5.5 实时窗口统计
SparkStreaming中提供一些列窗口函数,方便对窗口数据进行分析,文档:
http://spark.apache.org/docs/2.4.5/streaming-programming-guide.html#window-operations
在实际项目中,很多时候需求:每隔一段时间统计最近数据状态,并不是对所有数据进行统计,称为趋势统计或者窗口统计,SparkStreaming中提供相关函数实现功能,业务逻辑如下:
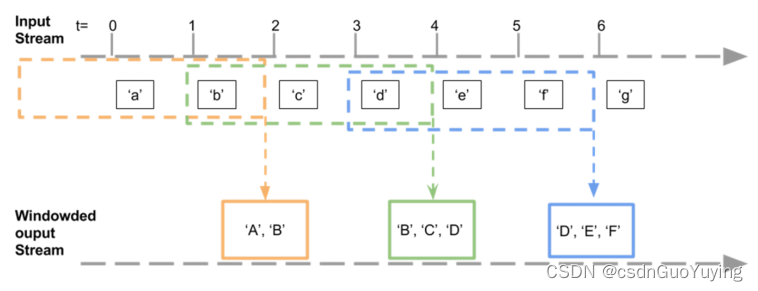
针对用户百度搜索日志数据,实现【近期时间内热搜Top10】,统计最近一段时间范围(比如,最近半个小时或最近2个小时)内用户搜索词次数,获取Top10搜索词及次数。
窗口函数【window】声明如下,包含两个参数:窗口大小(WindowInterval,每次统计数据范围)和滑动大小(每隔多久统计一次),都必须是批处理时间间隔BatchInterval整数倍。

案例完整实现代码如下,为了演示方便,假设BatchInterval为2秒,WindowInterval为4秒,SlideInterval为2秒。
package cn.itcast.spark.app.window
import cn.itcast.spark.app.StreamingContextUtils
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 实时消费Kafka Topic数据,每隔一段时间统计最近搜索日志中搜索词次数
* 批处理时间间隔:BatchInterval = 2s
* 窗口大小间隔:WindowInterval = 4s
* 滑动大小间隔:SliderInterval = 2s
*/
object StreamingWindow {
def main(args: Array[String]): Unit = {
// Streaming应用BatchInterval
val BATCH_INTERVAL: Int = 2
// Streaming应用窗口大小
val WINDOW_INTERVAL: Int = BATCH_INTERVAL * 2
val SLIDER_INTERVAL: Int = BATCH_INTERVAL * 1
// 1. 获取StreamingContext实例对象
val ssc: StreamingContext = StreamingContextUtils.getStreamingContext(this.getClass, BATCH_INTERVAL)
// 2. 从Kafka消费数据,使用Kafka New Consumer API
val kafkaDStream: DStream[String] = StreamingContextUtils
.consumerKafka(ssc, "search-log-topic")
.map(record => record.value())
// TODO: 添加窗口,设置对应参数
/*
def window(windowDuration: Duration, slideDuration: Duration): DStream[T]
警告信息:
ERROR KafkaRDD: Kafka ConsumerRecord is not serializable.
Use .map to extract fields before calling .persist or .window
*/
val windowDStream: DStream[String] = kafkaDStream.window(
Seconds(WINDOW_INTERVAL), Seconds(SLIDER_INTERVAL)
)
// 4. 对每批次的数据进行搜索词进行次数统计
val countDStream: DStream[(String, Int)] = windowDStream.transform{ rdd =>
val resultRDD = rdd
// 过滤不合格的数据
.filter( message => null != message && message.trim.split(",").length == 4)
// 提取搜索词,转换数据为二元组,表示每个搜索词出现一次
.map{message =>
val keyword: String = message.trim.split(",").last
keyword -> 1
}
// 按照单词分组,聚合统计
.reduceByKey((tmp, item) => tmp + item)
// 返回
resultRDD
}
// 5. 将结果数据输出 -> 将每批次的数据处理以后输出
countDStream.print()
// 6.启动流式应用,一直运行,直到程序手动关闭或异常终止
ssc.start()
ssc.awaitTermination()
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
SparkStreaming中同时提供将窗口Window设置与聚合reduceByKey合在一起的函数,为了更加方便编程。
