一. 简介
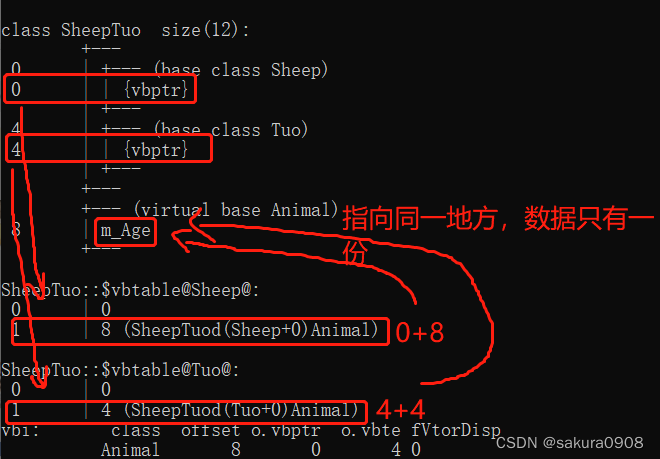
在本篇文章开始之前,先对上篇文章中的一个错误进行指正一下。在部分积生成的时候,需要计算-2A和2A的值,我的做法就是直接左移了一位,这样就会有一个问题,符号位被移掉了,为什么我的计算结果还是对的呢 ? 因为仿真的A比较小,15位的值和符号位是一样的,没有影响,所以当时没有发现。需要对符号位扩展一位,变成17位的数之后,再进行计算2A和-2A。如下图这样,扩展一下最高位。

本次的优化在上次的基础上,进行了一定程度的优化,下面就一一介绍一下。
二. 计算-A,-2A,2A部分
先来看一下之前的代码,可以看到取反模块,这里使用了两次,其实是没有必要的,
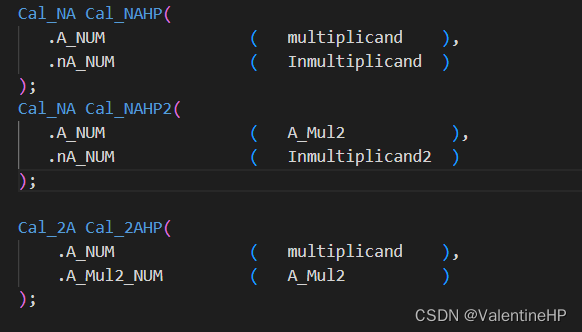
先移位再取反,和先取反再移位是完全等价的,但是在门电路的消耗上却节约了17个非门和17bit加法器。
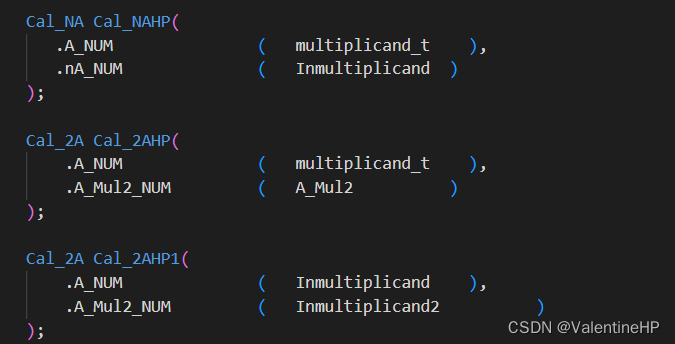
三. 部分积部分
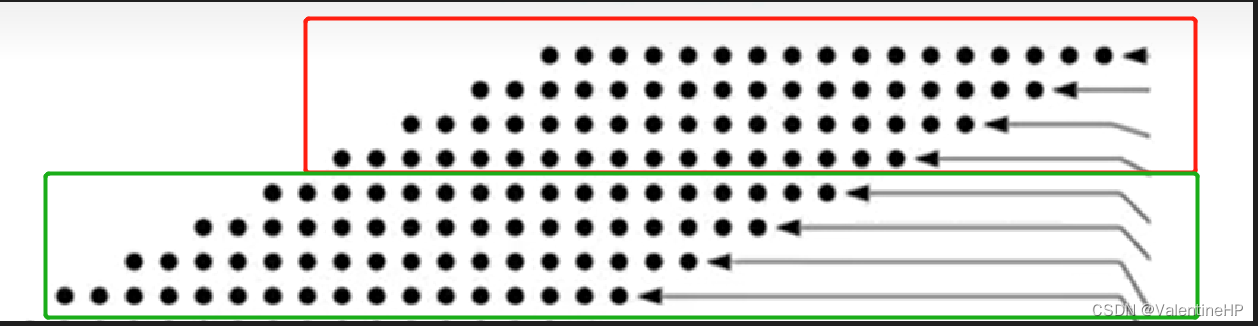
