目录
背影
BP神经网络的原理
BP神经网络的定义
BP神经网络的神经元
BP神经网络的激活函数
BP神经网络的传递函数
基于自定义训练函数的BP神经网络回归分析
背影
BP神经网络是一种成熟的神经网络,拥有很多训练函数,传递函数,激活函数,但是依然有扩展空间,最近遇到一组数据需要BP神经网络建模,输出层三个神经元,其中一维输出值总是极端偏大,调试参数都不敏感,于是对训练函数进行改进,加约束,效果瞬间很大提高,
BP神经网络的原理
BP神经网络的定义
人工神经网络无需事先确定输入输出之间映射关系的数学方程,仅通过自身的训练,学习某种规则,在给定输入值时得到最接近期望输出值的结果。作为一种智能信息处理系统,人工神经网络实现其功能的核心是算法。BP神经网络是一种按误差反向传播(简称误差反传)训练的多层前馈网络,其算法称为BP算法,它的基本思想是梯度下降法,利用梯度搜索技术,以期使网络的实际输出值和期望输出值的误差均方差为最小。
BP神经网络的基本结构
基本BP算法包括信号的前向传播和误差的反向传播两个过程。即计算误差输出时按从输入到输出的方向进行,而调整权值和阈值则从输出到输入的方向进行。正向传播时,输入信号通过隐含层作用于输出节点,经过非线性变换,产生输出信号,若实际输出与期望输出不相符,则转入误差的反向传播过程。误差反传是将输出误差通过隐含层向输入层逐层反传,并将误差分摊给各层所有单元,以从各层获得的误差信号作为调整各单元权值的依据。通过调整输入节点与隐层节点的联接强度和隐层节点与输出节点的联接强度以及阈值,使误差沿梯度方向下降,经过反复学习训练,确定与最小误差相对应的网络参数(权值和阈值),训练即告停止。此时经过训练的神经网络即能对类似样本的输入信息,自行处理输出误差最小的经过非线形转换的信息。
bp神经网络的神经元
神经网络是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。
神经网络由多个神经元构成,下图就是单个神经元的图1所示:

。。。。。。。。。。。。。。。。。。。。。。。。图1 ,神经元模型
bp神经网络激活函数及公式


BP神经网络传递函数及公式
图2是Sigmoid函数和双极S函数的图像,其中Sigmoid函数的图像区域是0到1,双极S函数的区间是正负1,归一化的时候要和传递函数的区域相对应,不然,可能效果不好
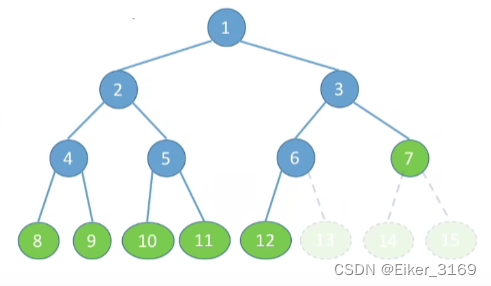
神经网络就是将许多个单一的神经元联结在一起,这样,一个神经元的输出就可以是另一个神经元的输入。
例如,下图就是一个简单的神经网络:

基于BP神经网络的洪水预测
基本模型B
BP神经网络的训练函数有很多,比如Trainlm Traingd Traingdx等,本文提出一种带约束输出神经元的Traingdx训练函数,即带约束自适应梯度动量因子梯度下降函数,
神经网络参数
三层神经网络,传递函数logsig , tansig,训练函数带约束自适应动量因子梯度下降函数,学习率0.01,学习目标0.001,最大迭代次数500
MATLAB编程代码
clc%清除命令窗口变量
clear%清除工作空间变量
close all%关闭FIGURE图像
[a ,ax,ay]= xlsread(‘data.xlsx’);
num = a(:,2:end);
n = randperm(size(num,1));
m = round(0.75.*size(num,1));
input_train=num(n(1:m),1:7)‘;%训练数据的输入数据
output_train=num(n(1:m),8:9)’;%训练数据的输出数据4
input_test=num(n(m+1:end),1:7)‘;%测试数据的输入数据
output_test=num(n(m+1:end),8:9)’; %测试数据的输出数据
global inputnum
global hiddennum
global outputnum
global inputps
global outputps
global inputn
global outputn
global yuesu1
global yuesu2
global yuesu3
inputnum = size(input_train,1);
hiddennum = 20;
outputnum = size(output_train,1);
%选连样本输入输出数据归一化
[inputn,inputps]=mapminmax(input_train,-1,1);%训练数据的输入数据的归一化
[outputn,outputps]=mapminmax(output_train,-1,1);%训练数据的输出数据的归一化de
%% BP网络训练
% %初始化网络结构
yy=mapminmax(‘apply’,[0 30;0 20],outputps);
yuesu1 = yy(1,:);
yuesu2 = yy(2,:);
yuesu3 = [6.25];
net=newff(inputn,outputn,[20],{‘logsig’,‘tansig’},‘traingdxg’);
%net.trainParam.max_fail = 950;
net.trainParam.epochs=500;%最大迭代次数
net.trainParam.lr=0.1;%学习率
net.trainParam.goal=0.0001;%学习目标
%网络训练
net=train(net,inputn,outputn);
%% BP网络预测
%预测数据归一化
inputn_test=mapminmax(‘apply’,input_test,inputps);
%网络预测输出
an=simg(net,inputn_test);
%网络输出反归一化-+
BPoutput=(mapminmax(‘reverse’,an,outputps));
% BPoutput = BPoutput-1;
