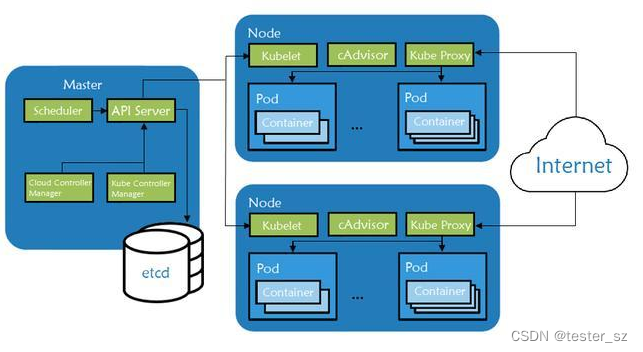
性能优化一直是前端领域讨论的一个热门问题,但在平时沟通及code review过程中发现很多人对于React中性能优化理解很模糊,讲不清楚组件什么时候更新,为什么会更新,关于React性能优化的文章虽然比较多,但大多数都是在罗列一些优化的点,本文将以React底层更新过程为基础,层层递进,将性能优化相关的用法、原理串联起来,让读者真正理解为什么需要性能优化以及如何使用。
更新流程
React使得前端开发者不再跟DOM打交道,只需要控制组件及其状态来完成应用开发。React在这背后做的最主要的工作就是保持组件状态与用户界面的一致性:将组件状态构建成用于描述用户界面的UI Tree(或者叫Virtual Dom)并反应的浏览器中,这也是React更新的一个最宏观的过程。
我们向下一层,看一下当更新发生时的具体过程。
如下图所示,假设用户蓝色的结点中发生了一次onClick,对应组件触发了相应setState,React就会重新开始构建整颗UI Tree。因为构建都是从根节点发生的,所以会先调用getRootForUpdateFiber找到根节点,并触发ScheduleUpdateOnFiber进入Scheduler进行调度开始更新过程;更新主要分为两个阶段,Render Phase和Commit Phase,其中
-
Render阶段就是根据每个组件中的状态构建出一个新的UI Tree,也叫WorkInProgress Tree,并为每一个结点对应的操作打上EffectTag,即更新、删除、新增。全部构建完成后就进入下一阶段。
-
Commit阶段就是将构建好的WIP Tree反应到浏览器中,即React为我们自动进行相应的dom操作,保持UI一致性。
当提交完成后,实际上一次更新就完成了,用户可以进行交互,可能又会触发新的更新,从而循环这个过程。
上图的这个过程,实际上就是React更新的核心Loop。开发者或者是React团队本身所做的所有关于性能优化的事情,本质上都是通过加速这个loop的过程,从而实现用户界面的高响应。比如Scheduler中Time Slice机制实际上就是减少每次循环的工作量,当然这个过程对我们开发者是无感的,不再详细展开,我们今天重点的关注是作为开发者,如何加速这一过程,也就是实现性能优化。
如何加速
这里我们再向下一层,看一下Render阶段到底是如何构建UI Tree的。因为结点会组成一个树结构,所以构建的过程本身是一个遍历的过程,每个阶段结点都会经历beginWork和completeWork,大致遍历过程如下图所示
遍历过程并非本篇重点,过程有简化
默认优化策略
然而对于一个实际的应用来说,涉及节点众多,而实际一个用户操作,往往只会影响个别的节点,如果挨个遍历,全部重新构建一遍显然会有些浪费,当然React自己也知道这件事,具体是怎么优化的呢?
