背景
分布式追踪的起源
自从微服务的兴起开始,整个系统架构开始变得极为庞大和复杂,但是服务之间的调用关系,调用消耗时间等等信息却依然是半黑盒的状态。为了能够将调用的链路进行串联,将系统的各种指标数据展示出来以使得系统的链路更加透明便于排查故障,分布式追踪便应运而生。
百花齐放的分布式追踪
Zipkin
Zipkin最初是由Twitter开发并与2012年开源的一款开源追踪系统。Zipkin的使用非常广泛,影响了很多的后来人。他的传输头为X-B3
Skywalking
Skywalking是由国人开发,并且在后续捐赠给了Apache基金会的一个开源项目。现在是Apache基金会的顶级项目。
Pinpoint
Pinpoint由Naver在2012年开发,并于2015年开源。Pinpoint适用于java,php和python。
Jaeger
Jaeger最早是由Uber开发并于2017年开源,后续捐赠给了CNCF基金会。
OpenTracing
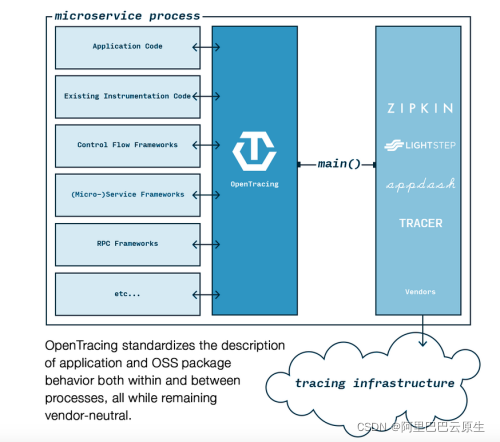
OpenTracing 的优势在于制定了一套无关厂商、无关平台的协议标准,使开发人员只需要修改 Tracer 就可以更迅捷的添加或更换底层监控的实现,被追踪的服务只需要调用相关 API 接口,就可被任何实现这套接口的追踪后台支持。也是基于这一点,2016 年云原生计算基金会 CNCF 正式接纳 OpenTracing,顺利成为 CNCF 第三个项目。而前两个项目都已成为云原生及开源领域的事实标准–Kubernetes 和 Prometheus,OpenTracing由CNCF托管,具备较为完善的instrumentation库。
遵循 OpenTracing 协议的产品有 Jaeger、Zipkin、 LightStep 和 AppDash 等追踪组件,并可以轻松集成到 gRPC、Flask、Django 和 Go-kit 等开源框架中。
MICROSERVICE PROCESS
APPLICATION CODE
EXISTING INSTRUNENTATION CODE(L
ZIPKIN
LIGHTSTEP
CONTROL FLOW FPAWEWORKS
MAIN()
OPENTRACING
APPDAAK
(MICRO-)SERVICE FRANEWORKS
TRACER
RPC FRANEWORKS
VENDORS
ETC.
OPEN TRACING STANDARDIZES THE DESCRIPTION
OF APPLICATION AND OSS PACKAGE
BEHAVIOR BOTH WITHIN AND BETWEEN
TRACING INFRASTRUCTURE
PROCESSES,ALL WHILE REMAINING
VENDOR-NEUTRAL.
