这些是之前的文章,里面有一些基础的知识点在前面由于前面已经有写过,所以这一篇就不再详细对之前的内容进行描述
Python自动化测试实战篇(1)读取xlsx中账户密码,unittest框架实现通过requests接口post登录网站请求,JSON判断登录是否成功
Python自动化测试实战篇(2)unittest实现批量接口测试,并用HTMLTestRunner输出测试报告
Python自动化测试实战篇(3)优化unittest批量自动化接口测试代码,ddt驱动+yaml实现用例调用,输出HTMLTestRunner测试报告
Python自动化测试实战篇(4)selenium+unttest+ddt实现自动化用例测试,模拟用户登陆点击交互测试,Assert捕获断言多种断言
Python自动化测试实战篇(5)优化selenium+unittest+ddt,搞定100条测试用例只执行前50条
- 1.准备数据
- 2.写代码
- 1.导入包
- 2.导入文件地址
- 3.定义一个函数用于调用和传参
- 4.输出用例测试报告
- 5.完整代码
一开始我想控制限制需要多少条用例执行多少条的方法有两种,一种就是在yaml或csv中写入多少条用例,这样就可以控制我有多少条用例去执行,不过这种操作也是不太行就是无法控制用例在执行100条中前50条这样。
于是我想到第二种方法就是在unttest中用suit.addTests中控制执行第多少条用例,只要把名字输进去就行,然后就可以控制指定第几条跑到第几条
但是这个方法还是有不足之处就是用例一旦多起来就无法再去控制用例在执行100条中前50条这样,那样就要写一堆进去,非常复杂和浪费时间

我后面又想到了一个方法就是用for循环来写和执行,那么这样就可以了,可是一开始执行时我就遇到一个麻烦,我无法从已经写好的用例中用for循环遍历获取值。查询了unttest的文档和搜索问题后发现discover这个方法
Unittest支持简单的Test Discovery。为了与Test Discovery兼容,所有的测试文件都必须是从项目的顶级目录中导入的模块或包(这意味着它们的文件名必须是有效的标识符)。Test Discovery是在testloader.discover()中实现的,但是也可以从命令行中使用
python -m unittest discover
这个命令可以直接执行文件夹中所有的用例,只要是之前生成过的 HTMLTestRunner输出过得用例

也可以指定py文件类型的测试用例进行测试
python -m unittest discover D:\pythonpj\pytest “test_2.py”
语法是python -m unittest discover 要查找用例的目录 “用例名称”
这样就行了,但是这个方法有个坏处就是无法识别需要导入其他包的方法,比如用了yaml包和xlrd这种就会出现错误代码
所以这个方法也可以用在我们的代码中,我可以用这个方法去遍历里面的用例这样我就可以做到100条用例只执行前50条的操作。
1.准备数据
沿用前面的数据用复制粘贴,yaml搞到100条用例
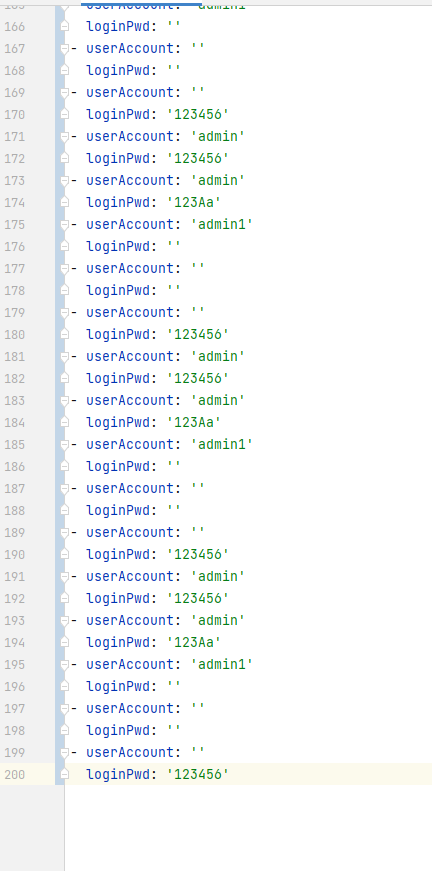
生成之后需要再生成一个100条的用例,yaml数据准备好后,生成用例代码沿用之前文章的代码直接生成就可以
Python自动化测试实战篇(3)优化unittest批量自动化接口测试代码,ddt驱动+yaml实现用例调用,输出HTMLTestRunner测试报告
2.写代码
1.导入包
import unittest
from HTMLTestRunner3_New import HTMLTestRunner
2.导入文件地址
report是输出html报告的地址
path是你自己执行文件.py所在的地址
report = r'D:\pythonpj\pytest\2023-02-18-30-32测试报告.html'
path = 'D:\pythonpj\pytest'
3.定义一个函数用于调用和传参
def kc_runner(n):
使用unittest的搜索本地执行文件的语法,start_dir就是初始地址就是文件所在目录地址
kcunt = unittest.defaultTestLoader.discover(start_dir=path,pattern='g2.py')
pattern就是执行文件这里执行文件可以是多个,如果你你想要同个目录下多个名字的g开头的执行文件就可以用g*.py开头,或者*g.py都可以

