文章目录
- 并行分布式计算 并行计算机体系结构
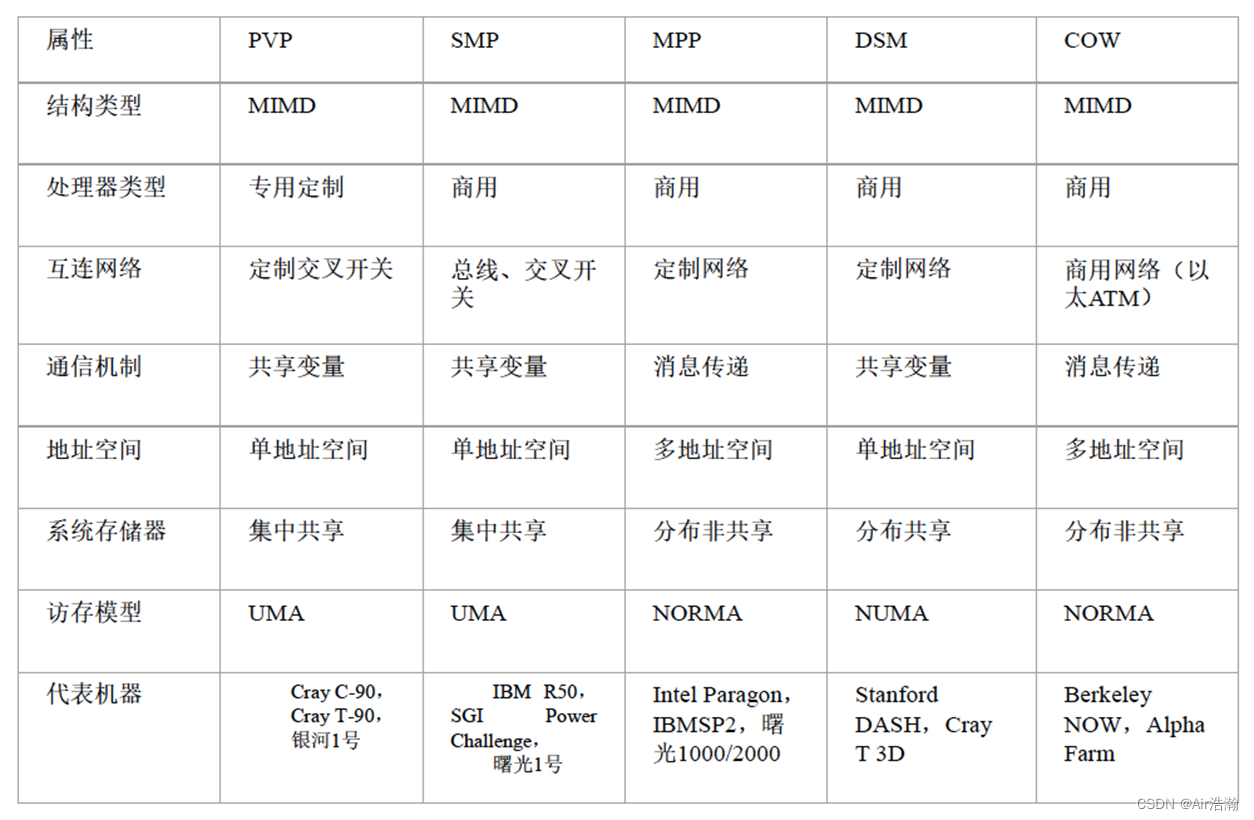
- 并行计算机结构模型
- SIMD 单指令多数据流
- PVP 并行向量处理机
- SMP 对称多处理机
- MPP 大规模并行处理机
- DSM 分布式共享存储多处理机
- COW 工作站集群
- 总结
- 并行计算机访存模型
- UMA 均匀存储访问模型
- NUMA 非均匀存储访问模型
- COMA 全高速缓存存储
- CC NUMA 高速缓存一致性非均匀存储访问
- NORMA 非远程存储访问
- 总结
- 并行计算机存储组织
- 层次存储结构
- 高速缓存一致性
- 监听总线协议
- 基于目录的协议
并行分布式计算 并行计算机体系结构
冯诺依曼体系存在的问题:运算器和存储器分离,导致运算器速度提升比存储器快得多,即“存储器墙”问题。
并行计算机结构模型
SIMD 单指令多数据流
CUDA 就是 SIMD 的形式,图形学中很多计算都是相同的计算形式、不同的数据流。
游戏图形计算中往往只需要单精度 SIMD,因为只需要算到屏幕中的某个像素的坐标(整数)。
PVP 并行向量处理机