CSON@阿里巴巴云原生
TIME
UNIQUEIDCONTEXT]
EDGE SERVICE
{CONTEXT]
{CONTEXT]
SPANS
TRACE
C
E
D
{CONTEXT]
{CONTEXT)
D
CSDN@阿里巴巴云原生
OpenCensus
OpenCensus由Google发起,最初是Google内部追踪平台,后开源。OpenCensus 提供了统一的测量工具:跨服务捕获跟踪跨度 Span、应用级别指标 Metrics。
• 相较于 OpenTracing 只支持 Traces,OpenCensus 支持 Traces 和 Metrics。
• 相较于 OpenTracing 制定规范,OpenCensus 不仅制定规范,还包含了 Agent 和 Collector。
• 家属团阵容相较 OpenTracing 更加庞大,获得 Google、微软支持。
收集库和应用记录的可观测结果,汇总、导出统计数据,并包括 Recording(记录)、Views(聚合度量查询)两部分。
核心术语介绍
除了沿用 OpenTracing 的相关术语之外,OpenCensus 也定义了一些新术语。
• Tags
OpenCensus 允许在记录时将指标与维度相关联。从而能够从不同角度分析测量结果。
• Stats
收集库和应用记录的可观测结果,汇总、导出统计数据,并包括 Recording(记录)、Views(聚合度量查询)两部分。
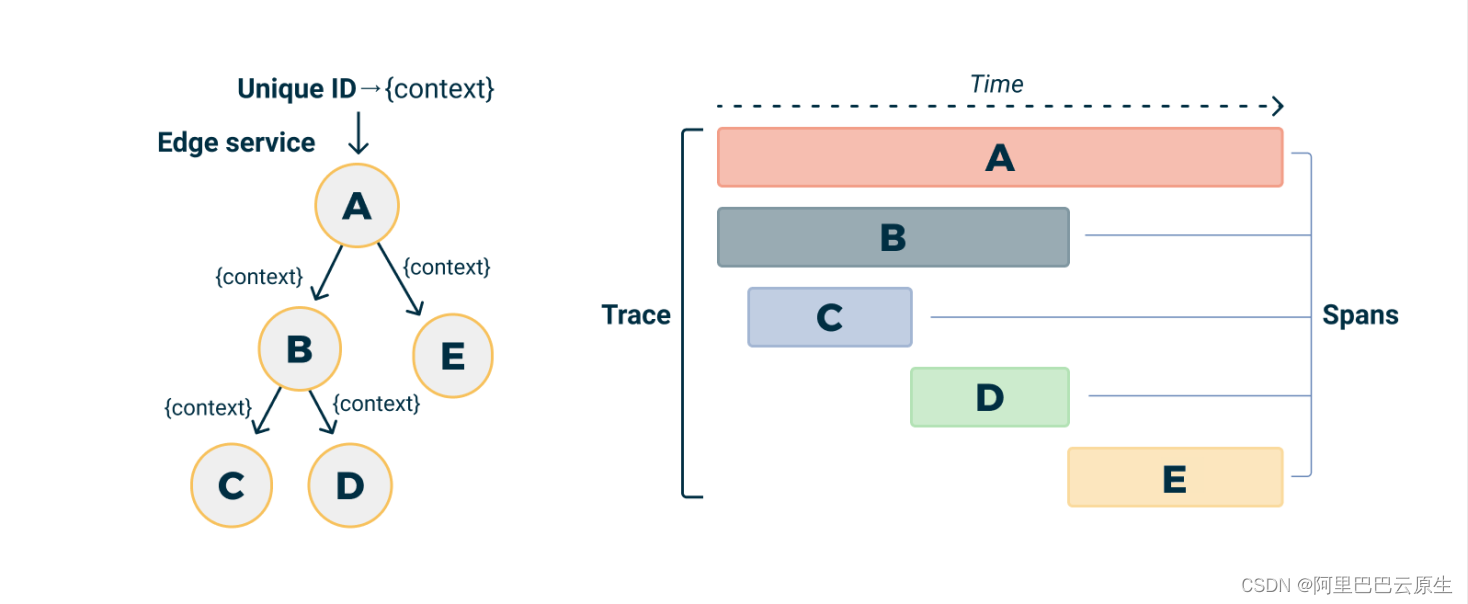
• Trace
除了 Opentracing 所提供的 Span 属性之外,OpenCensus 还支持 Parent SpanId、Remote Parent、Attributes、Annotations、Message Events、Links 等属性。
• Agent
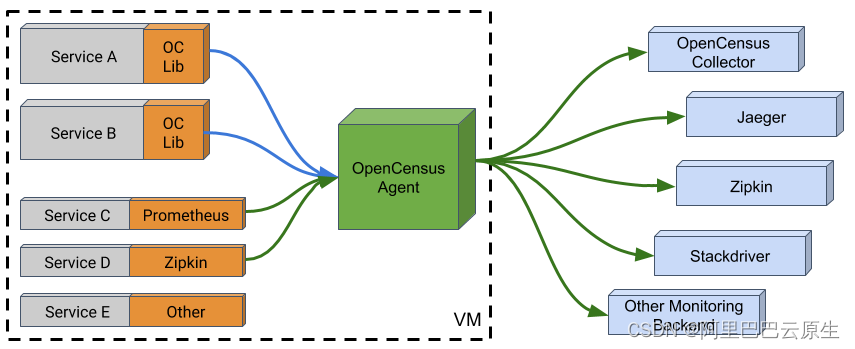
OpenCensus Agent 是一个守护进程,允许 OpenCensus 的多语言部署使用Exporter。与传统上为每个语言库和每个应用程序删除和配置 OpenCensus Exporter不同,使用 OpenCensus Agent,只需为其目标语言单独启用 OpenCensus Agent Exporter。对于运维团队而言,实现单个 exporte 管理并从多语言应用程序中获取数据,将数据发送到所选择的后端。与此同时,尽可能的减少反复启动或部署对于应用的影响。最后,Agent 还附带了“Receivers”。“Receivers”使 Agent 直通后端,去接收可观测数据并将其路由到所选择的 Exporter。比如 Zipkin、Jaeger 或 Prometheus。