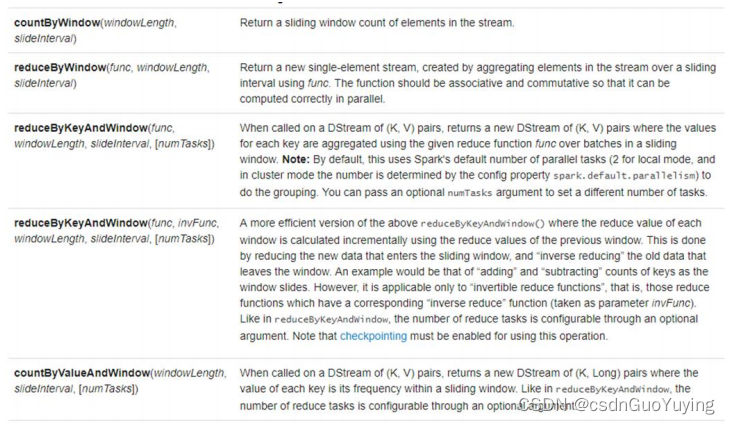
使用【reduceByKeyAndWindow】函数,修改上述代码,实现窗口统计,具体代码如下:
package cn.itcast.spark.app.window
import cn.itcast.spark.app.StreamingContextUtils
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 实时消费Kafka Topic数据,每隔一段时间统计最近搜索日志中搜索词次数
* 批处理时间间隔:BatchInterval = 2s
* 窗口大小间隔:WindowInterval = 4s
* 滑动大小间隔:SliderInterval = 2s
*/
object StreamingReduceWindow {
def main(args: Array[String]): Unit = {
// Streaming应用BatchInterval
val BATCH_INTERVAL: Int = 2
// Streaming应用窗口大小
val WINDOW_INTERVAL: Int = BATCH_INTERVAL * 2
val SLIDER_INTERVAL: Int = BATCH_INTERVAL * 1
// 1. 获取StreamingContext实例对象
val ssc: StreamingContext = StreamingContextUtils.getStreamingContext(this.getClass, BATCH_INTERVAL)
// 2. 从Kafka消费数据,使用Kafka New Consumer API
val kafkaDStream: DStream[String] = StreamingContextUtils
.consumerKafka(ssc, "search-log-topic")
.map(recored => recored.value())
// 3. 对每批次的数据进行搜索词进行次数统计
val etlDStream: DStream[(String, Int)] = kafkaDStream.transform{ rdd =>
val etlRDD = rdd
// 过滤不合格的数据
.filter( message => null != message && message.trim.split(",").length == 4)
// 提取搜索词,转换数据为二元组,表示每个搜索词出现一次
.map{message =>
val keyword: String = message.trim.split(",").last
keyword -> 1
}
etlRDD // 返回
}
// 4. 对获取流式数据进行ETL后,使用窗口聚合函数统计计算
/*
def reduceByKeyAndWindow(
reduceFunc: (V, V) => V, // 聚合函数
windowDuration: Duration, // 窗口大小
slideDuration: Duration // 滑动大小
): DStream[(K, V)]
*/
val resultDStream: DStream[(String, Int)] = etlDStream.reduceByKeyAndWindow(
(tmp: Int, value: Int) => tmp + value, //
Seconds(WINDOW_INTERVAL), //
Seconds(SLIDER_INTERVAL) //
)
// 5. 将结果数据输出 -> 将每批次的数据处理以后输出
resultDStream.print()
// 6.启动流式应用,一直运行,直到程序手动关闭或异常终止
ssc.start()
ssc.awaitTermination()
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
6. 偏移量管理
针对前面实现【百度热搜排行榜Top10】实时状态统计应用来说,当应用关闭以后,再次启动(Restart)执行,并没有继续从上次消费偏移量读取数据和获取以前状态信息,而是从最新偏移量(Latest Offset)开始的消费,肯定不符合实际需求,有两种解决方式:
方式一:Checkpoint 恢复
- 当流式应用再次启动时,从Checkpoint 检查点目录恢复,可以读取上次消费偏移量信息和状态相关数据,继续实时处理数据。
- 文档:http://spark.apache.org/docs/2.4.5/streaming-programming-guide.html#checkpointing
方式二:手动管理偏移量
- 用户编程管理每批次消费数据的偏移量,当再次启动应用时,读取上次消费偏移量信息,继续实时处理数据。
- 文档:http://spark.apache.org/docs/2.4.5/streaming-kafka-0-10-integration.html#storing-offsets
在实际生产项目中,常常使用第二种方式【手动管理偏移量】,将偏移量存储到MySQL、Redis或Zookeeper中,接下来讲解两种方式实现,都需要掌握。