目录
1. Deep Learning
1.2 Feed-forward NN
1.3 Neuron
1.4 Matrix Vector Notation 矩阵向量表示法
1.5 Output Layer
1.6 Learning from Data
1.7 Regularisation 正则化
1.8 Dropout
2. Applications in NLP
2.1 Topic Classification
2.2 Topic Classification - Training
2.3 Topic Classification - Prediction
2.4 Topic Classification - Improvements
2.5 Language Model Revisited
2.6 Language Models as Classifiers
2.6 Feed-forward NN Language Model
2.7 Word Embeddings
2.8 Topic Classification
2.9 Training a FFNN LM
2.10 Input and Output Word Embeddings
2.11 Language Model: Architecture
2.12 Advantages of FFNN LM
3. Convolutional Networks
3.1 Convolutional Networks for NLP
4. Final Words
1. Deep Learning
- A branch of machine learning 机器学习的一个分支
- Re-branded name for neural networks 神经网络的改名
- Why deep? Many layers are chained together in modern deep learning models 为什么是深度?在现代深度学习模型中,许多层都是连在一起的。
- Neural networks: historically inspired by the way computation works in the brain 神经网络:历史上受到大脑中计算方式的启发
- Consists of computation units called neurons 由称为神经元的计算单元组成
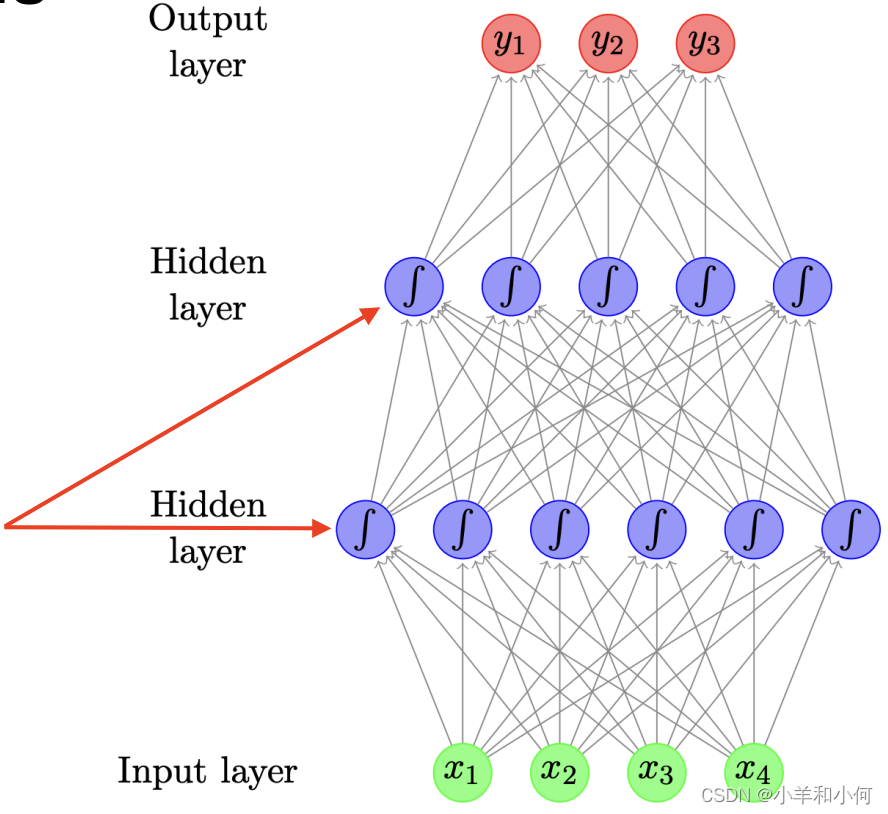
1.2 Feed-forward NN
- Aka multilayer perceptrons 又名多层感知器
- Each arrow carries a weight, reflecting its importance 每个箭头都有一个权重,反映其重要性
- Certain layers have nonlinear activation functions 某些层有非线性激活函数
1.3 Neuron
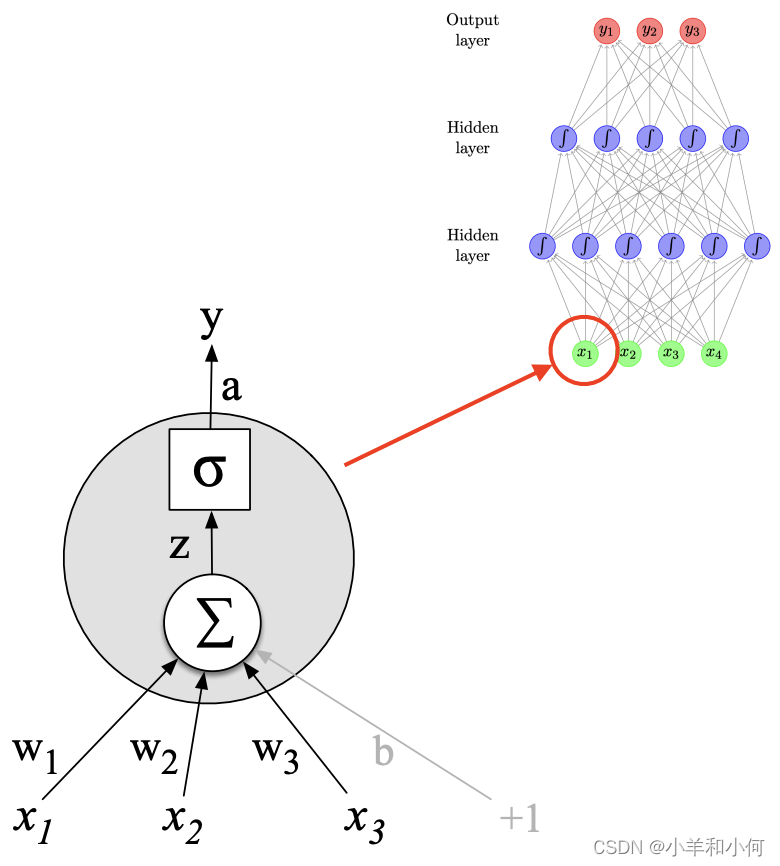
Each neuron is a function 每个神经元都是一个函数
- given input x, computes real-value (scalar) h 给定输入x,计算实值(标量)
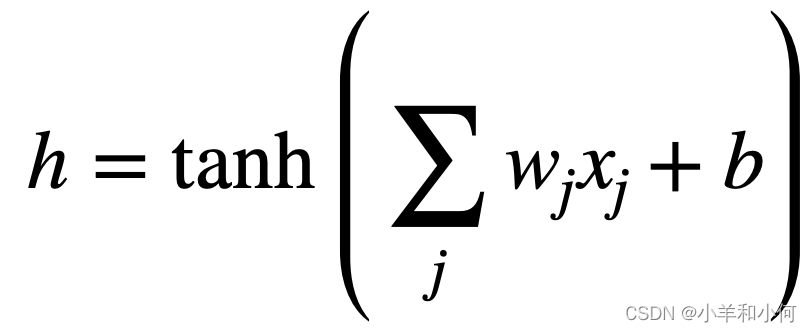
- scales input (with weights, w) and adds offset (bias, b)
- applies non-linear function:
- logistic sigmoid
- hyperbolic sigmoid (tanh)
- rectified linear unit
- w and b are parameters of the model
1.4 Matrix Vector Notation 矩阵向量表示法
- Typically have several hidden units, i.e.
