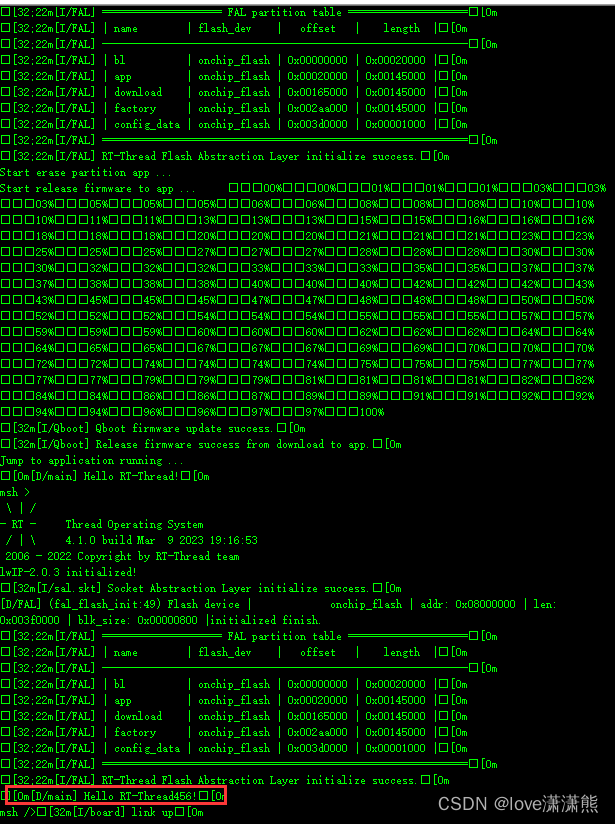
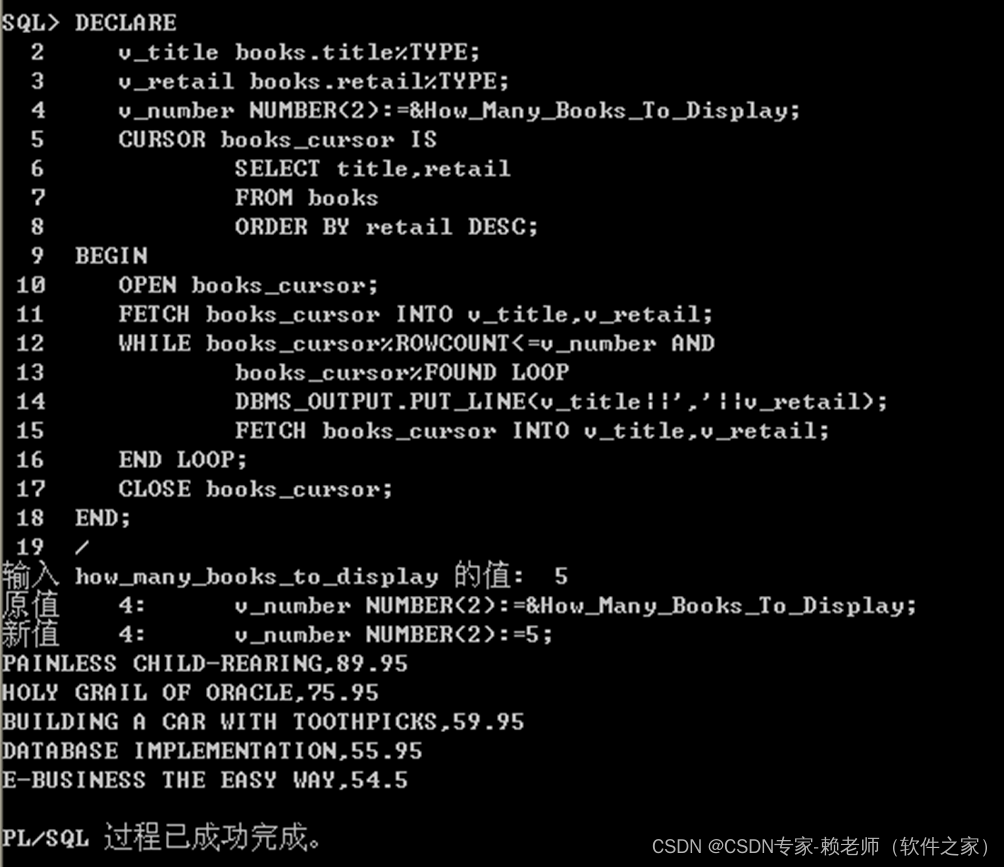
Project Reactor 框架
在Spring Boot 项目 Maven 中添加依赖管理。
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-core</artifactId>
</dependency>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-test</artifactId>
<scope>test</scope>
</dependency>如果想在Spring Boot 项目中使用 Reactor,那么你需要在构建中设置 Reactor 的 BOM(物料清单)。下面的依赖管理条目增加了 Reactor 的 Bismuth-RELEASE 到构建中:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-bom</artifactId>
<version>Bismuth-RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>Reactor 异步数据序列
响应式流规范的基本组件是一个异步的数据序列,在 Reactor 框架中,我们可以把这个异步数据序列表示成如下形式:
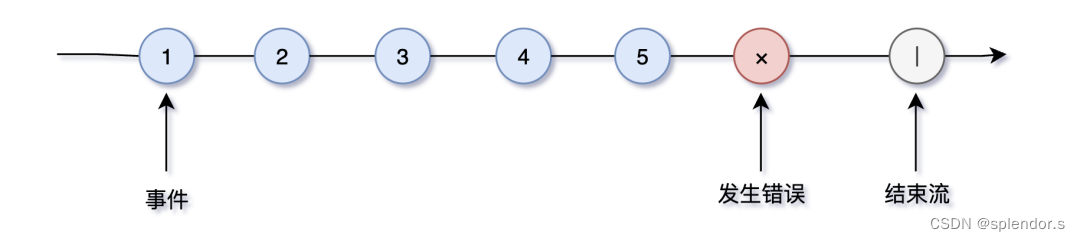
上面的异步数据序列可以用下面的公式来表示:
onNext x 0..N [onError | onComplete]-
onNext:表示正常的包含元素的消息通知
-
onComplete:表示序列结束的消息通知
-
onError:表示序列出错的消息通知
当触发这些消息通知时,异步序列的订阅者中对应的这三个同名方法将被调用。正常情况下,onNext() 和 onComplete() 方法都应该被调用,用来正常消费数据并结束序列。如果没有调用 onComplete() 方法就会生成一个无界数据序列,在业务系统中,这通常是不合理的。而 onError() 方法只有序列出现异常时才会被调用。
基于上述异步数据序列,Reactor 框架提供了两个核心组件来发布数据,分别是 Flux 和 Mono 组件。这两个组件可以说是应用程序开发过程中最基本的编程对象,这两个组件非常重要,理解清楚它两,Reactor 响应式编程才算进入门槛。
Flux 和 Mono 组件
Flux 代表的是一个包含 0 到 n 个元素的异步序列,如下:

-
Flux是一个标准Publisher,表示0到N个发射项的异步序列,可选地以完成信号或错误终止。与 Reactive Streams 规范中一样,这三种类型的信号转换为对下游订阅者的 onNext、onComplete 或 onError 方法的调用。 -
在这种大范围的可能信号中,Flux 是通用的 reactive 类型。注意,所有事件,甚至终止事件,都是可选的:没有 onNext 事件,但是 onComplete 事件表示一个空的有限序列,但是移除 onComplete 并且你有一个无限的空序列(除了关于取消的测试之外,没有特别有用)。同样,无限序列不一定是空的。例如,Flux.interval(Duration) 产生一个
Flux,它是无限的,从时钟发出规则的数据。
Mono 代表的是一个包含 0 到 1 个元素的异步序列,如下:
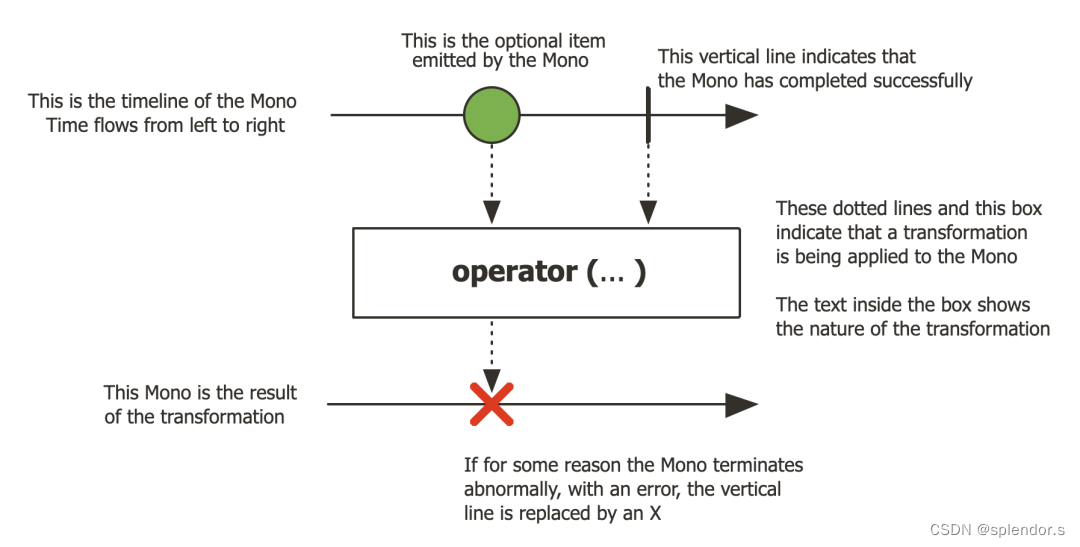
-
Mono是一个专门的Publisher,它最多发出一个项,然后可选地以 onComplete 信号或 onError 信号结束。 -
它只提供了可用于 Flux 的操作符的子集,并且一些操作符(特别是那些将 Mono 与另一个发布者组合的操作符)切换到 Flux。
-
例如,Mono#concatWith(Publisher) 返回一个 Flux ,而 Mono#then(Mono) 则返回另一个 Mono。
-
注意,Mono 可以用于表示只有完成概念(类似于Runnable)的无值异步进程。若要创建一个,请使用
Mono。
响应式操作实战
通过 Flux 对象创建响应式流