在之前的代码中,生成的8个部分积的位宽全部是32bit,在进行部分积压缩的时候,使用了3个32bit的4:2压缩器。
但是将按照下列方式分组,将8个部分积分成两部分,每部分、每个部分积均为24bit,这样在使用前两个4:2压缩器可以选择24bit的;然后第三个4:2压缩器选择32bit的,将第一部分进行符号位扩展,第二部分末尾进行补0,将其扩展为32bit即可。
这样就将3个32bit的,优化到了 2个24bit和1个32bit的4:2压缩器了。
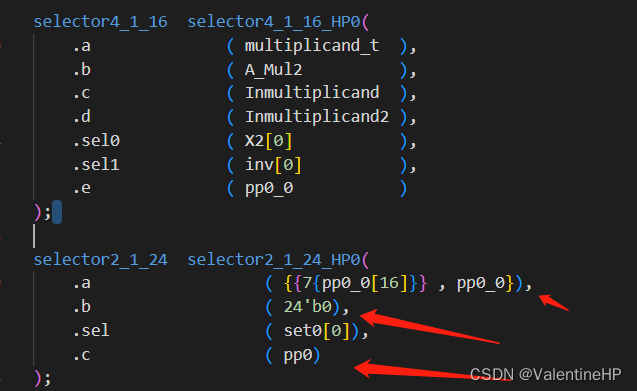
这里的三目运算符,替换为用搭建的选择器了。
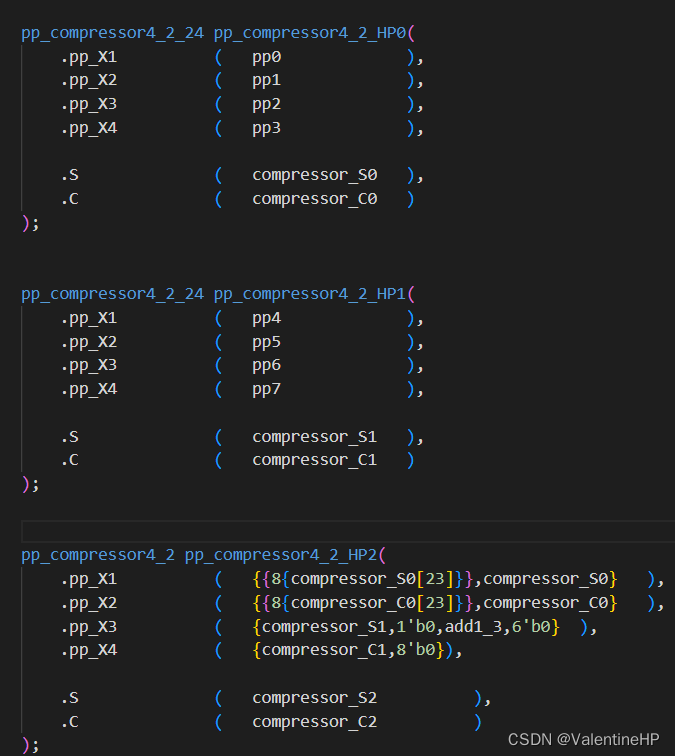
四. 取反加一操作
在求A的负数的时候,需要有个加一的操作,可以将这个操作添加到部分积压上面去,如下图所示,第一个部分积的加一,添加到了第二个部分积的对应的位置,依次类推,第八个部分积的加一,会添加到第九个,但是,部分积的个数只用8个**,所以这里就会多出一个部分积出来**,在压缩的时候,会额外使用一个3:2压缩器。测试知道这样的操作是可取的。
