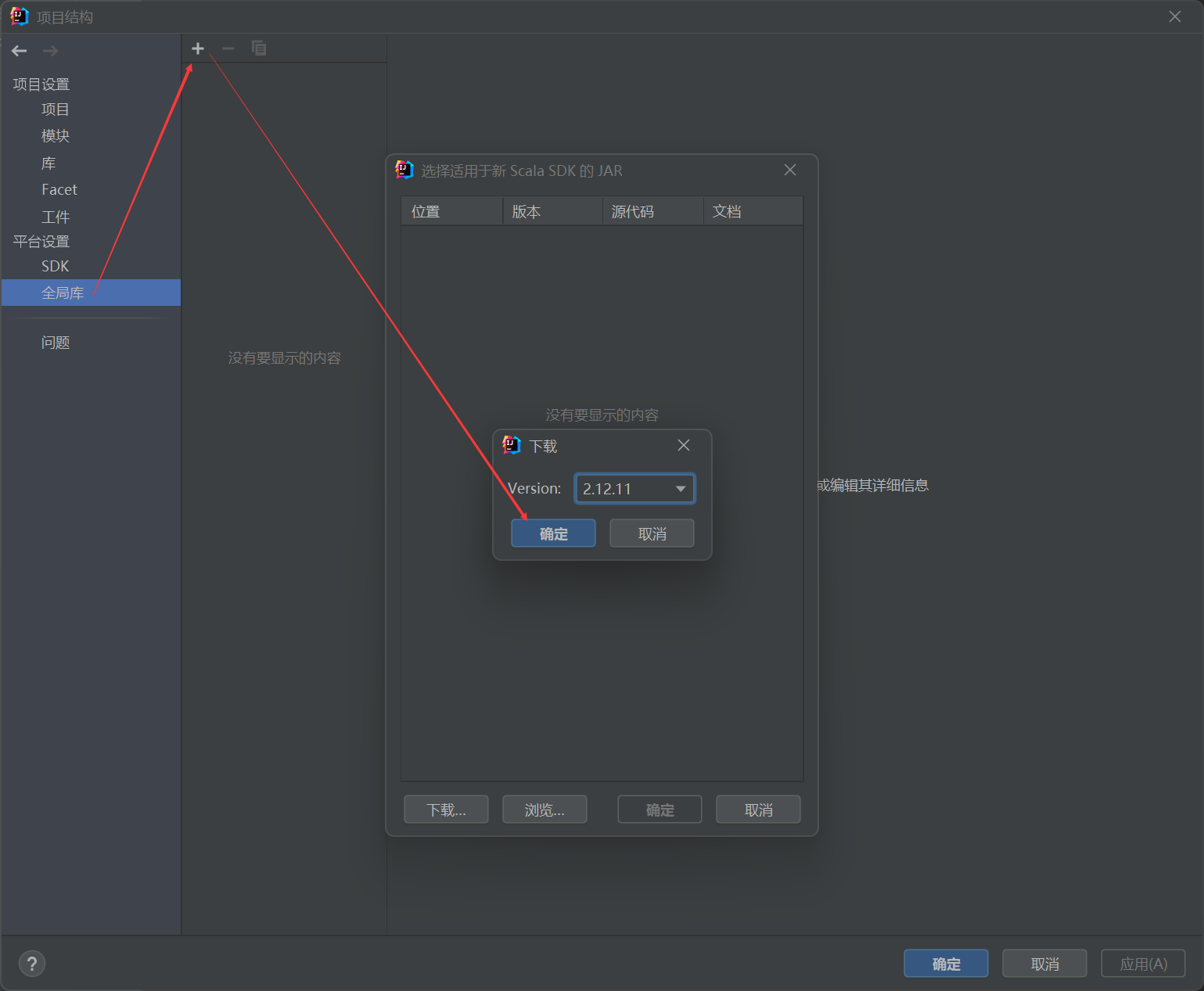
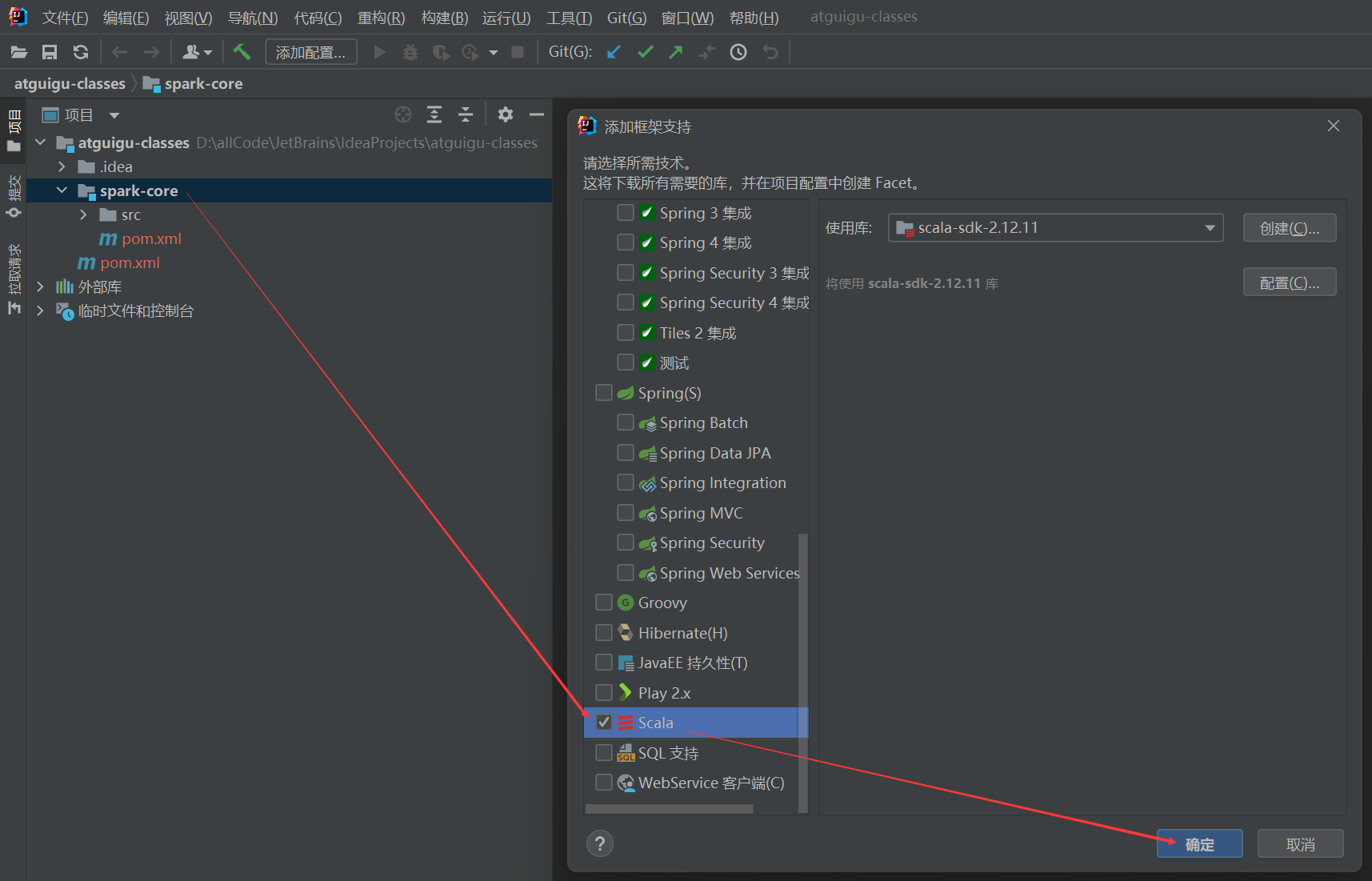
先在file-settings-plugin里面安装Scala插件,然后在这里的global libraries里点+号选Scala,再downloading对应版本的scala。
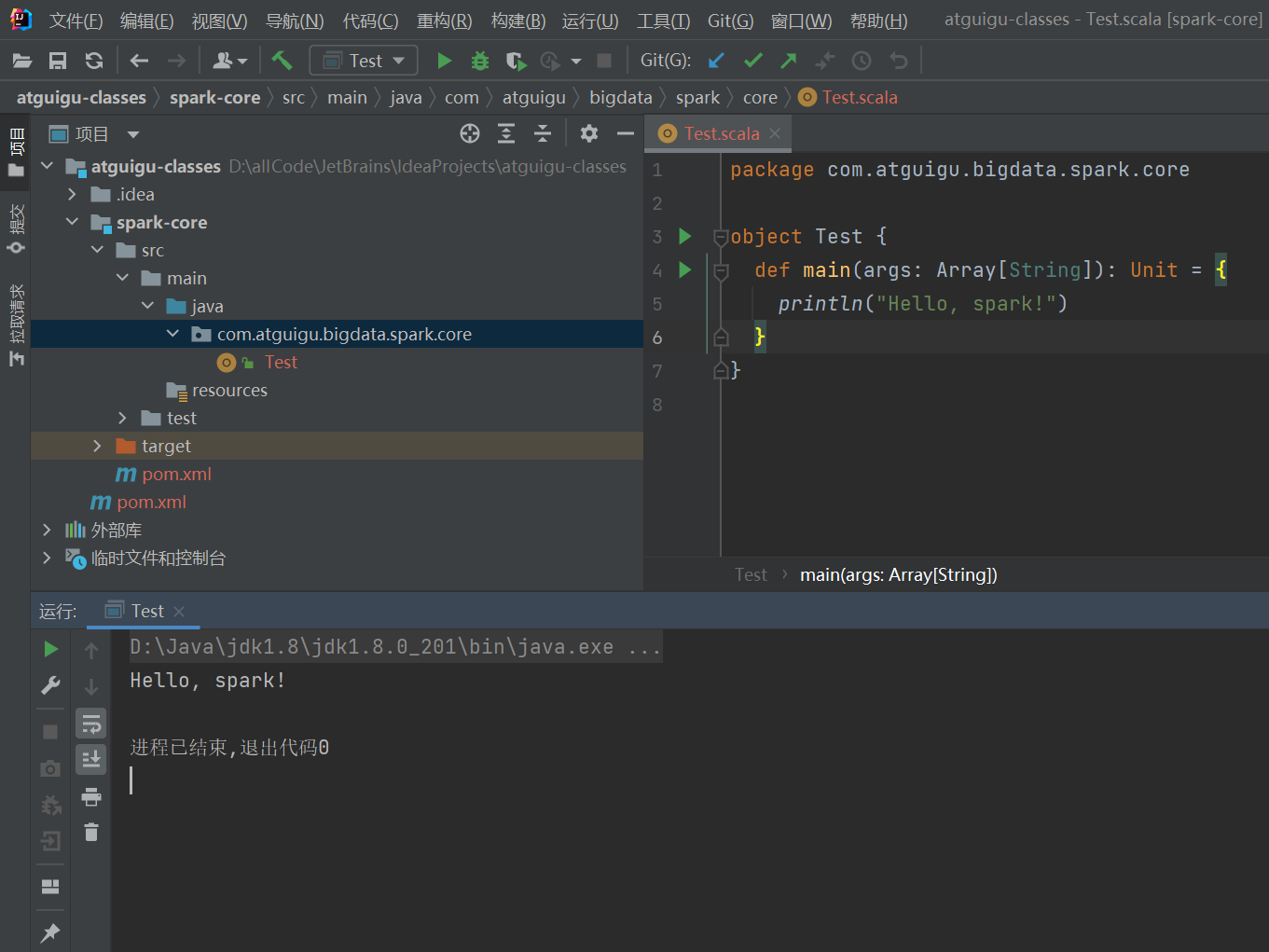
package com.atguigu.bigdata.spark.core
object Test {
def main(args: Array[String]): Unit = {
println("Hello, spark!")
