影响 Redis 性能的 5 大方面的潜在因素,分别是:
Redis 内部的阻塞式操作;
CPU 核和 NUMA 架构的影响;
Redis 关键系统配置;
Redis 内存碎片;
Redis 缓冲区。
先学习了解下 Redis 内部的阻塞式操作以及应对的方法。
Redis 实例有哪些阻塞点?
Redis 实例在运行时,要和许多对象进行交互,这些不同的交互就会涉及不同的操作,下面我们来看看和 Redis 实例交互的对象,以及交互时会发生的操作。
客户端:网络 IO,键值对增删改查操作,数据库操作;(主线程)
磁盘:生成 RDB 快照,记录 AOF 日志,AOF 日志重写;
主从节点:主库生成、传输 RDB 文件,从库接收 RDB 文件、清空数据库、加载 RDB 文件;
切片集群实例:向其他实例传输哈希槽信息,数据迁移。
客户端阻塞点:
网络 IO 有时候会比较慢,但是 Redis 使用了 IO 多路复用机制,避免了主线程一直处在等待网络连接或请求到来的状态,所以,网络 IO 不是导致 Redis 阻塞的因素。
键值对的增删改查操作是 Redis 和客户端交互的主要部分,也是 Redis 主线程执行的主要任务。所以,复杂度高的增删改查操作肯定会阻塞 Redis。
那么,怎么判断操作复杂度是不是高呢?这里有一个最基本的标准,就是看操作的复杂度是否为 O(N)。
Redis 中涉及集合的操作复杂度通常为 O(N),我们要在使用时重视起来。例如集合元素全量查询操作 HGETALL、LRANGE,SMEMBERS,以及集合的聚合统计操作,例如求交、并和差集。这些操作可以作为 Redis 的第一个阻塞点:集合全量查询和聚合操作。
除此之外,集合自身的删除操作同样也有潜在的阻塞风险。
其实,删除操作的本质是要释放键值对占用的内存空间。你可不要小瞧内存的释放过程。释放内存只是第一步,为了更加高效地管理内存空间,在应用程序释放内存时,操作系统需要把释放掉的内存块插入一个空闲内存块的链表,以便后续进行管理和再分配。这个过程本身需要一定时间,而且会阻塞当前释放内存的应用程序,所以,如果一下子释放了大量内存,空闲内存块链表操作时间就会增加,相应地就会造成 Redis 主线程的阻塞。
那么,什么时候会释放大量内存呢?其实就是在删除大量键值对数据的时候,最典型的就是删除包含了大量元素的集合,也称为 bigkey 删除
既然频繁删除键值对都是潜在的阻塞点了,那么,在 Redis 的数据库级别操作中,清空数据库(例如 FLUSHDB 和 FLUSHALL 操作)必然也是一个潜在的阻塞风险,因为它涉及到删除和释放所有的键值对。所以,这就是 Redis 的第三个阻塞点:清空数据库。
和磁盘交互时的阻塞点
Redis 开发者早已认识到磁盘 IO 会带来阻塞,所以就把 Redis 进一步设计为采用子进程的方式生成 RDB 快照文件,以及执行 AOF 日志重写操作。这样一来,这两个操作由子进程负责执行,慢速的磁盘 IO 就不会阻塞主线程了。
但是,Redis 直接记录 AOF 日志时,会根据不同的写回策略对数据做落盘保存。一个同步写磁盘的操作的耗时大约是 1~2ms,如果有大量的写操作需要记录在 AOF 日志中,并同步写回的话,就会阻塞主线程了。这就得到了 Redis 的第四个阻塞点了:AOF 日志同步写。
