文章目录
- 前言
- 断路器模式
- 舱壁隔离模式
- 重试模式
- 总结
- 附
前言
容错设计模式,指的是“要实现某种容错策略,我们该如何去做”。微服务中常见的设计模式包括断路器模式、舱壁隔离模式和超时重试模式等,另外还有流量控制模式等。
断路器模式
断路器模式是微服务架构中最基础的容错设计模式。断路器的思路也简单,就是通过代理(断路器对象)来一对一(一个远程服务对应一个断路器对象)地接管服务调用者的远程请求。断路器会持续监控并统计服务返回的成功、失败、超时、拒绝等各种结果,当出现故障(失败、超时、拒绝)的次数达到断路器的阈值时,它的状态就自动变为“OPEN”。之后这个断路器代理的远程访问都将直接返回调用失败,而不会发出真正的远程服务请求。
通过断路器对远程服务进行熔断,就可以避免因为持续的失败或拒绝而消耗资源,因为持续的超时而堆积请求,最终可以避免雪崩效应的出现。由此可见,断路器本质上是快速失败策略的一种实现方式。

从调用序列来看,断路器就是一种有限状态机,断路器模式就是根据自身的状态变化,自动调整代理请求策略的过程。
断路器一般可以设置为 CLOSED、OPEN 和 HALF OPEN 三种状态:
- CLOSED:表示断路器关闭(请求可正常响应),此时的远程请求会真正发送给服务提供者。断路器刚刚建立时默认处于这种状态,此后将持续监视远程请求的数量和执行结果,决定是否要进入 OPEN 状态。
- OPEN:表示断路器开启,此时不会进行远程请求,直接给服务调用者返回调用失败的信息,以实现快速失败策略。
- HALF OPEN:是一种中间状态。断路器必须带有自动的故障恢复能力,当进入 OPEN 状态一段时间以后,将“自动”(一般是由下一次请求而不是计时器触发的,所以这里的自动是带引号的)切换到 HALF OPEN 状态。在中间状态下,会放行一次远程调用,然后根据这次调用的结果成功与否,转换为 CLOSED 或者 OPEN 状态,来实现断路器的弹性恢复。
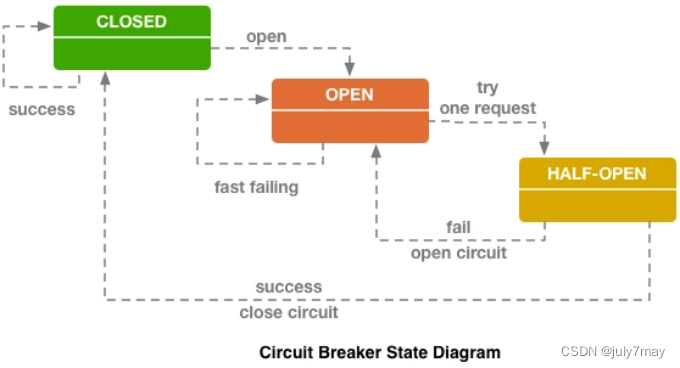
这里值得讨论的是OPEN 和 CLOSED 状态的转换条件,不同框架都有各自的偏好设置,如Netflix Hystrix中的默认设置:
当一次调用失败后,如果还同时满足下面两个条件,断路器的状态就变为 OPEN: - 一段时间(比如 10 秒以内)内,请求数量达到一定阈值(比如 20 个请求)。(响应频率)
- 一段时间(比如 10 秒以内)内,请求的故障率(发生失败、超时、拒绝的统计比例)到达一定阈值(比如 50%)。(可用性)
另外,服务熔断和服务降级之间的联系与差别:
断路器做的事情是自动进行服务熔断,属于一种快速失败的容错策略的实现方法。在快速失败策略明确反馈了故障信息给上游服务以后,上游服务必须能够主动处理调用失败的后果,而不是坐视故障扩散。这里的“处理”,指的就是一种典型的服务降级逻辑,降级逻辑可以是,但不应该只是,把异常信息抛到用户界面去,而应该尽力想办法通过其他路径解决问题,比如把原本要处理的业务记录下来,留待以后重新处理是最低限度的通用降级逻辑。
服务降级不一定是在出现错误后才被动执行的,我们在很多场景中谈论的降级更可能是指,需要主动迫使服务进入降级逻辑的情况。比如,出于应对可预见的峰值流量,或者是系统检修等原因,要关闭系统部分功能或关闭部分旁路服务,这时候就有可能会主动迫使这些服务降级。此时服务降级就是出于流量控制的范畴。
舱壁隔离模式
舱壁隔离模式,是常用的实现服务隔离的设计模式。舱壁这个词来自造船业,意思是在每个区域设计独立的水密舱室。
分布式系统中,服务隔离,就是避免某一个远程服务的局部失败影响到全局,而设置的一种止损方案。这种思想,对应的就是容错策略中的失败静默策略。
在调用外部服务可能面临的三大类故障:失败、拒绝和超时中,“超时”引起的故障,尤其容易给调用者带来全局性的风险。这是因为,目前主流的网络访问大多是基于 TPR 并发模型(Thread per Request)来实现的,只要请求一直不结束(无论是以成功结束还是以失败结束),就要一直占用着某个线程不能释放。而线程是典型的整个系统的全局性资源,尤其是在 Java 这类将线程映射为操作系统内核线程来实现的语言环境中。
