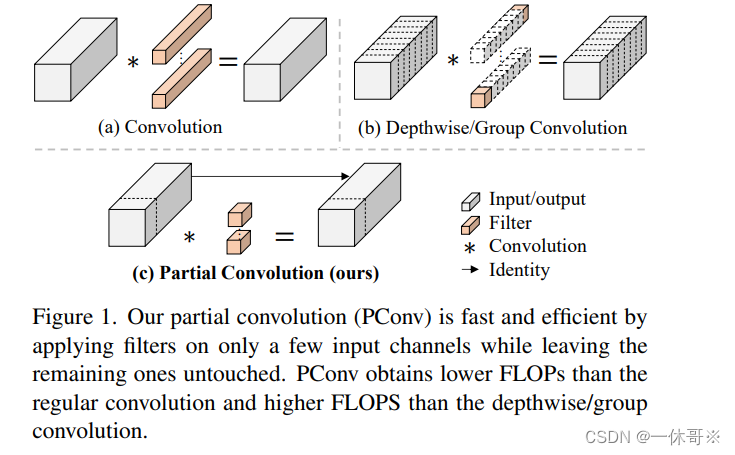
文章目录
- 任务
- 查看当前的准确率情况
- 使用遗传算法进行优化
- 完整代码
任务
使用启发式优化算法遗传算法对多层感知机中中间层神经个数进行优化,以提高模型的准确率。
待优化的模型:
基于TensorFlow2实现的Mnist手写数字识别多层感知机MLP
# MLP手写数字识别模型,待优化的参数为layer1、layer2
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(layer1, activation='relu'),
tf.keras.layers.Dense(layer2, activation='relu'),
tf.keras.layers.Dense(10,activation='softmax') # 对应0-9这10个数字
])
查看当前的准确率情况
设置随机树种子,避免相同结构的神经网络其结果不同的影响。
random_seed = 10
np.random.seed(random_seed)
tf.random.set_seed(random_seed)
random.seed(random_seed)
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(10,activation='softmax') # 对应0-9这10个数字
])
optimizer = tf.keras.optimizers.Adam()
loss_func = tf.keras.losses.SparseCategoricalCrossentropy()
model.compile(optimizer=optimizer,loss=loss_func,metrics=['acc'])
history = model.fit(dataset, validation_data=test_dataset, epochs=5, verbose=1)
score = model.evaluate(test_dataset)
print("测试集准确率:",score) # 输出 [损失率,准确率]
Epoch 1/5
235/235 [==============================] - 1s 5ms/step - loss: 0.4663 - acc: 0.8703 - val_loss: 0.2173 - val_acc: 0.9361
Epoch 2/5
235/235 [==============================] - 1s 4ms/step - loss: 0.1882 - acc: 0.9465 - val_loss: 0.1604 - val_acc: 0.9521
Epoch 3/5
235/235 [==============================] - 1s 4ms/step - loss: 0.1362 - acc: 0.9608 - val_loss: 0.1278 - val_acc: 0.9629
Epoch 4/5
235/235 [==============================] - 1s 4ms/step - loss: 0.1084 - acc: 0.9689 - val_loss: 0.1086 - val_acc: 0.9681
Epoch 5/5
235/235 [==============================] - 1s 4ms/step - loss: 0.0878 - acc: 0.9740 - val_loss: 0.1077 - val_acc: 0.9675
40/40 [==============================] - 0s 2ms/step - loss: 0.1077 - acc: 0.9675
测试集准确率: [0.10773944109678268, 0.9674999713897705]
准确率为96.7%
使用遗传算法进行优化
使用scikit-opt提供的遗传算法库进行优化。(pip install scikit-opt)
官方文档:https://scikit-opt.github.io/scikit-opt/#/zh/README
# 遗传算法调用
ga = GA(func=loss_func, n_dim=2, size_pop=4, max_iter=3, prob_mut=0.15, lb=[10, 10], ub=[256, 256], precision=1)
优化目标函数loss_func:1 - 模型准确率(求优化目标函数的最小值)
待优化的参数数量n_dim:2
种群数量size_pop:4
迭代次数max_iter:3
变异概率prob_mut:0.15
待优化两个参数的取值范围均为10-256
精确度precision:1
# 定义多层感知机模型函数
def mlp_model(layer1, layer2):
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(layer1, activation='relu'),
tf.keras.layers.Dense(layer2, activation='relu'),
tf.keras.layers.Dense(10,activation='softmax') # 对应0-9这10个数字
])
optimizer = tf.keras.optimizers.Adam()
loss_func = tf.keras.losses.SparseCategoricalCrossentropy()
model.compile(optimizer=optimizer,loss=loss_func,metrics=['acc'])
return model
# 定义损失函数
def loss_func(params):
random_seed = 10
np.random.seed(random_seed)
tf.random.set_seed(random_seed)
random.seed(random_seed)
layer1 = int(params[0])
layer2 = int(params[1])
model = mlp_model(layer1, layer2)
history = model.fit(dataset, validation_data=test_dataset, epochs=5, verbose=0)
return 1 - history.history['val_acc'][-1]
ga = GA(func=loss_func, n_dim=2, size_pop=4, max_iter=3, prob_mut=0.15, lb=[10, 10], ub=[256, 256], precision=1)
bestx, besty = ga.run()
print('bestx:', bestx, '\n', 'besty:', besty)
结果:
bestx: [165. 155.]