主从节点交互时的阻塞点
在主从集群中,主库需要生成 RDB 文件,并传输给从库。主库在复制的过程中,创建和传输 RDB 文件都是由子进程来完成的,不会阻塞主线程。
但是,对于从库来说,它在接收了 RDB 文件后,需要使用 FLUSHDB 命令清空当前数据库,这就正好撞上了刚才我们分析的第三个阻塞点(删除大量数据bigkey)。
此外,从库在清空当前数据库后,还需要把 RDB 文件加载到内存,这个过程的快慢和 RDB 文件的大小密切相关,RDB 文件越大,加载过程越慢,所以,加载 RDB 文件就成为了 Redis 的第五个阻塞点。
切片集群实例交互时的阻塞点
最后,当我们部署 Redis 切片集群时,每个 Redis 实例上分配的哈希槽信息需要在不同实例间进行传递,同时,当需要进行负载均衡或者有实例增删时,数据会在不同的实例间进行迁移。不过,哈希槽的信息量不大,而数据迁移是渐进式执行的,所以,一般来说,这两类操作对 Redis 主线程的阻塞风险不大。
不过,如果你使用了 Redis Cluster 方案,而且同时正好迁移的是 bigkey 的话,就会造成主线程的阻塞,因为 Redis Cluster 使用了同步迁移。你只需要知道,当没有 bigkey 时,切片集群的各实例在进行交互时不会阻塞主线程,就可以了。
五个阻塞点:
集合全量查询和聚合操作;
bigkey 删除;
清空数据库;
AOF 日志同步写;
从库加载 RDB 文件
如果在主线程中执行这些操作,必然会导致主线程长时间无法服务其他请求。为了避免阻塞式操作,Redis 提供了异步线程机制。所谓的异步线程机制,就是指,Redis 会启动一些子线程,然后把一些任务交给这些子线程,让它们在后台完成,而不再由主线程来执行这些任务。使用异步线程机制执行操作,可以避免阻塞主线程。
不过,这个时候,问题来了:这五大阻塞式操作都可以被异步执行吗?
对于 Redis 的五大阻塞点来说,除了“集合全量查询和聚合操作”和“从库加载 RDB 文件”,其他三个阻塞点涉及的操作都不在关键路径上,所以,我们可以使用 Redis 的异步子线程机制来实现 bigkey 删除,清空数据库,以及 AOF 日志同步写。
那么,Redis 实现的异步子线程机制具体是怎么执行呢?
异步的子线程机制
Redis 主线程启动后,会使用操作系统提供的 pthread_create 函数创建 3 个子线程,分别由它们负责 AOF 日志写操作、键值对删除以及文件关闭的异步执行。
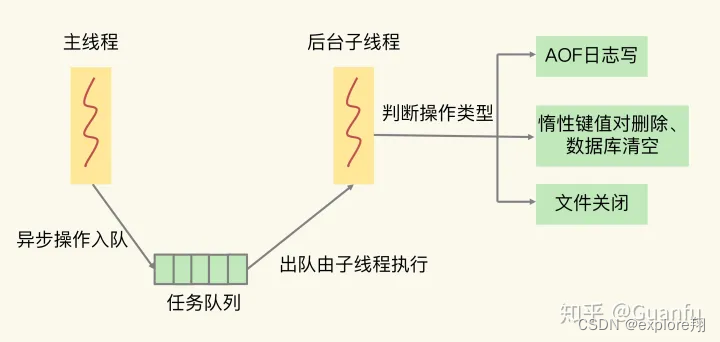
键值对删除:当你的集合类型中有大量元素(例如有百万级别或千万级别元素)需要删除时,我建议你使用 UNLINK 命令。(unlink是指redis用异步方式去del键值,但是异步删除键值有一个判断条件.会根据元素的个数来判断是否值得用异步线程去del,因为异步会有额外的消耗,如果元素较少(比如string,无论string多大都是在主线程里删除),直接在主线程里删除就行.)
清空数据库:可以在 FLUSHDB 和 FLUSHALL 命令后加上 ASYNC 选项,这样就可以让后台子线程异步地清空数据库,如下所示:
FLUSHDB ASYNC
FLUSHALL AYSNC
为什么CPU结构也会影响Redis的性能?
