一、前言
随着科技的进步和社会的发展,人工智能得到了愈加广泛的重视,特别是最近大火的Chatgpt,充分展现了研发通用人工智能助手广阔的研究和应用前景。让越来越多的组织和企业跟风加入到人工智能领域的研究中,
但机器学习的实施是一项极其复杂的工作,不仅需要专业技能,还涉及大量的试错。无论是“专业”,抑或是“试错”,其背后都是高昂的成本。而且,通过传统的方式创建机器学习模型,开发人员需要从高度手动的数据准备过程开始,经过可视化、选择算法、设置框架、训练模型、调整数百万个可能的参数、部署模型并监视其性能,这个过程往往需要重复多次,是非常繁琐且特别耗时的。所以说,究竟有多少公司能够玩得起,想必很多人都会在心里打出一个大大的问号。
最近刚好受邀参与了亚马逊云科技【云上探索实验室】活动,使用了它们推出的 Amazon SageMaker来开展机器学习的工作,体验下来的效果是让我很满意的,无论是在构建,数据标注还是模型训练部署等方面都带来了巨大的效率提升,通过使用它预置的常用算法,以及自动模型调优大大降低了模型构建和训练的难度,让我们更容易的使用ML。另外,Amazon SageMaker与其他亚马逊网络服务(AWS)产品集成,如AWS S3、AWS Glue和AWS Lambda,让我们能够轻松构建端到端的ML工作流程:

下面分享一下我体验官网的一个实验案例,在过程中遇到了什么问题和如何解决的,供大家参考。
二、体验分享
1、数据输入
1)原理
SageMaker Processing job 要求数据的输入和输出都需要在 S3 ,基本原理图如下:
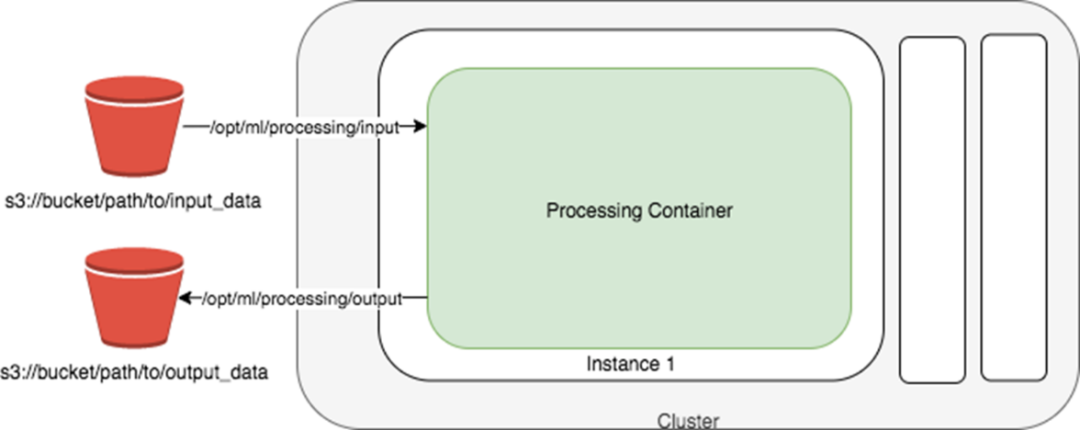
2)实操
步骤1:创建Amazon SageMaker 笔记本实例
Amazon SageMaker 笔记本实例是运行 Jupyter 笔记本应用程序的完全托管的机器学习 (ML) 亚马逊弹性计算云 (Amazon EC2) 计算实例。我们可以使用笔记本实例创建和管理 Jupyter 笔记本来预处理数据,以及训练和部署机器学习模型。
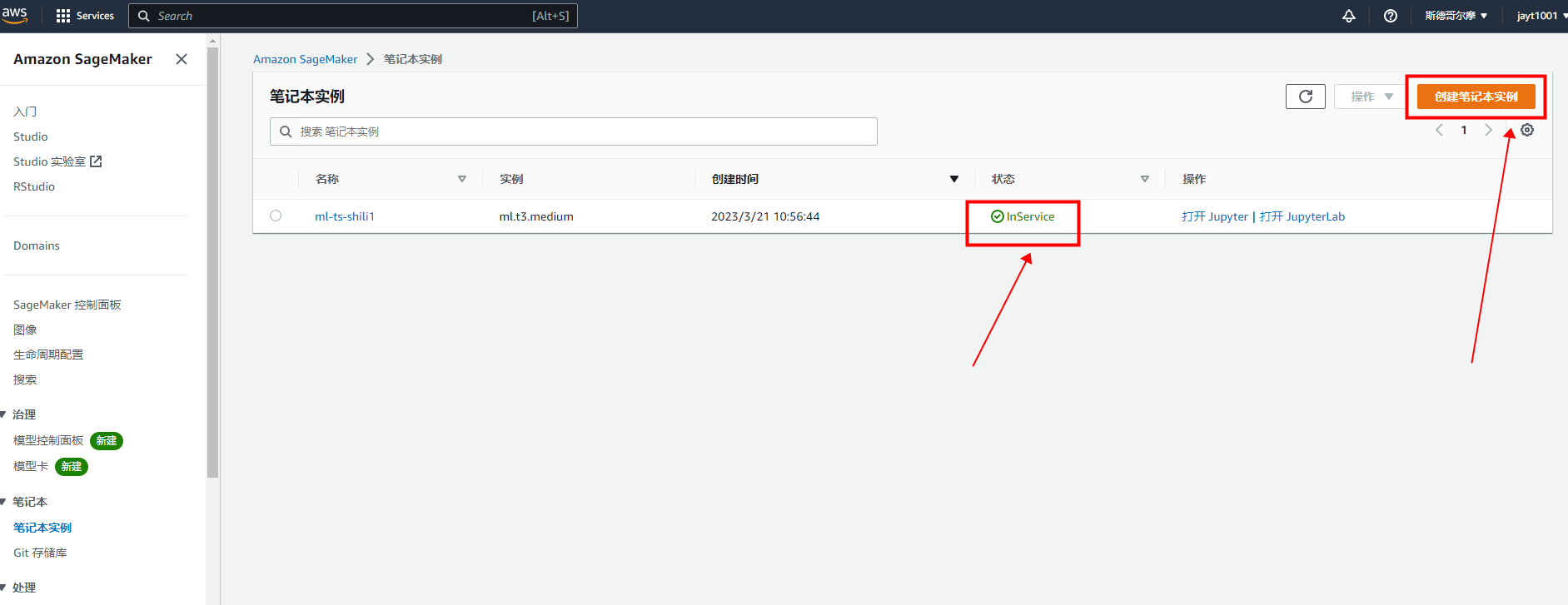
亚马逊 SageMaker 笔记本实例创建好之后会在图中的笔记本实例中新增一条状态为Pending的数据,稍等一会儿,状态会自动变为InService,此时改实例为可使用状态。
