需要学习基础的可参照这两文章
Elasticsearch 学习+SpringBoot实战教程(一)
Elasticsearch 学习+SpringBoot实战教程(一)_桂亭亭的博客-CSDN博客
Elasticsearch 学习+SpringBoot实战教程(二)
Elasticsearch 学习+SpringBoot实战教程(二)_桂亭亭的博客-CSDN博客
前言: 经过了前面2课的学习我们已经大致明白了ES怎么使用,包括原生语句,javaapi等等,现在我们要在业务中使用了,
所以我们选择spring-data作为我们的ORM框架,快速开发代码。
同时需要给规范化操作
目录
0 前辈动作
1 Springboot项目引入依赖
2 建立目录与文件
3 配置文件
4 实体类
1 使用ElasticsearchOperations的方式
新增文档
更新文档
删除文档
查询所有
查询指定id
分页+指定条件+高亮显示+排序+过滤结果
2 使用RestHighLevelClient的方式
精确查询
分页查询
字符匹配AND精准查询
编辑字符匹配OR精准查询
模糊查询
0 前置动作
1 Springboot项目引入依赖
注意你的ES版本号
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.20</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.10.1</version>
<exclusions>
<exclusion>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.10.1</version>
</dependency>
2 建立目录与文件

![]()
![]()
3 配置文件

spring:
elasticsearch:
uris: localhost:9200
connection-timeout: 3000
socket-timeout: 5000
4 实体类
package com.example.eslearn.entity;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.io.Serializable;
/**
* Document: 将这个类对象转为 es 中一条文档进行录入
* indexName: 用来指定文档的索引名称
* createIndex: 用来指定是否创建索引,默认为false
*/
@Document(indexName = "user", createIndex = true)
public class UserDocument implements Serializable {
@Id // 用来将放入对象id值作为文档_id进行映射
private String id;
@Field(type = FieldType.Keyword) // 字段映射类型
private String name;
private String sex;
private Integer age;
@Field(type = FieldType.Text) // 字段映射类型
private String city;
1 使用ElasticsearchOperations的方式
优点:更想我们的springdata的使用风格,简单,快捷,个人使用
新增文档
private final ElasticsearchOperations ESO;
// set方法注入
@Autowired
public CRUDService2(ElasticsearchOperations elasticsearchOperations) {
this.ESO = elasticsearchOperations;
}
// 新增文档
public String save() {
UserDocument user = new UserDocument();
user.setName("说不定看见的");
user.setCity("北京 上海 西安");
user.setAge(22);
user.setSex("男");
UserDocument save = ESO.save(user);
System.out.println(save);
return JSON.toJSONString(save);
}
使用可视化软件查询,得到下面的结果


更新文档
// 更新文档
public String update() {
UserDocument user = new UserDocument();
user.setId("W7w2HYcB32f1ZLmxRwzw");
user.setName("说快来打见的");
user.setCity("北京 上海 西安");