一个CPU处理器中一般有多个运行核心,我们把一个运行核心称为一个物理核,每个物理核都可以运行应用程序。每个物理核都拥有私有的一级缓存(Level 1 cache,简称L1 cache),包括一级指令缓存和一级数据缓存,以及私有的二级缓存(Level 2 cache,简称L2 cache)。
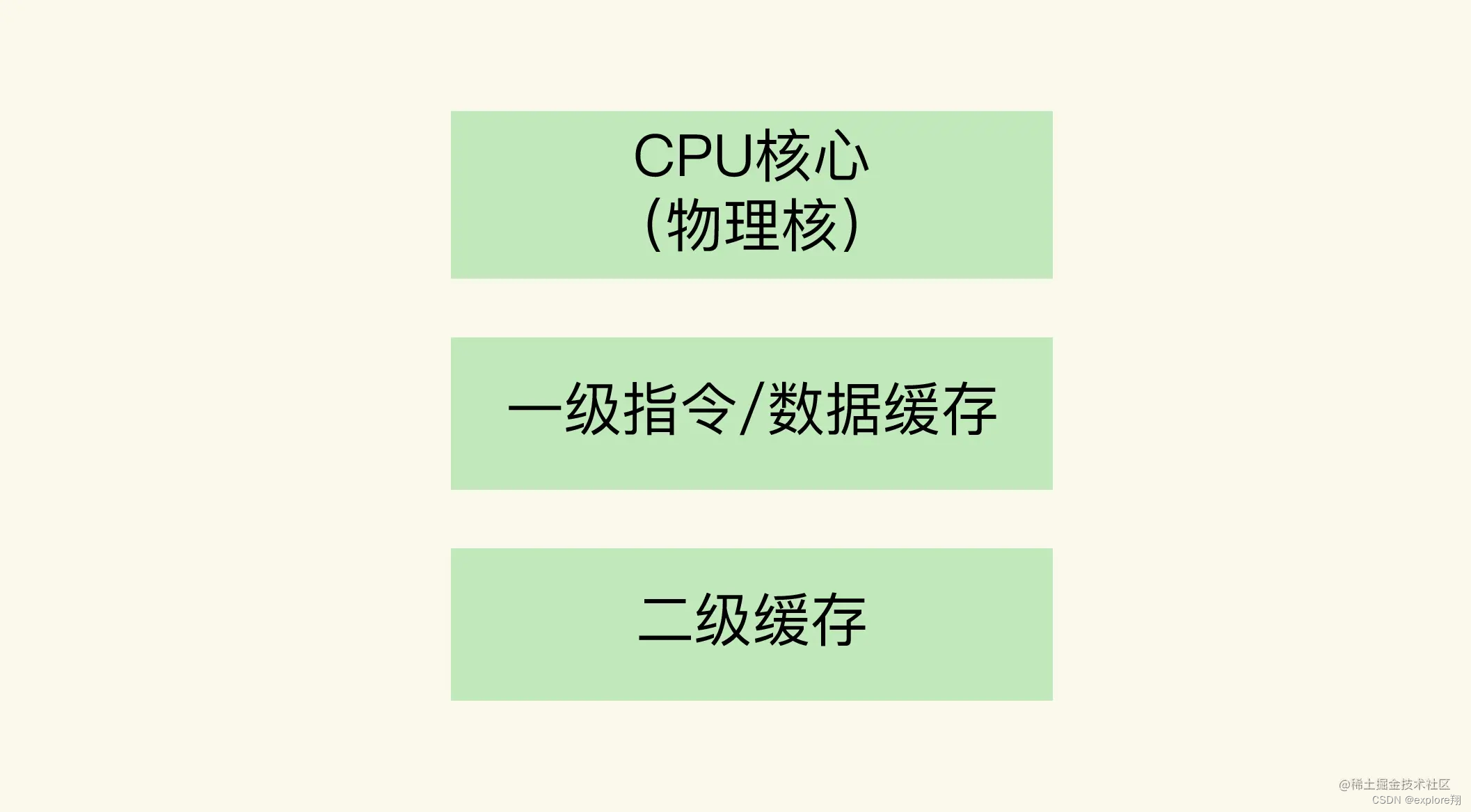
不同的物理核还会共享一个共同的三级缓存(Level 3 cache,简称为L3 cache)。L3缓存能够使用的存储资源比较多,所以一般比较大,能达到几MB到几十MB,这就能让应用程序缓存更多的数据。当L1、L2缓存中没有数据缓存时,可以访问L3,尽可能避免访问内存。
另外,现在主流的CPU处理器中,每个物理核通常都会运行两个超线程,也叫作逻辑核。同一个物理核的逻辑核会共享使用L1、L2缓存。
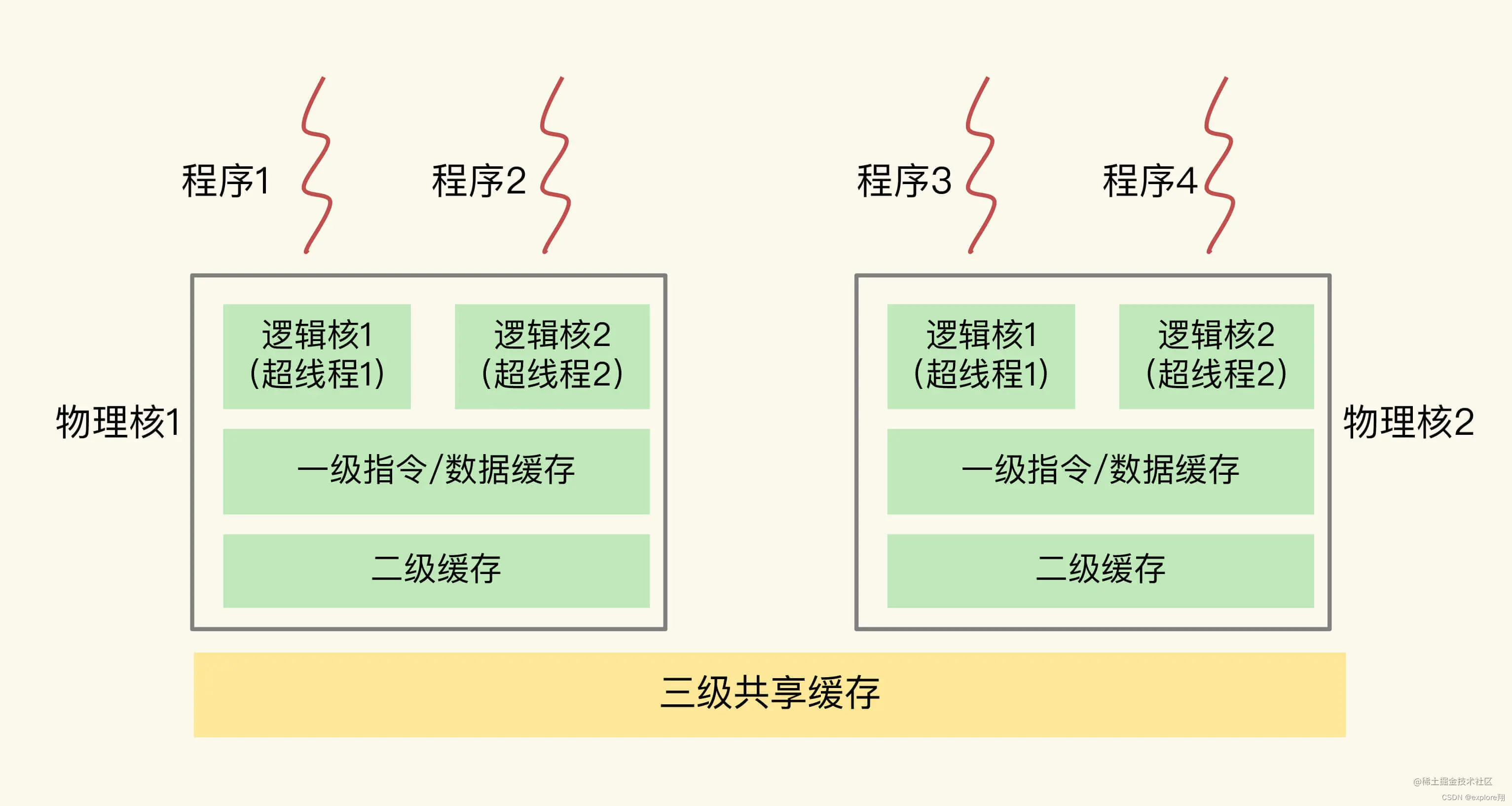