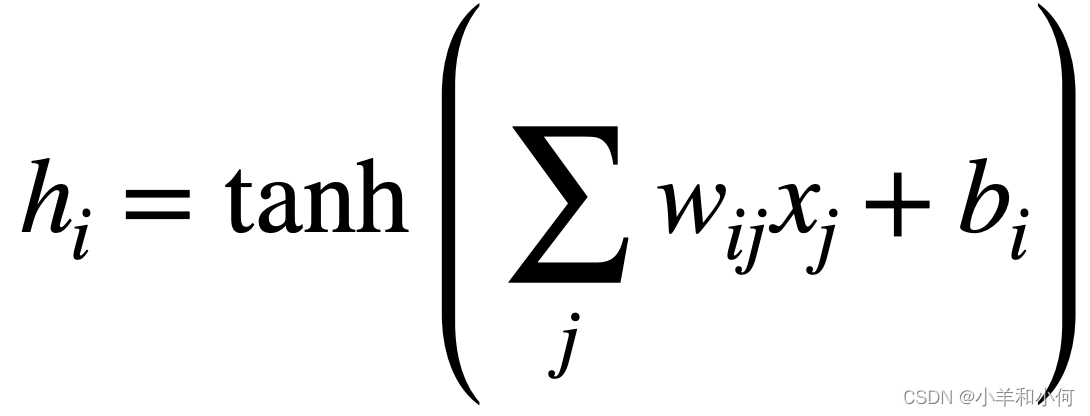
- Each with its own weights (![]() ) and bias term (
) and bias term (![]() )
)
- Can be expressed using matrix and vector operators 可以用矩阵和向量运算符表示
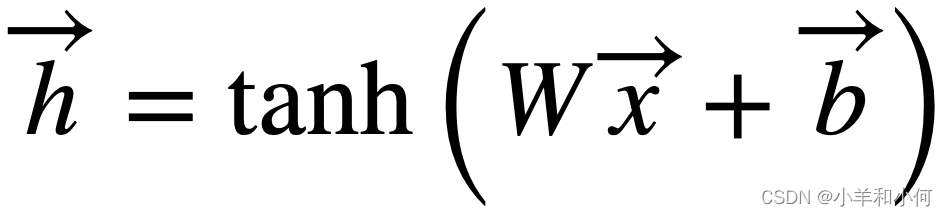
- Where ![]() a matrix comprisine the weight vectors, and
a matrix comprisine the weight vectors, and ![]() is a vector of all bias terms
is a vector of all bias terms
- Non-linear function applied element-wise 非线性函数的单元应用
1.5 Output Layer
- Binary classification problem, e.g. classify whether a tweet is + or - in sentiment
- sigmoid activation function
- Multi-class classification problem, e.g. native language identification
- softmax ensures probabilities > 0 and sum to 1
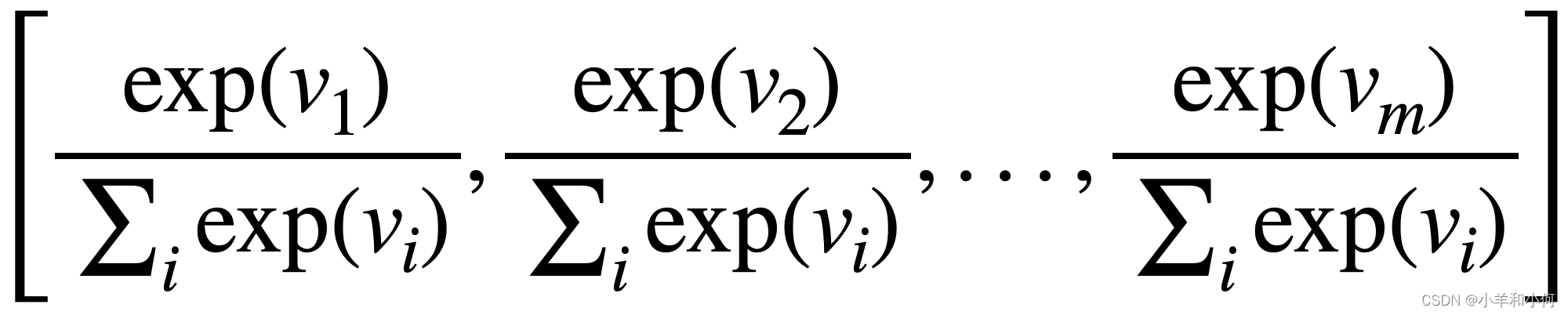
1.6 Learning from Data
- How to learn the parameters from data?
