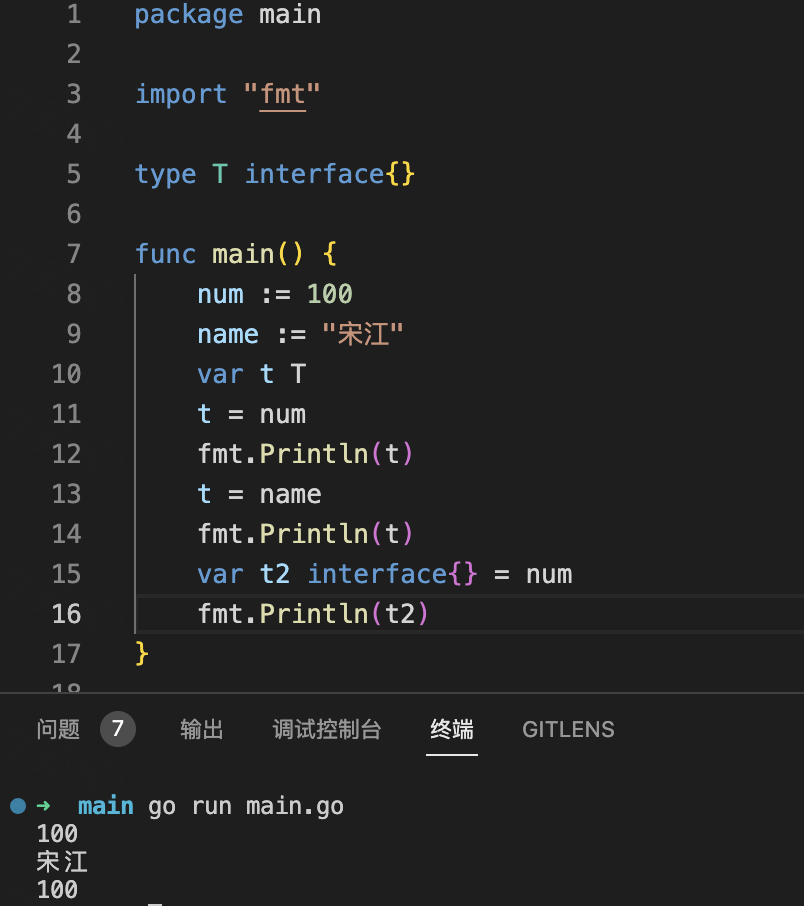
awk是一个有强大的文本格式化能力的linux命令,早期是在Unix上实现的,linux后来也可以使用了,我们在Linux上使用的awk是gawk(GNU awk的意思)
语法
awk [option] '模式{动作}' file
- option表示awk的可选参数,可以设置分隔符等内容
- 模式可以先简单理解成条件,用来指定打印的内容,非必填,未填时表示文本的所有行
- 动作可以理解为对文本进行处理,最常用的处理就是打印文本:
printf- file就是文本来源,可以指定是某个文件
基础概念
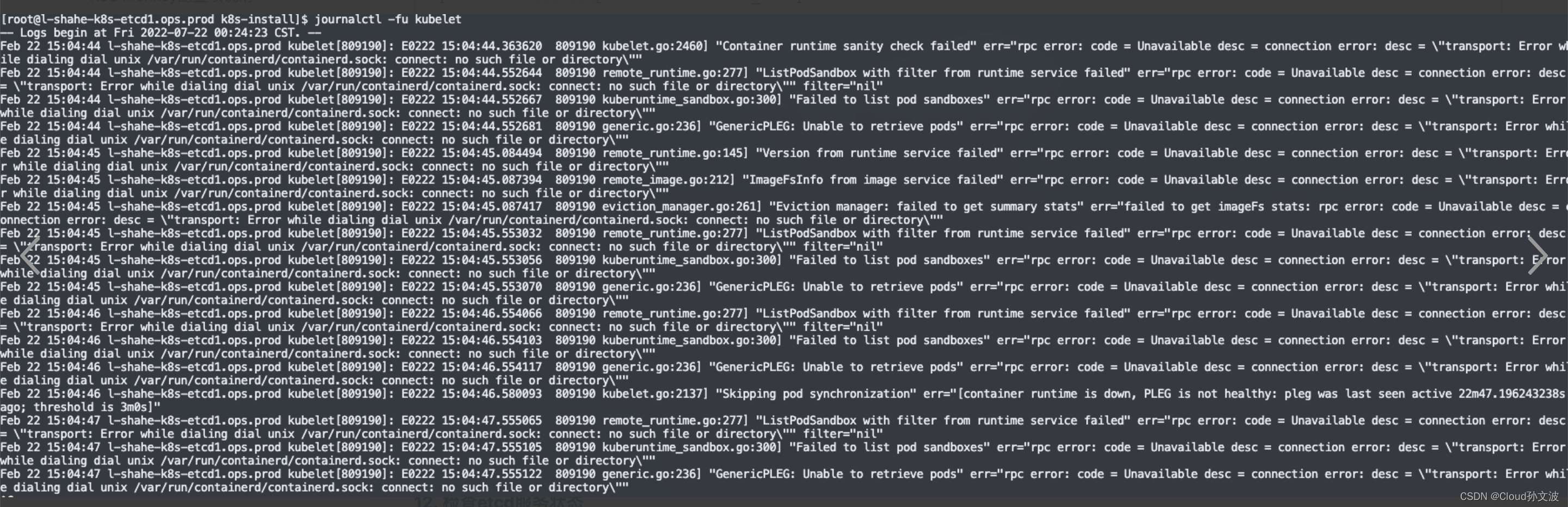
awk其实是将文本的内容按照行和列进行分割,然后按照指定行或列对数据进行格式化处理。以下先了解一些基础概念:
- awk默认以空格为分隔符(多个空格也识别为一个空格)
- awk一行行处理文件数据,根据分隔符将一行数据处理成列,使用
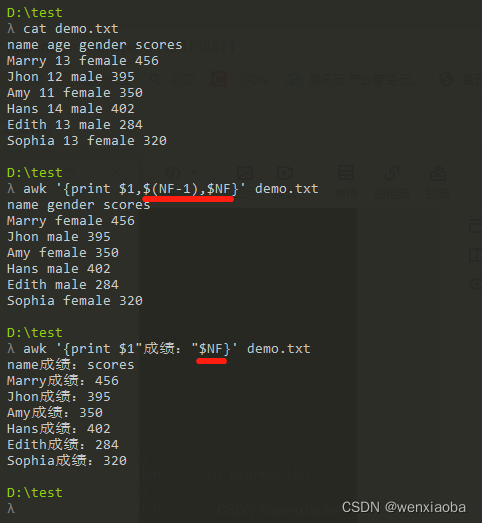
