最近碰到同事咨询的一个问题,在执行一个函数时,发现会一直卡在那里。
strace抓了下发现会话一直在执行lseek,大致情况如下:
16:13:55.451832 lseek(33, 0, SEEK_END) = 1368064 <0.000037> 16:13:55.477216 lseek(33, 0, SEEK_END) = 1368064 <0.000026> 16:13:55.502579 lseek(33, 0, SEEK_END) = 1368064 <0.000026> 16:13:55.528162 lseek(33, 0, SEEK_END) = 1368064 <0.000024> 16:13:55.553714 lseek(33, 0, SEEK_END) = 1368064 <0.000025> 16:13:55.579242 lseek(33, 0, SEEK_END) = 1368064 <0.000022> ...... % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 0.00 0.000000 0 124 lseek ------ ----------- ----------- --------- --------- ---------------- 100.00 0.000000 124 total
而当手动去取消掉会话时也能发现,是卡在了其中一个insert语句:
[postgres@xxx/(rasesql)himsdpsods][02-22.16:13:24]M=# select pgawr_snap('cron based snapshot',59451);
^CCancel request sent
ERROR: 57014: canceling statement due to user request
CONTEXT: SQL statement "INSERT INTO pgawr_indexes
( snapid, idx_scan, idx_tup_read, idx_tup_fetch, idx_blks_read,
idx_blks_hit, index_name_id, table_name_id)
SELECT
spid as snapid,
i.idx_scan as idx_scan,
i.idx_tup_read as idx_tup_read,
i.idx_tup_fetch as idx_tup_fetch,
ii.idx_blks_read as idx_blks_read,
ii.idx_blks_hit as idx_blks_hit,
n1.nameid,
n2.nameid
FROM
pg_stat_all_indexes i
join pg_statio_all_indexes ii on i.indexrelid = ii.indexrelid
join pgawr_names n1 on i.schemaname ||'.'|| i.indexrelname=n1.name
join pgawr_names n2 on i.schemaname ||'.'|| i.relname=n2.name"
PL/pgSQL function pgawr_snap(character varying,bigint) line 104 at SQL statement
LOCATION: ProcessInterrupts, postgres.c:3203
Time: 203994.651 ms (03:23.995)
当然分析这种函数执行慢的,最常用的还是auto_explain,可以在会话中设置来打印函数中具体执行的情况:
load 'auto_explain'; set client_min_messages='log'; set auto_explain.log_min_duration = 0; set auto_explain.log_analyze = true; set auto_explain.log_verbose = true; set auto_explain.log_buffers = true; set auto_explain.log_nested_statements = true;
根据上面得到的信息发现文件句柄33对应的恰好也是该SQL中的一张表,而lseek(33, 0, SEEK_END) = 1368064的返回值也的确是和该数据文件的大小一致,说明的确是扫描完该表了。
那就有点奇怪了,这个SQL也很简单,而且单独拿出来执行也都没问题,为什么会一直卡在lseek这个数据文件这里呢?
上网搜了下,发现有个类似的bug:BUG #15455: Endless lseek,其中的情况和我这个有些类似:

但是往后看了malilist里面的讨论也是不了了之,最终也没有个结论。。。
哎,没有办法,只能自己接着分析了。
为了方便查看,我这里把SQL简写了,insert也换成select。
[postgres@xxx/(rasesql)himsdpsods][02-22.16:40:10]M=# EXPLAIN ANALYZE SELECT
-> i.idx_scan as idx_scan,
-> i.idx_tup_read as idx_tup_read,
-> i.idx_tup_fetch as idx_tup_fetch,
-> ii.idx_blks_read as idx_blks_read,
-> ii.idx_blks_hit as idx_blks_hit,
-> n1.nameid
-> FROM
-> pg_stat_all_indexes i
-> join pg_statio_all_indexes ii on i.indexrelid = ii.indexrelid