定制高性能向量处理机,经由高带宽的交叉开关网络,连接共享存储器。
问题:交叉开关的成本高,适用于定制化的场景。
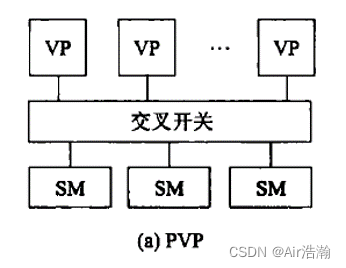
- VP:向量处理机,vector processor
- SM:共享存储器,shared memory
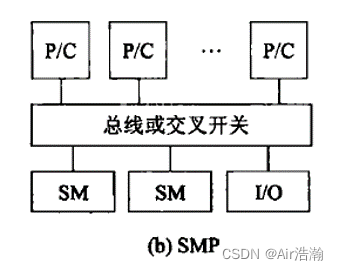
SMP 对称多处理机
商用处理器,经由高速总线(或交叉开关网络),连接共享存储器。
系统是对称的,每个处理器可以等同地访问共享存储器、IO 设备。(不同于 USMP 非对称处理机,只有部分处理器能够执行操作系统并能操作 I/O)
问题:共享存储器导致 P/C 之间的通信成本较高。
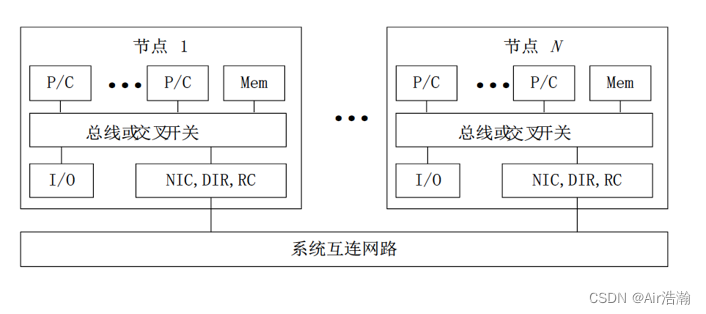
MPP 大规模并行处理机
处理节点为商用处理器,物理上的分布式存储器,专门设计和定制的高通信带宽低延迟网络。
扩展性好,能扩展到成千上万个处理器。
特点:异步 MIMD,多个进程,突破了共享内存的模式,每个处理器具有私有地址空间,所以进程间采用消息传递机制协同。