$去表示列$0:表示一整行,即该行的所有列$n:n表示一个具体的数字,表示第几列,比如$1表示第一列,$4表示第4列FS:字段分隔符,默认是空格NF:Number of fields,表示当前行分割后的字段数(即一共多少列),NF-1表示倒数第二列NR:Number of records,当前文本记录数(行数),可以通过NR==n去打印指定行的内容
列
分隔符
分隔符默认是空格(多个空格也识别成一个空格)
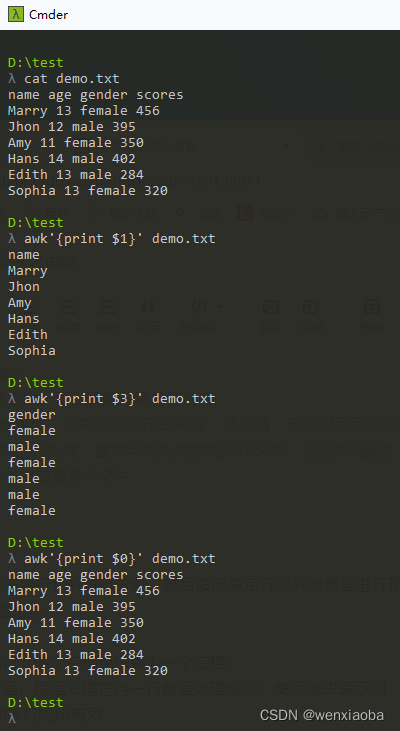
可以设置分隔符,设置方法有2种:
- 方法1:
-F可以指定分隔符 - 方法2:
-v FS="xx"设置分隔符,其中-v表示修改awk变量,FS是分隔符变量,-F也是通过方法2实现的
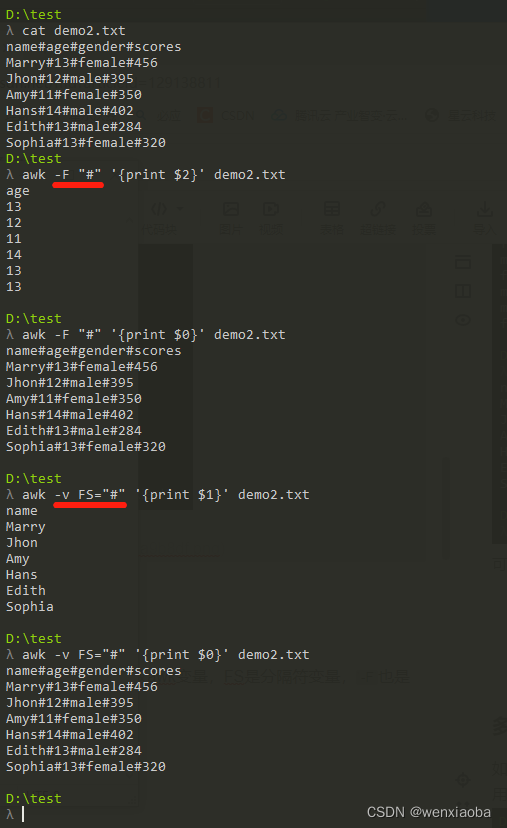
多个字段
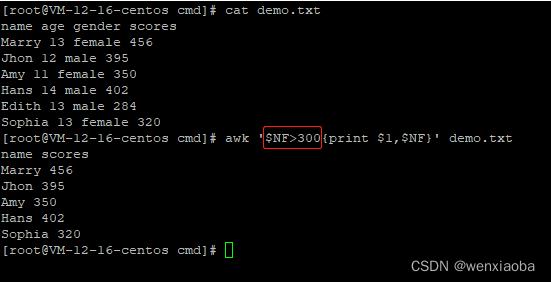
如果想输出多个指定的列的内容,需要使用英文逗号,进行分割(打印出来的内容默认使用空格进行分割)
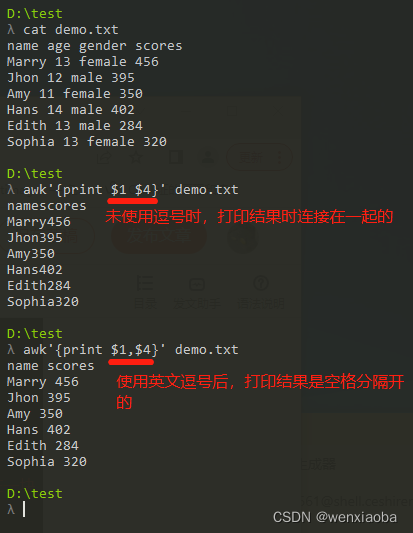
如果想要将列字段之间的逗号转成其他非空格输出,可以通过-v OFS=="xxx"的方式来指定英文逗号,的输出
