一 概述
简介
LinkedBlockingDeque(链接阻塞双端队列)类(下文简称链接阻塞双端队列)是BlockingDeqeue(阻塞双端队列)接口的唯一实现类,采用链表的方式实现。链接阻塞双端队列与LinkedBlockingQueue(链接阻塞队列)类在实现上基本一致,但在其基础上新增了针对队列头部进行插入/放置及针对队列尾部进行移除/拿取、检查等操作的方法及其实现。通俗的讲就是链接阻塞双端队列支持在两端进行插入/放置、移除/拿取、检查等操作,而不同于LinkedBlockingQueue(链接阻塞队列)类必须强制在某端进行。这就使得链接阻塞双端队列相较于LinkedBlockingQueue(链接阻塞队列)类而言有着更高的灵活性,令其可被用于模拟堆栈或其它数据结构。涉及到两端操作的相关方法由BlockingDeqeue(阻塞双端队列)接口或Deqeue(双端队列)接口负责定义,该知识点的详细内容会在下文详述。
链接阻塞双端队列不允许保存null。不允许保存null实际上是BlockingQueue(阻塞队列)接口的定义,BlockingDeqeue(阻塞双端队列)接口作为其子接口也同样遵循该定义,并延续到了链接阻塞双端队列中。不允许保存null的具体原因是因为null被poll()及peek()等方法作为了表示队列中不存在元素的特殊值。
链接阻塞双端队列支持有界及无界两种使用方式,即是否人为限制可保存的元素总数。如果在创建链接阻塞双端队列时没有指定具体容量,则其便为无界队列。我们并不推荐使用无界队列,由于元素可无限制保存的原因,一旦元素的移除/拿取速率低于其插入/放置的速率,则很容易导致元素大量堆积造成内存溢出错误。因此在实际开发中,还是推荐指定容量的有界队列用法,并根据业务的实际场景及资源的硬性限制选择合适的容量大小。此外,链接阻塞双端队列在无界队列的实现上并不纯粹,采用的是通过Integer.MAX_VALUE大小的有界队列来模拟无界队列的方式,这在一定程度上违背了无界队列的实现规范,该知识点的详细内容会在下文详述。
链接阻塞双端队列是线程安全的。线程安全实际上是BlockingQueue(阻塞队列)接口的定义,BlockingDeqeue(阻塞双端队列)接口作为其子接口也同样遵循该定义,并延续到了链接阻塞双端队列中。与LinkedBlockingQueue(链接阻塞队列)类支持更高并发的“双锁”线程安全机制不同,链接阻塞双端队列采用常规的“单锁”线程安全机制,即使用一个ReentrantLock(可重入锁)类对象来保证整体的线程安全,这实际是引入两端操作所带来的负面影响。两端操作的引入打破了阻塞队列插入/放置与移除/拿取方法之间原本头尾隔离的元素布局,使得链接阻塞双端队列中的元素数据成为了一个整体,从而不再适用“双锁”线程安全机制。
链接阻塞双端队列实现了正/倒序两类迭代器,并且它们都是弱一致性的,即可能迭代到已移除的元素或迭代不到新插入的元素。正/倒序两类迭代器的存在很好的契合了两端操作的执行,而弱一致性则有效兼容了并发的使用环境,使得移除/拿取方法的执行不会导致迭代的异常中断,该知识点的详细内容会在下文详述。
链接阻塞双端队列虽然与BlockingQueue(阻塞队列)接口一样都被纳入Executor(执行器)框架的范畴,但同时也是Collection(集)框架的成员。
结构

与LinkedBlockingQueue(链接阻塞队列)类的对比
- 链接阻塞双端队列支持在两端执行插入/放置、移除/拿取、检查及内部移除等操作,而LinkedBlockingQueue(链接阻塞队列)类只支持在指定端执行;
- 链接阻塞双端队列使用“单锁”线程安全机制,而LinkedBlockingQueue(链接阻塞队列)类使用支持更高并发的“双锁”线程安全机制;
- 链接阻塞双端队列的底层链表使用了哨兵节点,而LinkedBlockingQueue(链接阻塞队列)类没有使用哨兵节点;
- 链接阻塞双端队列的实现了正/倒序两种迭代器,而LinkedBlockingQueue(链接阻塞队列)类只实现了正序迭代器;
- 链接阻塞双端队列的正/倒序迭代器进行迭代移除时无需遍历底层链表,因为节点保存前驱/后继引用;而LinkedBlockingQueue(链接阻塞队列)类的节点值保存了后继引用,因此迭代器进行迭代移除时需要先通过遍历找到迭代元素的前驱节点后才能执行移除。
方法的不同形式