}
}P005【005.尚硅谷_Spark框架 - 快速上手 - WordCount - 案例分析】07:57
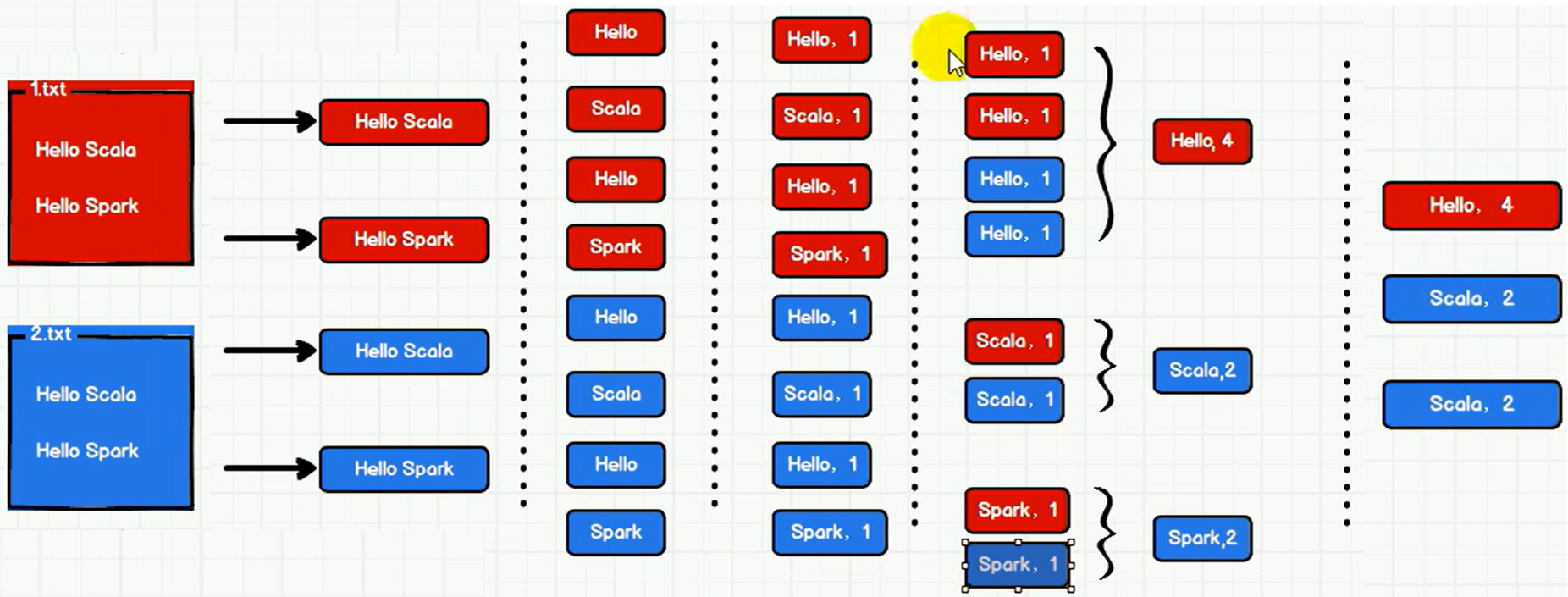
WordCount思路
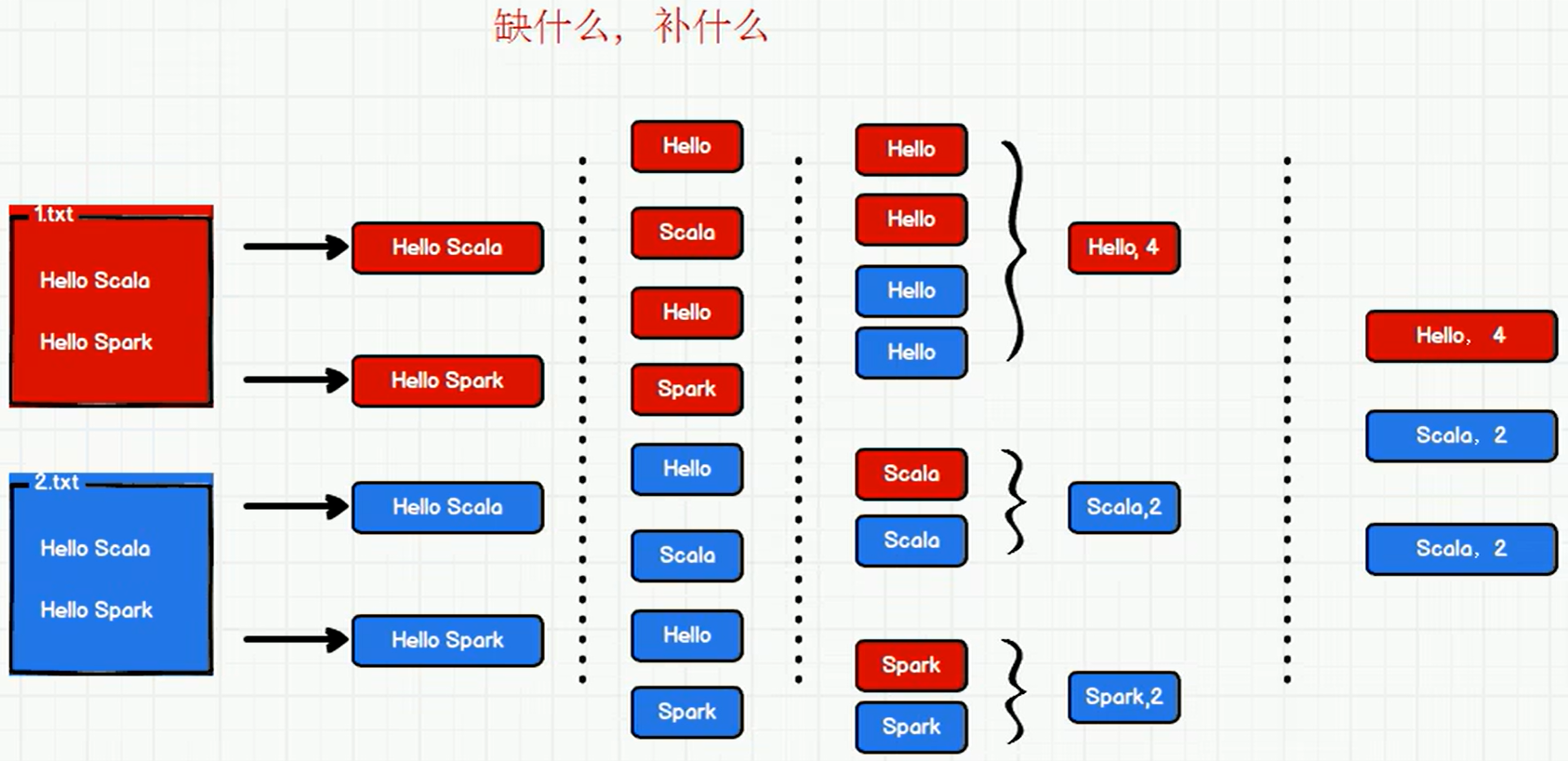
P006【006.尚硅谷_Spark框架 - 快速上手 - WordCount - Spark环境】07:07
TODO是标记下,表示待完善。
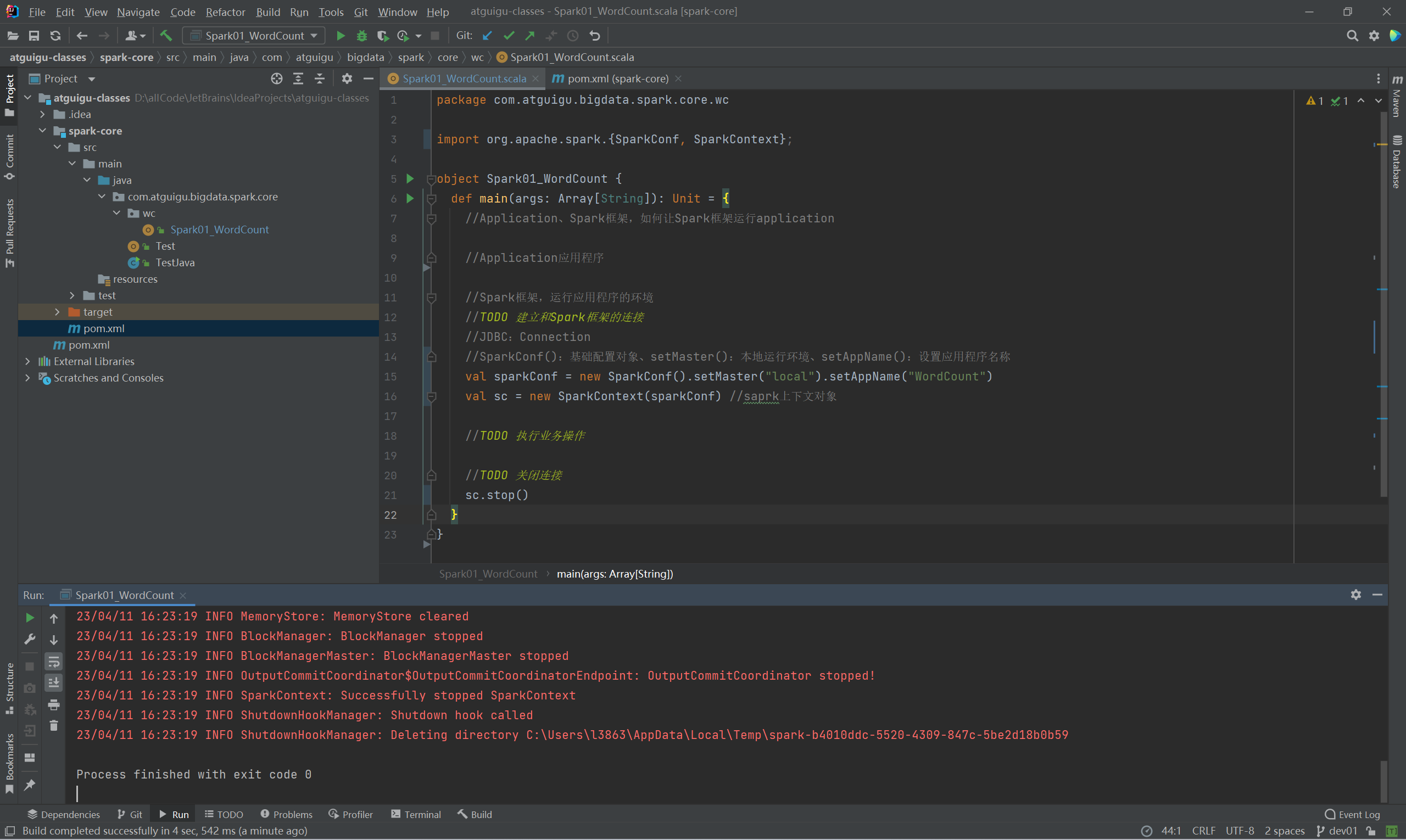
package com.atguigu.bigdata.spark.core.wc
import org.apache.spark.{SparkConf, SparkContext};
object Spark01_WordCount {
def main(args: Array[String]): Unit = {
//Application、Spark框架,如何让Spark框架运行application
//Application应用程序
//Spark框架,运行应用程序的环境
//TODO 建立和Spark框架的连接
//JDBC:Connection
//SparkConf():基础配置对象、setMaster():本地运行环境、setAppName():设置应用程序名称
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparkConf) //saprk上下文对象
//TODO 执行业务操作
//TODO 关闭连接
sc.stop()
}
}P007【007.尚硅谷_Spark框架 - 快速上手 - WordCount - 功能实现】11:56
_.split() 等价于 x => x.split() 等价于 (x) => {x.split},是一个匿名函数。
package com.atguigu.bigdata.spark.core.wc
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext};
object Spark01_WordCount {
def main(args: Array[String]): Unit = {
//Application、Spark框架,如何让Spark框架运行application
//Application应用程序
//Spark框架,运行应用程序的环境
//TODO 建立和Spark框架的连接
//JDBC:Connection