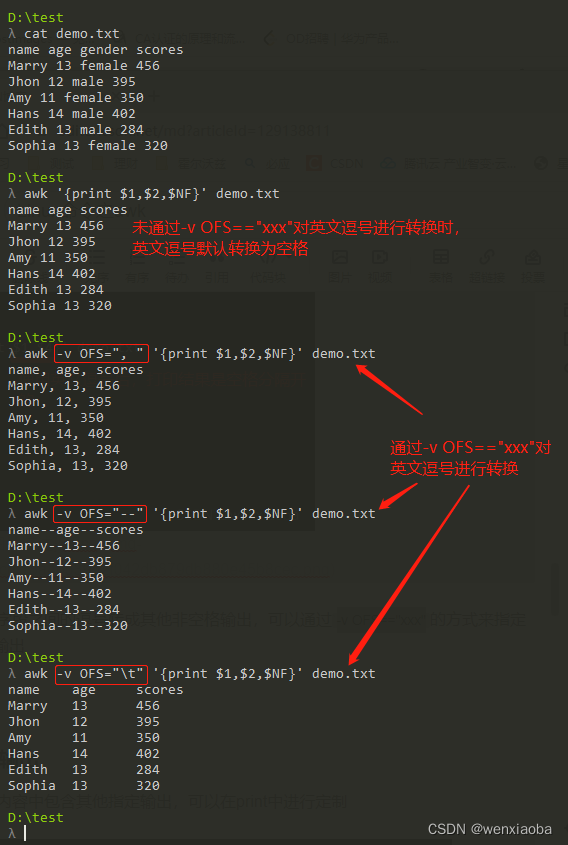
自定义输出
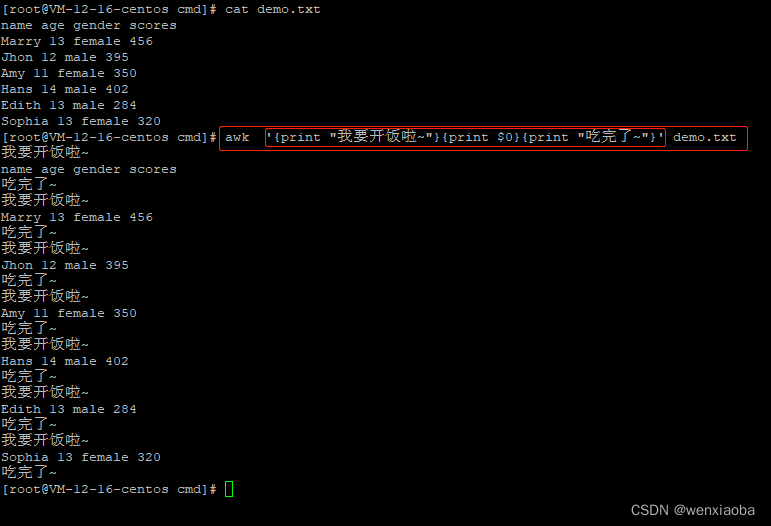
如果想在字段内容中包含其他指定输出,可以在print中进行定制
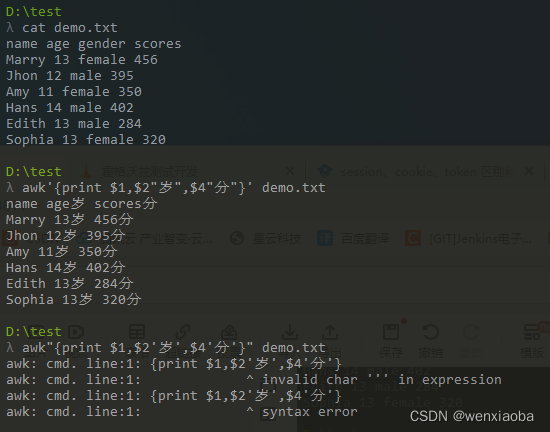
注意:如果有添加的字符串内容输出,则awk命令最外层必须是单引号,内层双引号
NF倒数列和字段数
NF可以表示当前行的字段数
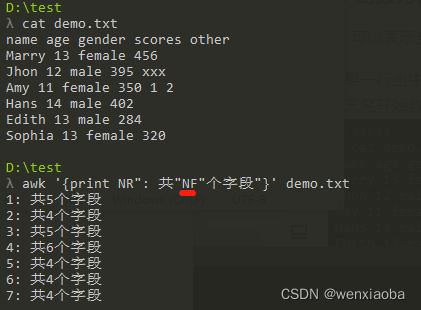
如果一行当中有多个字段,然后想要打印的字段又在末尾,从前面数的话容易数错,可以从末尾开始数,NF可以表示倒数第一列,NF-1表示倒数第二列,依次类推
行
NR:Number of records,当前文本记录数(行数),可以通过NR==n去打印指定行的内容
指定行
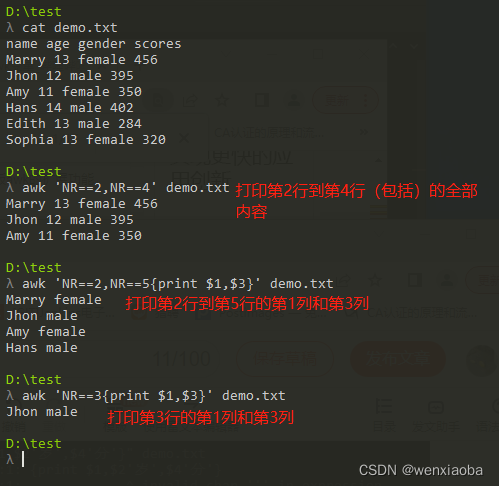
如果只想输出指定的行数据时,可以通过NR来设置条件,指定行
- 条件设置中只有一个
NR==n,则表示打印第几行的内容- 条件设置中有2个
NR==n(通过英文逗号,连接,如NR==n,NR==mm比n大),则表示打印从指定行到另一个指定行(包括)的内容