我们干脆再深入一层,直接到源码看看React在beginWork里都做了些什么
为方便读者理解,源码有一定程度简化
// ReactFiberBeginWork.new.js
function beginWork(current, workInPrgress, renderLanes) {// 检查props和context是否发生改变if (oldProps !== newProps || hasLegacyContextChanged()) { didReceiveUpdate = true;} else { // props或者context都未改变的时候,检查是否有pending中的updateconst hasScheduledUpdateOrContext = checkScheduledUpdateOrContext(current,renderLanes,);if (!hasScheduledUpdateOrContext) {didReceiveUpdate = false;// 当前Fiber可以复用,进入bailout流程return attemptEarlyBailoutIfNoScheduledUpdate(current, workInProgress, renderLanes);}}// 无法bailout,真正进入beginWork流程
}
代码中关于这部分可以看到名称叫LegacyContext,所以这里的context实际上是指旧版的context,新版的context是否发生变化实际上会反应到pending update中,但这里直接理解成context并不影响本文内容,因此不再展开
可以看到,React在真正进入beginWork构建之前,实际上会有一层逻辑判断,这就是React自带的性能优化策略。对于那些props state(pending update) context没有发生变化的结点会进入bailout流程,中文翻译过来为“急救”,可以简单理解成这个结点没有发生变化,还可以抢救一下,没必要让他重生。
我们再进一步看看attemptEarlyBailoutIfNoScheduledUpdate里面做了什么,核心其实下面这个方法,主要是看子节点state是否发生变化,如果没有,直接返回null,代表当前节点的子树都可以bailout,也就是跳过构建
function bailoutOnAlreadyFinishedWork( current: Fiber | null,workInProgress: Fiber,renderLanes: Lanes, ): Fiber | null {// 检查下children是否有pending workif (!includesSomeLane(renderLanes, workInProgress.childLanes)) {return null}// 当前结点无任务工作要做,但是子树有,克隆子结点,继续Reconciler的过程cloneChildFibers(current, workInProgress);return workInProgress.child;
}
🤔 为什么看子树有没有发生变化时为什么没有比较props
到这里我们就搞明白了React自带的性能优化策略,简单概括下如下
接下来我们看一个非常简单的demo,思考一下当点击update按钮时,Child中的"child render"会被打印吗
const Child = () => {console.log('child render');return <div>I am child</div>;
};
export default function App() {const [count, setCount] = useState(0);return (<><button onClick={() => setCount(count + 1)}>update</button><Child /></>);
}
根据我们刚才的分析,当Child组件进入beginWork流程时,因为props state context都没有变,应该会被跳过,即走Bailout流程才对。但是实际上可以看到每次点击,Child组件都会重新渲染,这是为什么呢
让我们带着疑问,直接到源码里面调试一下
可以看到,Child组件确实没有满足React默认优化策略的条件,而不满足的原因是props发生了变化。
我们知道,JSX本质上是React.createElement的语法糖,所以调用Child的地方(App组件内),本质上是调用React.createElement,传递的props为一个空对象,App两次渲染传递给子组件的props并不相等 {} !== {}
export default function App() {const [count, setCount] = useState(0);return (<><button onClick={() => setCount(count + 1)}>update</button>{React.createElement('Child', {})}<Child /></>);
}
手动跳过构建
既然Child与状态count无关,理论上来讲肯定是可以被跳过的重新渲染呢,怎么做呢?这里就要引入第一个性能优化API React.memo,如下面的例子通过memo包裹来组件之后,发现这时候点击后,Child不会再重新渲染了。
const Child = memo(() => {console.log('child render');return <div>I am child</div>;
});
export default function App() {const [count, setCount] = useState(0);return (<><button onClick={() => setCount(count + 1)}>update</button><Child /></>);
}
我们直接进入源码中看看memo到底做了什么
类似效果的API还有
PureComponent、ShouldComponentUpdate,由于现在基本都已经拥抱函数式组件,此处以memo为例
function updateSimpleMemoComponent( current: Fiber | null,workInProgress: Fiber,Component: any,nextProps: any,renderLanes: Lanes, ): null | Fiber {const prevProps = current.memoizedProps;// 使用浅比较代替了全等比较if (shallowEqual(prevProps, nextProps)) { didReceiveUpdate = false;}// 检查是否有pending的更新if (!checkScheduledUpdateOrContext(current, renderLanes)) {return bailoutOnAlreadyFinishedWork(current,workInProgress,renderLanes,);}// 无法bailout, 即进入render阶段return updateFunctionComponent(current,workInProgress,Component,nextProps,renderLanes,);
}
从源码中我们可以看到,当自动bailout不满足时,memo实际上提供了另一条路径进入bailout,而要求跟默认优化策略非常类似,唯一的区别是第10行,用shallowEqual替换了原先的props全等比较。而对于我们上面demo的情况,由于新旧props都是空对象,因此通过浅比较就满足了优化策略,从而跳过了构建过程。
🤔 那是不是给每个组件都包裹一下memo,来尽可能的命中bailout?
第三条路
上面的问题显然答案是否定的,因为如果是的话,那React为什么不直接默认给所有组件都包裹一下,还需要开发者手动来不是多此一举么?
