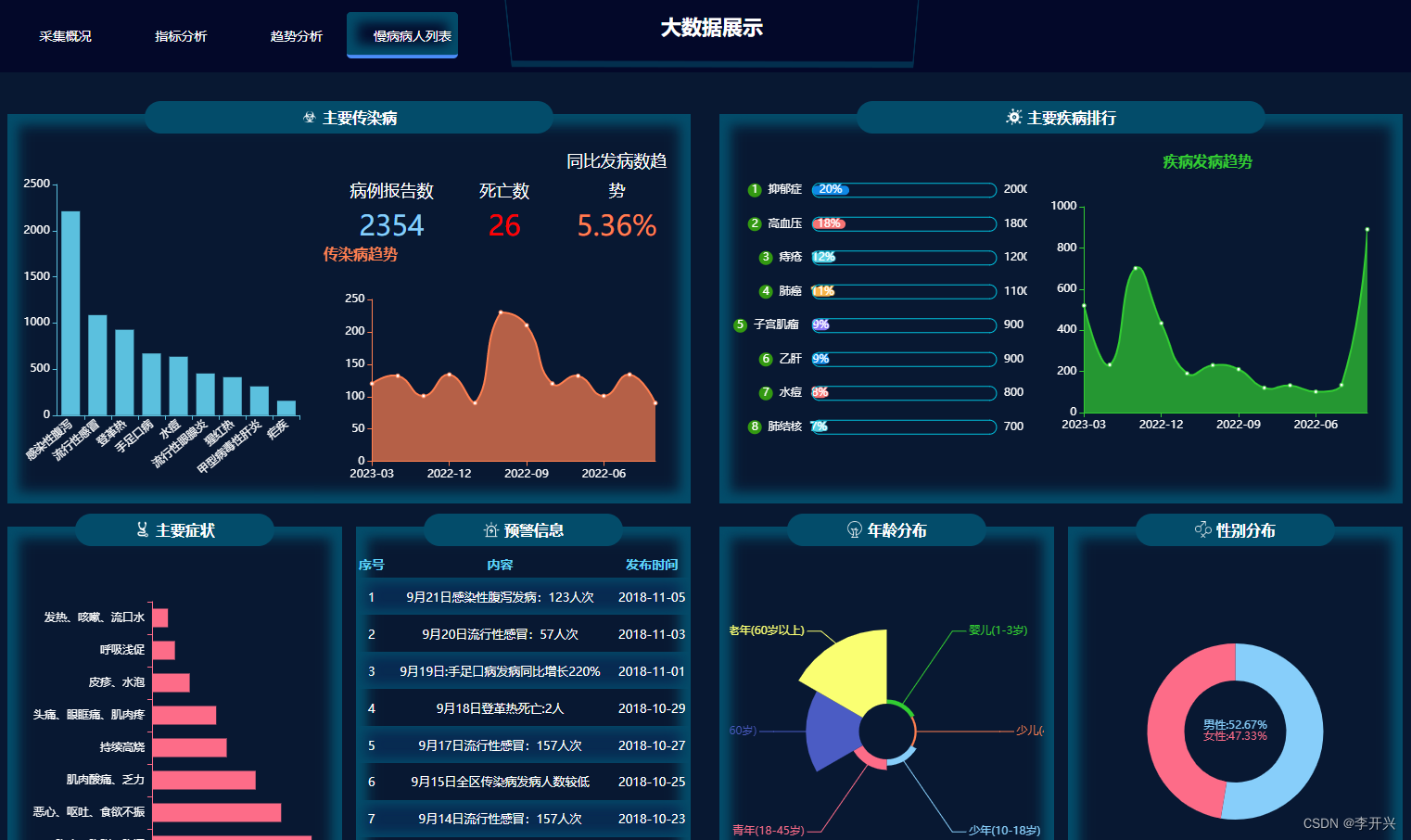
多卡训练的方式
以下内容来自知乎文章:当代研究生应当掌握的并行训练方法(单机多卡)
pytorch上使用多卡训练,可以使用的方式包括:
nn.DataParalleltorch.nn.parallel.DistributedDataParallel- 使用
Apex加速。Apex 是 NVIDIA 开源的用于混合精度训练和分布式训练库。Apex 对混合精度训练的过程进行了封装,改两三行配置就可以进行混合精度的训练,从而大幅度降低显存占用,节约运算时间。此外,Apex 也提供了对分布式训练的封装,针对 NVIDIA 的 NCCL 通信库进行了优化。 - 使用
Horovod加速。Horovod 是 Uber 开源的深度学习工具,它的发展吸取了 Facebook “Training ImageNet In 1 Hour” 与百度 “Ring Allreduce” 的优点,可以无痛与 PyTorch/Tensorflow 等深度学习框架结合,实现并行训练。
对比不同的方式,后面几种差别其实并不大,而pytorch官方也建议将第一种DataParallel替换成DistributedDataParallel,下面我们只关注DistributedDataParallel的实现,想了解其他的可以去看引用的文章。
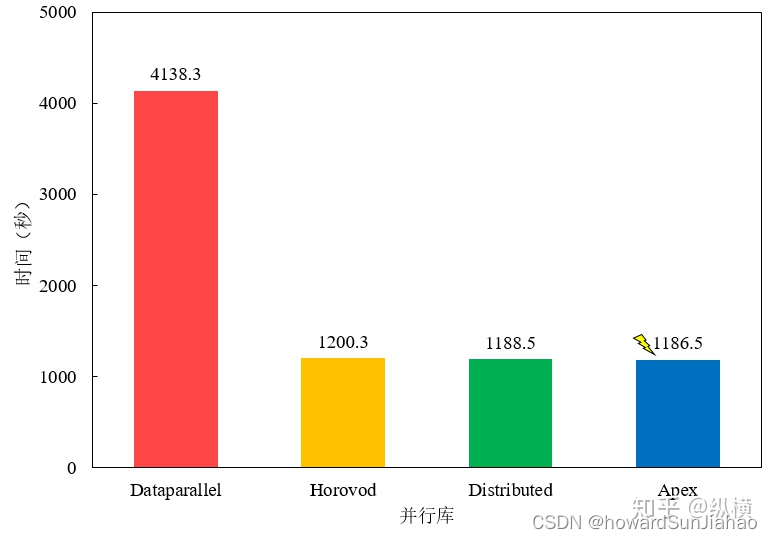
数据并行
一般来说并行加速可以分为模型并行和数据并行,模型并行指的是将模型的不同组成部分放到不同的gpu上,而数据并行则是把一个模型拷贝到多个gpu上(例如8块gpu),然后将一个完整的batch(例如batch size为128)再分成多个小的batch(每个小batch就是128/8个),分别由这多个gpu进行计算,反向传播之后得到参数的梯度,然后将不同gpu上的梯度求平均(reduce),然后同步不同模型上的参数更新。
DistributedDataParallel
一些概念:
Node: 一个节点, 可以理解为一台电脑.
Device: 工作设备, 可以简单理解为一张卡, 即一个GPU.
Process: 一个进程, 可以简单理解为一个Python程序.
DistributedDataParallel和DataParallel的区别
- DistributedDataParallel支持模型并行,而DataParallel并不支持,这意味如果模型太大单卡显存不足时只能使用前者;
- DataParallel是单进程多线程的,只用于单机情况,而DistributedDataParallel是多进程的,适用于单机和多机情况,真正实现分布式训练;
- DistributedDataParallel的训练更高效,因为每个进程都是独立的Python解释器,避免GIL问题,而且通信成本低其训练速度更快,基本上DataParallel已经被弃用;
- 必须要说明的是DistributedDataParallel中每个进程都有独立的优化器,执行自己的更新过程,但是梯度通过通信传递到每个进程,所有执行的内容是相同的;
参考链接:https://blog.csdn.net/weixin_43402775/article/details/114318434
如何使用DistributedDataParallel进行单机多卡的训练