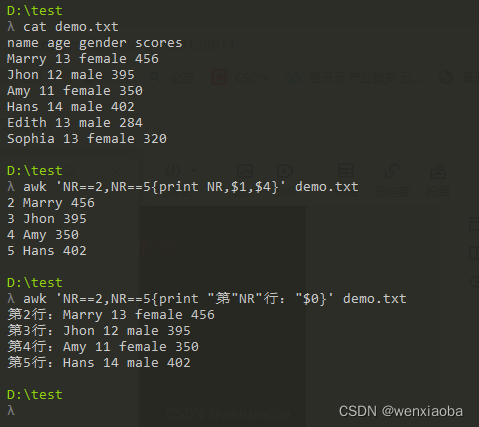
添加行号
如果想打印出对应内容在文本中的行号,也可以使用NR变量,因为NR表示当前行数
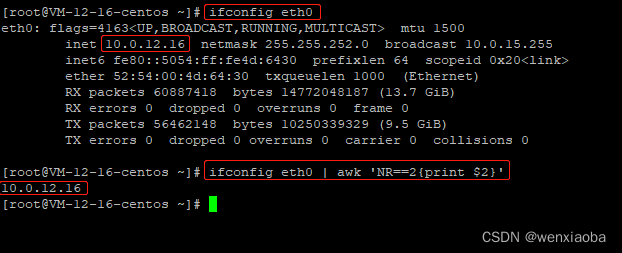
组合命令
awk也可以对其他命令的输出内容进行处理
比如获取本机的ip地址:
awk变量
前面的示例中我们使用-v参数,这个参数时可以定义或修改变量的
awk内置变量
awk有一些内置变量,常用的内置变量如下:
| 内置变量 | 说明 |
|---|---|
FS | File Separator,输入字段分隔符,默认为空格 |
OFS | Output File Separator,输出字段分隔符,默认为单个空格 |
RS | Record Separator,输入记录分隔符(输入换行符),指定输入时的换行符,即指定按照什么字符进行换行 |
ORS | Output Record Separator,输出记录分隔符(输出换行符),指定输出时的换行符,即指定输出的换行符 |
NF | Number of fields,表示当前行分割后的字段数(即一共多少列) |
