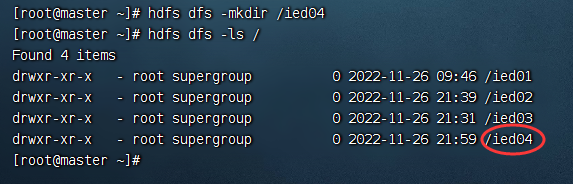
回归问题是一种常见的监督机器学习任务,在很多领域均有广泛应用。其典型应用包括销量预测、库存预测、股票价格预测、天气预测等。本问将讨论线性回归,包括线性回归模型的目标函数(损失函数和正则函数)、线性回归模型的优化求解、回归任务的性能指标、线性回归模型的超参数调优以及使用sklearn实现线性回归模型的应用案例。
线性回归简介
回归分析:回归分析法指利用数据统计原理,对大量统计数据进行数学处理,并确定因变量Y与某些自变量X的相关关系,建立一个相关性较好的回归方程(函数表达式),并加以外推,用于预测今后的因变量的变化分析方法。回归的目标是学习一个输入X到输出Y的映射f,并根据该模型预测新的测试数据x对应的响应y=f(x),公式:
f
(
x
,
w
)
=
w
T
+
b
f(x,w) = w^T+b
f(x,w)=wT+b
线性回归模型,包括一元线性回归模型、多元线性回归和多项式线性回归模型等。
- 依据定义的因变量与单个自变量可以构建如下模型:Y = w0 + w1 x (简单线性回归)
- 依据定义的因变量与多个自变量可以构建如下模型:Y = w0 + w1x1 + w2x2 +…+wnxn(多元线性回归)
- 依据定义的因变量与多个自变量可以构建如下模型:Y = w0 + w1x + w2x2 + …+ wnxn(多项式线性回归)
核心思想:从连续型统计数据中得到数学模型,然后将该数学模型用于预测。
回归是用来估计数据元素之间的数值关系
用来处理回归问题的,主要对数值型数据进行预测
应用:如股票预测,网站点击量预测等等
一元线性回归
线性回归模型是利用线性拟合的方式探寻数据背后的规律。先通过搭建线性回归模型寻找这些散点(也称样本点)背后的趋势线(也称回归曲线),再利用回归曲线进行一些简单的预测分析或因果关系分析。
在线性回归中,我们根据特征变量(也称自变量)来预测反应变量(也称因变量)。根据特征变量的个数可将线性回归模型分为一元线性回归和多元线性回归。
一元线性回归模型又称为简单线性回归模型,其形式可以表示为:y=ax+b,其中,y为因变量,x为自变量,a为回归系数,b为截距。
示例:
| 输入(x) | 输出(y) |
|---|---|
| 0.5 | 5.0 |
| 0.6 | 5.5 |
| 0.8 | 6.0 |
| 1.1 | 6.8 |
| 1.4 | 7.0 |
| … | … |
import matplotlib.pyplot as plt
x = [0.5, 0.6, 0.8, 1.1, 1.4]
y = [5.0, 5.5, 6.0, 6.8, 7.0]
plt.scatter(x,y)

预测(目标)函数:y = w0+w1x
x: 输入
y: 输出
w0和w1: 模型参数
所谓模型训练,就是根据已知的x和y,找到最佳的模型参数w0 和 w1,尽可能精确地描述出输入和输出的关系。
5.0 = w0 + w1 × 0.5
5.5 = w0 + w1 × 0.6

单样本误差:
根据预测函数求出输入为x时的预测值:y’ = w0 + w1x,单样本误差为(y - y’)2。
总样本误差:
把所有单样本误差相加即是总样本误差:

损失函数
所以损失函数就是总样本误差关于模型参数的函数,该函数属于三维数学模型,即需要找到一组w0 ,w1使得loss取极小值。
**核心:**找到w0和w1的值,使得预测值和真实值之间的平均差异最小。
**损失:**机器学习模型关于单个样本的预测值与真实值的差,损失越小,模型越好;如果预测值与真实值相等,就是没有损失。
**损失函数:**用于计算损失的函数模型每一次预测的好坏用损失函数来度量。
常见的损失函数:
- 平均平方误差(Mean Squared Error (MSE)):也称为 L2 Loss,是机器学习、深度学习回归任务中最常用的一种损失函数,对离群点敏感。
- 平均绝对误差( Mean Absolute Error(MAE)):也称为L1 Loss,使用绝对值,L1损失对离群点不敏感。
- 胡伯损失(Huber):综合了L2损失和L1损失的优点。
线性回归模型的优化求解
模型的目标函数确定后,我们就可以采用合适的优化方法寻找最佳的模型参数。在线性回归模型中,模型参数包括线性回归系数w1,和截距w0。 当训练数据集不大时,最小二乘线性回归可采用解析求解法求解,解析求解法涉及到大量公式推导,此处暂不做讲解。除此以外还可以使用梯度下降法求解。
梯度下降(Gradient Descent)
梯度下降法是求解无约束优化问题最常用的方法之一,亦被称为最速下降法。最小二乘回归和岭回归均可采用梯度下降法求解,Lasso回归由于目标函数中有L1正则函数而不可导,因此不能采用梯度下降法求解。梯度下降法是一种基于搜索的最优化方法,在机器学习中,熟练的使用梯度法(下降法或上升法)求取目标函数的最优解是非常重要的。线性回归算法模型的本质就是最小化一个损失函数,然后求出损失函数的参数的数学解; 梯度下降法是在机器学习领域中最小化损失函数的最为常用的方法。

假如你迷失在山上的浓雾之中,完全看不见下山的方向,你能感觉到的只有脚下的路面坡度。快速到达山脚的一个策略就是沿着最陡的方向下坡。这就是梯度下降的做法:通过测量参数向量θ相关的损失函数的局部梯度,并不断沿着降低梯度的方向调整,直到梯度将为0,达到最小值! 每下降一步都去选择最陡峭的方向,然后踏出一步。因此没迭代一次需要考虑两个变量,一个是方向(朝哪边走),一个是步长(走多少)。方向就是向量θ的斜率,步长是一个超参数叫做学习率(learning_rate)。
学习速率(learning_rate)
学习率是一个超参数,常用字母η表示,学习率的取值会影响获得最优解的速度;η 太小,算法需要经过大量迭代才能收敛,这将耗费很长时间;反过来学习率太大,可能会越过最小值直接到达另一边,甚至有可能比之前的起点还要高,这会导致算法发散,值越来越大,无法找到最优解。学习率是超参数需要手动调节,取值范围一般在[0, 1]之间。下图展示了不同学习率对梯度下降的影响。

梯度下降陷阱
并不是所有的损失函数都是二次曲线(看起来像碗),有的可能看着像洞、山脉、高原或者各种不规则的地形,导致很难收敛到最小值。如下图所示,梯度下降的两个主要挑战:如果随机初始化θ,算法从左侧起步,那么会收敛到一个布局最小值,而不是全局最小值。如果从右侧起步,那么需要很长时间才能越过正片“高原”,如果迭代次数太少,将永远无法到达全局最小值。

幸好,线性回归模型的MSE损失函数恰好是一个凸函数,这意味着连接曲线上任意两点的线段永远不会根曲线相交。也就是说不存在局部最小值,只有一个全局最小值。同时它也是一个连续函数,所以斜率不会产生陡峭的变化。这两点保证即便是乱走,MSE损失函数的梯度下降都可以趋近到全局最小值,只需要等待足够的时间,学习率也不需要太高。MSE损失函数虽然是碗状的,但有些时候如果不同特征的尺寸差距巨大,那么它也有可能是一个非常平坦的碗,像盘子一样。这样的话虽然最终还是会抵达最小值,但是这需要花费大量的时间。因此应用梯度下降时,需要保证所欲特征值的大小比例都差不多(比如使用特征工程对数据进行预处理,标准化 StandarScaler),否则收敛的时间会很长。
要实现梯度下降,你需要计算每个模型关于参数θj,损失函数会改变多少。这被称为偏导数。关于参数θj的损失函数的偏导数,计作:

公式推导太难写,此处省略…
梯度下降有很多种类可以选择,不同种类有各自的特点,下面将介绍梯度下降的分类
梯度下降分类
批量梯度下降:
在计算梯度下降的每一步时,都是基于完整的训练集X的。这就是为什么该算法被称为批量梯度下降,每一步都使用整批训练数据。因此面对非常庞大的训练集时,算法会变得极慢。但是,梯度下降算法随特征数量扩展的表现比较好。如果要训练的线性模型拥有几十万个特征,使用梯度下降比标准方程或者SVD要快很多。并且能够达到最小值,在最小值处停止。一旦有了梯度向量,哪个点向上,就朝反方向下坡。也就是θ-ΔMSE(θ)。这时学习率η就发挥作用了:用梯度向量乘以η确定下坡步长的大小,梯度下降的公式:
θ(下一步)=θ-ηΔMSE(θ)
批量梯度下降的主要问题是它要用整个训练集来计算每一步的梯度,所以训练集很大时,算法会特别慢。与之相反的就是随机梯度下降。

随机梯度下降:
随机梯度下降每一步在训练集中随机选择一个实例,并且仅基于该单个实例来计算梯度。显然这让算法变得快很多,因为每次迭代都只需要操作少量的数据。它也可以被用来训练海量的数据集,因此每次迭代只需要在内存中运行一个实例即可。另一方面,由于算法的随即性质,它比批量梯度下降要不规则的多。损失函数将不再是缓缓降低直到最小值,而是不断上下波动,但从整体来看,还是在慢慢下降。随着时间的推移最终会非常接近最小值,但是即使它到达了最小值,依然还会持续反弹,永远不会停止。所以算法停下来的参数值肯定时足够好的,但不是最优的。
当损失函数非常不规则时,随机梯度下降其实可以帮助算法跳出局部最小值,所以相比批量梯度下降,它对找到全局最小值更有优势。随机性的好处在于可以逃离局部最优,但缺点是永远定位不出最小值。要解决这个困境,可以通过逐步降低学习率。开始的步长比较大,然后越来越小,让算法尽量靠近全局最小值。这个过程叫做模拟退火。

由于实例是随机选取的,因此某些实例可能每个轮次中被选取几次,而其他实例则可能根本不被选取。如果要确保算法在每个轮次都遍历每个实例,则另一种方法是对训练集进行混洗(确保同时对输入特征和标签进行混洗),然后逐个实例进行遍历,然后对其进行再次混洗,以此类推。但是这种方法通常收敛缓慢。
小批量梯度下降
小批量梯度下降在每一步中,不是根据完整得训练集或仅基于一个实例来计算梯度,小批量梯度下降在称为小型批量的随机实例集上计算梯度。小批量梯度下降优于随机梯度下降的主要优点是,可以通过矩阵操作的硬件优化来提高性能,特别是在使用GPU时。小批量梯度下降最终将比随机梯度下降走得更接近最小值,但它可能很难摆脱局部最小值。
以下三种梯度下降类型得比较图:

线性回归算法的比较
m为训练实例的数量(行数,样本数量),n为特征数量(列数)
| 算法 | m很大 | 核外支持 | n很大 | 超参数 | 要求缩放 | Scikit-Learn |
|---|---|---|---|---|---|---|
| 标准方程 | 快 | 否 | 慢 | 0 | 否 | N/A |
| SVD | 快 | 否 | 慢 | 0 | 否 | LinearRegression |
| 批量GD | 慢 | 否 | 快 | 2 | 是 | SGDRegressor |
| 随机GD | 快 | 是 | 快 | >=2 | 是 | SGDRegressor |
| 小批量GD | 快 | 是 | 快 | >=2 | 是 | SGDRegressor |
多变量函数的梯度下降
左边是假设函数,右边是损失函数。因为有两个参数θ0和θ1,这使得我们的损失函数在三维图形上类似一个碗型。根据不同的训练集,会得到不同的碗型,底部平面的任何一个点表示了一个θ0和θ1,而这个三维图形在该点上的垂直高度即代表了相应的损失函数值。

以上内容为简单线性回归的原理以及一些概念,学习回归分析必须掌握的内容。