OPENCENSUS
OC
SERVICE A
COLLECTOR
LIB
JAEGER
OC
SERVICE B
LIB
OPENCENSUS
ZIPKIN
AGENT
SERVICE C
PROMETHEUS
STACKDRIVER
ZIPKIN
SERVICE D
OTHER MONITORING
SERVICE E
OTHER
VM
CSBAPRY阿里巴巴云原生
• Collector
Collector 作为 OpenCensus 的重要组成部分,由 Go 语言便编写,可以从任何可用 Receivers 的应用中接受流量,而不用关注编程语言以及部署方式,而这个好处显而易见。对于提供 Metrics 和 Trace 的服务或应用而言,只需要一个 Exporters 导出组件,就能从多语言应用中获取数据。
OPENCENSUS
JAEGER/ZIPKIN
PROMETHEUS / STATSD
OPENCENSUS
JAEGER
JAEGER/ZIPKIN
PROMETHEUS
PROMETHEUS/STATSD
ZIPKIN
OPENCENSUS AGENT
(AGENT)
JAEGER
OPENCENSUS
OPENCENSUS
COLLECTOR
PROMETHEUS
JAEGER/ZIPKIN
ZIPKIN
PROMETHEUS/STATSD
OPENCENSUS AGENT
(SIDECAR)
OPENCENSUS
COLLECTOR
HOST
OPENCENSUS
DATADOG
JAEGER/ZIPKIN
OMNITION
PROMETHEUS/STATSD
STACKDRIVER
OPENCENSUS AGENT
(DAEMONSET)
CSDN@阿里巴巴云原生

• Exporters
OpenCensus 可以通过各种 Exporter 实现将相关数据上传到各种后端,比如:Prometheus for stats、OpenZipkin for traces、Stackdriver Monitoring for stats and Trace for traces、Jaeger for traces、Graphite for stats。
OpenCensus与OpenTracing