besty: [0.02310002]
通过迭代,找到layer1、layer2的最好值为165、155,此时准确率为1-0.0231=0.9769。
查看每轮迭代的损失函数值图(1-准确率):
Y_history = pd.DataFrame(ga.all_history_Y)
fig, ax = plt.subplots(2, 1)
ax[0].plot(Y_history.index, Y_history.values, '.', color='red')
Y_history.min(axis=1).cummin().plot(kind='line')
plt.show()
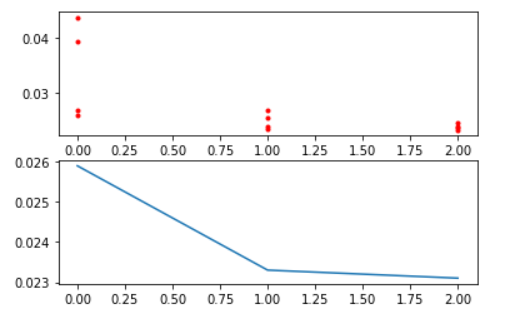
上图为三次迭代种群中,种群每个个体的损失函数值(每个种群4个个体)。
下图为三次迭代种群中,种群个体中的最佳损失函数值。
可以看出,通过遗传算法,其准确率有一定的提升。
增加种群数量及迭代次数效果可更加明显。
完整代码
# python3.6.9
import tensorflow as tf # 2.3
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import random
from sko.GA import GA
# 数据导入,获取训练集和测试集
(train_image, train_labels), (test_image, test_labels) = tf.keras.datasets.mnist.load_data()
# 增加通道维度
train_image = tf.expand_dims(train_image, -1)
test_image = tf.expand_dims(test_image, -1)
# 归一化 类型转换
train_image = tf.cast(train_image/255, tf.float32)
test_image = tf.cast(test_image/255, tf.float32)
train_labels = tf.cast(train_labels, tf.int64)
test_labels = tf.cast(test_labels, tf.int64)
# 创建Dataset
dataset = tf.data.Dataset.from_tensor_slices((train_image, train_labels)).shuffle(60000).batch(256)
test_dataset = tf.data.Dataset.from_tensor_slices((test_image, test_labels)).batch(256)
# 定义多层感知机模型函数
def mlp_model(layer1, layer2):
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(layer1, activation='relu'),
tf.keras.layers.Dense(layer2, activation='relu'),
tf.keras.layers.Dense(10,activation='softmax') # 对应0-9这10个数字
])
optimizer = tf.keras.optimizers.Adam()
loss_func = tf.keras.losses.SparseCategoricalCrossentropy()
model.compile(optimizer=optimizer,loss=loss_func,metrics=['acc'])
return model
# 定义损失函数
def loss_func(params):
random_seed = 10
np.random.seed(random_seed)
tf.random.set_seed(random_seed)
random.seed(random_seed)
layer1 = int(params[0])
layer2 = int(params[1])
model = mlp_model(layer1, layer2)
history = model.fit(dataset, validation_data=test_dataset, epochs=5, verbose=0)
return 1 - history.history['val_acc'][-1]
ga = GA(func=loss_func, n_dim=2, size_pop=4, max_iter=3, prob_mut=0.15, lb=[10, 10], ub=[256, 256], precision=1)
bestx, besty = ga.run()
print('bestx:', bestx, '\n', 'besty:', besty)