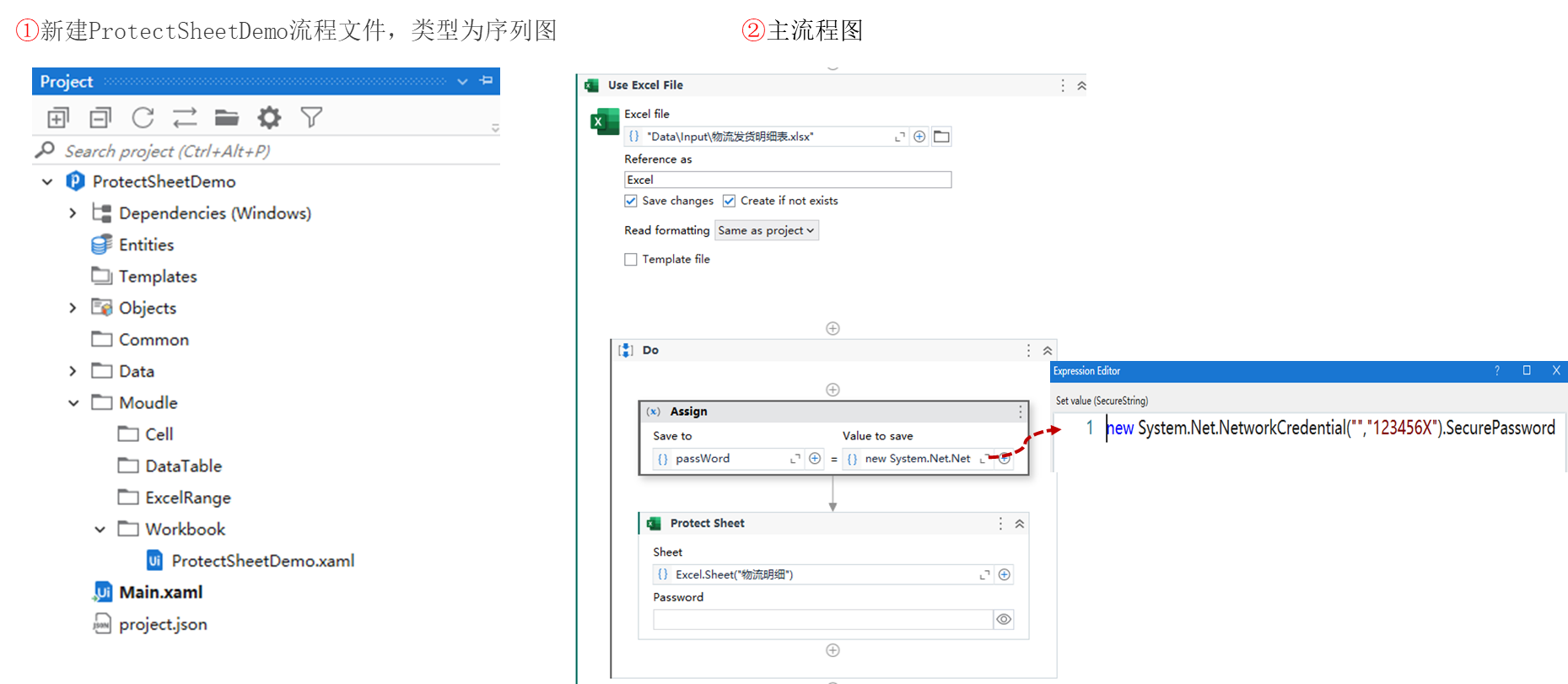
一、LinkedList
LinkedList同时实现了List接口和Deque对口,也就是收它既可以看作一个顺序容器,又可以看作一个队列(Queue),同时又可以看作一个栈(stack),这样看来,linkedList简直就是无敌的,当你需要使用栈或者队列时,可以考虑用LinkedList,一方面是因为Java官方已经声明不建议使用Stack类,更遗憾的是,Java里根本没有一个叫做Queue的类(只是一个接口的名字)。关于栈或队列,现在首选是ArrayDeque,它有着比LinkedList(当作栈或队列使用时)更好的性能。
虽然LinkedList是一个List集合,但是它的实现方式是通过一个动态的Object[]数组来实现的,而LinkedList的底层原理是通过链表来实现的,因此它的随机访问速度比较差,但是它的删除,插入操作会很快。
- LinkedList是基于双向循环链表来实现的,除了可以当做链表来操作外,它还可以当做栈、队列和双端队列来使用。
- LinkedList是非线程安全的,只在单线程下适合使用。
- LinkedList实现了Serializable接口,因此它支持序列化,能够通过序列化传输,实现Cloneable接口,能被克隆。
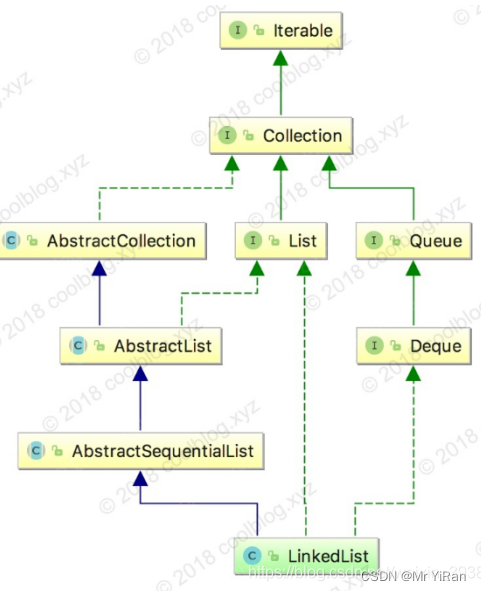
LinkedList 是一个继承自 AbstractSequentialList 的双向链表,因此它也可以被当作堆栈、队列或双端队列进行操作。
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
}
LinkedList内部定义了一个Node节点,它包含3个部分:元素内容item,前引用prev和后引用next,代码如下:
private static class Node<E> {
E item;
LinkedList.Node<E> next;
LinkedList.Node<E> prev;
Node(LinkedList.Node<E> prev, E element, LinkedList.Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