同时,为了提升服务器的处理能力,服务器上通常还会有多个CPU处理器(也称为多CPU Socket),每个处理器有自己的物理核(包括L1、L2缓存),L3缓存,以及连接的内存,同时,不同处理器间通过总线连接。
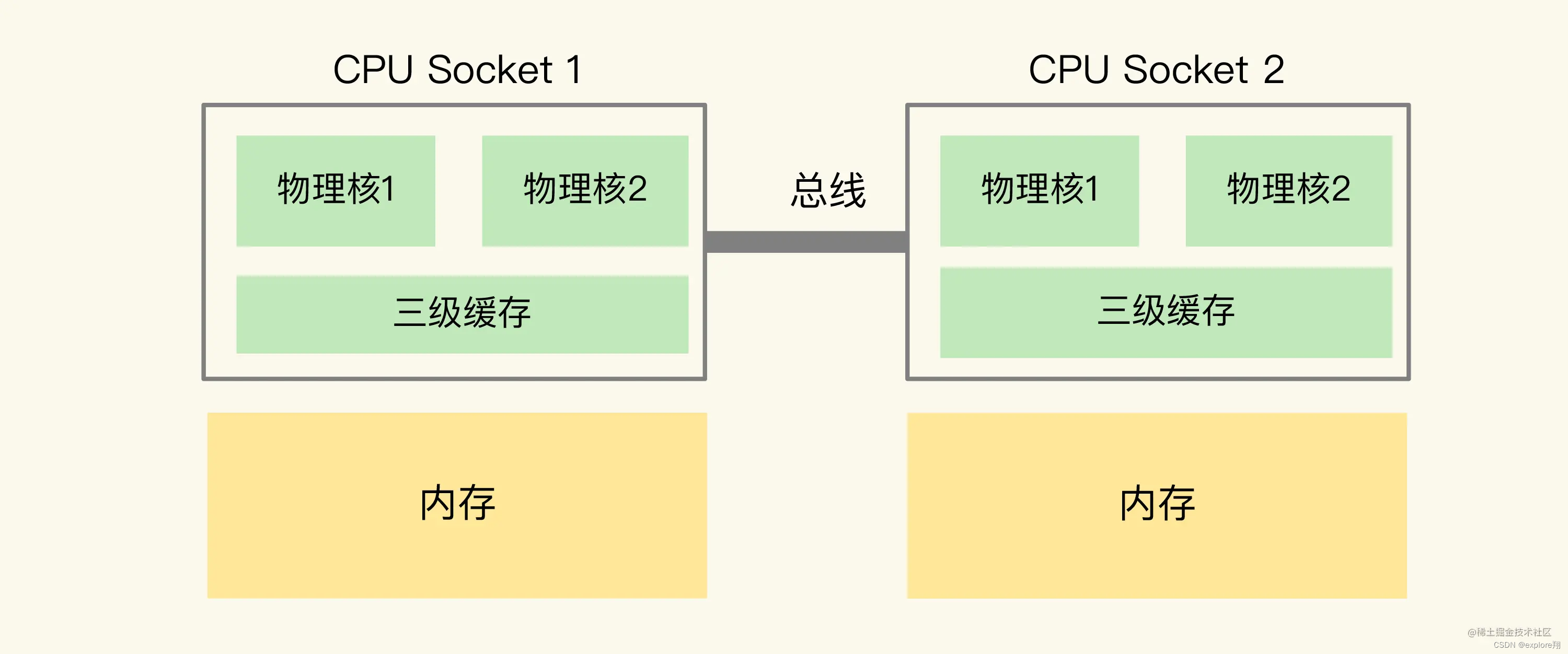
在多CPU架构下,一个应用程序访问所在Socket的本地内存和访问远端内存的延迟并不一致,所以,我们也把这个架构称为非统一内存访问架构(Non-Uniform Memory Access,NUMA架构)。
CPU多核对Redis性能的影响
在一个CPU核上运行时,应用程序需要记录自身使用的软硬件资源信息(例如栈指针、CPU核的寄存器值等),我们把这些信息称为运行时信息。同时,应用程序访问最频繁的指令和数据还会被缓存到L1、L2缓存上,以便提升执行速度。
但是,在多核CPU的场景下,一旦应用程序需要在一个新的CPU核上运行,那么,运行时信息就需要重新加载到新的CPU核上。而且,新的CPU核的L1、L2缓存也需要重新加载数据和指令,这会导致程序的运行时间增加。