在上述的项目中有两个项目较为特殊:其一是OpenTracing,他制定了一套无关平台的统一的Trace的标准,后续的很多项目例如Jaeger等都是基于此协议,因此他在当时的Trace标准领域具有不小影响力;其二是OpenCensus,他背靠Google,并且它不仅仅实现了Trace,还包括了Metrics,并且他包含了一系列诸如Agent和Collector的方案,可以说是相当完备。
在当时这两大流派可以说是互相有一大票的追随者,一边是以Google和微软领衔的OpenCensus,一边是众多开源项目和厂商使用的OpenTracing,两者可以说是各有优劣,各领风骚。
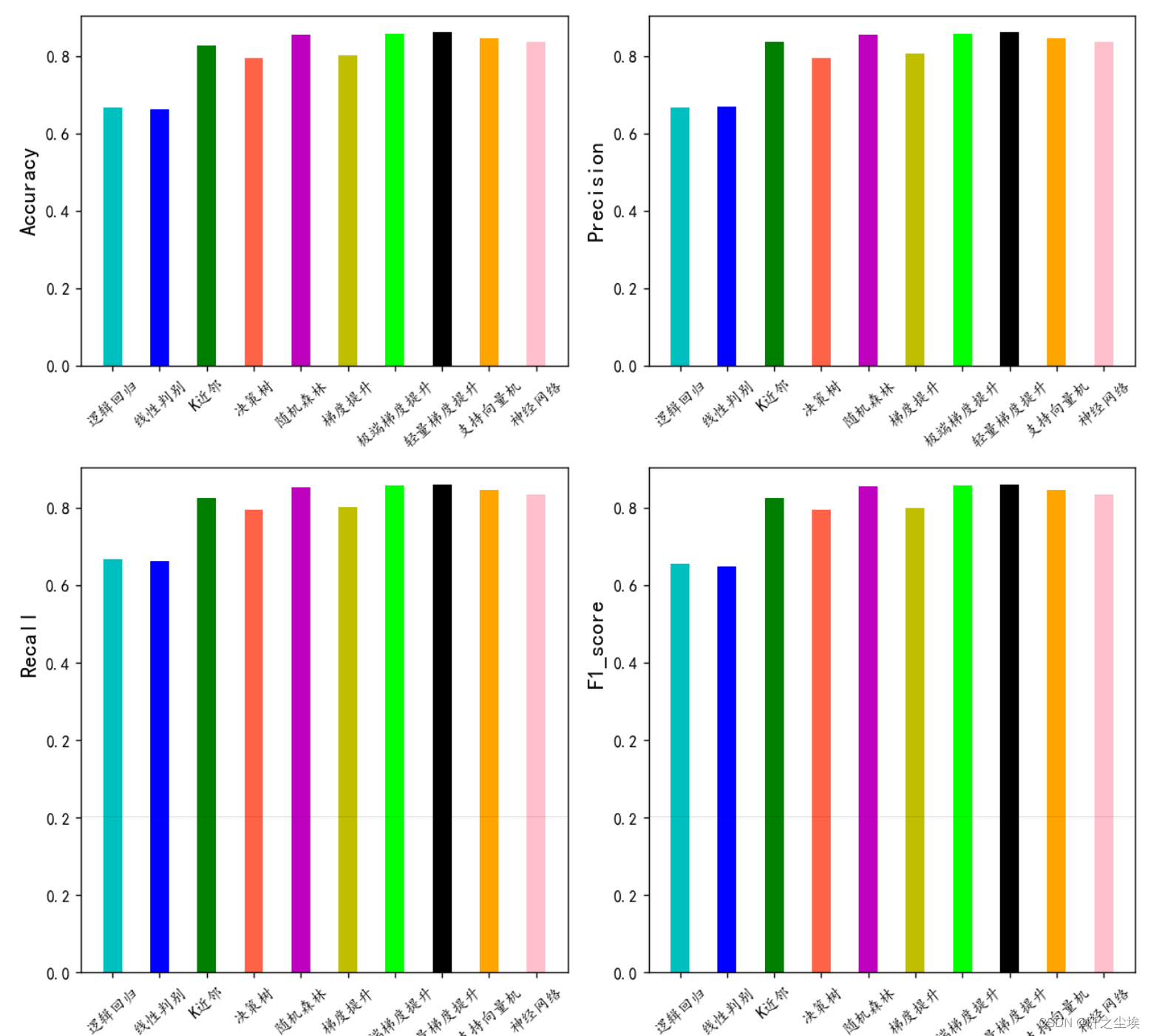
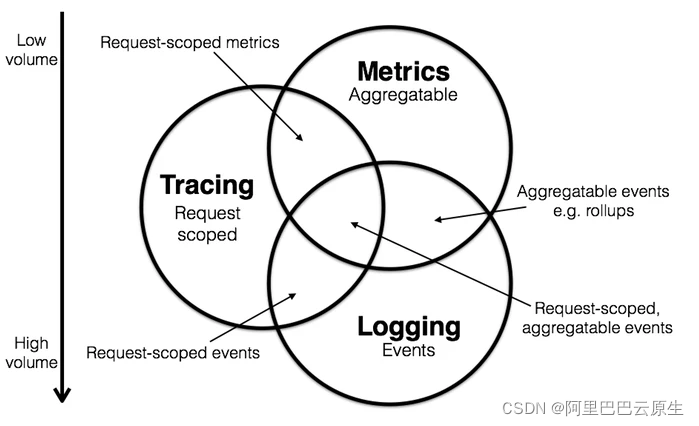
我们先看看一个典型服务问题排查过程是怎样的:
• 通过各式各样预设报警发现异常(Metrics/Logs)
• 打开监控大盘查找异常现象,并通过查询找到异常模块(Metrics)
• 对异常模块以及关联日志进行查询分析,找到核心的报错信息(Logs)
• 通过详细的调用链数据定位到引起问题的代码(Tracing)
为了能够获得更好的可观测性或快速解决上述问题,Tracing、Metrics、Logs缺一不可。
LOW
REQUEST-SCOPED METRICS
VOLUME
METRICS
AGGREGATABLE
TRACING
AGGREGATABLE EVENTS
E.G. ROLLUPS
REQUEST
SCOPED
REQUEST-SCOPED
LOGGING
AGGREGATABLE EVENTS
HIGH
EVENTS
REQUEST-SCOPED EVENTS
VOLUME
CSDN@阿里巴巴云原生
与此同时,行业中已经有了丰富的开源及商业方案,其中包括:
• Metric:Zabbix、Nagios、Prometheus、InfluxDB、OpenFalcon、OpenCensus
• Tracing:Jaeger、Zipkin、SkyWalking、OpenTracing、OpenCensus
• Logs:ELK、Splunk、SumoLogic、Loki、Loggly。
Opentelemetry