LinkedList 还实现了 Cloneable 接口,这表明 LinkedList 是支持拷贝的。
LinkedList 还实现了 Serializable 接口,这表明 LinkedList 是支持序列化的。LinkedList 中的关键字段 size、first、last 都使用了 transient 关键字修饰,这不又矛盾了吗?到底是想序列化还是不想序列化?
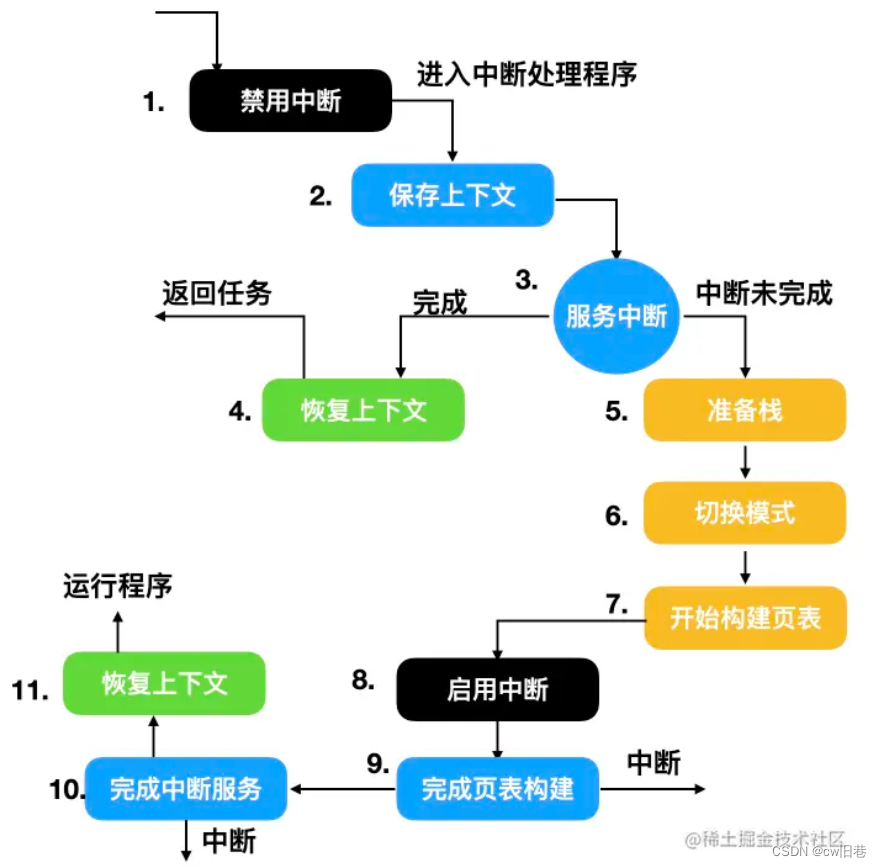
先来看看writeObject()方法
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out any hidden serialization magic
s.defaultWriteObject();
// Write out size
s.writeInt(size);
// Write out all elements in the proper order.
for (Node<E> x = first; x != null; x = x.next)
s.writeObject(x.item);
}
会发现LinkedList在序列化的时候只保留了元素的内容item,并没有保留元素的前后引用。这样就节省了不少内存空间。当我们在反序列化的时会有一个linkLast()方法,它可以把链表重新链接起来,这样就恢复了链表序列化之前的顺序。
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
和 ArrayList 相比,LinkedList 没有实现 RandomAccess 接口,这是因为 LinkedList 存储数据的内存地址是不连续的,所以不支持随机访问。
二、ArrayList
ArrayList是如何实现的?
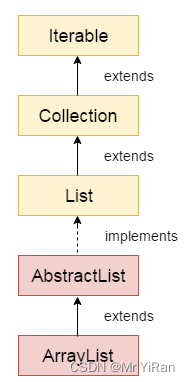
ArrayList实现了List接口,继承了AbstractList抽象类,底层是基于数组实现的,并且实现了动态扩容
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final long serialVersionUID = 8683452581122892189L;
private static final int DEFAULT_CAPACITY = 10;//默认分配长度
