目录
1. 虚机的安装与配置
1.1 安装parallels
1.2 安装fedora系统
1.3 fedora的配置
1.3.1 内存和硬盘配置
1.3.2 网络配置
1.3.3 共享文件夹
1.4 虚拟机克隆 与 加载
2. 免密登录
2.1 分别查看master, slave01,slave02 的ip
2.2 查看各虚机的hostname
编辑
编辑
2.3 设置DNS,在3太机器的“/etc/hosts”文件中,均加入以下内容
2.4 ssh服务设置
3. Jdk 和 hadoop的安装和配置
4. hadoop集群验证
5. 参考链接
6. 可能出现的一些问题
6.1 jps comment not found
6.2 防火墙问题
6.2.1 fedora34 开启http server发现无法访问,需要关闭防火墙
6.2.2 hadoop fs -put 出错
6.3 Hadoop yarn nodemanager启动提示 Retrying connect to server: 0.0.0.0/0.0.0.0:8031.
6.3 虚拟内存不够
6.4 程序有问题
6.5 其它定位问题的方法:
1. 虚机的安装与配置
1.1 安装parallels
从官网下载parallels,安装。
关于parallels的一些设置,可以右键Dock栏的Parallels Desktop图标,选择偏好设置查看。
Parallels 的试用期是14天,怎样永久使用呢?
命令行开启虚拟机:prlctl start 'master'
命令行重启虚拟机:prlctl restart 'slave01'
参考链接:https://www.youtube.com/watch?v=ZsqlVbR5aBw
1.2 安装fedora系统
打开parallels,直接在引导页面下载 fedora系统(该系统下载时间会比较长)
1.3 fedora的配置
安装好fedora系统后,右键Dock栏的Parallels Desktop图标,点击“控制中心”,可以看到刚才下载的fedora系统。
点击fedora虚机,进行配置(注意:关机后,才可以更改虚拟机的各种配置)
1.3.1 内存和硬盘配置
虚拟机的内存和硬盘默认即可,后续可以随时动态调整
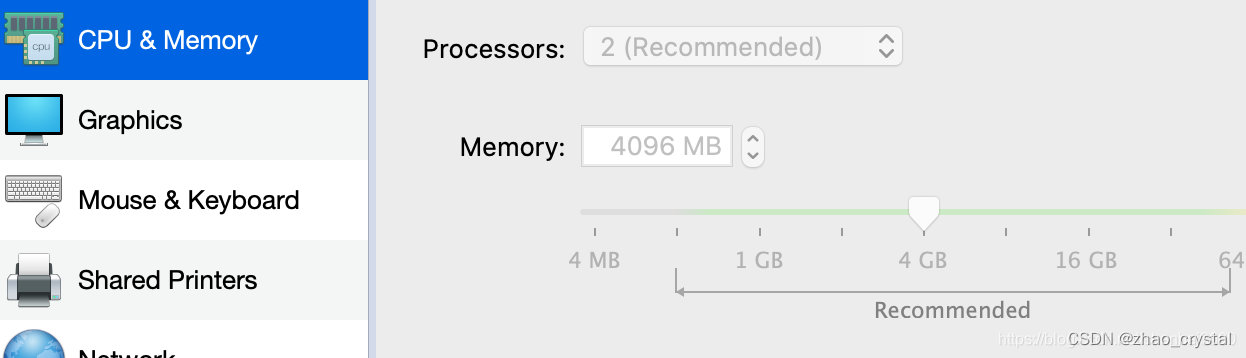
1.3.2 网络配置
网络选择默认的Shared Network
1.3.3 共享文件夹
开启文件夹共享(但仍需要配合Paralles Tools才能实现真正的文件夹共享)
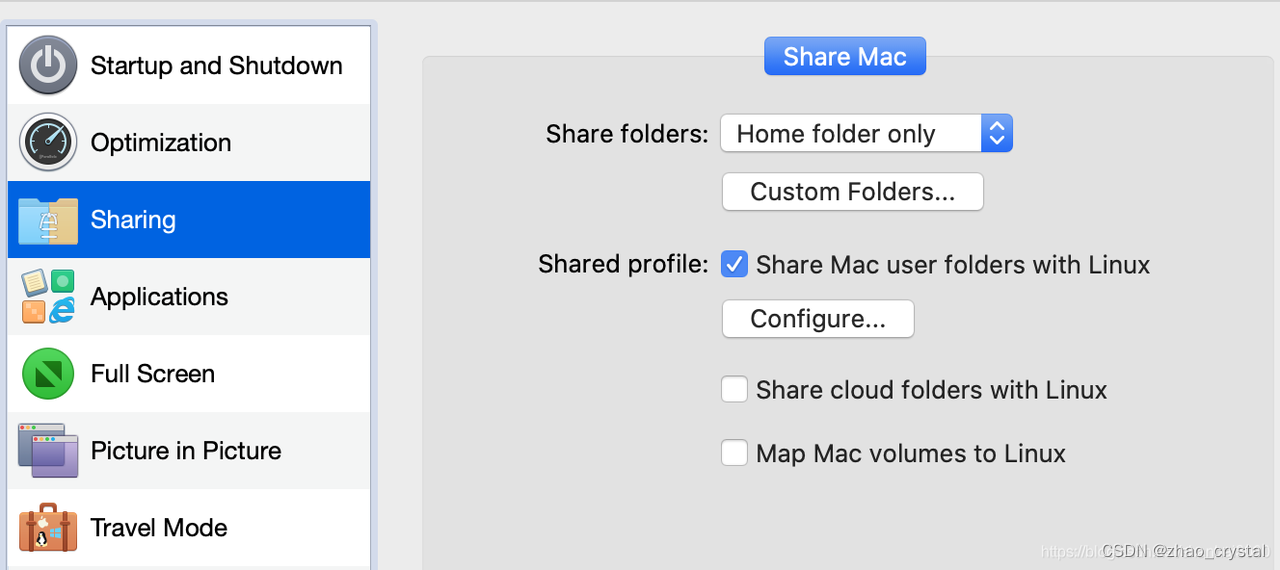
此时,/media/psf/Home 下面就可以看到宿主机的文件了
1.4 虚拟机克隆 与 加载
参考链接:克隆虚拟机
(1) 在控制中心内,选择要克隆的虚拟机(必须处于关闭状态),然后依次选择 文件> 克隆
(2) 选择所需的克隆虚拟机存储位置。
默认情况下,Parallels Desktop 会将克隆的虚拟机存储在“文档”>“Parallels”文件夹中。
(3) 点击 保存 以开始克隆虚拟机。
加载刚刚保存的虚拟机
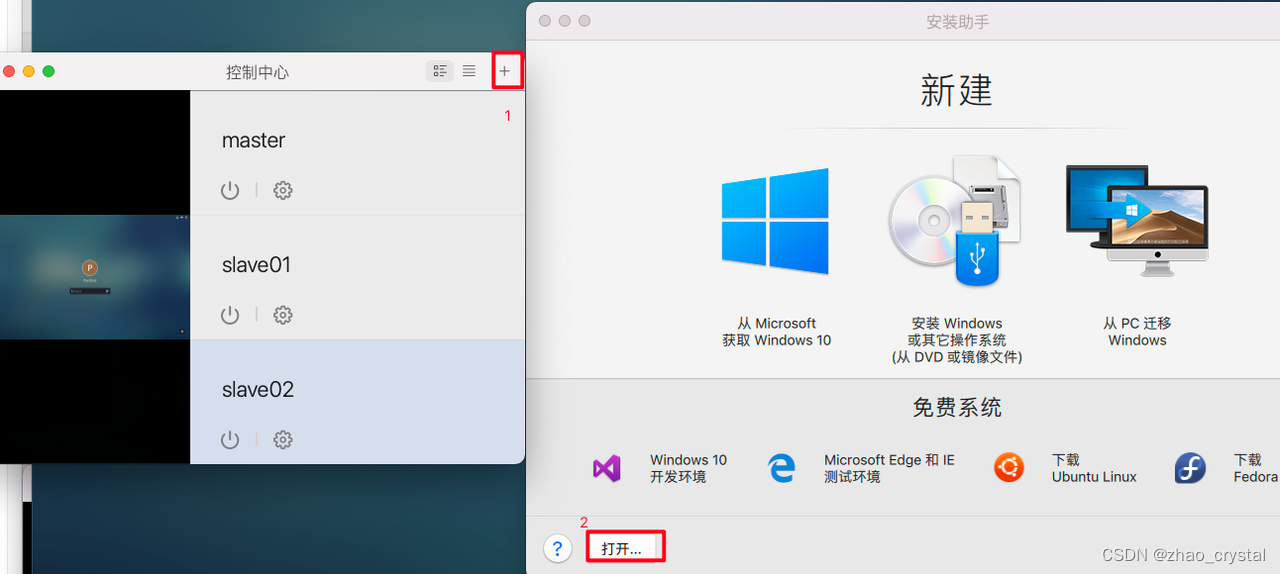
