1、BIGGAN 解读
1.1、作者
Andrew Brock、Jeff Donahue、Karen Simonyan
1.2、摘要
尽管最近在生成图像建模方面取得了进展,但从 ImageNet 等复杂数据集中 成功生成高分辨率、多样化的样本仍然是一个难以实现的目标。为此,我们以迄 今为止最大的规模训练生成对抗网络,并研究该规模特有的不稳定性。我们发现, 对生成器应用正交正则化使其易于使用简单的“截断技巧”,通过减少生成器输 入的方差,可以精细控制样本保真度和品种之间的权衡。我们的修改导致模型在 类条件图像合成中设置了新的技术状态。当以 128×128 分辨率在 ImageNet 上训 练时,BigGANs 的 IS 分数为 166.5,FID 分数为 7.4,比之前最好的 IS 为 52.52 和 FID 为 18.65 有所改进。
1.3、模型
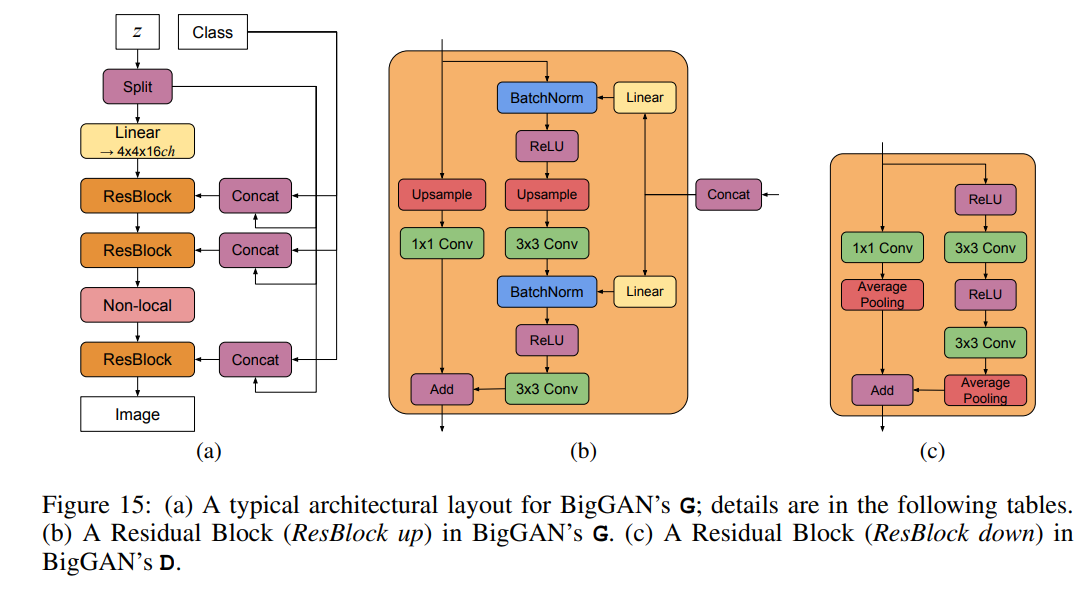
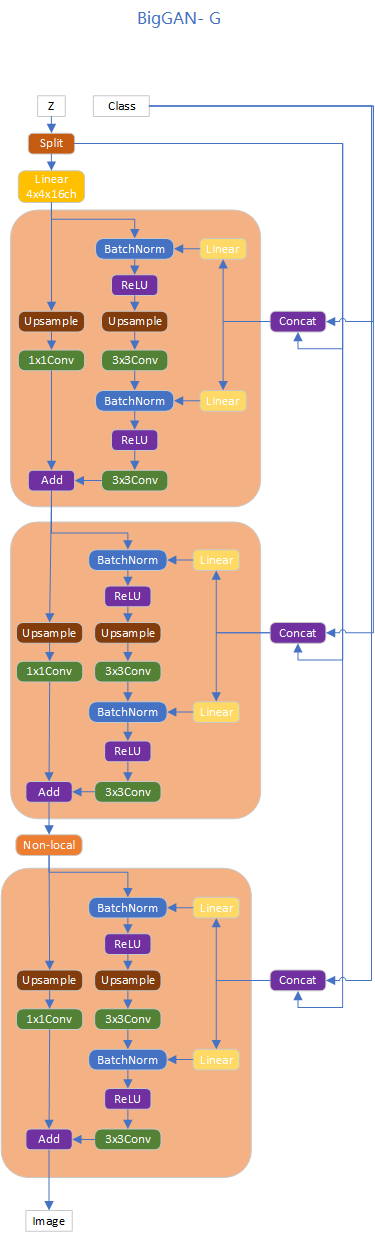
GResidualBlock块代码如下:
class GResidualBlock(nn.Module):
''' Implements a residual block in BigGAN's generator '''
def __init__(
self,
c_dim: int,
in_channels: int,
out_channels: int,
):
super().__init__()
self.conv1 = nn.utils.spectral_norm(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
self.conv2 = nn.utils.spectral_norm(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
self.bn1 = ClassConditionalBatchNorm2d(c_dim, in_channels)
self.bn2 = ClassConditionalBatchNorm2d(c_dim, out_channels)
self.activation = nn.ReLU()
self.upsample_fn = nn.Upsample(scale_factor=2) # upsample occurs in every gblock
self.mixin = (in_channels != out_channels)
if self.mixin:
self.conv_mixin = nn.utils.spectral_norm(nn.Conv2d(in_channels, out_channels, kernel_size=1, padding=0))
def forward(self, x, y):
# x,y输入给BatchNorm
h = self.bn1(x, y) # BatchNorm
h = self.activation(h)# ReLU
h = self.upsample_fn(h) # Upsample
h = self.conv1(h)# 3x3Conv
# x卷积后成h,y输入给BatchNorm
h = self.bn2(h, y) # BatchNorm
h = self.activation(h)# ReLU
h = self.conv2(h)# 3x3Conv
# x输入给Upsample
x = self.upsample_fn(x)# Upsample
if self.mixin:
x = self.conv_mixin(x)# 1x1Conv
# 1x1卷积后的x + 经过两次3x3卷积后的x
return h + x # addNon-Local Block的代码如下:
# Self-Attention module == Non-Local block
class AttentionBlock(nn.Module):
''' Implements a self-attention block from SA-GAN '''
def __init__(self, channels: int):
super().__init__()
self.channels = channels