如果在CPU多核场景下,Redis实例被频繁调度到不同CPU核上运行的话,那么,对Redis实例的请求处理时间影响就更大了。每调度一次,一些请求就会受到运行时信息、指令和数据重新加载过程的影响,这就会导致某些请求的延迟明显高于其他请求。分析到这里,我们就知道了刚刚的例子中99%尾延迟的值始终降不下来的原因。
所以,我们要避免Redis总是在不同CPU核上来回调度执行。于是,我们尝试着把Redis实例和CPU核绑定了,让一个Redis实例固定运行在一个CPU核上。我们可以使用taskset命令把一个程序绑定在一个核上运行。
比如说,我们执行下面的命令,就把Redis实例绑在了0号核上,其中,“-c”选项用于设置要绑定的核编号。
taskset -c 0 ./redis-server
CPU的NUMA架构对Redis性能的影响
那么,在CPU的NUMA架构下,当网络中断处理程序、Redis实例分别和CPU核绑定后,就会有一个潜在的风险:如果网络中断处理程序和Redis实例各自所绑的CPU核不在同一个CPU Socket上,那么,Redis实例读取网络数据时,就需要跨CPU Socket访问内存,这个过程会花费较多时间。
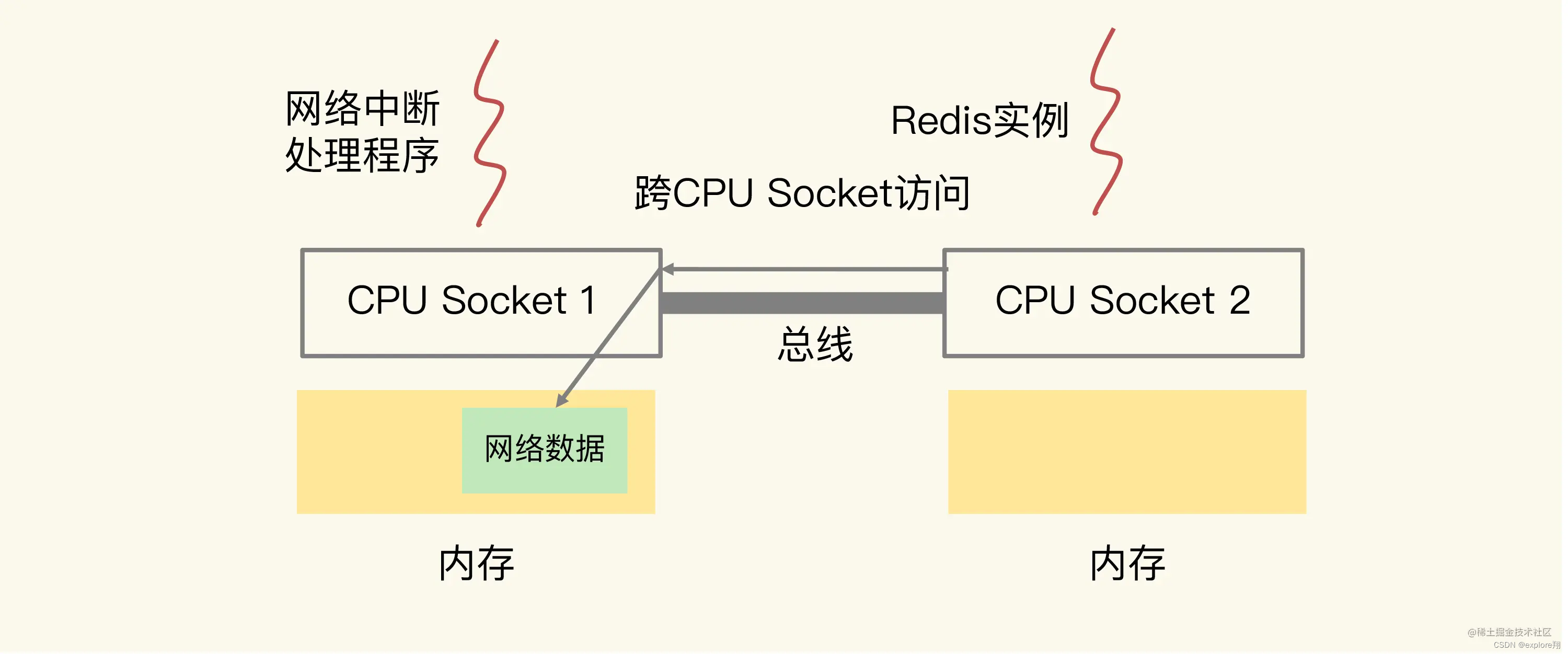
为了避免Redis跨CPU Socket访问网络数据,我们最好把网络中断程序和Redis实例绑在同一个CPU Socket上,这样一来,Redis实例就可以直接从本地内存读取网络数据了。不过,需要注意的是,在CPU的NUMA架构下,对CPU核的编号规则,并不是先把一个CPU Socket中的所有逻辑核编完,再对下一个CPU Socket中的逻辑核编码,而是先给每个CPU Socket中每个物理核的第一个逻辑核依次编号,再给每个CPU Socket中的物理核的第二个逻辑核依次编号。
Redis除了主线程以外,还有用于RDB生成和AOF重写的子进程。
当我们把Redis实例绑到一个CPU逻辑核上时,就会导致子进程、后台线程和Redis主线程竞争CPU资源,一旦子进程或后台线程占用CPU时,主线程就会被阻塞,导致Redis请求延迟增加。
虽然绑核可以帮助Redis降低请求执行时间,但是,除了主线程,Redis还有用于RDB和AOF重写的子进程,以及4.0版本之后提供的用于惰性删除的后台线程。当Redis实例和一个逻辑核绑定后,这些子进程和后台线程会和主线程竞争CPU资源,也会对Redis性能造成影响。所以,我给了你两个建议:
如果你不想修改Redis代码,可以把按一个Redis实例一个物理核方式进行绑定,这样,Redis的主线程、子进程和后台线程可以共享使用一个物理核上的两个逻辑核。(只能是缓解)
如果你很熟悉Redis的源码,就可以在源码中增加绑核操作,把子进程和后台线程绑到不同的核上,这样可以避免对主线程的CPU资源竞争。不过,如果你不熟悉Redis源码,也不用太担心,Redis 6.0出来后,可以支持CPU核绑定的配置操作了。
那么redis变慢因素的排查?
1**、获取Redis实例在当前环境下的基线性能。**
所谓的基线性能呢,也就是一个系统在低压力、无干扰下的基本性能,这个性能只由当前的软硬件配置决定。redis-cli命令提供了–intrinsic-latency选项,可以用来监测和统计测试期间内的最大延迟,这个延迟可以作为Redis的基线性能。
./redis-cli --intrinsic-latency 120
一般来说,你要**把运行时延迟和基线性能进行对比,如果你观察到的Redis运行时延迟是其基线性能的2倍及以上,就可以认定Redis变慢了。**比如虚拟机因为虚拟化软件层开销,基线性能差一点,10ms左右。
**是否用了慢查询命令?**如果是的话,就使用其他命令替代慢查询命令,或者把聚合计算命令放在客户端做。比如把smemebers换成sscan,多次返回避免阻塞。比如SORT、SUNION、SINTER聚合范围计算放在客户端。
slowlog get 10
是**否对过期key设置了相同的过期时间?**你要检查业务代码在使用EXPIREAT命令设置key过期时间时,是否使用了相同的UNIX时间戳。对于批量删除的key,可以在每个key的过期时间上加一个随机数,避免同时删除。
是否存在bigkey? 对于bigkey的删除操作,如果你的Redis是4.0及以上的版本,可以直接利用异步线程机制减少主线程阻塞;如果是Redis 4.0以前的版本,可以使用SCAN命令迭代删除;对于bigkey的集合查询和聚合操作,可以使用SCAN命令在客户端完成。
AOF 日志同步写(alaways);从库加载 RDB 是不能异步的,肯定阻塞。Redis AOF配置级别是什么?业务层面是否的确需要这一可靠性级别?如果我们需要高性能,同时也允许数据丢失,可以将配置项no-append fsync-on-rewrite设置为yes,避免AOF重写和fsync竞争磁盘IO资源,导致Redis延迟增加。当然, 如果既需要高性能又需要高可靠性,最好使用高速固态盘作为AOF日志的写入盘。
**Redis实例的内存使用是否过大?****发生swap了吗?**如果是的话,就增加机器内存,或者是使用Redis集群,分摊单机Redis的键值对数量和内存压力。同时,要避免出现Redis和其他内存需求大的应用共享机器的情况。
$ redis-cli info | grep process_id查看进程号, $ cd /proc/5332 $cat smaps | egrep ‘^(Swap|Size)’ 当出现百MB,甚至GB级别的swap大小时,就表明,此时,Redis实例的内存压力很大,很有可能会变慢。
**在Redis实例的运行环境中,是否启用了透明大页机制?**如果是的话,直接关闭内存大页机制就行了。Linux内核从2.6.38开始支持内存大页机制,该机制支持2MB大小的内存页分配,而常规的内存页分配是按4KB的粒度来执行的。
虽然内存大页可以给Redis带来内存分配方面的收益,但是,不要忘了,Redis为了提供数据可靠性保证,需要将数据做持久化保存。这个写入过程由额外的线程执行,所以,此时,Redis主线程仍然可以接收客户端写请求。客户端的写请求可能会修改正在进行持久化的数据。在这一过程中,Redis就会采用写时复制机制,也就是说,一旦有数据要被修改,Redis并不会直接修改内存中的数据,而是将这些数据拷贝一份,然后再进行修改。
如果采用了内存大页,那么,即使客户端请求只修改100B的数据,Redis也需要拷贝2MB的大页。相反,如果是常规内存页机制,只用拷贝4KB
是否运行了Redis主从集群?如果是的话,把主库实例的数据量大小控制在2~4GB,以免主从复制时,从库因加载大的RDB文件而阻塞。
是否使用了多核CPU或NUMA架构的机器运行Redis实例?使用多核CPU时,可以给Redis实例绑定物理核;使用NUMA架构时,注意把Redis实例和网络中断处理程序运行在同一个CPU Socket上。