我构建的是一个master,两个slave。(master,slave是我自己修改的名字,可以在配置里修改)
2. 免密登录
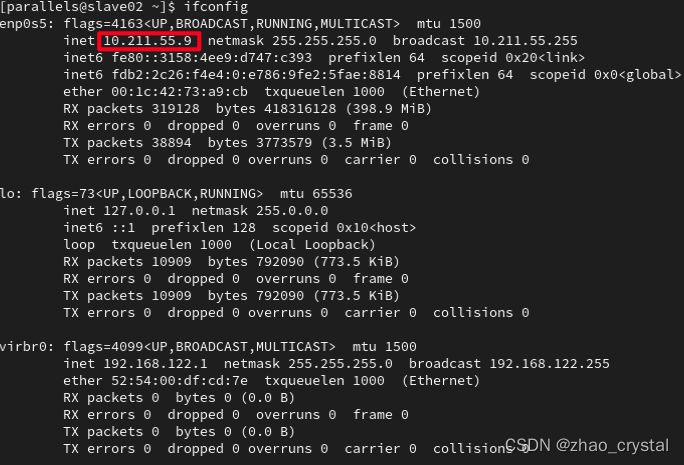
2.1 分别查看master, slave01,slave02 的ip
Ifconfig
注:如果master,slave01,slave02 的ip是一样的,要重新修改一下ip
master
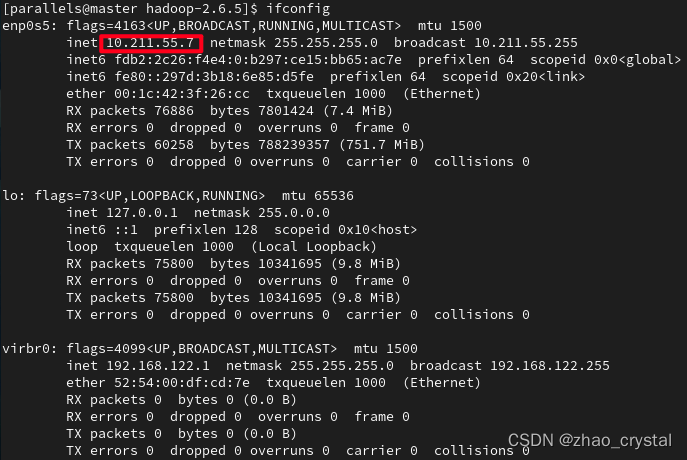
slave01
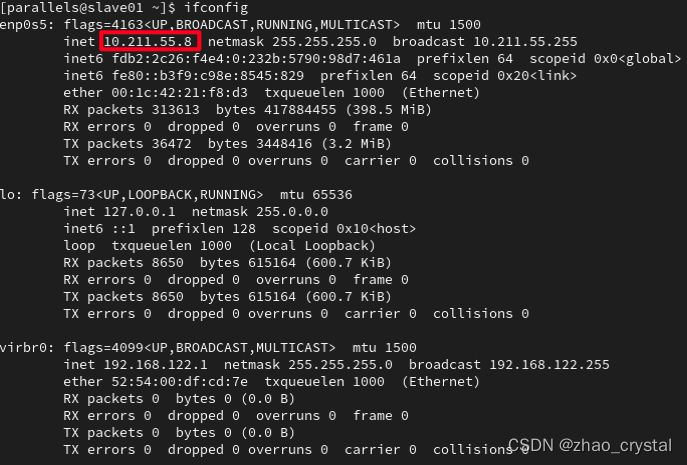
slave02
2.2 查看各虚机的hostname



- 修改hostname的方法
如果hostname显示有误,以为master机器为例,可以通过
Vi ~/.bashrc 添加 hostname master
在vim中,保存退出,执行bash,观察当前机器的hostname已经修改。
2.3 设置DNS,在3太机器的“/etc/hosts”文件中,均加入以下内容
10.21.55.7 master
10.21.55.8 slave01
10.21.55.9 slave02

slave01 和 slave02 同样操作
2.4 ssh服务设置
ssh服务开启,参考链接:https://blog.csdn.net/rs_network/article/details/8043109
A.确认是否已安装ssh服务
]# rpm -qa | grep openssh-server
openssh-server-5.3p1-19.fc12.i686 (这行表示已安装)
若未安装ssh服务,可输入:
#yum install openssh-server
B. 启动SSH服务
# systemctl start sshd.service
或者 #service sshd start
也可以用 restart 和 stop控制sshd服务
C. 设置系统启动时开启服务
# systemctl enable sshd.service
D. 同样也需开启防火墙22端口
#iptables -A INPUT -p tcp --dport 22 -j ACCEPT
也可以将上述参数加入防火墙配置中:
#vi /etc/sysconfig/iptables
加入:-A INPUT -m state --state NEW -m tcp -p tcp --dport 22 -j ACCEPT
保存后重启iptables即可
在master,slave01 和 slave02 机器上,均进行如下操作即可
2.5 ssh免密登录设置
以master为例,执行 “ssh-keygen”命令,一路回车,得到

然后,通过ssh-copy-id的方式进行免密配置
ssh-copy-id ~/.ssh/id_rsa.pub master
ssh-copy-id ~/.ssh/id_rsa.pub slave01
ssh-copy-id ~/.ssh/id_rsa.pub slave02
在slave01,slave02 机器上重复如上操作
在master机器上验证:
ssh slave01

