目录
作者有话说
为何要学习跳表?为了快,为了更快,为了折磨自己.....
跳表作用场景
1.不少公司自己会设计哈希表,如果解决哈希冲突是不可避免的事情。通常情况下会使用链址,很好理解,当有冲突产生时,我们在附加的链表中添加一位(如果使用的循环双链表没直接在后面加,效率很高O(1)。如果是单链表也可以使用头插法直接在头部添加,效率很高O(1),如果使用跳表需要O(logN))。
2.看到这里不少朋友会觉得,那需要什么跳表呀,还变慢了。不要着急,我们继续往下看,首先使用简单的头差法,得到的序列可以认为是乱序(不考虑依次插入是有序的),那么查找起来会变得比较费劲,需要O(N)。但是使用跳表查找的平均效率是O(logN),插入O(logN),删除O(logN)。
【注意这里写的是平均情况,如果跳表设计不好,很容易导致跳表退化成链表】
3.跳表有时候可以代替红黑树和AVL树,甚至说跳表的插入和删除的维护比AVL树代价低与红黑树差不多。
跳表的主要思想
二分!二分!还是二分!
接触了这么久的编程,会发现很多比较优秀的算法都是基于二分思想演变而来的。
至于算法如何选择,需要结合具体的业务情况,一个算法的最好时间复杂度、平均时间复杂度、最坏时间复杂度都是需要考虑的。两个相同功能的算法在不同应用场景下会有很大是差距,即使平时我们都认为他们的时间复杂度都是O(logN).
与时间复杂度具有类似概念的就是空间复杂度了,空间复杂度也是需要考虑的问题。一个占据CPU、一个占据内存....
空间复杂度总是与时间复杂度此消彼长,他们向一对冤家。但是通常情况下,我们普遍接受在允许的内存消耗内,选择最快的算法。天下武功为快不破....
跳表的特点
1.单向链表(这个不是绝对的,如果想居于范围查找,使用双向链表会更快 ==> 未测试过)
2.有序保存(二分的前提条件)
3.支持添加、删除和查找
4.查找效率 O(logN)
跳表与普通链表的区别
普通单链表
对于普通的单链表,越靠前的节点,查找快。对于越靠后的节点查找效率越低。其平均效率 = (1+ 2 + 3 + ... + n) / n = (1/2 * n(a1+an))/n = (1 + n) / 2 ==> O(N)
简单的跳表
跳表的结构是通过建立高纬度的索引来减少低纬度从而达到任何元素的检索接近线性时间的目的O(logN)。其实跳表的思想并不复杂,为了提高查找效率将中间节点提高维度,在查找过程中逐步的对半减小查找过程。


跳表的建立
我们知道了跳表的基本思想后,我们来手动模拟建立一个跳表。现在我们依次顺序插入1 5 8 3 2 7 9 这七个元素。===> 【我们采用间隔一个的方式提取高纬度的节点】
1.初始化 ==> 准备一个头部节点,我们知道链表有两种方式(一种是有头节点的、一种是没有头节点的,为了方便对第一个节点的操作,我们统一使用有头节点的)。
注意:指针域这里没有画出来
2.插入 1 ==> 像单链表一样直接将节点插入到右边就可以了。
注意: 空白部分代表指针指向NULL,防止野指针
3.插入 5 ==> 这里考虑将向上提取元素(也可以不提取),先查找需要查找的位置,5 > 1所以插入到1的后面就可以了。
==> 为了保证隔一个的一致性和写代码时少考虑一种情况,我们还是向上提取 5
注意: 空白部分代表指针指向NULL,防止野指针
4. 插入 8 ==> 还是同样的道理,我们需要提取查找8所需要查找的位置。8 > 5因为提前做了5的提升,我们不需要比较1,然后再比较5,我们直接拿到5就可以知道8应该插入到5的后面,跳表的优势就表现出来了。
【这个过程插入过程分成了两个步骤,先在1维链表中插入8】
注意:空白部分代表指针指向NULL,防止野指针
注意: 空白部分代表指针指向NULL,防止野指针
5.插入 3 ==> 我们先比较 5 > 3,那么整个范围变成了 【1-5】,然后 1 < 3 < 5 。那么需要将3插入到1和5之间
【将3插入,按两个提取的原则,需要将3提升,然后 3、5在同一层,需要将5提升】
注意:空白部分代表指针指向NULL,防止野指针
6.插入 2 ==> 过程同上面一样。不做过多的解释了....
