目录
- Zookeeper 概述
- Zookeeper 的特点
- Zookeeper 的应用场景
- Zookeeper的数据结构
- ZNode数据类型
- ZNode里面存储的信息
- Zookeeper的选举机制(重要)
- Zookeeper第一次启动选举机制
- Zookeeper非第一次启动选举机制
- Zookeeper 底层如何按照请求的先后顺序来处理的
Zookeeper 概述
什么是Zookeeper?
Zookeeper是一个开源的分布式的,为其他分布式监控提供协调服务的Apache项目。
Zookeeper 的特点
Zookeeper 有哪些特点?
-
Zookeeper是由一个Leader,和多个Follower组成的集群。
-
Zookeeper集群中只有半数以上的节点存活,Zookeeper集群才能正常提供服务。
-
Zookeeper集群全局数据统一,每个Zookeeper Server保存一份相同的数据副本,Client无论连接哪一台Server,数据都是一致的。
-
由于有事务的存在,每次写操作都有事务id(zxid),所以数据更新具有原子性,要么成功,要么失败。
Zookeeper 的应用场景
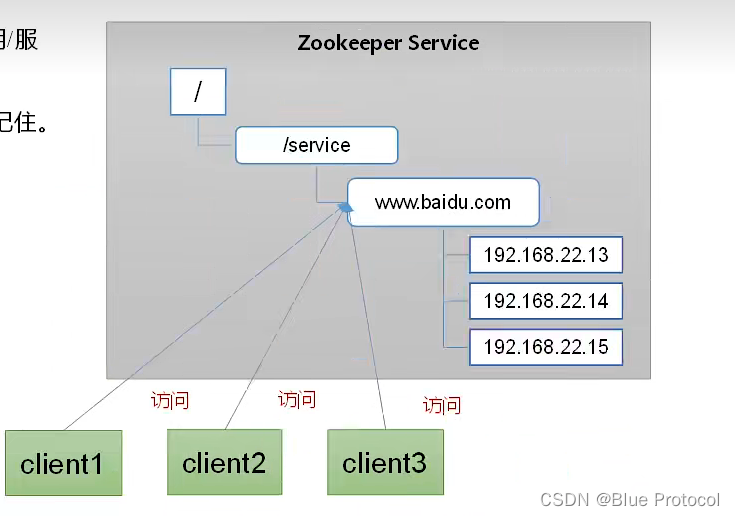
1、提供记录IP地址的域名服务。
如我们可以将www.baidu.com作为父节点,下面的子节点为真实的IP地址,便于标识。
2、统一配置管理。
可将配置信息写入Zookeeper的一个ZNode中,然后各个客户端服务器监听这个ZNode,一旦这个ZNode中的数据发生变化,Zookeeper将通知各个客户端服务器。
3、统一集群管理。Zookeeper可以实现监控集群中各节点的状态变化。
可将集群节点的信息写入Zookeeper的一个ZNode中,然后监听这个ZNode可获得它的实时状态变化。

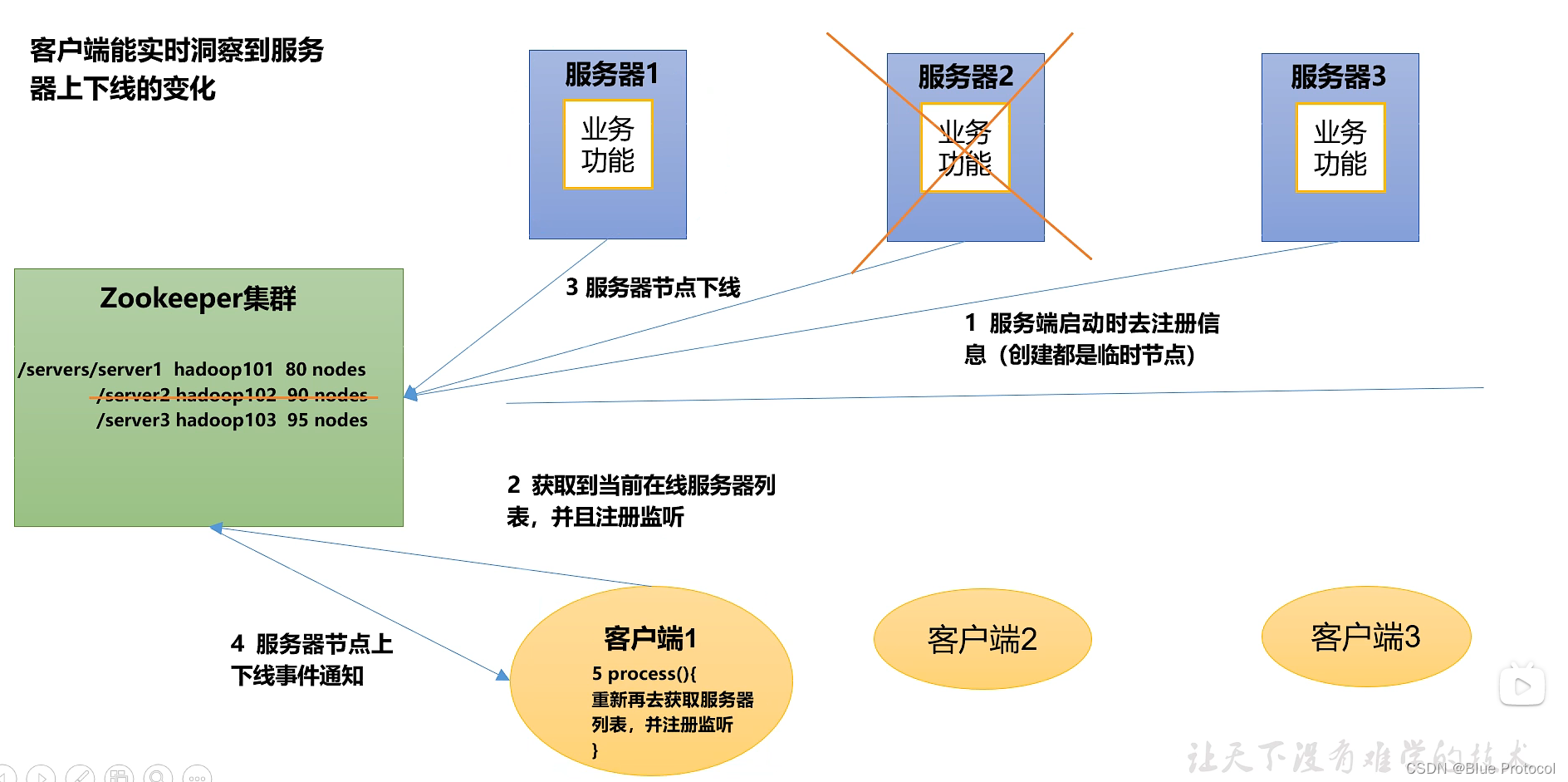
4、服务器动态上下线。客户端能实时洞察服务器上下线的变化。
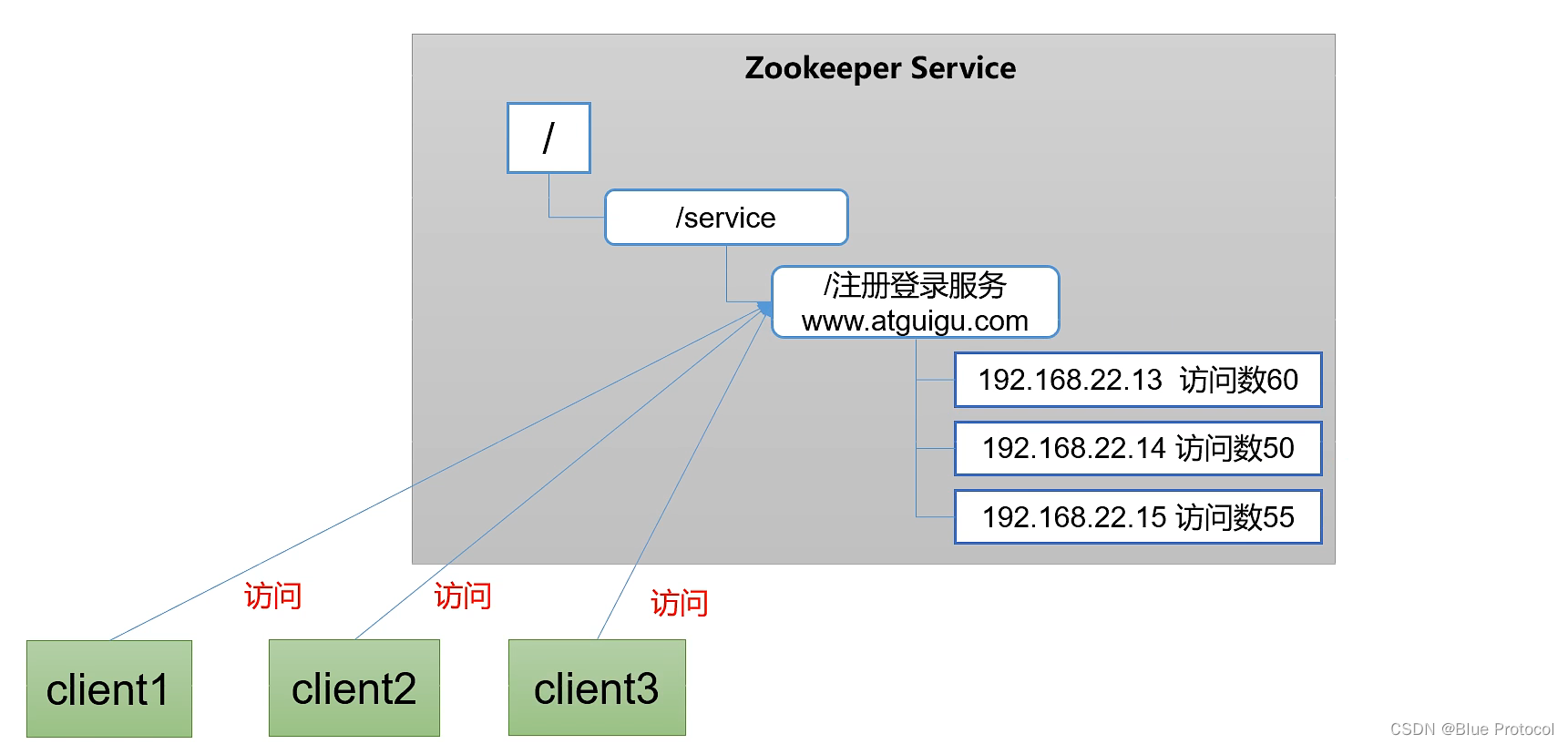