- Consider how well the model "fits" the training data, in terms of the probability it assigns to the correct output
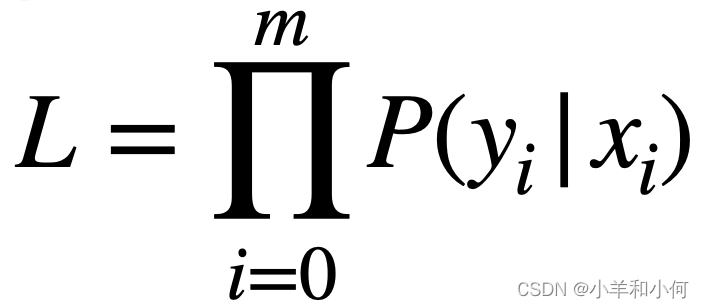
- want to maximise total probability, L 想要使总概率最大化,L
- equivalently minimise -log L with respect to parameters 等效地使-log L 相对于参数最小化
- Trained using gradient descent 用梯度下降法训练的
- tools like tensorflow, pytorch, dynet use autodiff to compute gradients automatically
1.7 Regularisation 正则化
- Have many parameters, overfits easily 有很多参数,很容易过拟合
- Low bias, high variance 过拟合的体现就是偏差小,方差大
- Regularisation is very very important in NNs 正规化在NNs中非常重要
- L1-norm: sum of absolute values of all parameters (W, b, etc) 所有参数(W、 b 等)的绝对值之和
