循环队列:
解决假上溢的方法:引入循环队列(判断是否溢出)
将入队操作由:
base[rear]=x;
rear++;
准确的来说,是:
Q.base[Q.rear]=x;
Q.rear++;
改为
Q.base[Q.rear]=x;
Q.rear=(Q.rear+1)% MAXQSIZE;
将出队操作由:
x=base[front];
front++;
改为
x=Q.base[s.front]
Q.front=(Q.front+1)%MAXQSIZE
准确(总的)来说:
就是将两指针自增的操作改(改进优化)为自增并取余的操作
这样,我们就实现了让队列形成一个循环顺序的结构:
后面新加进来的元素全部都可以重新从队列的数组(的)头部重新实现排序(按顺序)插入
Q:
如何判断和重新插入的时候数组里面已经清空了元素???
A:
首先,根据队列的结构特性,其数据存储形式必定是属于连续存储的形式
所以队头和队尾之外的数组空间内必定是没有我们所需要的、有用的数据在数组当中的
综上所述,在我们不断进行新插入元素的情况之下
除非出现两指针(位序)相等,即真(的)队满溢出的情况
新插入元素存储的位置里面一定是没有(有用的)数据元素的
循环队列解决队满时判断方法:少用一个元素空间
原本:

队空:front==rear
队满:front==rear
此时 无法区分:队空和队满 两种情况
注:
这里我们特别需要注意,队尾指针(rear)指向的位置
并不是队列最后插入的元素(队尾)的位置,而是队列最后插入的元素(队尾)的后一位的位置
如何实现少用一个元素空间:(实现区分判断队空和队满)
(rear+1) % MAXQSIZE = front;
当该语句为真,即:
当队尾指针(队列最后插入的元素(队尾)的后一位的位置)再往下面前进一格即为队头指针
也就是说,此时队列当中必定还有一个空着的位置(空间)
rear队尾指针就指向这一空间
如果我们在此时(这种情况下)判定这种队列中空着一个元素空间的情况为队满的情况
那我们就实现了:区分开队空和队满判断语句 的功能
解决了上面无法区分开队空和队满判断语句的问题,即:
当
(rear+1) % MAXQSIZE = front;
为真,判定为队满
前置条件:
//线性表的定义及其基础操作
#include<iostream>
using namespace std;
#include<stdlib.h>//存放exit
#include<math.h>//OVERFLOW,exit
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
#define MAXlength 100 //初始大小为100,可按需修改
typedef int Status; //函数调用状态
struct Poly
{
float p;
int e;
bool operator==(Poly t)
{
return t.p == p && t.e == e;
}
bool operator!=(Poly t)
{
return t.p != p || t.e != e;
}
};
struct Sqlist
{
Poly* elem;
int length;
};
typedef Poly QElemType;
struct SqQueue
{
QElemType* base;//初始化的动态分配存储空间
int rear;//头指针
int front;//尾指针
};rear:后面的
操作汇总:
初始化
求长度
取队头元素
入队和出队
PPT上没写(实用性不大)的操作:
销毁与清空
初始化:
project 1:
Status InitQueue(SqQueue &Q)//初始化
{
Q.base = new QElemType[MAXQSIZE];
Q.rear = Q.front = 0;
return true;
}但是这里我们忘了存储分配失败的情况:
if (!Q.base) exit(OVERFLOW);//存储分配失败
project 2:
Status InitQueue(SqQueue &Q)//初始化
{
Q.base = new QElemType[MAXQSIZE];
//Q.base = (QElemType*)malloc(MAXQSIZE * sizeof(QElemType));
if (!Q.base) exit(OVERFLOW);//存储分配失败
Q.rear = Q.front = 0;
return true;
}注意:同样的,这里开辟空间不能写成如下形式:
QElemType Q.base = new QElemType[MAXQSIZE];
详情详见:
数据结构与算法基础(王卓)(8)附:关于new的使用方法详解_宇 -Yu的博客-CSDN博客_数据结构new
求长度:
Status Queuelength(SqQueue Q)//求长度
{
return(Q.rear - Q.front + MAXQSIZE) % MAXQSIZE;
}为什么必须要加一轮进制数,原因出在C++取余算法的运行机制当中:
在编译器中,两个异号的数取余之后的结果取决于分子(被除数)的符号
负数%负数,编译器会将分母的负数自动转换为正整数,
然后再将分子负数的负号提取出来,将两个正整数取余,最后的结果加上负号
负数%正数,编译器先将分子负数的负号提取出来,将两个正整数取余,最后结果加上负号
正数%负数:
编译器自动将分母负数转换为正整数,然后两个正整数取余得到就是最终结果
比如说:
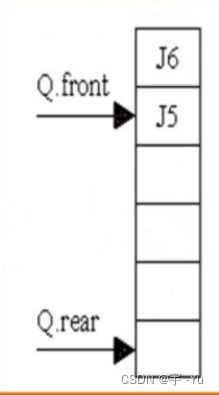
理论上我们知道两指针在该情况下和+2一样,都只差两个身位(位置),但是实际情况就是:
- 4 mod 6 = - 4;
2 mod 6 = 2 ;
所以在此,我们必须在被除数的基础之上再加一层进制数,来确保我们求数据长度函数的运算没有问题
取队头元素:
QElemType GetHead(SqQueue Q)//取队头元素
{
if (Q.front != Q.rear)
//别忘排除空表的情况
return(Q.base[Q.front]);
}
别忘排除空表的情况!
