Reis进阶
- Redis事物
- Redis管道
- Redis持久化
- RDB持久化
- RDB持久化优缺点分析
- RBD文件修复&禁用RDB快照
- AOF持久化
- AOF优缺点&AOF重写机制
- AOF&RDB混合写机制
Redis事物
什么是事物?相信学过数据库的铁子们都知道事物是什么。在MySQL当中事物是指和数据库连接的一次会话当中所以的SQL要么一起成功要么一起失败。说白了就是一次性可以执行多条命令,本质就是一组命令的集合一个事物当中所有的命令都会序列化按照顺序的串行化执行而不被其他命令插入,不许加塞。在MySQL当中的事物只要有一条命令失败了那么所有的命令都会回滚,在Redis当中又有所不同这个我们在后面详细的讨论。下面我们一起来学习一下Redis的事物吧
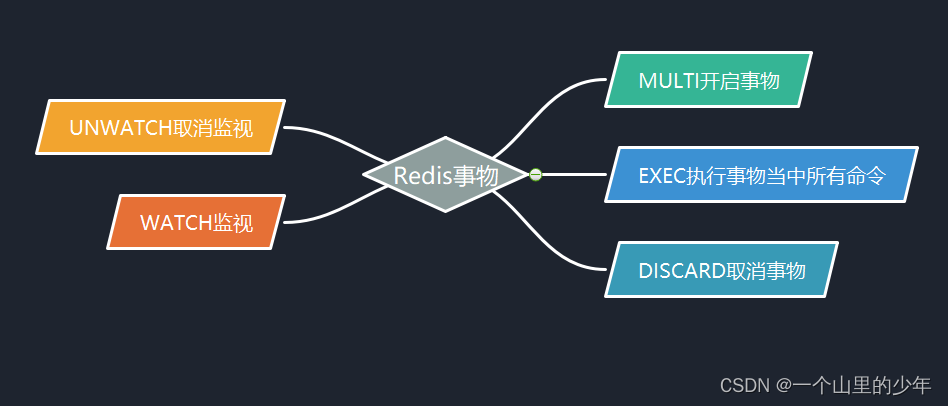
- MULTI :开启事务,redis会将后续的命令逐个放入队列中,然后使用EXEC命令来原子化执行这个命令系列。
- EXEC:执行事务中的所有操作命令。
- DISCARD:取消事务,放弃执行事务块中的所有命令。
- WATCH:监视一个或多个key,如果事务在执行前,这个key(或多个key)被其他命令修改,则事务被中断,不会执行事务中的任何命令。
- UNWATCH:取消WATCH对所有key的监视。
天上飞的理论需要有需要有落地的实现,下面我们就开始玩一下Redis当中的事物吧。
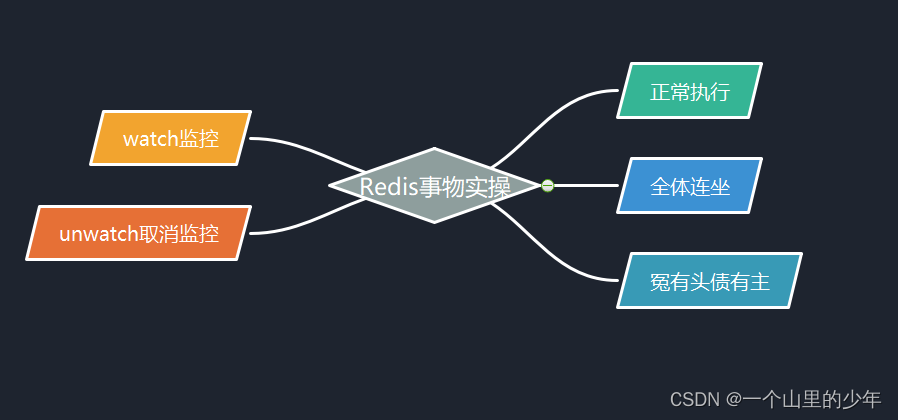
正常执行:
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> get k2
QUEUED
127.0.0.1:6379> exec
1) OK
2) OK
3) "v2"
我们发现开启事物之后,Redis指令不是客户端发一条执行一条而是将客户端发送过来的事物放到一个队列当中最后一次性、顺序性、排他性的执行一系列命令。
放弃执行:
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> discard
OK
127.0.0.1:6379> get k1
(nil)
有时候我们执行到一半了又不想执行了,我们可以使用discard命令取消事物。
全体连坐:
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2
(error) ERR wrong number of arguments for 'set' command
127.0.0.1:6379> exec
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> get k1
(nil)
现在有这样一个场景一个事物当中有一条命令执行过程当中发生了错误比如set k2 后面应该跟一个值,现在我不加了摆烂我们发现因为这个导致导致整个事物当中的命令全部作废了。
冤有头债有主:
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> incr k2
QUEUED
127.0.0.1:6379> exec
1) OK
2) OK
3) (error) ERR value is not an integer or out of range
上面的例子是这个我们给一个不是整型的变量进行这个自增,这当然是错误的。当我们进行exec执行事物的时候我们发现这个其他的命令并没有这个受到影响,这一点和数据库当中的事物是有区别的。
这也说明了Redis事物不保证原子性,而数据库里面的事物是保证原子性。
Watch监控:
Redis使用Watch来提供乐观锁定,类似于CAS这个就和这个悲观锁和乐观锁有点关系。这个在这里就不谈了。严格的说Redis的命令是原子性的,而事务是非原子性的,我们要让Redis事务完全具有事务回滚的能力,需要借助于命令WATCH来实现。Redis使用WATCH命令来决定事务是继续执行还是回滚,那就需要在MULTI之前使用WATCH来监控某些键值对,然后使用MULTI命令来开启事务,执行对数据结构操作的各种命令,此时这些命令入队列。当使用EXEC执行事务时,首先会比对WATCH所监控的键值对,如果没发生改变,它会执行事务队列中的命令,提交事务;如果发生变化,将不会执行事务中的任何命令,同时事务回滚。当然无论是否回滚,Redis都会取消执行事务前的WATCH命令。