方法的不同形式实际上是BlockingQueue(阻塞队列)接口的定义,链接阻塞双端队列只是继承了这个定义而已。所谓方法的不同形式,是指方法在保证自身核心操作不变的情况下实现了多种不同的回应形式来应对不同场景下的使用要求。例如对于插入,当容量不足时,有些场景希望在失败时抛出异常;而有些场景则希望能直接返回失败的标记值;而有些场景又希望可以等待直至有可用空间后成功新增为止…正因如此,BlockingQueue(阻塞队列)接口特意提供了四种不同的形式风格以满足不同场景下的使用需求,因此一个方法最多(并非所有方法都实现了四种形式)可能有四种不同回应形式。具体四种回应形式如下:
- 异常:当不满足操作条件时直接抛出异常;
- 特殊值:当不满足操作条件时直接返回失败标记值。例如之所以不允许存null值就是因为null被作为了获取操作失败时的标记值;
- 阻塞(无限等待):当不满足操作条件时无限等待,直至满足操作条件后执行;
- 超时(有限等待):当不满足操作条件时有限等待,如果在指定等待时间之前直至满足操作条件则执行;否则返回失败标记值。
二 创建
-
public LinkedBlockingDeque(int capacity) —— 创建一个指定容量的“有界”链接阻塞双端队列。该构造方法是现实中使用最多,也是最推荐使用的构造方法。优点在于其容量由开发者预先指定,最大程度的贴合了业务的实际场景及资源的硬性限制。
-
public LinkedBlockingDeque() —— 创建一个容量为Integer.MAX_VALUE的“无界”链接阻塞双端队列。现实开发中我们不推荐该构造方法,容易导致内存溢出错误(OOM)。
-
public LinkedBlockingDeque(Collection<? extends E> c) —— 创建一个容量为Integer.MAX_VALUE,并按迭代器顺序包含指定集中所有元素的“无界”链接阻塞双端队列。既然是无界队列,那自然也是不推荐使用的,但该方法在实现上也有值得一说的地方。具体源码及注释如下:
/**
* Creates a {@code LinkedBlockingDeque} with a capacity of {@link Integer#MAX_VALUE}, initially containing the elements of the given
* collection, added in traversal order of the collection's iterator.
* 创建一个容量为Integer#MAX_VALUE,初始包含指定集中所有元素链接阻塞双端队列,元素的新增按指定集迭代器顺序。
*
* @param c the collection of elements to initially contain 用于初始包含的元素的集
* @throws NullPointerException if the specified collection or any of its elements are null
* 空指针异常:如果指定集或其任意元素为null
* @Description: 名称:~
* @Description: 作用:创建一个容量为Integer.MAX_VALUE,并按迭代器顺序包含指定集中所有元素的链接阻塞双端队列,该链接阻塞
* @Description: 双端队列被视为无界队列。
* @Description: 逻辑:方法在按迭代器顺序将指定集中元素加入当前链接阻塞双端队列的过程中会加悲观锁。加锁的目的并不是为了避免
* @Description: 竞争,而是确保添加的元素对其它线程可见。
*/
public LinkedBlockingDeque(Collection<? extends E> c) {
this(Integer.MAX_VALUE);
// Never contended, but necessary for visibility
// 不竞争,但是为了「元素的」可见性是必要的
final ReentrantLock lock = this.lock;
lock.lock();
try {
for (E e : c) {
if (e == null)
throw new NullPointerException();
// 将指定集中的元素按迭代器顺序从双端队列的尾部依次加入。