3. Jdk 和 hadoop的安装和配置
(1) 将hadoop,java安装包,放到共享目录下,拷贝到master机器上,然后再将安装包同步到slave01 和 slave02 上,保证这三个机器安装的内容是一致的。故仍以master为例
Sudo cp /media/psf/Home/hadoop-2.6.5.tar.gz /usr/local/src/
Sudo cp /media/psf/Home/jdk-8u172-linux-x64.tar.gz /usr/local/src/
将hadoop 和 java 拷贝到机器slave01上
Sudo scp -rp /usr/local/src/hadoop-2.6.5.tar.gz parallels@slave01:~/
Sudo cp ~/hadoop-2.6.5.tar.gz /usr/local/src/
Sudo scp -rp /usr/local/src/jdk-8u172-linux-x64.tar.gz parallels@slave01:~/
Sudo cp ~/jdk-8u172-linux-x64.tar.gz /usr/local/src/
同理,将hadoop 和 java 拷贝到机器slave02上
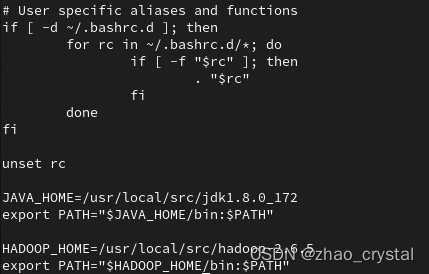
(2)安装java和hadoop,以master为例,slave01 和 slave02 参考master的方法

~/.bashrc 文件如下所示
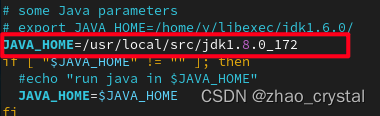
(3)在"/usr/local/src/hadoop-2.6.5/etc/hadoop"目录中,开始hadoop的一系列配置
hadoop-env.sh 配置JAVA_HOME

yarn-env.sh 配置JAVA_HOME
修改slaves文件,里面写从节点hostname

core-site.xml 配置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop-2.6.5/tmp</value>
</property>
</configuration>
mapred-site.xml 配置
cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml 配置
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>5</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.adderess</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
hdfs-site.xml 配置
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/hadoop-2.6.5/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/usr/local/src/hadoop-2.6.5/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