在我们执行exec之前如果被监控的事物被修改了,那么整个事物将会被中断这个是需要注意的。当然我们也可以使用这个unwatch取消监控,当然还有一个也是需要注意的:当我们执行了exec之后所有的监控都会被取消。
总结:
Redis的基本事务(basic transaction)需要用到MULTI命令和EXEC命令,这种事务可以让一个客户端在不被其他客户端打断的情况下执行多个命令。和关系数据库那种可以在执行的过程中进行回滚(rollback)的事务不同,在Redis里面,被MULTI命令和EXEC命令包围的所有命令会一个接一个地执行,直到所有命令都执行完毕为止。当一个事务执行完毕之后,Redis才会处理其他客户端的命令。Redis事务在执行的中途遇到错误
,不会回滚,而是继续执行后续命令;还未执行exec就报错:如果事务中出现语法错误,则事务会成功回滚,整个事务中的命令都不会提交****成功执行exec后才报错:如果事务中出现的不是语法错误,而是执行错误,不会触发回滚,该事务中仅有该错误命令不会提交,其他命令依旧会继续提交。另外,Redis里遇到有查询的情况穿插在事务中间,不会返回结果。只有执行exec才能返回查询.
Redis管道
redis客户端执行一条命令分4个过程:
发送命令-〉命令排队-〉命令执行-〉返回结果
这个过程称为Round trip time(简称RTT, 往返时间),mget mset有效节约了RTT,但大部分命令(如hgetall,并没有mhgetall)不支持批量操作,需要消耗N次RTT ,这个时候需要pipeline来解决这个问题.下面我们来讨论一下这个
1、未使用pipeline(也就是管道)执行N条命令
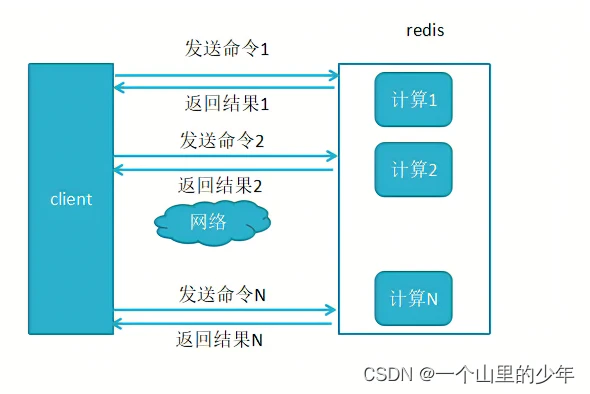
2、使用了pipeline执行N条命令
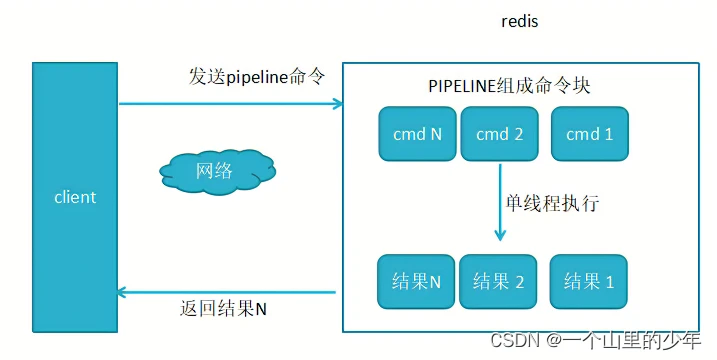
显然这个使用这个pipline的方式效率要更高.一次发送多条命令,减少这个和redis-server网络交互。
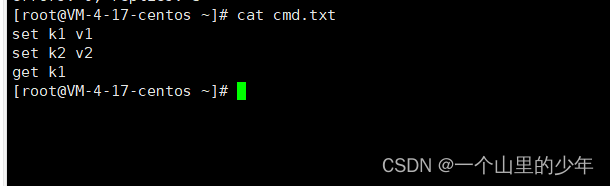
下面我们redis客户端建立一个socket连接然后将一个文件当中数据发送给redis