主要有以下两大类:
-
基于各种工厂模式的静态创建方法;
-
采用编程的方式动态创建 Flux;
基于各种工厂模式的静态创建方法
Reactor 中静态创建 Flux 的方法常见的包括 just()、range()、interval() 以及各种以 from- 为前缀的方法组等。
-
just() 方法
它可以指定序列中包含的全部元素,创建出来的 Flux 序列在发布这些元素之后会自动结束。一般情况下,在已知元素数量和内容时,使用 just() 方法是创建 Flux 的最简单直接的做法。
Flux.just("Apple", "Orange", "Grape", "Banana","Strawberry")
.subscribe(System.out::println);控制台输出:
Apple
Orange
Grape
Banana
Strawberry这里要想控制台有输出,必须要调用 subscribe 方法,Flux 要是没有订阅者,数据就不会流动。以花园软管的思路进行类比,你已经把软管接到出水口了,另一端就是从自来水公司流出的水。但是水不会流动,除非你打开水龙头。对响应式类型的订阅就是打开数据流的方式。
subscribe() 中的 lambda 表达式实际上是 java.util.Consumer,用于创建响应式流的 Subscriber。由于调用了 subscribe() 方法,数据开始流动了。在这个例子中,不存在中间操作,因此数据直接从 Flux 流到了 Subscriber。
-
fromXXX() 方法组
如果我们已经有了一个数组、一个 Iterable 对象或 Stream 对象,那么就可以通过 Flux 提供的 fromXXX() 方法组来从这些对象中自动创建 Flux,包括 fromArray()、fromIterable() 和 fromStream() 方法。

// fromArray()
String[] fruits = new String[] {"Apple", "Orange", "Grape", "Banana", "Strawberry"};
Flux.fromArray(fruits).subscribe(System.out::println);
// fromIterable()
List<String> fruitList = new ArrayList<>();
fruitList.add("Apple");
fruitList.add("Orange");
fruitList.add("Grape");
fruitList.add("Banana");
fruitList.add("Strawberry");
Flux.fromIterable(fruitList).subscribe(System.out::println);
// fromStream()
Stream<String> fruitStream =Stream.of("Apple", "Orange", "Grape", "Banana", "Strawberry");
Flux.fromStream(fruitStream).subscribe(System.out::println);三个方法控制台都是输出:
Apple
Orange
Grape
Banana
Strawberry-
range() 方法
有时你没有任何数据可供使用,只需要使用 Flux 作为计数器,发出一个随每个新值递增的数字。要创建计数器 Flux,可以使用静态 range() 方法。

Flux.range(1, 5).subscribe(System.out::println);-
interval() 方法
在 Reactor 框架中,interval() 方法可以用来生成从 0 开始递增的 Long 对象的数据序列。通过 interval() 所具备的一组重载方法,我们可以分别指定这个数据序列中第一个元素发布之前的延迟时间,以及每个元素之间的时间间隔。
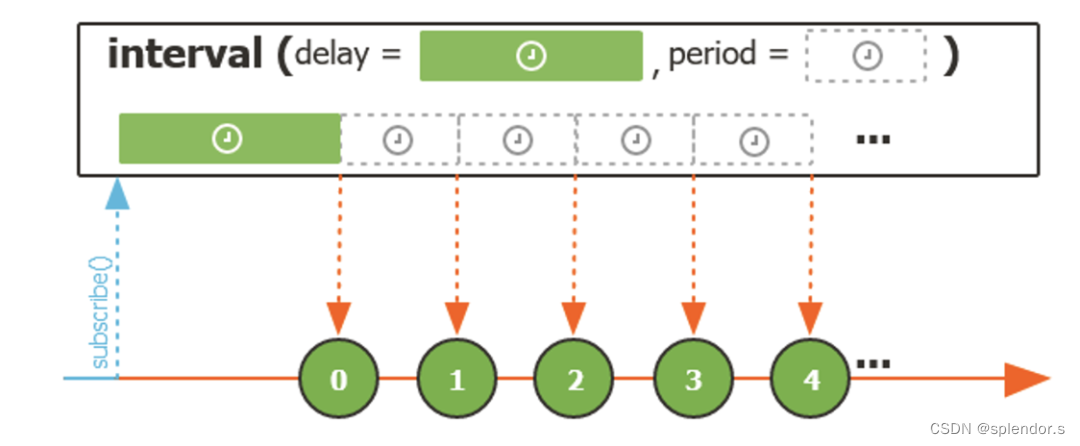
图中每个元素发布时相当于添加了一个定时器的效果。使用 interval() 方法的示例代码如下所示:
Flux.interval(Duration.ofSeconds(2), Duration.ofMillis(200)).subscribe(System.out::println);这段代码的执行效果相当于在等待 2 秒钟之后,生成一个从 0 开始逐一递增的无界数据序列,每 200 毫秒推送一次数据。
-
empty()、error() 和 never()
我们可以分别使用 empty()、error() 和 never() 这三个方法类创建一些特殊的数据序列。其中,如果你希望创建一个只包含结束消息的空序列,那么可以使用 empty() 方法,使用示例如下所示。显然,这时候控制台应该没有任何的输出结果。
Flux.empty().subscribe(System.out::println);然后,通过 error() 方法可以创建一个只包含错误消息的序列。如果你不希望所创建的序列不发出任何类似的消息通知,也可以使用 never() 方法实现这一目标。当然,这几个方法都比较少用,通常只用于调试和测试。
不难看出,静态创建 Flux 的方法简单直接,一般用于生成那些事先已经定义好的数据序列。而如果数据序列事先无法确定,或者生成过程中包含复杂的业务逻辑,那么就需要用到动态创建方法。
采用编程的方式动态创建 Flux
动态创建 Flux 所采用的就是以编程的方式创建数据序列,最常用的就是 generate() 方法和 create() 方法。
-
generate() 方法
generate() 方法生成 Flux 序列依赖于 Reactor 所提供的 SynchronousSink 组件,定义如下:
public static <T> Flux<T> generate(Consumer<SynchronousSink<T>> generator)SynchronousSink 组件包括 next()、complete() 和 error() 这三个核心方法。从 SynchronousSink 组件的命名上就能知道它是一个同步的 Sink 组件,也就是说元素的生成过程是同步执行的。这里要注意的是 next() 方法只能最多被调用一次。使用 generate() 方法创建 Flux 的示例代码如下:
Flux.generate(sink -> {
sink.next("splendor.s");
sink.complete();
}).subscribe(System.out::println);运行代码控制台会打印“splendor.s”,我们在这里调用了一次 next() 方法,并通过 complete() 方法结束了这个数据流,如果不调用 complete() 方法,那么就会生成一个所有元素均为“splendor.s”的无界数据流。
如果想要在序列生成过程中引入状态,那么可以使用如下所示的 generate() 方法重载。
Flux.generate(() -> 1, (i, sink) -> {
sink.next(i);
if (i == 5) {
sink.complete();
}
return ++i;
}).subscribe(System.out::println);这里引入了一个代表中间状态的变量 i,然后根据 i 的值来判断是否终止序列。显然,以上代码的执行效果会在控制台中输入 1 到 5 这 5 个数字。
-
create()
我们再来看下 create() 方法,定义如下:
public static <T> Flux<T> create(Consumer<? super FluxSink<T>> emitter)FluxSink 除了 next()、complete() 和 error() 这三个核心方法外,还定义了背压策略,并且可以在一次调用中产生多个元素。使用 create() 方法创建 Flux 的示例代码如下:
Flux.create(sink -> {
for (int i = 0; i < 5; i++) {
sink.next("splendor.s" + i);
}
sink.complete();
}).subscribe(System.out::println);运行代码控制台会打印“微splendor.s 0”到“splendor.s 4”的5个数据,通过 create() 方法创建 Flux 对象的方式非常灵活。
通过 Mono 对象创建响应式流
对于 Mono 而言,可以认为它是 Flux 的一种特例,所以很多创建 Flux 的方法同样适用。