步骤2:将数据加载到笔记本实例,并上传到Amazon S3
当实例状态变为InService之后,选择打开 Jupyter,然后在 Jupyter notebook 中,为 New(新建)选择 conda_python3,复制粘贴以下示例上传数据代码并运行:
import sagemaker
sess = sagemaker.Session()
bucket = sess.default_bucket()
!aws s3 sync s3://sagemaker-sample-files/datasets/image/caltech-101/inference/ s3://{bucket}/ground-truth-demo/images/
print('Copy and paste the below link into a web browser to confirm the ten images were successfully uploaded to your bucket:')
print(f'https://s3.console.aws.amazon.com/s3/buckets/{bucket}/ground-truth-demo/images/')
print('\nWhen prompted by Sagemaker to enter the S3 location for input datasets, you can paste in the below S3 URL')
print(f's3://{bucket}/ground-truth-demo/images/')
print('\nWhen prompted by Sagemaker to Specify a new location, you can paste in the below S3 URL')
print(f's3://{bucket}/ground-truth-demo/labeled-data/')3)使用中遇到的问题及解决方案
1、S3 Bucket创建时需要按照这个命名规则:sagemaker-<your-Region>-<your-aws-account-id>,否则运行上面的示例代码时会报错。
2、示例代码运行的时候遇到access is forbidden报错信息:
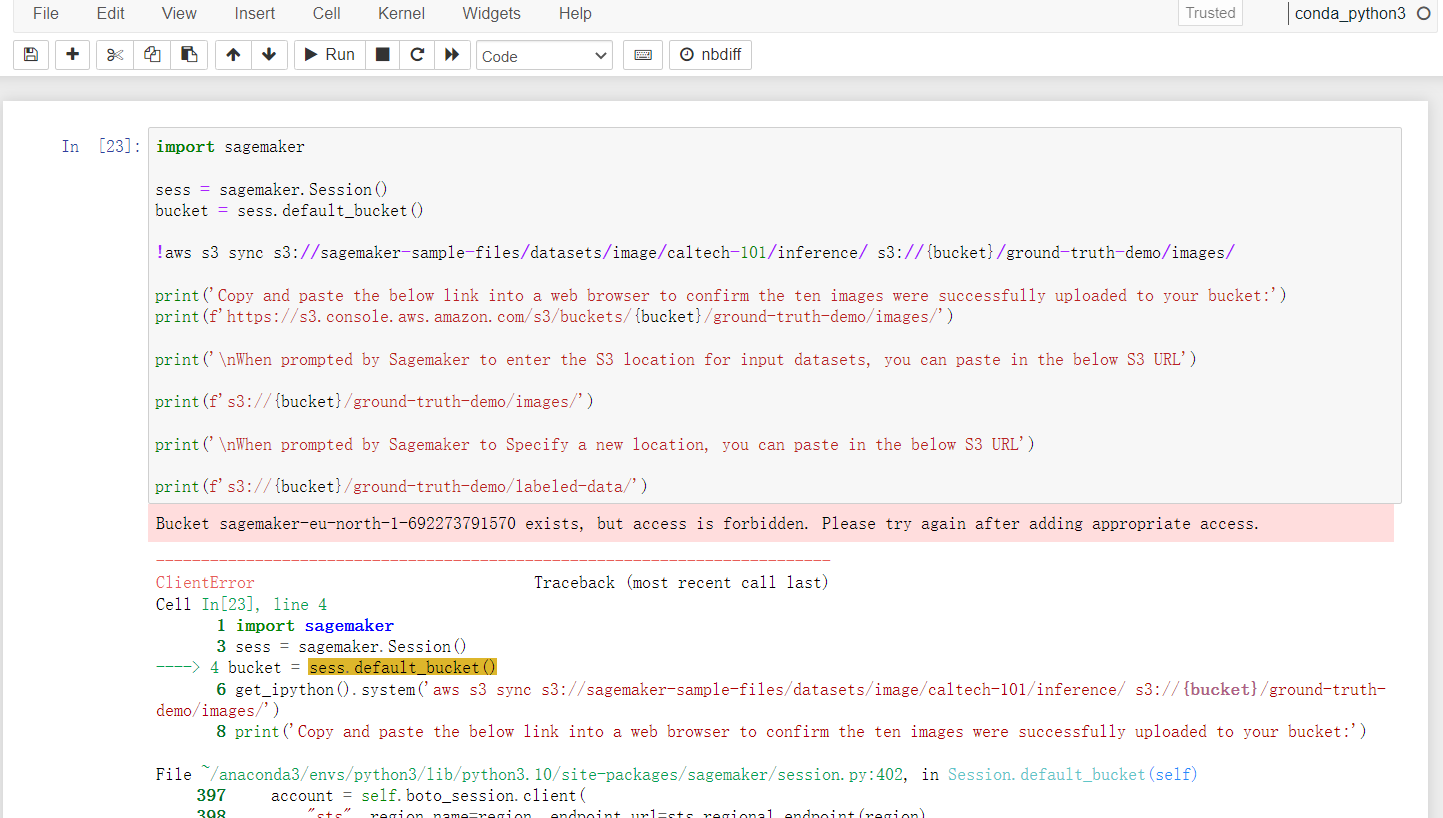