【画图不易,点个关注吧....只输出优质文章:大家有什么想算法,可以下方留言】
注意:空白部分代表指针指向NULL,防止野指针
7.插入 7 ==> 过程同上面一样。不做过多的解释了....
注意:空白部分代表指针指向NULL,防止野指针
8.插入 9 ==> 过程同上面一样。不做过多的解释了....
注意:空白部分代表指针指向NULL,防止野指针
【以上就是跳表建立的全部过程,如果不明白可以加入微信C++技术交流群:C++技术交流群-陈达叔】
【bilibili 搜索 陈达叔视频后续会更新,感谢大家关注....创作不易,点个关注吧...】
跳表的查找
跳表的查找很简单,就是二分查找的逻辑,为了更好的了解查找的过程,我们来看下示例...
示例1: 查找 3
先比较 5 ==> 3 < 5 ==> 查找范围变成 1-5之间
然后 header向下移动一位,比较 3 == 3 ==> 找到 3 返回 true
示例2:查找 9
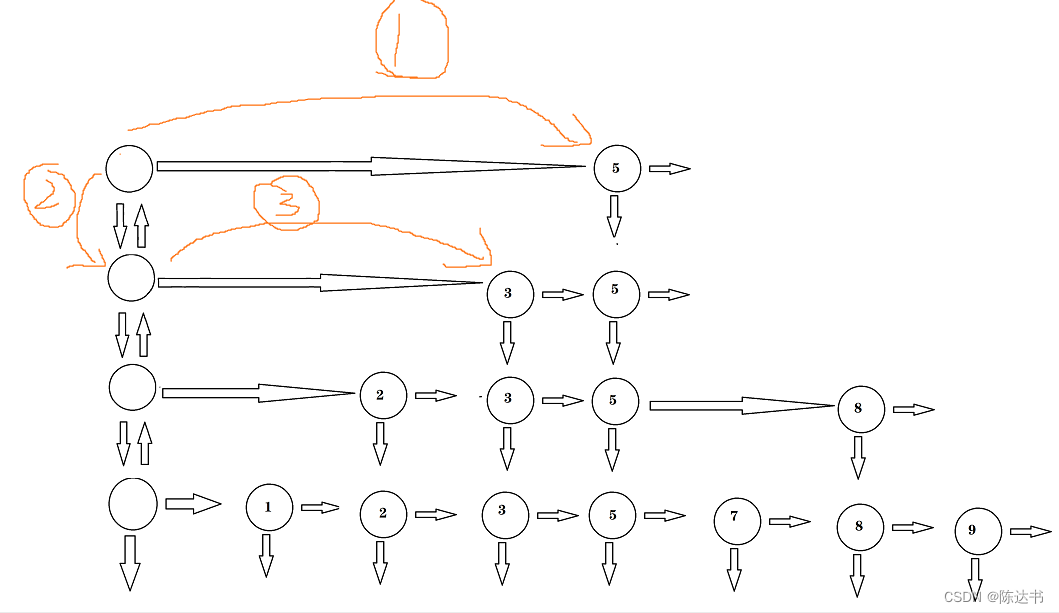
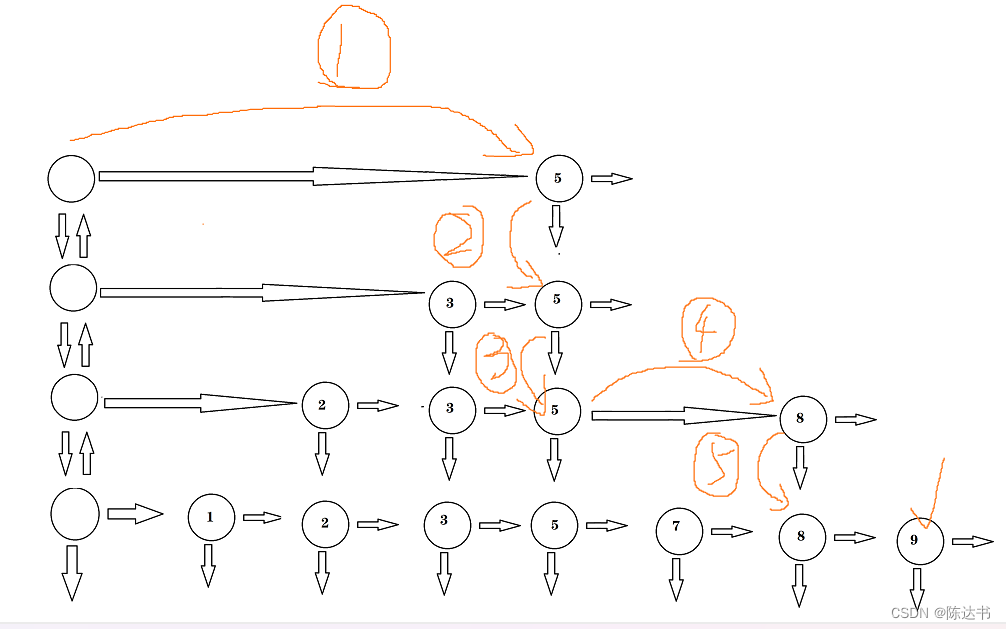
跳表的删除
跳表的查找很简单,就是二分查找的逻辑,为了更好的了解查找的过程,我们来看下示例...
示例1:删除 2
为了防止不断是增加,层数过高,我们可以做个调整
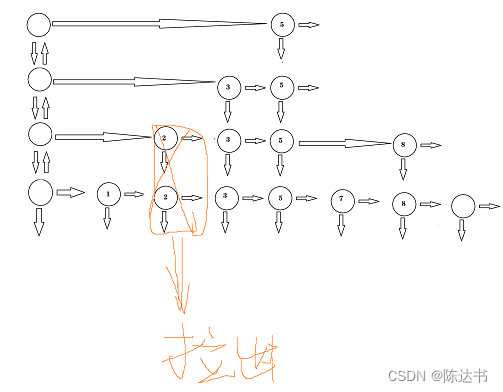
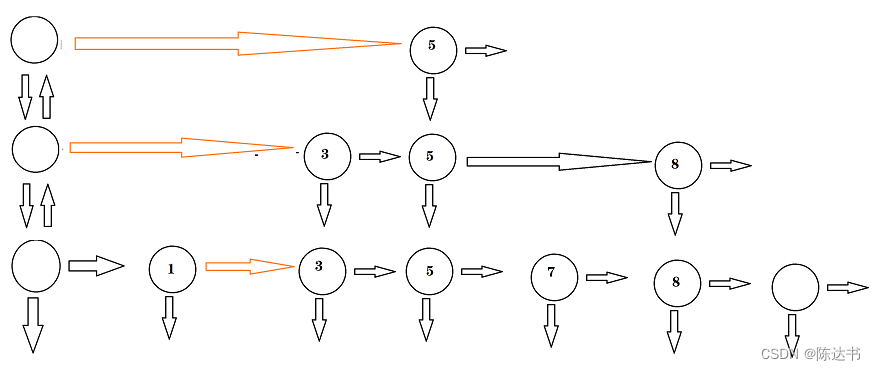
跳表的提取维度说明
不难发现,跳表的实现就是对数据做了向上的冗余操作,以时间换空间的的典型。
当我们设置的冗余颗粒越小,那么需要的空间越大。所以选择好的冗余颗粒度很重要,这个需要根据具体情况而定。
再跳表存在一个随机函数,其存在的意义是决定什么时候需要向上做冗余。实际的建造过程不会像我们示例一样的建造,这样代价会比较高。为了防止跳表插入节点增加而导致退化成链表的情况,我们通常通过一个随机函数来决定向上做提升的时刻。
跳表的代码
#pragma once #ifndef SKIPLIST_ENTRY_H_ #define SKIPLIST_ENTRY_H_ /* 一个更具备代表性的泛型版本 */ #include <ctime> #include <cstdlib> template<typename T> class Entry { private: int key; // 排序值 T value; // 保存对象 Entry* pNext; Entry* pDown; public: Entry(int k, T v) :value(v), key(k), pNext(nullptr), pDown(nullptr) {} Entry(const Entry& e) :value(e.value), key(e.key), pNext(nullptr), pDown(nullptr) {} public: /* 重载运算符 */ bool operator<(const Entry& right) { return key < right.key; } bool operator>(const Entry& right) { return key > right.key; } bool operator<=(const Entry& right) { return key <= right.key; } bool operator>=(const Entry& right) { return key >= right.key; } bool operator==(const Entry& right) { return key == right.key; } Entry*& next() { return pNext; } Entry*& down() { return pDown; } }; template<typename T> class SkipList_Entry { private: struct Endpoint { Endpoint* up; Endpoint* down; Entry<T>* right; }; struct Endpoint* header; int lvl_num; // level_number 已存在的层数 unsigned int seed; bool random() { srand(seed); int ret = rand() % 2; seed = rand(); return ret == 0; } public: SkipList_Entry() :lvl_num(1), seed(time(0)) { header = new Endpoint(); } /* 插入新元素 */ void insert(Entry<T>* entry) { // 插入是一系列自底向上的操作 struct Endpoint* cur_header = header; // 首先使用链表header到达L1 while (cur_header->down != nullptr) { cur_header = cur_header->down; } /* 这里的一个简单想法是L1必定需要插入元素,而在上面的各跳跃层是否插入则根据random确定 因此这是一个典型的do-while循环模式 */ int cur_lvl = 0; // current_level 当前层数 Entry<T>* temp_entry = nullptr; // 用来临时保存一个已经完成插入的节点指针 do { Entry<T>* cur_cp_entry = new Entry<T>(*entry); // 拷贝新对象 // 首先需要判断当前层是否已经存在,如果不存在增新增 cur_lvl++; if (lvl_num < cur_lvl) { lvl_num++; Endpoint *new_header = new Endpoint(); new_header->down = header; header->up = new_header; header = new_header; } // 使用cur_lvl作为判断标准,!