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
//SparkConf():基础配置对象、setMaster():本地运行环境、setAppName():设置应用程序名称
val sc = new SparkContext(sparkConf) //saprk上下文对象
//TODO 执行业务操作
//1.读取文件,获取一行一行的数据(以行为单位读取数据)
//hello world
val lines: RDD[String] = sc.textFile("datas")
//2.将一行数据进行拆分,形成一个一个的单词(分词)
//扁平化:将整体拆分成个体的操作
//"hello world" => hello, world, hello, world
val words: RDD[String] = lines.flatMap(_.split(" "))
//3.将数据根据单词进行分组,便于统计
//(hello, hello, hello), (world, world)
val wordGroup: RDD[(String, Iterable[String])] = words.groupBy(word => word)
//4.对分组后的数据进行转换
//(hello, hello, hello), (world, world)
//(hello, 3), (world, 2)
val wordToCount = wordGroup.map {
case (word, list) => {
(word, list.size)
}
}
//5.将转换结果采集到控制台打印出来
val array: Array[(String, Int)] = wordToCount.collect()
array.foreach(println)
//TODO 关闭连接
sc.stop()
}
}P008【008.尚硅谷_Spark框架 - 快速上手 - WordCount - 不同的实现】08:31
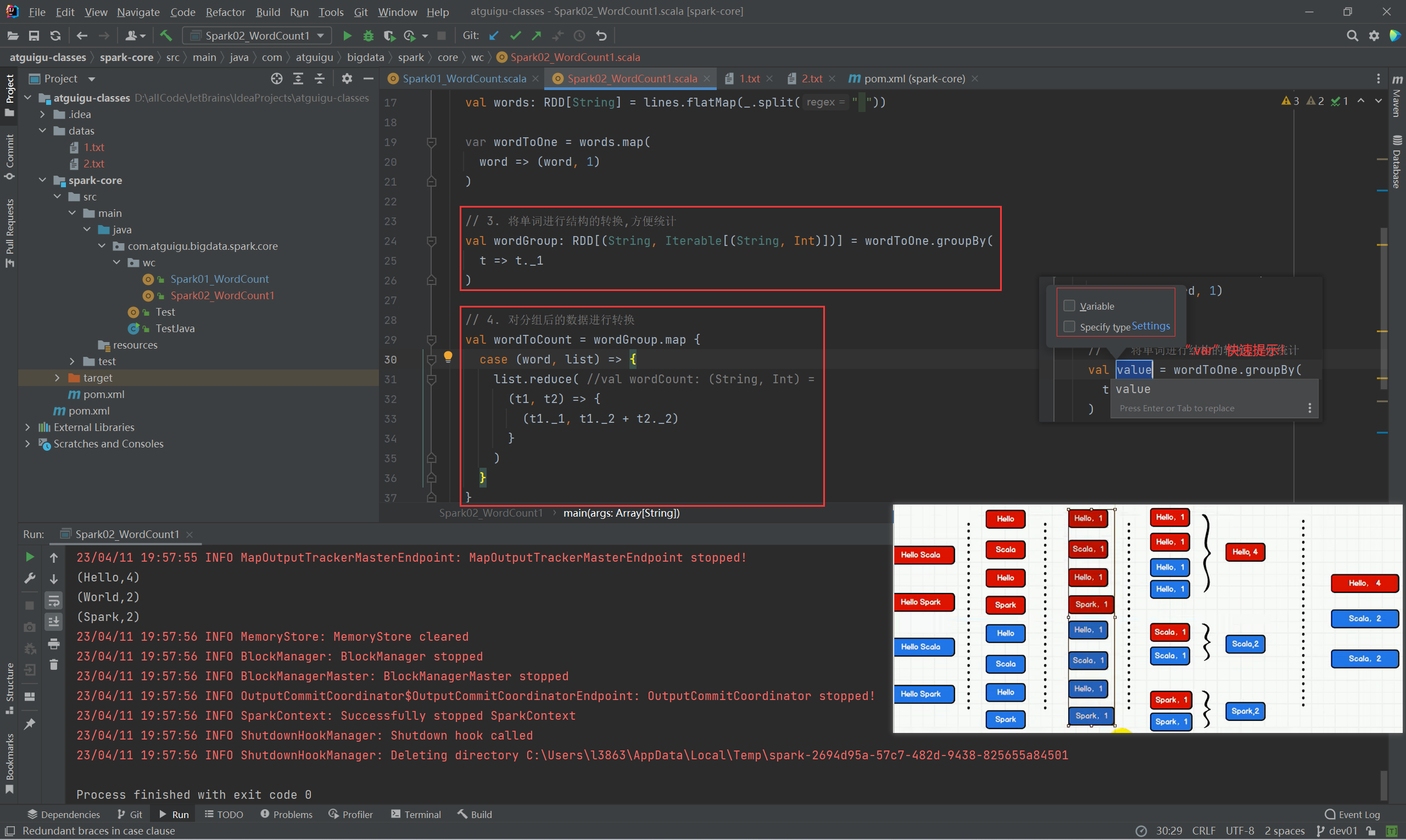
package com.atguigu.bigdata.spark.core.wc
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark02_WordCount {
def main(args: Array[String]): Unit = {
// TODO 建立和Spark框架的连接
val sparConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparConf)
// TODO 执行业务操作
// 1. 读取文件,获取一行一行的数据
val lines: RDD[String] = sc.textFile("datas")
// 2. 将一行数据进行拆分,形成一个一个的单词(分词),扁平化
val words: RDD[String] = lines.flatMap(_.split(" "))
var wordToOne = words.map(
word => (word, 1)
)
// 3. 将单词进行结构的转换,方便统计
val wordGroup: RDD[(String, Iterable[(String, Int)])] = wordToOne.groupBy(
t => t._1
)
// 4. 对分组后的数据进行转换
val wordToCount = wordGroup.map {
case (word, list) => {
list.reduce( //val wordCount: (String, Int) =
(t1, t2) => {
(t1._1, t1._2 + t2._2)
}
)
}
}
// 5. 将转换结果采集到控制台打印出来
val array: Array[(String, Int)] = wordToCount.collect()
array.foreach(println)
//TODO 关闭连接
sc.stop()
}
}P009【009.尚硅谷_Spark框架 - 快速上手 - WordCount - Spark的实现】04:24
package com.atguigu.bigdata.spark.core.wc
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark03_WordCount {
def main(args: Array[String]): Unit = {
// TODO 建立和Spark框架的连接
val sparConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparConf)
// TODO 执行业务操作
val lines: RDD[String] = sc.textFile("datas")
val words: RDD[String] = lines.flatMap(_.split(" "))
var wordToOne = words.map(