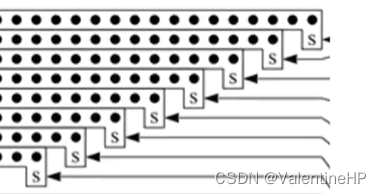
在进行booth编码的时候,添加一个变量,可以认为是这里的S,看看该部分积是否需要加一操作。只要set0为0,inv为1,即有取放操作。
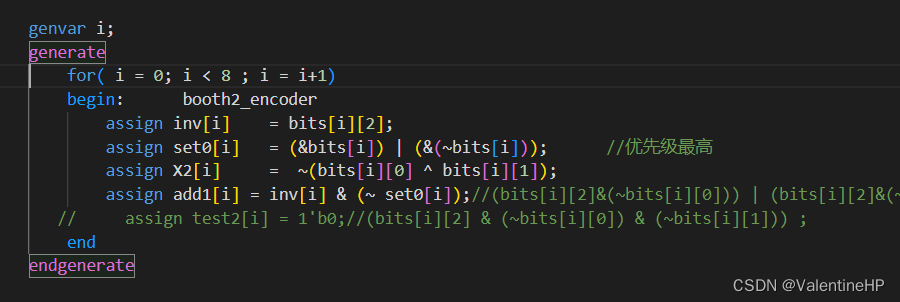
然后在部分积生成的时候,将第一个部分积的加一标志,添加到第二个部分积对应的位置。
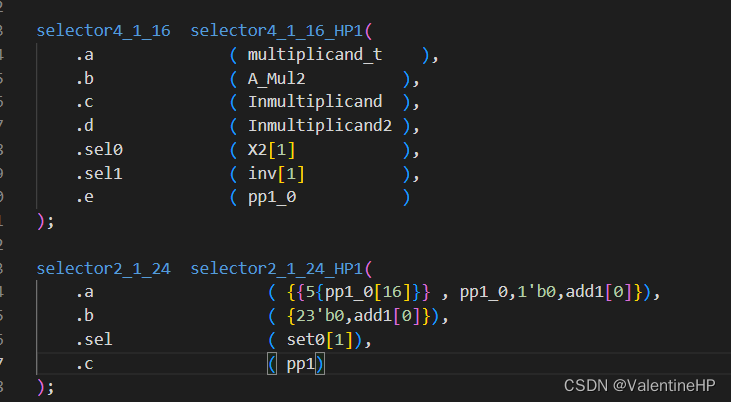
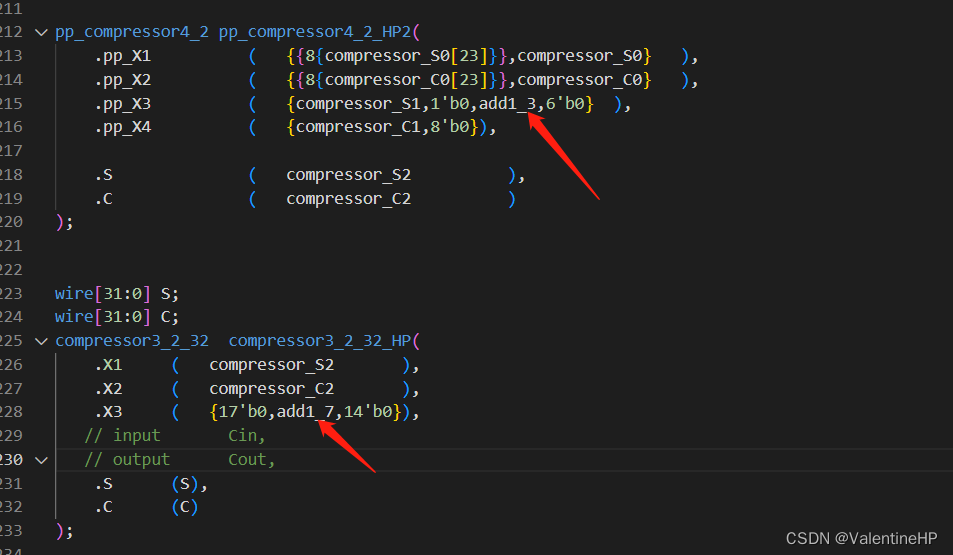
其中需要注意一点,由于我们对部分积进行了分组,第一组的最后一个部分积,是加不到第二组的第一个部分积的,需要在部分积压缩的时候添加上去,为什么可以看完整代码的位宽。
五. 小结
本次在上篇文章的基础上,进行了初步的优化,门的使用和延时有了初步的提升,在Vivado中延时从16ns下降到了15ns,DC中从6ns下降到了5ns。
回复 定点乘法器优化V1 获取完整代码
后面还会继续优化,欢迎关注。