=1表示cur_header需要上移并连接“同位素”指针 if (cur_lvl != 1) { cur_header = cur_header->up; cur_cp_entry->down() = temp_entry; } temp_entry = cur_cp_entry; // 再需要判断的情况是当前所在链表是否已经有元素节点存在,如果是空链表则直接对右侧指针赋值并跳出循环 if (cur_header->right == nullptr) { cur_header->right = cur_cp_entry; break; } else { Entry<T>* cursor = cur_header->right; // 创建一个游标指针 while (true) { // 于当前链表循环向右寻找可插入点,并在找到后跳出当前循环 if (*cur_cp_entry < *cursor) { // 元素小于当前链表所有元素,插入链表头 cur_header->right = cur_cp_entry; cur_cp_entry->next() = cursor; break; } else if (cursor->next() == nullptr) { // 元素大于当前链表所有元素,插入链表尾 cursor->next() = cur_cp_entry; break; } else if (*cur_cp_entry < *cursor->next()) { // 插入链表中间 cur_cp_entry->next() = cursor->next(); cursor->next() = cur_cp_entry; break; } cursor = cursor->next(); // 右移动游标 } } } while(random()); } /* 查询元素 */ bool search(Entry<T>* entry) const { if (header->right == nullptr) { // 判断链表头右侧空指针 return false; } Endpoint* cur_header = header; // 在lvl_num层中首先找到可以接入的点 for (int i = 0; i < lvl_num; i++) { if (*entry < *cur_header->right) { cur_header = cur_header->down; } else { Entry<T>* cursor = cur_header->right; while (cursor->down() != nullptr) { while (cursor->next() != nullptr) { if (*entry <= *cursor->next()) { break; } cursor = cursor->next(); } cursor = cursor->down(); } while (cursor->next() != nullptr) { if (*entry > *cursor->next()) { cursor = cursor->next(); } else if (*entry == *cursor->next()) { return true; } else { return false; } } return false; // 节点大于L1最后一个元素节点,返回false } } return false; // 找不到接入点,则直接返回false; } /* 删除元素 */ void remove(Entry<T>* entry) { if (header->right == nullptr) { return; } Endpoint* cur_header = header; Entry<T>* cursor = cur_header->right; int lvl_counter = lvl_num; // 因为在删除的过程中,跳跃表的层数会中途发生变化,因此应该在进入循环之前要获取它的值。 for (int i = 0; i < lvl_num; i++) { if (*entry == *cur_header->right) { Entry<T>* delptr = cur_header->right; cur_header->right = cur_header->right->next(); delete delptr; } else { Entry<T> *cursor = cur_header->right; while (cursor->next() != nullptr) { if (*entry == *cursor->next()) { // 找到节点->删除->跳出循环 Entry<T>* delptr = cursor->next(); cursor->next() = cursor->next()->next(); delete delptr; break; } cursor = cursor->next(); } } // 向下移动链表头指针的时候需要先判断当前链表中是否还存在Entry节点 if (cur_header->right == nullptr) { Endpoint* delheader = cur_header; cur_header = cur_header->down; header = cur_header; delete delheader; lvl_num--; } else { cur_header = cur_header->down; } } } }; #endif // !SKIPLIST_ENTRY_H_
对于C++的学习,存在一个的最大问题就是很少可以交流的人,甚至而言网上的资料又比较少。
如果对c++有疑惑或者想要交流的朋友记得加入V: Errrr113
坚持初心,勇敢果断....至每一个热爱技术的朋友!!!