word => (word, 1)
)
// Spark框架提供了更多的功能,可以将分组和聚合使用一个方法实现
// reduceByKey:相同的key数据,可以对value进行reduce聚合
// wordToOne.reduceByKey((x, y) => {x + y})
// wordToOne.reduceByKey((x, y) => x + y)
val wordToCount = wordToOne.reduceByKey(_ + _)
val array: Array[(String, Int)] = wordToCount.collect()
array.foreach(println)
//TODO 关闭连接
sc.stop()
}
}P010【010.尚硅谷_Spark框架 - 快速上手 - WordCount - 日志和错误】03:50
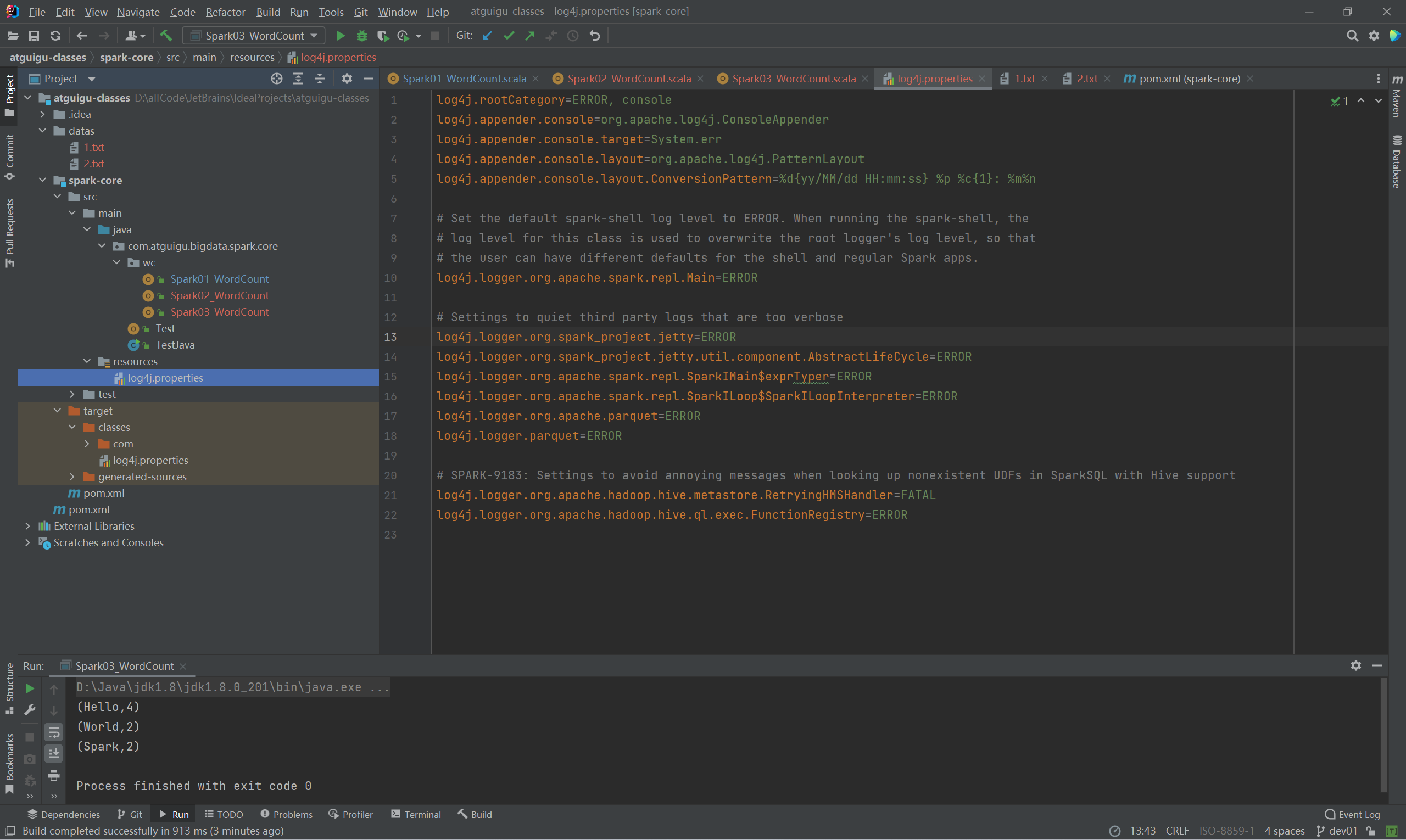
执行过程中,会产生大量的执行日志,如果为了能够更好的查看程序的执行结果,可以在项目的resources目录中创建log4j.properties文件,并添加日志配置信息。
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR第03章-Spark运行环境
P011【011.尚硅谷_Spark框架 - 运行环境 - 本地环境 - 基本配置和操作】08:11
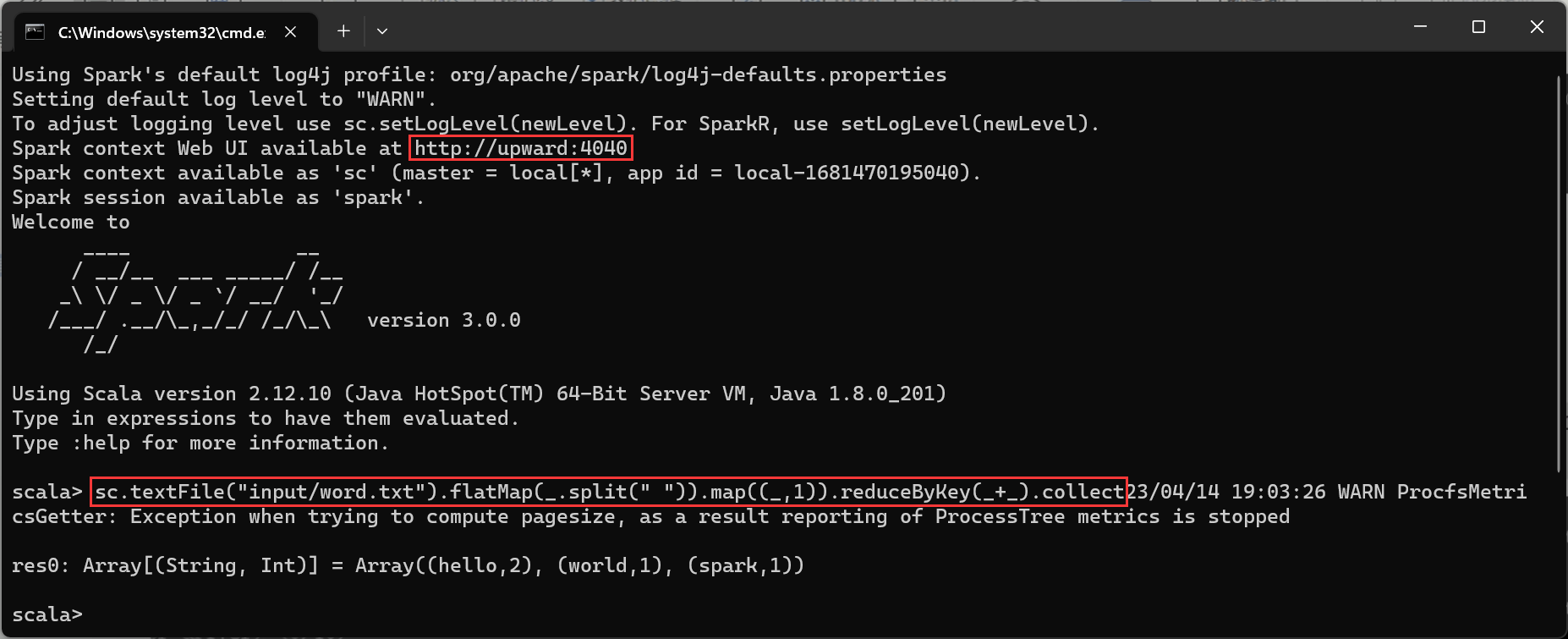
第3章-spark运行环境
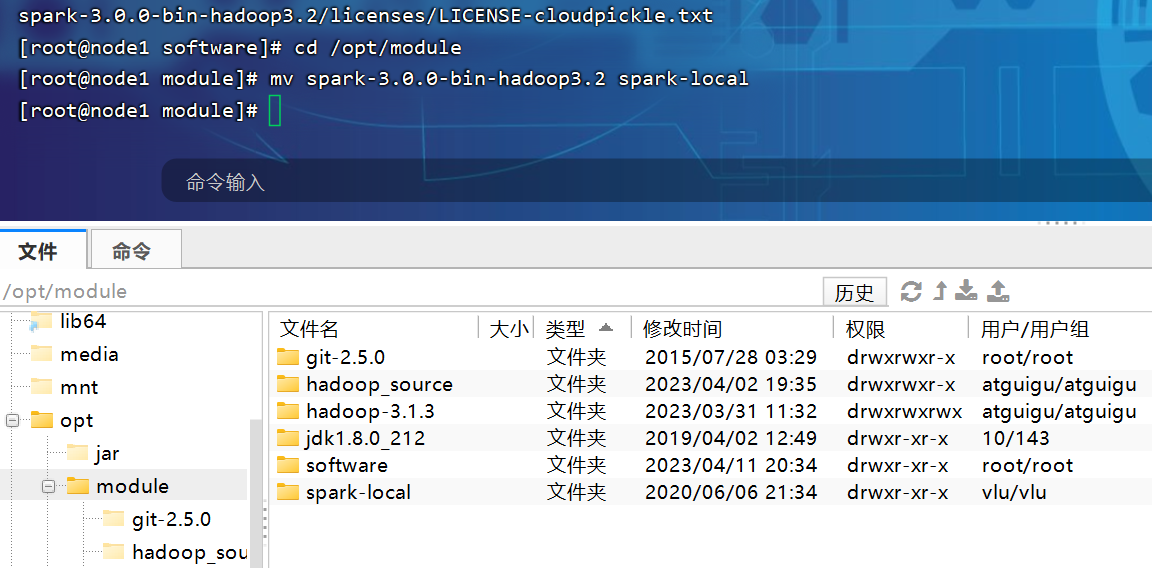
sc.textFile("data/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
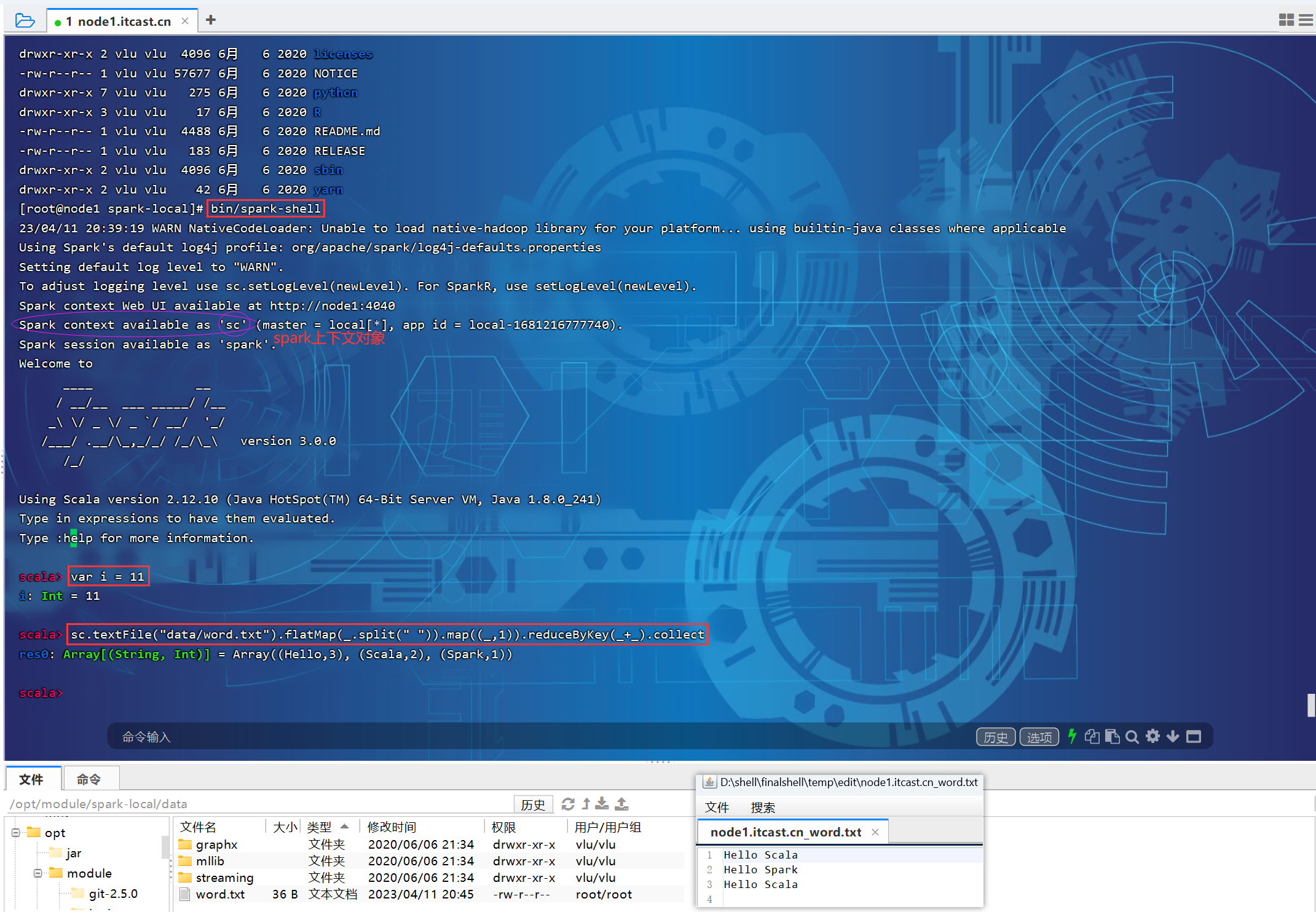
P012【012.尚硅谷_Spark框架 - 运行环境 - 本地环境 - 提交应用程序】03:10
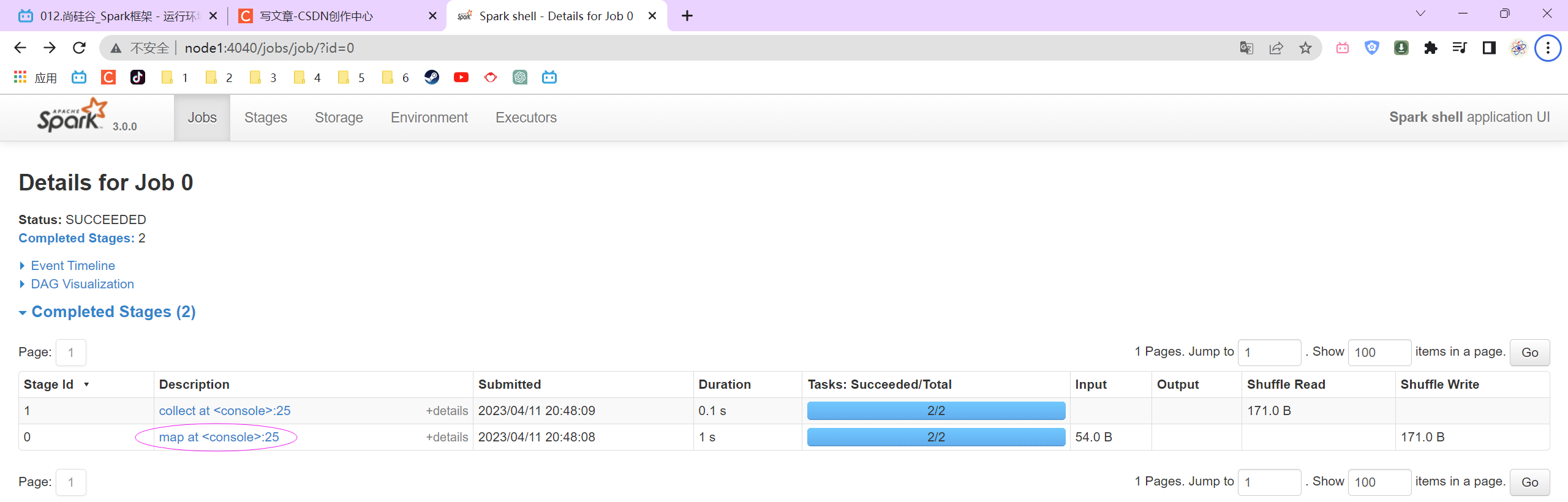
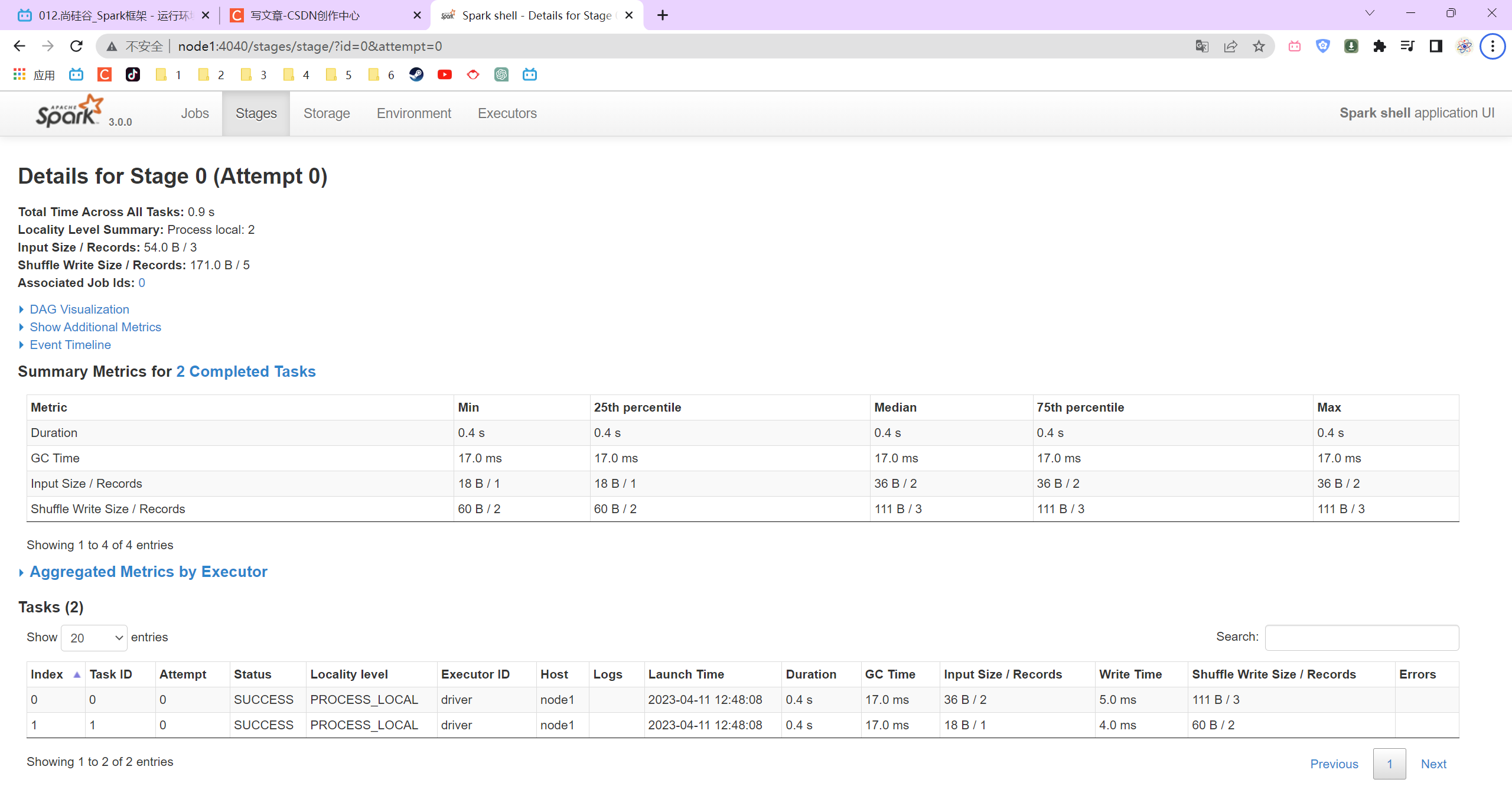
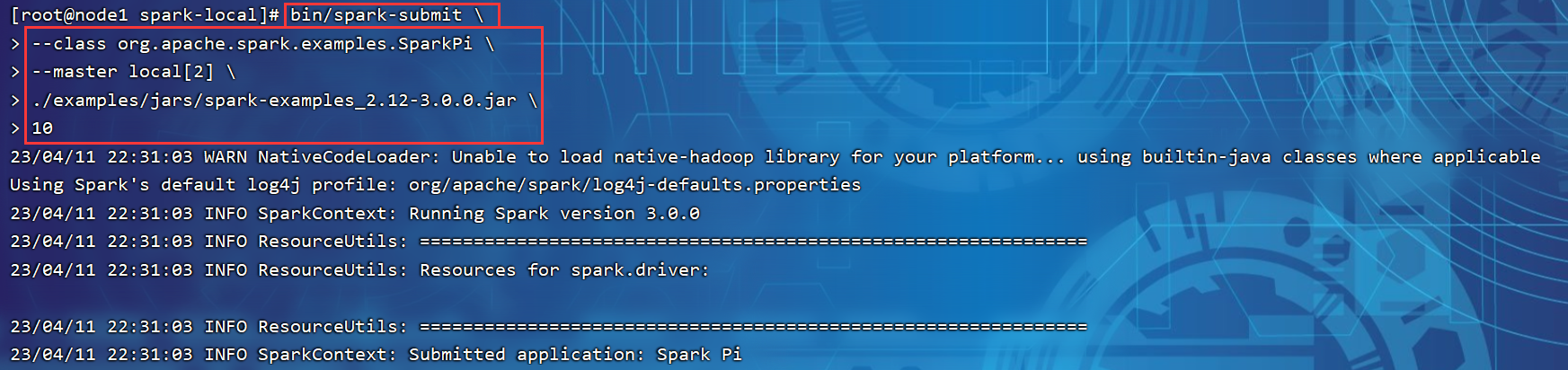
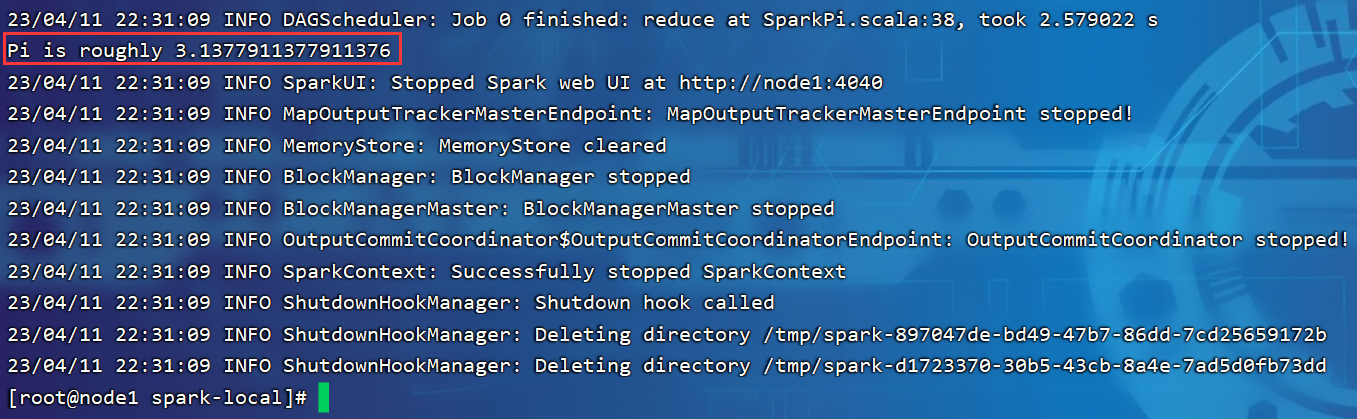
P013【013.尚硅谷_Spark框架 - 运行环境 - 独立部署环境 - 基本配置和操作】06:13
3.2 Standalone模式