对应cmd当中的命令内容为:
注意:
原生命令是原子的(mset,mget),而管道pipline不是原子的,原生批量命令一次只能执行一条命令,pipeline支持批量执行不同命令,原生批量命令是服务端实现的,而pipeline需要和服务端和客户端共同完成。
Redis持久化
什么是Redis持久化?redis 读写速度快、性能优越是因为它将所有数据存在了内存中,然而当 redis 进程退出或重启后,所有数据就会丢失。所以我们希望 redis 能保存数据到硬盘中,在 redis 服务重启之后,原来的数据能够恢复,这个过程就叫持久化。
redis 提供两种持久化机制 RDB(默认)和 AOF 机制,当两种方式同时开启时,数据恢复 redis 会优先选择 RDB 恢复。
Redis默认的持久化方式是rdb持久化方式。
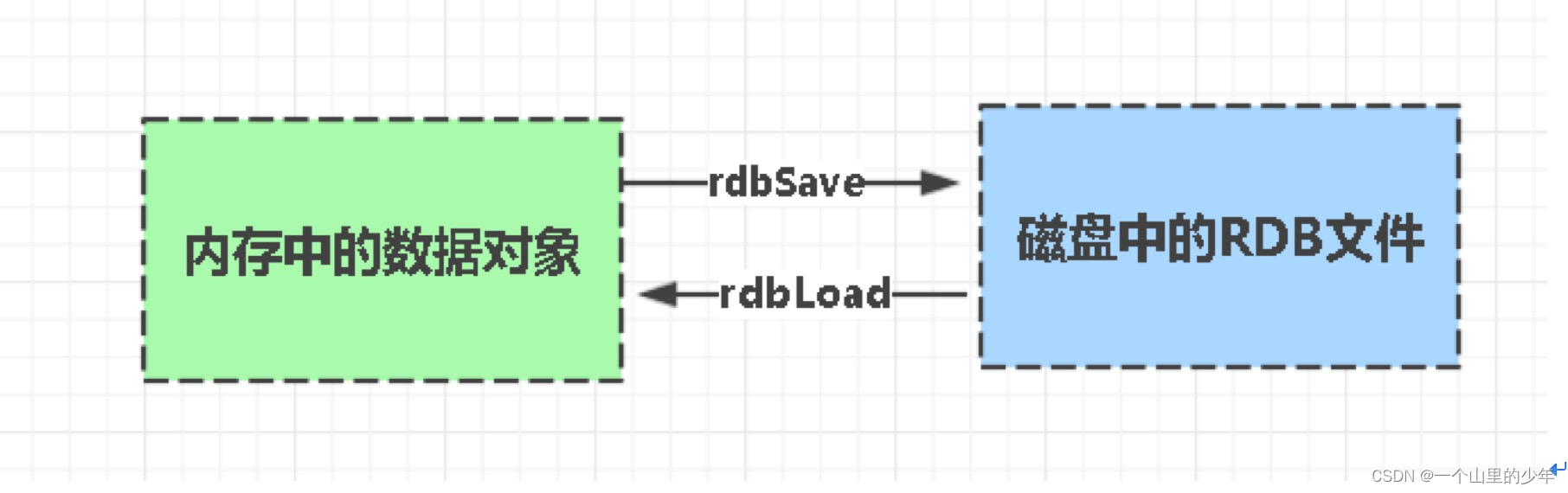
RDB持久化
Redis默认的持久化模式rdb按指定时间间隔执行数据集的时间点快照,RDB类似于MySQL Dump的 frm 文件。将内存当中的数据拍一个照片写入到磁盘当中去.
下面我们来看一下这个Redis当中的conf文件看如何配置这个写入时间
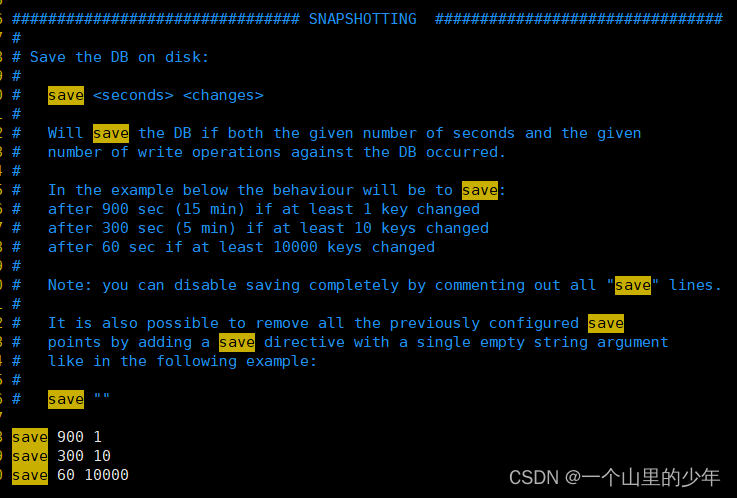
这个触发RDB持久化机制这个自动触发的条件是这个:
下面看看这个自动触发:
- 900秒内有1次修改
- 300秒内有10次修改
- 60秒内有10000次修改
在这里说一下在更高的版本这个RDB的写入机制发生了变化个低版本的高版本的就不再说明了。 - 3600秒内有一次修改
- 300秒内有100次修改
- 60秒内有10000次修改
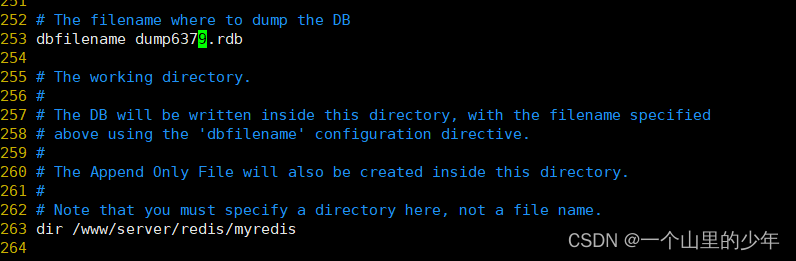
这里的修改是指新增了key,或者对key做了修改是这个意思。下面我们来实验一下我们将rdb的名字设置为这个
当然我们也可以使用config set 对应的dbfilename
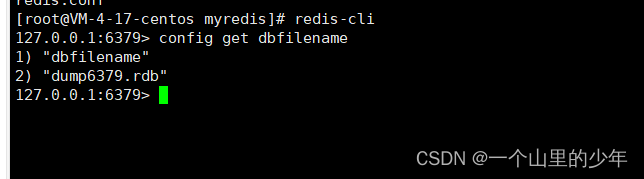
如果你不想打开配置文件进行修改也可以通过config set 进行修改.在这里为了演示方便我们将这个触发的时间改成5分钟有2次修改就可以了这样我们就能够看到这个效果了。
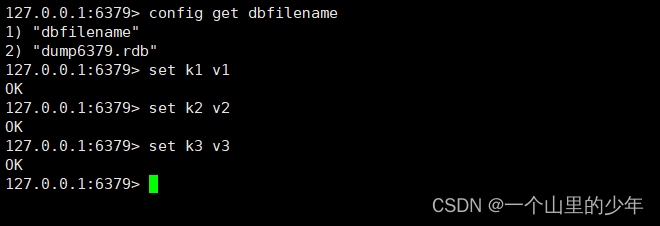
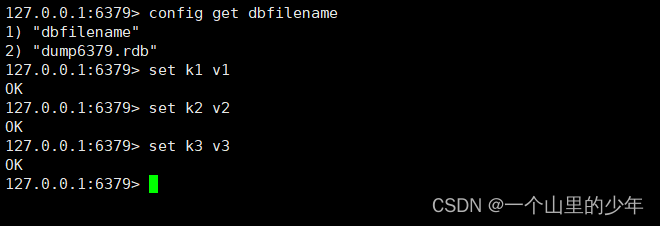
我们去目录下看有没有生成这个dump6379.rdb文件
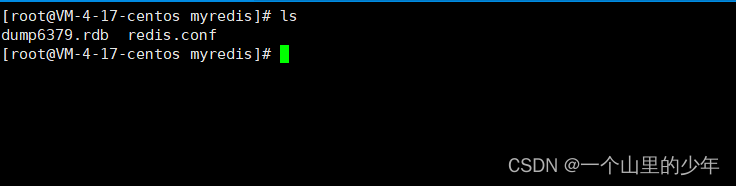
我们发现她确实生成了这个rdb文件。这个RDB的触发方式还要当我们flushall或者flushdb的时候或者我们shutdown时也会生成这个RDB文件。但是这里是有坑的,下面我们来演示一下这个坑