针对静态创建 Mono 的场景,前面给出的 just()、empty()、error() 和 never() 等方法同样适用。除了这些方法之外,比较常用的还有 justOrEmpty() 等方法。
justOrEmpty() 方法会先判断所传入的对象中是否包含值,只有在传入对象不为空时,Mono 序列才生成对应的元素,该方法示例代码如下:
Mono.justOrEmpty(Optional.of("splendor.s")).subscribe(System.out::println);如果要想动态创建 Mono,我们同样也可以通过 create() 方法并使用 MonoSink 组件,示例代码如下:
Mono.create(sink -> sink.success("splendor.s")).subscribe(System.out::println);操作符分类
Reactor 库中的 API 提供了一组丰富的操作符,这些操作符为响应式流规范提供了很大的一个便利性。但 Reactor 中所提供的操作符数量众多,这里只针对几类具有代表性的操作符来讨论。
我将 Flux 和 Mono 操作符分成如下六大类型:
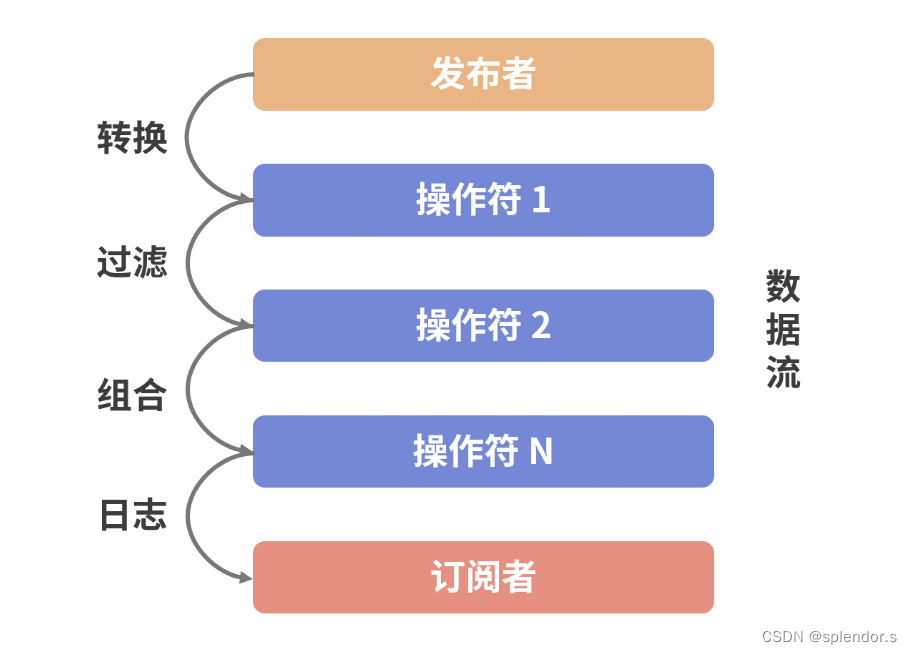
-
转换(Transforming)操作符,负责将序列中的元素转变成另一种元素;
-
过滤(Filtering)操作符,负责将不需要的数据从序列中剔除出去;
-
组合(Combining)操作符,负责将序列中的元素进行合并、连接和集成;
-
条件(Conditional)操作符,负责根据特定条件对序列中的元素进行处理;
-
裁剪(Reducing)操作符,负责对序列中的元素执行各种自定义的裁剪操作;
-
工具(Utility)操作符,负责一些针对流式处理的辅助性操作。
其中,前面三种操作符统称为“转换类”操作符,剩余的三大类统称为“裁剪类”操作符。
转换类操作符
转换类操作符在我们编码的时候最常见了,比如 buffer、window、map 和 flatMap 等。
-
buffer 操作符
buffer 操作符的作用相当于把当前流中的元素统一收集到一个集合中,并把这个集合对象作为新的数据流。使用 buffer 操作符在进行元素收集时,可以指定集合对象所包含的元素的最大数量。

给定一个 String 值的 Flux,每个值都包含一个水果的名称,你可以创建一个新的 List 集合的 Flux,其中每个 List 的元素数不超过指定的数目。
Flux<String> fruitFlux = Flux.just("Apple", "Orange", "Grape", "Banana", "Strawberry");
fruitFlux.buffer(3).subscribe(System.out::println);运行代码控制台会打印:
["Apple", "Orange", "Grape"]
["Banana", "Strawberry"]-
window 操作符
window 操作符的作用类似于 buffer,不同的是 window 操作符是把当前流中的元素收集到另外的 Flux 序列中,而不是一个集合。因此该操作符的返回值类型就变成了 Flux<Flux>。window 操作符相对比较复杂,如下图:
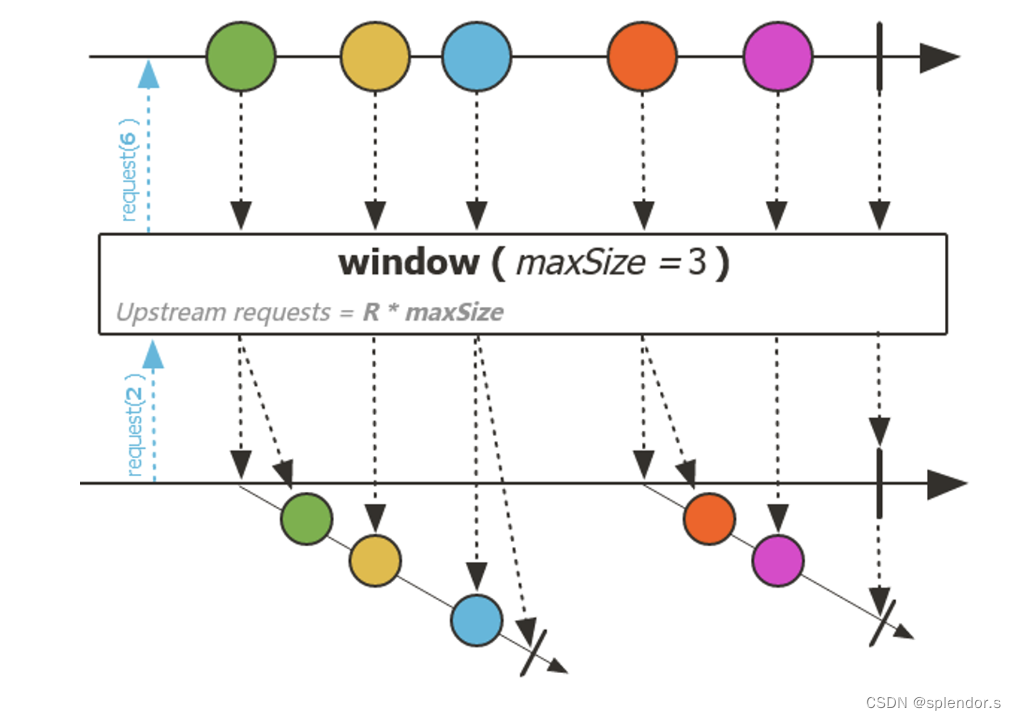
上图比较复杂,代表的是一种对序列进行开窗的操作。我们来看下代码方便理解:
Flux.range(1, 5).window(2).toIterable().forEach(w -> {
w.subscribe(System.out::println);
System.out.println("-------");
});这里我们生成了 5 个元素,然后通过 window 操作符把这 5 个元素转变成 3 个 Flux 对象。在将这些 Flux 对象转化为 Iterable 对象后,通过 forEach() 循环打印出来,运行代码控制台会打印:
1
2
-------
3
4
-------
5-
map 操作符
map 操作符相当于一种映射操作,它对流中的每个元素应用一个映射函数从而达到转换效果,比较简单,我们来看一下示例。
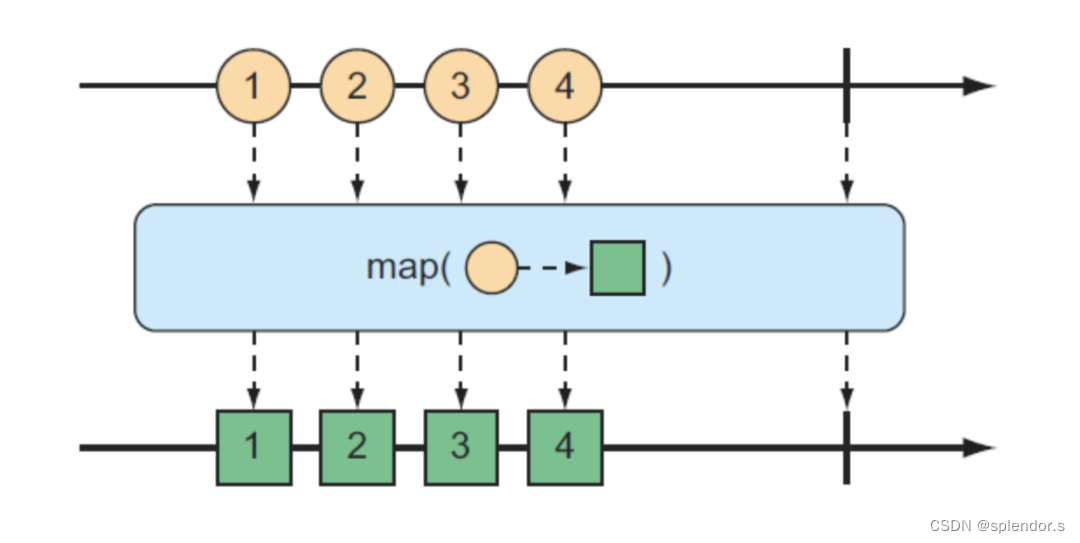