NR | Number of records,当前文本记录数(行数) |
FNR | Files Number of records,各文件分别计数的行号 |
FILENAME | 当前文件名 |
ARGC | 命令行参数 |
ARGV | 数组,保存的是命令行所给定的各参数 |
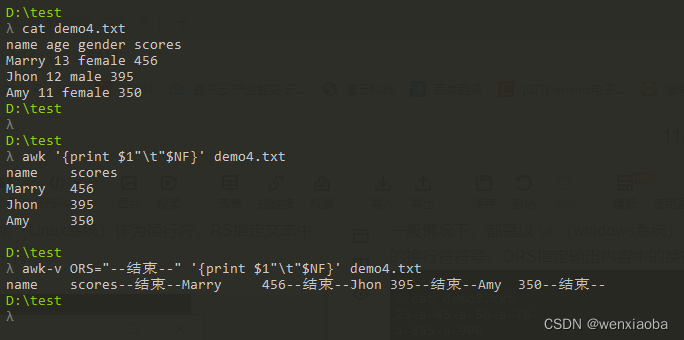
RS和ORS
一般情况下,都是以\n(windows系统)或\r(Linux系统)作为换行符,RS指定文本中的换行符符号,ORS指定输出内容中的换行符符号

FNR按照各文件计算行号
前面的章节有说到NR,这个针对全部文本内容的行号。
FNR,Files Number of records的缩写,是按照各个文本内的行号输出的
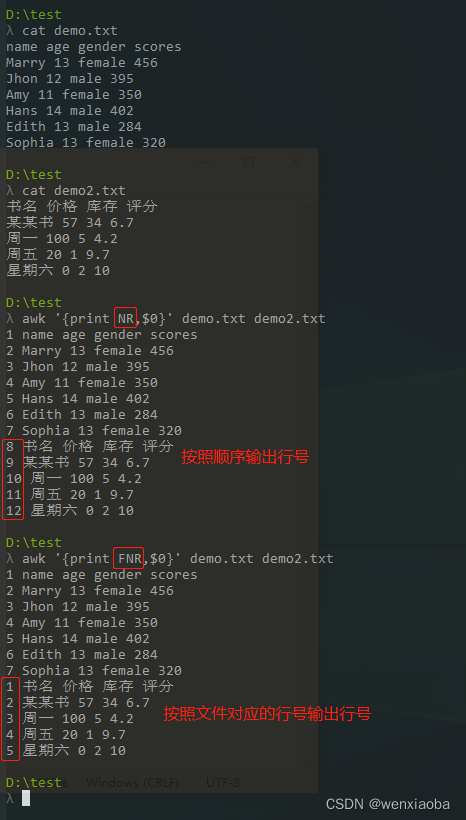
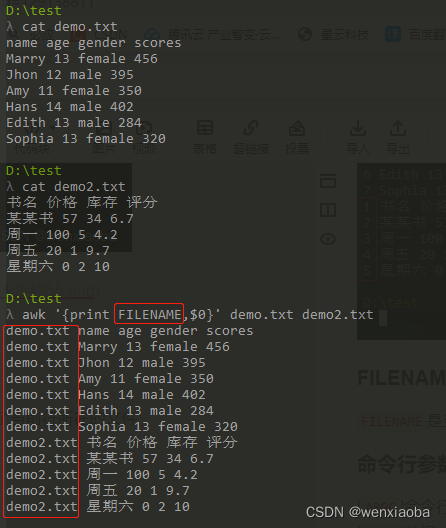
FILENAME文件名
FILENAME是当前文件名的awk内置变量,保存了当前行所在的文件
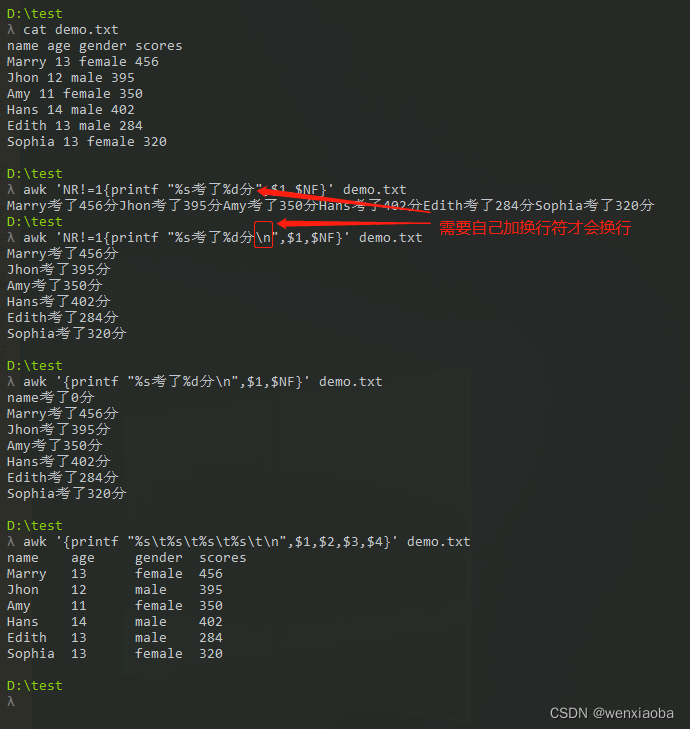
格式化输出