问题:改变了编程方式,一台机器上编程只能看到自己的地址空间,访问其他核和 LM 需要时钟同步。

-
LM:本地存储器,Local Memory
-
NIC:网卡,Network Interface Card
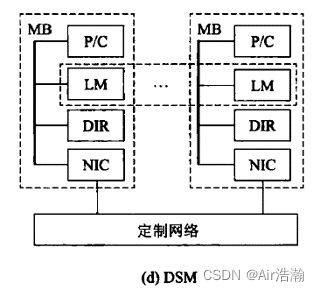
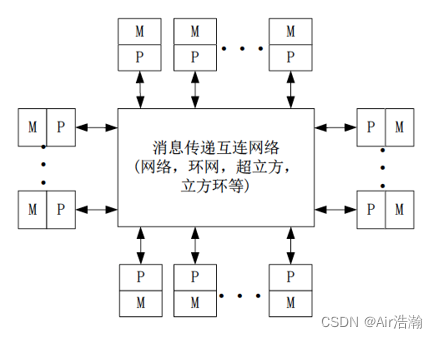
DSM 分布式共享存储多处理机
使用高速缓存目录(DIR)支持分布高速缓存一致性。
采用分布式共享存储器(逻辑上共享,由 DIR 实现),系统硬件和软件提供单一地址的编程空间。
特点:DIR 是一种硬件协议,使用 DIR 可以解决 MPP 中地址空间分隔的问题。
问题:DIR 是一种标准的协议,无法对具体的算法提供特殊优化点。
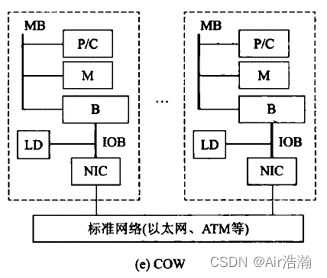
COW 工作站集群
每个节点是完整“无头工作站”(没有显示器、鼠标、键盘等),通过低成本商品网络互连。
每个节点有本地磁盘(MPP没有本地磁盘,只有本地内存),网络层耦合到 I/O 总线(MPP则是将网络层耦合到存储总线),每个节点驻留完整操作系统(MPP 的每个节点是微核)