Flux.just(1, 2).map(i -> "number-" + i).subscribe(System.out::println);运行代码控制台会打印:
number-1
number-2关于 map() 的重要理解是,映射是同步执行的,因为每个项都是由源 Flux 发布的。如果要异步执行映射,应考虑使用 flatMap() 操作。
-
flatMap 操作符
flatMap 操作符执行的也是一种映射操作,但与 map 不同,该操作符会把流中的每个元素映射成一个流而不是一个元素,flatMap() 不是简单地将一个对象映射到另一个对象,而是将每个对象映射到一个新的 Mono 或 Flux。Mono 或 Flux 的结果被压成一个新的 Flux。当与subscribeOn() 一起使用时,flatMap() 可以释放 Reactor 类型的异步能力。然后再把得到的所有流中的元素进行合并,整个过程的流程图请看下图:

Flux.just(1, 5)
.flatMap(x -> Mono.just(x * x))
.subscribe(System.out::println);效果如下:
1
25事实上,flatMap 可以对任何你感兴趣的操作进行转换。例如,在系统开发过程中,我们经常会碰到对从数据库查询所获取的数据项逐一进行处理的场景,这时候就可以充分利用 flatMap 操作符的特性开展相关操作。
如下所示的代码演示了针对从数据库获取的 User 数据,如何使用该操作符逐一查询 User 所生成的订单信息的实现方法。
Flux<User> users = userRepository.getUsers();
users.flatMap(u -> getOrdersByUser(u))过滤操作符
-
filter 操作符
filter 操作符其实跟 Java8 里的 filter 方法类似,对流中的元素过滤,而过滤条件的指定一般是通过断言。
Flux.range(1, 10).filter(i -> i % 2 == 0).subscribe(System.out::println);比如过滤出1到10这10个元素是偶数的数出来,其中“i % 2 == 0”代表的就是一种断言。
-
first/last 操作符
first 操作符的执行效果为返回流中的第一个元素,而 last 操作符的执行效果即返回流中的最后一个元素。
-
skip/skipLast
如果使用 skip 操作符,将会忽略数据流的前 n 个元素。类似的,如果使用 skipLast 操作符,将会忽略流的最后 n 个元素。
-
take/takeLast
take 系列操作符用来从当前流中提取元素。我们可以按照指定的数量来提取元素,也可以按照指定的时间间隔来提取元素。类似的,takeLast 系列操作符用来从当前流的尾部提取元素。
组合操作符
Reactor 中常用的组合操作符有 then/when、merge、startWith 和 zip 等,组合操作符会比过滤操作符复杂一点。
-
then/when 操作符
then 操作符的含义是等到上一个操作完成再进行下一个。
Flux.just(1, 2, 3)
.then()
.subscribe(System.out::println);这里尽管生成了一个包含 1、2、3 三个元素的 Flux 流,但 then 操作符在上游的元素执行完成之后才会触发新的数据流,也就是说会忽略所传入的元素,所以上述代码在控制台上实际并没有任何输出。
和 then 一起的还有一个 thenMany 操作服务,具有同样的含义,但可以初始化一个新的 Flux 流。示例代码如下所示,这次我们会看到控制台上输出了 4 和 5 这两个元素。
Flux.just(1, 2, 3)
.thenMany(Flux.just(4, 5))
.subscribe(System.out::println);对应的,when 操作符的含义则是等到多个操作一起完成。如下代码很好地展示了 when 操作符的实际应用场景。
public Mono<Void> updateOrders(Flux<Order> orders) {
return orders
.flatMap(file -> {
Mono<Void> saveOrderToDatabase = ...;