-> join pgawr_names n1 on i.schemaname ||'.'|| i.indexrelname=n1.name;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=1805.21..3055.18 rows=3 width=44) (actual time=0.381..0.384 rows=0 loops=1)
Join Filter: ((((n.nspname)::text || '.'::text) || (i.relname)::text) = (n1.name)::text)
-> Seq Scan on pgawr_names n1 (cost=0.00..228.00 rows=1 width=44) (actual time=0.380..0.381 rows=0 loops=1)
-> Nested Loop (cost=1805.21..2815.83 rows=502 width=136) (never executed)
-> Hash Join (cost=1804.92..2585.91 rows=502 width=140) (never executed)
Hash Cond: (c.relnamespace = n.oid)
-> Nested Loop (cost=1801.01..2580.62 rows=502 width=80) (never executed)
-> Hash Join (cost=1800.73..2057.32 rows=900 width=12) (never executed)
Hash Cond: (x.indexrelid = x_1.indexrelid)
-> Hash Join (cost=766.65..1005.74 rows=2267 width=8) (never executed)
Hash Cond: (x.indrelid = c.oid)
-> Seq Scan on pg_index x (cost=0.00..224.09 rows=5709 width=8) (never executed)
-> Hash (cost=715.81..715.81 rows=4067 width=8) (never executed)
-> Seq Scan on pg_class c (cost=0.00..715.81 rows=4067 width=8) (never executed)
Filter: (relkind = ANY ('{r,t,m}'::"char"[]))
-> Hash (cost=1005.74..1005.74 rows=2267 width=4) (never executed)
-> Hash Join (cost=766.65..1005.74 rows=2267 width=4) (never executed)
Hash Cond: (x_1.indrelid = c_1.oid)
-> Seq Scan on pg_index x_1 (cost=0.00..224.09 rows=5709 width=8) (never executed)
-> Hash (cost=715.81..715.81 rows=4067 width=8) (never executed)
-> Seq Scan on pg_class c_1 (cost=0.00..715.81 rows=4067 width=8) (never executed)
Filter: (relkind = ANY ('{r,t,m}'::"char"[]))
-> Index Scan using pg_class_oid_index on pg_class i (cost=0.29..0.58 rows=1 width=68) (never executed)
Index Cond: (oid = x.indexrelid)
-> Hash (cost=2.85..2.85 rows=85 width=68) (never executed)
-> Seq Scan on pg_namespace n (cost=0.00..2.85 rows=85 width=68) (never executed)
-> Index Only Scan using pg_class_oid_index on pg_class i_1 (cost=0.29..0.46 rows=1 width=4) (never executed)
Index Cond: (oid = i.oid)
Heap Fetches: 0
可以看到卡住的SQL拿出来单独执行是没有问题的,但是仔细观察可以发现,该执行计划中很多never executed的节点,说明下面的这些部分实际都没有执行,那是因为pgawr_names这张表是空的,因此对于这个嵌套循环来说,被驱动的部分其实就没有必要执行了。
而查看完该函数的内容之后发现,在执行这个SQL之前是有往pgawr_names这张表里面插入数据的。
这样一下子就有思路了:因为在同一个会话中,前一条SQL往pgawr_names表里面插入了大量数据,而表的统计信息在会话提交前是不会更新的。
[postgres@xxx/(rasesql)himsdpsods][02-22.16:54:40]M=# begin; BEGIN Time: 0.128 ms [postgres@xxx/(rasesql)himsdpsods][02-22.16:55:11]M=# select n_live_tup,last_analyze from pg_stat_all_tables where relname = 'pgawr_names'; n_live_tup | last_analyze ------------+------------------------------- 0 | 2023-02-22 15:09:43.348236+08 (1 row) Time: 11.319 ms [postgres@xxx/(rasesql)himsdpsods][02-22.16:55:27]M=# insert into pgawr_names (name) -> select distinct i.schemaname ||'.'|| i.indexrelname -> from pg_stat_all_indexes i -> left join pgawr_names on i.schemaname ||'.'|| i.indexrelname=name -> where -> name is null; INSERT 0 5709 Time: 207.526 ms [postgres@xxx/(rasesql)himsdpsods][02-22.16:55:41]M=# ANALYZE pgawr_names ; ANALYZE Time: 73.666 ms [postgres@xxx/(rasesql)himsdpsods][02-22.16:55:46]M=# select n_live_tup,last_analyze from pg_stat_all_tables where relname = 'pgawr_names'; n_live_tup | last_analyze ------------+------------------------------- 0 | 2023-02-22 15:09:43.348236+08 (1 row) Time: 0.876 ms
既然如此,看来前面看到的会话一直卡在lseek其实是执行计划后面的嵌套循环太多导致的,我们可以把pgawr_names表中手动插入较少的数据来验证下:
[postgres@xxx:6266/(rasesql)himsdpsods][02-22.17:02:00]M=# begin;
BEGIN
Time: 0.141 ms
[postgres@xxx:6266/(rasesql)himsdpsods][02-22.17:02:02]M=# select n_live_tup,last_analyze from pg_stat_all_tables where relname = 'pgawr_names';
n_live_tup | last_analyze
------------+-------------------------------
0 | 2023-02-22 17:01:53.272047+08
(1 row)
Time: 11.615 ms
[postgres@xxx:6266/(rasesql)himsdpsods][02-22.17:02:03]M=# insert into pgawr_names(name) select md5(random()::text) from generate_series(1,200);
INSERT 0 200
Time: 52.083 ms
[postgres@xxx:6266/(rasesql)himsdpsods][02-22.17:02:28]M=# EXPLAIN ANALYZE SELECT
-> i.idx_scan as idx_scan,
-> i.idx_tup_read as idx_tup_read,
-> i.idx_tup_fetch as idx_tup_fetch,
-> ii.idx_blks_read as idx_blks_read,
-> ii.idx_blks_hit as idx_blks_hit,
-> n1.nameid
-> FROM
-> pg_stat_all_indexes i
-> join pg_statio_all_indexes ii on i.indexrelid = ii.indexrelid
-> join pgawr_names n1 on i.schemaname ||'.'|| i.indexrelname=n1.name;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=1805.21..3055.18 rows=3 width=44) (actual time=5618.220..5618.229 rows=0 loops=1)
Join Filter: ((((n.nspname)::text || '.'::text) || (i.relname)::text) = (n1.name)::text)
Rows Removed by Join Filter: 1141800
-> Seq Scan on pgawr_names n1 (cost=0.00..228.00 rows=1 width=44) (actual time=0.014..0.417 rows=200 loops=1)
-> Nested Loop (cost=1805.21..2815.83 rows=502 width=136) (actual time=0.071..26.143 rows=5709 loops=200)
-> Hash Join (cost=1804.92..2585.91 rows=502 width=140) (actual time=0.069..16.342 rows=5709 loops=200)
Hash Cond: (c.relnamespace = n.oid)
-> Nested Loop (cost=1801.01..2580.62 rows=502 width=80) (actual time=0.068..14.519 rows=5709 loops=200)
-> Hash Join (cost=1800.73..2057.32 rows=900 width=12) (actual time=0.066..4.280 rows=5709 loops=200)
Hash Cond: (x.indexrelid = x_1.indexrelid)
-> Hash Join (cost=766.65..1005.74 rows=2267 width=8) (actual time=0.028..2.815 rows=5709 loops=200)
Hash Cond: (x.indrelid = c.oid)
-> Seq Scan on pg_index x (cost=0.00..224.09 rows=5709 width=8) (actual time=0.002..0.833 rows=5709 loops=200)
-> Hash (cost=715.81..715.81 rows=4067 width=8) (actual time=5.083..5.085 rows=4070 loops=1)
Buckets: 4096 Batches: 1 Memory Usage: 191kB
-> Seq Scan on pg_class c (cost=0.00..715.81 rows=4067 width=8) (actual time=0.010..4.506 rows=4070 loops=1)
Filter: (relkind = ANY ('{r,t,m}'::"char"[]))
Rows Removed by Filter: 6170
-> Hash (cost=1005.74..1005.74 rows=2267 width=4) (actual time=7.443..7.445 rows=5709 loops=1)
Buckets: 8192 (originally 4096) Batches: 1 (originally 1) Memory Usage: 265kB
-> Hash Join (cost=766.65..1005.74 rows=2267 width=4) (actual time=4.328..6.637 rows=5709 loops=1)
Hash Cond: (x_1.indrelid = c_1.oid)
-> Seq Scan on pg_index x_1 (cost=0.00..224.09 rows=5709 width=8) (actual time=0.005..1.006 rows=5709 loops=1)
-> Hash (cost=715.81..715.81 rows=4067 width=8) (actual time=4.312..4.313 rows=4070 loops=1)
Buckets: 4096 Batches: 1 Memory Usage: 191kB
-> Seq Scan on pg_class c_1 (cost=0.00..715.81 rows=4067 width=8) (actual time=0.009..3.746 rows=4070 loops=1)
Filter: (relkind = ANY ('{r,t,m}'::"char"[]))
Rows Removed by Filter: 6170
-> Index Scan using pg_class_oid_index on pg_class i (cost=0.29..0.58 rows=1 width=68) (actual time=0.001..0.001 rows=1 loops=1141800)
Index Cond: (oid = x.indexrelid)
-> Hash (cost=2.85..2.85 rows=85 width=68) (actual time=0.038..0.039 rows=85 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 17kB
-> Seq Scan on pg_namespace n (cost=0.00..2.85 rows=85 width=68) (actual time=0.010..0.023 rows=85 loops=1)
-> Index Only Scan using pg_class_oid_index on pg_class i_1 (cost=0.29..0.46 rows=1 width=4) (actual time=0.001..0.001 rows=1 loops=1141800)
Index Cond: (oid = i.oid)
Heap Fetches: 1141800
Planning Time: 3.383 ms
Execution Time: 5618.715 ms
(38 rows)
Time: 5623.090 ms (00:05.623)
发现果然如此,仅仅插入了200条数据而已,循环次数就达到了1141800次(5709*200)。而在原先的函数中往pgawr_names表中插入了有5000多条数据,这意味着至少要循环1千万次,这也是为什么会觉得SQL一直卡住在执行lseek的原因了。
回头再去看BUG #15455: Endless lseek,其实也是类似的原因,由于在会话中表数据量变化较多,而统计信息无法更新,同时SQL中有嵌套循环,导致性能异常,陷入了endless lseek中。
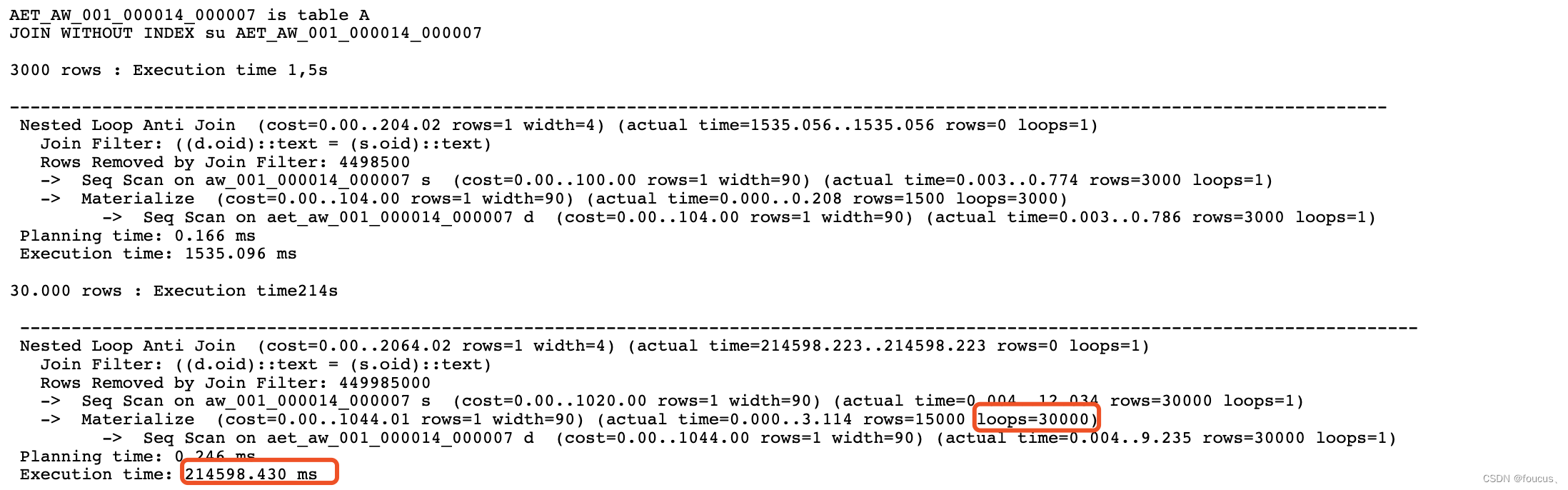
对此我们需要注意了,如果在同一个事务中先对某张表进行大量的增删操作,又由于其统计信息在事务结束前是不会更新的,而恰好该事务后面又有相关查询使用了该表,可能会对性能产生巨大影响,而如果该SQL中又包含较多嵌套循环,那么你也可能陷入看上去无休无止的lseek中了~