为了更好的将 Traces、Metrics 和 Logs 融合在一起,OpenTelemetry 诞生了。作为 CNCF 的孵化项目,OpenTelemetry 由 OpenTracing 和 OpenCensus 项目合并而成,是一组规范、API 接口、SDK、工具和集成。为众多开发人员带来 Metrics、Tracing、Logs 的统一标准,三者都有相同的元数据结构,可以轻松实现互相关联。
@稀士掘金技术社区

OPENTELEMETRY
@稀土掘金技术社区

Opentelemetry可以说是含着金汤匙出生:OpenTracing支持,OpenCensus支持,刚开始就自带经验丰富的的社区人员,同时背后也有互联网巨头的支持。
OpenTelemetry 与厂商、平台无关,不提供与可观测性相关的后端服务。可根据用户需求将可观测类数据导出到存储、查询、可视化等不同后端,如 Prometheus、Jaeger 、云厂商服务中。
优势
OpenTelemetry 核心优势集中在以下部分:
• 规范的制定和协议的统一
OpenTelemetry 采用基于标准的实现方法。对标准的关注对于 OpenTelemetry 来说尤其重要,因为需要追踪跨语言的互操作性。许多语言都带有类型定义,可以在实现中使用,例如用于创建可重用组件的接口。包括可观测客户端内部实现所需要的规范,以及可观测客户端与外部通信所需实现的协议规范。具体包括:
• API:定义 Metrics、Tracing、Logs 数据的类型和操作。
• SDK:定义 API 特定语言实现需求,定义配置、数据处理和导出概念。
• 数据:定义 OpenTelemetry Line Protocol (OTLP)。虽然在 Opentelemetry中组件支持了 Zipkin v2 或 Jaeger Thrift 协议格式的实现,但都以第三方贡献库形式提供。只有 OTLP 是 Opentelemetry 官方原生支持的格式。
OPEN TELEMETRY API
SEMANTIC
CONTEXT
TRACER
METER
CONVENTIONS
API
API
API
METER
SHARED CONTEXT
TRACER
PROPAGATOR
INSTRUMENT
SPAN
SPAN
PROCESSOR
PROCESSOR
AGGREGATOR
METRICREADER
SPAN
SPAN
METRIC
METRIC
EXPORTER
OPEN TELEMETRY SDK
EXPORTER
EXPORTER
EXPORTER
OPEN TELEMETRY
COLLECTOR
EXTENSION POINT
SPAN
METRIC
EXPORTER
EXPORTER
VENDOR INGEST
CSDN@阿里巴巴云原生
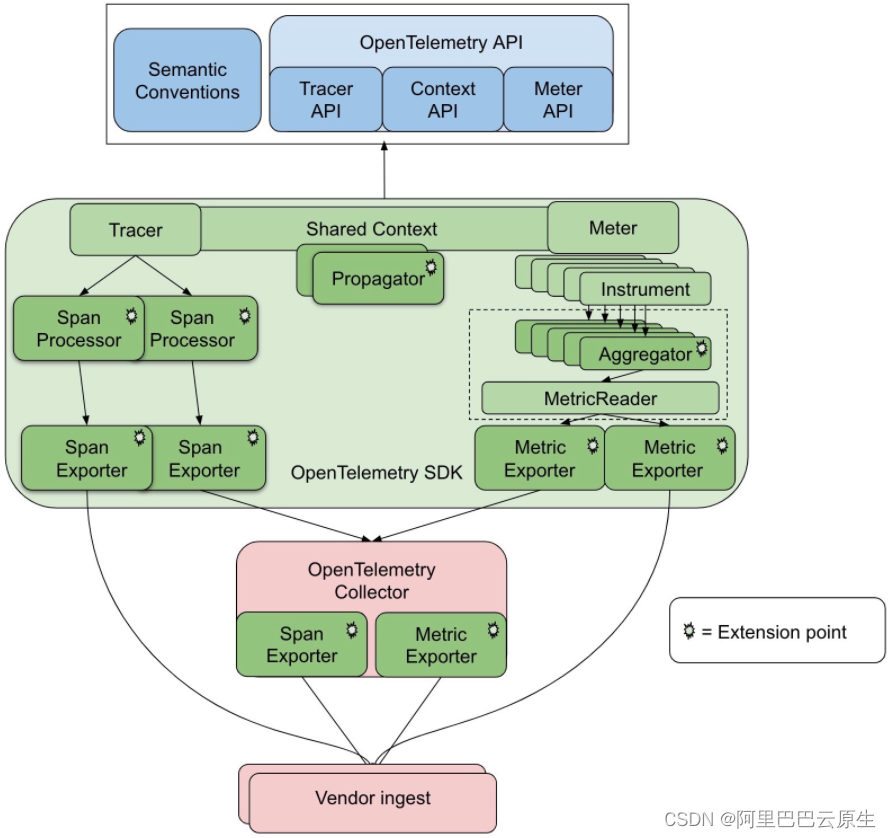
多语言 SDK 的实现和集成
OpenTelemetry 为每个常见语言都实现了对应 SDK,将导出器与 API 结合在一起。SDK 是具体的、可执行的 API 实现。包含 C++、.NET、Erlang/Elixir、Go、Java、JavaScript、PHP、Python、Ruby、Rust、Swift。
OpenTelemetry SDK 通过使用 OpenTelemetry API 使用选择的语言生成可观测数据,并将该数据导出到后端。并允许为公共库或框架增强。用户可以使用 SDK 进行代码自动注入和手动埋点,同时对其他三方库(Log4j、LogBack 等)集成支持;这些包一般都是根据 opentelemetry-specification 里面的规范与定义,结合语言自身的特点去实现在客户端采集可观测数据的基本能力。如元数据在服务间、进程间的传递,Trace 添加监测与数据导出,Metrics 指标的创建、使用及数据导出等。

数据收集系统的实现
在 Tracing 实践中有个基本原则,可观测数据收集过程需要与业务逻辑处理正交。尽量减少可观测客户端对原有业务逻辑的影响,Collector 是基于这个原则。OpenTelemetry 基于 OpenCensus Service 的收集系统,包括 Agent 和 Collector。Collector 涵盖采集(Collect)、转换(Transform)和导出(Export)可观测数据的功能,支持以多种格式(例如 OTLP、Jaeger、Prometheus 等)接收可观测数据,并将数据发送到一个或多个后端。它还支持在输出可观测数据之前,对其进行处理和过滤。Collector contrib 软件包支持更多数据格式和后端。
从架构层面来说,Collector 有两种模式。一种是把 Collector 部署在应用相同的主机内(如Kubernetes 的 DaemonSet),或者部署在应用相同的 Pod 里面(如Kubernetes 中的 Sidecar),应用采集到的遥测数据,直接通过回环网络传递给 Collector。这种模式统称为 Agent 模式。另一种模式是把 Collector 当作一个独立的中间件,应用把采集到的遥测数据往这个中间件里面传递。这种模式称之为 Gateway 模式。两种模式既可以单独使用,也可以组合使用,只需要数据出口的数据协议格式跟数据入口的数据协议格式保持一致。
SigNoz
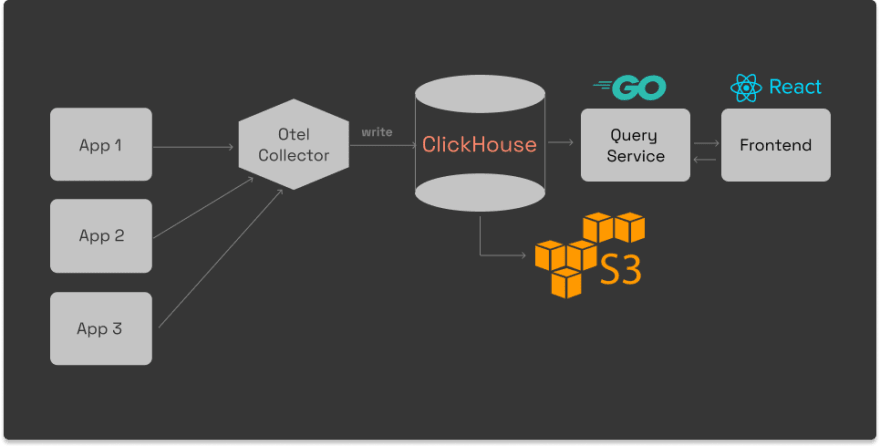
OpenTelemetry源自OpenSencuc和OpenTracing的合并,它的目标是集成Trace,Metrics,Logging能力来提供可观测性。过去的分布式追踪往往是各做各的,没有固定的标准,各个分布式追踪方案各显神通,使用不同的协议,不同的标准。但是OpenTelemetry不同,它提供了一系列的标准, 是一个与供应商无关的仪器库。它提供了一组工具、API 和 SDK 来创建和管理遥测数据(Trace,Metrics,Logging)。所以我们更倾向选择原生支持 OpenTelemetry 协议的工具。而目前火热的 SigNoz 就是一个好的选择。
SigNoz 是一个全栈开源应用程序性能监控和可观察性工具,旨在原生支持 OpenTelemetry。它还提供了一个快速的 OLAP 数据库——ClickHouse 作为存储后端。带有开箱即用的应用程序指标图表。
compare
SigNoz vs Prometheus
Prometheus is good if you want to do just metrics. But if you want to have a seamless experience between metrics and traces, then current experience of stitching together Prometheus & Jaeger is not great.
Our goal is to provide an integrated UI between metrics & traces - similar to what SaaS vendors like Datadog provides - and give advanced filtering and aggregation over traces, something which Jaeger currently lack.
SigNoz vs Jaeger
Jaeger only does distributed tracing. SigNoz supports metrics, traces and logs - all the 3 pillars of observability.
Moreover, SigNoz has few more advanced features wrt Jaeger:
Jaegar UI doesn’t show any metrics on traces or on filtered traces
Jaeger can’t get aggregates on filtered traces. For example, p99 latency of requests which have tag - customer_type='premium'. This can be done easily on SigNoz
SigNoz vs Elastic
SigNoz Logs management are based on ClickHouse, a columnar OLAP datastore which makes aggregate log analytics queries much more efficient
50% lower resource requirement compared to Elastic during ingestion
We have published benchmarks comparing Elastic with SigNoz. Check it out here
SigNoz vs Loki
SigNoz supports aggregations on high-cardinality data over a huge volume while loki doesn’t.
SigNoz supports indexes over high cardinality data and has no limitations on the number of indexes, while Loki reaches max streams with a few indexes added to it.
Searching over a huge volume of data is difficult and slow in Loki compared to SigNoz
We have published benchmarks comparing Loki with SigNoz. Check it out here
实践
Trace
无需改动代码,只要启动应用的时候加个代理就可以把全链路的数据传进Signoz里了。
java -javaagent:/agent/opentelemetry-javaagent.jar \
-Dotel.logs.exporter=otlp \
-Dotel.exporter.otlp.endpoint=http://172.34.91.29:4317 \
-Dotel.resource.attributes=service.name=service-provider \
-jar service-provider.jarLogging
这一块需要侵入应用程序,opentelemetry 使用 jaeger 生成 traceId,并可以和 logback 集成,通过 logback 的 mdc 注入到日志文件中。
<dependency>
<groupId>io.opentelemetry.instrumentation</groupId>
<artifactId>opentelemetry-spring-boot-starter</artifactId>
<version>1.22.1-alpha</version>
</dependency>
<dependency>
<groupId>io.opentelemetry.instrumentation</groupId>
<artifactId>opentelemetry-jaeger-spring-boot-starter</artifactId>
<version>1.22.1-alpha</version>
</dependency>
<dependency>
<groupId>io.opentelemetry.instrumentation</groupId>
<artifactId>opentelemetry-logback-mdc-1.0</artifactId>
<version>1.22.1-alpha</version>
</dependency>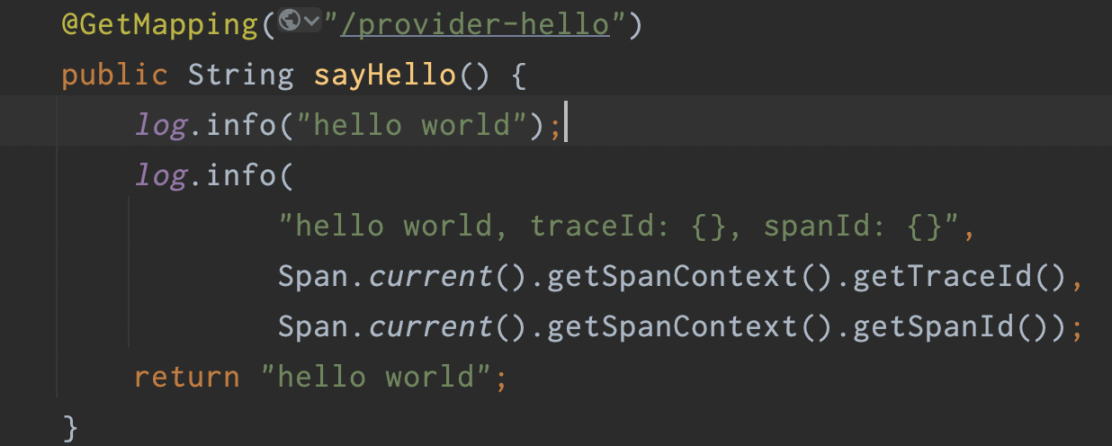


2、需要把我们的日志文件,导入到 Signoz 里。
Collecting Application Logs from Log file | SigNoz
Metrics
Send Metrics to SigNoz | SigNoz