这表明权限策略的设置有问题,需要我们去修改存储桶权限、配置存储桶策略以及配置角色策略
2.1:修改存储桶权限——进入编辑“屏蔽公共访问权限(存储桶设置)”位置,把”阻止所有公开访问“复选框标记为未选中状态
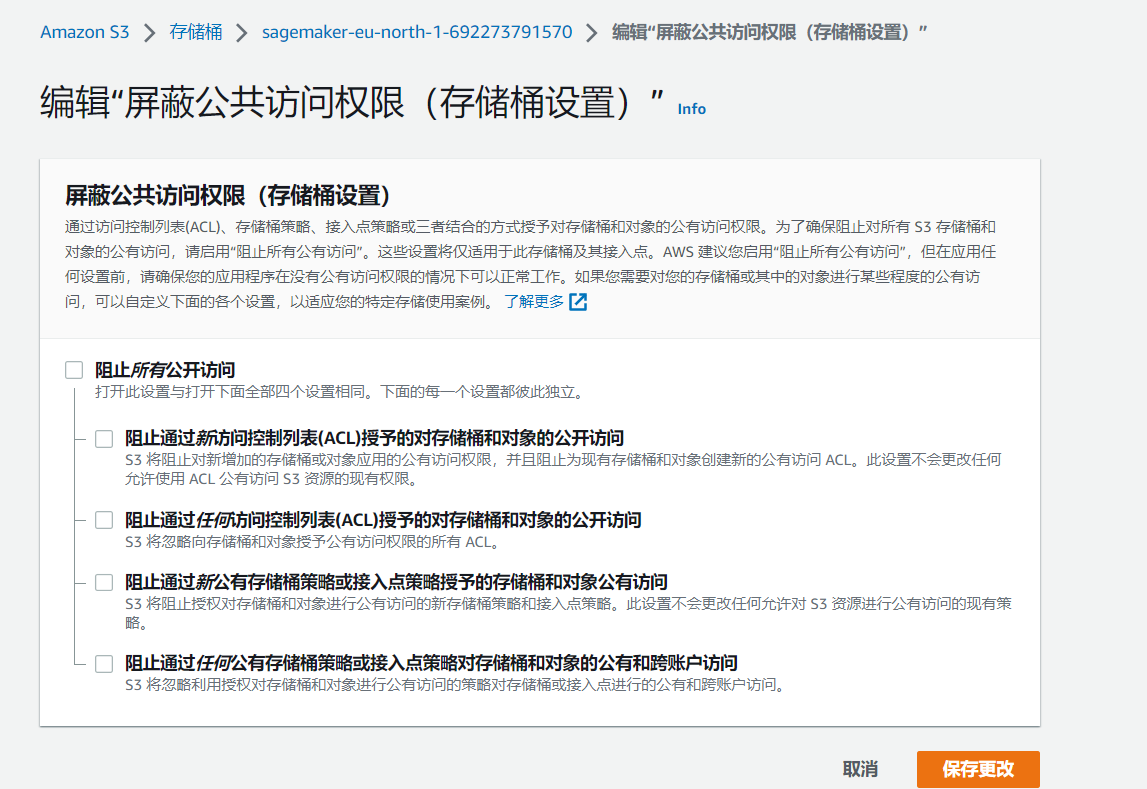
2.2:配置存储桶策略——我们可以使用SageMaker自带的策略生成器,正确填写对应信息后一键快捷生成Json策略:
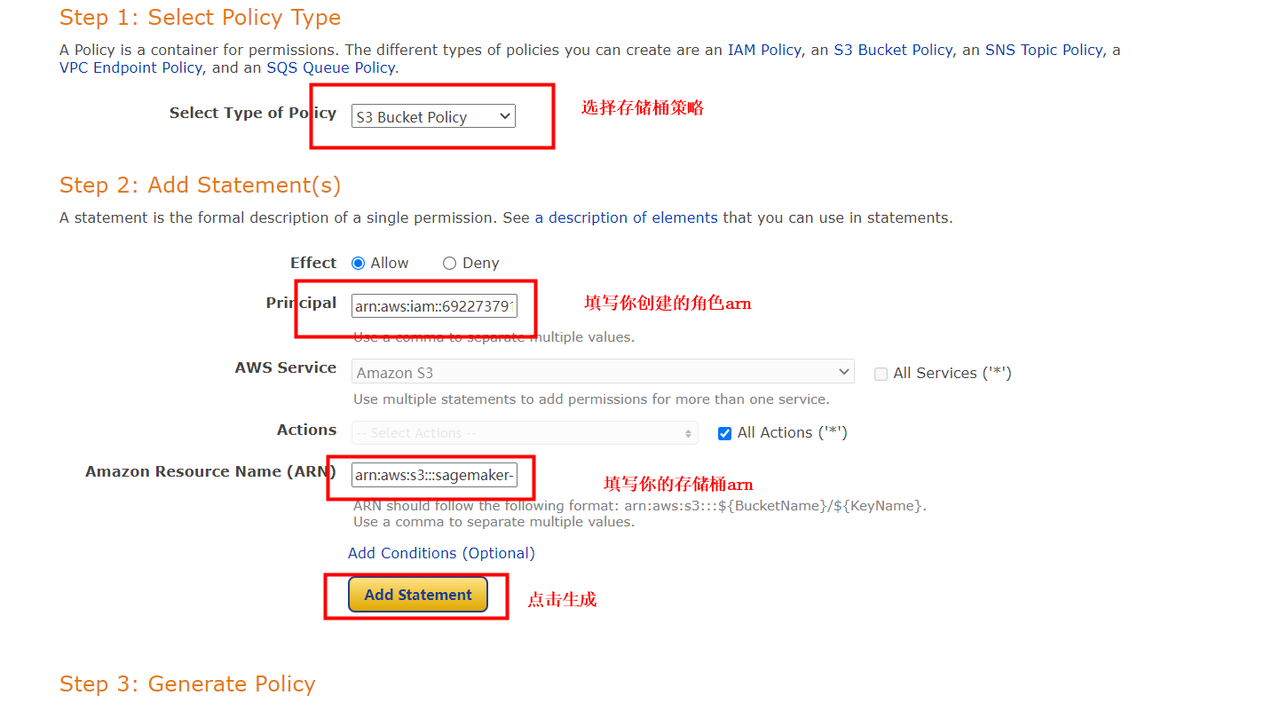
上述步骤点击”Add Statement“按钮后会自动生成如下Json策略
{
"Version": "2012-10-17",
"Id": "Policy1679391476168",
"Statement": [
{
"Sid": "Stmt1679391475056",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::692273791570:role/service-role/SageMaker-tt"
},
"Action": "s3:*",
"Resource": "arn:aws:s3:::sagemaker-eu-north-1-692273791570"
}
]
}上面的json策略生成成功后,直接复制粘贴到存储桶权限策略中:
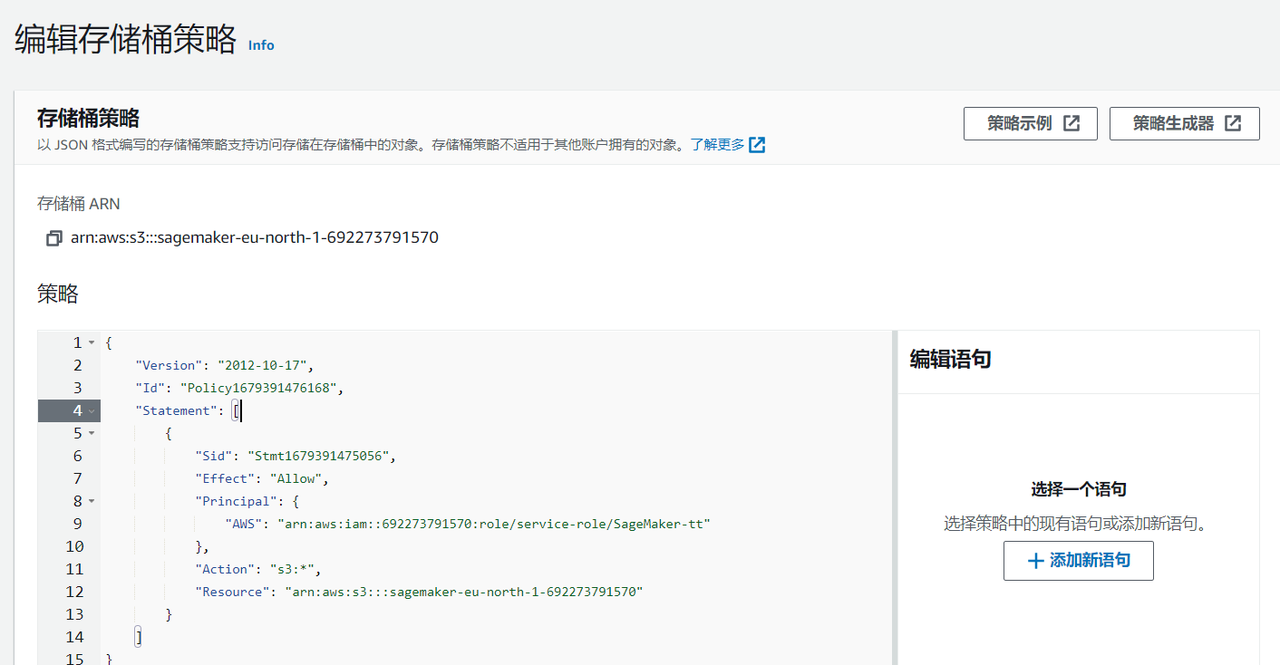
2.3:配置角色策略——我们可以在笔记本示例详情中找到配置的IAM角色:
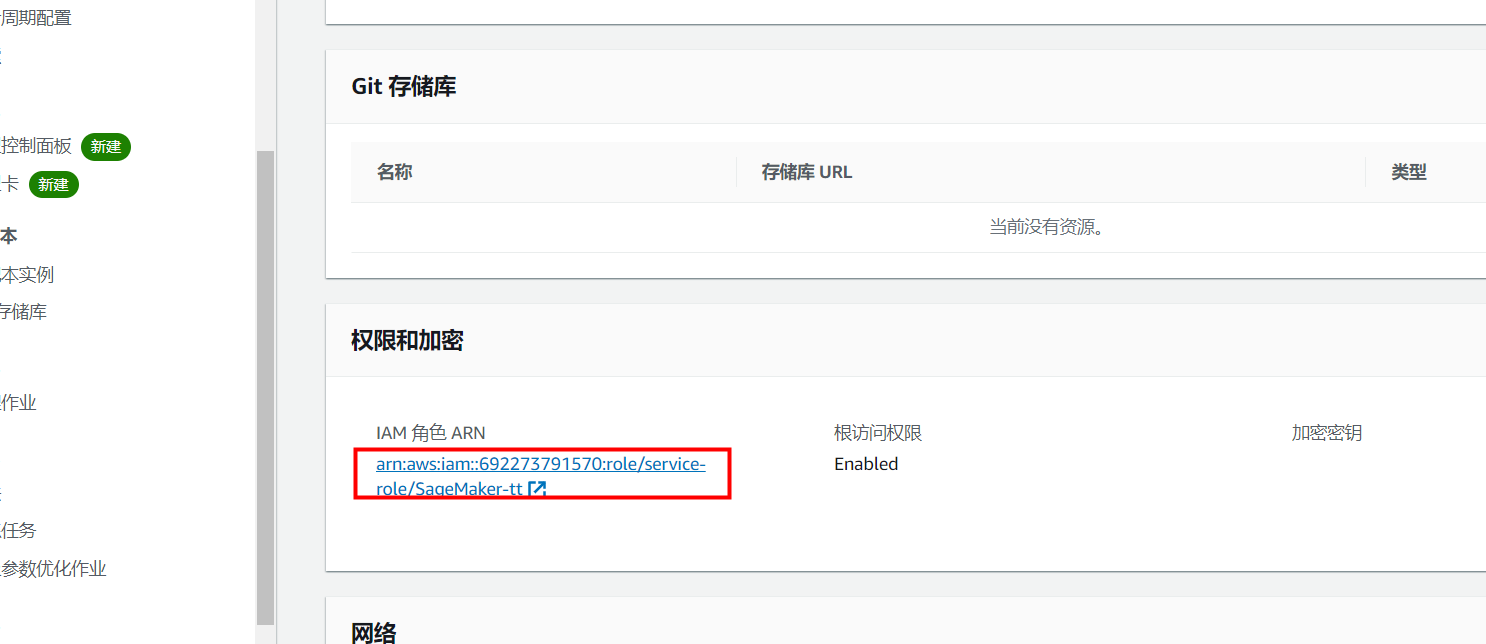
点击进入后,找到下面的策略项就可对存储桶权限策略进行编辑:
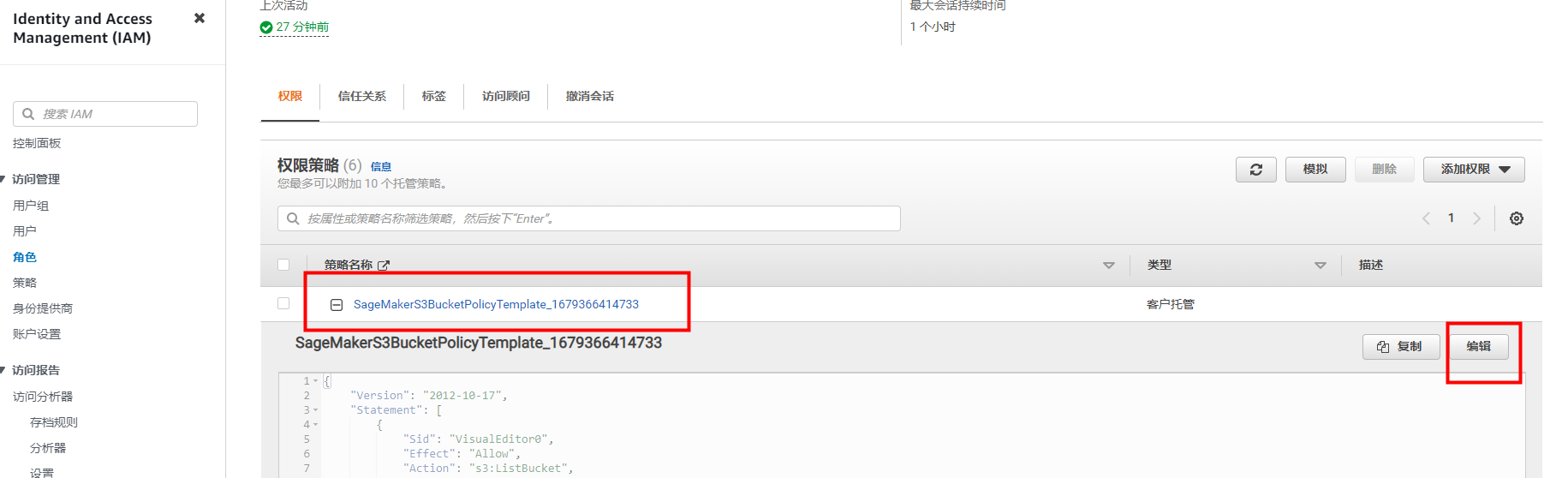
提供两种编辑方式,这里建议使用可视化编辑更加的友好:
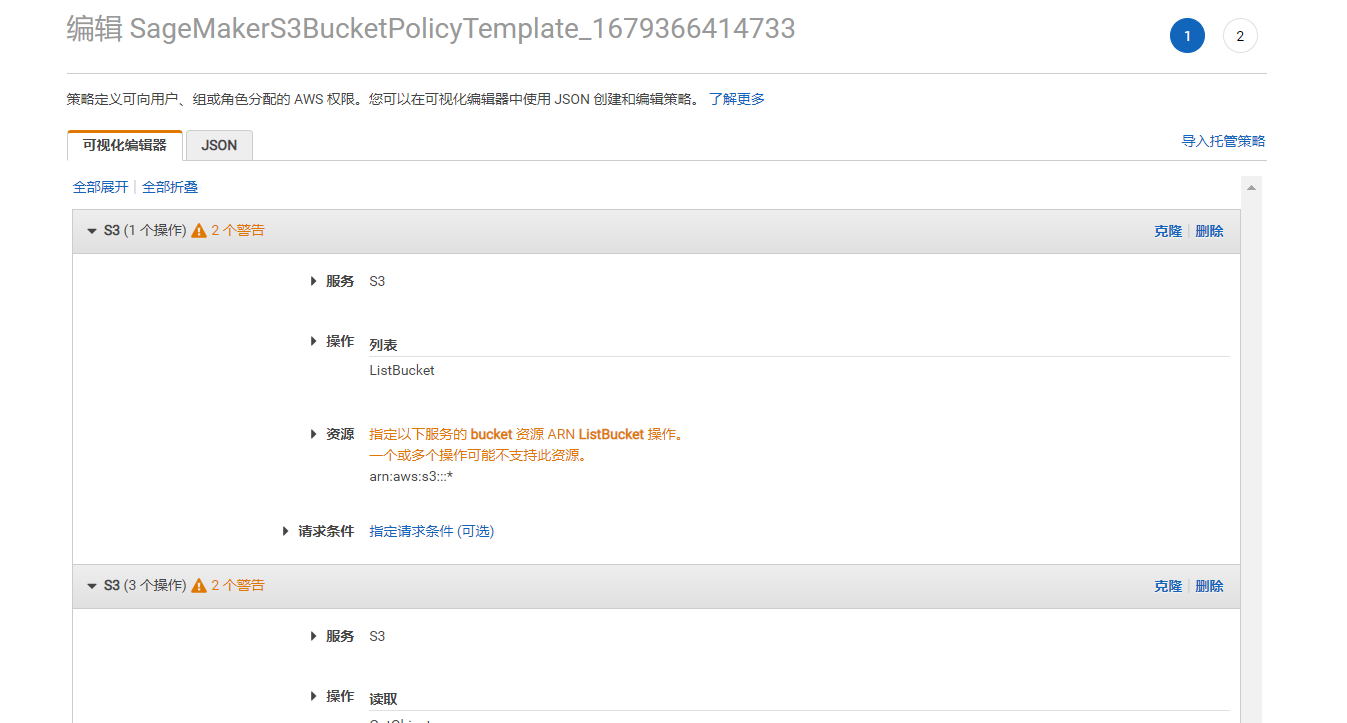
我这里将资源范围设置为所有S3存储桶(你们也可以指定刚刚创建的存储桶)都放开,然后保存后就会生成json策略,如下所示:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "s3:ListBucket",