if (!linkLast(new Node<E>(e)))
throw new IllegalStateException("Deque full");
}
} finally {
lock.unlock();
}
}
我们可以在上述的源码中发现将指定集中的元素存入链接阻塞双端队列的整个过程是加了锁的,而源码给出的英文注释是“没有竞争,但为了可见性有必要(加锁)”。其中本人对可见性是可以理解的(如果理解没有错的话):如果在过程中没有加锁,就会出现并发中其它线程获取到节点但获取不到元素的情况(即节点中不包含元素)。为什么会出现这样的问题呢?这是因为在Java中对象的创建不是原子操作,整个过程按顺序大致可分为以下三部分:
- 实例化(分配内存);
- 初始化(执行构造方法);
- 引用赋值(令变量持有对象的引用)。
但现实中由于指令重排序的原因,具体在执行中顺序就可能变成:
- 实例化(分配内存);
- 引用赋值(令变量持有对象的引用);
- 初始化(执行构造方法)。
这就意味着加入到链接阻塞双端队列中的节点可能是个空节点(即还未完成初始化的过程)。如此一来,如果有线程在链接阻塞双端队列构造方法执行结束后获取元素,则其获取到的节点中元素完全可能是空的,因此整个过程必须在锁的保护下执行。锁的存在虽然无法避免同步块中的指令重排序,但可以避免其重排序到同步块外,这就使得节点的初始化一定会在同步块中完成,确保队列创建完成后其它线程获取到的节点一定是完整的(存在元素的)。
如果上述我的理解都是对的,那就有一个讲不通的地方就是既然对象的创建不是原子操作,那么在不加锁的情况下,完全可能存在有线程向一个未执行初始化(或未执行完初始化)的链接阻塞双端队列保存元素的可能,如此应该是可能存在竞争的,而不是英文注释中说的“没有竞争”,这也是我目前尚未完全理解的地方…当然,也可能是我对可见性的理解本就是错的,希望有懂的同学能在评论区不吝赐教,本人万分感谢。
无界队列
上文已经提及过链接阻塞双端队列在无界队列的实现上并不纯粹,观察上述罗列的构造方法其实也可以看出链接阻塞双端队列的无界队列用法实质上是通过有界队列用法模拟实现的。通过创建一个指定容量为Integer.MAX_VALUE的有界队列,确实可以达到与无界队列基本一致的效果,从而简化了链接阻塞双端队列的实现,但由于该方案毕竟不是无界队列的标准实现,故而如此获得的“无界”队列与真正的无界队列还是存在部分差异的。
标准无界队列的容量只受限于堆内存的大小。当然,这是逻辑上的说法,在实现中其可能会受到具体的物理限制(例如int类型的空间制约),但这属于被动情况,并且当触发该类限制时也会模拟堆内存不足的场景手动抛出内存溢出错误来掩盖真实原因。除此之外,BlockingQueue(阻塞队列)接口还规定对于无界队列,当获取其剩余容量时需强制返回Integer.MAX_VALUE表示容量无限,诸如PriorityBlockingQueue(优先级阻塞队列)类、DelayQueue(延迟队列)类及LinkedTransferQueue(链接迁移队列)类等无界队列在实现上皆是如此。
链接阻塞双端队列的无界队列用法与标准无界队列的差异如下。也正是因为下列几点,虽然在说法上称链接阻塞双端队列支持有界及无界两种使用方式,但个人一直将之视为纯粹的有界队列。
- 人为的限制了容量,该容量虽然等同于int类型的最大值,但由“被动”转为“主动”使得自身性质发生了根本性改变,成为了实际的有界队列;
- 当元素总数达到Integer.MAX_VALUE时并不会抛出内存溢出错误,而是抛出非法状态异常,使得真实的异常原因暴露在外。而对于无界队列来说,不应该出现这种定义上因为容量不足而抛出的异常;
- 获取剩余容量时不会返回Integer.MAX_VALUE表示容量无限,而是返回真实的剩余容量。
三 方法
插入/放置
插入/放置是阻塞队列两大最核心也是最常用的方法之一,用于向阻塞队列的尾部插入指定元素。链接阻塞双端队列增强了该功能,新增了“向阻塞队列的头部插入指定元素”的方法实现,并对“向阻塞队列的尾部插入指定元素”的方法实现进行了封装(即为了保证命名规范实现了功能相同但名称不同的方法)。由于场景的多样性需求,链接阻塞双端队列提供了插入/放置方法四种形式的实现以供使用。
-
public void addFirst(E e) —— 新增首个 —— 向当前链接阻塞双端队列的头部插入指定元素。该方法是头部插入/放置方法“异常”形式的实现,当链接阻塞双端队列存在剩余容量时插入/放置成功,否则抛出非法状态异常。
-
public void addLast(E e) —— 新增最后 —— 向当前链接阻塞双端队列的尾部插入指定元素。该方法是尾部插入/放置方法“异常”形式的实现,当链接阻塞双端队列存在剩余容量时插入/放置成功;否则抛出非法状态异常。
-
public boolean add(E e) —— 新增 —— 向当前链接阻塞双端队列的尾部插入指定元素。该方法是插入/放置方法“异常”形式的实现,当链接阻塞双端队列存在剩余容量时插入/放置成功并返回true;否则抛出非法状态异常。该方法等价于addLast(E e)方法,但存在返回值,可由于方法执行失败时会抛出非法状态异常,因此该返回值实际上没有任何意义。
-
public boolean offerFirst(E e) —— 提供首个 —— 向当前链接阻塞双端队列的头部插入指定元素。该方法是头部插入/放置方法“特殊值”形式的实现,当链接阻塞双端队列存在剩余容量时插入/放置成功并返回true;否则返回false。
-
public boolean offerLast(E e) —— 提供最后 —— 向当前链接阻塞双端队列的尾部插入指定元素。该方法是尾部插入/放置方法“特殊值”形式的实现,当链接阻塞双端队列存在剩余容量时插入/放置成功并返回true;否则返回false。
-
public boolean offer(E e) —— 提供 —— 向当前链接阻塞双端队列的尾部插入指定元素。该方法是插入/放置方法“特殊值”形式的实现,当链接阻塞双端队列存在剩余容量时插入/放置成功并返回true;否则返回false。该方法等价于offerLast(E e)方法。
-
public void putFirst(E e) throws InterruptedException —— 放置首个 —— 向当前链接阻塞双端队列的头部插入指定元素。该方法是头部插入/放置方法“阻塞”形式的实现,当链接阻塞双端队列存在剩余容量时插入/放置成功;否则等待至存在剩余容量为止。
-
public void putLast(E e) throws InterruptedException —— 放置最后 —— 向当前链接阻塞双端队列的尾部插入指定元素。该方法是尾部插入/放置方法“阻塞”形式的实现,当链接阻塞双端队列存在剩余容量时插入/放置成功;否则等待至存在剩余容量为止。
-
public void put(E e) throws InterruptedException —— 放置 —— 向当前链接阻塞双端队列的尾部插入指定元素。该方法是插入/放置方法“阻塞”形式的实现,当链接阻塞双端队列存在剩余容量时插入/放置成功;否则等待至存在剩余容量为止。该方法等价于putLast(E e)方法。
-
public boolean offerFirst(E e, long timeout, TimeUnit unit) throws InterruptedException —— 提供首个 —— 向当前链接阻塞双端队列的头部插入指定元素。该方法是头部插入/放置方法“超时”形式的实现,当链接阻塞双端队列存在剩余容量时插入/放置成功并返回true;否则在指定等待时间内等待至存在剩余容量,超出等待时间则返回false。
-
public boolean offerLast(E e, long timeout, TimeUnit unit) throws InterruptedException —— 提供最后 —— 向当前链接阻塞双端队列的尾部插入指定元素。该方法是尾部插入/放置方法“超时”形式的实现,当链接阻塞双端队列存在剩余容量时插入/放置成功并返回true;否则在指定等待时间内等待至存在剩余容量,超出等待时间则返回false。
-
public boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException —— 提供 —— 向当前链接阻塞双端队列的尾部插入指定元素。该方法是插入/放置方法“超时”形式的实现,当链接阻塞双端队列存在剩余容量时插入/放置成功并返回true;否则在指定等待时间内等待至存在剩余容量,超出指定等待时间则返回false。该方法等价于offerLast(E e, long timeout, TimeUnit unit)方法。
移除/拿取
移除/拿取是阻塞队列两大最核心也是最常用的方法之一,用于从阻塞队列的头部移除并获取元素。链接阻塞双端队列增强了该功能,新增了“从阻塞队列的尾部移除并获取元素”的方法实现,并对“从阻塞队列的头部移除并获取元素”的方法实现进行了封装。移除/拿取方法同样有四种形式的实现。
-
public E removeFirst() —— 移除首个 —— 从当前链接阻塞双端队列的头部移除并获取元素。该方法是头部移除/拿取方法中“异常”形式的实现,当链接阻塞双端队列存在元素时移除/拿取并返回头元素;否则抛出无如此元素异常。
-
public E removeLast() —— 移除最后 —— 从当前链接阻塞双端队列的尾部移除并获取元素。该方法是尾部移除/拿取方法中“异常”形式的实现,当链接阻塞双端队列存在元素时移除/拿取并返回尾元素;否则抛出无如此元素异常。
-
public E remove() —— 移除 —— 从当前链接阻塞双端队列的头部移除并获取元素。该方法是移除/拿取方法中“异常”形式的实现,当链接阻塞双端队列存在元素时移除/拿取并返回头元素;否则抛出无如此元素异常。该方法等价于removeFirst()方法。
-
public E pollFirst() —— 轮询首个 —— 从当前链接阻塞双端队列的头部移除并获取元素。该方法是头部移除/拿取方法中“特殊值”形式的实现,当链接阻塞双端队列存在元素时移除/拿取并返回头元素;否则返回null。
-
public E pollLast() —— 轮询最后 —— 从当前链接阻塞双端队列的尾部移除并获取元素。该方法是尾部移除/拿取方法中“特殊值”形式的实现,当链接阻塞双端队列存在元素时移除/拿取并返回尾元素;否则返回null。
-
public E poll() —— 轮询 —— 从当前链接阻塞双端队列的头部移除并获取元素。该方法是移除/拿取方法中“特殊值”形式的实现,当链接阻塞双端队列存在元素时移除/拿取并返回头元素;否则返回null。该方法等价于pollFirst()方法。
-
public E takeFirst() throws InterruptedException —— 拿取首个 —— 从当前链接阻塞双端队列的头部移除并获取元素。该方法是头部移除/拿取方法中“阻塞”形式的实现,当链接阻塞双端队列存在元素时移除/拿取并返回头元素;否则等待至存在元素。
-
public E takeLast() throws InterruptedException —— 拿取最后 —— 从当前链接阻塞双端队列的尾部移除并获取元素。该方法是尾部移除/拿取方法中“阻塞”形式的实现,当链接阻塞双端队列存在元素时移除/拿取并返回尾元素;否则等待至存在元素。
-
public E take() throws InterruptedException —— 拿取 —— 从当前链接阻塞双端队列的头部移除并获取元素。该方法是移除/拿取方法中“阻塞”形式的实现,当链接阻塞双端队列存在元素时移除/拿取并返回头元素;否则等待至存在元素。该方法等价于takeFirst()方法。
-
public E pollFirst(long timeout, TimeUnit unit) throws InterruptedException —— 轮询首个 —— 从当前链接阻塞双端队列的头部移除并获取元素。该方法是头部移除/拿取方法中“超时”形式的实现,当链接阻塞双端队列存在元素时移除/拿取并返回头元素;否则在指定等待时间内等待至存在元素,超出指定等待时间则返回null。
-
public E pollLast(long timeout, TimeUnit unit) throws InterruptedException —— 轮询最后 —— 从当前链接阻塞双端队列的尾部移除并获取元素。该方法是尾部移除/拿取方法中“超时”形式的实现,当链接阻塞双端队列存在元素时移除/拿取并返回尾元素;否则在指定等待时间内等待至存在元素,超出指定等待时间则返回null。
-
public E poll(long timeout, TimeUnit unit) throws InterruptedException —— 轮询 —— 从当前链接阻塞双端队列的头部移除并获取元素。该方法是移除/拿取方法中“超时”形式的实现,当链接阻塞双端队列存在元素时移除/拿取并返回头元素;否则在指定等待时间内等待至存在元素,超出指定等待时间则返回null。该方法等价于pollFirst(long timeout, TimeUnit unit)方法。
检查
检查也是阻塞队列的常用方法之一,用于从阻塞队列的头部获取元素,但并不会将元素从阻塞队列中移除,属于移除/拿取方法的阉割版。链接阻塞双端队列增强了该功能,新增了“从阻塞队列的尾部获取元素”的方法实现,并对“从阻塞队列的头部获取元素”的方法实现进行了封装。检查方法同样具备多形式的实现,但只有“异常”与“特殊值”两种。
-
public E getFirst() —— 获取首个 —— 从当前链接阻塞双端队列的头部获取元素。该方法是头部检查方法中“异常”形式的实现,当链接阻塞双端队列存在元素时返回头元素;否则抛出无如此元素异常。
-
public E getLast() —— 获取首个 —— 从当前链接阻塞双端队列的尾部获取元素。该方法是尾部检查方法中“异常”形式的实现,当链接阻塞双端队列存在元素时返回尾元素;否则抛出无如此元素异常。
-
public E element() —— 元素 —— 从当前链接阻塞双端队列的头部获取元素。该方法是头部检查方法中“异常”形式的实现,当链接阻塞双端队列存在元素时返回头元素;否则抛出无如此元素异常。该方法等价于getFirst()方法。
-
public E peekFirst() —— 窥视首个 —— 从当前链接阻塞双端队列的头部获取元素。该方法是头部检查方法中“特殊值”形式的实现,当链接阻塞双端队列存在元素时返回头元素;否则返回null。
-
public E peekLast() —— 窥视最后 —— 从当前链接阻塞双端队列的尾部获取元素。该方法是尾部检查方法中“特殊值”形式的实现,当链接阻塞双端队列存在元素时返回尾元素;否则返回null。
-
public E peek() —— 窥视 —— 从当前链接阻塞双端队列的头部获取元素。该方法是头部检查方法中“特殊值”形式的实现,当链接阻塞双端队列存在元素时返回头元素;否则返回null。该方法等价于peekFirst()方法。
迁移
迁移也是阻塞队列的常用方法之一,用于将阻塞队列中的元素迁移至指定集中,迁移后的元素不再存在于阻塞队列中。为了避免迁移过程中元素丢失问题,实现往往会先将元素加入指定集中后再将元素从阻塞队列中移除。
- public int drainTo(Collection<? super E> c) —— 流失 —— 将当前链接阻塞双端队列中的所有元素迁移至指定集中,并返回迁移的元素总数。
- public int drainTo(Collection<? super E> c, int maxElements) —— 流失 —— 将当前链接阻塞双端队列中的最多指定数量的元素迁移至指定集中,并返回迁移的元素总数。
内部移除
内部移除的原始方法定义源自Collection(集)接口的remove(Object o)方法,用于将集中指定元素的首个单例(迭代器顺序)移除。由于指定元素可能处于集中的任意位置(不一定是头/尾),因此被称为内部移除。内部移除在队列中并不是常用的方法:一是其不符合队列FIFO的数据结构;二是各类队列为了提高性能可能会使用各种优化策略,而remove(Object o)方法往往无法适配这些策略,导致性能较/极差。链接阻塞双端队列增强了内部移除功能,在“从阻塞队列中移除指定元素的首个单例”的方法链接阻塞双端队列基础上新增了“从阻塞队列中移除指定元素的最后单例”的方法实现,并对“从阻塞队列中移除指定元素的首个单例”的方法实现进行了封装。
- public boolean removeFirstOccurrence(Object o) —— 移除首次出现 —— 从当前链接阻塞双端队列中移除指定元素的首个单例,移除成功返回true;否则返回false。
- public boolean removeLastOccurrence(Object o) —— 移除最后出现 —— 从当前链接阻塞双端队列中移除指定元素的最后单例,移除成功返回true;否则返回false。
- public boolean remove(Object o) —— 移除 —— 从当前链接阻塞双端队列中移除指定元素的首个单例,移除成功返回true;否则返回false。该方法等价于removeFirstOccurrence()方法。
堆栈
堆栈功能是Deque(双端队列)接口为了模拟堆栈适配Stack(堆栈)类而新增的方法定义,而链接阻塞双端队列继承并实现了这些定义。
-
public void push(E e) —— 推送 —— 向当前链接阻塞双端队列的头部插入指定元素。如果存在剩余空间则插入成功,否则抛出非法状态异常。该方法等价于addFirst(E e)方法。
-
public E pop() —— 弹出 —— 从当前链接双端队列的头部移除并获取元素。如果存在元素则返回头元素,否则抛出无如此元素异常。该方法等价于removeFirst()方法。
迭代器
常规队列通常只实现了正序(从头到尾)迭代器,而链接阻塞双端队列增强了该功能,新增了倒序(从尾到头)迭代器的实现。
- public Iterator iterator() —— 迭代器 —— 获取一个当前链接阻塞双端队列的正序(从头到尾)迭代器。
- public Iterator descendingIterator() —— 下降迭代器 —— 获取一个当前链接阻塞双端队列的倒序(从尾到头)迭代器。
其它
除了上述提及的主要方法之外,链接阻塞双端队列还有一些常用方法如下所示:
- public int size() —— 大小 —— 获取当前链接阻塞双端队列中的元素总数。
- public int remainingCapacity() —— 剩余容量 —— 获取当前链接阻塞双端队列的剩余容量。
- public Object[] toArray() —— 转化数组 —— 获取一个按迭代器顺序包含当前链接阻塞双端队列中所有元素的数组。
- public T[] toArray(T[] a) —— 转化数组 —— 获取一个按迭代器顺序包含当前链接阻塞双端队列中所有元素的泛型数组。如果参数泛型数组长度足以容纳所有元素,则令之承载所有元素后返回。并且如果参数泛型数组的长度大于当前链接阻塞双端队列的元素总数,则将已承载所有元素的参数泛型数组的size索引位置设置为null,表示从当前链接阻塞双端队列中承载的元素到此为止。当然,该方案只对不允许保存null元素的集有效。如果参数泛型数组的长度不足以承载所有元素,则重分配一个相同泛型且长度与当前链接阻塞双端队列元素总数相同的新泛型数组以承接所有元素后返回。
- public void clear() —— 清理 —— 移除当前链接阻塞双端队列中的所有元素。
事实上,由于链接阻塞双端队列是Collection(集)接口的实现类,因为其也实现了其定义的所有方法,例如contains(Object o)、remove(Object o)及 toArray()等。但由于这些方法的执行效率不高,并且与链接阻塞双端队列的主流使用方式并不兼容,因此一般情况下是不推荐使用的,有兴趣的可以去查看源码实现。
四 正/倒序弱一致性迭代器
链接阻塞双端队列实现了正/倒序两类迭代器,并且它们都是弱一致性的,即可能迭代到已移除的元素或迭代不到新插入的元素。正/倒序两类迭代器的存在很好的契合了两端操作的执行,而弱一致性则有效兼容了并发的使用环境,使得移除/拿取方法的执行不会导致迭代的异常中断。与LinkedBlockingQueue(链接阻塞队列)类的迭代器相比,链接阻塞双端队列的迭代器最大在于其执行迭代移除时不需要进行遍历,这是节点同事保存了前驱/后继引用所带来的附加效果。而LinkedBlockingQueue(链接阻塞队列)类的节点由于只保存了后继引用,因此迭代移除时必须先遍历找到前驱节点后才能执行移除。
事实上,除了元素的迭代顺序有所差异外,正/倒序迭代器本质上完全相同,因此链接阻塞双端队列采用了模板模式来简化正/倒序迭代器的实现。链接阻塞双端队列内部设计了一个迭代器父/超类,该迭代器父/超类提供了hasNext()、next()及remove()方法的完整实现,但却将元素迭代顺序的选择权交给了子类。子类只需提供“获取指定顺序下的头元素”及“获取指定顺序下指定元素的下个元素”的方法实现就能够快速实现迭代器,就如同正/倒序迭代器正是通过重写“获取正/倒序下的头元素”及“获取正/倒序下的指定元素的下个元素”两个方法实现的。
对于迭代器的弱一致性,链接阻塞双端队列是通过以下两步操作实现的:
-
迭代器保存了下次迭代节点/元素的快照:由于迭代器保存了下次迭代的节点/元素的快照,因此即使下次迭代时节点/元素实际已从链接阻塞双端队列中移除,迭代器也依然可以返回迭代元素。与之相应的是如果迭代器已判断下次迭代的节点/元素为null,则即使插入了新元素也无法被迭代,因为迭代器已经判定迭代完整结束。如此一来就实现了弱一致性“可能迭代到已移除的元素或迭代不到新插入的元素”的特点。
-
节点被移除(移除/拿取、内部移除)后不会断开前驱/后继引用:由于节点不会断开前驱/后继引用,因此即使节点已经被判定为下次迭代的节点且被移除(移除/拿取、内部移除),迭代器依然可以继续通过其持有引用访问到其在链接阻塞双端队列中的首个前驱/后继节点(对应倒序/正序迭代),从而避免迭代过程的异常中断。由于在迭代器两次迭代之间可能有多个节点被连续的移除(多发生于移除/拿取中,内部移除的可能性较小),因此如果发现前驱/后继节点同样已从链接阻塞双端队列中移除(通过查看节点中的元素是否为null判断),则需要连续的向前/后遍历,直至找到首个存在于链接阻塞双端队列的前驱/后继节点作为下次迭代的节点/元素为止。
虽说通过上述两步操作成功实现了迭代器的弱一致性,但与此同时两者也各自带来了一个问题…并且只能解决其中的部分:
- 移除节点/元素可能在迭代器中长期保留;
- 可能导致的频繁老年代GC。
移除节点/元素可能在迭代器中长期保留
由于迭代器会提前保存迭代的节点/元素,因此即使该节点/元素已从链接阻塞双端队列中被移除,也可能无法被GC回收,因为迭代器还持有其引用。该问题的关键在于这种保留在时间上是难以预测的,即可能是短期、长期、甚至是永久保存。这完全取决于迭代器的迭代频率,而频率又与具体的业务相关。频率高就是短期,低就是长期,不调用就是永久。事实上,该问题也是所有弱一致性迭代器的共性,是难以被解决的。但所幸的是发生该问题的概率不高,并且也只会导致少许对象被延迟回收或浪费少量存储空间,因此并不会产生较大的负面影响。
可能导致的频繁老年代GC
由于被移除(移除/拿取、内部移除)的节点不会断开前驱/后继引用,那就可能造成这样一种情况:由于移除(移除/拿取、内部移除)操作的不断执行,使得在链接阻塞双端队列外也形成一条条空节点链(下文简称外链),并最终与队内节点相连接。大致示例如下:

上图看起来并无不妥,无外乎残留了部分无效节点节点,只需等待GC慢慢回收即可。事实上也确实如此,Java的GC太过智能,以至于我们往往/从来不会考虑垃圾回收的具体过程。实际上虽然无需亲自执行回收,但开发者仍有义务保证GC准确高效的执行。在上述所示情况中存在这样一种场景:外链中存在部分空节点存活于老年代,并与前驱/后继存活于新生代的节点相连,造成跨带引用的现象。示例如下:

跨带引用是非常难以处理的。在跨带引用中,为了回收被引用的新生代对象,必须先强制执行老年代对象的回收。老年代的Major GC本身就是不频繁的(因为老年代的对象存活周期一般都比较长),并且执行速度也远比新生代的Minor GC慢得多(有资料说至少有10倍以上的差距),因此在实际开发中要时刻注意避免。在当前场景中,为了回收外链中处于新生代的空节点,必须先触发老年代的Minor GC。这本质上不算太过严重的问题,一次跨带引用并不会对程序带来多少影响…但问题的关键在于程序在不断的运行,每时每刻都有新的元素被插入/放置,同样也不断会有元素被移除(移除/拿取、内部移除)。这就意味着外链会一次又一次的形成,从而频繁的导致跨带引用。
为了解决这一点(即在保证迭代器弱一致性的基础上避免跨带引用),链接阻塞双端队列采用的方案是将移除/拿取的节点的前驱/后继引用设置为自引用,之所以不设置null是因为null是头/尾节点的标志。节点自引用有两大作用:一是移除/拿取的节点不再具有其它节点的前驱/后继引用,那自然也就不会再出现跨带引用的问题;二是其可以作为迭代器的标记位使用。当迭代器迭代是发现节点是自引用时,就说明该节点已经因为移除/拿取出队了,这就意味着其首个存在于链接阻塞双端队列的前驱/后继节点必然是头/尾节点,因此会直接跳跃至链接阻塞双端队列的头/尾部继续进行迭代。
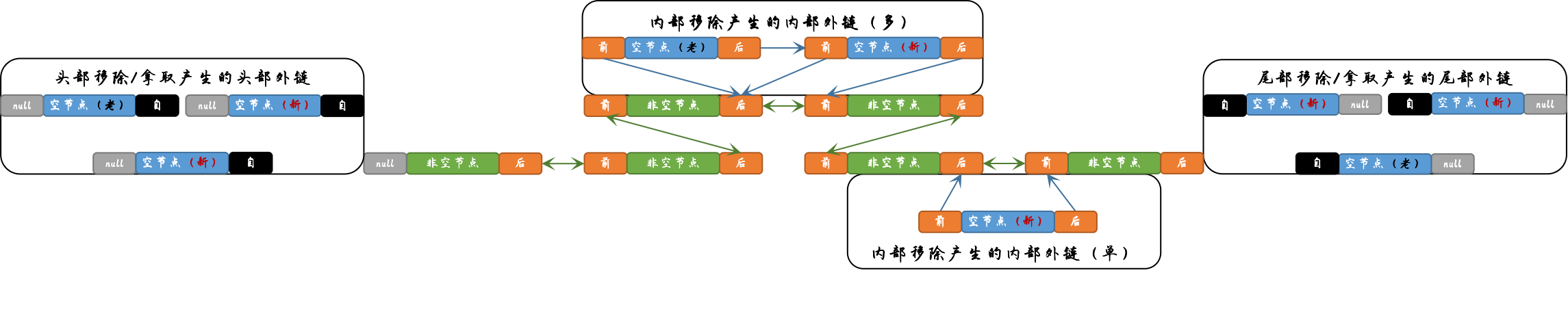
上述操作虽然精妙,但遗憾的是该操作并不能对内部移除的节点使用,即该类节点依然要保持原本的前驱/后继引用。这是因为该类移除可能在队列的任意位置发生,其首个存在于链接阻塞双端队列的前驱/后继节点并不一定位于头/尾部,故而不可采用该方案,这也意味着内部移除存在着引发跨带引用的隐患…但由于内部移除本身在开发中就较少且不推荐使用…并且想要连续的移除还是有一定难度的…因此总体来说并不会有太大影响。
五 相关系列
- 《Java ~ Collection【目录】》