特点:可以看作是低成本 MPP;
问题:标准以太网较慢,需要想办法降低网络负载,增加了开发难度;
总结
并行计算机访存模型
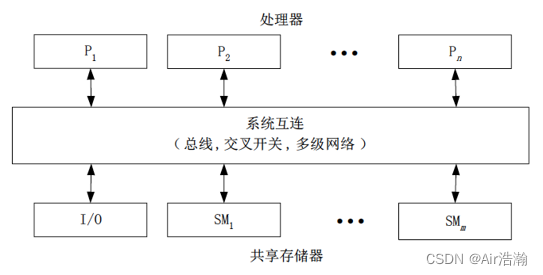
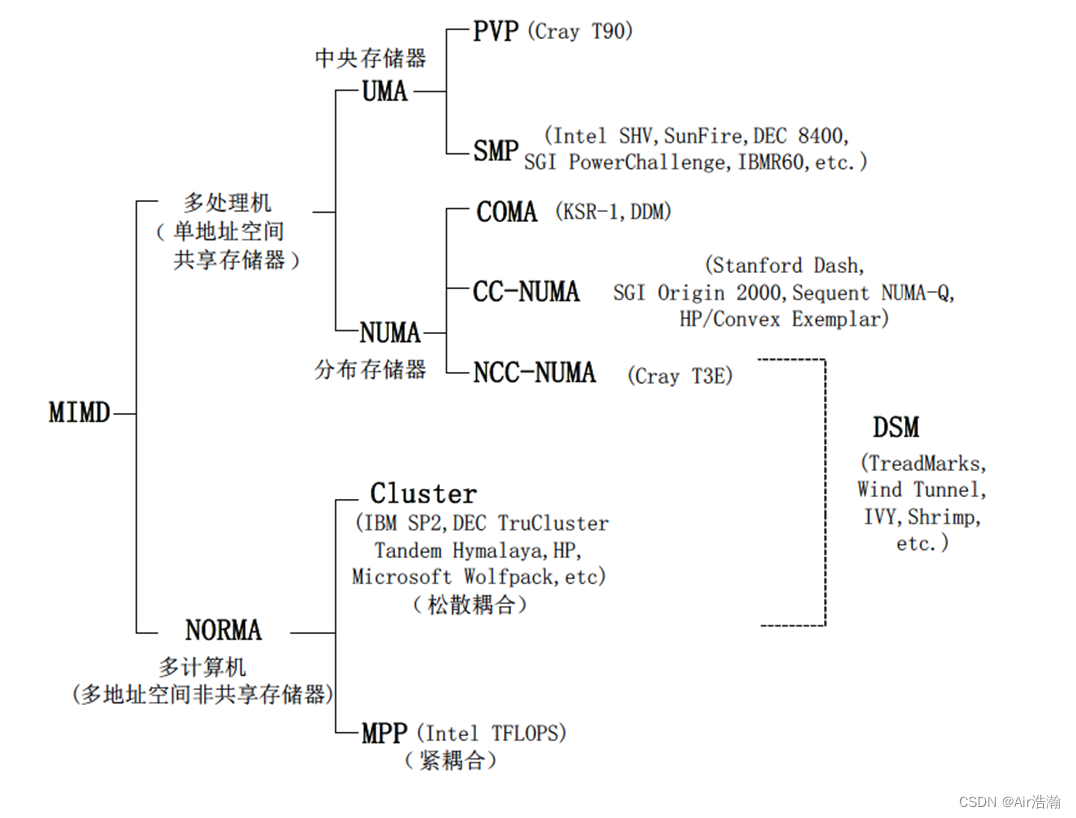
UMA 均匀存储访问模型
特点:例如 SMP、PVP
- 物理存储器被所有处理器均匀共享;
- 所有处理器访问任何存储字是相同的时间;
- 每台处理器可以带有私有高速缓存;
- 外围设备 I/O 也可以以一定形式共享;
问题:处理器数量受限,否则交叉开关网络会变得很复杂
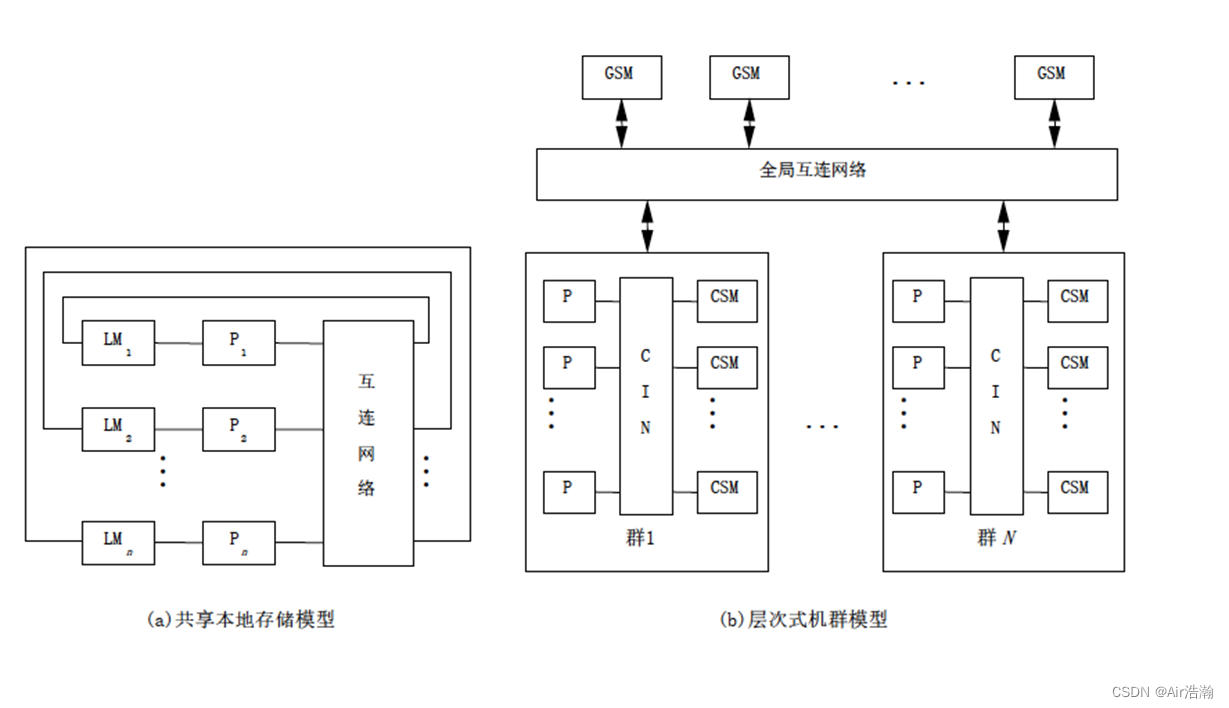
NUMA 非均匀存储访问模型
特点:
- 被共享的存储器在物理上是分布在所有的处理器中的,所有本地存储器的集合就组成的全局地址空间;
- 处理器访问不同存储器的时间是不一样的,访问本地存储器 LM 或群内贡献存储器 CSM 较快,而访问外地的存储器或者全局共享存储器 GSM 较慢;
- 每台处理器可带有私有高速缓存,外设也可以以某种形式共享。
- 处理器数量相对于 UMA 来说可以扩展到更多,更常用;