Mono<Void> sendMessage = ...;
return Mono.when(saveOrderToDatabase, sendMessage);
});
}假设我们对订单列表进行批量更新,首先把订单数据持久化到数据库,然后再发送一条通知类的消息。我们需要确保这两个操作都完成之后方法才能返回,所以用到了 when 操作符。
-
merge 操作符
merge 操作符用来把多个 Flux 流合并成一个 Flux 序列,而合并的规则就是按照流中元素的实际生成的顺序进行。
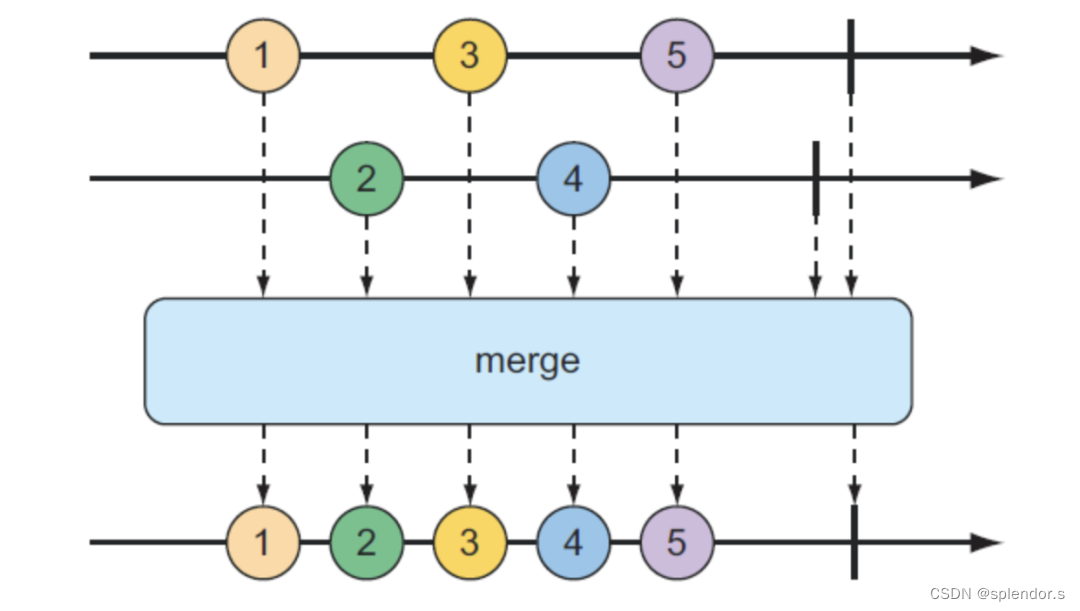 我们通过 Flux.intervalMillis() 方法分别创建了两个 Flux 序列,然后将它们 merge 之后打印出来。
我们通过 Flux.intervalMillis() 方法分别创建了两个 Flux 序列,然后将它们 merge 之后打印出来。
Flux.merge(Flux.intervalMillis(0, 100).take(2), Flux.intervalMillis(50, 100).take(2))
.toStream().forEach(System.out::println);请注意,这里的第一个 intervalMillis 方法没有延迟,每隔 100 毫秒生成一个元素,而第二个 intervalMillis 方法则是延迟 50 毫秒之后才发送第一个元素,时间间隔同样是 100 毫秒。相当于两个数据序列会交错地生成数据,并合并在一起。所以以上代码的执行效果如下所示:
0
0
1
1和 merge 类似的还有一个 mergeSequential 方法。不同于 merge 操作符,mergeSequential 操作符则按照所有流被订阅的顺序,以流为单位进行合并。现在我们来看一下这段代码,这里仅仅将 merge 操作换成了 mergeSequential 操作。
Flux.mergeSequential (Flux.intervalMillis(0, 100).take(2), Flux.intervalMillis(50, 100).take(2))
.toStream().forEach(System.out::println);执行以上代码,我们将得到不同的结果,如下所示:
0
1
0
1显然从结果来看,mergeSequential 操作是等上一个流结束之后再 merge 新生成的流元素。
-
zip 操作符
上面的 merge 操作符合并后的 Flux 发出的数据的顺序,与源发出的数据的时间顺序一致。由于两个 Flux 都被设置为固定频率发送数据,因此值会通过合并后的 Flux 交替出现 —— a…b…a…b 一直这样下去。如果其中任何一个 Flux 的发送时间被修改了的话,你可能会看到 2 个 a 跟在 1 个 b 后面或是 2 个 b 跟在 1 个 a 后面的情况。
因为 merge 不能保证源之间的完美交替,所以可能需要考虑使用 zip() 操作。当两个 Flux 对象压缩在一起时,会产生一个新的 Flux,该 Flux 生成一个元组,其中元组包含来自每个源 Flux 的一个项。下图说明了如何将两个 Flux 对象压缩在一起:
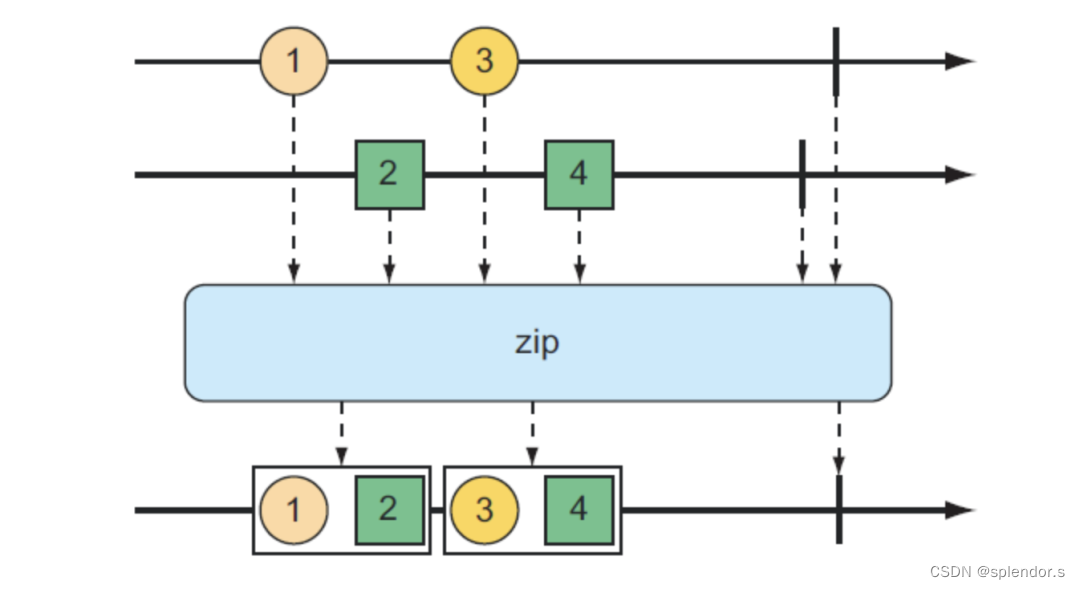
使用 zip 操作符在合并时可以不做任何处理,由此得到的是一个元素类型为 Tuple2 的流,示例代码如下所示:
Flux flux1 = Flux.just(1, 2);
Flux flux2 = Flux.just(3, 4);
Flux.zip(flux1, flux2).subscribe(System.out::println);执行效果如下:
[1,3]
[2,4]我们可以使用 zipWith 操作符实现同样的效果,示例代码如下所示:
Flux.just(1, 2).zipWith(Flux.just(3, 4))
.subscribe(System.out::println);条件操作符
-
defaultIfEmpty 操作符
defaultIfEmpty 操作符针对空数据流提供了一个简单而有用的处理方法。该操作符用来返回来自原始数据流的元素,如果原始数据流中没有元素,则返回一个默认元素。
@GetMapping("/orders/{id}")