启动进程
要使用分布式训练,首先需要在每个训练节点(Node)上生成多个分布式训练进程。对于每一个进程, 它都有一个local_rank和global_rank, local_rank对应的就是该Process在自己的Node上的编号, 而global_rank就是全局的编号。比如你有2个Node, 每个Node上各有4个Proess (Process0, Process1, Process2, Process3). 那么对于Process2来说, 它的local_rank就是0(即它在Node1上是第0个Process), global_rank 就是2。对于单机多卡的情况,那么local_rank和global_rank是一样的。
可以使用的方法有:
-
torch.distributed.launch:这是一个非常常见的启动方式,在单节点分布式训练或多节点分布式训练的两种情况下,此程序将在每个节点启动给定数量的进程(--nproc_per_node)。如果用于GPU训练,这个数字需要小于或等于当前系统上的GPU数量(nproc_per_node),并且每个进程将运行在单个GPU上,从GPU 0到GPU (nproc_per_node - 1)。
使用方式为:python -m torch.distributed.launch --nproc_per_node=N --use_env xxx.py,其中-m表示后面加上的是模块名,因此不需要带.py,--nproc_per_node=N表示启动N个进程,--use_env表示pytorch会将当前进程在本机上的rank添加到环境变量“LOCAL_RANK”,因此可以通过os.environ['LOCAL_RANK']来获取当前的gpu编号,如果不加--use_env,那么必须声明一个命令行参数--local_rank,因为启动的时候会给每个进程传入这样一个参数,我们需要用变量来接收他,这边还是建议使用--use_env的方式。最后我们加上要运行的python文件名即可。 -
torchrun:是为了替代torch.distributed.launch的新型启动方式, 可以支持ELASTIC LAUNCH, 即动态控制启动的节点数量, 但是由于是新功能, 只有最新的torch 1.10, 处于兼容性考虑还是建议使用torch.distributed.launch。torchrun默认有--use_env的。python -m torch.distributed.launch --use-env train_script.py可以用torchrun train_script.py来替代。
初始化进程组
在启动多个进程之后,需要初始化进程组,使用的方法是使用torch.distributed.init_process_group()来初始化默认的分布式进程组。
torch.distributed.init_process_group(backend=None, init_method=None, timeout=datetime.timedelta(seconds=1800), world_size=- 1, rank=- 1, store=None, group_name='', pg_options=None)
一般需要传入的参数有:
- backend :使用什么后端进行进程之间的通信,选择有:mpi、gloo、nccl、ucc,一般使用nccl。
- world_size:使用几个进程,每个进程会对应一个gpu。
- rank:当前进程的编号,大小在[0,world_size-1]
如果使用了--use_env,那么这里的rank和world_size都可以通过os.environ['LOCAL_RANK']和os.environ['WORLD_SIZE']来获取,然后传入这个函数。
该语句后面最好加一句torch.distributed.barrier(),这个函数会进行多个进程间的同步,确保每一个进程都执行完了init_process_group()。
创建模型
做完以上这些之后,我们就可以创建模型了:
# 创建模型, 并将其移动到local_rank对应的GPU上
model = ToyModel().to(local_rank)
ddp_model = DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank)
上面说过,local_rank可以通过环境变量来获取。第一句是将model放到对应的gpu上,也可以通过以下方式来实现:
- torch.cuda.set_device(local_rank)
- with torch.cuda.device(local_rank)
注意,这里的ddp_model和原来的model就不一样了,如果你要保存的是原来模型的参数,需要通过ddp_model.module来获取。
读取数据
有了模型之后,如何读取数据进行训练呢?如果一个batch有n个数据,我们有m个gpu参与训练,那么肯定希望m个gpu上都有不同的n/m个数据,这个就是采样的问题了,数据集dataset和dataloader的使用并不受影响。
在分布式训练的时候,我们要使用DistributedSampler这个类。和DistributedDataParallel搭配使用的时候,每个进程都可以将DistributedSampler实例作为DataLoader采样器传递,并加载原始数据集的一个专有子集。使用方式:
torch.utils.data.distributed.DistributedSampler(dataset, num_replicas=None, rank=None, shuffle=True, seed=0, drop_last=False)
除了dataset都是可选参数,如果不传入默认会从当前的进程组中获取有关的参数,因此我们只需要传入一个dataset即可。然后再dataloader中传入这个sampler就行。
load和save
在训练完,我们一般都会保存模型的权重,这时候最好是保存ddp_model.module.statedict(),然后load的时候也是ddp_model.module.load_state_dict()。
其他可能用到的函数
torch.distributed.all_gather():把所有进程中的某个tensor收集起来,比如有8个进程,都有一个tensor a,那么可以把所有进程中的a收集起来得到一个listtorch.distributed.all_reduce():汇总所有gpu上的某一个tensor值,可以选择平均或者求和等,然后再分发到所有gpu上使得每个gpu上的值都是相同的。