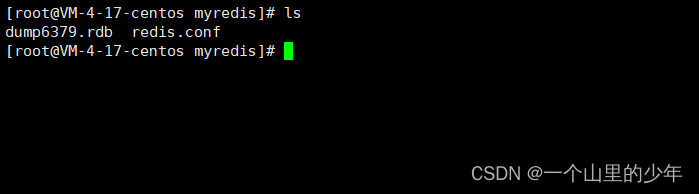
我们发现确实有这个rdb文件生成。下面我们重启redis看数据是否能够恢复了

我们发现数据依然是空的,这是为什么了?因为当我们flushdb时数据被清空那么此时的快照也是空的那么我们重写启动时数据也是空的这是没有问题的这一点我们需要特别注意,这个非常的坑。
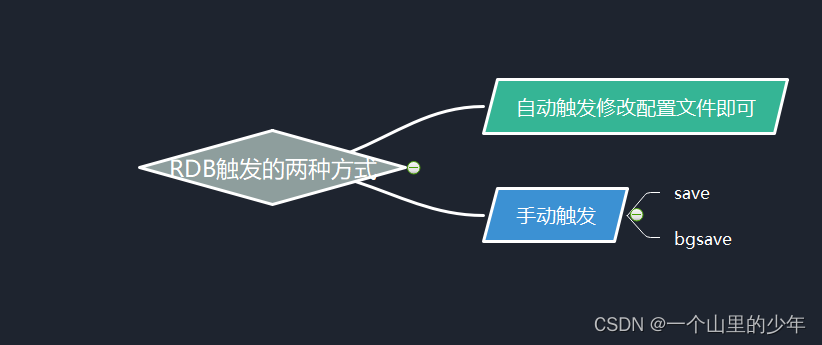
手动触发:
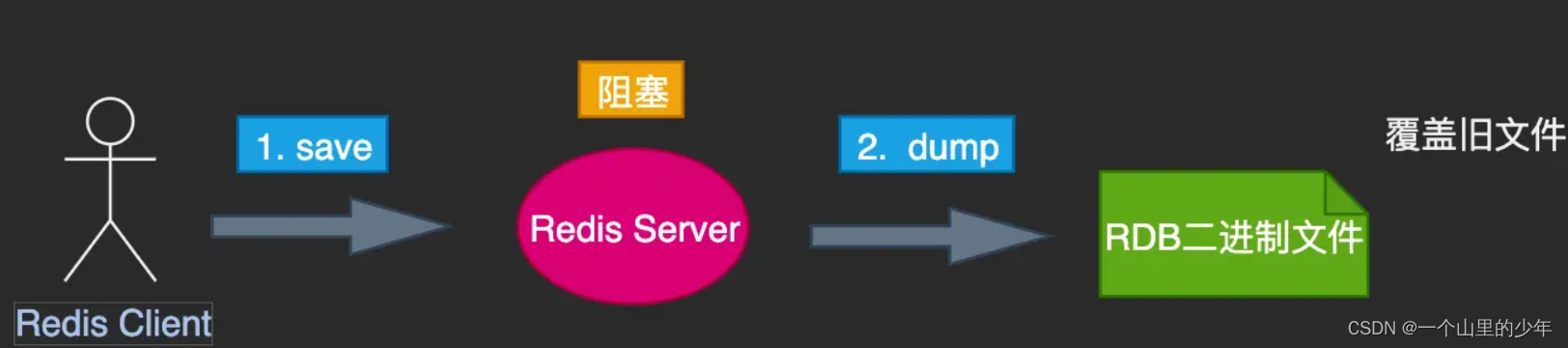
手动触发有两个命令一个是save一个是bgsave.这两个命令有着本质的区别
- save: 可以由客户端显示触发,也可在redis shutdown 时触发。 save本身是单线程串行方式执行,因此当数据量大时,可能会发生Redis Server的长时间卡顿。但其备份期间不会有其他命令执行,因此备份时期 数据的状态始终是一致性的。但是严重不推荐使用因为当数据量非常大时会导致redis无法处理其他客户端的请求。
- bgsave:命令在执行时,会fork一个子进程。子进程提交完成后,会立即给客户端返回响应,备份操作在后台异步执行,期间不会影响Redis的正常响应。对于bgsave来说,当父进程Fork完子进程之后,异步任务会将当前的内存状态作为一个版本进行复制。在复制过程中产生的变更,不会反映在这次备份当中。
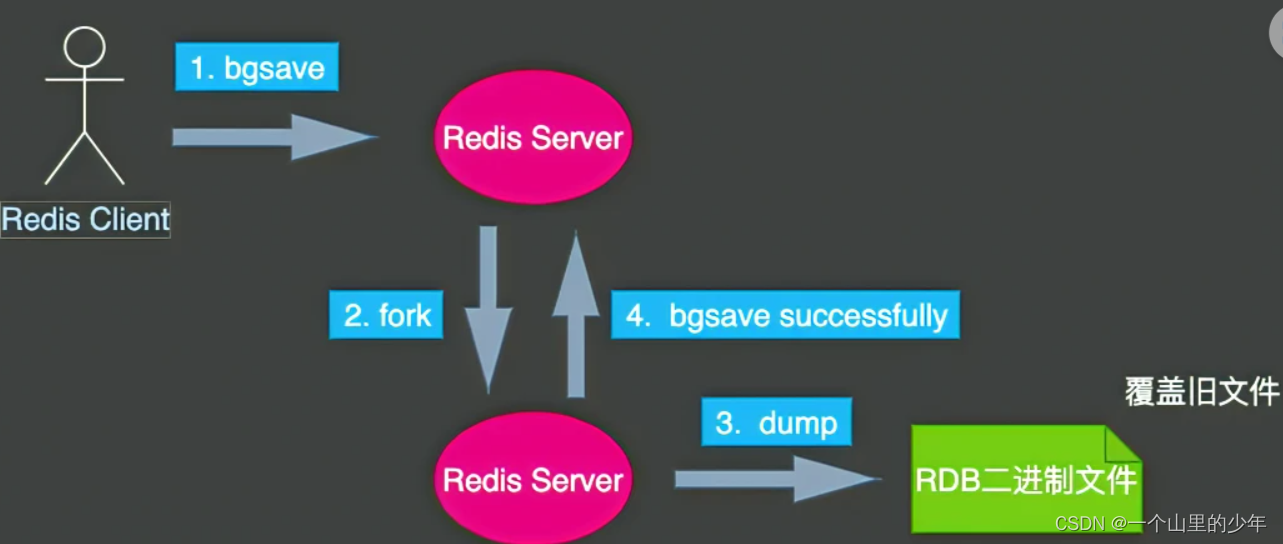
我们严重不推荐使用save这是特别需要注意的!!!!!!!!!。但是了使用bgsave创建子进程产生了和父进程相同的子进程,但子进程在此后会多exec系统调用,数据会存在两份这也是我们需要考虑的。
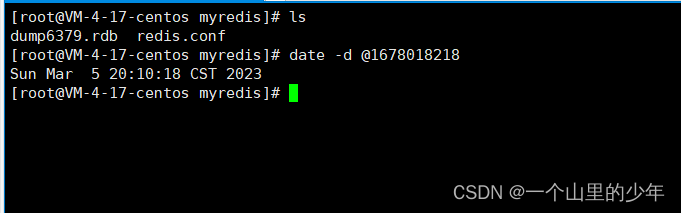
最后我们说一下我们可以通过lastsave获取最后一次成功执行快照的时间。
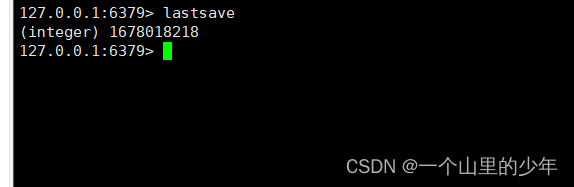
在用linux下的date命令进行查看
RDB持久化优缺点分析
优点:
- RDB会生成多个数据文件,每个文件都代表了某时刻Redis中的所有数据,这种方式非常适合做冷备,可将这种完整数据文件发送到云服务器存储,比如ODPS分布式存储,以预定好的备份策略来定期备份Redis中的数据。
- RDB对Redis对外提供的读写服务,影响非常小,可让Redis保持高性能
- 因为Redis主进程只要fork一个子进程,让子进程执行RDB相对于AOF,直接基于RDB文件重启和恢复Redis进程,更加快速。
缺点:
- fork():耗内存,copy-on-write策略
RDB每次在fork子进程来执行RDB快照数据文件生成的时候,如果数据文件特别大,可能会导致对客户端提供的服务暂停数毫秒,或者甚至数秒不可控,容易丢失数据 - 一般RDB每隔5分钟,或者更长时间生成一次,若过程中Redis宕机,就会丢失最近未持久化的数据
下面我们来模拟一下redis宕机,我们将redis当中的策略改为 5 秒钟修改2次才触发。
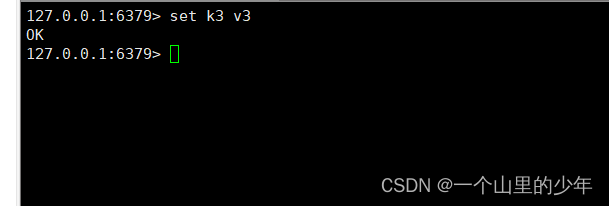
然后我们再将redis给干掉

重写启动redis
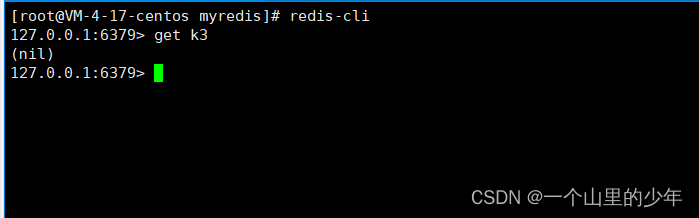
我们发现这个k3这个数据就丢失了。
RBD文件修复&禁用RDB快照
有可能这个Redis在使用RDB进行数据备份时,写入文件少写了一部分导致这个文件少写了,此时RDB文件不正确此时我们可以使用命令来进行修复
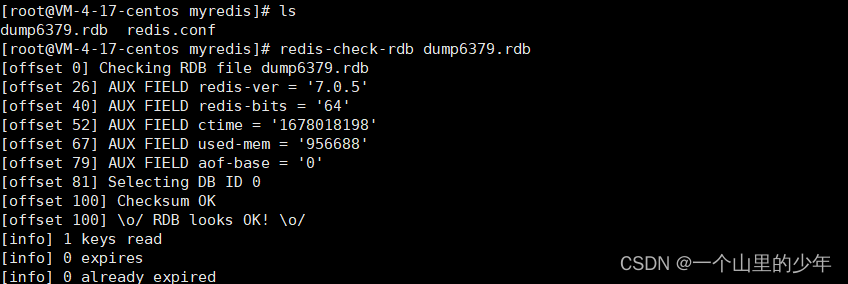
这这里演示一下就可以了,不用不他给搞坏了。
如果我们想要禁用RDB这种持久化方式我们可以通过以下方式:
- 通过命令:config set save “”
修改配置文件添加save “”
AOF持久化
AOF持久化方式是以日志的形式记录每一个写操作,将Redis执行过的所以写指令记录下来(读操作不记录)只许追加文件但不可以改文件,Redis启动时会读取该配置文件重新构建数据,换而言之redis重启的话就根据日志文件内容将写指令从前到后执行一遍完成数据恢复工作。
默认情况下时没有开启AOF持久化发生如果我们想要使用需要修改配置文件
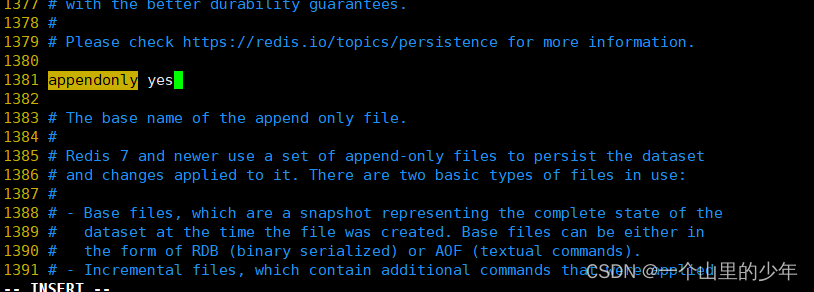
我们需要将appendonly 该为yes同样的AOF也有几种这个策略下面我们一一介绍一下:
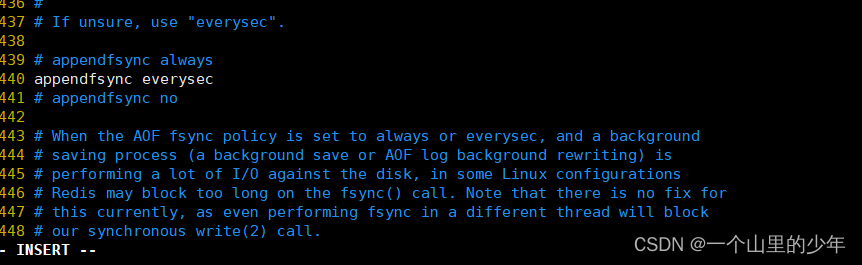
always
每次刷新缓冲区,都会同步触发同步操作。但因为每次写操作都会触发同步,所以该策略会大大降低Redis的吞吐量。当然了,该模式会拥有最高的容错性。就像一个傻子一样你写一个我写一个

AOF的回放时机也是在机器启动时,一旦存在AOF,Redis就会选择增量回放。因为增量持久化是持续的写盘,相比于全量持久化,数据更加完整。回放过程就是将AOF中存放的命令,重新执行一遍。完成后再继续接收客户端新命令。
下面我们看看他的三种策略:
every second

no

总结一下:

在这里我们选择一秒钟写入一次也就是使用redis默认的。在这里说明一下在低版本的redis当中只有一个aof文件并且rdb文件和aof文件时防止一起的高版本以后aof文件被放到一个目录下:
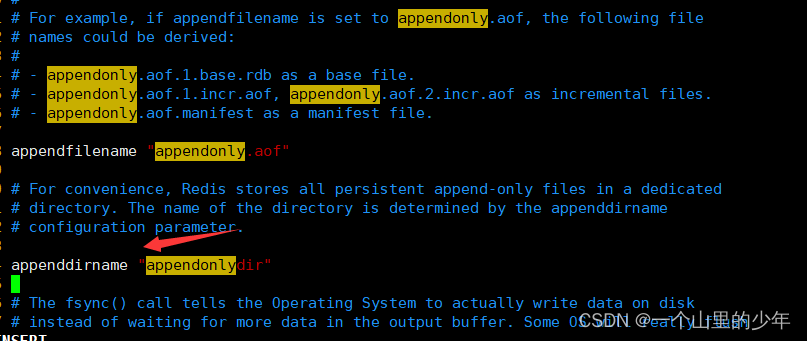
并且aof文件也变成了三个并不是低版本时的一个

// 几种类型文件的前缀,后跟有关序列和类型的附加信息
appendfilename "appendonly.aof"
// 新版本增加的目录配置项目
appenddirname "appendonlydir"
// 如有下的aof文件存在
1. 基本文件
appendonly.aof.1.base.rdb
2. 增量文件
appendonly.aof.1.incr.aof
appendonly.aof.2.incr.aof
3. 清单文件
appendonly.aof.manifest
下面我们来演示一下看一下这个aof文件

下面我们看看这个aof文件里面是些什么东西
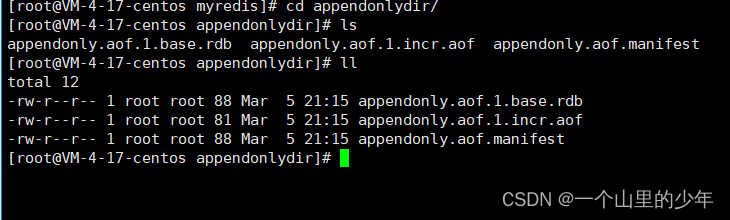

我们发现确实是这个记录的是我们的写操作。如果我们flushdb 那么这个aof会有什么结果了。
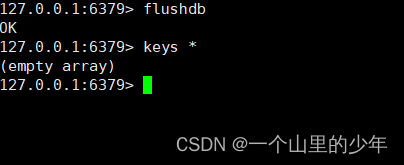
我们重启redis服务看数据能不能恢复,铁子们可以想一下数据是否能够恢复
答案是这肯定不能够恢复
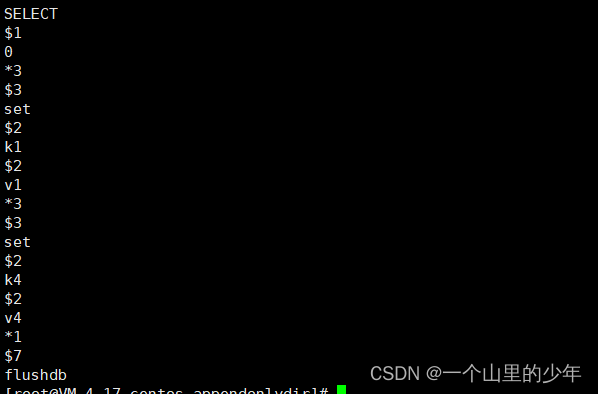
我们查看这个aof文件发现flushdb也被记录下来了,如果我们需要恢复我们需要将flushdb删除即可。
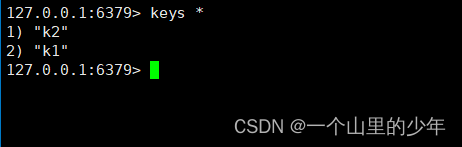
下面我们看看这个AOF异常文件恢复,在这里我们依然是进行模拟我们将文件里面添加一些乱七八糟的内容
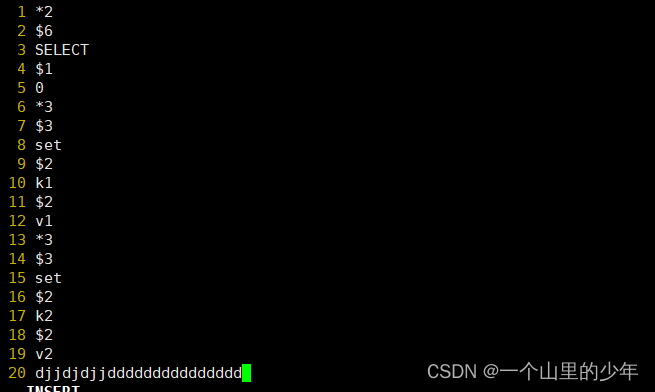
我们重启服务器试试
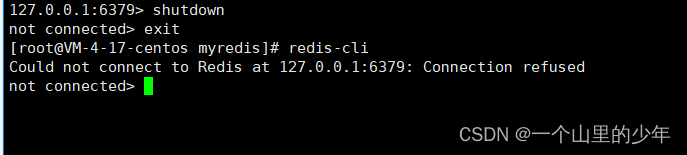
完蛋我们发现此时服务起不来了,那这个又该如何恢复了:

我们使用 redis-check-aof --fix文件名就可以了
AOF优缺点&AOF重写机制
优点:
- 更好避免数据丢失一般AOF每隔1s,通过子进程执行一次fsync,最多丢1s数据
- append-only模式追加写所以没有任何磁盘寻址的开销,写入性能高,且文件不易破损,即使文件尾部破损,也易修复
- 日志文件即使过大,出现后台重写操作,也不会影响客户端的读写
因为在rewrite log时,会压缩其中的指令,创建出一份需要恢复数据的最小日志。在创建新日志时,旧日志文件还是照常写入。当新的merge后的日志文件准备好时,再交换新旧日志文件即可!命令通过非常可读的方式记录该特性非常适合做灾难性误删除操作的紧急恢复。比如某人不小心用flushall命令清空了所有数据,只要这个时候后台rewrite还没有发生,可立即拷贝AOF文件,将最后一条flushall命令给删了,然后再将该AOF文件放回去,就可通过恢复机制,自动恢复所有数据。
缺点:
- 对于同一份数据,AOF日志一般比RDB快照更大AOF开启后,写QPS会比RDB的低,因为AOF一般会配置成每s fsync一次日志文件,当然,每s一次fsync,性能也还是很高的
- 以前AOF发生过bug,就是通过AOF记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来类似AOF这种较为复杂的基于命令日志/merge/回放的方式,比基于RDB的每次持久化一份完整的数据快照方式相比更加脆弱一些,易产生bug不过AOF就是为了避免rewrite过程导致的bug,因此每次rewrite并不是基于旧的指令日志进行merge的,而是基于当时内存中的数据进行指令的重新构建,这样健壮性会更好
下面我们看看这个AOF文件的重写机制
AOF的重写是为了优化记录的命令进行体积的压缩,比如我们set k1 v1,
set k2 v2 ,set k3 v3 本质上我们只需要记录set k3 v3 就行。
同样的这个AOF也有两种机制一种是自动另外一种手动的方式也就是通过命令的方式
首先我们看看自动的方式

这里默认是64mb时并将是扩大了一倍才会触发这个机制。在这里我们将其该小一点

我们首先进行这个写入数据
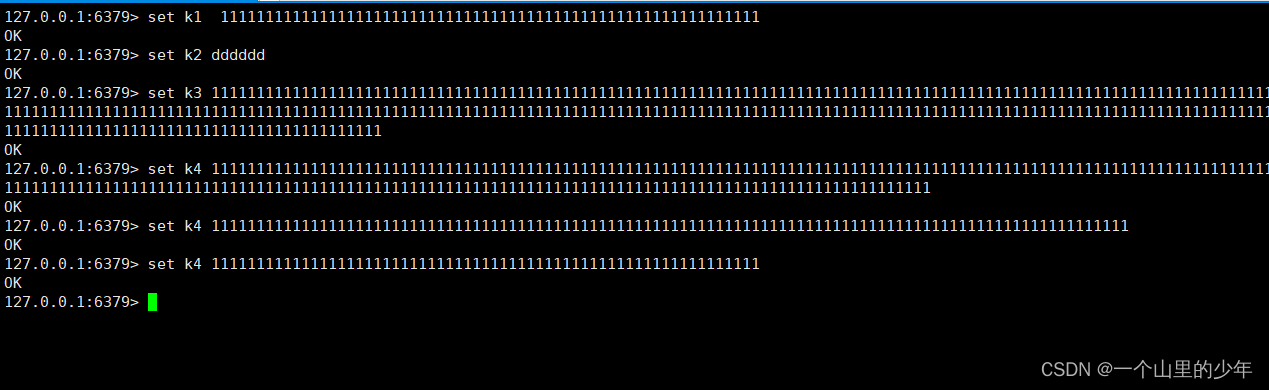
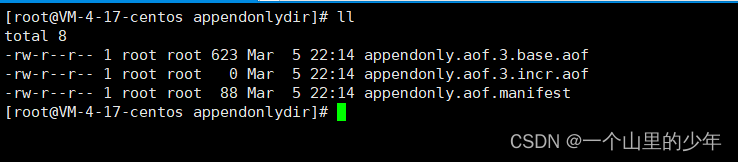
当我们查看aof文件时我们发现
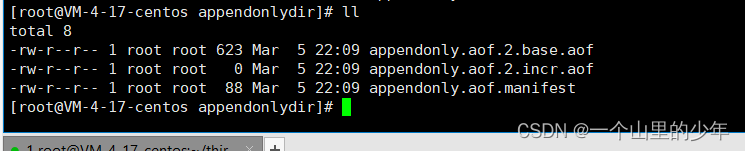
这个文件发生了变化增量文件大小变为了0全部到了这个基本文件当中。进行了压缩,有兴趣的铁子可以看看base文件里面记录的就是我们那些命令
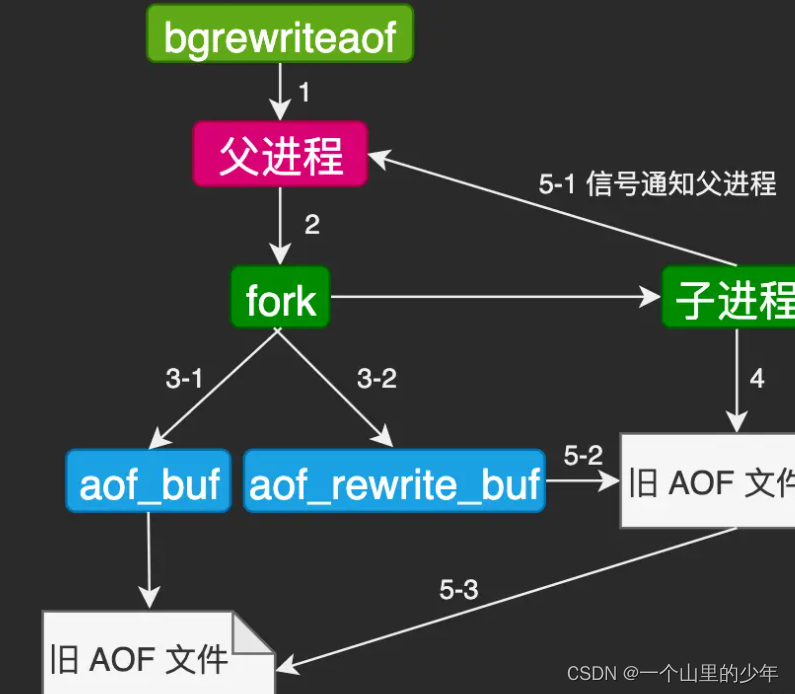
大致过程就是这样的。
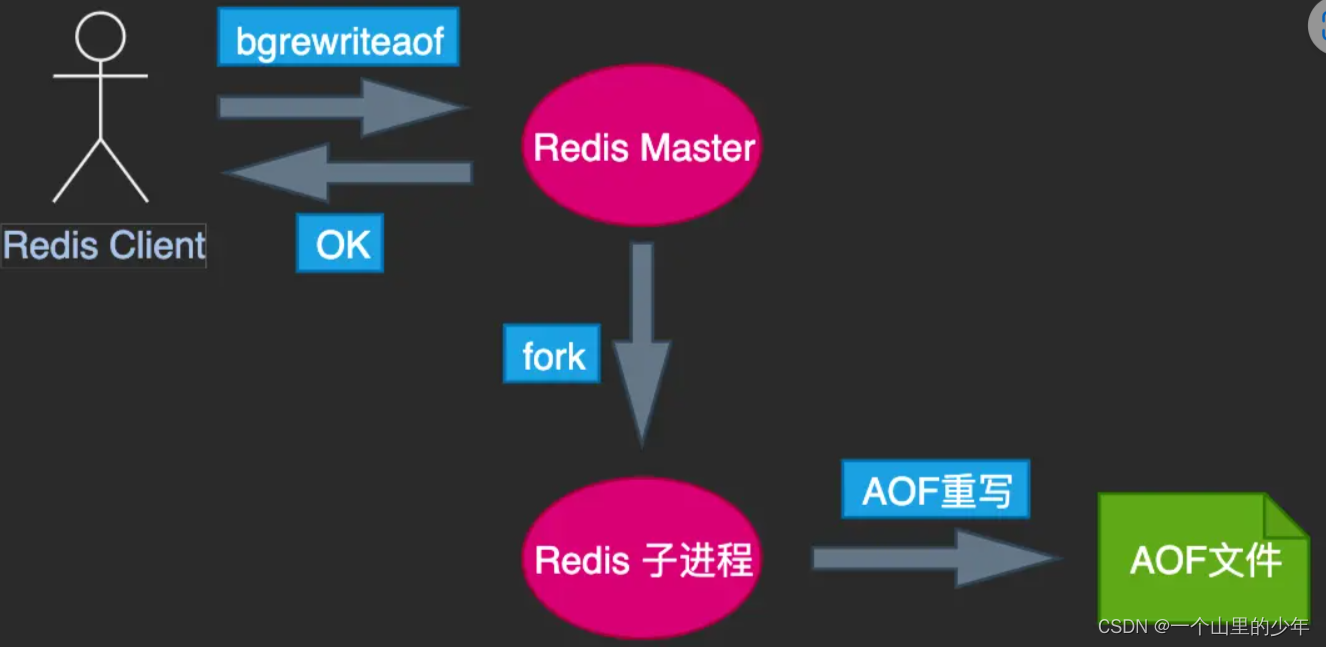
手动触发我们使用bgrewriteaof命令即可
我们在查看aof文件
其大致原理如下:
AOF&RDB混合写机制
了解了AOF持久化过程和RDB持久化过程以后,混合持久化过程就相对简单了。
混合持久化同样也是通过bgrewriteaof完成的,不同的是当开启混合持久化时,fork出的子进程先将共享的内存副本全量的以RDB方式写入aof文件,然后在将重写缓冲区的增量命令以AOF方式写入到文件,写入完成后通知主进程更新统计信息,并将新的含有RDB格式和AOF格式的AOF文件替换旧的的AOF文件。简单的说:新的AOF文件前半段是RDB格式的全量数据后半段是AOF格式的增量数据,如下图:
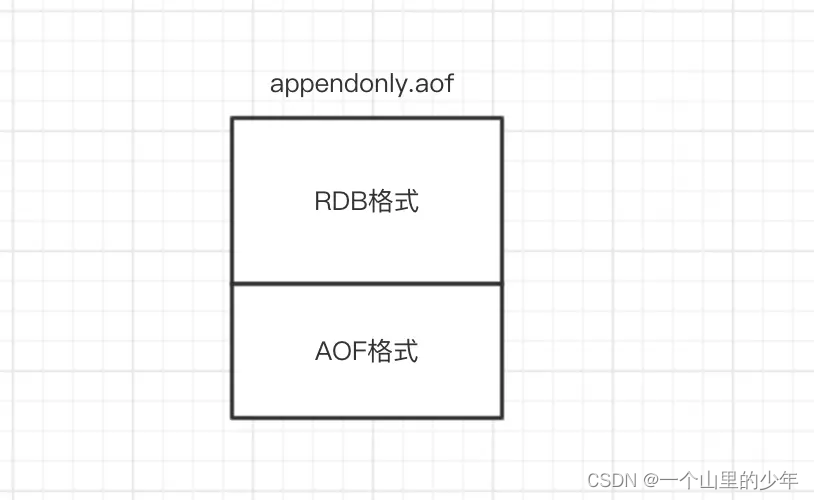
注意这个数据恢复如果aof和rdb同时存在优先加载aof,如果没有aof才会加载rdb。
我们通过这个参数进行修改。RDB和AOF的混合写机制我们可以使用RDB做全量,AOF做增量持久化。





![[Latex]参考文献的格式:数字,作者+年份](https://img-blog.csdnimg.cn/5634e9a8127b4d66925c131c5a419ebf.png)