self.theta = nn.utils.spectral_norm(nn.Conv2d(channels, channels // 8, kernel_size=1, padding=0, bias=False))
self.phi = nn.utils.spectral_norm(nn.Conv2d(channels, channels // 8, kernel_size=1, padding=0, bias=False))
self.g = nn.utils.spectral_norm(nn.Conv2d(channels, channels // 2, kernel_size=1, padding=0, bias=False))
self.o = nn.utils.spectral_norm(nn.Conv2d(channels // 2, channels, kernel_size=1, padding=0, bias=False))
self.gamma = nn.Parameter(torch.tensor(0.), requires_grad=True)
def forward(self, x):
spatial_size = x.shape[2] * x.shape[3]
# apply convolutions to get query (theta), key (phi), and value (g) transforms
theta = self.theta(x)
phi = F.max_pool2d(self.phi(x), kernel_size=2)
g = F.max_pool2d(self.g(x), kernel_size=2)
# reshape spatial size for self-attention
theta = theta.view(-1, self.channels // 8, spatial_size)
phi = phi.view(-1, self.channels // 8, spatial_size // 4)
g = g.view(-1, self.channels // 2, spatial_size // 4)
# compute dot product attention with query (theta) and key (phi) matrices
beta = F.softmax(torch.bmm(theta.transpose(1, 2), phi), dim=-1)
# compute scaled dot product attention with value (g) and attention (beta) matrices
o = self.o(torch.bmm(g, beta.transpose(1, 2)).view(-1, self.channels // 2, x.shape[2], x.shape[3]))
# apply gain and residual
return self.gamma * o + xBigGAN的Generation结构如图所示:

根据上图代码如下:
class Generator(nn.Module):
''' Implements the BigGAN generator '''
def __init__(
self,
base_channels: int = 96,
bottom_width: int = 4,# yml里面是2
z_dim: int = 120,
shared_dim: int = 128,
n_classes: int = 1000,
):
super().__init__()
n_chunks = 6 # 5 (generator blocks) + 1 (generator input)
self.z_chunk_size = z_dim // n_chunks # 120//6 == 20
self.z_dim = z_dim
self.shared_dim = shared_dim
self.bottom_width = bottom_width
self.n_classes = n_classes
# no spectral normalization on embeddings, which authors observe to cripple the generator
self.shared_emb = nn.Embedding(n_classes, shared_dim)