5、软负载均衡。
让Zookeeper记录每台服务器的访问数,让访问最好的服务器去处理最小的客户端请求。
Zookeeper的数据结构
Zookeeper的数据结构与文件系统很类似,属于树形结构。
整体可以看做是一颗树,每个节点称为一个ZNode,每个ZNode都可以通过其路径唯一标识,如/znode1/leaf1,就可以找到根目录/下的/znode1下的leaf1。每个ZNode能存储的数据量非常小,大约能够存储1MB的数据,只能用来存储一些简单的配置信息,不能存储海量数据。
ZNode数据类型
ZNode包括四种不同的类型,分别是 持久的、持久有序的、短暂的、短暂有序的。其中持久和短暂是指
1)持久:客户端与服务器断开连接之后,创建的节点不删除。
2)短暂:客户端与服务器断开连接之后,创建的节点被删除。
3)有序:创建有序的ZNode时,ZNode的名称后会附加一个顺序号,顺序号是一个单调递增的计数器,由父节点维护。
ZNode里面存储的信息
ZNode里面包含了存储的数据(data)、访问权限(acl)、子节点引用(child)和节点状态信息(stat)。
其中
访问权限acl是指记录客户端对ZNode节点的访问权限。
子节点引用child是指当前节点的子节点引用。
节点状态信息stat包含Znode节点的状态信息,比如事务id,版本号,时间戳等。
Zookeeper的选举机制(重要)
关于Zookeeper的选举机制,我们先要记住它的半数以上选举机制,而且我们还需要看看是第一次启动还是非第一次启动。
Zookeeper第一次启动选举机制
假设我们的Zookeeper集群有4个节点。而刚开始我们的Zookeeper服务都是关闭的。
(1)节点1启动,会发起一次选举。节点1会投自己一票,不够半数以上(3票),选举无法完成,节点1状态保持为LOOKING状态;
(2)节点2启动,再次发起一次选举。节点1和节点2分别投自己一票然后交换选品信息,此时节点1发现节点2的myid比自己大,所以更改选票为节点2,不够半数以上(3票),选举无法完成,节点1和节点2状态保持为LOOKING状态;
