虽然现在各种量化教程和自助平台铺天盖地,但是对于新人来说入门最重要的事情就是挖掘特征。
对于传统的学习路径第一步是学习Python或者某一门编程语言,虽说Python入门容易上手快,但是要在实际应用中对股票数据进行分析,并挖掘有用特征还是一件比较麻烦的事情。以一个简单的分析为例,使用从Kaggle下载的日本股市数据(实验使用train_files目录下的stock_prices.csv,或者直接下载CSDN附件):
- 计算买入后持有1天,2天的收益
- 计算3个指标:5日,10日均价,以及日最高价除以最低价的5日最大值。
- 分析上述3个指标以及组合后与收益的关系,寻找潜在可用的特征组合。
- 对指标进行挡位划分后对特征做进一步的分析。
直接使用编程语言当然可以解决问题,但是存在以下几个挑战:
- 原始数据包含多个交易日多个股票的数据,需要进行拆分。
- 针对单个股票数据,计算特征需要自行设计算法管理时间窗口。
- 数据挡位划分,特征排列组合需要大量代码实现。
- 代码正确性验证困难,维护理解成本高。
相比与Python之类的编程语言,SQL最大的特点是声明式的,你只需要告诉系统你想做什么,具体怎么做系统在后台帮你默默完成。上面我们提到的几个挑战,借助于SQL的OLAP函数我们可以轻松完成。
本教程使用Jupyter Lab编写,大家可以直接安装Anaconda全家桶,也可以安装较小的mini conda,在文章的末尾有相关安装参考教程链接。安装后执行"pip install asqlcell"安装jupyter lab的一个sql插件,本文的Python/SQL混合编程依赖该插件实现。在教程中我们也会顺带穿插讲解一下用到的OLAP函数。
点这里下载测试数据。
首先引入我们需要的包
import asqlcell使用sql加载数据,直接使用csv文件作为数据源。%%sql代表后面要执行的是SQL语句,%%sql后面跟的名字用于存储SQL语句执行的结果,是pandas的DataFrame类型,可以在Python代码里直接访问使用。
%%sql prices
select RowId as code,
strftime(Date, '%Y-%m-%d') as date,
Open as open,
High as high,
Low as low,
Close as close
from stock_prices.csv执行结果如下:
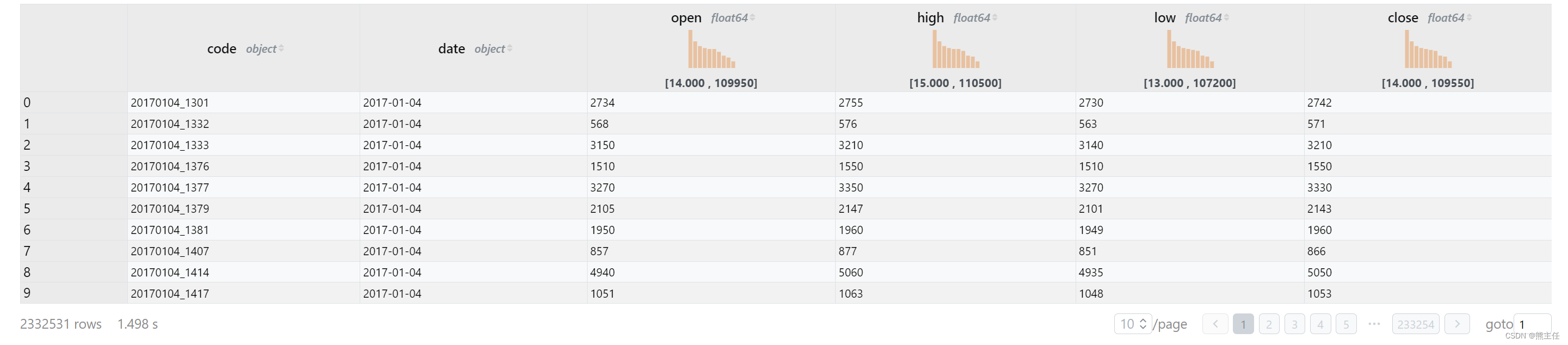
使用asqlcell插件,在标题栏对数值类型直接展示了一个简单的分布提示,可以点击进行排序,还可以分页查看所有数据。