user.setAge(21);
user.setSex("女");
UserDocument save = ESO.save(user);
System.out.println(save);
return JSON.toJSONString(save);
}

删除文档
// 删除
public String delete(){
UserDocument userDocument = new UserDocument();
userDocument.setId("8966e506-1763-4d4b-bf1c-4f5d9bd9b052");
return ESO.delete(userDocument);
}
查询所有
// 查询所有
public String findAll(){
//查询所有
SearchHits<UserDocument> search = ESO.search(Query.findAll(), UserDocument.class);
for (SearchHit<UserDocument> uc : search) {
System.out.println(uc.getContent());
}
return JSON.toJSONString(search);
}
查询指定id
// 根据id查询文档
public String getById(){
UserDocument userDocument = ESO.get("W7w2HYcB32f1ZLmxRwzw", UserDocument.class);
return JSON.toJSONString(userDocument);
}
分页+指定条件+高亮显示+排序+过滤结果
服务层
//大杂烩,一次学会
public String findSource(){
//查询条件构建
MatchQueryBuilder mp=new MatchQueryBuilder("name","妲己");
//排序构建
FieldSortBuilder f = new FieldSortBuilder("age");
//分页构建
Pageable page= PageRequest.of(0,5);
// 高亮构建
HighlightBuilder highlightBuilder = new HighlightBuilder()
.preTags("<span style='color:yellow'>")
.postTags("</span>")
.field("name");
//结果过滤构建,相当于返回那些字段
FetchSourceFilter filter = new FetchSourceFilter(new String[]{"name", "city"}, null);
//查询语句构建
NativeSearchQueryBuilder query = new NativeSearchQueryBuilder()
.withQuery(mp)
.withSorts(f)
.withPageable(page)
.withHighlightBuilder(highlightBuilder)
.withSourceFilter(filter);
//执行查询
SearchHits<UserDocument> search = ESO.search(query.build(), UserDocument.class);
return JSON.toJSONString(search);
}
控制器
@GetMapping("/findSource")
private String findSource(){
return sv.findSource();
}

2 使用RestHighLevelClient的方式
优点:安全,企业级常用
精确查询
对应的原生查询语句
注意这里的term就是精准查询到 关键字
GET user/_search
{
"query": {
"term": {
"city": "上海"
}
}
}服务层
// 文档搜索
public String searchDocument(String indexName,String city){
//2 构建搜索请求
SearchRequest searchRequest = new SearchRequest().indices(indexName);
//3 构建搜索内容
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("city", city);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(termQueryBuilder);
//4 填充搜索内容
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = null;