# Linear层 Linear(20,16*96*2**2)
self.proj_z = nn.Linear(self.z_chunk_size, 16 * base_channels * bottom_width ** 2)
# 不能用一个大nn。连续的,因为我们在每个块上添加class+noise
self.g_blocks = nn.ModuleList([
# ResBlock up 16ch → 16ch
GResidualBlock(shared_dim + self.z_chunk_size, 16 * base_channels, 16 * base_channels),
# ResBlock up 16ch → 8ch
GResidualBlock(shared_dim + self.z_chunk_size, 16 * base_channels, 8 * base_channels),
# ResBlock up 8ch → 4ch
GResidualBlock(shared_dim + self.z_chunk_size, 8 * base_channels, 4 * base_channels),
# ResBlock up 4ch → 2ch
GResidualBlock(shared_dim + self.z_chunk_size, 4 * base_channels, 2 * base_channels),
# Non-Local Block (64 × 64)
AttentionBlock(2 * base_channels),
# ResBlock up 2ch → ch
GResidualBlock(shared_dim + self.z_chunk_size, 2 * base_channels, base_channels),
])
self.proj_o = nn.Sequential(
# BN, ReLU, 3 × 3 Conv ch → 3, Tanh
nn.BatchNorm2d(base_channels),
nn.ReLU(inplace=True),
nn.utils.spectral_norm(nn.Conv2d(base_channels, 3, kernel_size=1, padding=0)),
nn.Tanh(),
)
def forward(self, z, y):
'''
z: random noise with size self.z_dim
y: one-hot class embeddings with size self.shared_dim
'''
y = self.shared_emb(y)# class
# 块z并连接到共享类嵌入
zs = torch.split(z, self.z_chunk_size, dim=1)
z = zs[0]
ys = [torch.cat([y, z], dim=1) for z in zs[1:]] # Split的结果+Class
# project noise and reshape to feed through generator blocks
h = self.proj_z(z)# Linear层
h = h.view(h.size(0), -1, self.bottom_width, self.bottom_width)
# feed through generator blocks
idx = 0
for g_block in self.g_blocks:
if isinstance(g_block, AttentionBlock):
h = g_block(h)
else:
h = g_block(h, ys[idx])
idx += 1
# project to 3 RGB channels with tanh to map values to [-1, 1]
h = self.proj_o(h)
return h1.4、试验
1.4.1、不同 Batch size 对性能的影响
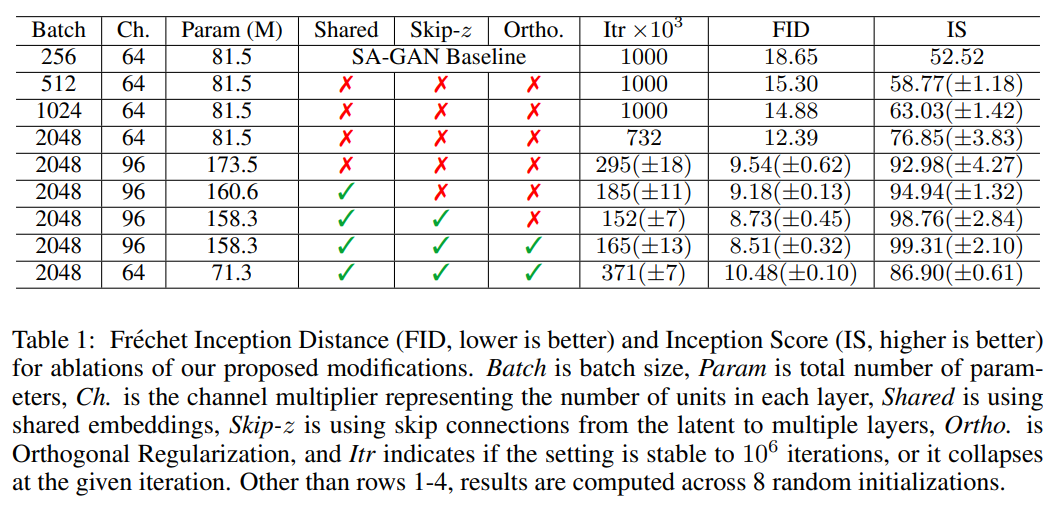