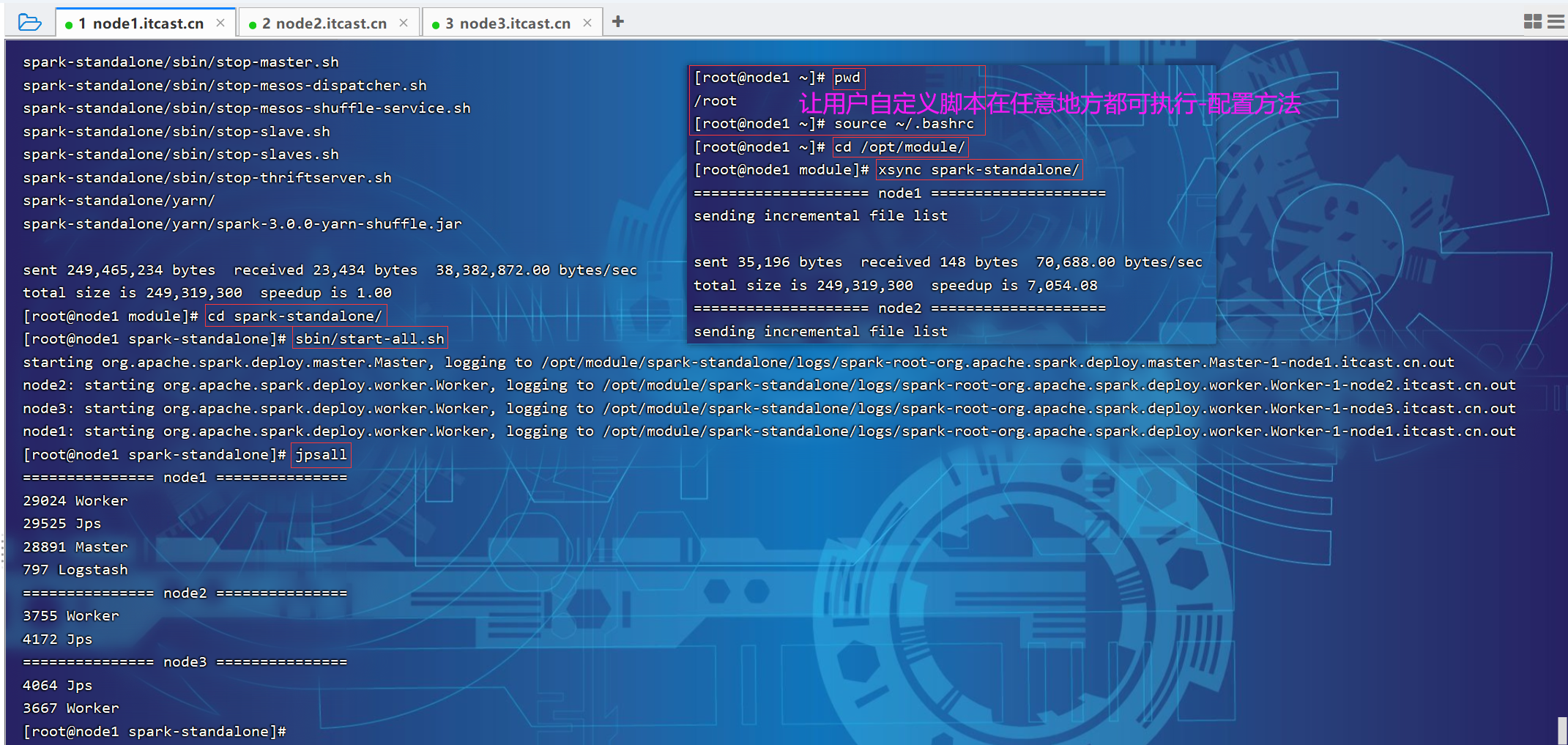
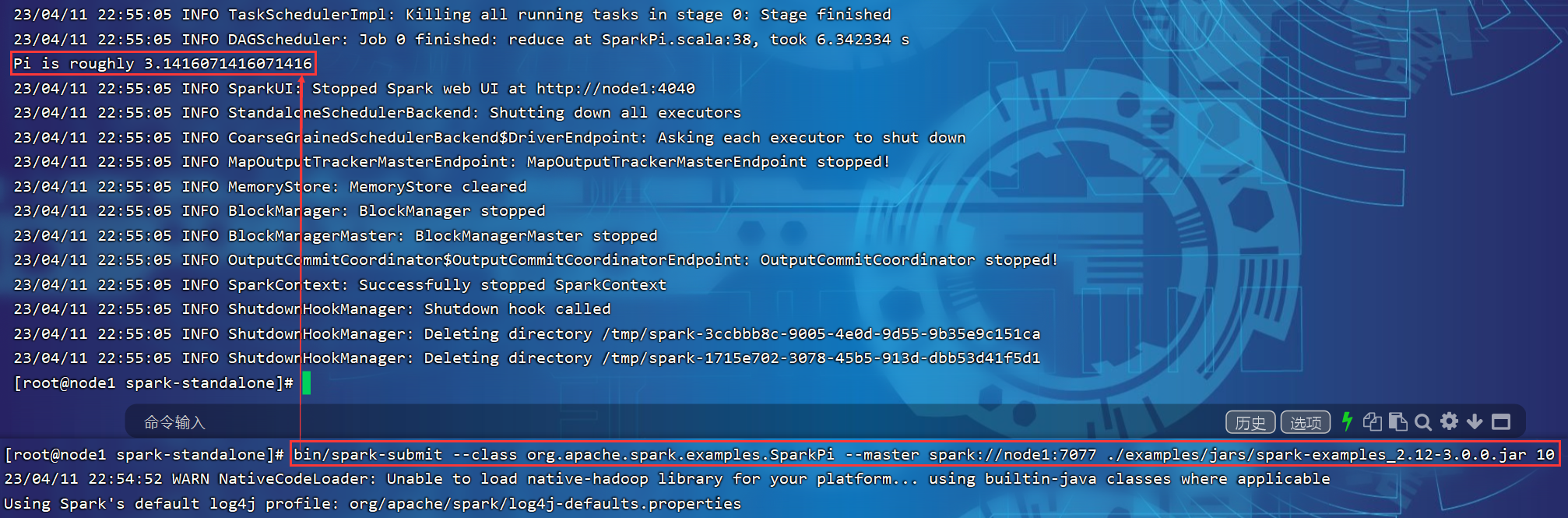
P014【014.尚硅谷_Spark框架 - 运行环境 - 独立部署环境 - 提交参数解析】03:08
3.2.4 提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://linux1:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
- --class表示要执行程序的主类
- --masterspark:/nux1:7077独立部署模式,连接到Spark集群
- spark-examples_2.12-3.0.0.jar运行类所在的jar包
- 数字10表示程序的入口参数,用于设定当前应用的任务数量
P015【015.尚硅谷_Spark框架 - 运行环境 - 独立部署环境 - 配置历史服务】04:08
先启动hadoop服务(主要是hdfs),再启动spark相关服务。
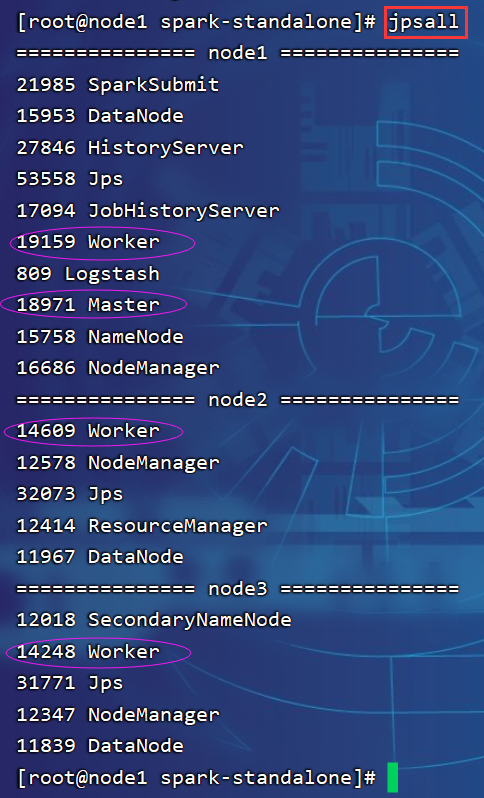
su atguigu
myhadoop.sh start
jpsallcd /opt/module/spark-standalone/
bin/spark-shell
sbin/start-all.sh
sbin/start-history-server.sh
jpsallhistory
- http://node1:9870/explorer.html#/
- http://node1:4040/jobs/
- http://node1:8080/
- http://node1:8020/
- http://node1:18080/
3.2.6 配置历史服务
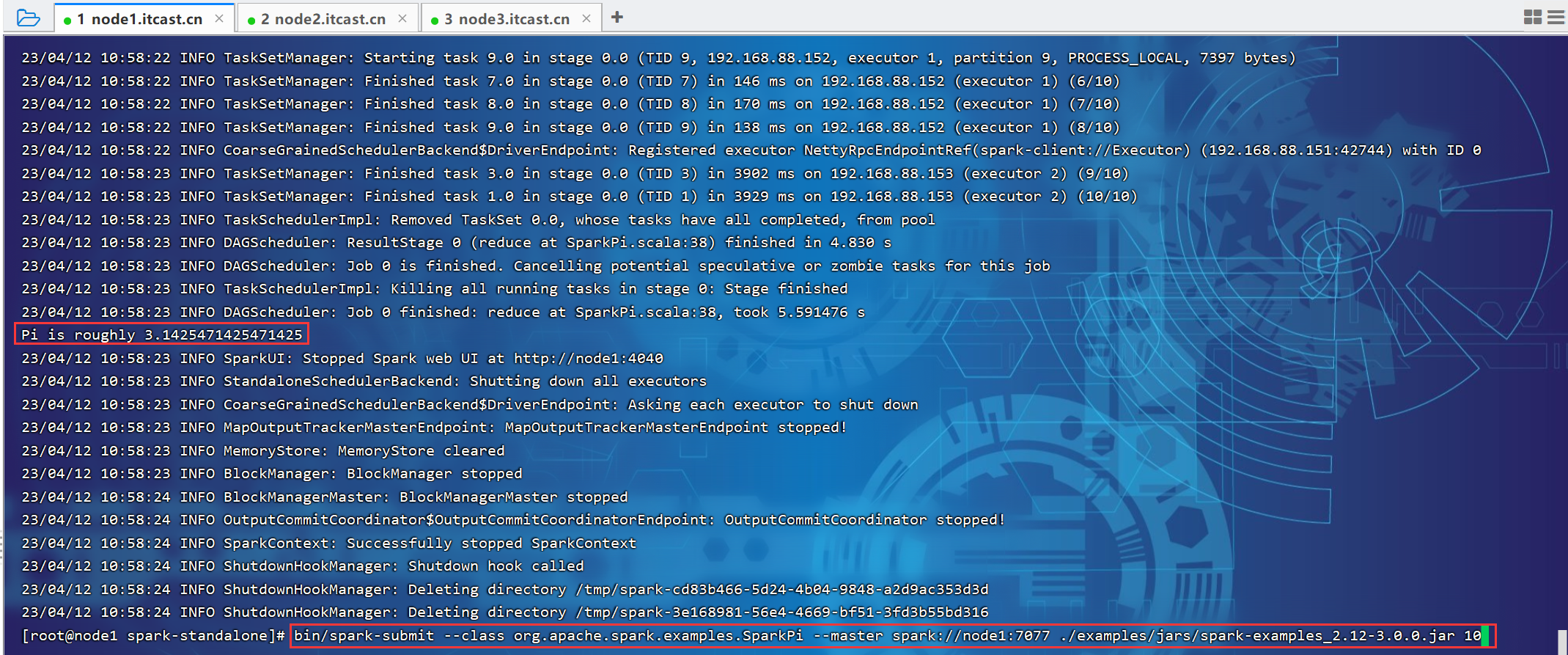

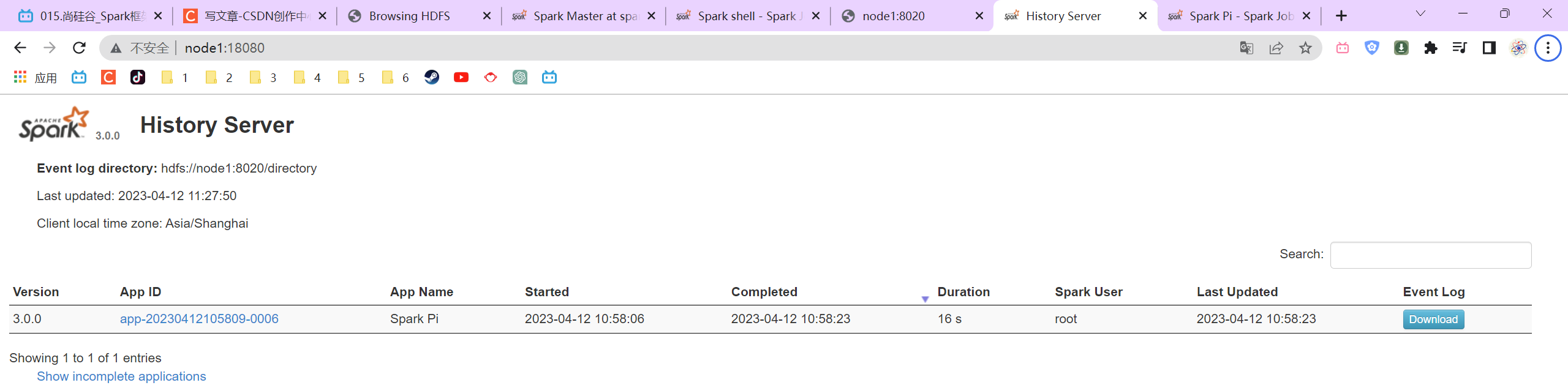
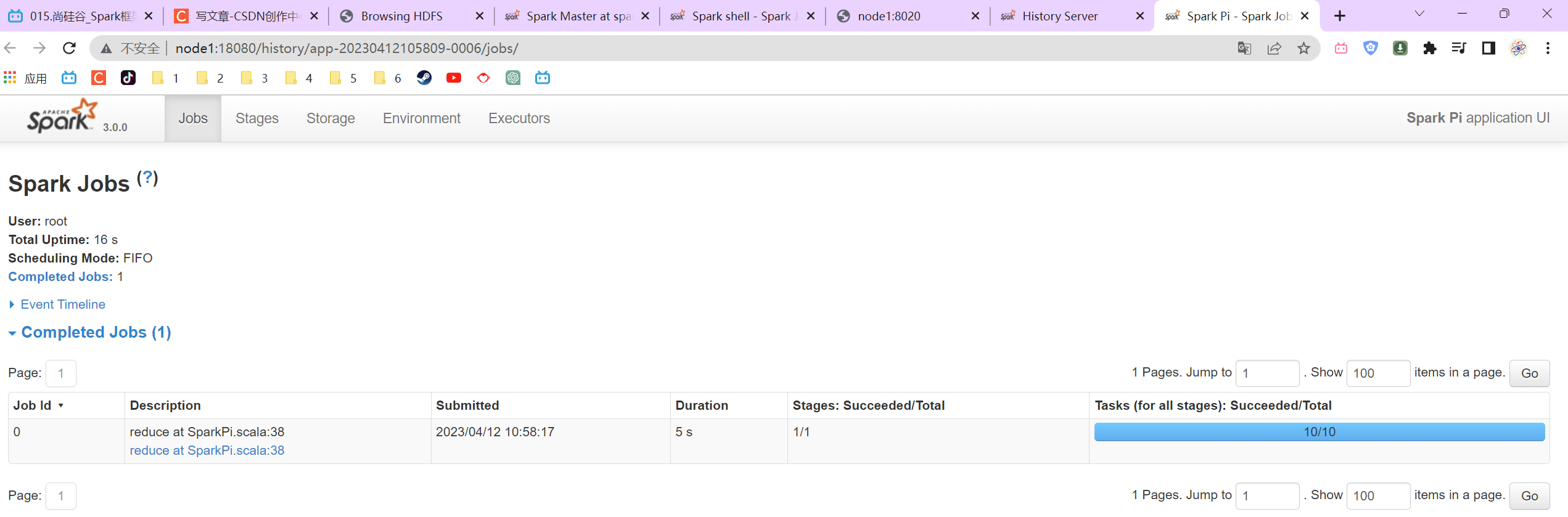
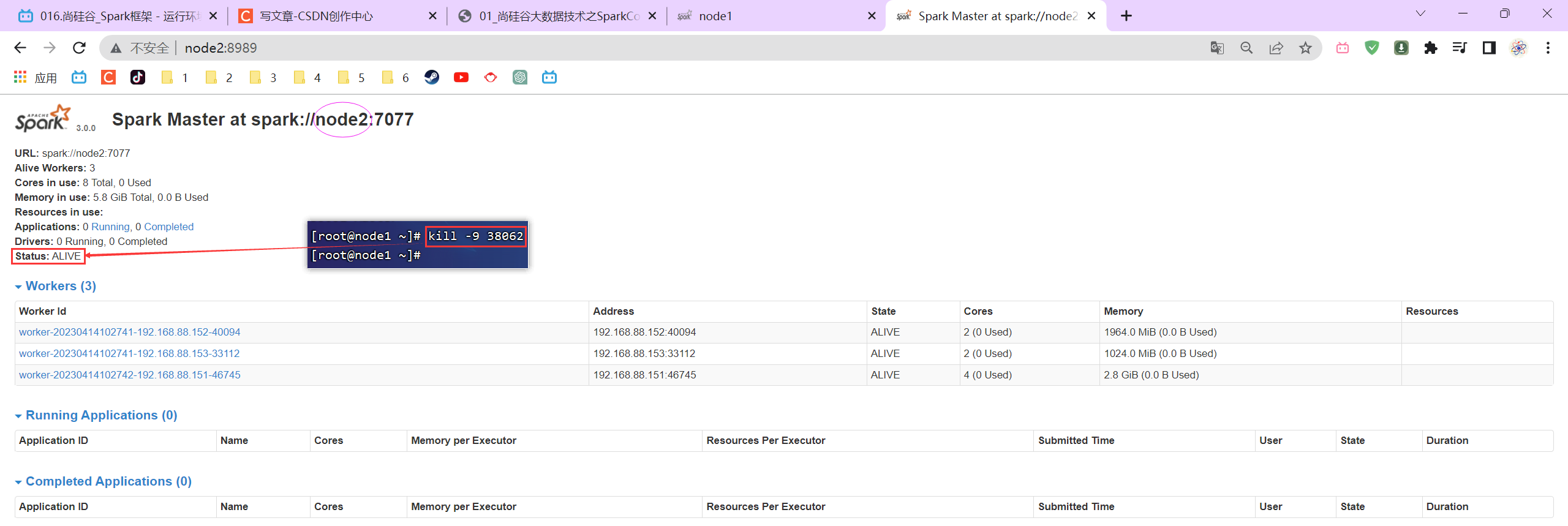
P016【016.尚硅谷_Spark框架 - 运行环境 - 独立部署环境 - 配置高可用】05:51
3.2.7 配置高可用(HA)
所谓的高可用是因为当前集群中的Master节点只有一个,所以会存在单点故障问题。所以为了解决单点故障问题,需要在集群中配置多个Master节点,一旦处于活动状态的Master发生故障时,由备用Master提供服务,保证作业可以继续执行。这里的高可用一般采用Zookeeper设置。