try {
//5 执行搜索操作
searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
//6 返回值
return JSON.toJSONString(searchResponse.getHits().getHits());
}控制器
@GetMapping("/searchUserByCity")
public String searchUserByCity() throws IOException {
return service.searchDocument("user","上海");
}访问链接localhost:8080/searchUserByCity
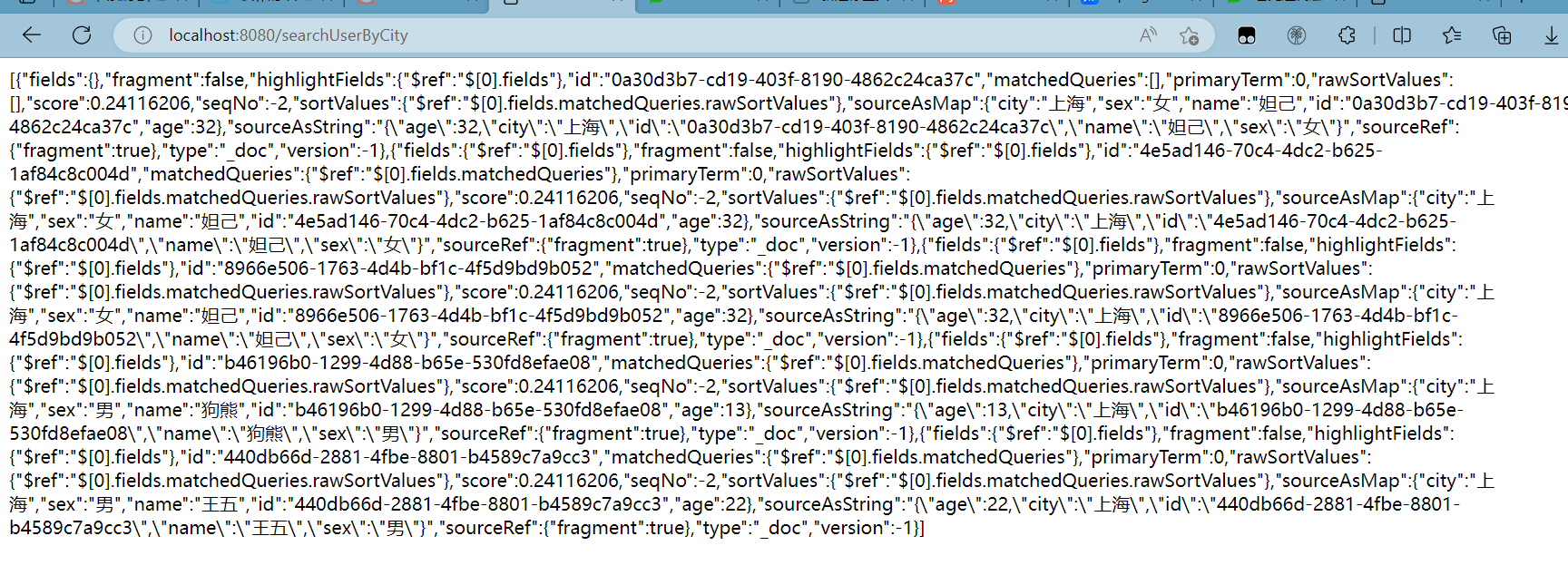
分页查询
GET user/_search
{
"query": {
"term": {
"city": "上海"
}
},
"from":0,
"size":5
}服务层
// 文档搜索--分页查询
public String searchDocument2(String indexName,String city){
//2 构建搜索请求
SearchRequest searchRequest = new SearchRequest().indices(indexName);
//3 构建搜索内容
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//拿到前5条数据
searchSourceBuilder
.query(QueryBuilders.termQuery("city", city))
.from(0)
.size(5);
//4 填充搜索内容
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = null;
try {
//5 执行搜索操作
searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
//6 返回值
return JSON.toJSONString(searchResponse.getHits().getHits());
}控制层
@GetMapping("/searchUserByCity2")
public String searchUserByCity2() throws IOException {
return service.searchDocument2("user","上海");
}访问localhost:8080/searchUserByCity2
字符匹配AND精准查询
term 与matchphrase的比较 term用于精确查找有点像 mysql里面的"=" match是先将查询关键字分词然后再进行查找。term一般用在keywokrd类型的字段上进行精确查找。
注意这里的bool,表示使用布尔查询,其中的must是相当于SQL语句中的and的意思。
所以就是查找name中包含“妲己”并且年龄为22岁的信息,请注意不能写成"妲",因为我们在新建文档的时候是这样新建的“妲己”,那么我们如果匹配“妲”就会匹配不到,加入这样写就可以匹配到了“妲 己”,请注意空格,这是分词的依据之一
ES查询语句。
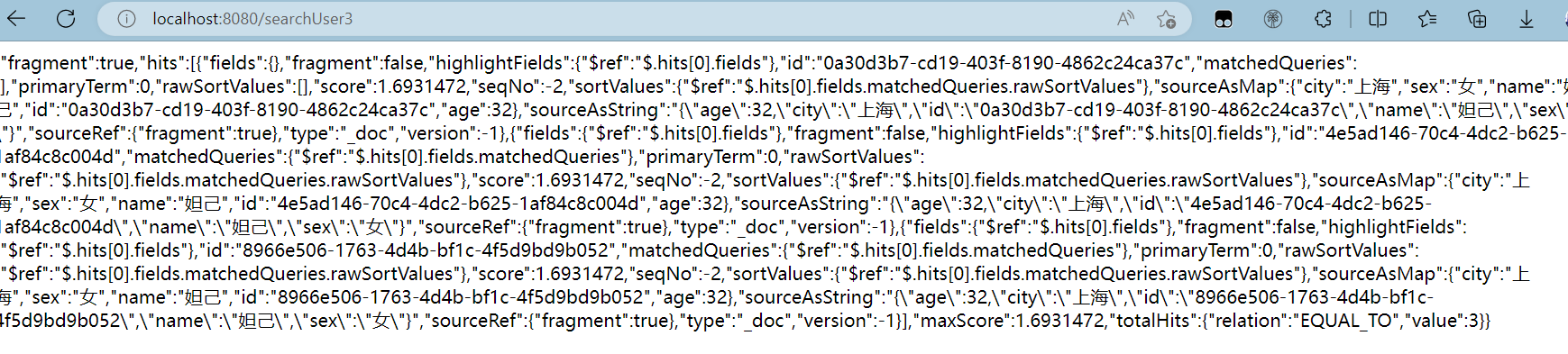
GET user/_search
{
"query": {
"bool":{
"must": [
{
"match_phrase": {
"name": "妲己"
}
},
{
"term": {
"age": "32"
}
}
]
}
},
"from":0,
"size":10
}服务层
// 文档分词搜索+精确查询
public String searchDocument3(String indexName,String name,Integer age){
//2 构建搜索请求
SearchRequest searchRequest = new SearchRequest().indices(indexName);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//3 构建复杂的查询语句
BoolQueryBuilder bq=QueryBuilders
.boolQuery()
//分词匹配
.must(QueryBuilders.matchPhraseQuery("name",name))
//精确匹配
.must(QueryBuilders.matchQuery("age",age));
//4 填充搜索语句
searchSourceBuilder
.query(bq)
.from(0)
.size(5);