前面的例子基本上是使用的print,这里重点说下printf,与print最大的不同是:
printf需要指定format,format用于只当后面的每个item的输出格式printf语句不会自动打印换行符(\n)
printf跟C语言的printf()函数基本一致,这里简单介绍下格式和一些修饰符。
format格式的指示符都以%开头,后面跟一个字符,相关的内容如下:
| 格式 | 描述 |
|---|---|
%c | 显示字符的ASCII码 |
%d、%i | 十进制整数 |
%e、%E | 科学计数法显示数值 |
%f | 显示浮点数 |
%g、%G | 以科学计数法的格式或浮点数的格式显示数值 |
%s | 字符串 |
%u | 无符号整数 |
%% | 显示%自身 |
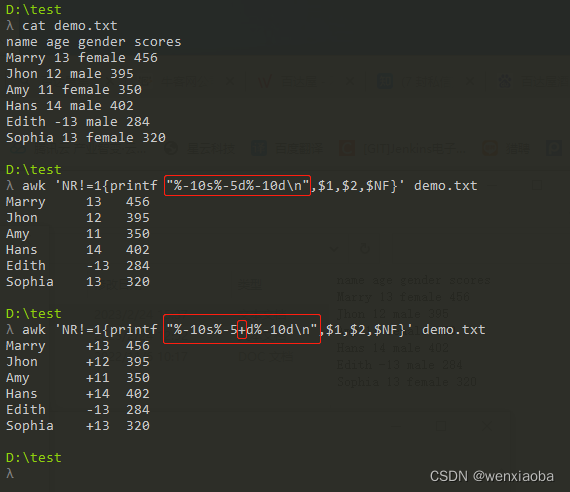
printf比较常用的修饰符:
-:左对齐,默认右对齐+:显示数值符号,即正数会在数值前有“+”,负数在数值前有“-”
修饰符一般在符号%后面加上
模式(条件)
awk命令awk [option] '模式{动作}' file中,模式可以简单理解为条件,这个条件可以是指定行或指定列,或者指定前置和后置,在前面的例子中,我们有通过NR==n去指定行,这里再详细说下模式。