public Mono<ResponseEntity<Order>> findOrderById(@PathVariable String id) {
return orderService.findOrderById(id)
.map(ResponseEntity::ok)
.defaultIfEmpty(ResponseEntity.status(404).body(null));
}可以看到,这里使用 defaultIfEmpty 操作符实现默认返回值。在示例代码所展示的 HTTP 端点中,当找不到指定的数据时,我们可以通过 defaultIfEmpty 方法返回一个空对象以及 404 状态码。
-
takeUntil/takeWhile 操作符
takeUntil 操作符的基本用法是 takeUntil (Predicate predicate),其中 Predicate 代表一种断言条件,该操作符将从数据流中提取元素直到断言条件返回 true。
takeUntil 的示例代码如下所示,我们希望从一个包含 100 个连续元素的序列中获取 1~10 个元素。
Flux.range(1, 100).takeUntil(i -> i == 10)
.subscribe(System.out::println);类似的,takeWhile 操作符的基本用法是 takeWhile (Predicate continuePredicate),其中 continuePredicate 代表的也是一种断言条件。与 takeUntil 不同的是,takeWhile 会在 continuePredicate 条件返回 true 时才进行元素的提取。takeWhile 的示例代码如下所示,这段代码的执行效果与 takeUntil 的示例代码一致。
Flux.range(1, 100).takeWhile(i -> i <= 10)
.subscribe(System.out::println);-
skipUntil/skipWhile 操作符
与 takeUntil 相对应,skipUntil 操作符的基本用法是 skipUntil (Predicate predicate)。skipUntil 将丢弃原始数据流中的元素直到 Predicate 返回 true。
同样,与 takeWhile 相对应,skipWhile 操作符的基本用法是 skipWhile (Predicate continuePredicate),当 continuePredicate 返回 true 时才进行元素的丢弃。
裁剪操作符
裁剪操作符通常用于统计流中的元素数量,或者检查元素是否具有一定的属性。在 Reactor 中,常用的裁剪操作符有 any 、concat、count 和 reduce 等。
-
any 操作符
any 操作符用于检查是否至少有一个元素具有所指定的属性,代码如下:
Flux.just(3, 5, 7, 9, 11, 15, 16, 17)
.any(e -> e % 2 == 0)
.subscribe(isExisted -> System.out.println(isExisted));在这个 Flux 流中存在一个元素 16 可以被 2 除尽,所以控制台将输出“true”。
-
concat 操作符
在这个 Flux 流中存在一个元素 16 可以被 2 除尽,所以控制台将输出“true”。
-
concat 操作符
concat 操作符用来合并来自不同 Flux 的数据。与上面所介绍的 merge 操作符不同,这种合并采用的是顺序的方式,所以严格意义上并不是一种合并操作,所以我们把它归到裁剪操作符类别中。
Flux.concat(
Flux.range(1, 3),
Flux.range(4, 2),
Flux.range(6, 5)
).subscribe(System.out::println);我们将在控制台中依次看到 1 到 10 这 10 个数字。
-
reduce 操作符
裁剪操作符中最经典的就是这个 reduce 操作符。reduce 操作符对来自 Flux 序列中的所有元素进行累积操作并得到一个 Mono 序列,该 Mono 序列中包含了最终的计算结果。reduce 操作符示意图如下所示:

这里的 BiFunction 就是一个求和函数,用来对 1 到 10 的数字进行求和,运行结果为 55。