"Resource": "arn:aws:s3:::*"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject"
],
"Resource": "arn:aws:s3:::*/*"
}
]
}这样我们就把角色权限也配置好了,再次执行示例上传代码就成功了:
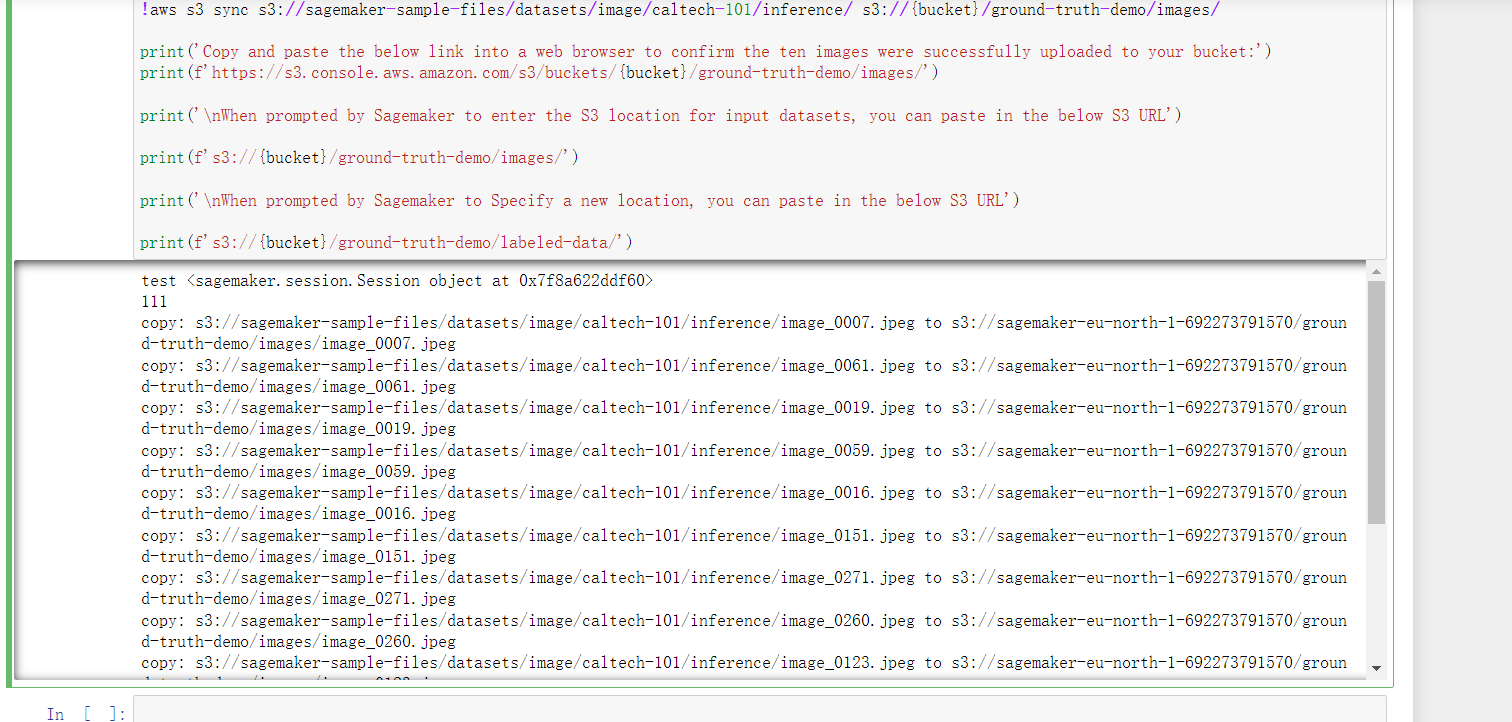
在成功运行代码以后,打开 Amazon S3 控制台并导航至 sagemaker-<your-Region>-<your-aws-account-id>/ground-truth-demo/images 位置,可以看到图片已经在你的默认S3存储桶文件列表了:
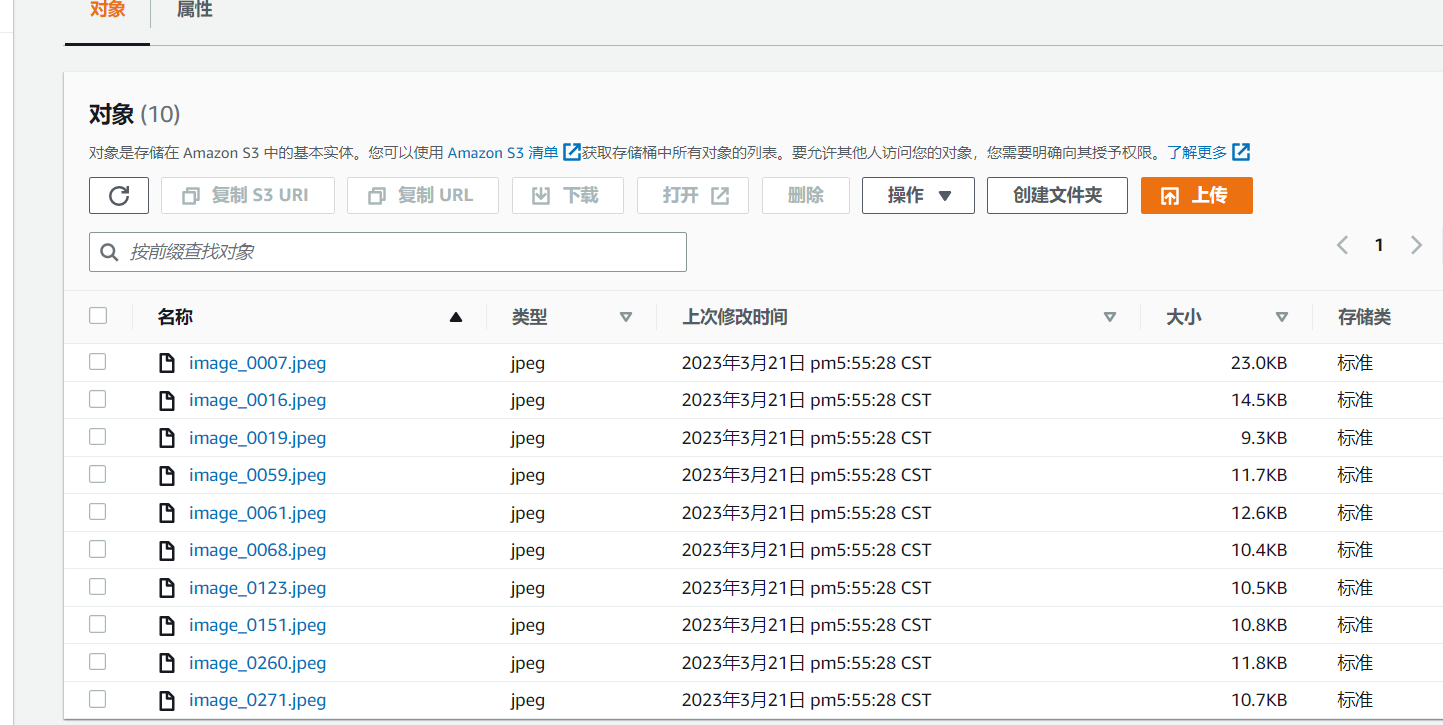
2、数据处理
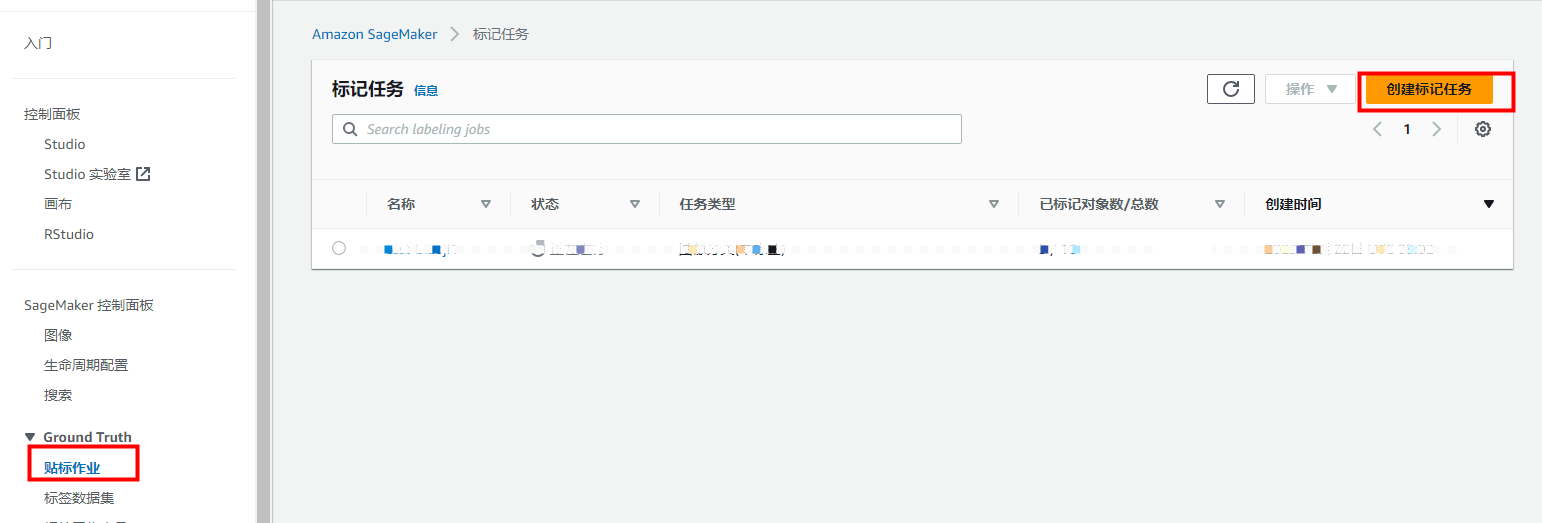
1)创建标记任务
打开 SageMaker 控制台。在左侧导航窗格中,选择 Ground Truth、Labeling jobs(贴标作业)。然后选择 Create labeling job(创建标记任务)。
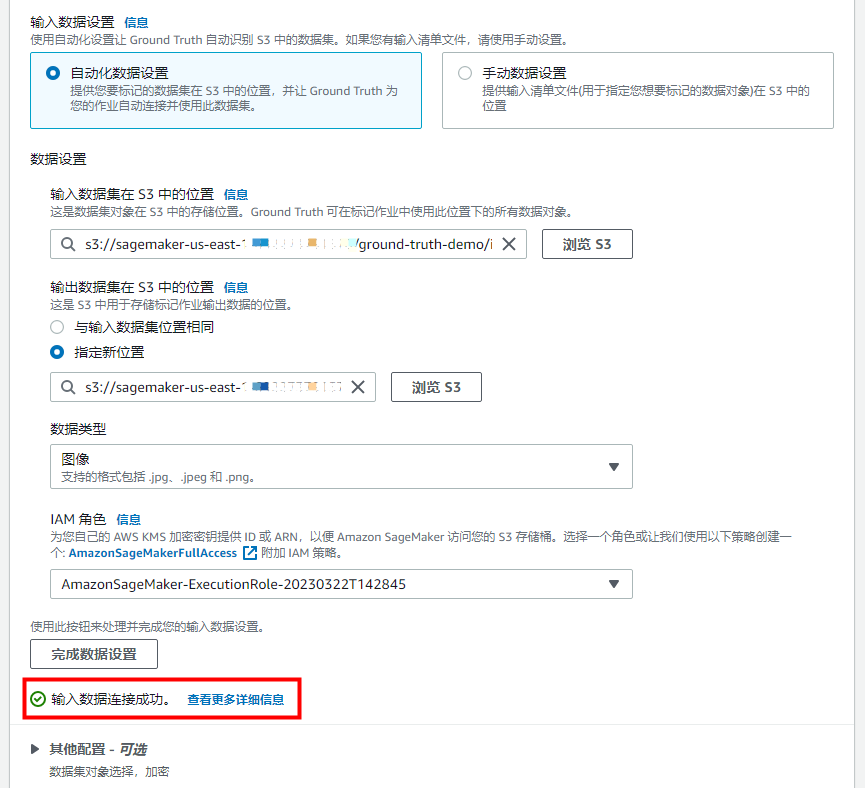
在标记任务详细信息页面,按照下图进行配置,图中的两个路径也可以直接从我们早前所运行 Jupyter notebook 的 print 语句里面去复制对应的值,配置成功后,点击”完成数据设置“,就会出现输入数据链接成功的提示。
2)设置标签
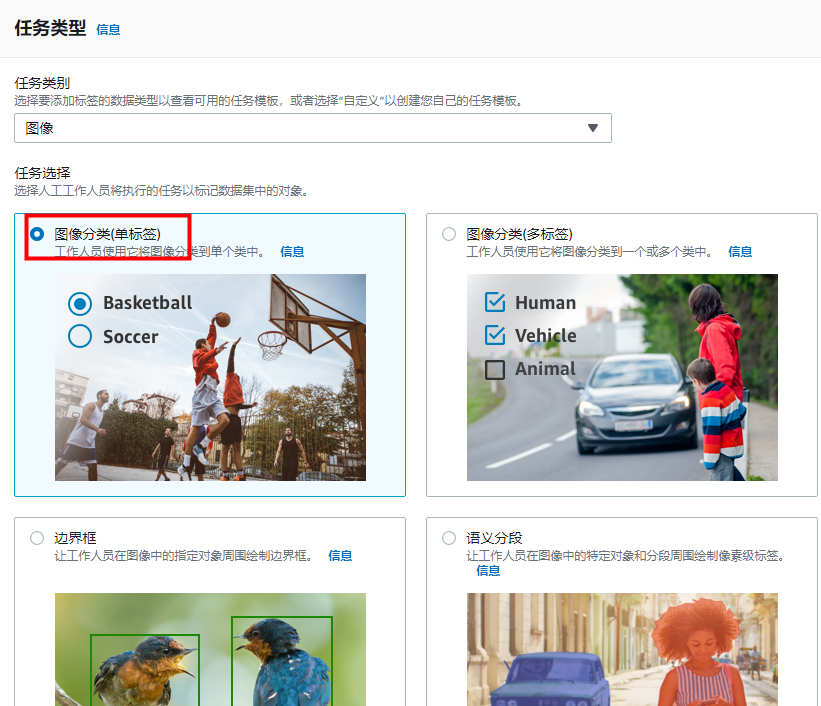
在 Task type(任务类型)部分,为 Task category(任务类别)选择 Image(图像)。对于 Task selection(任务选择),选择 Image Classification (Single Label)(图像分类(单标签)),然后选择 Next(下一步)。
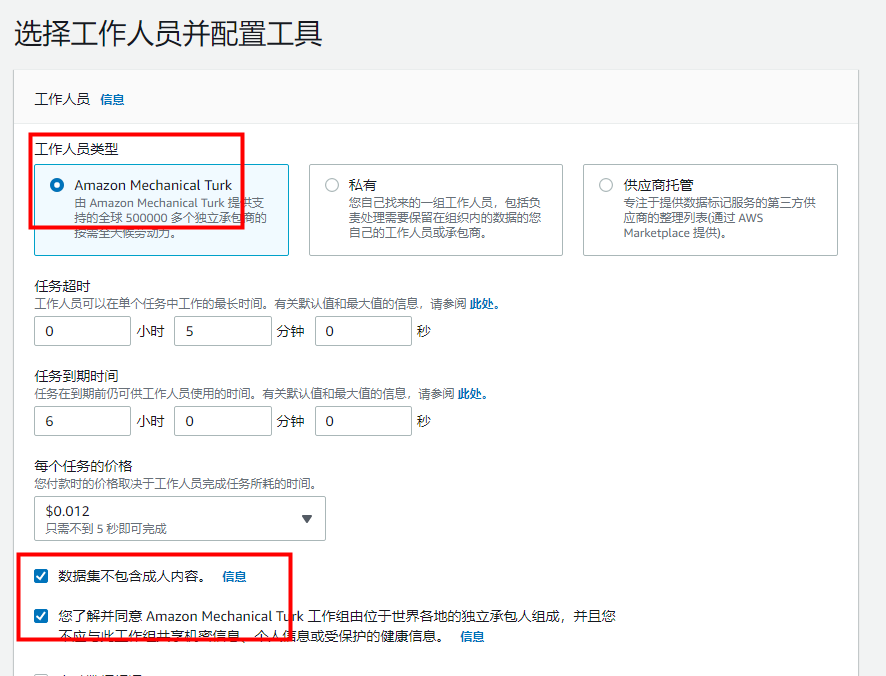
在 Select workers and configure tool(选择工作人员并配置工具)部分中,对于Worker types(工作人员类型),选择 Amazon Mechanical Turk。
选择 The dataset does not contain adult content(数据集不包含成人内容)。