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData; // non-private to simplify nested class access
private int size;
}
ArrayList还实现了RandomAccess接口,这是一个标记接口
public interface RandomAccess {
}
内部是空的,标记“实现了这个接口的类支持快速(通常是固定时间)随机访问”。快速随机访问是什么意思呢?就是说不需要遍历,就可以通过下标(索引)直接访问到内存地址。
ArrayList还实现了Cloneable接口,这表明ArrayList是支持拷贝的。ArrayList内部的确也重写了Object类的Clone()方法。
/**
* Returns a shallow copy of this <tt>ArrayList</tt> instance. (The
* elements themselves are not copied.)
*
* @return a clone of this <tt>ArrayList</tt> instance
*/
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
ArrayList还实现了Serializable接口,同样是一个标记接口:
public interface Serializable {
}
内部也是空的,标记“实现了这个接口的类支持序列化”。Java的序列化是指将对象转换成以字节序列的形式来表示,这些序列中包含了对象的字段和方法。序列化后的对象可以被写到数据库、写到文件,也可用于网络传输。
ArrayList中的关键字段elementData使用了transient 关键字修饰,这个关键字的作用是,让它修饰的字段不被序列化。
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData; // non-private to simplify nested class access
这个时候会有疑问,一个类既然实现了Serializable 接口,肯定是想要被序列化,那么为什么保存关键数据的elementData又不想被序列化呢?
