文本分类类似于图片分类,也是很常见的一种分类任务,将一段不定长的文本序列变换为文本的类别。这节主要就是关注文本的情感分析(sentiment analysis),对电影的评论进行一个正面情绪与负面情绪的分类。
整理数据集
第一步都是将数据集整理好,这里我们使用"大型电影评论数据集"LMDB(Large Movie Review Dataset v1.0),该数据集包含电影评论及其相关二进制情感标签。标签的整体分布是平衡的,一半的正类标签和一半的负类标签,另外有一些未贴标签的用于无监督学习。电影评分满分是10分,将评分>=7分的判定为正面评论,评论得分<= 4分则为负面评论。
下载数据集,可以使用自带的函数
import d2lzh as d2l
d2l.download_imdb(data_dir='data')或者手动下载:http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
自动下载虽然只有80M的大小,但是下载特别慢。这里依然推荐迅雷下载,下载下来之后就手动解压(自动下载的函数包括自动解压)
我们先来看下这个数据集里面有一些什么内容,本人地址截图如下:

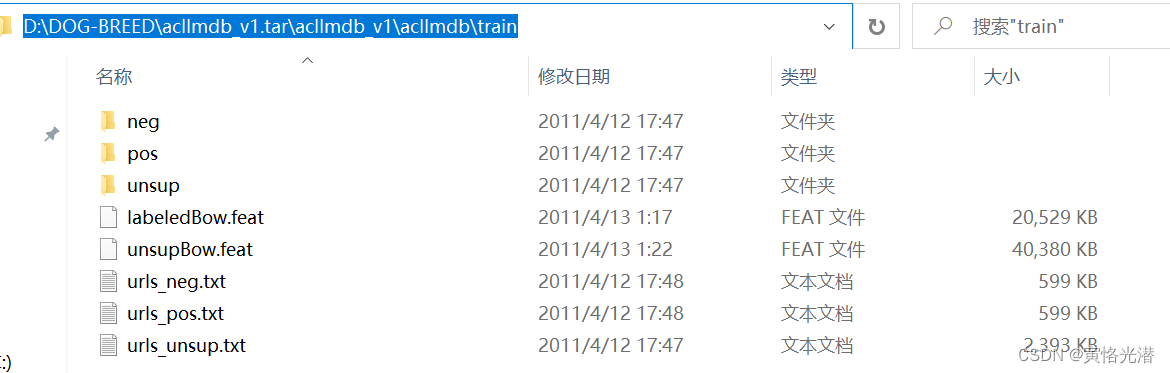
可以看到有train和test两个数据集,里面都有neg和pos的评论,分别表示负面和正面的评论:
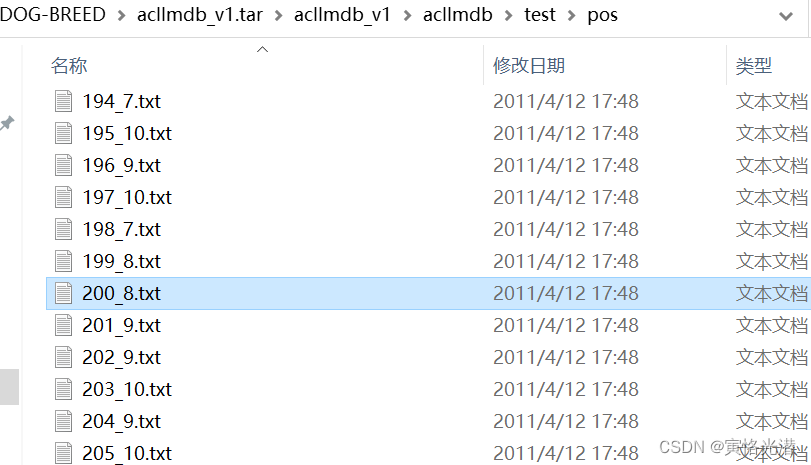
每个文本是一条影评,文本名称构造:id_评分,比如上面图中的200_8.txt表示id为200的这条影评的评分是8分。
还有一种feat文件,如下图:
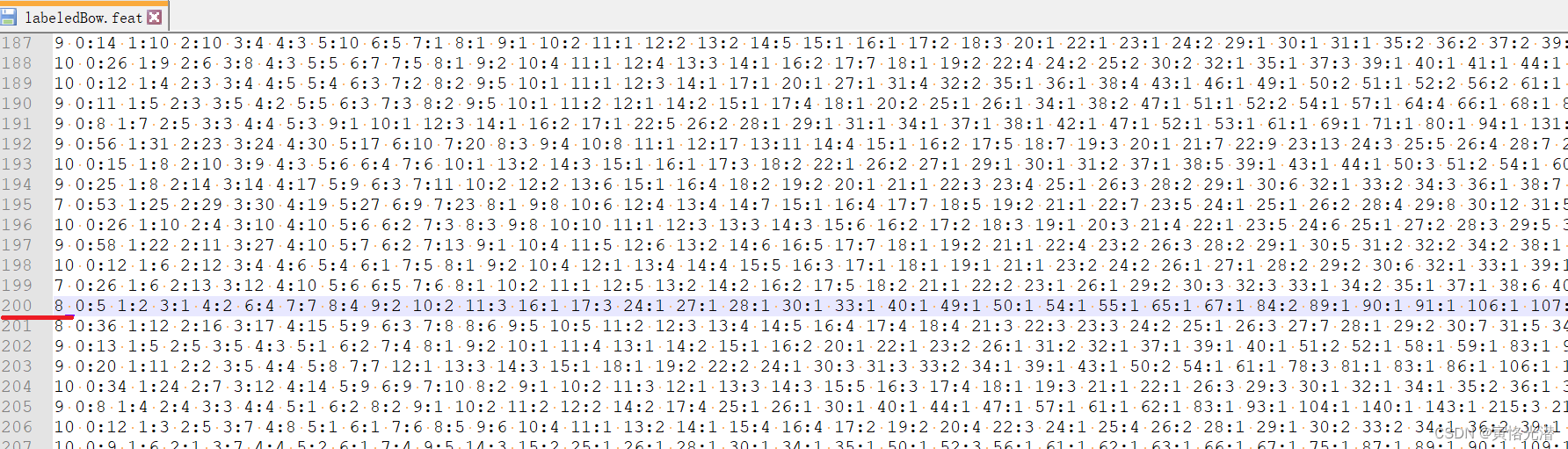
这种.feat文件的格式为LIBSVM,是一种用于标记的ascii稀疏向量格式数据,比如图片中红色划线处的第200条评论,8后面的数字表示什么意思呢?
8 0:5 1:2 3:1 4:2 6:4 7:7 8:4 9:2 10:2 11:3 16:1 17:3 ... ...
这里的0:5表示第一个单词出现了5次,1:2就是第二个单词出现了2次,后面依次类推。
接下来使用自带的read_imdb函数来读取训练集和测试集,当然这里使用自带的函数需要注意目录的位置,将aclImdb整个目录剪切到上级目录data里面,比如本人电脑上的地址:D:\data\aclImdb
train_data, test_data = d2l.read_imdb("train"), d2l.read_imdb("test")
print(train_data[1])
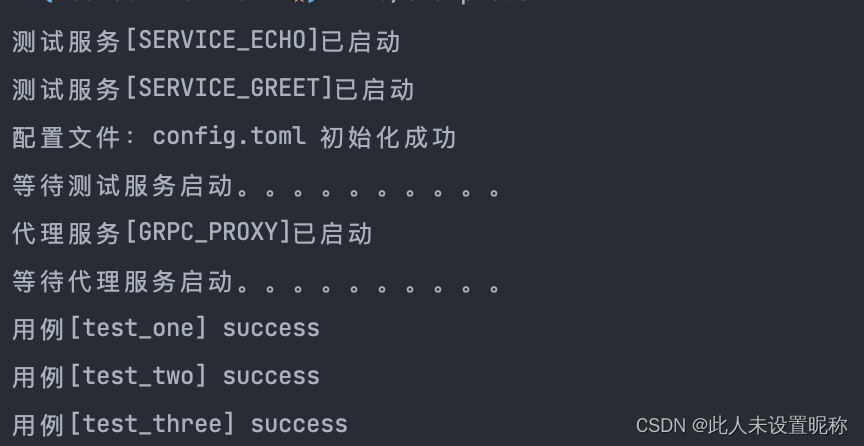
'''
(pygpu) D:\DOG-BREED>python test.py
["i went to this movie expecting an artsy scary film. what i got was scare after scare. it's a horror film at it's core. it's not dull like other horror films where a haunted house just has ghosts and gore. this film doesn't even show you the majority of the deaths it shows the fear of the characters. i think one of the best things about the concept where it's not just the house thats haunted its whoever goes into the house. they become haunted no matter where they are. office buildings, police stations, hotel rooms... etc. after reading some of the external reviews i am really surprised that critics didn't like this film. i am going to see it again this week and am excited about it.<br /><br />i gave this film 10 stars because it did what a horror film should. it scared the s**t out of me.", 1]
'''返回的结果是列表,里面元素是评论加一个正负类标签。这里是赞叹这部恐怖片拍的很不错,后面的1表示正类评价。
上面两个函数的源码附上[../envs/pygpu/Lib/site-packages/d2lzh/utils.py]:
def download_imdb(data_dir='../data'):
"""Download the IMDB data set for sentiment analysis."""
url = ('http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz')
sha1 = '01ada507287d82875905620988597833ad4e0903'
fname = gutils.download(url, data_dir, sha1_hash=sha1)
with tarfile.open(fname, 'r') as f:
f.extractall(data_dir)
def read_imdb(folder='train'):
"""Read the IMDB data set for sentiment analysis."""
data = []
for label in ['pos', 'neg']:
folder_name = os.path.join('../data/aclImdb/', folder, label)
for file in os.listdir(folder_name):
with open(os.path.join(folder_name, file), 'rb') as f:
review = f.read().decode('utf-8').replace('\n', '').lower()
data.append([review, 1 if label == 'pos' else 0])
random.shuffle(data)
return data预处理数据集
数据集和测试集读取没有问题之后,我们对评论进行分词,这里基于空格分词,也是自带的函数get_tokenized_imdb进行分词并做了小写处理。
def get_tokenized_imdb(data):
"""Get the tokenized IMDB data set for sentiment analysis."""
def tokenizer(text):
return [tok.lower() for tok in text.split(' ')]
return [tokenizer(review) for review, _ in data]然后将分好词的训练数据集创建Vocabulary词典,我们这里过滤掉出现次数少于5的词,min_freq=5。
def get_vocab_imdb(data):
"""Get the vocab for the IMDB data set for sentiment analysis."""
tokenized_data = get_tokenized_imdb(data)
counter = collections.Counter([tk for st in tokenized_data for tk in st])
return text.vocab.Vocabulary(counter, min_freq=5)
tokenized_data = d2l.get_tokenized_imdb(train_data)
vocab=d2l.get_vocab_imdb(train_data)
print(len(vocab))#46151可以看到过滤掉次数少的之后,词汇量从25000降低到了46151,这里返回的变量vocab是mxnet.contrib.text.vocab.Vocabulary类型,我们可以查看它里面有哪些属性与方法:
dir(mxnet.contrib.text.vocab.Vocabulary)
'''
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__len__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_index_counter_keys', '_index_unknown_and_reserved_tokens', 'idx_to_token', 'reserved_tokens', 'to_indices', 'to_tokens', 'token_to_idx', 'unknown_token']
'''
print(vocab.idx_to_token[1])#the由于每条评论的字数或说长度不一样,所以不能直接组合成小批量,我们通过一个辅助函数让它的长度固定在500,超出的进行截断,不足的进行'<pad>'补足。这个函数preprocess_imdb在d2lzh包中也自带有
features, labels = d2l.preprocess_imdb(train_data, vocab)
print(features.shape, labels.shape)#(25000, 500) (25000,)从形状可以看到每条评论都固定到了长度为500
print(features)
'''
[[5.0000e+00 5.3200e+02 0.0000e+00 ... 0.0000e+00 0.0000e+00 0.0000e+00]
[2.0100e+02 5.4810e+03 4.2891e+04 ... 1.6000e+01 2.9200e+02 1.1000e+01]
[0.0000e+00 0.0000e+00 3.6000e+01 ... 0.0000e+00 0.0000e+00 0.0000e+00]
...
[9.0000e+00 2.2600e+02 3.0000e+00 ... 0.0000e+00 0.0000e+00 0.0000e+00]
[2.8690e+03 1.2220e+03 1.4000e+01 ... 1.1538e+04 5.2700e+02 2.9000e+01]
[9.0000e+00 1.9900e+02 1.2108e+04 ... 0.0000e+00 0.0000e+00 0.0000e+00]]
<NDArray 25000x500 @cpu(0)>
'''附上源码:
def preprocess_imdb(data, vocab):
"""Preprocess the IMDB data set for sentiment analysis."""
max_l = 500
def pad(x):
return x[:max_l] if len(x) > max_l else x + [0] * (max_l - len(x))
tokenized_data = get_tokenized_imdb(data)
features = nd.array([pad(vocab.to_indices(x)) for x in tokenized_data])
labels = nd.array([score for _, score in data])
return features, labels当然如果想要查看'<pad>'对应的值,print(vocab.token_to_idx['<pad>'])会报错:
Traceback (most recent call last):
File "test.py", line 19, in <module>
print(vocab.token_to_idx['<pad>'])
KeyError: '<pad>'
所以在创建词典Vocabulary的时候,需指定参数reserved_tokens=['<pad>']保留这个词
def get_vocab_imdb(data):
"""Get the vocab for the IMDB data set for sentiment analysis."""
tokenized_data = d2l.get_tokenized_imdb(data)
counter = collections.Counter([tk for st in tokenized_data for tk in st])
return text.vocab.Vocabulary(counter, min_freq=5,reserved_tokens=['<pad>'])创建数据迭代器
数据集都整理好了之后,就开始做数据迭代器,每次迭代将返回一个小批量的数据
batch_size = 64
#train_set = gdata.ArrayDataset(*d2l.preprocess_imdb(train_data, vocab))
train_set=gdata.ArrayDataset(*[features,labels])
test_set = gdata.ArrayDataset(*d2l.preprocess_imdb(test_data, vocab))
train_iter = gdata.DataLoader(train_set, batch_size, shuffle=True)
test_ieter = gdata.DataLoader(test_set, batch_size)
print(len(train_iter))
for X,y in train_iter:
print(X.shape,y.shape)
break
'''
391
(64, 500) (64,)
'''创建RNN模型
数据迭代器测试没有问题之后,接下来就是选择循环神经网络模型来试下效果怎么样了。
首先就是将每个词做嵌入,也就是通过嵌入层得到特征向量,然后我们使用双向循环神经网络对特征序列进一步编码得到序列信息,最后将编码的序列信息通过全连接层变换成输出。
具体来说,我们可以将双向长短期记忆在最初时间步和最终时间步的隐藏状态连结,作为特征序列的表征传递给输出层分类。在下面实现BiRNN类中,Embedding实例就是嵌入层,LSTM实例即为序列编码的隐藏层,Dense实例即生成分类结果的输出层。
class BiRNN(nn.Block):
def __init__(self, vocab, embed_size, num_hiddens, num_layers, **kwargs):
super(BiRNN, self).__init__(**kwargs)
# 词嵌入层
self.embedding = nn.Embedding(input_dim=len(vocab), output_dim=embed_size)
# bidirectional设为True就是双向循环神经网络
self.encoder = rnn.LSTM(
hidden_size=num_hiddens,
num_layers=num_layers,
bidirectional=True,
input_size=embed_size,
)
self.decoder = nn.Dense(2)
def forward(self, inputs):
# LSTM需要序列长度(词数)作为第一维,所以inputs[形状为:(批量大小,词数)]需做转置
embeddings = self.embedding(inputs.T)
print(embeddings.shape)
outputs = self.encoder(embeddings)
print(outputs.shape)
# 将初始时间步和最终时间步的隐藏状态作为全连接层输入
encoding = nd.concat(outputs[0], outputs[-1])
print(encoding.shape)
outs = self.decoder(encoding)
return outs
# 创建一个含2个隐藏层的双向循环神经网络
embed_size, num_hiddens, num_layers, ctx = 100, 100, 2, d2l.try_all_gpus()
net = BiRNN(
vocab=vocab, embed_size=embed_size, num_hiddens=num_hiddens, num_layers=num_layers
)
net.initialize(init.Xavier(), ctx=ctx)
#print(net)
'''
BiRNN(
(embedding): Embedding(46152 -> 100, float32)
(encoder): LSTM(100 -> 100, TNC, num_layers=2, bidirectional)
(decoder): Dense(None -> 2, linear)
)
'''其中LSTM长短期记忆的公式如下(来自源码):
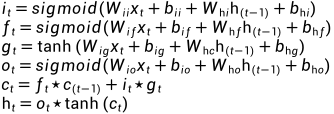
训练模型
由于情感分类的训练数据集并不大,容易过拟合,所以这里将使用glove.6B.100d.txt的语料库,将这个预训练的词向量作为每个词的特征向量。
需要注意的是,这里选择的预训练词向量维度是100,需要跟创建的模型中的嵌入层输出层大小embed_size一致,以及在训练中就不再需要更新这些词向量。
glove_embedding = text.embedding.create(
"glove", pretrained_file_name="glove.6B.100d.txt", vocabulary=vocab
)
net.embedding.weight.set_data(glove_embedding.idx_to_vec)
net.embedding.collect_params().setattr('grad_req','null')
lr,num_epochs=0.01,5
trainer=gluon.Trainer(net.collect_params(),'adam',{'learning_rate':lr})
loss=gloss.SoftmaxCrossEntropyLoss()
d2l.train(train_iter,test_ieter,net,loss,trainer,ctx,num_epochs)
print(d2l.predict_sentiment(net,vocab,['this','movie','is','so','good']))
print(d2l.predict_sentiment(net,vocab,['this','movie','is','so','bad']))
'''
training on [gpu(0)]
epoch 1, loss 0.6553, train acc 0.605, test acc 0.738, time 65.4 sec
epoch 2, loss 0.4273, train acc 0.807, test acc 0.809, time 65.4 sec
epoch 3, loss 0.3514, train acc 0.851, test acc 0.849, time 65.5 sec
epoch 4, loss 0.3054, train acc 0.874, test acc 0.859, time 65.6 sec
epoch 5, loss 0.2765, train acc 0.887, test acc 0.843, time 65.6 sec
positive
negative
'''其中预测函数的源码如下:
def predict_sentiment(net, vocab, sentence):
"""Predict the sentiment of a given sentence."""
sentence = nd.array(vocab.to_indices(sentence), ctx=try_gpu())
label = nd.argmax(net(sentence.reshape((1, -1))), axis=1)
return 'positive' if label.asscalar() == 1 else 'negative'