加载用例
suit = unittest.TestSuite()
写入文件
f = open(report,'wb')
输出HTMLTESTRunner的用例报告
run = HTMLTestRunner(stream=f,title='测试用例',description='执行情况如下',tester='yourname')
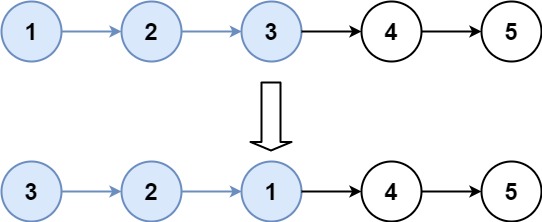
创建一个for循环将遍历好的值放入
t1=[]
t2=[]
for i in kcunt:
for j in i:
for l in j:
t1.append(l)
添加用例判断,如果用例在传入值的范围内就执行不然就不执行
if len(t1)<=n:
suit.addTests(t1)
run.run(suit)
else:
for a in range(n):
t2.append(t1[a])
suit.addTests(t2)
run.run(suit)
最后写一个主函数
if __name__ == '__main__':
kc_runner(50)
4.输出用例测试报告
可以看到目前已经执行了50条用例,我有100条用例,那么就跟我的需求是一致,如果多个测试用例存在的情况下也是50条,不过会分开执行,这个分出多少就看用例内有多少条,少的话就是全部执行,然后再另一个多的按你给的测试条数进行执行。一样的话应该就是平均分配
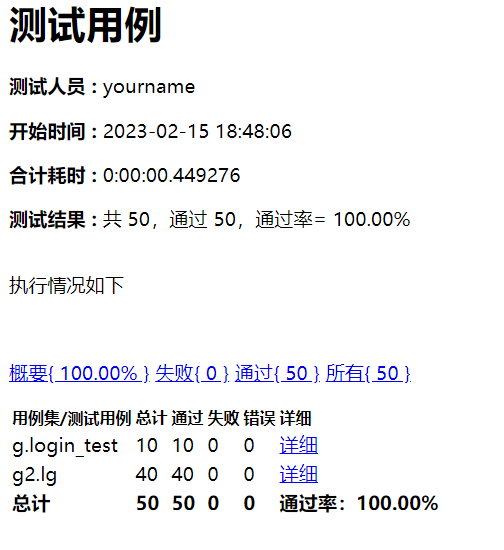
5.完整代码
import unittest
from HTMLTestRunner3_New import HTMLTestRunner
report = r'D:\pythonpj\pytest\2023-02-18-30-32测试报告.html'
path = 'D:\pythonpj\pytest'
def kc_runner(n):
kcunt = unittest.defaultTestLoader.discover(start_dir=path,pattern='g*.py')
suit = unittest.TestSuite()
f = open(report,'wb')
run = HTMLTestRunner(stream=f,title='测试用例',description='执行情况如下',tester='yourname')
t1=[]
t2=[]
for i in kcunt:
for j in i:
for l in j:
t1.append(l)
if len(t1)<=n:
suit.addTests(t1)
run.run(suit)
else:
for a in range(n):
t2.append(t1[a])
suit.addTests(t2)
run.run(suit)
if __name__ == '__main__':
kc_runner(50)