问题:Cache 的同步协议复杂,会浪费带宽。
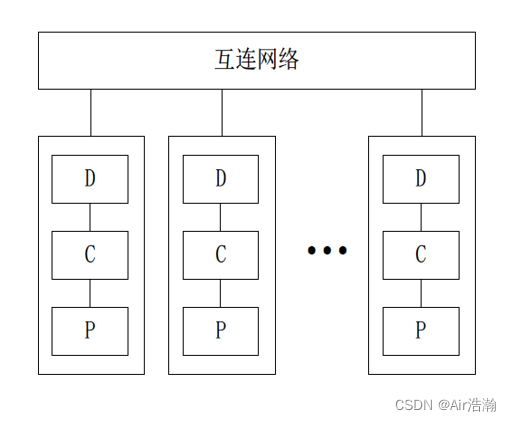
COMA 全高速缓存存储
Cache Only Memory Access
特点:
-
各处理器节点中没有存储器层次结构,而是由全部高速缓存组成了全局地址空间;
-
利用分布的高速缓存目录 D 进行远程的高速缓存的访问
-
COMA 中的高速缓存容量一般都大于 2 级高速缓存容量;
-
使用 COMA 时,数据开始时可以任意分布,因为在运行时它们最终会被迁移到要用到它们的地方
Tip:DIR 协议中就体现了 Cache
CC NUMA 高速缓存一致性非均匀存储访问
Coherent-Cache Nonuniform Memory
特点:
- 大多数使用基于目录的高速缓存一致性协议;
- 保留 SMP 结构易于编程的特点,也改善了常规 SMP 对于处理器的可扩放性;
- CC NUMA 实际上是一个分布共享存储的 DSM 多处理机系统
- 最显著的优点是共享存储,程序员无需明确地在节点上分配数据,系统的 硬件和软件开始时自动在个节点分配数据。在运行期,高速缓存一致性硬件会自动地将数据迁移至要用到它的地方。