R2 = R_2(output_test,BPoutput);
[MSE0, RMSE0, MBE0, MAE0 ] =MSE_RMSE_MBE_MAE(output_test,BPoutput);
% save maydata.mat net inputps outputps
%% 结果分析
figure
plot(BPoutput(1,:),‘r-o’)%预测的结果数据画图:代表虚线,O代表圆圈标识,G代表绿色
hold on
plot(output_test(1,:),‘k-*’);%期望数据,即真实的数据画图,-代表实现,就是代表的标识
hold on
legend(‘BP预测输出’,‘期望输出’)%标签
title(‘BP神经网络’,‘fontsize’,12)%标题 字体大小为12
ylabel(‘y1’)
set(gca,‘fontsize’,12)
figure
plot(BPoutput(2,:),‘r-o’)%预测的结果数据画图:代表虚线,O代表圆圈标识,G代表绿色
hold on
plot(output_test(2,:),‘k-*’);%期望数据,即真实的数据画图,-代表实现,就是代表的标识
hold on
legend(‘BP预测输出’,‘期望输出’)%标签
title(‘BP神经网络’,‘fontsize’,12)%标题 字体大小为12
ylabel(‘y2’)
set(gca,‘fontsize’,12)
%预测误差
error=BPoutput-output_test;
figure
plot(error’)
ylabel(‘误差’)
baifenbi = error./output_test;
figure
plot(baifenbi’)
function [out1,out2] = traingdxg(varargin)
%TRAINGDX Gradient descent w/momentum & adaptive lr backpropagation.
%
% traingdx is a network training function that updates weight and
% bias values according to gradient descent momentum and an
% adaptive learning rate.
%
% [NET,TR] = traingdx(NET,X,T) takes a network NET, input data X
% and target data T and returns the network after training it, and a
% a training record TR.
%
% [NET,TR] = traingdx(NET,X,T,Xi,Ai,EW) takes additional optional
% arguments suitable for training dynamic networks and training with
% error weights. Xi and Ai are the initial input and layer delays states
% respectively and EW defines error weights used to indicate
% the relative importance of each target value.
%
% Training occurs according to training parameters, with default values.
% Any or all of these can be overridden with parameter name/value argument
% pairs appended to the input argument list, or by appending a structure
% argument with fields having one or more of these names.
% epochs 1000 Maximum number of epochs to train
% goal 0 Performance goal
% lr 0.01 Learning rate
% lr_inc 1.05 Ratio to increase learning rate
% lr_dec 0.7 Ratio to decrease learning rate
% max_fail 5 Maximum validation failures
% max_perf_inc 1.04 Maximum performance increase
% mc 0.9 Momentum constant
% min_grad 1e-5 Minimum performance gradient
% show 25 Epochs between displays
% showCommandLine false Generate command-line output
% showWindow true Show training GUI
% time inf Maximum time to train in seconds
%
% To make this the default training function for a network, and view
% and/or change parameter settings, use these two properties:
%
% net.trainFcn = ‘traingdx’;
% net.trainParam
%
% See also TRAINGD, TRAINGDM, TRAINGDA, TRAINLM.
% Copyright 1992-2014 The MathWorks, Inc.