入队和出队:
Status EnQueue(SqQueue& Q, QElemType e)//入队
{
if ((Q.rear + 1) % MAXQSIZE == Q.front)
return OVERFLOW;
Q.base[Q.rear] = e;
//这里rear只是下标,不是指针,所以只能这样用
Q.rear = (Q.rear + 1) % MAXQSIZE;
return true;
}
Status DeQueue(SqQueue& Q, QElemType e)//出队
{
if (Q.front == Q.rear)
return NULL;
e = Q.base[Q.front];
Q.front = (Q.front + 1) % MAXQSIZE;
return true;
}链式队列:
初始化,销毁,入队,出队,求顶部元素
前置条件:
//链表的定义及其基础操作
#include<iostream>
using namespace std;
#include<stdlib.h>//存放exit
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
typedef int Status; //函数调用状态
struct K
{
float a;
int b;
string c;
bool operator==(K& t)
{
return t.a == a && t.b == b;
//&& t.c = c;
}
bool operator!=(K& t)
{
return t.a != a || t.b != b;
//|| t.c = c;
}
};
typedef K Elemtype; //函数调用状态
struct Lnode
//node:结; 结点;
{
Elemtype data;
Lnode* next;
};
typedef Lnode* LinkList;
typedef K QElemType;
typedef int Status; //函数调用状态
#define MAXQSIZE 100 //初始大小为100,可按需修改
struct QNode//一个链队结点的结构
{
QElemType data;
QNode* next;
};
typedef QNode* QuenePtr;//Pointer
struct LinkQueue
{
QuenePtr front; // 队头指针
QuenePtr rear; // 队尾指针
};
int main()
{
}初始化
Status InitQueue(LinkQueue& Q)//初始化
{
Q.front = Q.rear = new QNode;
if (!Q.front)
return false;
Q.rear->next = NULL;
return true;
}销毁
project 1:
Status DesQueue(LinkQueue& Q)//销毁
{
while (Q.rear)
{
auto p = Q.rear->next;
delete Q.rear;
Q.rear = p;
}
return true;
}注意,我们从头往后一个一个销毁,用的是front指针而不是rear指针
最终成品:
Status DesQueue(LinkQueue& Q)//销毁
{
while (Q.front)
{
QNode* p = Q.front->next;
delete (Q.front);
Q.front = p;
}
//也可以直接指定指针rear暂时储存Q.front->next的地址,反正他放在这闲着也没事
//Q.rear=Q.front->next; free(Q.front); Q.front=Q.rear;
return OK;
}注意,这里因为我们前面开辟空间时用的是new,所以这里写的是delete
如果根据PPT上面的malloc开辟空间,释放空间的语句就应该用free,详见:
free 与 delete 区别_free delete_460833359的博客-CSDN博客
入队:
Status EnQueue(LinkQueue& Q, QElemType e)//入队
{
QNode* p = new QNode;
//QNode* p = (QuenePtr)malloc(sizeof(QNode));
p->data = e;
p->next = NULL;
Q.rear->next = p;
Q.rear = p;
return OK;
}注意:从这里我们就能知道:
链队的头指针指向的是一个空着的结点
出队:
project 1:
Status DeQueue(LinkQueue& Q, QElemType e)//出队
{
QNode* p = Q.front->next;
delete Q.front;
Q.front = p;
return true;
}参考PPT完善程序:
注意:
链队的头指针指向的是一个空着的结点
(1):链队指向的第一个节点是一个头结点,不是队列的第一个元素
所以其实整个程序需要全部重新翻新修改
(2):根据新顺序,让头指针找到出队后的队列的队头
Q.front->next = p->next;
(3):出队之前,需先判断队列是否为空
if (Q.front == Q.rear) return ERROR;
project 2:
Status DeQueue(LinkQueue& Q, QElemType e)//出队
{
QNode* p = Q.front->next;
e = p->data;//保存删除的信息
Q.front->next = p->next;
delete p;
return true;
}(4):如果删除到最后队列当中就只有一个元素节点了
那么这时尾指针的位置也需要做出调整改变:
if (Q.rear == p) Q.rear = Qfront;
如果不作出调整(即不写这个(句)语句),就会导致删除结点以后我们对队尾指针也没了
队列中只剩下front指针
最终成品:
Status DeQueue(LinkQueue& Q, QElemType e)//出队
{
if (Q.front == Q.rear) return ERROR;
QNode* p = Q.front->next;
e = p->data;//保存删除的信息
Q.front->next = p->next;
if (Q.rear == p)
Q.rear = Q.front;
delete p;
return true;
}求链队列的队头元素:
Status GetHead(LinkQueue Q, QElemType& e)
{
if (Q.front == Q.rear) return ERROR;
e = Q.front->next->data;
return OK;
}