在HADOOP_HOME(/usr/local/src/hadoop-2.6.5)下,创建3个空目录
mkdir tmp
mkdir -p dfs/name
mkdir -p dfs/data
配置已全部配好,然后将所有配置,同步到slave01,slave02(可以使用scp)
4. hadoop集群验证
进行hdfs集群格式化,中间会提示Y or N,这里直接Y回车就好
cd /usr/local/src/hadoop-2.6.5/bin
./hdfs namenode -format
启动集群
cd /usr/local/src/hadoop-2.6.5
./sbin/start-all.sh
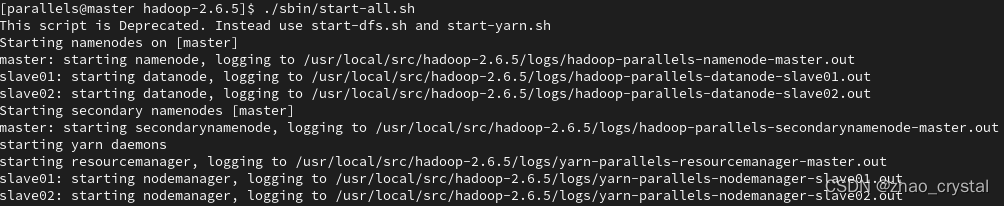
在master上观察进程
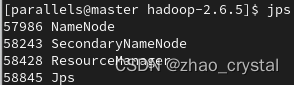
在slave01上观察进行
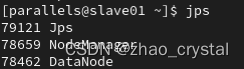
同理,在slave02上观察进程
关闭集群
cd /usr/local/src/hadoop-2.6.5
./sbin/stop-all.sh
5. 参考链接
(1)https://zhuanlan.zhihu.com/p/507297549
(2)使用Paralles Desktop,在虚拟机环境中搭建hadoop集群(2主3从5节点)_山海王子的博客-CSDN博客_hadoop 二主三从
(3)http://www.sunnyos.com/article-show-78.html
6. 可能出现的一些问题
6.1 jps comment not found
(1) 查看是否安装java
java -version
若安装,则会看到java版本;若未安装,则安装
(2)若安装java,在~/.bash_profile 中加入jdk路径。
export PATH=$PATH:/usr/local/java/jdk1.8.0_172/bin/
source ~/.bash_profile
参考博客:解决jps command not found
6.2 防火墙问题
6.2.1 fedora34 开启http server发现无法访问,需要关闭防火墙
fedora34 关闭防火墙
临时停止防火墙
$ sudo systemctl stop firewalld
永久禁止防火墙
$ sudo systemctl disable firewalld
查看防火墙状态
$ systemctl status firewalld
参考链接:https://insidelinuxdev.net/article/a0bf3j.html
6.2.2 hadoop fs -put 出错
在master机器上执行 hadoop fs -put 出现如下错误
“put:call from master/192.168.44.128 to master:9000 failed on connection exception:java.net connect Exception 拒绝链接”