%% =======================================================
% BOILERPLATE_START
% This code is the same for all Training Functions.
persistent INFO;
if isempty(INFO),
INFO = get_info;
end
nnassert.minargs(nargin,1);
in1 = varargin{1};
if ischar(in1)
switch (in1)
case ‘info’
out1 = INFO;
case ‘apply’
[out1,out2] = train_network1(varargin{2:end});
case ‘formatNet’
out1 = formatNet(varargin{2});
case ‘check_param’
param = varargin{2};
err = nntest.param(INFO.parameters,param);
if isempty(err)
err = check_param(param);
end
if nargout > 0
out1 = err;
elseif ~isempty(err)
nnerr.throw(‘Type’,err);
end
otherwise,
try
out1 = eval([‘INFO.’ in1]);
catch me, nnerr.throw([‘Unrecognized first argument: ‘’’ in1 ‘’‘’])
end
end
else
net = varargin{1};
oldTrainFcn = net.trainFcn;
oldTrainParam = net.trainParam;
if ~strcmp(net.trainFcn,mfilename)
net.trainFcn = mfilename;
net.trainParam = INFO.defaultParam;
end
[out1,out2] = train(net,varargin{2:end});
net.trainFcn = oldTrainFcn;
net.trainParam = oldTrainParam;
end
a=1;
end
% BOILERPLATE_END
%% =======================================================
function info = get_info
isSupervised = true;
usesGradient = true;
usesJacobian = false;
usesValidation = true;
supportsCalcModes = true;
info = nnfcnTraining(mfilename,‘Gradient Descent with Momentum & Adaptive LR’,8.0,…
isSupervised,usesGradient,usesJacobian,usesValidation,supportsCalcModes,…
[ …
nnetParamInfo(‘showWindow’,‘Show Training Window Feedback’,‘nntype.bool_scalar’,true,…
‘Display training window during training.’), …
nnetParamInfo(‘showCommandLine’,‘Show Command Line Feedback’,‘nntype.bool_scalar’,false,…
‘Generate command line output during training.’) …
nnetParamInfo(‘show’,‘Command Line Frequency’,‘nntype.strict_pos_int_inf_scalar’,25,…
‘Frequency to update command line.’), …
…
nnetParamInfo(‘epochs’,‘Maximum Epochs’,‘nntype.pos_int_scalar’,1000,…
‘Maximum number of training iterations before training is stopped.’) …
nnetParamInfo(‘time’,‘Maximum Training Time’,‘nntype.pos_inf_scalar’,inf,…
‘Maximum time in seconds before training is stopped.’) …
…
nnetParamInfo(‘goal’,‘Performance Goal’,‘nntype.pos_scalar’,0,…
‘Performance goal.’) …
nnetParamInfo(‘min_grad’,‘Minimum Gradient’,‘nntype.pos_scalar’,1e-5,…
‘Minimum performance gradient before training is stopped.’) …
nnetParamInfo(‘max_fail’,‘Maximum Validation Checks’,‘nntype.pos_int_scalar’,6,…
‘Maximum number of validation checks before training is stopped.’) …
…
nnetParamInfo(‘lr’,‘Learning Rate’,‘nntype.pos_scalar’,0.01,…
‘Learning rate.’) …
nnetParamInfo(‘lr_inc’,‘Learning Rate Increase’,‘nntype.over1’,1.05,…
‘Learning rate increase mulitiplier.’) …
nnetParamInfo(‘lr_dec’,‘Learning Rate’,‘nntype.real_0_to_1’,0.7,…
‘Learning rate decrease mulitiplier.’) …
nnetParamInfo(‘max_perf_inc’,‘Maximum Performance Increase’,‘nntype.strict_pos_scalar’,1.04,…
‘Maximum acceptable increase in performance.’) …
nnetParamInfo(‘mc’,‘Momentum Constant’,‘nntype.real_0_to_1’,0.9,…
‘Momentum constant.’) …
], …
[ …
nntraining.state_info(‘gradient’,‘Gradient’,‘continuous’,‘log’) …
nntraining.state_info(‘val_fail’,‘Validation Checks’,‘discrete’,‘linear’) …
nntraining.state_info(‘lr’,‘Learning Rate’,‘continuous’,‘linear’) …
]);
end
function err = check_param(param)
err = ‘’;
end
function net = formatNet(net)
if isempty(net.performFcn)
warning(message(‘nnet🚋EmptyPerformanceFixed’));
net.performFcn = ‘mse’;
end
end
function [archNet,tr] = train_network1(archNet,rawData,calcLib,calcNet,tr)
[archNet,tr] = nnet.train.trainNetwork(archNet,rawData,calcLib,calcNet,tr,localfunctions);
end
function worker = initializeTraining(archNet,calcLib,calcNet,tr)
% Cross worker existence required
worker.WB2 = [];
% Initial Gradient
[worker.perf,worker.vperf,worker.tperf,worker.gWB,worker.gradient] = calcLib.perfsGrad(calcNet);
if calcLib.isMainWorker
% Training control values
worker.epoch = 0;
worker.startTime = clock;
worker.param = archNet.trainParam;
worker.originalNet = calcNet;
[worker.best,worker.val_fail] = nntraining.validation_start(calcNet,worker.perf,worker.vperf);
worker.WB = calcLib.getwb(calcNet);
worker.dWB = worker.param.lr * worker.gWB;
worker.lr = worker.param.lr;
% Training Record
worker.tr = nnet.trainingRecord.start(tr,worker.param.goal,...