NORMA 非远程存储访问
特点:例如 MMP、COW
- 所有存储器是私有的,仅能尤其处理器访问
- 绝大多数 NORMA 都不支持远程存储器的访问
- 最常用,对于计算特点明显的任务,可以对每个单独的处理器和存储器进行硬件选择和特殊优化,扩展性好
问题:编程难度高
总结
并行计算机存储组织
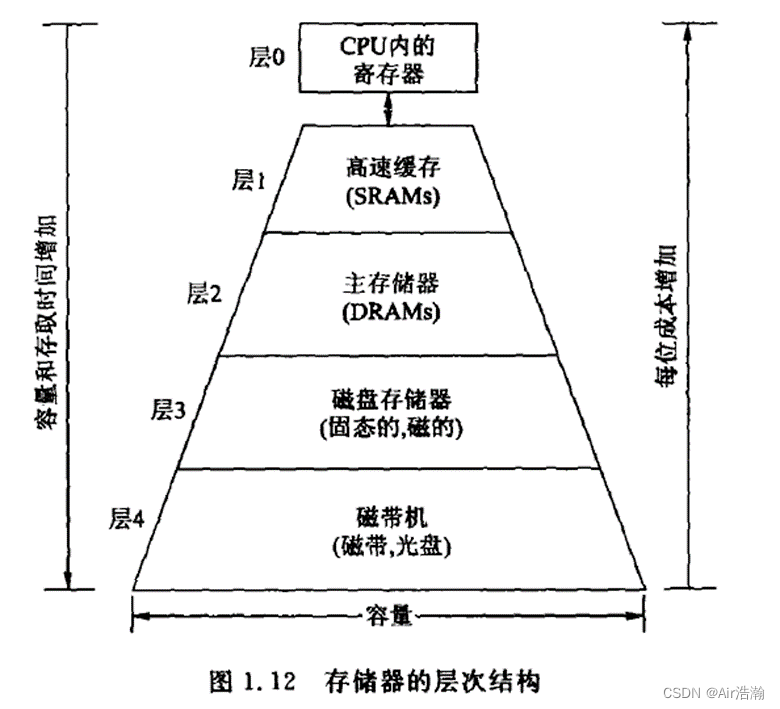
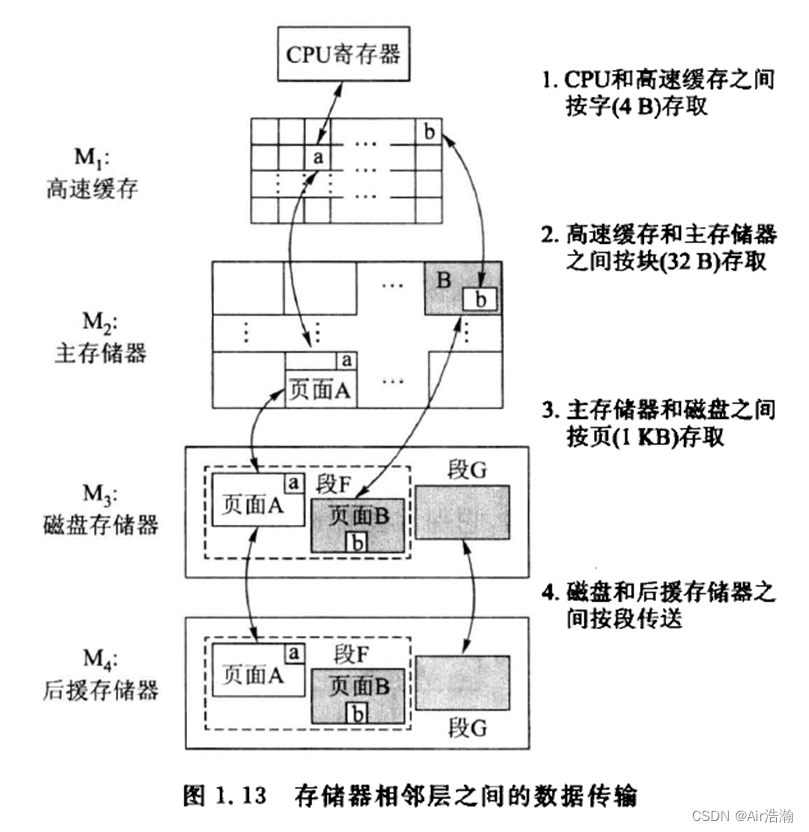
层次存储结构
跟之前计组学的差不多。
注意:一台机器内的存储一定要是同步的。
 |  |
|---|
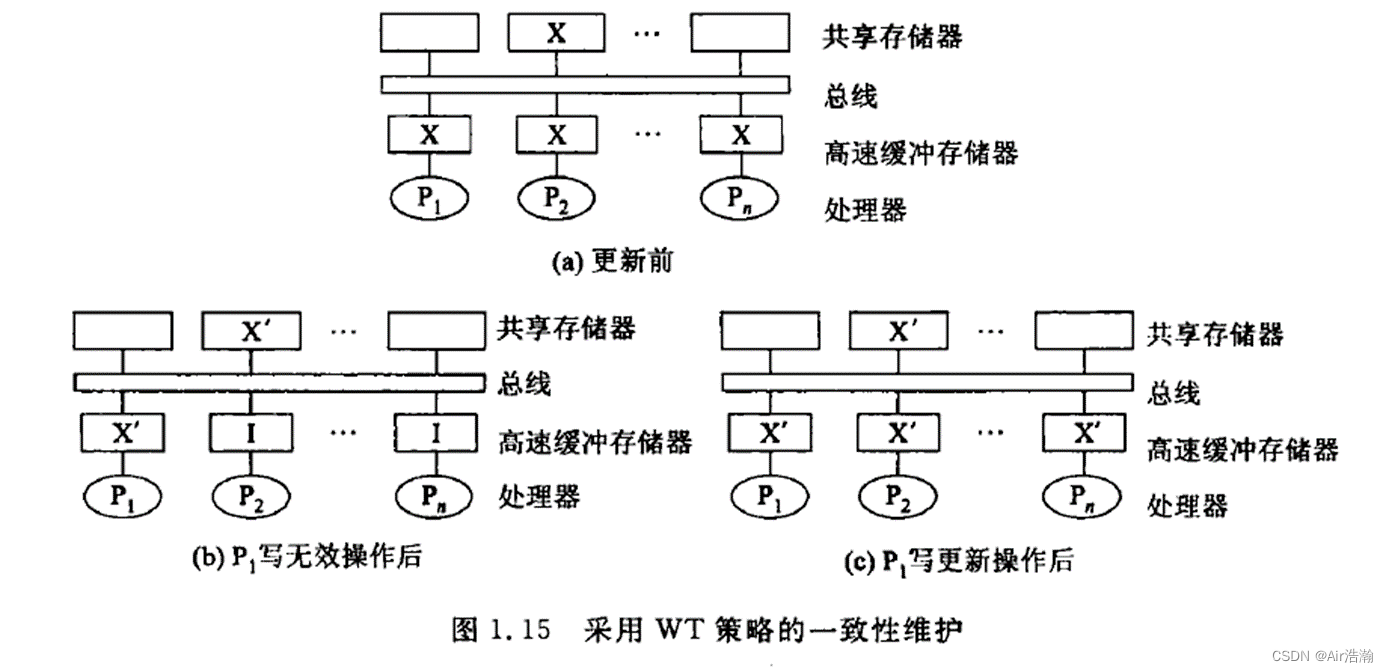
高速缓存一致性
高速缓存策略有:
- 写直达(WT):在某一层的存储器修改了一个字,下一层的存储器需要立即修改;尽最大可能保证一致性,但是慢;
- 写回(WB):下一层存储器的修改延迟到上一层中修改的字被替换或者消除后才进行;节省带宽,速度快,但是容易发生共享可读写数据不一致的情况;
监听总线协议