Linux1
Linux2
Linux3
Spark
Master
Zookeeper
Worker
Master
Zookeeper
Worker
Zookeeper
Worker
省流简洁版zookeeper环境搭建:zookeeper 3.5.7安装部署
视频地址:【尚硅谷】大数据技术之Zookeeper 3.5.7版本教程_哔哩哔哩_bilibili
- 尚硅谷大数据技术Zookeeper教程-笔记01【Zookeeper(入门、本地安装、集群操作)】
- 尚硅谷大数据技术Zookeeper教程-笔记02【服务器动态上下线监听案例、ZooKeeper分布式锁案例、企业面试真题】
- 尚硅谷大数据技术Zookeeper教程-笔记03【源码解析-算法基础】
- 尚硅谷大数据技术Zookeeper教程-笔记04【源码解析-源码详解】
P017【017.尚硅谷_Spark框架 - 运行环境 - Yarn环境 - 基本配置 & 历史服务】06:42
3.3 Yarn模式
独立部署(Standalone)模式由 Spark 自身提供计算资源,无需其他框架提供资源。这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是你也要记住,Spark 主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是和其他专业的资源调度框架集成会更靠谱一些。所以接下来我们来学习在强大的Yarn 环境下 Spark 是如何工作的(其实是因为在国内工作中,Yarn 使用的非常多)。
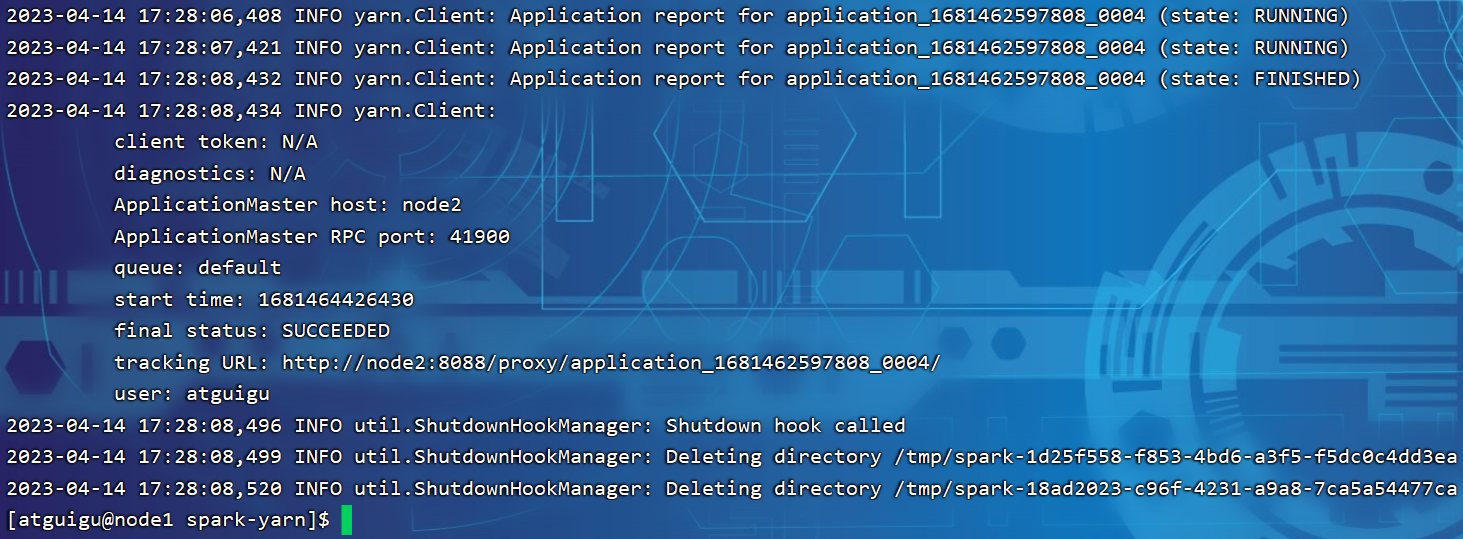
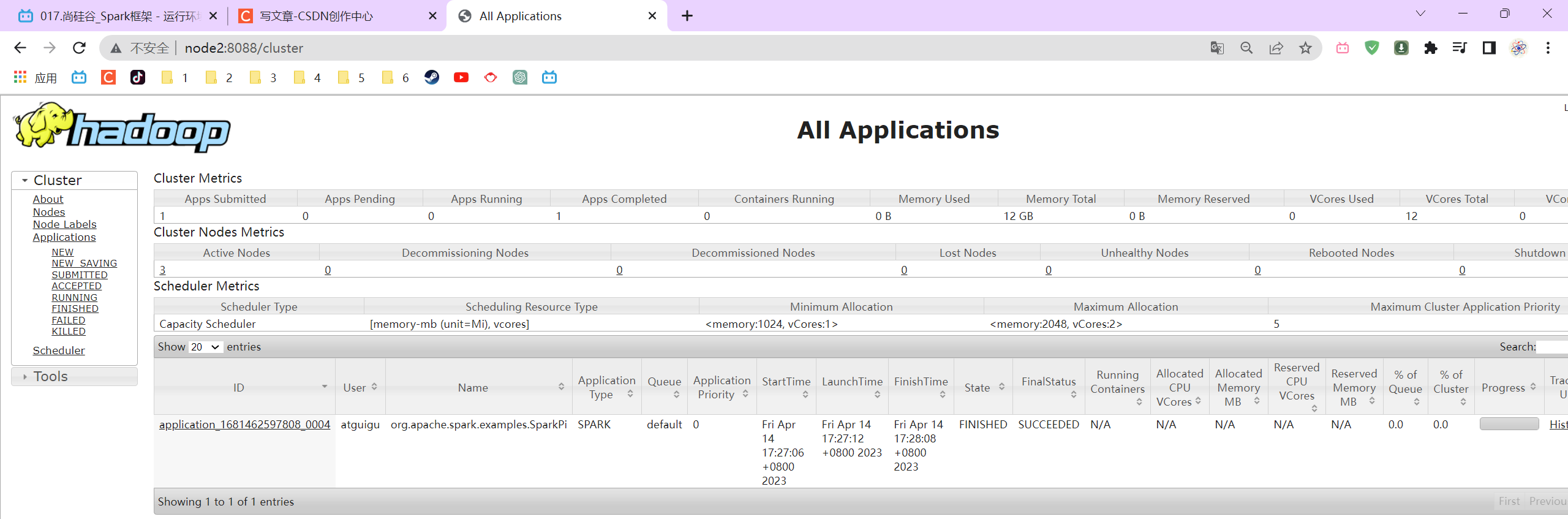
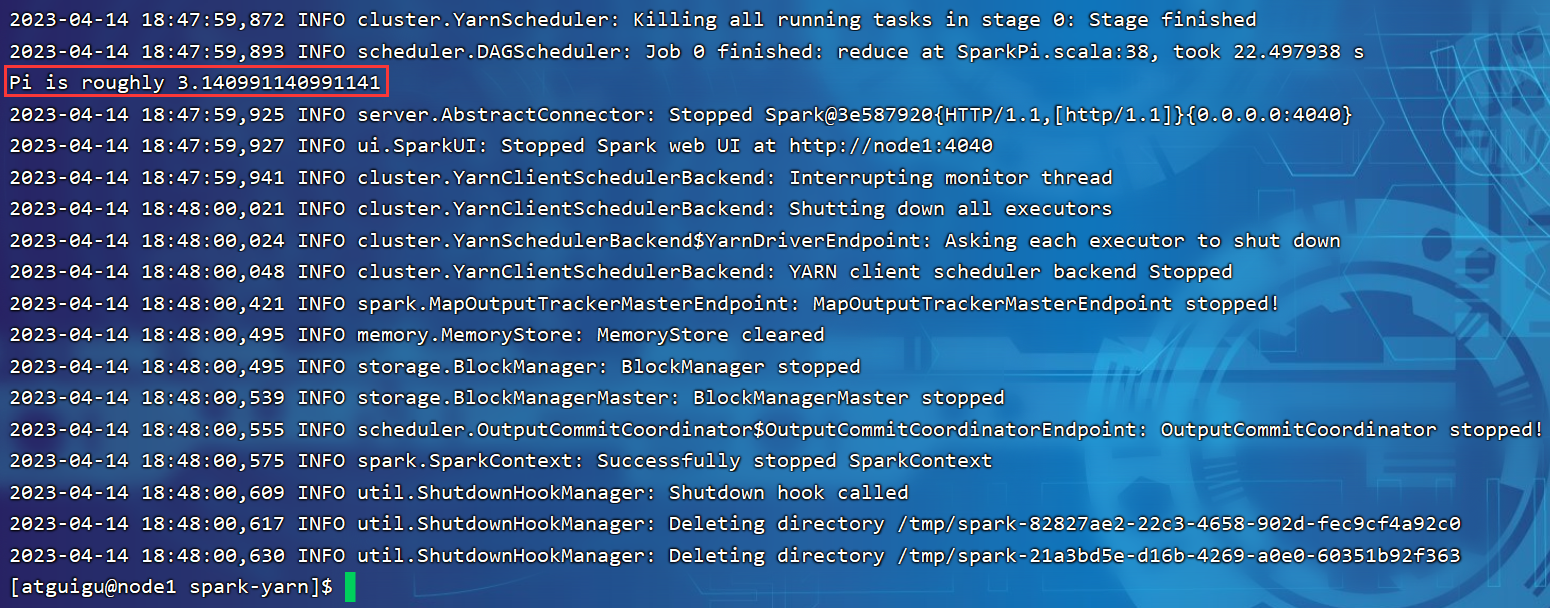
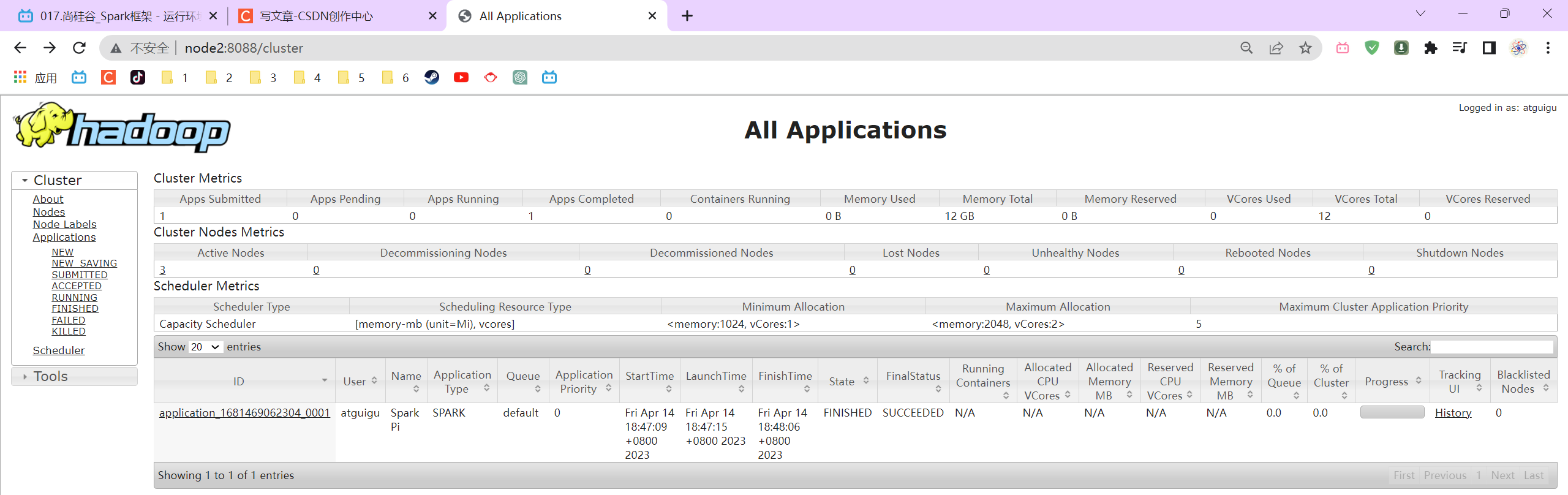
3.3.5 配置历史服务器
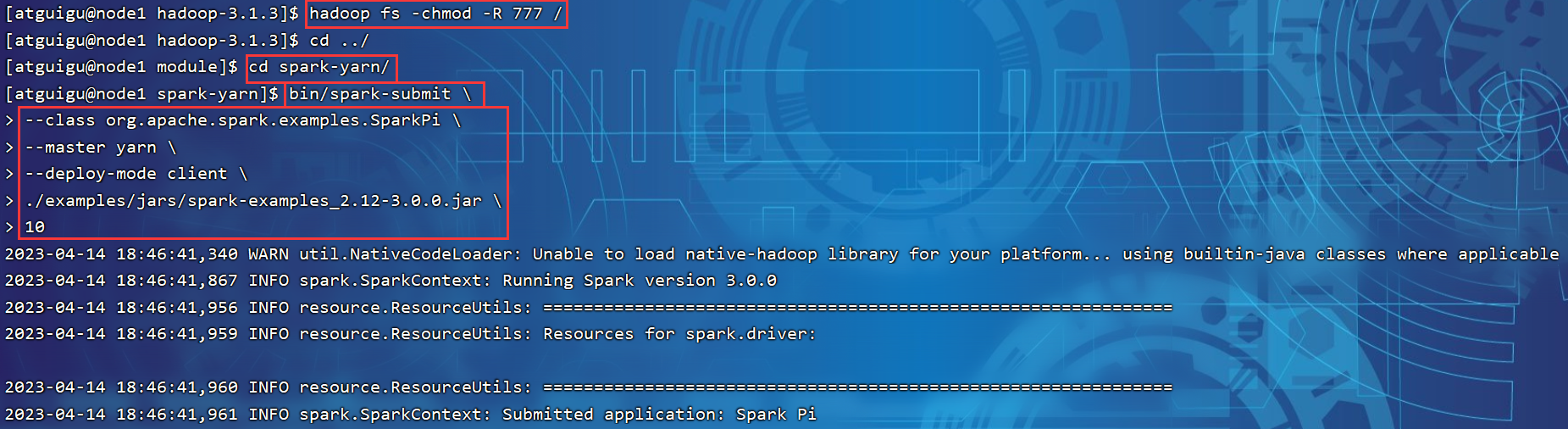
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=root, access=WRITE, inode="/user":atguigu:super
hadoop fs -chmod -R 777 /
P018【018.尚硅谷_Spark框架 - 运行环境 - Windows环境 & 总结】11:06