{'epoch','time','perf','vperf','tperf','gradient','val_fail','lr'});
% Status
worker.status = ...
[ ...
nntraining.status('Epoch','iterations','linear','discrete',0,worker.param.epochs,0), ...
nntraining.status('Time','seconds','linear','discrete',0,worker.param.time,0), ...
nntraining.status('Performance','','log','continuous',worker.perf,worker.param.goal,worker.perf) ...
nntraining.status('Gradient','','log','continuous',worker.gradient,worker.param.min_grad,worker.gradient) ...
nntraining.status('Validation Checks','','linear','discrete',0,worker.param.max_fail,0) ...
];
end
end
function [worker,calcNet] = updateTrainingState(worker,calcNet)
% Stopping Criteria
current_time = etime(clock,worker.startTime);
[userStop,userCancel] = nntraintool(‘check’);
if userStop
worker.tr.stop = message(‘nnet:trainingStop:UserStop’);
calcNet = worker.best.net;
elseif userCancel
worker.tr.stop = message(‘nnet:trainingStop:UserCancel’);
calcNet = worker.originalNet;
elseif (worker.perf <= worker.param.goal)
worker.tr.stop = message(‘nnet:trainingStop:PerformanceGoalMet’);
calcNet = worker.best.net;
elseif (worker.epoch == worker.param.epochs)
worker.tr.stop = message(‘nnet:trainingStop:MaximumEpochReached’);
calcNet = worker.best.net;
elseif (current_time >= worker.param.time)
worker.tr.stop = message(‘nnet:trainingStop:MaximumTimeElapsed’);
calcNet = worker.best.net;
elseif (worker.gradient <= worker.param.min_grad)
worker.tr.stop = message(‘nnet:trainingStop:MinimumGradientReached’);
calcNet = worker.best.net;
elseif (worker.val_fail >= worker.param.max_fail)
worker.tr.stop = message(‘nnet:trainingStop:ValidationStop’);
calcNet = worker.best.net;
end
% Training Record
worker.tr = nnet.trainingRecord.update(worker.tr, …
[worker.epoch current_time worker.perf worker.vperf worker.tperf …
worker.gradient worker.val_fail worker.lr]);
worker.statusValues = …
[worker.epoch,current_time,worker.best.perf,worker.gradient,worker.val_fail];
end
function [worker,calcNet] = trainingIteration(worker,calcLib,calcNet)
% Cross worker control variables
keepChange = [];
% Gradient Descent with Momentum and Adaptive Learning Rate
if calcLib.isMainWorker
worker.dWB = worker.param.mc * worker.dWB + (1-worker.param.mc) * worker.lr * worker.gWB;
worker.WB2 = worker.WB + worker.dWB;
end
calcNet2 = calcLib.setwb(calcNet,worker.WB2);
[perf2,vperf2,tperf2,gWB2,gradient2] = calcLib.perfsGrad(calcNet2);
if calcLib.isMainWorker
keepChange = (perf2 / worker.perf) <= worker.param.max_perf_inc;
end
if calcLib.broadcast(keepChange)
if calcLib.isMainWorker
if (perf2 < worker.perf)
worker.lr = worker.lr * worker.param.lr_inc;
end
[worker.WB,worker.perf,worker.vperf,worker.tperf,worker.gWB,worker.gradient] = …
deal(worker.WB2,perf2,vperf2,tperf2,gWB2,gradient2);
end
calcNet = calcNet2;
elseif calcLib.isMainWorker
worker.lr = worker.lr * worker.param.lr_dec;
worker.dWB = worker.lr * worker.gWB;
end
% Track Best Network
if calcLib.isMainWorker
[worker.best,worker.tr,worker.val_fail] = nnet.train.trackBestNetwork(…
worker.best,worker.tr,worker.val_fail,calcNet,worker.perf,worker.vperf,worker.epoch);
end
end
效果图



结果分析
从效果图上看,图一为MATLAB自带的traingdx训练函数,整个模型输出的值偏大,导致误差很大,模型无法使用,图2位加输出限制条件,设置输出上限,训练好,逼近效果较好,说明改进的加约束traingdx训练函数,在处理类似这种,模型输出值偏大或者偏小,比MATLAB自带的函数效果要好
展望
针对神经网络供工具箱,可以自己写传递函数,激活函数的代入并原本的工具箱函数,可以有很多种改进方法