不这么做的原因是,memo并不是免费的,shallowEqual会去挨个遍历props并进行比较,这个成本可要比全等大多了,那有没有办法不使用memo又能命中bailout的第三条路呢,这里给大家介绍两种方式
Move state down - 状态下放
还是拿刚才那个例子,我们可以看到App组件更新的原因是内部的count发生了变化,而Child虽然跟count没有任何关系,但是由于同属于一个组件,也被带着重新渲染了
const Child = () => {console.log('child render');return <div>I am child</div>;
};
export default function App() {const [count, setCount] = useState(0);return (<><button onClick={() => setCount(count + 1)}>update</button><Child /></>);
}
我们稍微改造一下,把count及其相关的逻辑抽离到另外一个子组件Counter中
const Child = () => {console.log('child render');return <div>I am child</div>;
};
const Counter = () => {const [count, setCount] = useState(0);return <button onClick={() => setCount(count + 1)}>update</button>;
}
export default function App() {return (<><Counter /><Child /></>);
}
可以实际测试一下上面的代码,虽然只是简单调整了一下组件结构,Child居然不再重新渲染了
原因就在于变化的内容现在在Counter内部,App组件会由于满足了默认的性能优化策略不再重新渲染,因此传递给Child的props就不会发生变化,从而Child也就满足了默认的性能优化策略,这种逻辑是具有传递性的,即如果Child还有子组件,也会因为Child没有重渲染,继续满足默认性能优化策略而都被跳过。
大家是否有听说过这样的建议要避免大组件,将组件的粒度控制要尽可能的细。
在React中,组件本质上就是函数,函数有单一职责原则,组件也适用 。 想必通过上面的例子,我们对于这句话能有更深的理解,这么做不仅仅是便于维护,而是会直接影响到性能优化。
Lift content up - 内容提升
当然也有状态下放不适用的情况,比如但是当遇到下面这个case,Child的外层div中也用到了count,如果将Child全部拆分过去到Counter中,实际Counter变化,Child还是会重新渲染,这时候就可以用另外一种方法 内容提升
const Child = () => {console.log('child render');return <div>I am child</div>;
};
export default function App() {const [count, setCount] = useState(0);return (<div classname={count}><button onClick={() => setCount(count + 1)}>update</button><Child /></div>);
}
简而言之就是虽然将Child拆分到Counter中,但是Child得渲染不依赖任何Counter的内容,可以将Child提升到App中,以children的方式进行传递
const Child = () => {console.log('child render');return <div>I am child</div>;
};
const Counter = ({children}) => {const [count, setCount] = useState(0);return (<div classname={count}><button onClick={() => setCount(count + 1)}>update</button>{children} </div> );
}
export default function App() {return (<Counter><Child /></Counter>);
}
通过上面这种方式,其实Child也不会重新渲染,调试一下看看Counter的props,发现children实际上就是Child,能看到两次渲染Child内容并没有变
原因是Child现在是作为Counter组件的props,props的内容是在App组件中传递的,因此可以理解成Child依然是直接依赖于App组件,由于App没有重新渲染,因此Child也满足了默认的性能优化策略。
跳过局部构建
通过上面的内容,我们知道了每次更新时会去重新构建组件树,当然我们也可以通过命中bailout来避免组件重新构建,但组件内确实发生了状态变化就无法bailout,这时候就会进入一个组件的render阶段
function updateSimpleMemoComponent( current: Fiber | null,workInProgress: Fiber,Component: any,nextProps: any,renderLanes: Lanes, ): null | Fiber {// ...// 无法bailout, 即进入render阶段return updateFunctionComponent(current,workInProgress,Component,nextProps,renderLanes,);
}
跟随代码继续走我们可以看到render阶段实际上就是调用组件的渲染方法
export function renderWithHooks(current: Fiber | null,workInProgress: Fiber,Component: (p: Props, arg: SecondArg) => any,props: Props,secondArg: SecondArg,nextRenderLanes: Lanes,
): any {// ...let children = Component(props, secondArg);// ...