- L2-norm: sum of squares 平方和
- Dropout: randomly zero-out some neurons of a layer 随机地使一层中的某些神经元中断
1.8 Dropout
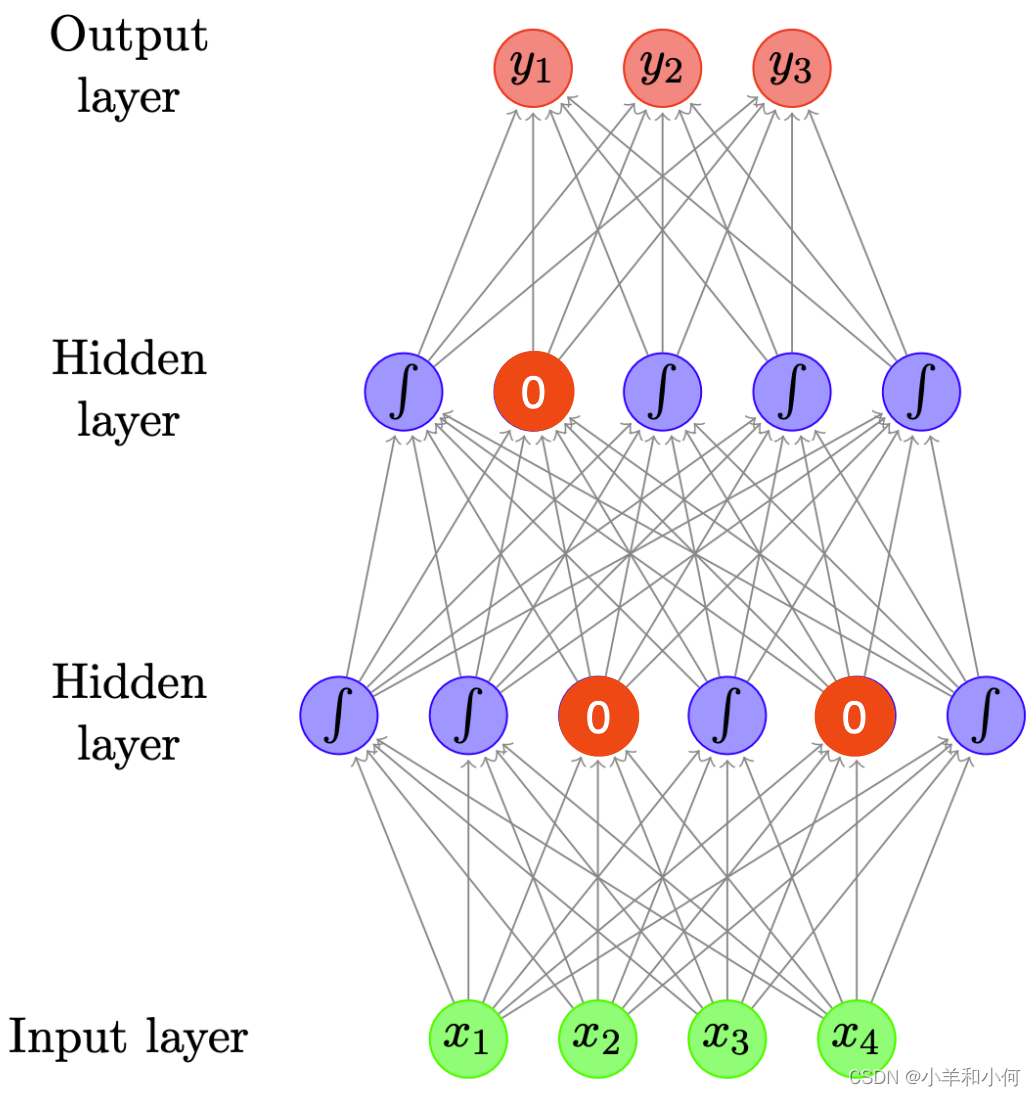
- If dropout rate = 0.1, a random 10% of neurons now have 0 values 如果辍学率 = 0.1,那么随机抽取的10% 的神经元现在的值为0
- Can apply dropout to any layer, but in practice, mostly to the hidden layers 可以应用到任何图层,但在实践中,大多数是隐藏的图层
2. Applications in NLP
2.1 Topic Classification
Given a document, classify it into a predefined set of topics (e.g. economy, politics, sports) 给定一个文档,将其分类为一组预定义的主题(如经济、政治、体育)
Input: bag-of-words
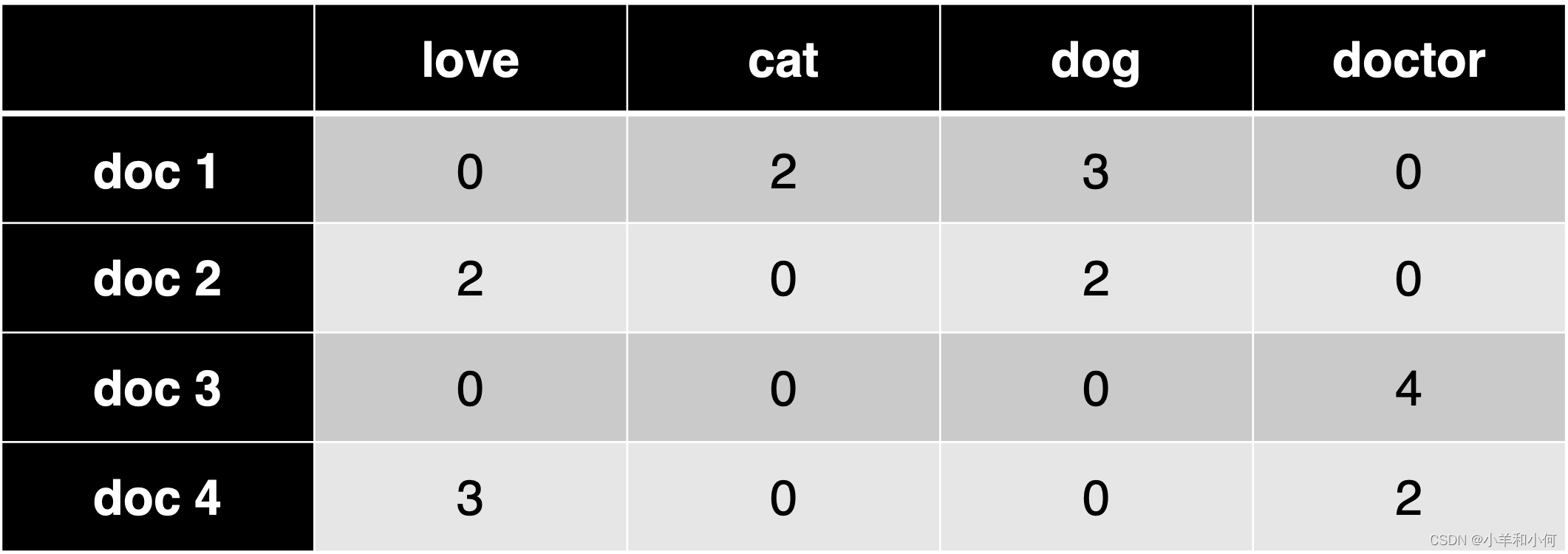
2.2 Topic Classification - Training
2.3 Topic Classification - Prediction
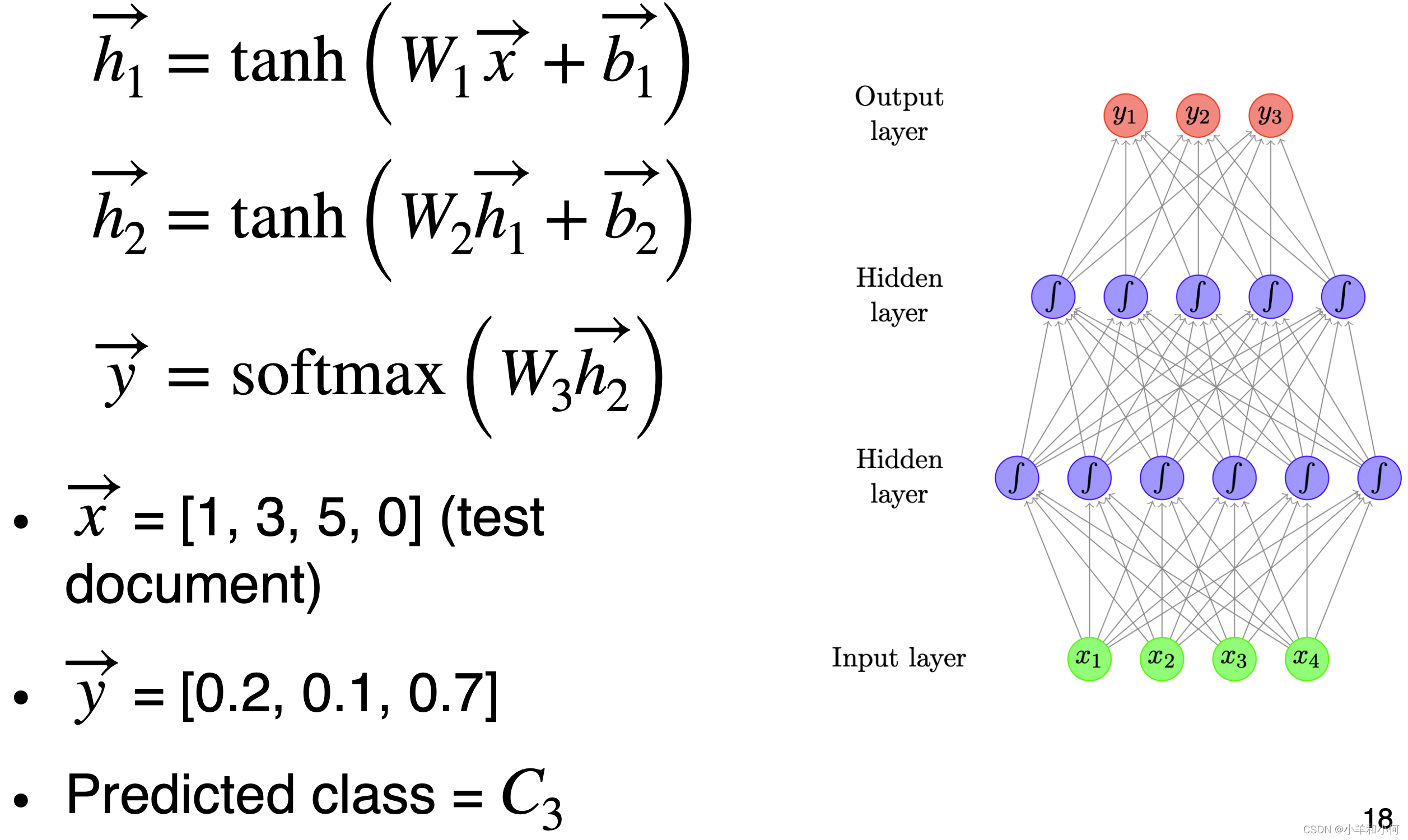
