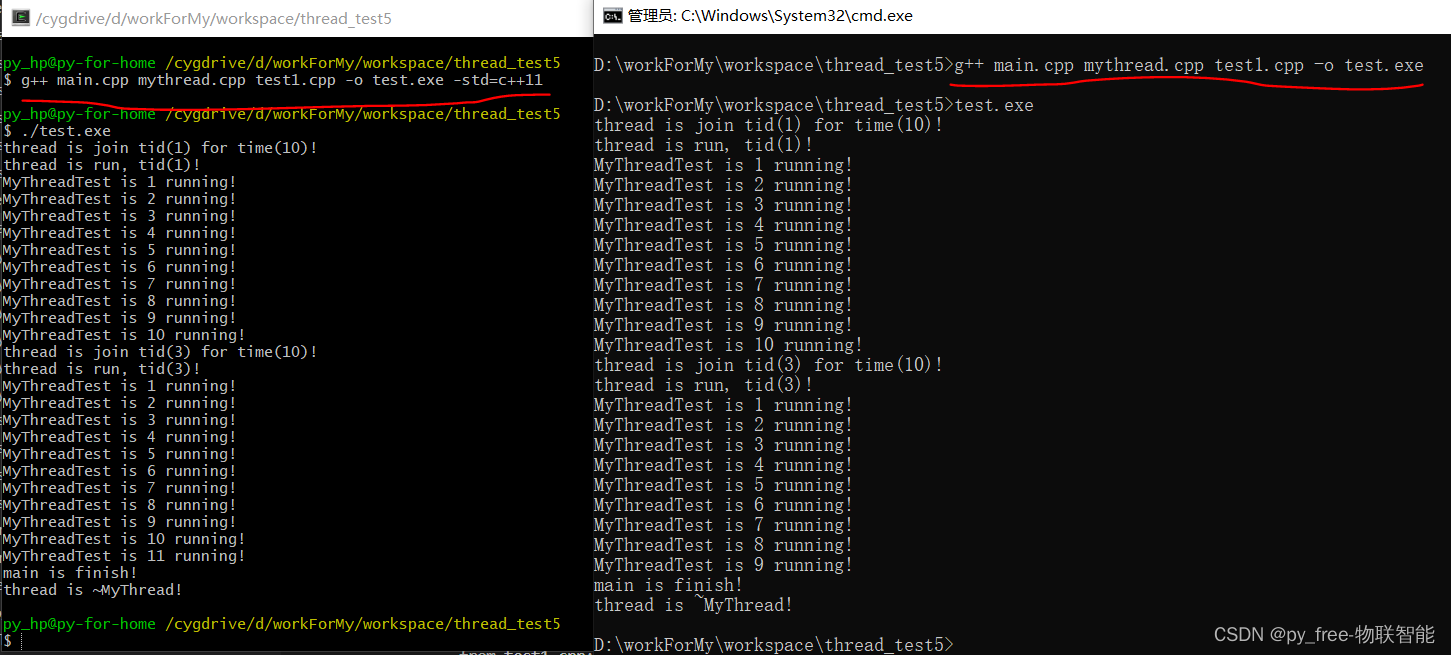
📚回顾C++
🐇struct和class
- 从功能上说,struct和class几乎没什么区别
- 在不显式声明的情况下,struct成员默认为public,class默认为private
- 和c语言的struct不同,c++的struct可以定义成员函数,重载运算符等操作
- 在编写竞赛代码时,我们不需要考虑成员的访问权限,全部使用public就可以解决问题。因此通常使用struct更方便,若使用class还需要手动标注public成员
🐇引用
- 一个变量的引用相当于给它起了别名
int a; int &b = a;//如果改变b,a也会变化,反之亦然 - 函数传参时使用引用可以避免拷贝,相当于直接操作实参
void swap(int &a,int &b) {//如果不写&,那完成这个函数之后,在主函数中,a和b并没有发生改变 int tmp = a; a = b; b = tmp; } void parse(string &s) {//直接传引用,避免拷贝影响性能 //... }
🐇运算符重载
-
可以让自定义的结构体像基本类型一样通过运算符计算
-
如果不用运算符重载,那么需要定义一个函数才能完成计算
struct Point { int x,y; Point(int X = 0,int Y = 0):x(X),y(Y){} Point add(const Point &p)const { return Point(x+p.x,y+p.y); } }; //这时如果在之后需要在主函数中实现加法,那就有p = p.add(q)类似这样的语句 -
把函数名换成operator+即可完成加法运算重载
struct Point { int x,y; Point(int X = 0,int Y = 0):x(X),y(Y){} Point operator + (const Point &p)const {//这里的const建议写上,有的编译器不写会报错 return Point(x+p.x,y+p.y); } }; int main() { Point a(1,2),b(3,4); Point c = a + b; }
🐇template
- 模板的作用是,写一份代码可以适用于多种类型,减少代码冗余
int min_int(int a, int b) { if(a<b) return a; else return b; } double min_double(double a, double b) { if(a<b) return a; else return b; } //上边两个函数几乎完全相同,只是参数类型和返回值类型不同 template<class T> T min(T a,T b) { if(a<b) return a; else return b; } //用模板参数T替代实际类型,使用时再实例化为实际的类型 - 实际上,在吃薯片时,我们不需要手动编写模板,主要做到熟练运用C++自带的模板即可
- 模板函数的调用
int a = 10, b = 15; int c = max(a,b); //在调用模板函数时,编译器会根据传入参数类型自动判断模板参数类型 - 模板类:
map<int, string>mp;,需要在类名后面写一个尖括号,里面是模板参数。
🐇万能头文件
- 包含了c++标准库的所有头文件
#include<bits/stdc++.h> using namespace std;
🐇pair
- pair是一个结构体,包含两个成员,分别是first和second。两个模板参数分别标注两个成员的类型
pair<string, int> p; - 相当于
struct s { string first; int second; }p; - pair重载了< == >等运算符,先比较第一个成员,若第一个成员相同再比较第二个
pair<int,string>p1(2,"aab"),p2(3,"aaa"),p3(2,"aaa"); p1 < p2;//true p1 < p3;//false - 可以使用
make_pair()或大括号得到一个pairpair<int, int>a,b; a = make_pair(3,5); b = {3,5};
🐇tuple
- 如果成员不止两个,可以使用pair嵌套,也可以使用tuple,它也重载了各种比较方法