}
到这里就要轮到两个性能优化的API出场了: useMemo useCallback ,背后的逻辑是如果一个组件必须重新绘制时,我们可以尽可能加速这个绘制的过程。
useMemo的基本用法相关资料很多这里不再赘述,重点说明下使用useMemo的两种场景
- 避免耗时的逻辑重复计算
如下面的例子所示,heavyCalc是一个耗时比较严重的逻辑运算,我们期望与state2无关的reRender能够跳过这次运算,通过useMemo包裹heavyCalc能够实现只有当state2变化时才重新计算val。
const Comp = () => {const [state1, setState1] = useState();const [state2, setState2] = useState();const val = heavyCalc(state2);return (// ...);
}
- 防止子组件的缓存击穿
list由于是Child组件的props,而每次Comp更新都会生成一个全新的对象,这会导致Child即使使用了性能优化策略,如使用React.memo也无法命中bailout,而通过userMemo返回list,可以实现每次渲染都返回同一个值。
const Comp = () => {// ...// 通过缓存这个值来避免子组件memo失效const list = []return (// ...<Child list={list} />);
}
useMemo是如何做到的呢,我们直接看看源码:
function updateMemo(nextCreate, deps) {// ...const prevDeps: Array<mixed> | null = prevState[1];// 对于数组中的每一项全等比较if (areHookInputsEqual(nextDeps, prevDeps)) {return prevState[0];}// 调用函数返回新创建的值const nextValue = nextCreate();hook.memoizedState = [nextValue, nextDeps];return nextValue;
}
实现比较简单,最关键的就是第四行,做的事情就是将依赖项中的每一个挨个和上一次渲染时传递的依赖项进行全等比较,如果都没有发生变化,直接将存储的缓存值进行返回,否则重新计算。
那我们再看看顺便看看useCallback的实现
function updateCallback(callback, deps) {// ...const nextDeps = deps === undefined ? null : deps;const prevState = hook.memoizedState;// 对于数组中的每一项全等比较const prevDeps: Array<mixed> | null = prevState[1];if (areHookInputsEqual(nextDeps, prevDeps)) {return prevState[0];}// 直接返回callbackhook.memoizedState = [callback, nextDeps];return callback;
}
可以看出,两者唯一的区别在于一个存储函数的本身(useCallback) 一个存储函数返回的值(useMemo)
从实现上我们其实能看出useCallback中不包含任何运算逻辑,因此使用场景要比useMemo更少,只适用于第二种场景,即防止子组件的缓存击穿,通过将父组件中声明的回调函数进行缓存来保持子组件props的不变。
const Comp = () => {// ...// 通过缓存这个值来避免子组件memo失效const handleClick = useCallback(() => {}, []);return (// ...<Child onClick={handleClick} />);
}
总结和建议
回顾
先简单回顾一下整体的更新逻辑:当用户触发更新操作时,
-
React会首先尝试应用默认的性能优化策略尝试对组件进行
bailout,这一阶段我们在编码过程中可以尽可能的应用状态下放和内容提升满足默认性能优化策略条件提高bailout命中率 -
默认
bailout不满足时,我们也可以使用像PureComponentShouldComponentUpdateReact.memo来降低匹配条件,再次进行bailout -
当必不可少的需要重新渲染时,我们可以使用
useMemouseCallback来减少渲染的时间
当全部渲染完成后,实际上就构建好了一颗新的UI Tree,React会去对比新旧两颗Tree来找出需要对哪些dom结点进行何种操作,这个过程也被称为reconcile,大家比较熟悉的diff算法就是发生在这里,但是作为开发者这一做的事情很有限,我们唯一可以做的事是在通过循环添加组件时,注意为组件添加有效的key,来让React进行diff的时候少做一些比较,减少不必要的dom操作。
建议
了解这些性能优化的手段后,迫不及待在自己的组件中整改一顿?这边的建议是注意不要过度优化
为什么这么说呢
-
一方面我们能够发现
useMemo和useCallback本身也不是免费的,需要开辟空间去存储依赖并且每次都要去比较 -
另外,从实际的开发体验上,在组件中大量使用
useMemo和useCallback,会导致代码比较臃肿可读性变差,对开发者心智要求比较高,维护依赖项
我们要知道React本身的性能优化已经做的很好了,正确的逻辑应该是当实际性能问题发生时,我们需要去定位发生问题的组件,再应用上文提到的性能优化方法进行优化。
最后出现性能问题时的组件定位,这边推荐一下React Profiler,相关文档比较清楚这边不再赘述,简单分享些小tip,可以勾一下这两选项,可以方便的看到组件重新渲染的原因和操作时发生重新渲染的组件

以上就是本次分享的全部内容,读者如果觉得有帮助可以顺手点个赞,觉得哪里有不理解的也可以评论区留言讨论:)
最后
最近还整理一份JavaScript与ES的笔记,一共25个重要的知识点,对每个知识点都进行了讲解和分析。能帮你快速掌握JavaScript与ES的相关知识,提升工作效率。



有需要的小伙伴,可以点击下方卡片领取,无偿分享