2.4 Topic Classification - Improvements
- + Bag of bigrams as input
- Preprocess text to lemmatise words and remove stopwords 对文本进行预处理,使单词词干化,并删除stopwords
- Instead of raw counts, we can weight words using TF-IDF or indicators (0 or 1 depending on presence of words) 我们可以使用 TF-IDF 或指示器(0或1取决于单词的存在)来为单词加权,而不是原始计数
2.5 Language Model Revisited
- Assign a probability to a sequence of words 给一系列单词赋予一个概率
- Framed as "sliding a window" over the sentence, predicting each word from finite context 在句子上方设置“滑动窗口”,从有限的上下文中预测每个单词
E.g., n=3, a trigram model 例如,n = 3,一个三元模型
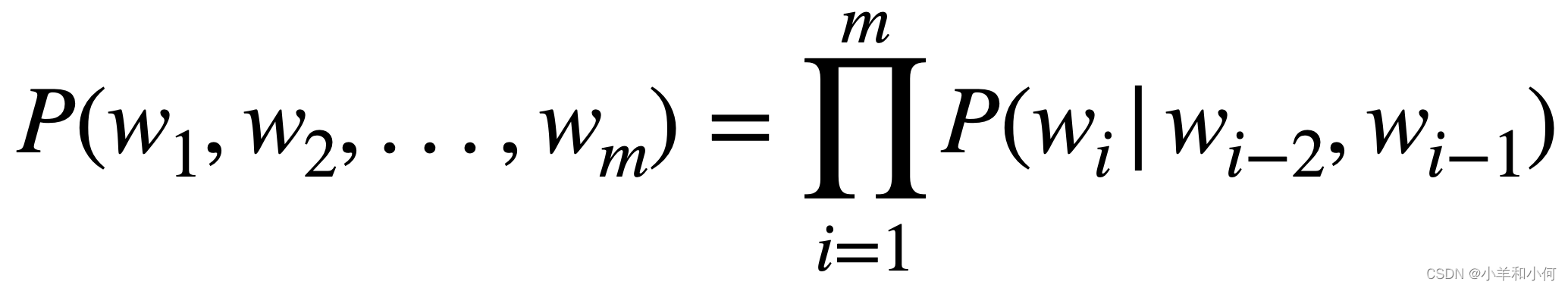
- Training involves collecting frequency counts 训练包括收集频率计数