(3)节点3启动,发起一次选举。过程和节点2发起选票一样,最后更改选票为节点3.此次投票结果:节点1和节点2为0票,节点3为3票,由于半数以上选举机制,节点3当选Leader,并更改状态为LEADING,节点1和节点2Follower,并且更改状态为FOLLOWING。
(4)节点4启动,发起一次选票。此时此时节点1/2/3已经半数LOOKING状态,不会更改选票信息。交换选票信息结果:节点3为3票,节点4为1票,此时节点4更改选票为节点3,并更改状态为FOLLOWING。
Zookeeper非第一次启动选举机制
当其中一台机器由于网络分区故障无法与集群和Leader保持连接时,该节点进入选举状态,但是由于半数以上选举机制,该节点无法成为Leader,只能不断与其他节点进行连接,在连接成功之后,集群可能会出现两种情况:
1、集群中本来就存在Leader。对于这种情况,该节点会被当中当前集群的Leader信息,对于该节点来说,只要与Leader重新进行连接并更新状态即可。
2、集群中确实不存在Leader。
这个情况下,我们需要了解几个核心参数:
(1)SID:服务器ID,服务器ID和配置中的myid一致。
(2)ZXID:事务ID,该ID和服务器对于客户端更新请求有关。
(3)Epoch:每个Leader任期的代号,没有Leader时这个在各节点中是相同的,每次投完一次票这个数据就会增加。
假设Zookeeper集群由4个节点组成,SID为1/2/3/4,ZXID为8887,此时节点3为Leader。某时刻,节点4和Leader都挂掉了。
那么只剩下节点1和节点2,他们的(Epoch,ZXID,SID)分别为(1,8,1)和(1,7,2)
非第一次启动并Leader不存在的Leader选举机制为:
(1)Epoch大的胜出
(2)Epoch相同,ZXID大的胜出
(3)ZXID相同,SID大的胜出
综上,节点1当选Leader。
Zookeeper 底层如何按照请求的先后顺序来处理的
Leader收到请求之后,会给每个请求分配一个全局唯一的递增的ZXID,如何把请求放入一个FIFO队列里面,之后就按照FIFO的策略发送给所有的Follower。