这要从ArrayList是基于数组实现开始,数组是固定长度的,一旦声明了,长度就是固定的。数组一旦装满,就不能添加新的元素进来了。
因此ArrayList选择实现动态扩容,通过oldCapacity >> 1从而实现按照原来数组的长度的1.5倍进行扩容。假设oldCapacity=10,oldCapacity >> 1=5,那么 int newCapacity = oldCapacity + (oldCapacity >> 1);newCapacity 的长度就扩容到15。
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
*/
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
动态扩容表示实际数组大小可能永远无法被填满的,总有多余出来空置的内存空间。
比如说,默认的数组大小是 10,当添加第 11 个元素的时候,数组的长度扩容了 1.5 倍,也就是 15,意味着还有 4 个内存空间是闲置的,对吧?
序列化的时候,如果把整个数组都序列化的话,是不是就多序列化了 4 个内存空间。当存储的元素数量非常非常多的时候,闲置的空间就非常非常大,序列化耗费的时间就会非常非常多。
于是ArrayList内部提供了两个私有方法writeObject和readObject来完成序列化和反序列化。
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}
从writeObject和readObject方法的源码中可以看出,它使用了ArrayList的实际大小size而不是数组长度(elementData.length)来作为元素的上限进行序列化。
LinkedList和ArrayList的选择
- 如果列表很大很大,ArrayList 和 LinkedList 在内存的使用上也有所不同。LinkedList 的每个元素都有更多开销,因为要存储上一个和下一个元素的地址。ArrayList 没有这样的开销。
- 但是,ArrayList 占用的内存在声明的时候就已经确定了(默认大小为 10),不管实际上是否添加了元素,因为复杂对象的数组会通过 null 来填充。LinkedList 在声明的时候不需要指定大小,元素增加或者删除时大小随之改变。
- 另外,ArrayList 只能用作列表;LinkedList 可以用作列表或者队列,因为它还实现了 Deque 接口。
ArrayList和LinkedList之间的区别
插入之间的区别
-
ArrayList可以插入到指定下标位置,或者数组末尾,这种插入普通情况下是很快的,但是如果某次插入操作触发了扩容,那么本次插入就增加了额外的扩容成本。
-
对于LinkedList,如果是插在链表的头部或者是尾部都是很快的,因为LinkedList中有单独的属性记录的链表的头结点和尾结点,不过,如果是插在指定下标位置,那么就需要遍历链表找到指定位置,从而降低了效率。但是,使用LinkedList是不用担心扩容问题的,链表是不需要扩容的。
查询之间的区别
首先,从名字就可以看出,ArrayList和LinkedList的区别,ArrayList是基于数组的,LinkedList是基于链表的。
从这一点,我们可以推理出来,ArrayList适合查询,LinkedList适合插入,但是这只是一个广泛的结论,我们应该了解的更细致一点。
-
比如,对于ArrayList,它真正的优点是按下标查询元素(快速随机访问),相比于LinkedList,LinkedList也可以按下标查询元素,但是LinkedList需要对底层链表进行遍历,才能找到指定下标的元素,而ArrayList不用,所以这是ArrayList的优点。
-
但是,如果我们讨论的是获取第一个元素,或最后一个元素,ArrayList和LinkedList在性能上是没有区别的,因为LinkedList中有两个属性分别记录了当前链表中的头结点和尾结点,并不需要遍历链表。
总结
- 默认情况下,比如调用ArrayList和LinkedList的add(e)方法,都是插入在最后,如果这种操作比较多,那么就用LinkedList,因为不涉及到扩容。
- 如果调用ArrayList和LinkedList的add(index, e)方法比较多,就要具体考虑了,因为ArrayList可能会扩容,LinkedList需要遍历链表,这两种到底哪种更快,没有一个完全的结论,得具体情况具体分析。
- 如果是插入场景比较少,但经常需要查询的话,查询分两种,第一种就是普通遍历,也就是经常需要对List中的元素进行遍历,那么这两种是区别不大的,遍历链表和遍历数组的区别,第二种就是经常需要按指定下标获取List中的元素(ArrayList有快速随机访问的特性),如果这种情况如果比较多,那么就用ArrayList