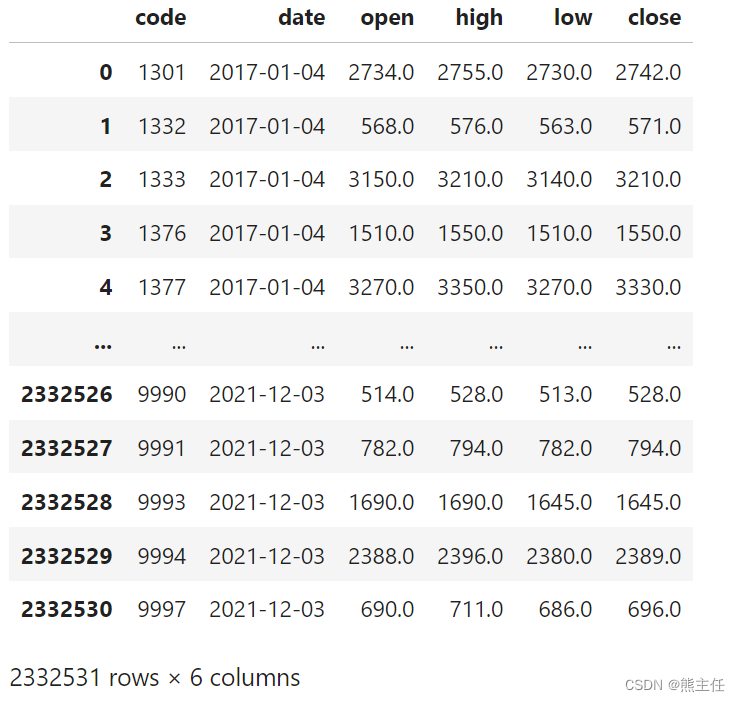
源数据的code字段是"日期_股票代码"的格式,这部分处理也可用用SQL完成,但是我们使用asqlcell插件的优点就是可用进行混合编程,因为SQL语句返回的数据集是pandas的DataFrame,所以这里就用Python来做个简单的处理。
prices['code'] = prices['code'].str.split('_', expand=True)[1]
prices查看一下prices,确认后我们在此基础上开始分析处理。
现在插播一下OLAP函数,虽然很多同学都能熟练使用group by和聚合函数求和求平均,但是对OLAP相关函数使用还是比较陌生。
我们有一张如下的销售业绩表,我们需要对每个地区的销售员业绩进行排序。直接用order by是对所有人的业绩排序,如果用group by则可以根据每个地区的业绩汇总(总和,平均...)等进行排序。那怎么对做到根据每个地区分组然后再根据每个组的排序结果给出排名序号呢?
| 员工 | 地区 | 业绩 |
| Tom | 上海 | 80 |
| Jack | 广州 | 90 |
| Marry | 广州 | 110 |
| Mike | 上海 | 85 |
| Jeff | 上海 | 70 |
现在我们就需要借助OLAP函数了,也被称为窗口函数。因为我们按地区把数据划分为一个个窗口,然后在窗口内做排序。代码如下:
%%sql sales_rank
select *, rank() over (partition by 地区 order by 业绩 desc) as ranking
from data.csv
窗口函数的基本语法规则如下:
<窗口函数> over (partition by <用于分组的列名> order by <用于排序的列名>)在这里我们根据地区对数据进行分组,按照每个地区的数据根据业绩倒序排序,然后再使用rank函数计算每个窗口内员工的排名。这个功能如果用Python实现,大概分为以下几步:1)通过字典将数据分组;2)实现排序函数;3)根据排序结果填充排名;4)数据合并。显然通过SQL实现效率大大提高了,执行效率在我们后面的例子会体现出来,肯定比你直接用Python实现跑得快。
与GROUP BY相比,窗口函数不影响数据的总行数,只是计算在每个窗口分别进行。
如果窗口需要复用,可以使用window关键字将这部分提取出来:
%%sql sales_rank
select *, rank() over area_window as ranking
from data.csv
window
area_window as (partition by 地区 order by 业绩 desc)现在我们进入正题,需求如下,计算以下以下特征:
- FA: 5日均线
- FB: 10日均线
- FC: 日最高价除以最低价的5日最大值
- GA1: 当前交易日的下一个交易日开盘价买入,T+1日收盘价卖出的收益
- GA2: 当前交易日的下一个交易日开盘价买入,T+2日收盘价卖出的收益
我们使用上面生成的prices数据集,以5日均线这个特征为例。首先是怎么划分窗口,因为数据包含了一段时间内所有股票的数据,所以我们根据股票代码划分窗口,每个窗口代表一个股票,然后再根据日期从远到近排序。因为我们要找的是5日均线,所以用between限制数据范围。"4 preceding and 0 following"代表从4天前到今天总共5天。
代码如下:
%%sql fa
select code,
date,
avg(close) over five as fa,
from prices
window
five as (partition by code order by date asc rows between 4 preceding and 0 following)230万行数据,1.65秒完成了计算和输出。
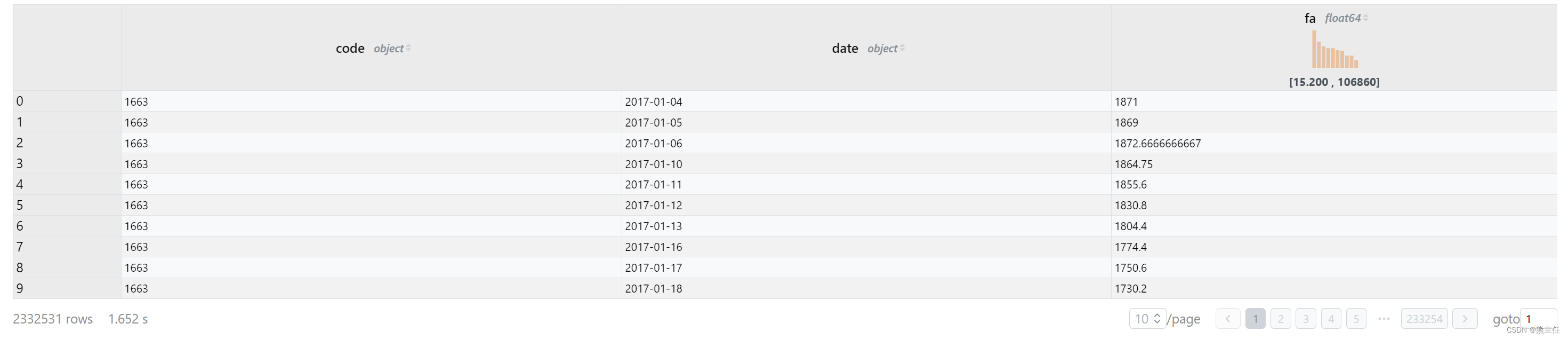
下面我们要计算T+1的收益,对于某个股票某一天这条记录来说,就是买入价按后一天的开盘价计算,卖出价按再后一天的收盘价计算。我们直接根据股票代码划分窗口,每个窗口按日期排序就可以。关于如何选择后N天的记录我们可以使用lead函数。如果是前N天则使用lag函数。
%%sql gain
select code,
date,
(lead(close, 2, null) over days) / (lead(close, 1, null) over days) - 1 as ga1,
(lead(close, 3, null) over days) / (lead(close, 1, null) over days) - 1 as ga2
from prices
window
days as (partition by code order by date asc)到这里大家可以自己尝试一下解决这两个问题:
- 计算”日最高价除以最低价的5日最大值“
- 可能会存在开盘价格一部拉到位无法买入的情况,如何判断?
下面我们提供完整的SQL语句:
%%sql features
select code,
date,
avg(close) over five as FA,
avg(close) over ten as FB,
max(high / close) OVER five as FC,
(lead(low, 1, null) over days) < (lead(high, 1, null) over days) as canBuy,
(lead(close, 2, null) over days) / (lead(close, 1, null) over days) - 1 as GA1,
(lead(close, 3, null) over days) / (lead(close, 1, null) over days) - 1 as GA2
from prices
window
five as (partition by code order by date asc rows between 4 preceding and 0 following),
ten as (partition by code order by date asc rows between 9 preceding and 0 following),
days as (partition by code order by date asc)230万行数据不到3秒就完成了处理。
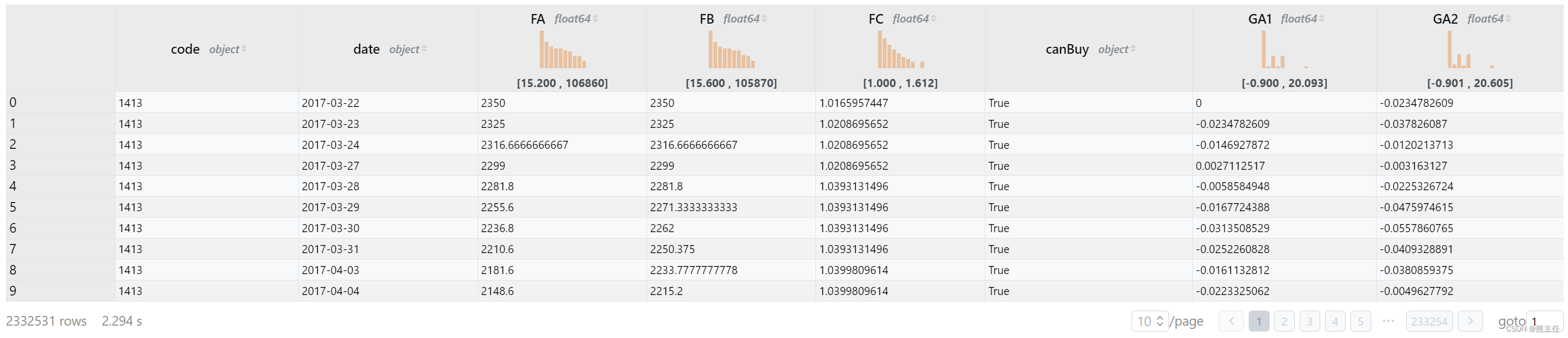
下面我们要根据收益的情况对FA/FB/FC三个特征进行分析。分析前必须对以下数据进行过滤:1)收益超过30%的记录(不要相信天上掉馅饼);2)没有买入机会的记录(参考A股就是全体封死涨停板)。经过处理发现大约4万条记录被过滤。
%%sql filtered_features
select *
from features
where GA1 is not null and
abs(GA1) < 0.30 and
GA2 is not null and
abs(GA2) < 0.3 and
canBuy is not null and
canBuy我们做一个简单的相关性分析,及计算特征与收益的相关系数。一般来说,相关系数越大这个特征越值得我们关注,及变化方向趋同更明显。如果是负值则表明变化方向相反。
%%sql corr
select corr(FA, GA1) as ca_1,
corr(FB, GA1) as cb_1,
corr(FC, GA2) as cc_1,
corr(FA, GA2) as ca_2,
corr(FB, GA2) as cb_2,
corr(FC, GA2) as cc_2
from filtered_features
在实际工作中,一个特征往往会继续划分,比如收入我们会细分不同的收入层次。这里我们把5日均线这个特征分为几档,查看不同挡位的收益分布。这里我们会发现低挡位的收益表现要好于高档位。
%%sql analysis
SELECT RFA, avg(GA1) * 100 as GA1, avg(GA2) * 100 as GA2, count(1) as rows
from
(
select cast(percent_rank() over wfa * 5 as int) as RFA,
ga1, ga2
from filtered_features
window
wfa as (partition by date order by FA)
)
group by RFA
在实际应用中,我们肯定不会只使用一个指标,如果我们想查看所有指标排列组合后的情况呢?cube函数可以帮到你,使用cube(a, b, c)等于生成不同的组合group by然后把结果合并起来。
%%sql cube_analysis
SELECT RFA, RFB, RFC, avg(GA1) * 100 as GA1, avg(GA2) * 100 as GA2, count(1) as rows
from
(
select cast(percent_rank() over window_fa * 5 as int) as RFA,
cast(percent_rank() over window_fb * 5 as int) as RFB,
cast(percent_rank() over window_fc * 5 as int) as RFC,
ga1, ga2
from filtered_features
window
window_fa as (partition by date order by FA),
window_fb as (partition by date order by FB),
window_fc as (partition by date order by FC)
)
group by cube(RFA, RFB, RFC)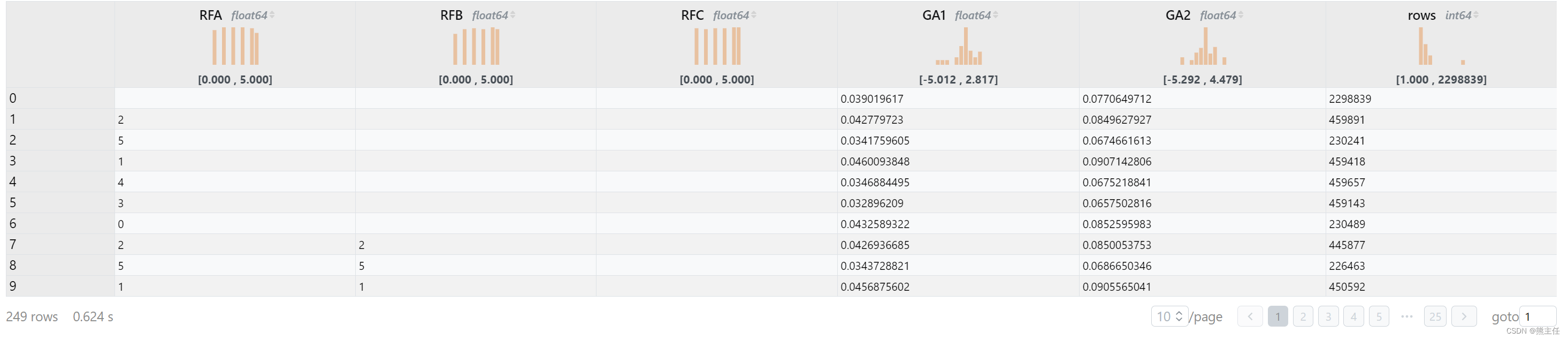
我们可以直接筛选一下,找出T+1收益大于0.1%或者T+2收益大于0.2%的记录。对结果排序我们会发现一些好的特征组合。最好的特征居然一天就有接近3%的收益,但是记录条数太少,属于可遇不可求。可以点击rows看下记录最多的组合,收益接近0.1%每天,不考虑手续费年化收益超过20%。争对这种特征,可以考虑试着去做进一步的深入挖掘看是否有实盘机会。
%%sql good_features
select *
from cube_analysis
where (GA1 > 0.1) or (GA2 > 0.2)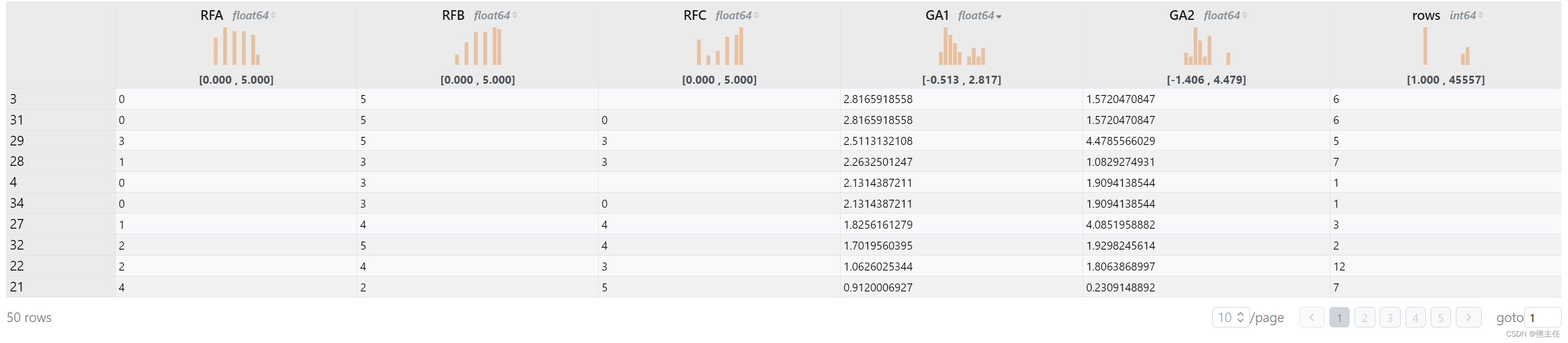
相比传统的Python编程,使用SQL语句对数据进行把玩表达能力更强,出错更容易排查,对结果验证也比较方便。大家可以试着在网上下载数据进行实验,练好神功,早日实现财务自由。