3.4 K8S&Mesos模式
Mesos 是Apache 下的开源分布式资源管理框架,它被称为是分布式系统的内核,在Twitter 得到广泛使用,管理着 Twitter 超过 30,0000 台服务器上的应用部署,但是在国内,依然使用着传统的Hadoop 大数据框架,所以国内使用 Mesos 框架的并不多,但是原理其实都差不多,这里我们就不做过多讲解了。
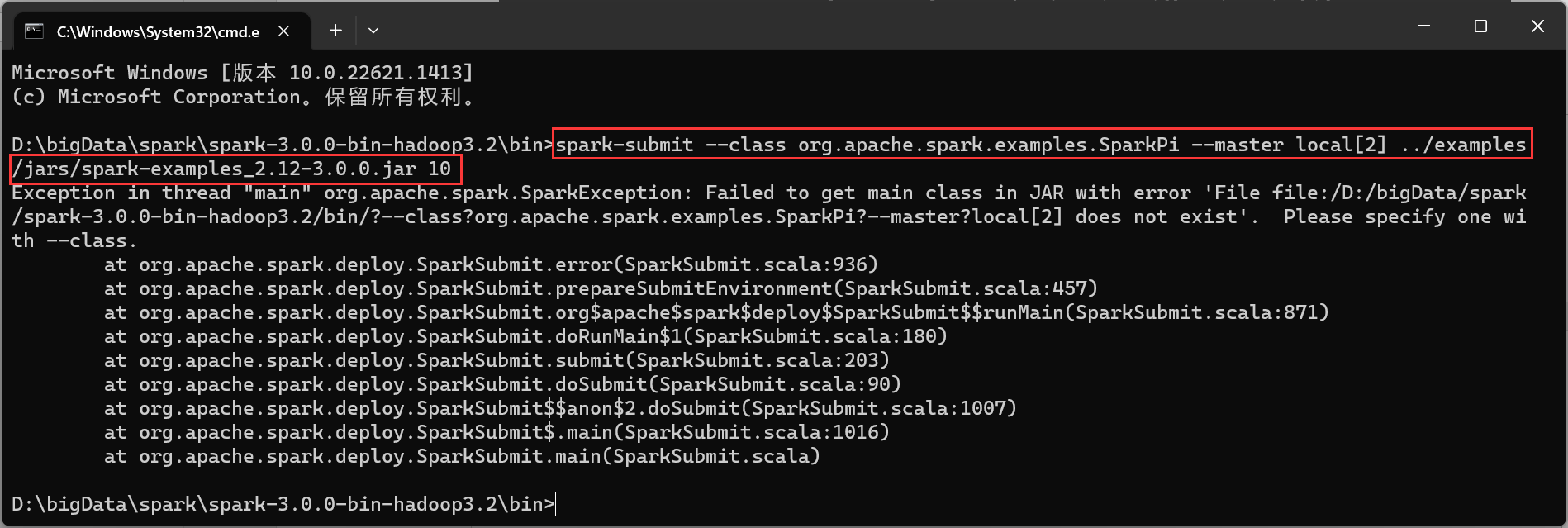
3.5 Windows模式
sc.textFile("input/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ../examples/jars/spark-examples_2.12-3.0.0.jar 10
3.6 部署模式对比
模式
Spark 安装机器数
需启动的进程
所属者
应用场景
Local
1
无
Spark
测试
Standalone
3
Master 及 Worker
Spark
单独部署
Yarn
1
Yarn 及 HDFS
Hadoop
混合部署
3.7 端口号
- Spark 查看当前 Spark-shell 运行任务情况端口号:4040(计算)
- Spark Master 内部通信服务端口号:7077
- Standalone 模式下,Spark Master Web 端口号:8080(资源)
- Spark 历史服务器端口号:18080
- Hadoop YARN 任务运行情况查看端口号:8088
第04章-Spark运行架构
P019【019.尚硅谷_Spark框架 - 核心组件 - 介绍】03:33
第4章 Spark运行架构
4.1 运行架构
4.2.1 Driver
4.2.2 Executor
4.2.3 Master&Worker
4.2.4 ApplicationMaster
P020【020.尚硅谷_Spark框架 - 核心概念 - Executor & Core & 并行度】03:31
4.3 核心概念
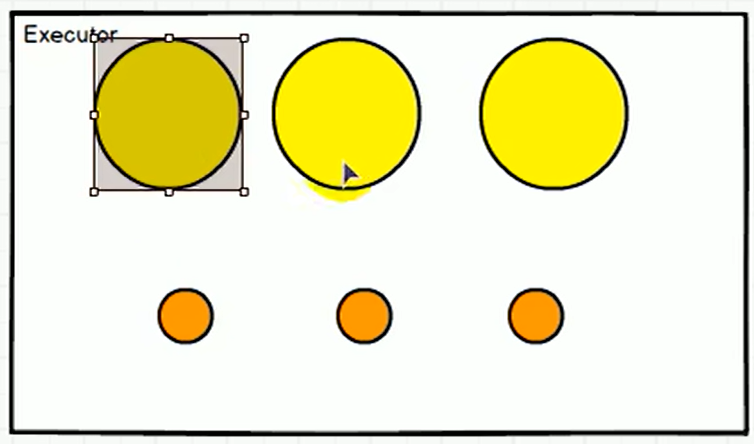
4.3.1 Executor与Core
4.3.2 并行度(Parallelism)
P021【021.尚硅谷_Spark框架 - 核心概念 - DAG & 提交流程 & Yarn两种部署模式】07:00
4.3.3 有向无环图(DAG)
4.4 提交流程
4.2.1 Yarn Client 模式
4.2.2 Yarn Cluster 模式