新浪微博
[Scrapy 教程] 3. 利用 scrapy 爬取网站中的详细信息 - YouTube
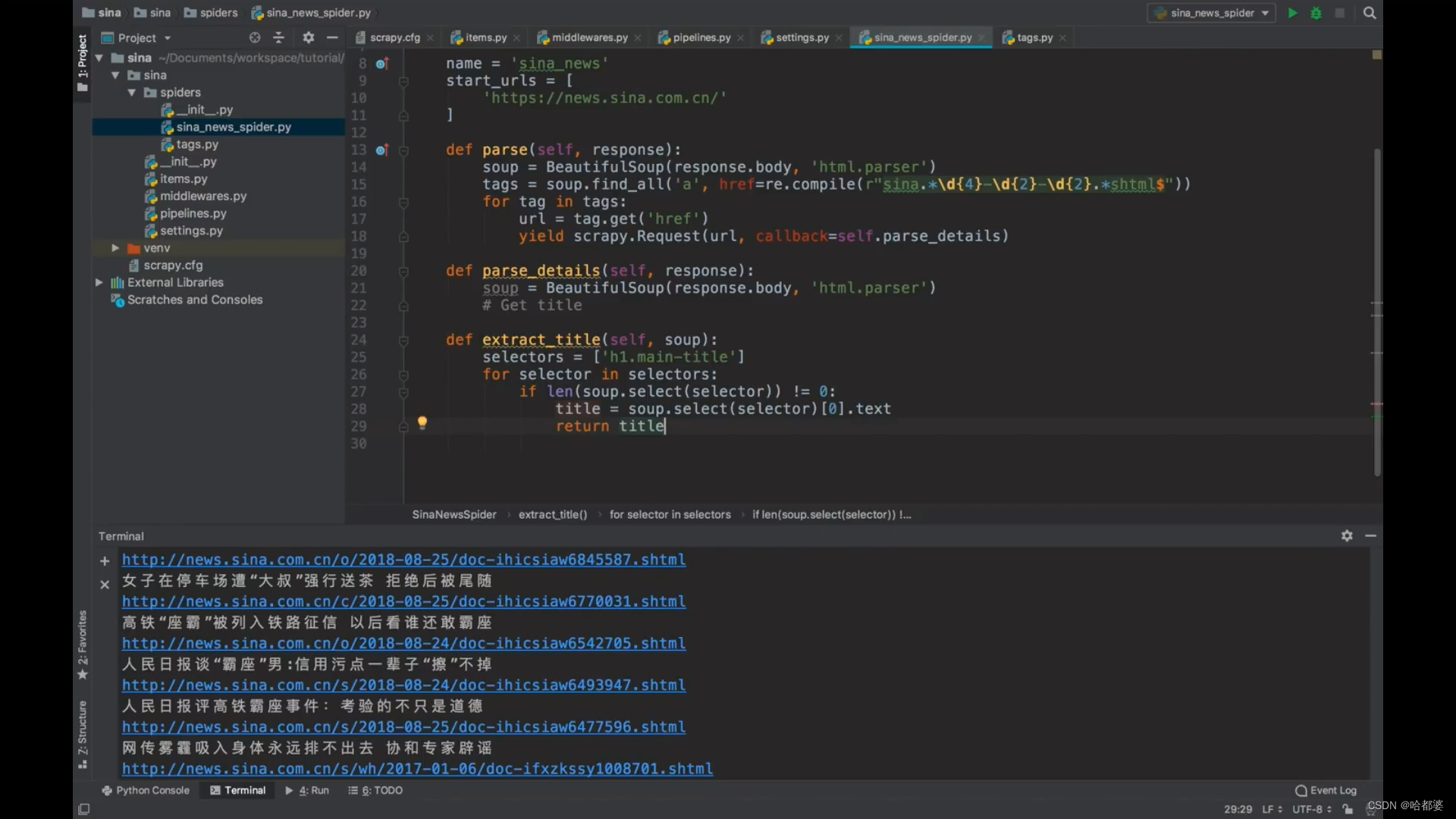

def parse(self,response):
soup BeautifulSoup(response.body,'html.parser')
tags soup.find_all('a',href=re.compile(r"sina.*\d{4}-\d{2}-\d{2}.*shtmls"))#匹配日期
for tag in tags:
url tag.get('href')
yield scrapy.Request(url,callback=self.parse_details)
def extract_title(self,soup):
selectors =['h1.main-title']
for selector in selectors:
if len(soup.select(selector))!=0:
title soup.select(selector)[0].text
return title
python与数据库
(6条消息) pymysql详解(connect连接、游标cursor、获取查询结果集、获取实时数据、解决查询数据为历史数据问题、insert into需要注意的地方)_pymysql.connect_XC_SunnyBoy的博客-CSDN博客
这是一个连接到本地MySQL数据库服务器的命令,其中:
-h127.0.0.1指定要连接的主机名或IP地址,这里使用本地主机(localhost)的IP地址127.0.0.1。
-uroot指定要用哪个MySQL用户进行连接,这里使用root用户进行连接。
-p123456指定连接时使用的密码,这里使用123456作为root用户的密码。
整个命令的意思是使用root用户和密码123456连接到本地MySQL服务器。如果连接成功,将打开MySQL客户端命令行界面,可以在其中执行各种MySQL命令和查询。
#创建对象
db = pymysql.connect(host='localhost',
user='root',
password='@hdp020820',
database='maoyandb',
)pymysql.err.OperationalError: (1049, "Unknown database 'maoyandb'")

CREATE TABLE movieinfo (
name VARCHAR(255),
actor VARCHAR(255),
release_date DATE
);import pymysql
导出数据库
#创建对象
self.db = pymysql.connect(host='localhost',
user='root',
password='@hdp020820',
database='maoyandb',
)
cursor = db.cursor()
# sql语句执性,单行插入
info_list = ['刺杀,小说家','雷佳音,杨幂','2021-2-12']
sql = 'insert into filmtab values(%s,%s,%s)'
#列表传参
cursor.execute(sql,info_list)
db.commit()
# 关闭
cursor.close()
db.close()