选择 You understand and agree that the Amazon Mechanical Turk workforce consists of independent contractors located worldwide and that you should not share confidential information, personal information or protected health information with this workforce(您了解并同意 Amazon Mechanical Turk 工作团队由分布在世界各地的独立合约商组成,而且您不得与该工作团队分享机密信息、个人信息或受保护的健康信息。)
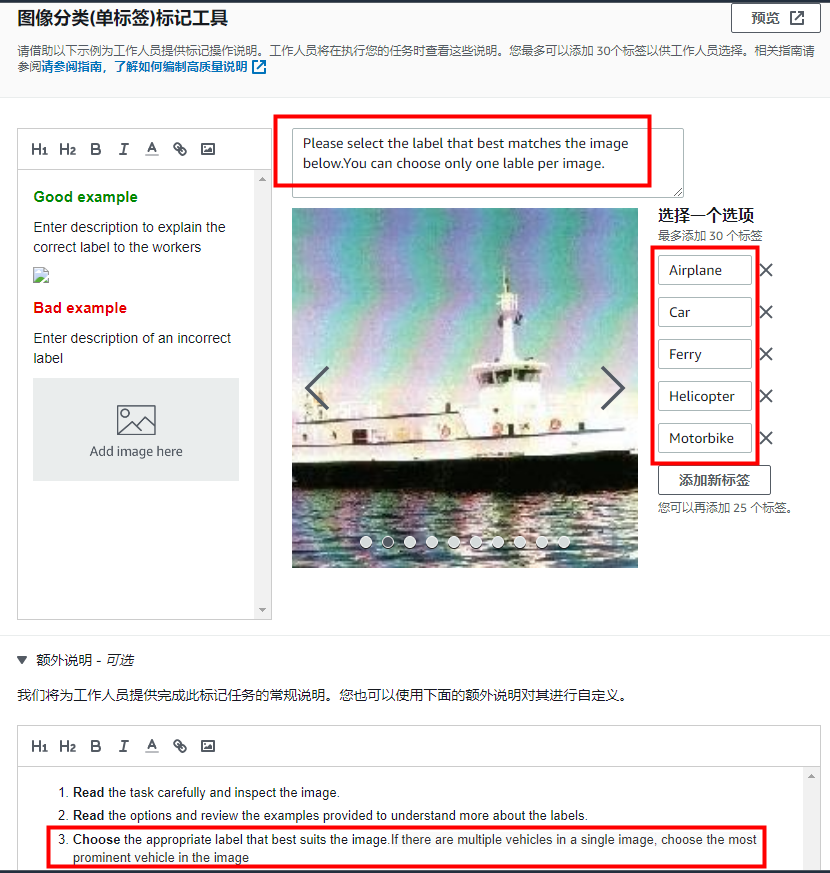
在 Image classification (Single Label) labeling tool(图像分类(单标签)标记工具)部分中,输入以下信息:
对于 brief description of task(任务的简短描述),输入 Please select the label that best matches the image below(请在下方选择与图像最匹配的标签)。您可以为每张图像仅选择 1 个标签。
对于 Select an option(选择选项),在单独的框中输入以下标签:Airplane(飞机)、Car(汽车)、Ferry(渡轮)、Helicopter(直升机)、Motorbike(摩托车)。
展开 Additional instructions(其他说明),添加以下文本到第 3 步:If there are multiple vehicles in a single image, choose the most prominent vehicle in the image(如果一张图像中有多个交通工具,请选择在图像中最突出的交通工具)。
要了解标注人员将看到怎样的标记工具,请选择 Preview(预览)。
选择 Create(创建)。