pair<int, pair<double,string>>p;//pair嵌套 tuple<int, double, string>q;//三个成员的tuple //tuple允许更多成员 - 使用
get<N>来访问从0数第N个元素,N必须是常量p.second.first; get<2>q;//访问q的第二个成员
📚算法
algorithm中提供了许多常用算法
🐇sort
- 时间复杂度 O ( n l o g n ) O(nlogn) O(nlogn) 实现对指定区间进行排序
- 基础用法

- 排序方式:默认排序方式是升序排序,如果想进行降序排序或者自定义排序,可以修改第三个参数
- 第三个参数接受一个函数,这个函数要求传入两个元素,如果第一个应该排在第二个前面,则返回true,否则返回false
- 以下操作完成对整数的降序排序
bool cmp(int a, int b) { return a > b; } int a[9] = {1,9,2,8,3,7,4,6,5}; sort(a, a+9, cmp); //a:{9,8,7,6,5,4,3,2,1} - c++本身提供了一个模板,
greater<T>,它重载的小括号运算符也可以实现以上功能sort(a,a+9,greater<int>()); - sort的第三个参数默认为less(),相当于自动调用小于号进行比较,进行升序排序
- 如果对结构体进行排序,可以传入比较函数,也可以重载结构体的小于号,这样sort会自动根据小于号进行比较
struct s { int a,b,c; bool operator < (const s &x) const { //先按照a比较 if(a < x,a) return true; if(a > x.a) return false; //若a相同再按照b比较 if(b > x.b) return true; if(b < x.b) return false; //若ab均相同按照c比较 return c < x.c; } }; s arr[10]; /*进行赋值*/ sort(arr,arr + 10);//自动调用小于运算符,按照指定规则排序
- sort可以对容器使用,但要求容器支持随机取址
- Lambda在sort函数上的应用
/* 传统的排序 */ bool cmp(int a, int b){return a<b;} int a[]={1,5,3,2}; sort(a, a+4, cmp); /* 引入Lambda,写匿名函数*/ sort(a, a+4,[](int a,int b)->bool{return a<b;}); // Lambda 支持的结构体多关键字排序 struct P { int a,b,c;}Ps[10]; sort(Ps, Ps+10, [](P &p1, P &p2)->bool{ if(p1.a != p2.a) return p1.a<p2.a; if(p1.b l= p2.b) return p1.b>p2.b; return p1.c < p2.c; });
🐇二分相关
lower_bound和upper_bound,传入一个区间(第一个位置和最后一个元素的下一个位置)和一个值,假定最后一个元素的下一个位置是无穷大lower_bound可以在指定区间内查找大于或等于给定值的第一个位置upper_bound可以在指定区间内查找大于给定值的第一个位置int a[10] = {1,2,3,4,5,5,5,6,7,8}; int lb = lower_bound(a, a + 10, 5) - a;//4 int ub = upper_bound(a, a + 10, 5) - a;//7
- 复杂度 O ( l o g n ) O(logn) O(logn)
🐇去重
- unique 用于去重,对于连续的相同元素,只保留一个
- 由于去重后元素数量会变少,unique函数会返回去重后新的区间结束位置
int a[10] = {1,1,2,3,3,5,3,3,4,1}; unique(a, a + 10);//返回a+7,a到a+7区间内变成1,2,3,5,3,4,1 - 这个函数经常配合sort使用,因为sort会让区间内相同的元素放在一起
- 复杂度 O ( n ) O(n) O(n)
🐇全排列