Flux.range(1, 10).reduce((x, y) -> x + y)
.subscribe(System.out::println);与 reduce 操作符类似的还有一个 reduceWith 操作符,用来在 reduce 操作时指定一个初始值。reduceWith 操作符的代码示例如下所示,我们使用 5 来初始化求和过程,显然得到的结果将是 60。
Flux.range(1, 10).reduceWith(() -> 5, (x, y) -> x + y)
.subscribe(System.out::println);工具操作符
Reactor 中常用的工具操作符有 subscribe、timeout、block、log 和 debug 等。
-
subscribe 操作符
subscribe 操作符用使用最多,接下来看下它的 API。
/订阅流的最简单方法,忽略所有消息通知
subscribe();
//对每个来自 onNext 通知的值调用 dataConsumer,但不处理 onError 和 onComplete 通知
subscribe(Consumer<T> dataConsumer);
//在前一个重载方法的基础上添加对 onError 通知的处理
subscribe(Consumer<T> dataConsumer, Consumer<Throwable> errorConsumer);
//在前一个重载方法的基础上添加对 onComplete 通知的处理
subscribe(Consumer<T> dataConsumer, Consumer<Throwable> errorConsumer, Runnable completeConsumer);
//这种重载方法允许通过请求足够数量的数据来控制订阅过程
subscribe(Consumer<T> dataConsumer, Consumer<Throwable> errorConsumer, Runnable completeConsumer, Consumer<Subscription> subscriptionConsumer);
//订阅序列的最通用方式,可以为我们的 Subscriber 实现提供所需的任意行为
subscribe(Subscriber<T> subscriber);-
timeout 操作符
timeout 操作符非常简单,保持原始的流发布者,当特定时间段内没有产生任何事件时,将生成一个异常。
-
block 操作符
顾名思义,block 操作符在接收到下一个元素之前会一直阻塞。block 操作符常用来把响应式数据流转换为传统数据流。例如,使用如下方法将分别把 Flux 数据流和 Mono 数据流转变成普通的 List对象和单个的 Order 对象,我们同样可以设置 block 操作的等待时间。
public List<Order> getAllOrders() {
return orderservice.getAllOrders().block(Duration.ofSecond(5));
}
public Order getOrderById(Long orderId) {
return orderservice.getOrderById(orderId).block(Duration.ofSecond(2));
}-
log 操作符
Reactor 中专门提供了针对日志的工具操作符 log,它会观察所有的数据并使用日志工具进行跟踪。我们可以通过如下代码演示 log 操作符的使用方法,在 Flux.just() 方法后直接添加 log() 函数。
Flux.just(1, 2).log().subscribe(System.out::println);以上代码的执行结果如下所示(为了显示简洁,部分内容和格式做了调整)。通常,我们也可以在 log() 方法中添加参数来指定日志分类的名称。
Info: | onSubscribe([Synchronous Fuseable] FluxArray.ArraySubscription)
Info: | request(unbounded)
Info: | onNext(1)
1
Info: | onNext(2)
2
Info: | onComplete()