创建成功后新的标记任务被列在 SageMaker 控制台 Labeling jobs(贴标作业)部分的下方,其 Status(状态)为 In progress,Task type(任务类型)为 Image Classification (Single Label)(图像分类(单个标签))。标记任务可能需要几分钟才能完成。 在 Amazon Mechanical Turk 公共工作人员标记数据后,状态变为 Complete。
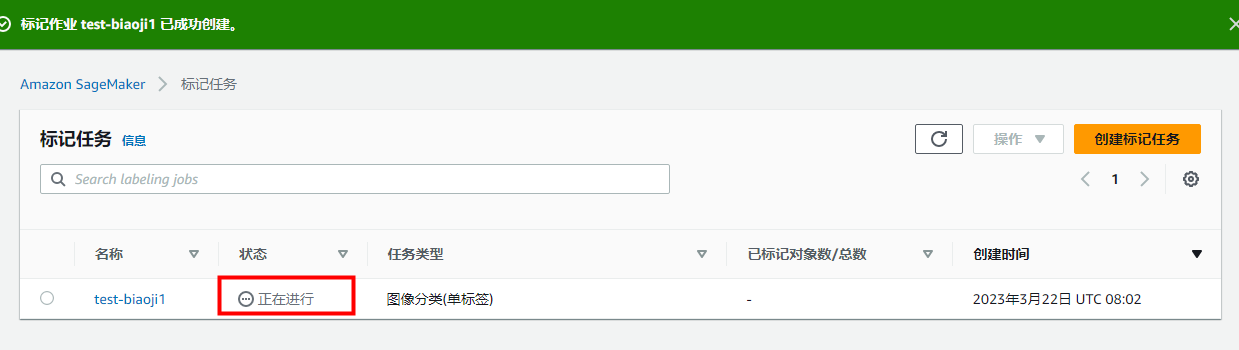
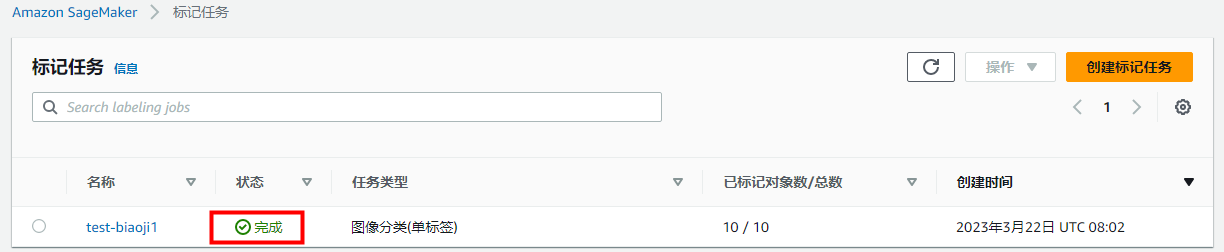
标记任务的创建及参数配置使用相对比较简单,没有像在笔记本实例中使用代码上传数据那样遇到很多权限类的问题。
3)结果查看
在标记任务的详细信息页面上,已标记数据集对象将显示您的数据集图像的缩略图,并以对应标签作为标题。
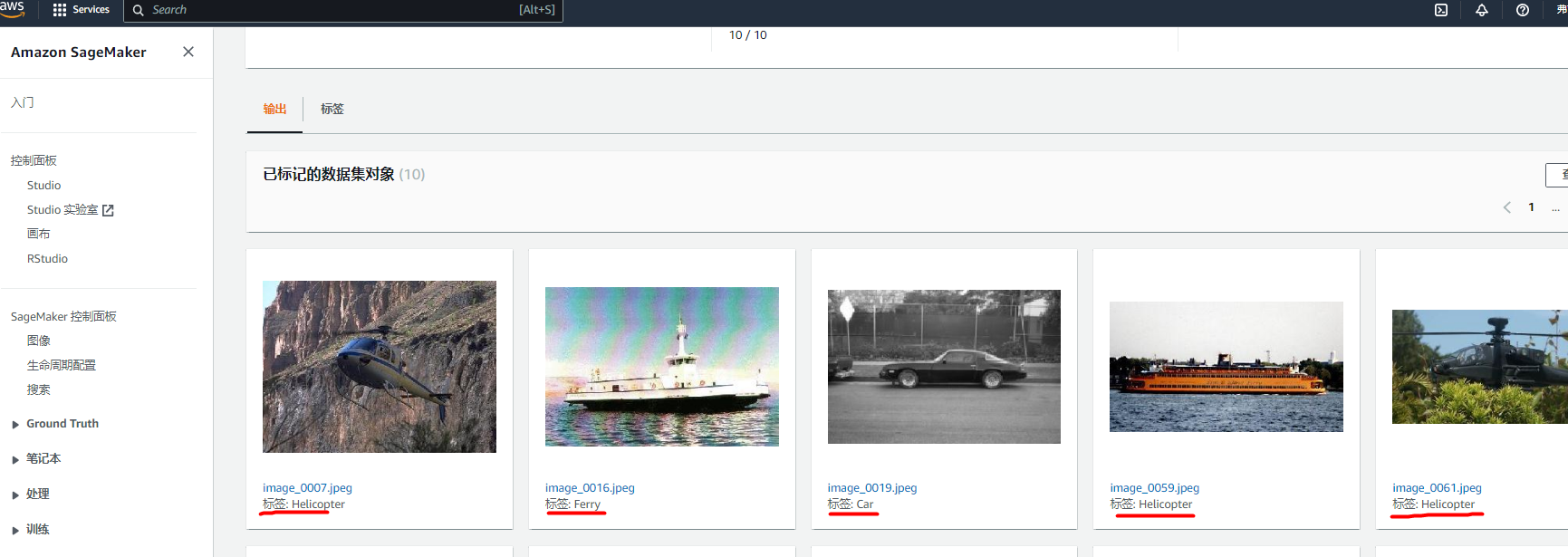
详细结果可以通过标记任务的摘要部分,打开输出数据集位置链接,选择 manifests(清单)、output(输出)、output.manifest
其中output.manifest 清单包括以下数据:
source-ref:在输入清单文件中指定图像条目的位置。由于您在第 2 步中选择了 Automated data setup(自动数据设置),Amazon SageMaker Ground Truth 已自动创建这些条目以及输入清单文件。
test-biaoji1:使用从 0 开始的编号数值来指定目标标签。针对此示例中的五个图像分类,标签分别为 0、1、2、3、4。
test-biaoji1-metadata:指定标记元数据,如置信度评分、作业名称、标签字符串名称(例如,飞机、汽车、渡轮、直升机和摩托车),以及人工或机器注释(主动学习)。
然后我们就可以在Amazon SageMaker 中使用 output.manifest 文件来进行模型的训练。
3、模型训练
1)训练任务
我们的数据准备好后,就可以在左侧训练菜单栏中创建训练任务:
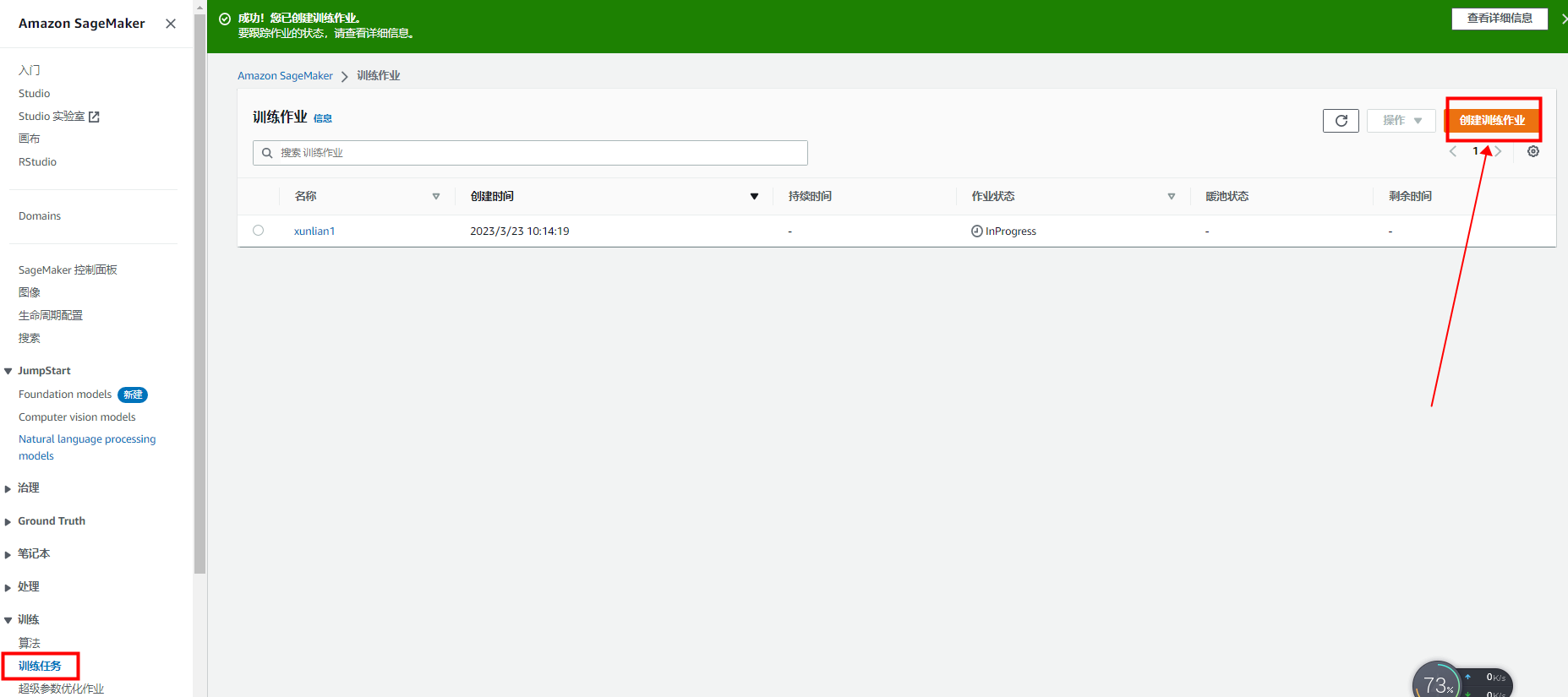
然后对学习算法、训练集群规范和超参数进行配置:
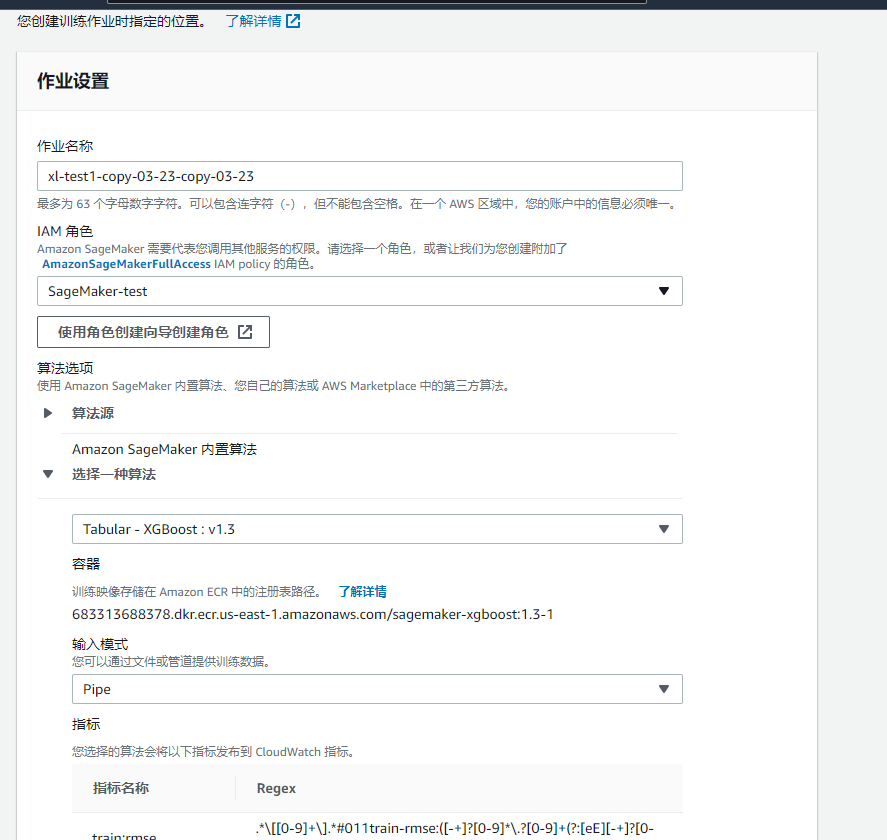
之后按下图配置好输入数据:
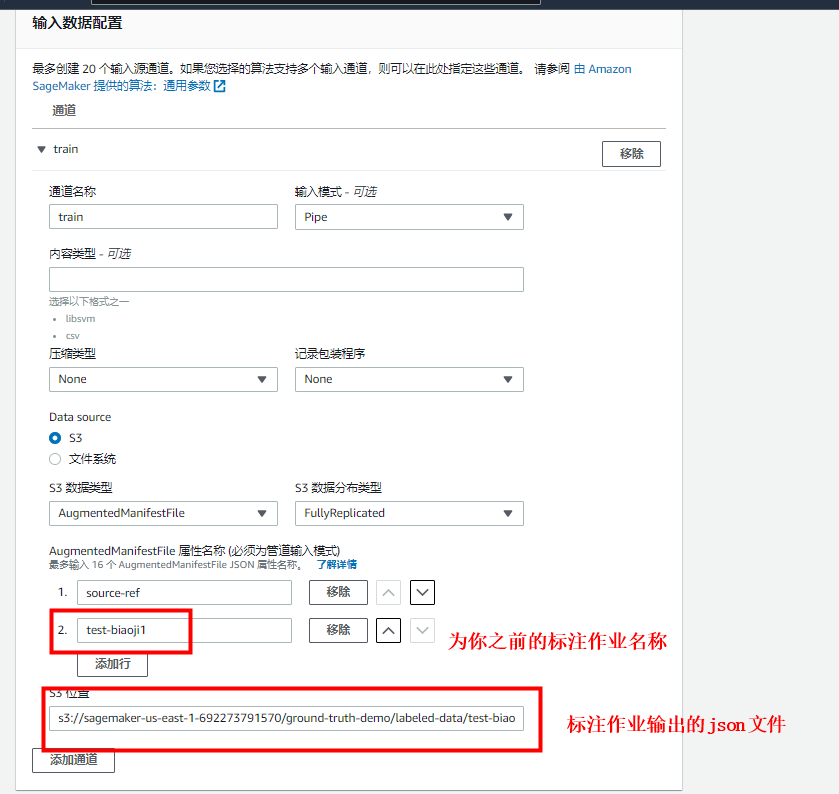
之后点击“创建训练作业”按钮即可,该作业就会开始训练:
待训练完成后我们可以点击右上角的创建模型按钮来创建我们的训练模型。
2)超级参数配置
超参数调整可以通过尝试模型的多种变体来提高工作效率。它通过聚焦在您指定范围内最有前途的超参数值组合来自动寻找最佳模型。为了获得良好的结果,您必须选择正确的范围进行探索。
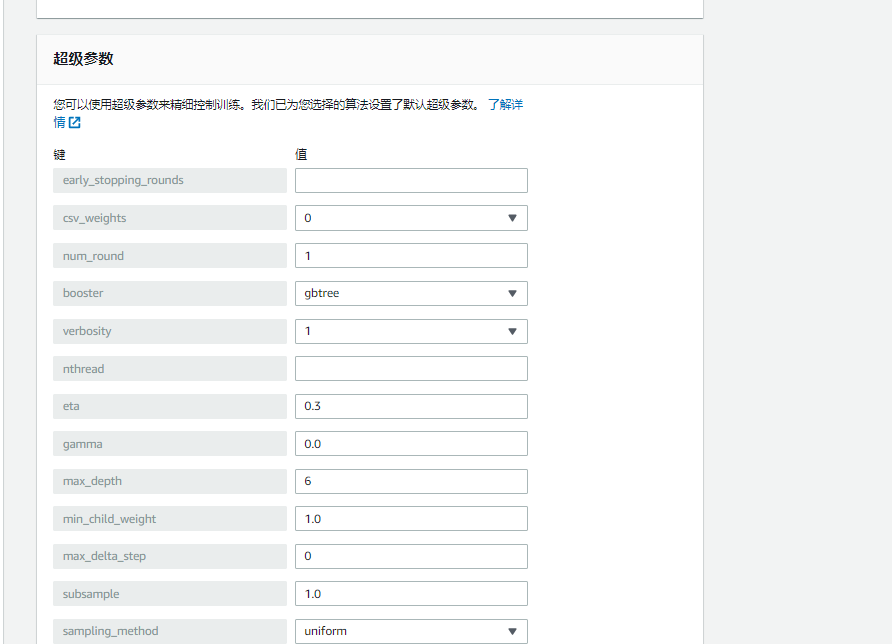
下面列举出了一些可以设置的可选超参数。包含 Amazon SageMaker XGBoost 算法必需或最常用的超参数子集。这些是由用户设置的参数,以便于从数据中评估模型参数。
参数名称 | 描述 |
num_class | 类的数量。如果设置objective为 m ulti-softmax 或 mu lti-softprob 则为@@ 必填项。有效值:整数 |
num_round | 运行训练的轮数。必填有效值:整数 |
alpha | 权重上的 L1 正则化项。增加此值会使模型更加保守。可选有效值:浮点值默认值:0 |
base_score | 所有实例的初始预测分数,全局偏移。可选有效值:浮点值缩放细节凹凸法线强度。 |
booster | 要使用的助推程序。gbtree 和 dart 值使用基于树的模型,而 gblinear 使用线性函数。可选有效值:字符串. gbtree、gblinear 或 dart。默认值:gbtree |
colsample_bylevel | 每个级别中每个拆分的列的子样本比率。可选有效值:浮点值。范围:[0,1]。默认值:1 |
colsample_bynode | 每个节点中列的子样本比率。可选有效值:浮点值。范围:(0,1]。默认值:1 |
colsample_bytree | 构造每个树时列的子样本比率。可选有效值:浮点值。范围:[0,1]。默认值:1 |
csv_weights | 启用此标志时,对于 csv 输入,XGBoost 通过获取训练数据中的第二列(标签后的一列)作为实例权重,以此来区分实例的重要性。可选有效值:0 或 1默认值:0 |
deterministic_histogram | 启用此标志后,XGBoost 会确定性地在 GPU 上构建直方图。仅在 tree_method 设置为 gpu_hist 时才会使用。有关有效输入的完整列表,请参阅 XGBoost 参数。可选有效值:字符串. 范围:true 或 false默认值:true |
early_stopping_rounds | 模型会一直训练直到验证分数停止改善。验证错误需要至少在每个 early_stopping_rounds 减少才能继续训练。 SageMaker 托管使用最佳模型进行推理。可选有效值:整数默认值: - |
eta | 在更新中用于防止过度适合的步骤大小收缩。在每个提升步骤之后,您可以直接获得新特征的权重。eta 参数实际上缩小了特征权重,使提升过程更加保守。可选有效值:浮点值。范围:[0,1]。默认值:0.3 |
不是所有的算法都需要走自动超参数调优,需要权衡模型性能(就是指模型效果)与成本。一般来说,对于深度学习模型或者海量数据集的情况下可能做自动超参数调优的时间代价和成本代价太大。因此在实际的 ML 项目中,用户很少对深度学习模型或者海量数据集做自动超参数调优;对于传统的机器学习模型并且在数据集不大的情况下,可以考虑用自动超参数调优来找到可能的最优解。
三、总结
本次的整体使用过程比较愉快,总的来说Amazon SageMaker的使用比较符合大众习惯,框架设计也很简洁,可读性好,类层次清晰,能够把使用者的关注点更集中在训练脚本本身。
而且,Amazon SageMaker针对当前机器学习应用瓶颈做了很多针对性的提升,比如大数据量的监督训练,Amazon SageMaker则采用完全托管的服务模式;训练时间及资源消耗上,Amazon SageMaker则是秉持工具善其事,必先利其器的理念,在训练之前的数据标记上提供了多种方式及算法,让标记数据的准确性大大提高,从而省去重复训练调参等时间;工程实现上,Amazon SageMaker在模型开发全流程上都提供了相应的功能帮助算法工程师们专注于业务和模型本身,提高开发效率。它是基于 container 的设计,相比于业界比较流行的Kubernetes来说,减少了软件依赖和复杂度。相信Amazon SageMaker的落地,将会为更多的企业插上翅膀,让机器学习无处不在,让创新迈入新的时代。
亚马逊最近也在开展相关的活动,给小伙伴们提供了云上探索实验室,大家通过云上探索实验室,可以学习实践云上技术,同时将自己的技术心得分享给其他小伙伴。
云上探索实验室出现的意义就是让广大开发者能够一同创造分享,互助启发,玩转云上技术。所以说,云上探索实验室不仅是体验的空间,更是分享的平台。如果有有兴趣快点击活动链接试试吧:点我访问