reverse:传入一个区间(左闭右开),对区间内元素进行翻转,复杂度 O ( n ) O(n) O(n)min_element/max_element:返回区间内最小/最大值,复杂度 O ( n ) O(n) O(n)next_permutation: 生成指定区间的下一个排列,若不存在下一个排列则返回false#include<bits/stdc++.h> using namespace std; const int n = 4; int a[n]; int main() { for(int i = 0; i < n; i ++) { a[i] = i; } do{ for(int i = 0;i < n;i++) { cout << a[i] << ' '; } cout << '\n'; }while(next_permutation(a,a + n)); return 0; }0,1,2,3的下一个排列是0,1,3,2,再下一个是0,2,1,3,以此类推
📚顺序容器
🐇vector
- vector 是不定长数组容器。其数组长度的扩增策略是每次乘 2,所以倘若数组长度下界较为确定的话,声明 vector 时传入初始大小是比较明智的。
- 对于容器类,较为关注的是它的声明、赋值、遍历、清空操作及相应复杂度

- 迭代器:其实类似一个指针,只不过指针指向的是一个物理地址,而迭代器,是一个虚拟的结构,指向的数据结构中的一个位置。可以通过迭代器访问它所指的内容,也可以根据迭代器访问数据结构中相邻的内容,这一点类似指针的++,–,[]操作
-
begin和end分别返回指向vector 第一个元素的迭代器和指向最后一个元素的下一个位置的迭代器,类型为vector<T>::iteratorsort(a.begin(),a.end()); sort(a.begin() + 1,a.end());//忽略第0个元素,对其他进行排序 -
可以使用下标遍历,也可以使用迭代器遍历
for(int i = 0;i < a.size();i++) { //a[i]为访问的元素 } for(vector<int>::iterator i = a.begin();i != a.end();i++) { //*i即为我们要访问的元素 } for(int &i: a) {//int可以替换为auto //i本身就是要访问元素的引用 }//c++11的range for 写法
-
- 插入删除
- 在某个迭代器前面插入一个元素
vector<int> a = {1,3,5,7,9}; a.insert(a.begin() + 2, 0);//a = {1,3,0,5,7,9} - 删除某个迭代器所指的元素
vector<int> a = {1,3,5,7,9}; a.erase(a.begin() + 2);//a = {1,3,7,9} - 删除一个区间(左闭右开)
vector<int> a = {1,2,3,4,5,6,7,8,9}; a.erase(a.begin() + 1,a.begin() +4);//a = {1,5,6,7,8,9}
- 在某个迭代器前面插入一个元素
- 一切会让vector长度增加的操作,都有可能让之前的迭代器失效
| 插入 | 删除 | 访问 |
|---|---|---|
| push_back: O ( 1 ) O(1) O(1) | pop_back : O ( 1 ) O(1) O(1) | O ( 1 ) O(1) O(1) |
| insert: O ( n ) O(n) O(n) | erase: O ( n ) O(n) O(n) |
deque与vector类似,它支持vector的所有函数(包括下标访问),并且实现了O(1)复杂度的前端插入与删除。虽说在功能上可以替代vector,但是对比效率还是vector更优秀一些。
//声明
deque<int>d(10);
//赋值
d.push_front(13);//添加至末尾
d.push_back(25);//添加至末尾
d[0] = 64;
//删除
d.pop_front();//删除首个元素
d.pop_back();//删除尾部元素
🐇list
- list是链表容器,将数组换作链表使用