作者发现简单地将 Batch size 增大就可以实现性能上较好的提升,文章做 了实验验证。在 Batch size 增大到原来 8 倍的时候,生成性能上的 IS 提高 了 46%。文章推测这可能是每批次覆盖更多模式的结果,为生成和判别两个网 络提供更好的梯度。增大 Batch size 还会带来在更少的时间训练出更好性能的 模型,但增大 Batch size 也会使得模型在训练上稳定性下降,后续再分析如何 提高稳定性。
在实验上,单单提高 Batch size 还受到限制,文章在每层的通道数也做了 相应的增加,当通道增加 50%,大约两倍于两个模型中的参数数量。这会导致 IS 进一步提高 21%。文章认为这是由于模型的容量相对于数据集的复杂性而增加。
1.4.2、选择先验分布
z 通过实验对比了 N(0,1)、Bernoulli{0,1}、Censored Normal max(N(0,1), 0),根据参考训练速度、模型性能,文章最终选择了 z∼ N(0,I)。
1.4.3、选择阈值
所谓的“截断技巧”就是通过对从先验分布 z 采样,通过设置阈值的方式 来截断 z 的采样,其中超出范围的值被重新采样以落入该范围内。这个阈值可 以根据生成质量指标 IS 和 FID 决定。 通过实验可以知道通过对阈值的设定,随着阈值的下降生成的质量会越来越 好,但是由于阈值的下降、采样的范围变窄,就会造成生成上取向单一化,造成 生成的多样性不足的问题。往往 IS 可以反应图像的生成质量,FID 则会更假注 重生成的多样性。

1.4.4、尝试控制 G
在探索模型的稳定性上,文章在训练期间监测一系列权重、梯度和损失统计 数据,以寻找可能预示训练崩溃开始的指标。实验发现每个权重矩阵的前三个奇 异值 σ0,σ1,σ2 是最有用的,它们可以使用 Alrnoldi 迭代方法进行有效计 算。
对于奇异值 σ0,大多数 G 层具有良好的光谱规范,但有些层(通常是 G 中 的第一层而非卷积)则表现不佳,光谱规范在整个训练过程中增长,在崩溃时爆 炸。
一顿操作后,文章得出了调节 G 可以改善模型的稳定性,但是无法确保一 直稳定,从而文章转向对 D 的控制。
1.4.5、尝试控制 D
考虑 D 网络的光谱,试图寻找额外的约束来寻求稳定的训练。使用正交正 则化,DropOut 和 L2 的各种正则思想重复该实验,揭示了这些正则化策略的都 有类似行为:对 D 的惩罚足够高,可以实现训练稳定性但是性能成本很高,但 是在图像生成性能上也是下降的,而且降的有点多。
实验还发现 D 在训练期间的损失接近于零,但在崩溃时经历了急剧的向上 跳跃,这种行为的一种可能解释是 D 过度拟合训练集,记忆训练样本而不是学 习真实图像和生成图像之间的一些有意义的边界。
为了评估这一猜测,文章在 ImageNet 训练和验证集上评估判别器,并测量 样本分类为真实或生成的百分比。虽然在训练集下精度始终高于 98%,但验证 准确度在 50-55% 的范围内,这并不比随机猜测更好(无论正则化策略如何)。
这证实了 D 确实记住了训练集,也符合 D 的角色:不断提炼训练数据并为 G 提 供有用的学习信号。 可以通过约束 D 来强制执行稳定性,但这样做会导致性能上的巨大成本。 使用现有技术,通过放松这种调节并允许在训练的后期阶段发生崩溃(人为把握 训练实际),可以实现更好的最终性能,此时模型被充分训练以获得良好的结果。
1.4.6、用分辨率评估模型
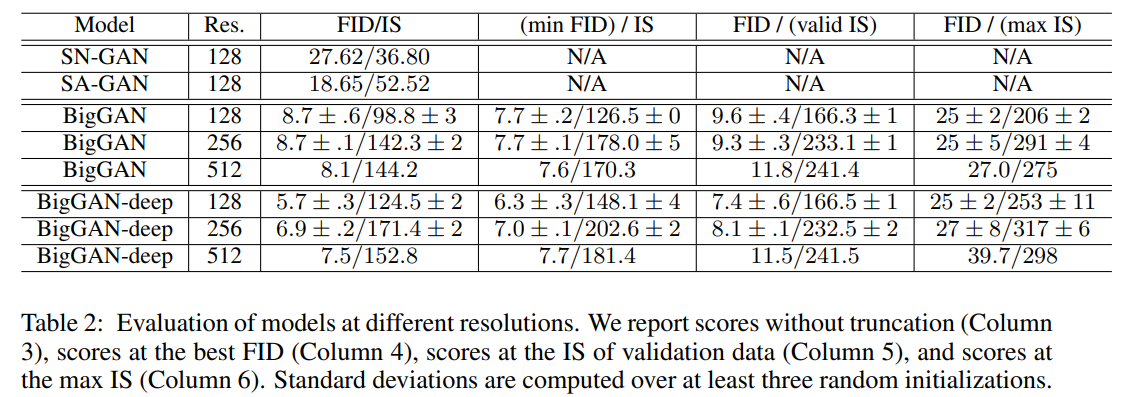
在 ImageNet 数据集下做评估,实验在 ImageNet ILSVRC 2012(大家都在 用的 ImageNet 的数据集)上 128×128,256×256 和 512×512 分辨率评估模 型。

1.4.7、验证 G 网络并非是记住训练集
为了进一步说明 G 网络并非是记住训练集,在固定 z 下通过调节条件标签 c 做插值生成,通过下图的实验结果可以发现,整个插值过程是流畅的,也能说 明 G 并非是记住训练集,而是真正做到了图像生成。

1.5、与 GAN 的对比
BigGAN 的主要改进有一下三部分:
(1)通过大规模 GAN 的应用,BigGAN 实现了生成上的巨大突破,参数量 扩大两到四倍,batchsize 扩大八倍;
(2)采用先验分布 z 的“截断技巧”,允许对样本多样性和保真度进行精 细控制;
(3)在大规模 GAN 的实现上不断克服模型训练问题,采用技巧减小训练的 不稳定,但完全的稳定性只能以极高的性能成本实现。