监听协议:如果总线业务破坏了本地高速缓存中数据的一致性状态,那么高速缓存中的控制器就应采取相应的动作使本地的副本无效,采用此机制保证高速缓存一致性协议的协议称为监听协议。(想一下 SIS 里学的 MESI)
- 写无效(WI):某一处高速缓存发生修改,通过总线是其他高速缓存无效;延迟高,总线不繁忙;
- 写更新(WU):某一处高速缓存发生修改,通过总线广播新的数据给其他高速缓存;数据总是同步,总线繁忙;
基于目录的协议
使用一个目录来记录共享数据的所有高速缓存行的位置和状态,读取缓存就不需要经过 CPU 了,而是直接通过 DIR。
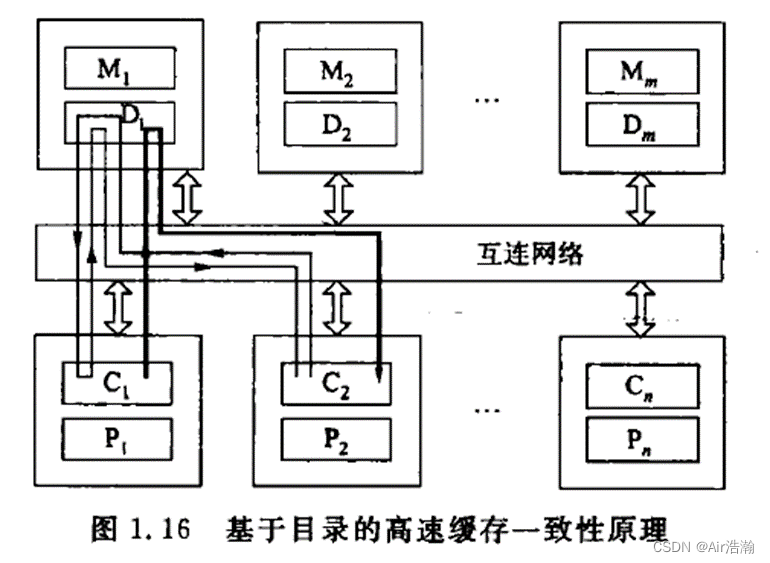
C 2 C_2 C2 读缺失时:
- C 2 C_2 C2 产生一个请求给 D 1 D_1 D1 ;
- D 1 D_1 D1 指示在 C 1 C_1 C1 中有 C l e a n Clean Clean 副本;
- 控制器将请求传递给 C 1 C_1 C1 ;
- C 1 C_1 C1 将内容传递给 M 1 M_1 M1 和 C 2 C_2 C2 ;
C 1 C_1 C1 写命中时:
- 控制器发送无效命令给 D 1 D_1 D1 中有标记的所有高速缓存。