list<int> l1; l1.push_back(1);//末尾增加一个元素 l1.push_front(1);//最前面插入一个元素 l1.pop_front();//删除第一个元素 l1.pop_back();//删除最后一个元素 //均为O(1)时间复杂度 list<int>::iterator it = l1.begin(); it ++;//迭代器移动 l1.insert(it,1);//在it之前插入一个元素 it = l1.erase(it);//删除it所在位置的元素,返回被删除元素的下一个元素的迭代器,原先选代器由于指向位置被删除而失效 //均为O(1)时间复杂度 l1.clear();//删除所有元素,时间复杂度为O(n) l1.sort();对l1的内容进行升序排序l1.unique();对l1的内容进行相邻去重- 既然有sort函数,为什么list又提供一个sort成员函数❓sort函数要求随机访问迭代器,而list提供双向迭代器。sort 函数用到的迭代器的操作链表是不可能做到的,故 list 需要设计自己的 sort 函数。
- list可以用迭代器或者range for进行遍历
for(auto i = l1.begin(); i != l1.end(); i++) { cout<< *i <<' '; } for(auto &i: l1) { cout<< i <<' '; }
| 插入 | 删除 | 访问 |
|---|---|---|
| push_front: O ( 1 ) O(1) O(1) | pop_front: O ( 1 ) O(1) O(1) | O ( n ) O(n) O(n) |
| push_back: O ( 1 ) O(1) O(1) | pop_back : O ( 1 ) O(1) O(1) | |
| insert: O ( 1 ) O(1) O(1) | erase: O ( 1 ) O(1) O(1) |
🐇string
在C语言中,字符串就是字符数组,使用起来处处受限,C++提供了#include <string>中的string类型,重载了很多运算符,使程序更加自然,简单。
string s1 = "123";
string s2;
cin >> s2;
cout << s1 << '\n';//可以使用 cin和 cout 输入和输出 string
cout << s1.size() << '\n';
string s3 = "abc";
s1 += s3;//s1="123abc"
s1 += 'x';//s1="123abcx"
cout << s1 << '\n';
s2 = s1 + s3;//s2="123abcxabc"
s.substr(2,3);//取下标从2开始,长度为3的字串
s.push_back('1');//在末尾添加一个字符
s.c_str();//返回一个常量字符数组的指针
📚关联容器
🐇set
- set可以维护一个集合,可以增加元素,删除元素,查找元素,同时保证元素唯一性,时间复杂度
O
(
l
o
g
n
)
O(logn)
O(logn)
set<int> s;//定义一个set,里面装整数。一开始是空集。 s.insert(3);//s中插入3 s.insert(3);// s中又插入3,但没有实际效果,因为本来就有了 s.erase(3);//删除s中的3,现在s又是一个空集了 s.erase(4);//删除s中的4。但没有实际效果,因为s中本来就没有4 - 查找操作将返回一个迭代器,若找到则返回的迭代器指着这个元素,找不到则返回end()
set<int> s = {1,2,3,4,5,7,8}; auto itl = s.find(4),it2 = s.find(6);//这里的auto可以改成set<int>::iterator if(itl == s.end()) cout << "4 is not found\n"; if(it2 == s.end()) cout << "6 is not found\n"; - 可以使用
count函数判断一个元素是否存在set<int> s = {1,2,3}; cout << s.count(1)<< '\n';// 1 cout << s.count(4)<< '\n';// 0 - 遍历
set<int> s = {1,2,3,4,5,6,7,8,9}; for(auto i= s.begin();i != s.end);i++) { cout<< *i <<' '; } cout << '\n'; for(const int &i: s) { //const int可以改成auto cout << i<<' '; }
🐇map
概念:<key, value> 键值对。给一个 key,可以得到唯一 value。
/*声明*/
map<int,bool>mp;
/* 赋值*/
mp[13]=true;
/*查key是否有对应value*/
if(mp[13]) printf("visited");//这里可以直接如此,而如果value类型非bool时需换成以下这种
if(mp.find(13) != mp.end()) printf("visited");
if(mp.count(13)) printf("visited");
/* 遍历 */
for(map<int,int>::iterator it=mp.begin();it != mp.end();it++)
printf("%d %d\n",it->first,it->second);//输出是升序的
for(map<int,int>::reverse_iterator it=mp.rbegin();it != mp.rend();it++)
printf("%d %d\n",it->first,it->second);//输出是降序的
/* 遍历(C++11 特性)*/
for(auto &entry : mp) printf("%d %d\n", entry.first,entry.second);// for range
/*清空*/
mp.erase(13);//以键为关键字删除某该键-值对,复杂度是logn
mp.clear();
/* 常量map声明,而不是声明一个空的map随后在main中赋值*/
const map<char,char>mp({
{'R','P'},
{'P','S'},
{'S','R'}
});
/*结构体使用map需要重写比较方法(map元素存储是有序的,自定义类型要告诉C++如何比较)*/
struct Point
{
int x,y;
bool operator<(const Point &p)const
{
return x != p.x ? x<p.x : y<p.y;
}
};
int main()
{
map<Point,bool>mp;
printf("%d\n",mp[{1,5}]);
mp[{1,5}]= true;
printf("%d\n",mp[{1,5}]);
return 0;
}
🐇multimap/multiset
一般来讲,set中的元素是互不相同的,即使插入相同的元素,也只保留一个。map的key值也是同理。如果要实现在set中存储多个相同元素,就需要用到multiset
/* 声明 */
multiset<int>s;
/* 赋值 */
s.insert(9); s.insert(4);
s.insert(6); s.insert(4);
//set中有4个元素
/* 查找*/
cout << *s.find(4) << end1;//输出4
cout << *s.count(4) << endl;//输出2
s.erase(s.find(4));//删除一个4
s.erase(5);//删除所有的5
/* 声明*/
multimap<int,int>m;
/* 赋值*/
m.emplace(1,3);
m.emplace(1,4);
//插入两个键值对,其中键相同
/* 查找*/
cout << *m.count(1);//输出2
cout << m.find(1)->first << ' ' << m.find(1)->second;//输出1 3,实际上可能会输出任意一个键值对
m.erase(s.find(1));//删除一个1
m.erase(1);//删除所有的1
既然有find函数,为什么set和map又提供find成员函数❓
- find 函数的确有很好的通用性,但是也有很大的缺点,就是算法的效率不高,算法的复杂度为 O ( n ) O(n) O(n)。
- 当数据量是百万或者千万级的时候,std::find的 O ( n ) O(n) O(n)算法就无法正常应对了,这时候用到了set 和 map 的find 成员函数,map 和 set 中的 find 算法是用红黑树来实现的。算法复杂度为 O ( l o g n ) O(logn) O(logn)。
📚容器适配器
什么是容器适配器?
- 封装了序列容器的类模板
- 顺序容器提供的方法过多、或过于基础,因此需要“适配”。
- 容器适配器不支持迭代器。
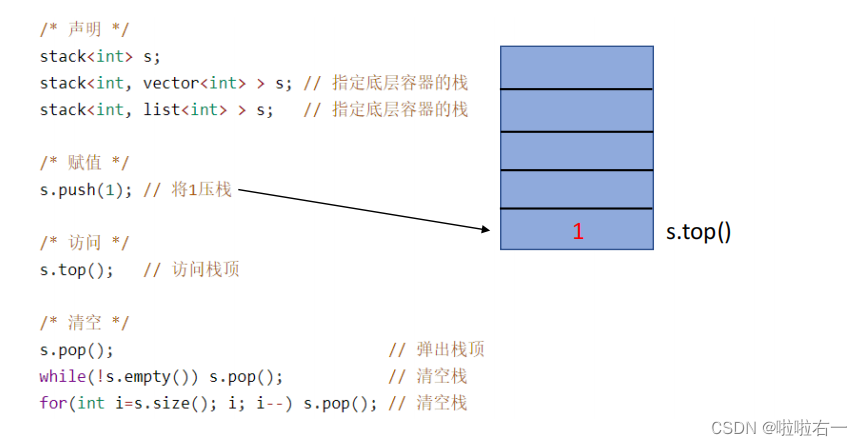
🐇stack
栈,先进后出,后进先出的数据结构
🐇queue & priority_queue
队列,先进先出;优先队列,又称为“堆”

priority_queue默认自动构建大根堆- 优先队列怎么知道元素的大小判断方法?刚刚的例子因为使用了基本的数据类型,它们自带天然的大小判断方法。如果我们自己实现的复杂数据结构,则需要重写比较方法!

最后输出的是2,虽然按照运算符重载看似应该是{1,3,4}在最上边,但是堆构建的时候,默认是大根堆,所以最后实际上还是{2,2,3}在top。
结构体重载为什么只需要重载一个<号?

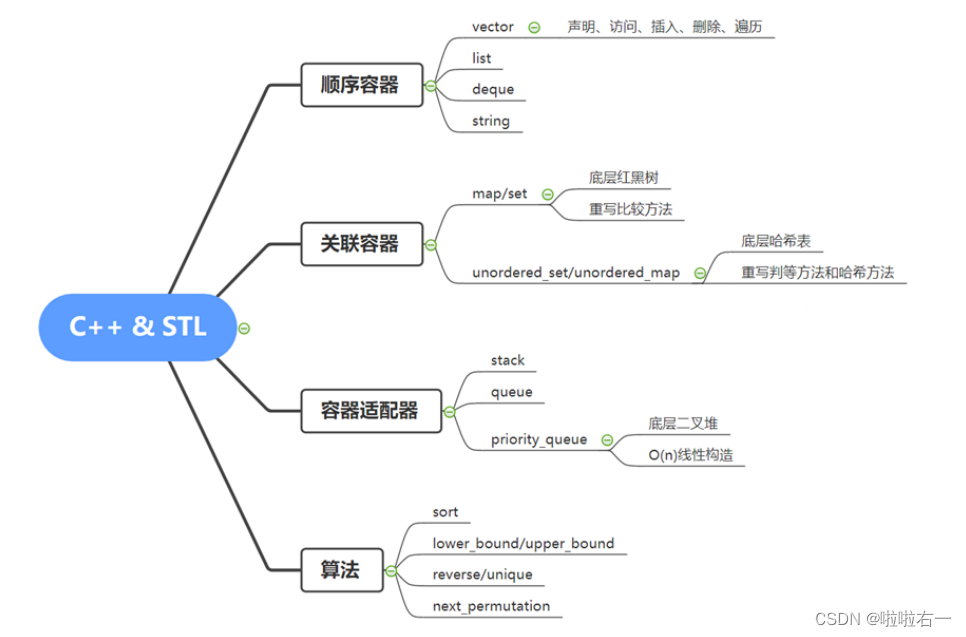
📚小结
oj写不来,抄会儿博客发会呆o(╥﹏╥)o