关系运算符
前面关于指定行我们用的是==,其实是有多个关系运算符选择,关系运算符适用于行和列
| 关系运算符 | 描述 | 示例 |
|---|---|---|
< | 小于 | NR<x |
<= | 小于等于 | NR<=x |
== | 等于 | NR==x |
!= | 不等于 | NR!=x |
>= | 大于等于 | NR>=x |
> | 大于 | NR>x |
~ | 匹配正则 | /正则表达式/,如果正则表达式中有/符号,则通过\进行转义 |
!~ | 不匹配正则 | NRx |
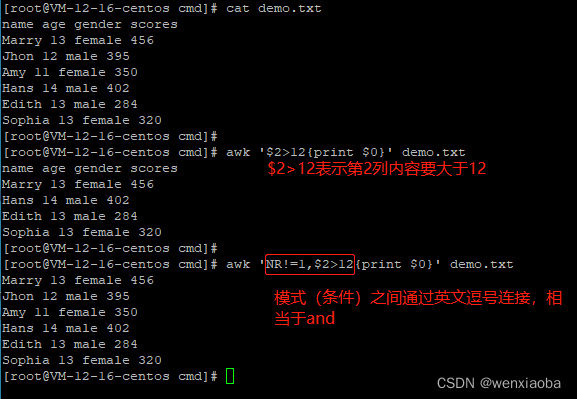
多个模式(条件)时,通过英文逗号
,连接,相当于and
BEGIN和END
有2个比较特殊的模式:
BEGIN:设置处理文本之前需要执行的操作END:设置处理文本完成之后需要执行的操作
在awk命令awk [option] '模式{动作}' file中,动作有多个的话,每处理一行文本内容都会去执行另一个操作,因为动作是按照符合模式的文本去一行行处理的,如下:
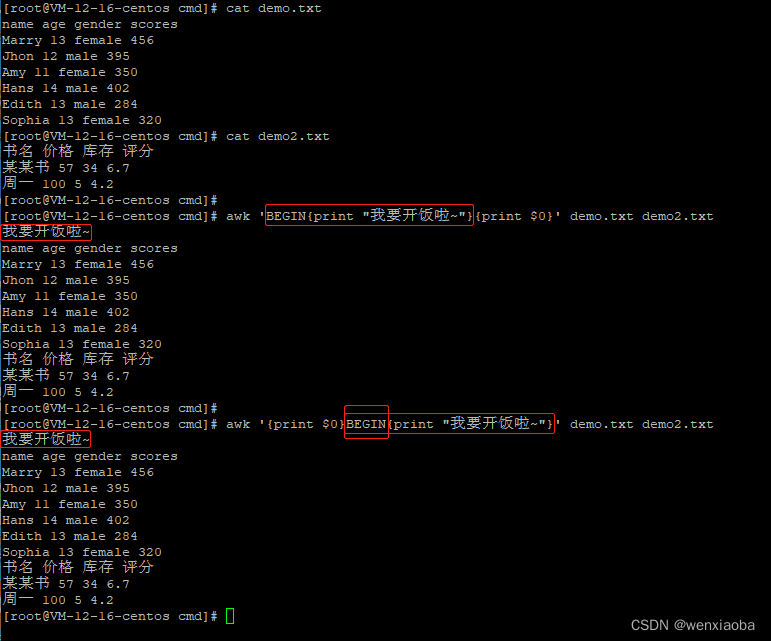