- Difficulty with rare events 一 smoothing 平滑
2.6 Language Models as Classifiers
- LMs can be considered simple classifiers, e.g. for a trigram model LM 可以被认为是简单的分类器,例如对于一个三元模型:
![]()
- classifies the likely next word in a sequence, given “salt” and “and” 根据“ salt”和“ and”将可能的下一个单词按顺序分类
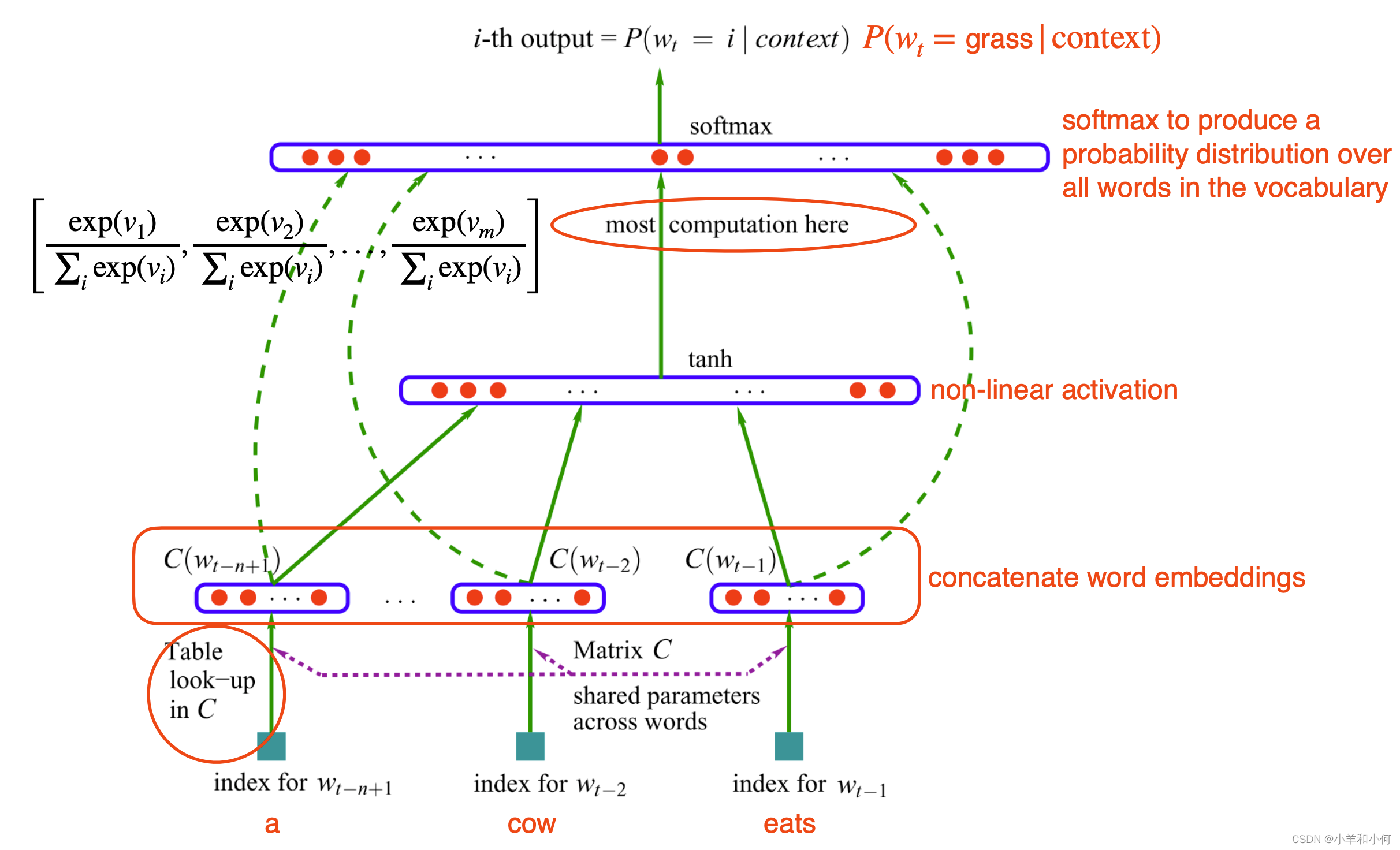
2.6 Feed-forward NN Language Model
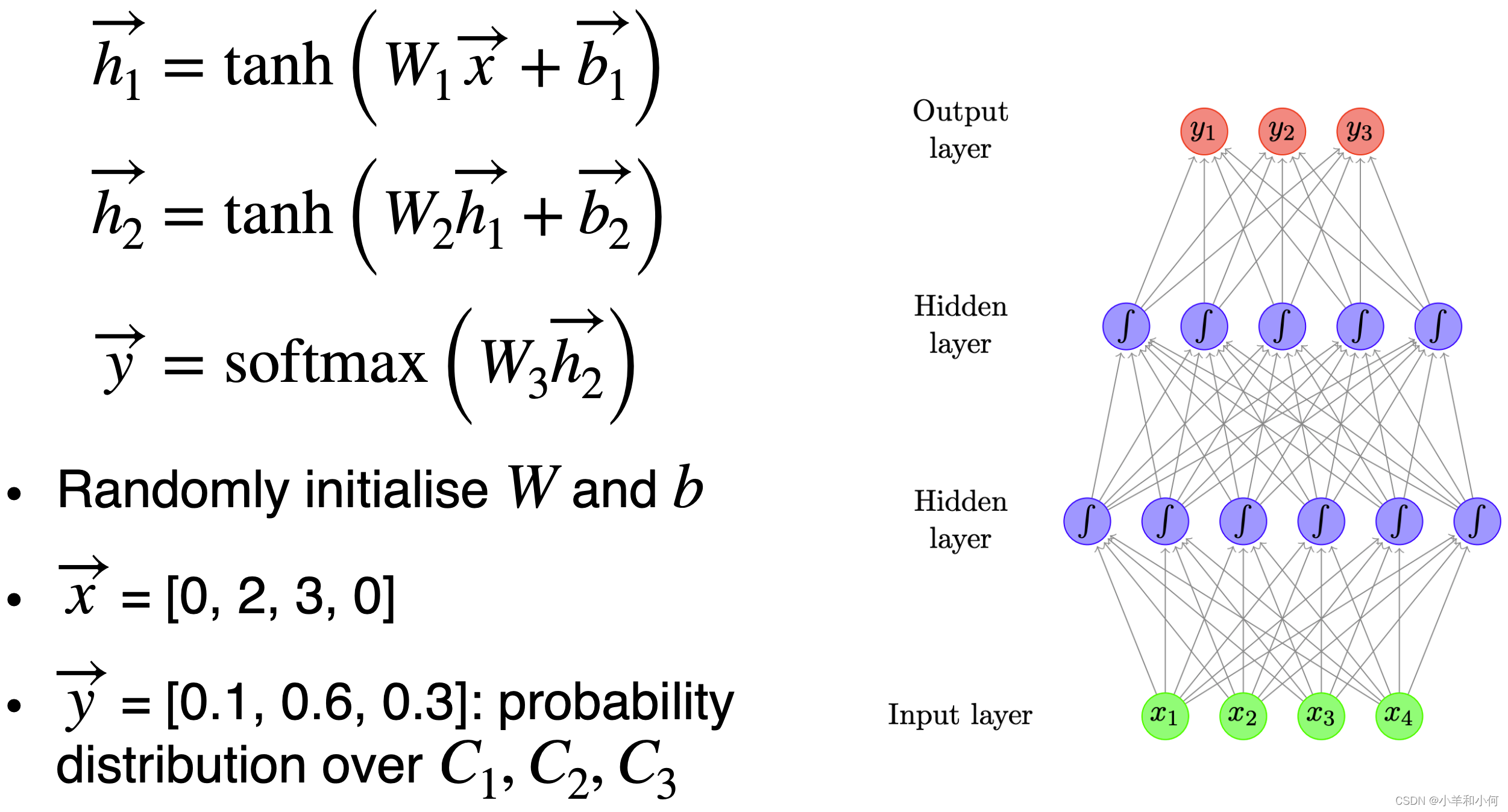
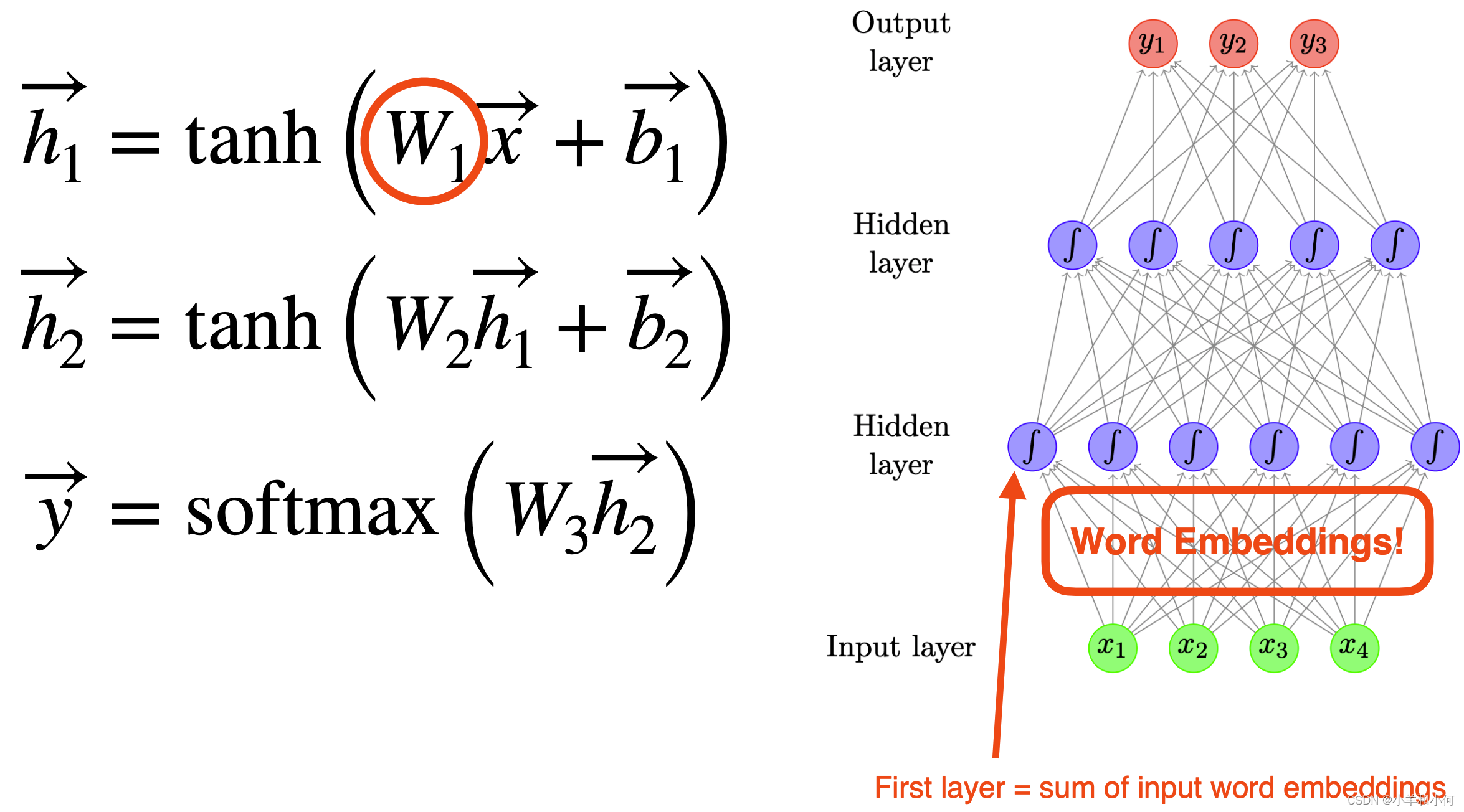
- Use neural network as a classifier to model 使用神经网络作为分类器进行建模
![]()
- Input features = the previous two words 输入特征 = 前两个单词
- Output class = the next word 输出类 = 下一个单词
- How to represent words? Embeddings 如何表示单词? Embeddings
![]()
2.7 Word Embeddings