错误信息里面还给了一个链接 ConnectionRefused - HADOOP2 - Apache Software Foundation
在slave机器上执行hadoop fs -put 出现如下错误
“put:No route to host from slave/192.168.44.129 to master:9000 failed on socket timeout exception:java.net. NoRouteToHostException 没有到主机的路由”
错误信息里也给了一个链接NoRouteToHost - HADOOP2 - Apache Software Foundation
解决方法
关闭防火墙,重启。
Centos 7 关闭防火墙
-
开启命令: systemctl start firewalld.
-
临时关闭命令: systemctl stop firewalld.
-
永久关闭命令: systemctl disable firewalld.
也可试着使用 service iptables stop/start 关闭/打开防火墙
6.3 Hadoop yarn nodemanager启动提示 Retrying connect to server: 0.0.0.0/0.0.0.0:8031.
https://blog.csdn.net/cl723401/article/details/82949139
原因,是因为 nodemanager 找不到 resourcemanager
在yarn-site.xml中添加
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
6.3 虚拟内存不够

参考链接
https://blog.csdn.net/ztx22555/article/details/125918895
关于Hadoop集群物理及虚拟内存的检测的设置说明_7&的博客-CSDN博客
6.4 程序有问题
Error: java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 1
Running a job using hadoop streaming and mrjob: PipeMapRed.waitOutputThreads(): subprocess failed wi
https://stackoverflow.com/questions/17037300/running-a-job-using-hadoop-streaming-and-mrjob-pipemapred-waitoutputthreads
6.5 其它定位问题的方法:
(1)注意看log
(2)根据log,看可能有哪些问题。比如 log中显示slave 找不到resourcemanager,而resourcemanager是在master上的一个服务,所以,就需要查看,master上相应的服务是否开启等。
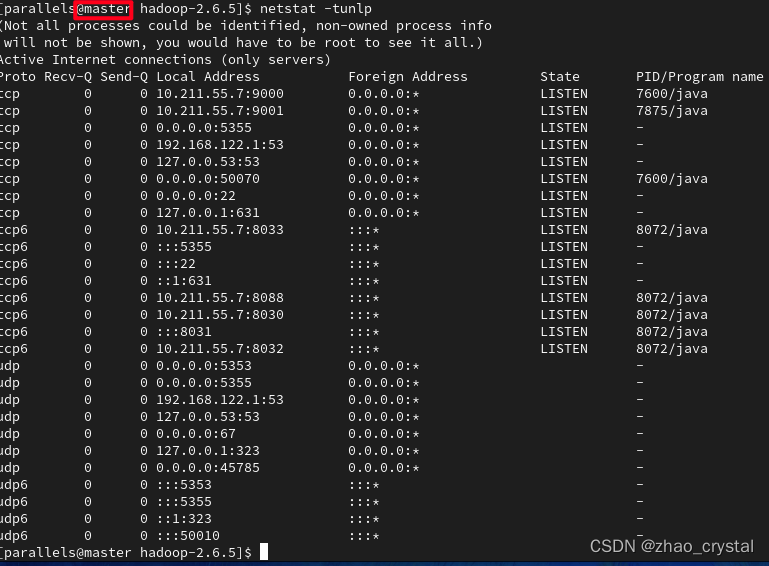
比如可以使用netstat 查看一下网络的状态,具体用法详见:Linux netstat命令 | 菜鸟教程
使用 netstat -tunlp 得到如下结果