文章目录
- 随机森林在决策树的哪些方面做出了改进
- 随机森林里每棵树的权重不一定会变成什么模型
- 方差和偏差,正则化解决的是方差大还是偏差大的问题
- 正则化的方法总结
- 了解VC维吗
- svd++了解吗
随机森林在决策树的哪些方面做出了改进
回答思路:
- 随机森林和决策树有什么关联
- 和决策树相比,随机森林在哪些方面有什么优势
回答:
- 随机森林是决策树的集成模型,它将多个决策树的输出整合起来生成最后的输出结果
- 优势:
- 1.随机决策森林纠正了决策树的过度拟合(最主要):
- 集成学习的优势:单棵决策树对数据的变化很敏感,很容易对一些噪声进行过拟合,当不断添加决策树到随机森林中时,过拟合的趋势会减少。
- 引入随机性:在随机森林构建每棵决策树时,选择的特征子集是随机的,训练样本集也是随机的,随机性的引入在一定程度上减少了过拟合现象的发生
- 随机森林的核心思想是“三个臭皮匠顶个诸葛亮”,即构建由多个弱分类器组合成的强分类器,所以在训练每棵决策树时,树的复杂度不会很高,这也减少了过拟合的趋势
- 1.随机决策森林纠正了决策树的过度拟合(最主要):
随机森林里每棵树的权重不一定会变成什么模型
方差和偏差,正则化解决的是方差大还是偏差大的问题
一张图概括
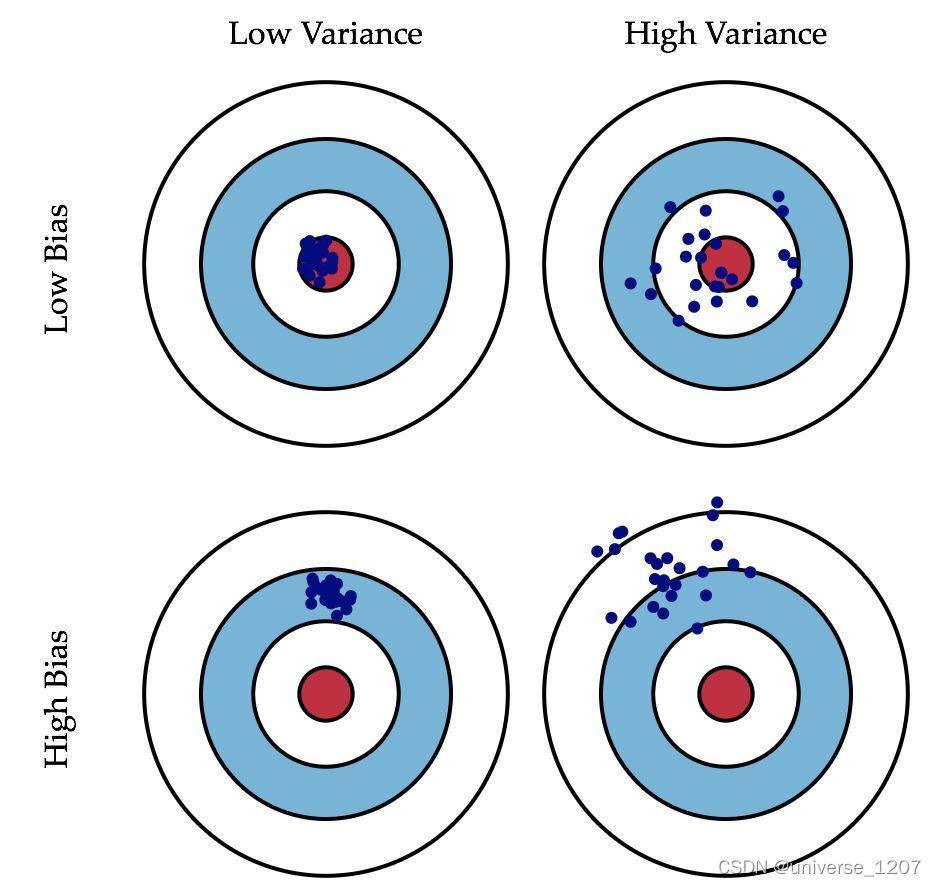
- 偏差bias:描述的是预测值的期望与真实值之间的差距。偏差越大,越偏离真实数据
- 方差:描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,数据的分布越分散
- 偏差大,说明预测不准确,模型太简单
- 方差大,说明数据一点点波动就引起输出的巨大偏移,学习能力过强,过拟合了
- 总结一下:学习能力不行造成的误差是偏差,学习能力太强造成的误差是方差
- 正则化解决的是模型太复杂的问题,也就是过拟合,所以解决的是方差大的问题
正则化的方法总结
参考BGoodHabit博主
- 首先,正则化是啥意思?我记得好像是在支持向量机中提出过,软间隔支持向量机那一章
- 传统定义:在模型的损失函数增加惩罚项来增强模型的泛化能力
- 现在定义更广泛,为提高测试集精度的一切方式都能称作正则化