//4 填充搜索内容
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = null;
try {
//5 执行搜索操作
searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
//6 返回值
return JSON.toJSONString(searchResponse.getHits());
}控制层
@GetMapping("/searchUser3")
public String searchUser3() throws IOException {
return service.searchDocument3("user","妲己",32);
}
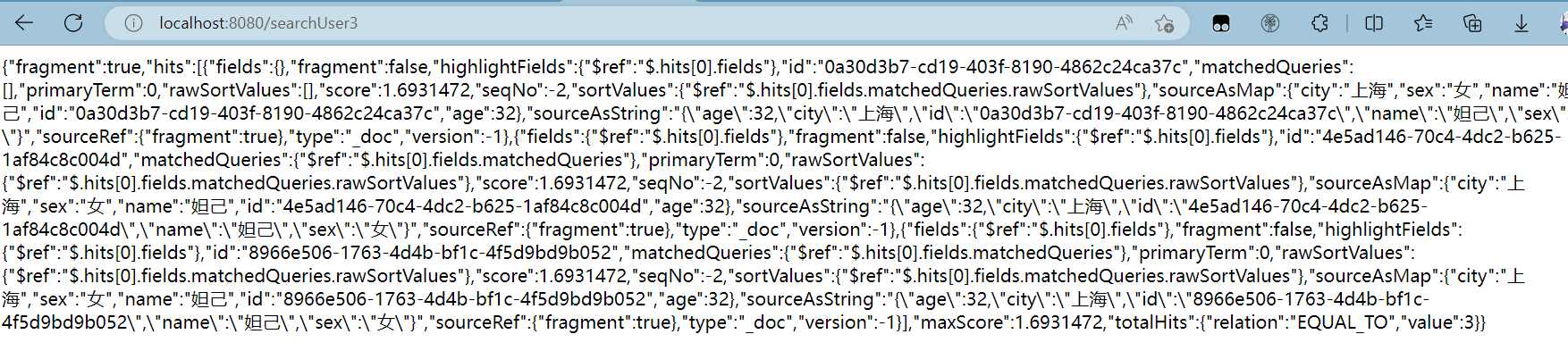 字符匹配OR精准查询
字符匹配OR精准查询
原始查询语句
GET user/_search
{
"query": {
"bool":{
"should": [
{
"match_phrase": {
"name": "妲己"
}
},
{
"term": {
"age": "32"
}
}
]
}
},
"from":0,
"size":10
}服务层
// 文档分词搜索OR精确查询
public String searchDocument4(String indexName,String name,Integer age){
//2 构建搜索请求
SearchRequest searchRequest = new SearchRequest().indices(indexName);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//3 构建复杂的查询语句
BoolQueryBuilder bq=QueryBuilders
.boolQuery()
//分词匹配
.should(QueryBuilders.matchPhraseQuery("name",name))
//精确匹配
.should(QueryBuilders.matchQuery("age",age));
//4 填充搜索语句
searchSourceBuilder
.query(bq)
.from(0)
.size(5);
//4 填充搜索内容
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = null;
try {
//5 执行搜索操作
searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
//6 返回值
return JSON.toJSONString(searchResponse.getHits());
}控制层
@GetMapping("/searchUser4")
public String searchUser4() throws IOException {
return service.searchDocument4("user","妲己",22);
}结果

模糊查询
原始语句
GET user/_search
{
"query": {
"wildcard": {
"city": {
"value": "上*"
}
}
}
} // 文档模糊查询
public String searchDocument5(String indexName,String city){
//2 构建搜索请求
SearchRequest searchRequest = new SearchRequest().indices(indexName);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//3 构建模糊查询的语句
WildcardQueryBuilder bq=QueryBuilders
.wildcardQuery("city",city);
//4 填充搜索语句
searchSourceBuilder
.query(bq);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = null;
try {
//5 执行搜索操作
searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
//6 返回值
return JSON.toJSONString(searchResponse.getHits());
} @GetMapping("/searchUser5")
public String searchUser5() throws IOException {
return service.searchDocument5("user","上*");
}结果