如果只是想在文本处理前输出,并不想在每一行文本处理前输出,则可以使用BEGIN
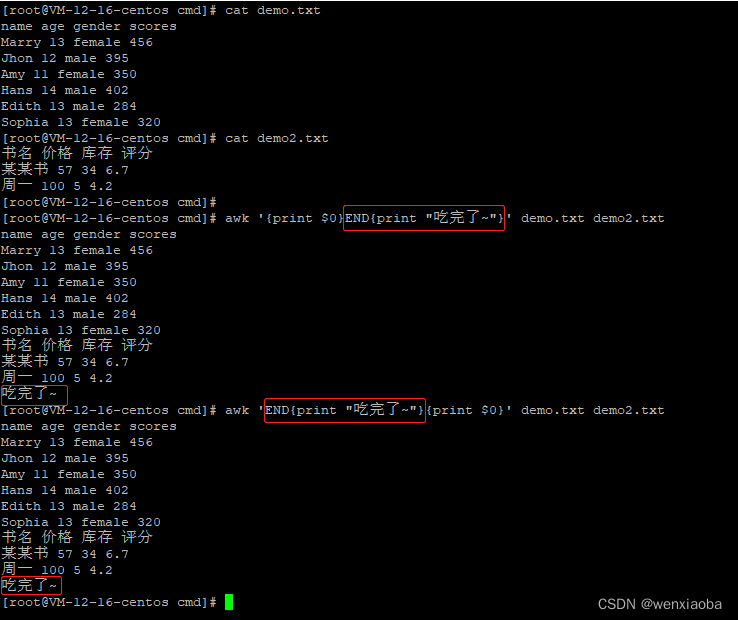
如果只是想在(全部)文本处理完成后输出,并不想在每一行文本处理完成后输出,则可以使用END
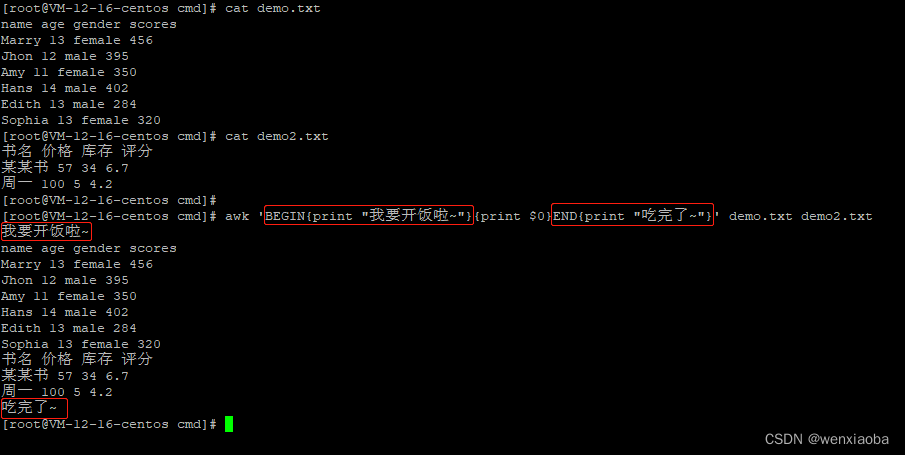
BEGIN和END一起使用
使用正则表达式
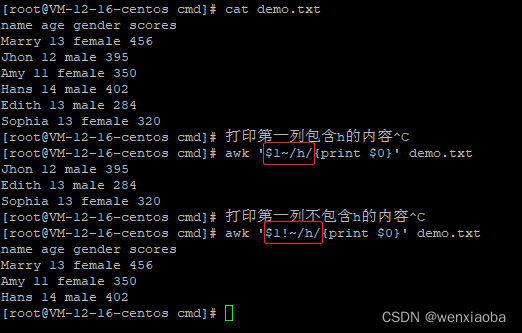
模式可以使用正则表达式。
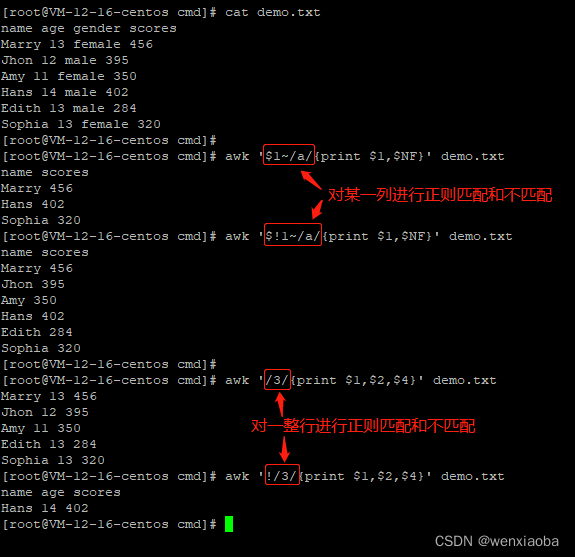
- 对某一个指定字段进行正则匹配或不匹配
- 匹配:
awk [option] '$n~/正则表达式/{动作}' file($n中的n表示第几列) - 不匹配:
awk [option] '$n!~/正则表达式/{动作}' file($n中的n表示第几列)
- 匹配:
- 对一行的内容进行正则匹配或不匹配
- 匹配:
awk [option] '/正则表达式/{动作}' file - 不匹配:
awk [option] '!/正则表达式/{动作}' file
- 匹配: