本文已收录到 AndroidFamily,技术和职场问题,请关注公众号 [彭旭锐] 提问。
前言
大家好,我是小彭。
SharedPreferences 是 Android 平台上轻量级的 K-V 存储框架,亦是初代 K-V 存储框架,至今被很多应用沿用。
有的小伙伴会说,SharedPreferences 是旧时代的产物,现在已经有 DataStore 或 MMKV 等新时代的 K-V 框架,没有学习意义。但我认为,虽然 SharedPreference 这个方案已经过时,但是并不意味着 SharedPreference 中使用的技术过时。做技术要知其然,更要知其所以然,而不是人云亦云,如果要你解释为什么 SharedPreferences 会过时,你能说到什么程度?
不知道你最近有没有读到一本在技术圈非常火爆的一本新书 《安卓传奇 · Android 缔造团队回忆录》,其中就讲了很多 Android 架构演进中设计者的思考。如果你平时也有从设计者的角度思考过 “为什么”,那么很多内容会觉得想到一块去了,反之就会觉得无感。
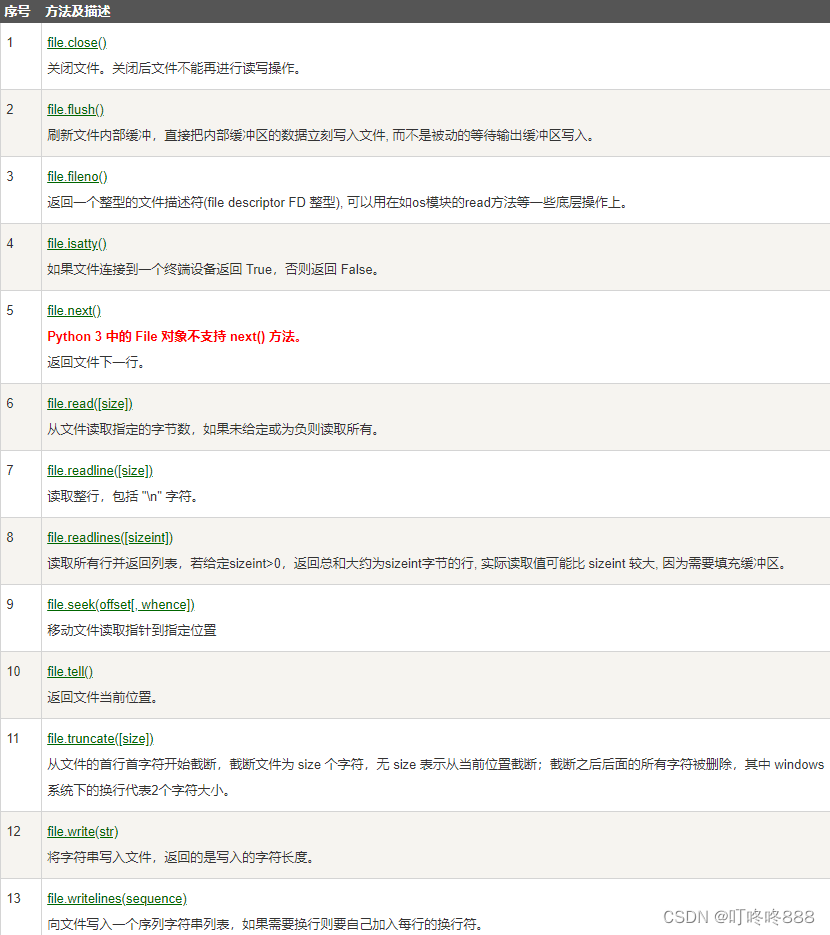
小彭的 Android 交流群 02 群已经建立啦,公众号回复 “加群” 加入我们~

—— 图片引用自电商平台
今天,我们就来分析 SharedPreference 源码,在过程中依然可以学习到非常丰富的设计技巧。在后续的文章中,我们会继续分析其他 K-V 存储框架,请关注。
本文源码分析基于 Android 10(API 31),并关联分析部分 Android 7.1(API 25)。
思维导图:

1. 实现 K-V 框架应该思考什么问题?
在阅读 SharedPreference 的源码之前,我们先思考一个 K-V 框架应该考虑哪些问题?
-
问题 1 - 线程安全: 由于程序一般会在多线程环境中执行,因此框架有必要保证多线程并发安全,并且优化并发效率;
-
问题 2 - 内存缓存: 由于磁盘 IO 操作是耗时操作,因此框架有必要在业务层和磁盘文件之间增加一层内存缓存;
-
问题 3 - 事务: 由于磁盘 IO 操作是耗时操作,因此框架有必要将支持多次磁盘 IO 操作聚合为一次磁盘写回事务,减少访问磁盘次数;
-
问题 4 - 事务串行化: 由于程序可能由多个线程发起写回事务,因此框架有必要保证事务之间的事务串行化,避免先执行的事务覆盖后执行的事务;
-
问题 5 - 异步写回: 由于磁盘 IO 是耗时操作,因此框架有必要支持后台线程异步写回;
-
问题 6 - 增量更新: 由于磁盘文件内容可能很大,因此修改 K-V 时有必要支持局部修改,而不是全量覆盖修改;
-
问题 7 - 变更回调: 由于业务层可能有监听 K-V 变更的需求,因此框架有必要支持变更回调监听,并且防止出现内存泄漏;
-
问题 8 - 多进程: 由于程序可能有多进程需求,那么框架如何保证多进程数据同步?
-
问题 9 - 可用性: 由于程序运行中存在不可控的异常和 Crash,因此框架有必要尽可能保证系统可用性,尽量保证系统在遇到异常后的数据完整性;
-
问题 10 - 高效性: 性能永远是要考虑的问题,解析、读取、写入和序列化的性能如何提高和权衡;
-
问题 11 - 安全性: 如果程序需要存储敏感数据,如何保证数据完整性和保密性;
-
问题 12 - 数据迁移: 如果项目中存在旧框架,如何将数据从旧框架迁移至新框架,并且保证可靠性;
-
问题 13 - 研发体验: 是否模板代码冗长,是否容易出错。
提出这么多问题后:
你觉得学习 SharedPreferences 有没有价值呢?
如果让你自己写一个 K-V 框架,你会如何解决这些问题呢?
新时代的 MMKV 和 DataStore 框架是否良好处理了这些问题?
2. 从 Sample 开始
SharedPreferences 采用 XML 文件格式持久化键值对数据,文件的存储位置位于应用沙盒的内部存储 /data/data/<packageName>/shared_prefs/ 位置,每个 XML 文件对应于一个 SharedPreferences 对象。
在 Activity、Context 和 PreferenceManager 中都存在获取 SharedPreferences 对象的 API,它们最终都会走到 ContextImpl 中:
ContextImpl.java
class ContextImpl extends Context {
// 获取 SharedPreferences 对象
@Override
public SharedPreferences getSharedPreferences(String name, int mode) {
// 后文详细分析...
}
}
示例代码
SharedPreferences sp = getSharedPreferences("prefs", Context.MODE_PRIVATE);
// 创建事务
Editor editor = sp.edit();
editor.putString("name", "XIAO PENG");
// 同步提交事务
boolean result = editor.commit();
// 异步提交事务
// editor.apply()
// 读取数据
String blog = sp.getString("name", "PENG");
prefs.xml 文件内容
<?xml version='1.0' encoding='utf-8' standalone='yes' ?>
<map>
<string name="name">XIAO PENG</string>
</map>
3. SharedPreferences 的内存缓存
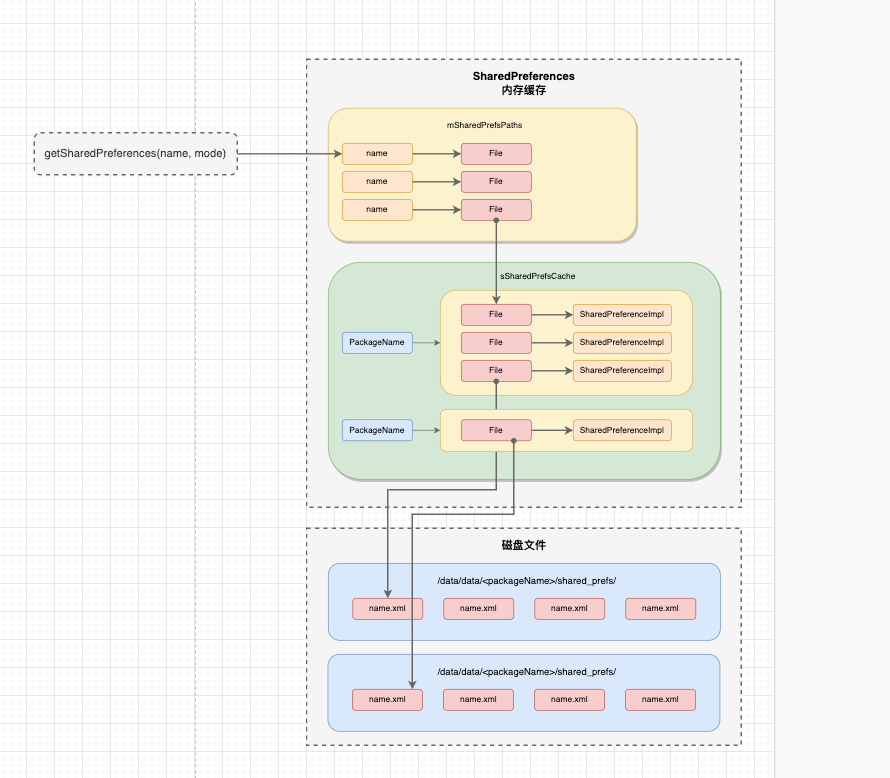
由于磁盘 IO 操作是耗时操作,如果每一次访问 SharedPreferences 都执行一次 IO 操作就显得没有必要,所以 SharedPreferences 会在业务层和磁盘之间增加一层内存缓存。在 ContextImpl 类中,不仅支持获取 SharedPreferencesImpl 对象,还负责支持 SharedPreferencesImpl 对象的内存缓存。
ContextImpl 中的内存缓存逻辑是相对简单的:
- 步骤1:通过文件名 name 映射文件对应的 File 对象;
- 步骤 2:通过 File 对象映射文件对应的 SharedPreferencesImpl 对象。
两个映射表:
- mSharedPrefsPaths: 缓存 “文件名 to 文件对象” 的映射;
- sSharedPrefsCache: 这是一个二级映射表,第一级是包名到 Map 的映射,第二级是缓存 “文件对象 to SP 对象” 的映射。每个 XML 文件在内存中只会关联一个全局唯一的 SharedPreferencesImpl 对象
继续分析发现: 虽然 ContextImpl 实现了 SharedPreferencesImpl 对象的缓存复用,但没有实现缓存淘汰,也没有提供主动移除缓存的 API。因此,在 APP 运行过程中,随着访问的业务范围越来越多,这部分 SharedPreferences 内存缓存的空间也会逐渐膨胀。这是一个需要注意的问题。
在 getSharedPreferences() 中还有 MODE_MULTI_PROCESS 标记位的处理:
如果是首次获取 SharedPreferencesImpl 对象会直接读取磁盘文件,如果是二次获取 SharedPreferences 对象会复用内存缓存。但如果使用了 MODE_MULTI_PROCESS 多进程模式,则在返回前会检查磁盘文件相对于最后一次内存修改是否变化,如果变化则说明被其他进程修改,需要重新读取磁盘文件,以实现多进程下的 “数据同步”。
但是这种同步是非常弱的,因为每个进程本身对磁盘文件的写回是非实时的,再加上如果业务层缓存了 getSharedPreferences(…) 返回的对象,更感知不到最新的变化。所以严格来说,SharedPreferences 是不支持多进程的,官方也明确表示不要将 SharedPreferences 用于多进程环境。
SharedPreferences 内存缓存示意图
流程图
ContextImpl.java
class ContextImpl extends Context {
// SharedPreferences 文件根目录
private File mPreferencesDir;
// <文件名 - 文件>
@GuardedBy("ContextImpl.class")
private ArrayMap<String, File> mSharedPrefsPaths;
// 获取 SharedPreferences 对象
@Override
public SharedPreferences getSharedPreferences(String name, int mode) {
// 1、文件名转文件对象
File file;
synchronized (ContextImpl.class) {
// 1.1 查询映射表
if (mSharedPrefsPaths == null) {
mSharedPrefsPaths = new ArrayMap<>();
}
file = mSharedPrefsPaths.get(name);
// 1.2 缓存未命中,创建 File 对象
if (file == null) {
file = getSharedPreferencesPath(name);
mSharedPrefsPaths.put(name, file);
}
}
// 2、获取 SharedPreferences 对象
return getSharedPreferences(file, mode);
}
// -> 1.2 缓存未命中,创建 File 对象
@Override
public File getSharedPreferencesPath(String name) {
return makeFilename(getPreferencesDir(), name + ".xml");
}
private File getPreferencesDir() {
synchronized (mSync) {
// 文件目录:data/data/[package_name]/shared_prefs/
if (mPreferencesDir == null) {
mPreferencesDir = new File(getDataDir(), "shared_prefs");
}
return ensurePrivateDirExists(mPreferencesDir);
}
}
}
文件对象 to SP 对象:
ContextImpl.java
class ContextImpl extends Context {
// <包名 - Map>
// <文件 - SharedPreferencesImpl>
@GuardedBy("ContextImpl.class")
private static ArrayMap<String, ArrayMap<File, SharedPreferencesImpl>> sSharedPrefsCache;
// -> 2、获取 SharedPreferences 对象
@Override
public SharedPreferences getSharedPreferences(File file, int mode) {
SharedPreferencesImpl sp;
synchronized (ContextImpl.class) {
// 2.1 查询缓存
final ArrayMap<File, SharedPreferencesImpl> cache = getSharedPreferencesCacheLocked();
sp = cache.get(file);
// 2.2 未命中缓存(首次获取)
if (sp == null) {
// 2.2.1 检查 mode 标记
checkMode(mode);
// 2.2.2 创建 SharedPreferencesImpl 对象
sp = new SharedPreferencesImpl(file, mode);
// 2.2.3 缓存
cache.put(file, sp);
return sp;
}
}
// 3、命中缓存(二次获取)
if ((mode & Context.MODE_MULTI_PROCESS) != 0 ||
getApplicationInfo().targetSdkVersion < android.os.Build.VERSION_CODES.HONEYCOMB) {
// 判断当前磁盘文件相对于最后一次内存修改是否变化,如果时则重新加载文件
sp.startReloadIfChangedUnexpectedly();
}
return sp;
}
// 根据包名获取 <文件 - SharedPreferencesImpl> 映射表
@GuardedBy("ContextImpl.class")
private ArrayMap<File, SharedPreferencesImpl> getSharedPreferencesCacheLocked() {
if (sSharedPrefsCache == null) {
sSharedPrefsCache = new ArrayMap<>();
}
final String packageName = getPackageName();
ArrayMap<File, SharedPreferencesImpl> packagePrefs = sSharedPrefsCache.get(packageName);
if (packagePrefs == null) {
packagePrefs = new ArrayMap<>();
sSharedPrefsCache.put(packageName, packagePrefs);
}
return packagePrefs;
}
...
}
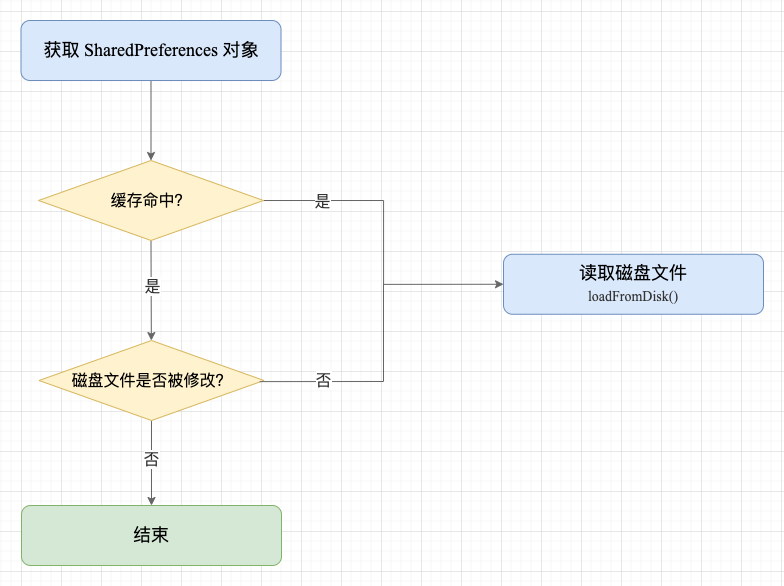
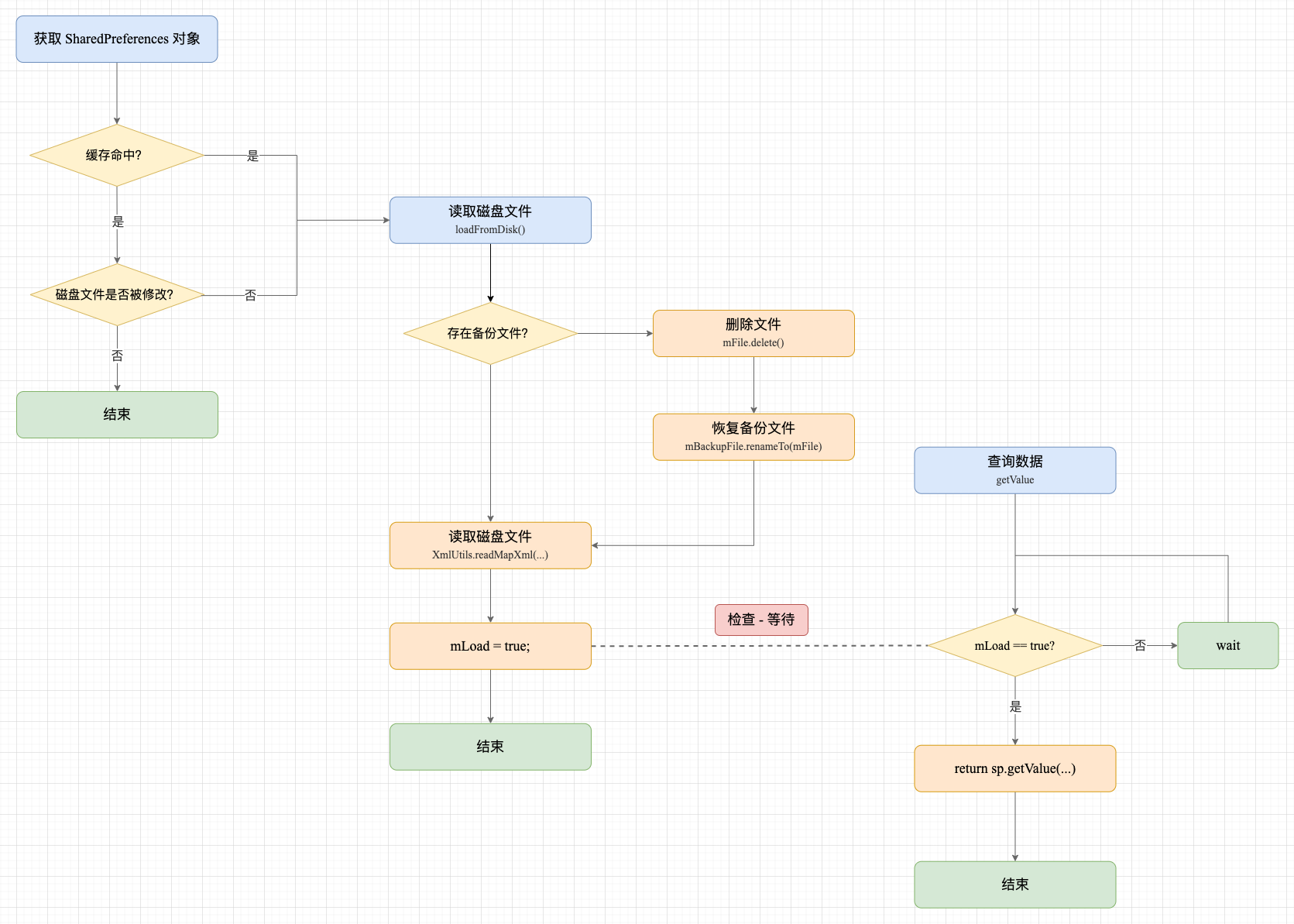
4. 读取和解析磁盘文件
在创建 SharedPreferencesImpl 对象时,构造函数会启动一个子线程去读取本地磁盘文件,一次性将文件中所有的 XML 数据转化为 Map 散列表。
需要注意的是: 如果在执行 loadFromDisk() 解析文件数据的过程中,其他线程调用 getValue 查询数据,那么就必须等待 mLock 锁直到解析结束。
如果单个 SharedPreferences 的 .xml 文件很大的话,就有可能导致查询数据的线程被长时间被阻塞,甚至导致主线程查询时产生 ANR。这也辅证了 SharedPreferences 只适合保存少量数据,文件过大在解析时会有性能问题。
读取示意图
SharedPreferencesImpl.java
// 目标文件
private final File mFile;
// 备份文件(后文详细分析)
private final File mBackupFile;
// 模式
private final int mMode;
// 锁
private final Object mLock = new Object();
// 读取文件标记位
@GuardedBy("mLock")
private boolean mLoaded = false;
SharedPreferencesImpl(File file, int mode) {
mFile = file;
mBackupFile = makeBackupFile(file);
mMode = mode;
mLoaded = false;
mMap = null;
mThrowable = null;
// 读取并解析文件数据
startLoadFromDisk();
}
private void startLoadFromDisk() {
synchronized (mLock) {
mLoaded = false;
}
// 子线程
new Thread("SharedPreferencesImpl-load") {
public void run() {
loadFromDisk();
}
}.start();
}
// -> 读取并解析文件数据(子线程)
private void loadFromDisk() {
synchronized (mLock) {
if (mLoaded) {
return;
}
// 1、如果存在备份文件,则恢复备份数据(后文详细分析)
if (mBackupFile.exists()) {
mFile.delete();
mBackupFile.renameTo(mFile);
}
}
Map<String, Object> map = null;
if (mFile.canRead()) {
// 2、读取文件
BufferedInputStream str = new BufferedInputStream(new FileInputStream(mFile), 16 * 1024);
// 3、将 XML 数据解析为 Map 映射表
map = (Map<String, Object>) XmlUtils.readMapXml(str);
IoUtils.closeQuietly(str);
}
synchronized (mLock) {
mLoaded = true;
if (map != null) {
// 使用解析的映射表
mMap = map;
} else {
// 创建空的映射表
mMap = new HashMap<>();
}
// 4、唤醒等待 mLock 锁的线程
mLock.notifyAll();
}
}
static File makeBackupFile(File prefsFile) {
return new File(prefsFile.getPath() + ".bak");
}
查询数据可能会阻塞等待:
SharedPreferencesImpl.java
public String getString(String key, @Nullable String defValue) {
synchronized (mLock) {
// 等待 mLoaded 标记位
awaitLoadedLocked();
// 查询数据
String v = (String)mMap.get(key);
return v != null ? v : defValue;
}
}
private void awaitLoadedLocked() {
// “检查 - 等待” 模式
while (!mLoaded) {
try {
mLock.wait();
} catch (InterruptedException unused) {
}
}
}
5. SharedPreferences 的事务机制
是的,SharedPreferences 也有事务操作。
虽然 ContextImpl 中使用了内存缓存,但是最终数据还是需要执行磁盘 IO 持久化到磁盘文件中。如果每一次 “变更操作” 都对应一次磁盘 “写回操作” 的话,不仅效率低下,而且没有必要。
所以 SharedPreferences 会使用 “事务” 机制,将多次变更操作聚合为一个 “事务”,一次事务最多只会执行一次磁盘写回操作。虽然 SharedPreferences 源码中并没有直接体现出 “Transaction” 之类的命名,但是这就是一种 “事务” 设计,与命名无关。
5.1 MemoryCommitResult 事务对象
SharedPreferences 的事务操作由 Editor 接口实现。
SharedPreferences 对象本身只保留获取数据的 API,而变更数据的 API 全部集成在 Editor 接口中。Editor 中会将所有的 putValue 变更操作记录在 mModified 映射表中,但不会触发任何磁盘写回操作,直到调用 Editor#commit 或 Editor#apply 方法时,才会一次性以事务的方式发起磁盘写回任务。
比较特殊的是:
- 在 remove 方法中:会将
this指针作为特殊的移除标记位,后续将通过这个 Value 来判断是移除键值对还是修改 / 新增键值对; - 在 clear 方法中:只是将
mClear标记位置位。
可以看到: 在 Editor#commit 和 Editor#apply 方法中,首先都会调用 Editor#commitToMemery() 收集需要写回磁盘的数据,并封装为一个 MemoryCommitResult 事务对象,随后就是根据这个事务对象的信息写回磁盘。
SharedPreferencesImpl.java
final class SharedPreferencesImpl implements SharedPreferences {
// 创建修改器对象
@Override
public Editor edit() {
// 等待磁盘文件加载完成
synchronized (mLock) {
awaitLoadedLocked();
}
// 创建修改器对象
return new EditorImpl();
}
// 修改器
// 非静态内部类(会持有外部类 SharedPreferencesImpl 的引用)
public final class EditorImpl implements Editor {
// 锁对象
private final Object mEditorLock = new Object();
// 修改记录(将以事务方式写回磁盘)
@GuardedBy("mEditorLock")
private final Map<String, Object> mModified = new HashMap<>();
// 清除全部数据的标记位
@GuardedBy("mEditorLock")
private boolean mClear = false;
// 修改 String 类型键值对
@Override
public Editor putString(String key, @Nullable String value) {
synchronized (mEditorLock) {
mModified.put(key, value);
return this;
}
}
// 修改 int 类型键值对
@Override
public Editor putInt(String key, int value) {
synchronized (mEditorLock) {
mModified.put(key, value);
return this;
}
}
// 移除键值对
@Override
public Editor remove(String key) {
synchronized (mEditorLock) {
// 将 this 指针作为特殊的移除标记位
mModified.put(key, this);
return this;
}
}
// 清空键值对
@Override
public Editor clear() {
synchronized (mEditorLock) {
// 清除全部数据的标记位
mClear = true;
return this;
}
}
...
@Override
public void apply() {
// commitToMemory():写回磁盘的数据并封装事务对象
MemoryCommitResult mcr = commitToMemory();
// 同步写回,下文详细分析
}
@Override
public boolean commit() {
// commitToMemory():写回磁盘的数据并封装事务对象
final MemoryCommitResult mcr = commitToMemory();
// 异步写回,下文详细分析
}
}
}
MemoryCommitResult 事务对象核心的字段只有 2 个:
- memoryStateGeneration: 当前的内存版本(在
writeToFile()中会过滤低于最新的内存版本的无效事务); - mapToWriteToDisk: 最终全量覆盖写回磁盘的数据。
SharedPreferencesImpl.java
private static class MemoryCommitResult {
// 内存版本
final long memoryStateGeneration;
// 需要全量覆盖写回磁盘的数据
final Map<String, Object> mapToWriteToDisk;
// 同步计数器
final CountDownLatch writtenToDiskLatch = new CountDownLatch(1);
@GuardedBy("mWritingToDiskLock")
volatile boolean writeToDiskResult = false;
boolean wasWritten = false;
// 后文写回结束后调用
void setDiskWriteResult(boolean wasWritten, boolean result) {
this.wasWritten = wasWritten;
// writeToDiskResult 会作为 commit 同步写回的返回值
writeToDiskResult = result;
// 唤醒等待锁
writtenToDiskLatch.countDown();
}
}
5.2 创建 MemoryCommitResult 事务对象
下面,我们先来分析创建 Editor#commitToMemery() 中 MemoryCommitResult 事务对象的步骤,核心步骤分为 3 步:
- 步骤 1 - 准备映射表
首先,检查 SharedPreferencesImpl#mDiskWritesInFlight 变量,如果 mDiskWritesInFlight == 0 则说明不存在并发写回的事务,那么 mapToWriteToDisk 就只会直接指向 SharedPreferencesImpl 中的 mMap 映射表。如果存在并发写回,则会深拷贝一个新的映射表。
mDiskWritesInFlight 变量是记录进行中的写回事务数量记录,每执行一次 commitToMemory() 创建事务对象时,就会将 mDiskWritesInFlight 变量会自增 1,并在写回事务结束后 mDiskWritesInFlight 变量会自减 1。
- 步骤 2 - 合并变更记录
其次,遍历 mModified 映射表将所有的变更记录(新增、修改或删除)合并到 mapToWriteToDisk 中(此时,Editor 中的数据已经同步到内存缓存中)。
这一步中的关键点是:如果发生有效修改,则会将 SharedPreferencesImpl 对象中的 mCurrentMemoryStateGeneration 最新内存版本自增 1,比最新内存版本小的事务会被视为无效事务。
- 步骤 3 - 创建事务对象
最后,使用 mapToWriteToDisk 和 mCurrentMemoryStateGeneration 创建 MemoryCommitResult 事务对象。
事务示意图

SharedPreferencesImpl.java
final class SharedPreferencesImpl implements SharedPreferences {
// 进行中事务计数(在提交事务是自增 1,在写回结束时自减 1)
@GuardedBy("mLock")
private int mDiskWritesInFlight = 0;
// 内存版本
@GuardedBy("this")
private long mCurrentMemoryStateGeneration;
// 磁盘版本
@GuardedBy("mWritingToDiskLock")
private long mDiskStateGeneration;
// 修改器
public final class EditorImpl implements Editor {
// 锁对象
private final Object mEditorLock = new Object();
// 修改记录(将以事务方式写回磁盘)
@GuardedBy("mEditorLock")
private final Map<String, Object> mModified = new HashMap<>();
// 清除全部数据的标记位
@GuardedBy("mEditorLock")
private boolean mClear = false;
// 获取需要写回磁盘的事务
private MemoryCommitResult commitToMemory() {
long memoryStateGeneration;
boolean keysCleared = false;
List<String> keysModified = null;
Set<OnSharedPreferenceChangeListener> listeners = null;
Map<String, Object> mapToWriteToDisk;
synchronized (SharedPreferencesImpl.this.mLock) {
// 如果同时存在多个写回事务,则使用深拷贝
if (mDiskWritesInFlight > 0) {
mMap = new HashMap<String, Object>(mMap);
}
// mapToWriteToDisk:需要写回的数据
mapToWriteToDisk = mMap;
// mDiskWritesInFlight:进行中事务自增 1
mDiskWritesInFlight++;
synchronized (mEditorLock) {
// changesMade:标记是否发生有效修改
boolean changesMade = false;
// 清除全部键值对
if (mClear) {
// 清除 mapToWriteToDisk 映射表(下面的 mModified 有可能重新增加键值对)
if (!mapToWriteToDisk.isEmpty()) {
changesMade = true;
mapToWriteToDisk.clear();
}
keysCleared = true;
mClear = false;
}
// 将 Editor 中的 mModified 修改记录合并到 mapToWriteToDisk
// mapToWriteToDisk 指向 SharedPreferencesImpl 中的 mMap,所以内存缓存越会被修改
for (Map.Entry<String, Object> e : mModified.entrySet()) {
String k = e.getKey();
Object v = e.getValue();
if (v == this /*使用 this 指针作为魔数*/|| v == null) {
// 移除键值对
if (!mapToWriteToDisk.containsKey(k)) {
continue;
}
mapToWriteToDisk.remove(k);
} else {
// 新增或更新键值对
if (mapToWriteToDisk.containsKey(k)) {
Object existingValue = mapToWriteToDisk.get(k);
if (existingValue != null && existingValue.equals(v)) {
continue;
}
}
mapToWriteToDisk.put(k, v);
}
// 标记发生有效修改
changesMade = true;
// 记录变更的键值对
if (hasListeners) {
keysModified.add(k);
}
}
// 重置修改记录
mModified.clear();
// 如果发生有效修改,内存版本自增 1
if (changesMade) {
mCurrentMemoryStateGeneration++;
}
// 记录当前的内存版本
memoryStateGeneration = mCurrentMemoryStateGeneration;
}
}
return new MemoryCommitResult(memoryStateGeneration, keysCleared, keysModified, listeners, mapToWriteToDisk);
}
}
}
步骤 2 - 合并变更记录中,存在一种 “反直觉” 的 clear() 操作:
如果在 Editor 中存在 clear() 操作,并且 clear 前后都有 putValue 操作,就会出现反常的效果:如以下示例程序,按照直观的预期效果,最终写回磁盘的键值对应该只有 ,但事实上最终 和 两个键值对都会被写回磁盘。
出现这个 “现象” 的原因是:SharedPreferences 事务中没有保持 clear 变更记录和 putValue 变更记录的顺序,所以 clear 操作之前的 putValue 操作依然会生效。
示例程序
getSharedPreferences("user", Context.MODE_PRIVATE).let {
it.edit().putString("name", "XIAOP PENG")
.clear()
.putString("age", "18")
.apply()
}
小结一下 3 个映射表的区别:
- 1、mMap 是 SharedPreferencesImpl 对象中记录的键值对数据,代表 SharedPreferences 的内存缓存;
- 2、mModified 是 Editor 修改器中记录的键值对变更记录;
- 3、mapToWriteToDisk 是 mMap 与 mModified 合并后,需要全量覆盖写回磁盘的数据。
6. 两种写回策略
在获得事务对象后,我们继续分析 Editor 接口中的 commit 同步写回策略和 apply 异步写回策略。
6.1 commit 同步写回策略
Editor#commit 同步写回相对简单,核心步骤分为 4 步:
- 1、调用
commitToMemory()创建MemoryCommitResult事务对象; - 2、调用
enqueueDiskWrite(mrc, null)提交磁盘写回任务(在当前线程执行); - 3、调用 CountDownLatch#await() 阻塞等待磁盘写回完成;
- 4、调用 notifyListeners() 触发回调监听。
commit 同步写回示意图

其实严格来说,commit 同步写回也不绝对是在当前线程同步写回,也有可能在后台 HandlerThread 线程写回。但不管怎么样,对于 commit 同步写回来说,都会调用 CountDownLatch#await() 阻塞等待磁盘写回完成,所以在逻辑上也等价于在当前线程同步写回。
SharedPreferencesImpl.java
public final class EditorImpl implements Editor {
@Override
public boolean commit() {
// 1、获取事务对象(前文已分析)
MemoryCommitResult mcr = commitToMemory();
// 2、提交磁盘写回任务
SharedPreferencesImpl.this.enqueueDiskWrite(mcr, null /* 写回成功回调 */);
// 3、阻塞等待写回完成
mcr.writtenToDiskLatch.await();
// 4、触发回调监听器
notifyListeners(mcr);
return mcr.writeToDiskResult;
}
}
6.2 apply 异步写回策略
Editor#apply 异步写回相对复杂,核心步骤分为 5 步:
- 1、调用
commitToMemory()创建MemoryCommitResult事务对象; - 2、创建
awaitCommitRuunnable 并提交到 QueuedWork 中。awaitCommit 中会调用 CountDownLatch#await() 阻塞等待磁盘写回完成; - 3、创建
postWriteRunnableRunnable,在 run() 中会执行 awaitCommit 任务并将其从 QueuedWork 中移除; - 4、调用
enqueueDiskWrite(mcr, postWriteRunnable)提交磁盘写回任务(在子线程执行); - 5、调用 notifyListeners() 触发回调监听。
可以看到不管是调用 commit 还是 apply,最终都会调用 SharedPreferencesImpl#enqueueDiskWrite() 提交磁盘写回任务。
区别在于:
- 在 commit 中 enqueueDiskWrite() 的第 2 个参数是 null;
- 在 apply 中 enqueueDiskWrite() 的第 2 个参数是一个
postWriteRunnable写回结束的回调对象,enqueueDiskWrite() 内部就是根据第 2 个参数来区分 commit 和 apply 策略。
apply 异步写回示意图
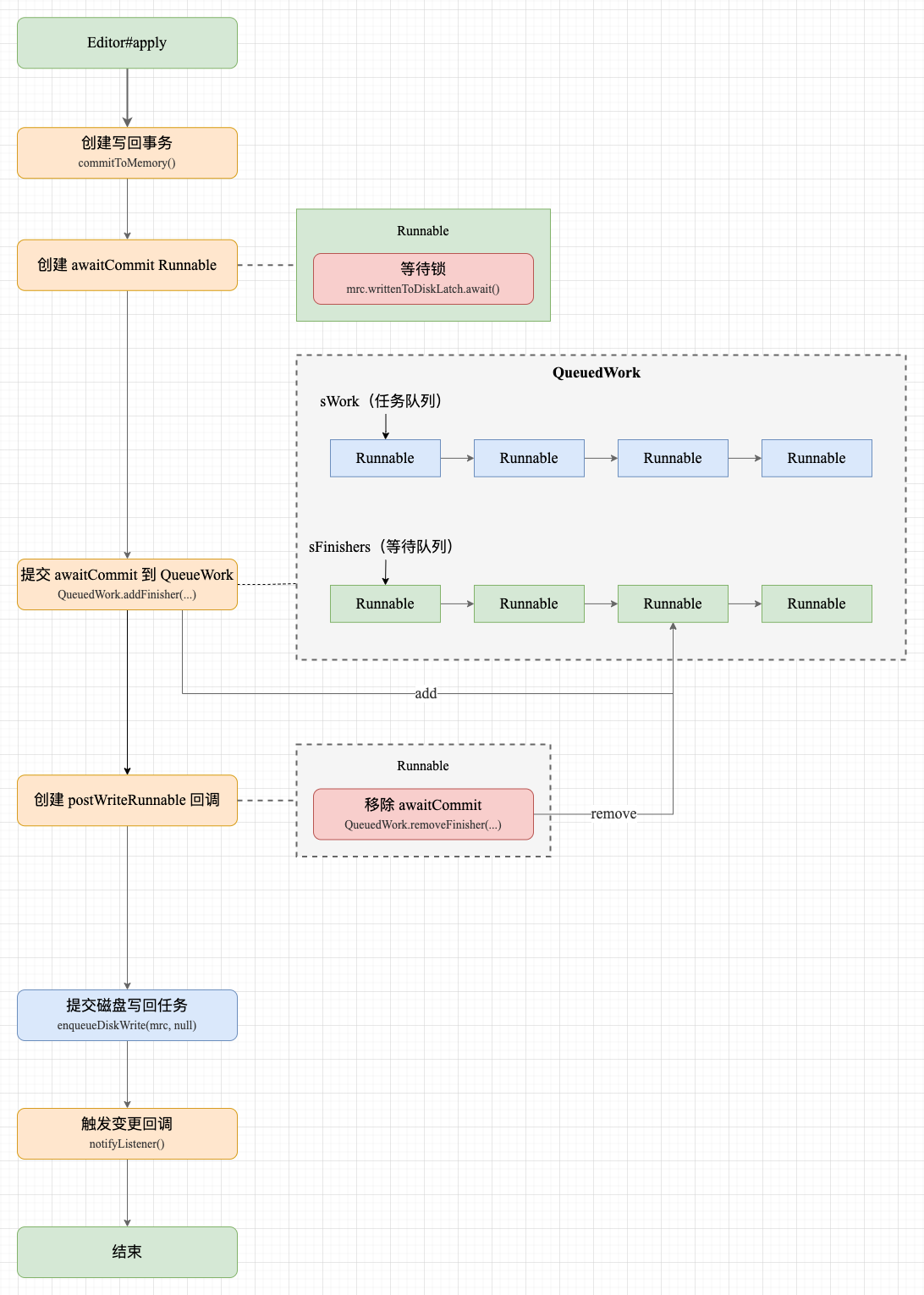
SharedPreferencesImpl.java
@Override
public void apply() {
// 1、获取事务对象(前文已分析)
final MemoryCommitResult mcr = commitToMemory();
// 2、提交 aWait 任务
// 疑问:postWriteRunnable 可以理解,awaitCommit 是什么?
final Runnable awaitCommit = new Runnable() {
@Override
public void run() {
// 阻塞线程直到磁盘任务执行完毕
mcr.writtenToDiskLatch.await();
}
};
QueuedWork.addFinisher(awaitCommit);
// 3、创建写回成功回调
Runnable postWriteRunnable = new Runnable() {
@Override
public void run() {
// 执行 aWait 任务
awaitCommit.run();
// 移除 aWait 任务
QueuedWork.removeFinisher(awaitCommit);
}
};
// 4、提交磁盘写回任务,并绑定写回成功回调
SharedPreferencesImpl.this.enqueueDiskWrite(mcr, postWriteRunnable /* 写回成功回调 */);
// 5、触发回调监听器
notifyListeners(mcr);
}
QueuedWork.java
// 提交 aWait 任务(后文详细分析)
private static final LinkedList<Runnable> sFinishers = new LinkedList<>();
public static void addFinisher(Runnable finisher) {
synchronized (sLock) {
sFinishers.add(finisher);
}
}
public static void removeFinisher(Runnable finisher) {
synchronized (sLock) {
sFinishers.remove(finisher);
}
}
这里有一个疑问:
在 apply() 方法中,在执行 enqueueDiskWrite() 前创建了 awaitCommit 任务并加入到 QueudWork 等待队列,直到磁盘写回结束才将 awaitCommit 移除。这个 awaitCommit 任务是做什么的呢?
我们稍微再回答,先继续往下走。
6.3 enqueueDiskWrite() 提交磁盘写回事务
可以看到,不管是 commit 还是 apply,最终都会调用 SharedPreferencesImpl#enqueueDiskWrite() 提交写回磁盘任务。虽然 enqueueDiskWrite() 还没到真正调用磁盘写回操作的地方,但确实创建了与磁盘 IO 相关的 Runnable 任务,核心步骤分为 4 步:
- 步骤 1:根据是否有 postWriteRunnable 回调区分是 commit 和 apply;
- 步骤 2:创建磁盘写回任务(真正执行磁盘 IO 的地方):
- 2.1 调用 writeToFile() 执行写回磁盘 IO 操作;
- 2.2 在写回结束后对前文提到的 mDiskWritesInFlight 计数自减 1;
- 2.3 执行 postWriteRunnable 写回成功回调;
- 步骤 3:如果是异步写回,则提交到 QueuedWork 任务队列;
- 步骤 4:如果是同步写回,则检查 mDiskWritesInFlight 变量。如果存在并发写回的事务,则也要提交到 QueuedWork 任务队列,否则就直接在当前线程执行。
其中步骤 2 是真正执行磁盘 IO 的地方,逻辑也很好理解。不好理解的是,我们发现除了 “同步写回而且不存在并发写回事务” 这种特殊情况,其他情况都会交给 QueuedWork 再调度一次。
在通过 QueuedWork#queue 提交任务时,会将 writeToDiskRunnable 任务追加到 sWork 任务队列中。如果是首次提交任务,QueuedWork 内部还会创建一个 HandlerThread 线程,通过这个子线程实现异步的写回任务。这说明 SharedPreference 的异步写回相当于使用了一个单线程的线程池,事实上在 Android 8.0 以前的版本中就是使用一个 singleThreadExecutor 线程池实现的。
提交任务示意图
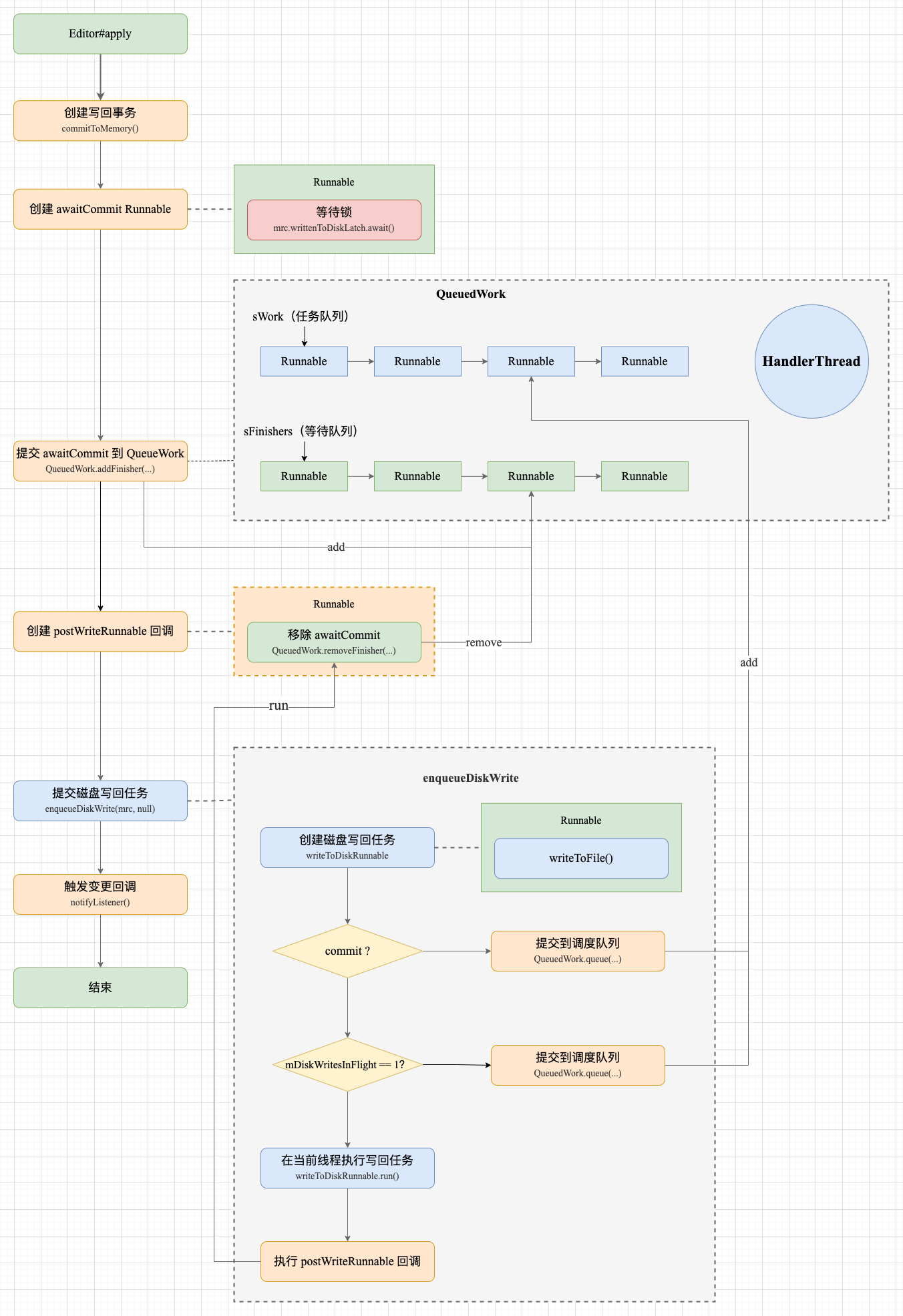
SharedPreferencesImpl.java
private void enqueueDiskWrite(final MemoryCommitResult mcr, final Runnable postWriteRunnable) {
// 1、根据是否有 postWriteRunnable 回调区分是 commit 和 apply
final boolean isFromSyncCommit = (postWriteRunnable == null);
// 2、创建磁盘写回任务
final Runnable writeToDiskRunnable = new Runnable() {
@Override
public void run() {
synchronized (mWritingToDiskLock) {
// 2.1 写入磁盘文件
writeToFile(mcr, isFromSyncCommit);
}
synchronized (mLock) {
// 2.2 mDiskWritesInFlight:进行中事务自减 1
mDiskWritesInFlight--;
}
if (postWriteRunnable != null) {
// 2.3 触发写回成功回调
postWriteRunnable.run();
}
}
};
// 3、同步写回且不存在并发写回,则直接在当前线程
// 这就是前文提到 “commit 也不是绝对在当前线程同步写回” 的源码出处
if (isFromSyncCommit) {
boolean wasEmpty = false;
synchronized (mLock) {
// 如果存在并发写回的事务,则此处 wasEmpty = false
wasEmpty = mDiskWritesInFlight == 1;
}
// wasEmpty 为 true 说明当前只有一个线程在执行提交操作,那么就直接在此线程上完成任务
if (wasEmpty) {
writeToDiskRunnable.run();
return;
}
}
// 4、交给 QueuedWork 调度(同步任务不可以延迟)
QueuedWork.queue(writeToDiskRunnable, !isFromSyncCommit /*是否可以延迟*/ );
}
@GuardedBy("mWritingToDiskLock")
private void writeToFile(MemoryCommitResult mcr, boolean isFromSyncCommit) {
// 稍后分析
}
QueuedWork 调度:
QueuedWork.java
@GuardedBy("sLock")
private static LinkedList<Runnable> sWork = new LinkedList<>();
// 提交任务
// shouldDelay:是否延迟
public static void queue(Runnable work, boolean shouldDelay) {
Handler handler = getHandler();
synchronized (sLock) {
// 入队
sWork.add(work);
// 发送 Handler 消息,触发 HandlerThread 执行任务
if (shouldDelay && sCanDelay) {
handler.sendEmptyMessageDelayed(QueuedWorkHandler.MSG_RUN, DELAY /* 100ms */);
} else {
handler.sendEmptyMessage(QueuedWorkHandler.MSG_RUN);
}
}
}
private static Handler getHandler() {
synchronized (sLock) {
if (sHandler == null) {
// 创建 HandlerThread 后台线程
HandlerThread handlerThread = new HandlerThread("queued-work-looper", Process.THREAD_PRIORITY_FOREGROUND);
handlerThread.start();
sHandler = new QueuedWorkHandler(handlerThread.getLooper());
}
return sHandler;
}
}
private static class QueuedWorkHandler extends Handler {
static final int MSG_RUN = 1;
QueuedWorkHandler(Looper looper) {
super(looper);
}
public void handleMessage(Message msg) {
if (msg.what == MSG_RUN) {
// 执行任务
processPendingWork();
}
}
}
private static void processPendingWork() {
synchronized (sProcessingWork) {
LinkedList<Runnable> work;
synchronized (sLock) {
// 创建新的任务队列
// 这一步是必须的,否则会与 enqueueDiskWrite 冲突
work = sWork;
sWork = new LinkedList<>();
// Remove all msg-s as all work will be processed now
getHandler().removeMessages(QueuedWorkHandler.MSG_RUN);
}
// 遍历 ,按顺序执行 sWork 任务队列
if (work.size() > 0) {
for (Runnable w : work) {
w.run();
}
}
}
}
比较不理解的是:
同一个文件的多次写回串行化可以理解,对于多个文件的写回串行化意义是什么,是不是可以用多线程来写回多个不同的文件?或许这也是 SharedPreferences 是轻量级框架的原因之一,你觉得呢?
6.4 主动等待写回任务结束
现在我们可以回答 6.1 中遗留的问题:
在 apply() 方法中,在执行 enqueueDiskWrite() 前创建了 awaitCommit 任务并加入到 QueudWork 等待队列,直到磁盘写回结束才将 awaitCommit 移除。这个 awaitCommit 任务是做什么的呢?
要理解这个问题需要管理分析到 ActivityThread 中的主线程消息循环:
可以看到,在主线程的 Activity#onPause、Activity#onStop、Service#onStop、Service#onStartCommand 等生命周期状态变更时,会调用 QueudeWork.waitToFinish():
ActivityThread.java
@Override
public void handlePauseActivity(...) {
performPauseActivity(r, finished, reason, pendingActions);
// Make sure any pending writes are now committed.
if (r.isPreHoneycomb()) {
QueuedWork.waitToFinish();
}
...
}
private void handleStopService(IBinder token) {
...
QueuedWork.waitToFinish();
ActivityManager.getService().serviceDoneExecuting(token, SERVICE_DONE_EXECUTING_STOP, 0, 0);
...
}
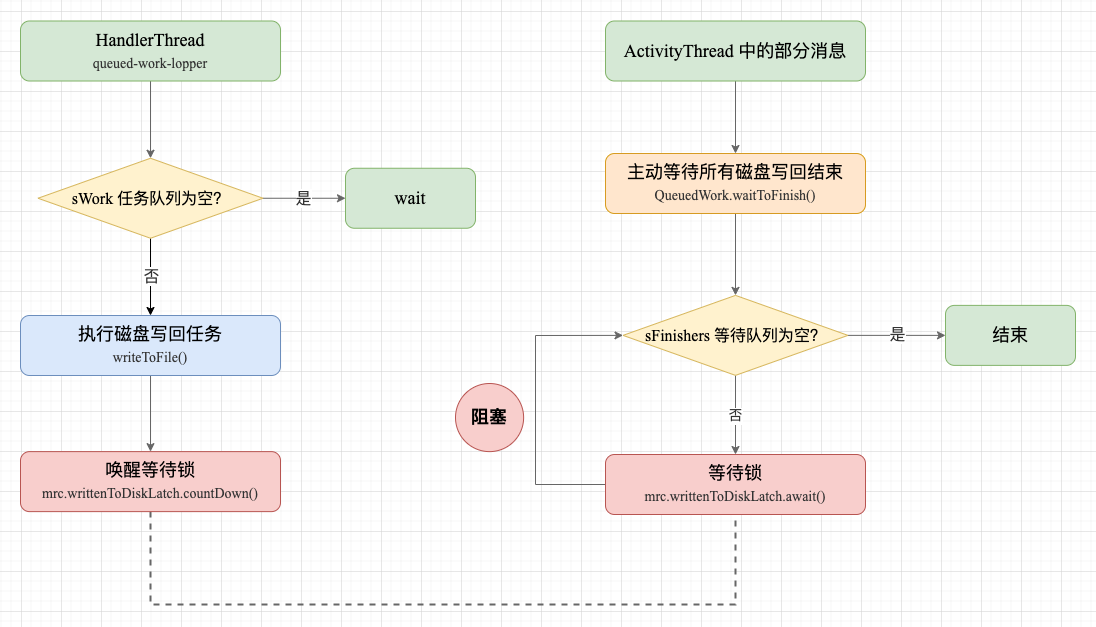
waitToFinish() 会执行所有 sFinishers 等待队列中的 aWaitCommit 任务,主动等待所有磁盘写回任务结束。在写回任务结束之前,主线程会阻塞在等待锁上,这里也有可能发生 ANR。
主动等待示意图
至于为什么 Google 要在 ActivityThread 中部分生命周期中主动等待所有磁盘写回任务结束呢?官方并没有明确表示,结合头条和抖音技术团队的文章,我比较倾向于这 2 点解释:
- 解释 1 - 跨进程同步(主要): 为了保证跨进程的数据同步,要求在组件跳转前,确保当前组件的写回任务必须在当前生命周期内完成;
- 解释 2 - 数据完整性: 为了防止在组件跳转的过程中可能产生的 Crash 造成未写回的数据丢失,要求当前组件的写回任务必须在当前生命周期内完成。
当然这两个解释并不全面,因为就算要求主动等待,也不能保证跨进程实时同步,也不能保证不产生 Crash。
抖音技术团队观点

QueuedWork.java
@GuardedBy("sLock")
private static Handler sHandler = null;
public static void waitToFinish() {
boolean hadMessages = false;
Handler handler = getHandler();
synchronized (sLock) {
if (handler.hasMessages(QueuedWorkHandler.MSG_RUN)) {
// Delayed work will be processed at processPendingWork() below
handler.removeMessages(QueuedWorkHandler.MSG_RUN);
}
// We should not delay any work as this might delay the finishers
sCanDelay = false;
}
// Android 8.0 优化:帮助子线程执行磁盘写回
// 作用有限,因为 QueuedWork 使用了 sProcessingWork 锁保证同一时间最多只有一个线程在执行磁盘写回
// 所以这里应该是尝试在主线程执行,可以提升线程优先级
processPendingWork();
// 执行 sFinshers 等待队列,等待所有写回任务结束
try {
while (true) {
Runnable finisher;
synchronized (sLock) {
finisher = sFinishers.poll();
}
if (finisher == null) {
break;
}
// 执行 mcr.writtenToDiskLatch.await();
// 阻塞线程直到磁盘任务执行完毕
finisher.run();
}
} finally {
sCanDelay = true;
}
}
Android 7.1 QueuedWork 源码对比:
public static boolean hasPendingWork() {
return !sPendingWorkFinishers.isEmpty();
}
7. writeToFile() 姗姗来迟
最终走到具体调用磁盘 IO 操作的地方了!
7.1 写回步骤
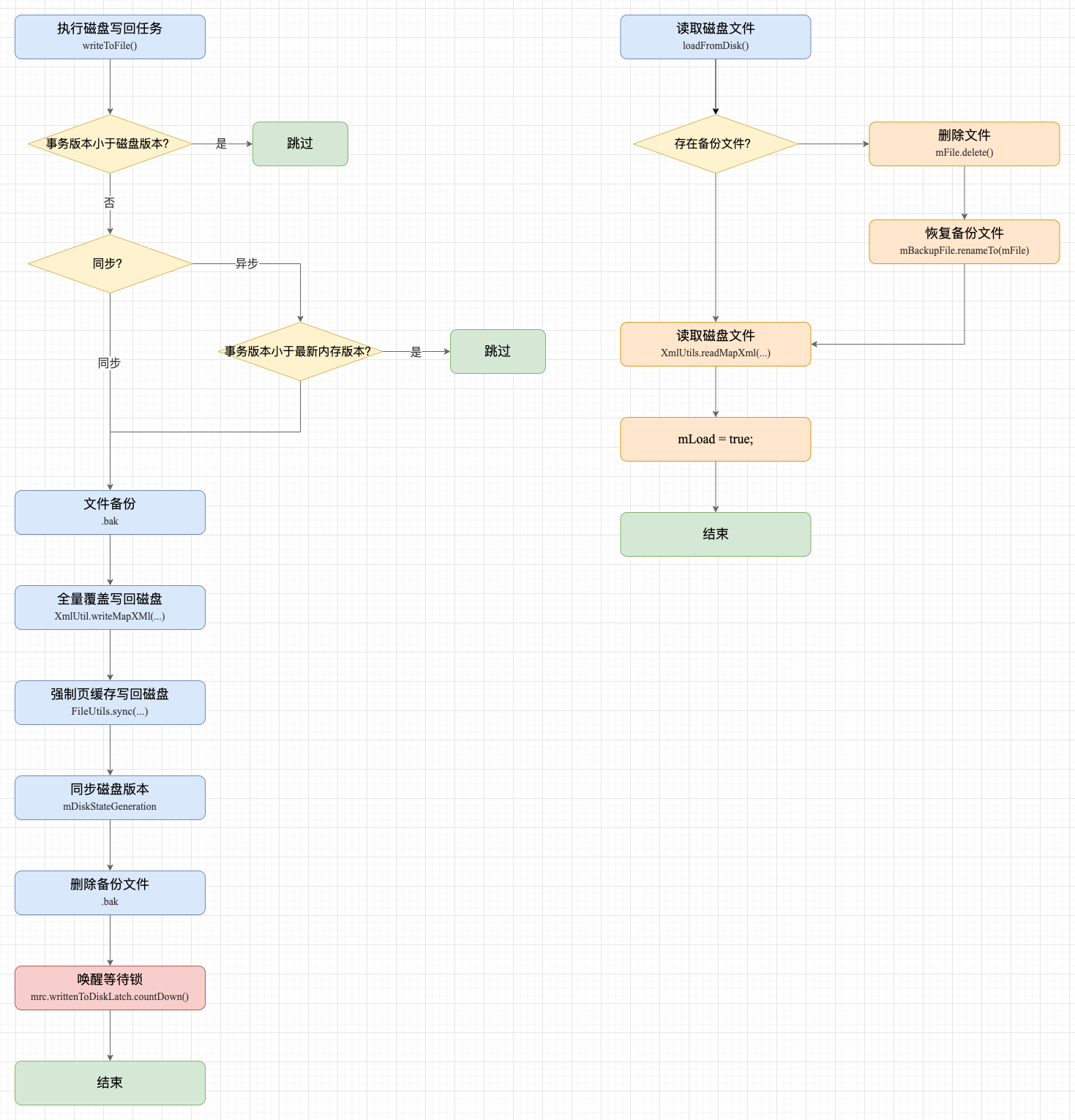
writeToFile() 的逻辑相对复杂一些了。经过简化后,剩下的核心步骤只有 4 大步骤:
-
步骤 1:过滤无效写回事务:
- 1.1 事务的 memoryStateGeneration 内存版本小于 mDiskStateGeneration 磁盘版本,跳过;
- 1.2 同步写回必须写回;
- 1.3 异步写回事务的 memoryStateGeneration 内存版本版本小于 mCurrentMemoryStateGeneration 最新内存版本,跳过。
-
步骤 2:文件备份:
- 2.1 如果不存在备份文件,则将旧文件重命名为备份文件;
- 2.2 如果存在备份文件,则删除无效的旧文件(上一次写回出并且后处理没有成功删除的情况)。
-
步骤 3:全量覆盖写回磁盘:
- 3.1 打开文件输出流;
- 3.2 将 mapToWriteToDisk 映射表全量写出;
- 3.3 调用 FileUtils.sync() 强制操作系统页缓存写回磁盘;
- 3.4 写入成功,则删除被封文件(如果没有走到这一步,在将来读取文件时,会重新恢复备份文件);
- 3.5 将磁盘版本记录为当前内存版本;
- 3.6 写回结束(成功)。
-
步骤 4:后处理: 删除写至半途的无效文件。
7.2 写回优化
继续分析发现,SharedPreference 的写回操作并不是简单的调用磁盘 IO,在保证 “可用性” 方面也做了一些优化设计:
- 优化 1 - 过滤无效的写回事务:
如前文所述,commit 和 apply 都可能出现并发修改同一个文件的情况,此时在连续修改同一个文件的事务序列中,旧的事务是没有意义的。为了过滤这些无意义的事务,在创建 MemoryCommitResult 事务对象时会记录当时的 memoryStateGeneration 内存版本,而在 writeToFile() 中就会根据这个字段过滤无效事务,避免了无效的 I/O 操作。
- 优化 2 - 备份旧文件:
由于写回文件的过程存在不确定的异常(比如内核崩溃或者机器断电),为了保证文件的完整性,SharedPreferences 采用了文件备份机制。在执行写回操作之前,会先将旧文件重命名为 .bak 备份文件,在全量覆盖写入新文件后再删除备份文件。
如果写回文件失败,那么在后处理过程中会删除写至半途的无效文件。此时磁盘中只有一个备份文件,而真实文件需要等到下次触发写回事务时再写回。
如果直到应用退出都没有触发下次写回,或者写回的过程中 Crash,那么在前文提到的创建 SharedPreferencesImpl 对象的构造方法中调用 loadFromDisk() 读取并解析文件数据时,会从备份文件恢复数据。
- 优化 3 - 强制页缓存写回:
在写回文件成功后,SharedPreference 会调用 FileUtils.sync() 强制操作系统将页缓存写回磁盘。
写回示意图
SharedPreferencesImpl.java
// 内存版本
@GuardedBy("this")
private long mCurrentMemoryStateGeneration;
// 磁盘版本
@GuardedBy("mWritingToDiskLock")
private long mDiskStateGeneration;
// 写回事务
private static class MemoryCommitResult {
// 内存版本
final long memoryStateGeneration;
// 需要全量覆盖写回磁盘的数据
final Map<String, Object> mapToWriteToDisk;
// 同步计数器
final CountDownLatch writtenToDiskLatch = new CountDownLatch(1);
// 后文写回结束后调用
// wasWritten:是否有执行写回
// result:是否成功
void setDiskWriteResult(boolean wasWritten, boolean result) {
this.wasWritten = wasWritten;
writeToDiskResult = result;
// 唤醒等待锁
writtenToDiskLatch.countDown();
}
}
// 提交写回事务
private void enqueueDiskWrite(final MemoryCommitResult mcr, final Runnable postWriteRunnable) {
...
// 创建磁盘写回任务
final Runnable writeToDiskRunnable = new Runnable() {
@Override
public void run() {
synchronized (mWritingToDiskLock) {
// 2.1 写入磁盘文件
writeToFile(mcr, isFromSyncCommit);
}
synchronized (mLock) {
// 2.2 mDiskWritesInFlight:进行中事务自减 1
mDiskWritesInFlight--;
}
if (postWriteRunnable != null) {
// 2.3 触发写回成功回调
postWriteRunnable.run();
}
}
};
...
}
// 写回文件
// isFromSyncCommit:是否同步写回
@GuardedBy("mWritingToDiskLock")
private void writeToFile(MemoryCommitResult mcr, boolean isFromSyncCommit) {
boolean fileExists = mFile.exists();
// 如果旧文件存在
if (fileExists) {
// 1. 过滤无效写回事务
// 是否需要执行写回
boolean needsWrite = false;
// 1.1 磁盘版本小于内存版本,才有可能需要写回
// (只有旧文件存在才会走到这个分支,但是旧文件不存在的时候也可能存在无意义的写回,
// 猜测官方是希望首次创建文件的写回能够及时尽快执行,毕竟只有一个后台线程)
if (mDiskStateGeneration < mcr.memoryStateGeneration) {
if (isFromSyncCommit) {
// 1.2 同步写回必须写回
needsWrite = true;
} else {
// 1.3 异步写回需要判断事务对象的内存版本,只有最新的内存版本才有必要执行写回
synchronized (mLock) {
if (mCurrentMemoryStateGeneration == mcr.memoryStateGeneration) {
needsWrite = true;
}
}
}
}
if (!needsWrite) {
// 1.4 无效的异步写回,直接结束
mcr.setDiskWriteResult(false, true);
return;
}
// 2. 文件备份
boolean backupFileExists = mBackupFile.exists();
if (!backupFileExists) {
// 2.1 如果不存在备份文件,则将旧文件重命名为备份文件
if (!mFile.renameTo(mBackupFile)) {
// 备份失败
mcr.setDiskWriteResult(false, false);
return;
}
} else {
// 2.2 如果存在备份文件,则删除无效的旧文件(上一次写回出并且后处理没有成功删除的情况)
mFile.delete();
}
}
try {
// 3、全量覆盖写回磁盘
// 3.1 打开文件输出流
FileOutputStream str = createFileOutputStream(mFile);
if (str == null) {
// 打开输出流失败
mcr.setDiskWriteResult(false, false);
return;
}
// 3.2 将 mapToWriteToDisk 映射表全量写出
XmlUtils.writeMapXml(mcr.mapToWriteToDisk, str);
// 3.3 FileUtils.sync:强制操作系统将页缓存写回磁盘
FileUtils.sync(str);
// 关闭输出流
str.close();
ContextImpl.setFilePermissionsFromMode(mFile.getPath(), mMode, 0);
// 3.4 写入成功,则删除被封文件(如果没有走到这一步,在将来读取文件时,会重新恢复备份文件)
mBackupFile.delete();
// 3.5 将磁盘版本记录为当前内存版本
mDiskStateGeneration = mcr.memoryStateGeneration;
// 3.6 写回结束(成功)
mcr.setDiskWriteResult(true, true);
return;
} catch (XmlPullParserException e) {
Log.w(TAG, "writeToFile: Got exception:", e);
} catch (IOException e) {
Log.w(TAG, "writeToFile: Got exception:", e);
}
// 在 try 块中抛出异常,会走到这里
// 4、后处理:删除写至半途的无效文件
if (mFile.exists()) {
if (!mFile.delete()) {
Log.e(TAG, "Couldn't clean up partially-written file " + mFile);
}
}
// 写回结束(失败)
mcr.setDiskWriteResult(false, false);
}
// -> 读取并解析文件数据
private void loadFromDisk() {
synchronized (mLock) {
if (mLoaded) {
return;
}
// 1、如果存在备份文件,则恢复备份数据(后文详细分析)
if (mBackupFile.exists()) {
mFile.delete();
mBackupFile.renameTo(mFile);
}
}
...
}
至此,SharedPreferences 核心源码分析结束。
8. SharedPreferences 的其他细节
SharedPreferences 还有其他细节值得学习。
8.1 SharedPreferences 锁总结
SharedPreferences 是线程安全的,但它的线程安全并不是直接使用一个全局的锁对象,而是采用多种颗粒度的锁对象实现 “锁细化” ,而且还贴心地使用了 @GuardedBy 注解标记字段或方法所述的锁级别。
使用 @GuardedBy 注解标记锁级别
@GuardedBy("mLock")
private Map<String, Object> mMap;
| 对象锁 | 功能呢 | 描述 |
|---|---|---|
| 1、SharedPreferenceImpl#mLock | SharedPreferenceImpl 对象的全局锁 | 全局使用 |
| 2、EditorImpl#mEditorLock | EditorImpl 修改器的写锁 | 确保多线程访问 Editor 的竞争安全 |
| 3、SharedPreferenceImpl#mWritingToDiskLock | SharedPreferenceImpl#writeToFile() 的互斥锁 | writeToFile() 中会修改内存状态,需要保证多线程竞争安全 |
| 4、QueuedWork.sLock | QueuedWork 的互斥锁 | 确保 sFinishers 和 sWork 的多线程资源竞争安全 |
| 5、QueuedWork.sProcessingWork | QueuedWork#processPendingWork() 的互斥锁 | 确保同一时间最多只有一个线程执行磁盘写回任务 |
8.2 使用 WeakHashMap 存储监听器
SharedPreference 提供了 OnSharedPreferenceChangeListener 回调监听器,可以在主线程监听键值对的变更(包含修改、新增和移除)。
SharedPreferencesImpl.java
@GuardedBy("mLock")
private final WeakHashMap<OnSharedPreferenceChangeListener, Object> mListeners =
new WeakHashMap<OnSharedPreferenceChangeListener, Object>();
SharedPreferences.java
public interface SharedPreferences {
public interface OnSharedPreferenceChangeListener {
void onSharedPreferenceChanged(SharedPreferences sharedPreferences, String key);
}
}
比较意外的是: SharedPreference 使用了一个 WeakHashMap 弱键散列表存储监听器,并且将监听器对象作为 Key 对象。这是为什么呢?
这是一种防止内存泄漏的考虑,因为 SharedPreferencesImpl 的生命周期是全局的(位于 ContextImpl 的内存缓存),所以有必要使用弱引用防止内存泄漏。想想也对,Java 标准库没有提供类似 WeakArrayList 或 WeakLinkedList 的容器,所以这里将监听器对象作为 WeakHashMap 的 Key,就很巧妙的复用了 WeakHashMap 自动清理无效数据的能力。
提示: 关于 WeakHashMap 的详细分析,请阅读小彭说 · 数据结构与算法 专栏文章 《WeakHashMap 和 HashMap 的区别是什么,何时使用?》
8.3 如何检查文件被其他进程修改?
在读取和写入文件后记录 mStatTimestamp 时间戳和 mStatSize 文件大小,在检查时检查这两个字段是否发生变化
SharedPreferencesImpl.java
// 文件时间戳
@GuardedBy("mLock")
private StructTimespec mStatTimestamp;
// 文件大小
@GuardedBy("mLock")
private long mStatSize;
// 读取文件
private void loadFromDisk() {
...
mStatTimestamp = stat.st_mtim;
mStatSize = stat.st_size;
...
}
// 写入文件
private void writeToFile(MemoryCommitResult mcr, boolean isFromSyncCommit) {
...
mStatTimestamp = stat.st_mtim;
mStatSize = stat.st_size;
...
}
// 检查文件
private boolean hasFileChangedUnexpectedly() {
synchronized (mLock) {
if (mDiskWritesInFlight > 0) {
// If we know we caused it, it's not unexpected.
if (DEBUG) Log.d(TAG, "disk write in flight, not unexpected.");
return false;
}
}
// 读取文件 Stat 信息
final StructStat stat = Os.stat(mFile.getPath());
synchronized (mLock) {
// 检查修改时间和文件大小
return !stat.st_mtim.equals(mStatTimestamp) || mStatSize != stat.st_size;
}
}
至此,SharedPreferences 全部源码分析结束。
9. 总结
可以看到,虽然 SharedPreferences 是一个轻量级的 K-V 存储框架,但的确是一个完整的存储方案。从源码分析中,我们可以看到 SharedPreferences 在读写性能、可用性方面都有做一些优化,例如:锁细化、事务化、事务过滤、文件备份等,值得细细品味。
在下篇文章里,我们来盘点 SharedPreferences 中存在的 “缺点”,为什么 SharedPreferences 没有乘上新时代的船只。请关注。
参考资料
- Android SharedPreferences 的理解与使用 —— ghroosk 著
- 一文读懂 SharedPreferences 的缺陷及一点点思考 —— 业志陈 著
- 反思|官方也无力回天?Android SharedPreferences 的设计与实现 —— 却把青梅嗅 著
- 剖析 SharedPreference apply 引起的 ANR 问题 —— 字节跳动技术团队
- 今日头条 ANR 优化实践系列 - 告别 SharedPreference 等待 —— 字节跳动技术团队



![[REDIS]redis的一些配置文件](https://img-blog.csdnimg.cn/4bf9fbd226074ea685d659561d08d5cd.png)