- Maps discrete word symbols to continuous vectors in a relatively low dimensional space 在一个相对低维的空间中将离散的单词符号映射到连续的向量
- Word embeddings allow the model to capture similarity between words 词语嵌入允许模型捕获词语之间的相似性
- dog vs. cat
- walking vs. running
2.8 Topic Classification
2.9 Training a FFNN LM


2.10 Input and Output Word Embeddings

2.11 Language Model: Architecture
2.12 Advantages of FFNN LM
- Count-based N-gram models (lecture 3) 基于计数的 N-gram 模型
- cheap to train (just collect counts)
- problems with sparsity and scaling to larger contexts
- don't adequately capture properties of words (grammatical and semantic similarity ), e.g., film vs movie 不能充分捕捉单词的属性(语法和语义相似性)
- FFNN N-gram models
- automatically capture word properties, leading to more robust estimates
3. Convolutional Networks
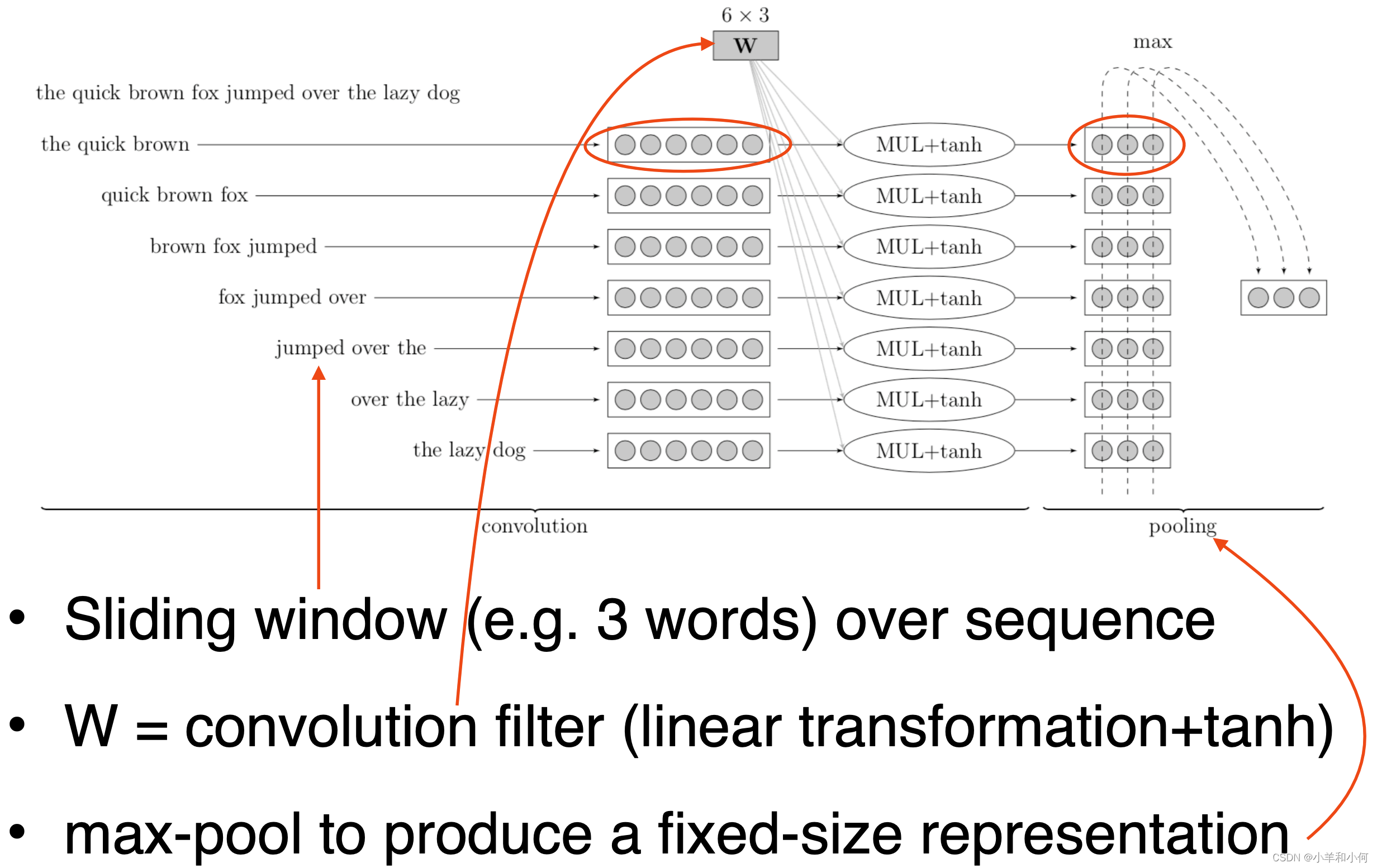
- Commonly used in computer vision 常用于计算机视觉
- Identify indicative local predictors 识别指示性局部预测因子
- Combine them to produce a fixed-size representation 将它们组合起来生成一个固定大小的表示
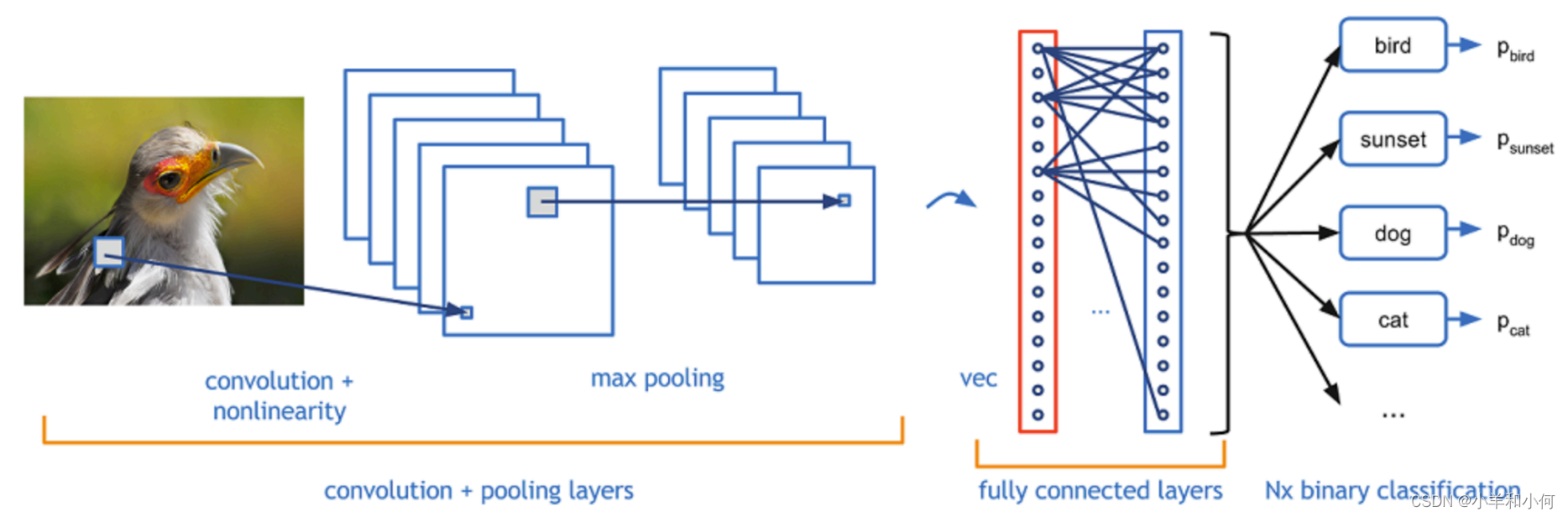
3.1 Convolutional Networks for NLP
4. Final Words
Pros
- Excellent performance
- Less hand-engineering of features
- Flexible — customised architecture for different tasks
Cons
- Much slower than classical ML models... needs GPU
- Lots of parameters due to vocabulary size
- Data hungry, not so good on tiny data sets
- Pre-training on big corpora helps