要解决这类问题,本质上就是要控制单个服务的最大连接数。一种可行的解决办法是为每个服务单独设立线程池,这些线程池默认不预置活动线程,只用来控制单个服务的最大连接数。使用局部的线程池来控制服务的最大连接数,有很多好处,比如当服务出问题时能够隔离影响,当服务恢复后,还可以通过清理掉局部线程池,瞬间恢复该服务的调用。而如果是 Tomcat 的全局线程池被占满,再恢复就会非常麻烦。
但是,局部线程池有一个显著的弱点,那就是它额外增加了 CPU 的开销,每个独立的线程池都要进行排队、调度和下文切换工作。
为应对这种情况,还有一种更轻量的控制服务最大连接数的办法,那就是信号量机制(Semaphore)。如果不考虑清理线程池、客户端主动中断线程这些额外的功能,仅仅是为了控制单个服务并发调用的最大次数的话,我们可以只为每个远程服务维护一个线程安全的计数器,并不需要建立局部线程池。具体做法是,当服务开始调用时计数器加 1,服务返回结果后计数器减 1;一旦计数器的值超过设置的阈值就立即开始限流,在回落到阈值范围之前都不再允许请求了。因为不需要承担线程的排队、调度和切换工作,所以单纯维护一个作为计数器的信号量的性能损耗,相对于局部线程池来说,几乎可以忽略不计。
一般来说,我们会选择将服务层面的隔离实现在服务调用端或者边车代理上,将系统层面的隔离实现在 DNS 或者网关处。
重试模式
故障转移和故障恢复这两种策略都需要对服务进行重复调用,差别就在于这些重复调用有可能是同步的,也可能是后台异步进行;有可能会重复调用同一个服务,也可能会调用服务的其他副本。但是,无论具体是通过怎样的方式调用、调用的服务实例是否相同,都可以归结为重试设计模式的应用范畴。
重试模式适合解决系统中的瞬时故障,简单地说就是有可能自己恢复(Resilient,称为自愈,也叫做回弹性)的临时性失灵,比如网络抖动、服务的临时过载(比如返回了 503 Bad Gateway 错误)这些都属于瞬时故障。
重试模式实现起来并不难,在实践中,我们判断是否应该且是否能够对一个服务进行重试时,要看是否同时满足下面 4 个条件:
- 第一,仅在主路逻辑的关键服务上进行同步的重试。(如果不是关键服务,一般不要把重试作为首选容错方案,尤其不应该进行同步重试。)
- 第二,仅对由瞬时故障导致的失败进行重试。尽管要做到精确判定一个故障是否属于可自愈的瞬时故障并不容易,但我们至少可以从 HTTP 的状态码上获得一些初步的结论。比如,当发出的请求收到了 401 Unauthorized 响应时,说明服务本身是可用的,只是你没有权限调用,这时候再去重试就没有什么意义。
- 第三,仅对具备幂等性的服务进行重试。比如,RESTful 服务中的 POST 请求是非幂等的;GET、HEAD、OPTIONS、TRACE 请求应该被设计成幂等的,因为它们不会改变资源状态;PUT 请求一般也是幂等的,因为 n 个 PUT 请求会覆盖相同的资源 n-1 次;DELETE 请求也可看作是幂等的,同一个资源首次删除会得到 200 OK 响应,此后应该得到 204 No Content 响应。
- 第四,重试必须有明确的终止条件,常用的终止条件有超时终止和次数终止两种:
超时终止。其实,超时机制并不限于重试策略,所有涉及远程调用的服务都应该有超时机制来避免无限期的等待。
次数终止。重试必须要有一定限度,不能无限制地做下去,通常是重试 2~5 次。因为重试不仅会给调用者带来负担,对服务提供者来说也同样是负担,所以我们要避免把重试次数设得太大。
另外,由于重试模式可以在网络链路的多个环节中去实现,比如在客户端发起调用时自动重试、网关中自动重试、负载均衡器中自动重试等等,如果配置不当,可能会带来巨大的负担。
总结
熔断、隔离、重试、降级、超时等概念,都是建立具有韧性的微服务系统的必须的保障措施。那么就目前来说,这些措施的正确运作,主要还是依靠开发人员对服务逻辑的了解,以及根据运维人员的经验去静态地调整、配置参数和阈值。
但是,面对能够自动扩缩(Auto Scale)的大型分布式系统,静态的配置越来越难以起到良好的效果。这就要求,系统不仅要有能力可以自动地根据服务负载来调整服务器的数量规模,同时还要有能力根据服务调用的统计结果,或者启发式搜索的结果来自动变更容错策略和参数。当然,目前这方面的研究,还处于各大厂商在内部分头摸索的初级阶段,不过这正是服务治理未来的重要发展方向之一。
附
此文章为3月Day02学习笔记,内容来源于极客时间《周志明的软件架构课》