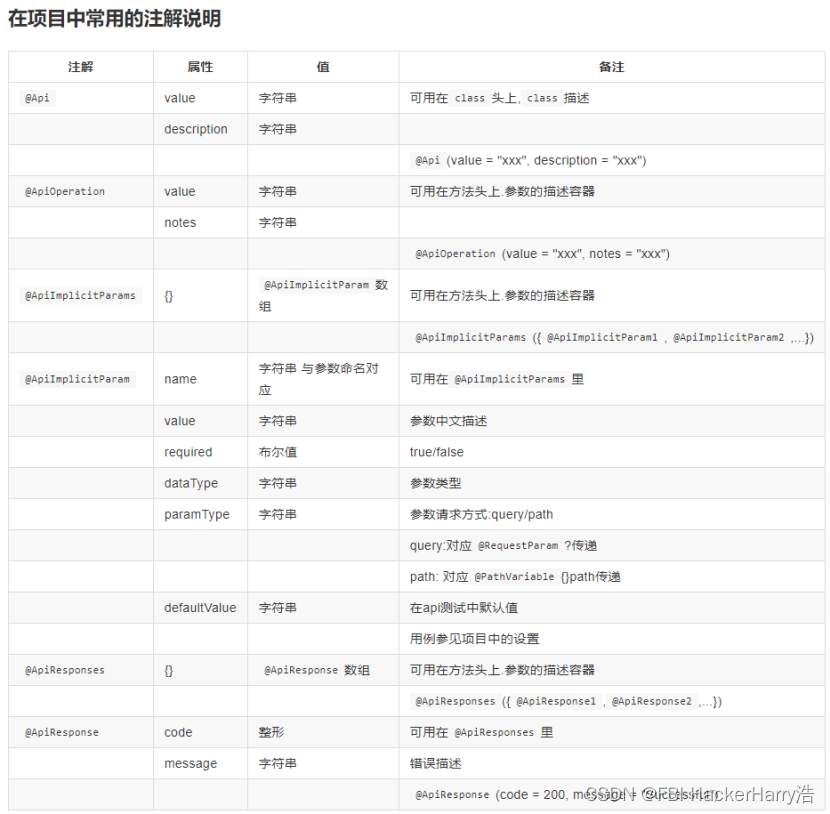
分类与性能

| 排序方法 | 平均情况 | 最好情况 | 最坏情况 | 辅助空间 | 稳定性 |
|---|
| 冒泡排序 | O(N^2) | O(N) | O(N^2) | O(1) | 稳定 |
| 简单选择排序 | O(N^2) | O(N^2) | O(N^2) | O(1) | 不稳定 |
| 直接插入排序 | O(N^2) | O(N) | O(N^2) | O(1) | 稳定 |
| 希尔排序 | O(N*logN) ~ O(N^2) | O(N^1.3) | O(N^2) | O(1) | 不稳定 |
| 堆排序 | O(N*logN) | O(N*logN) | O(N*logN) | O(1) | 不稳定 |
| 归并排序 | O(N*logN) | O(N*logN) | O(N*logN) | O(N) | 稳定 |
| 快速排序 | O(N*logN) | O(N*logN) | O(N^2) | O(logN) ~ O(N) | 不稳定 |
代码实现
栈实现
Stack.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
typedef int STDatatype;
typedef struct Stack {
STDatatype* arr;
int capacity;
int top;
}ST;
void StackInit(ST* ps);
void StackDestroy(ST* ps);
void StackPush(ST* ps,STDatatype x);
void StackPop(ST* ps);
bool StackEmpty(ST* ps);
int StackSize(ST* ps);
STDatatype StackTop(ST* ps);
Stack.c
#include"Stack.h"
void StackInit(ST* ps) {
assert(ps);
ps->arr = (STDatatype*)malloc(sizeof(STDatatype) * 4);
if (ps->arr == NULL) {
perror("malloc failed");
exit(-1);
}
ps->top = 0;
ps->capacity = 4;
}
void StackDestroy(ST* ps) {
assert(ps);
free(ps->arr);
ps->arr = NULL;
ps->top = ps->capacity = 0;
}
void StackPush(ST* ps, STDatatype x) {
assert(ps);
if (ps->top == ps->capacity) {
STDatatype* tmp = (STDatatype*)realloc(ps->arr, sizeof(STDatatype) * ps->capacity * 2);
if (tmp == NULL) {
perror("realloc failed");
exit(-1);
}
ps->arr = tmp;
ps->capacity *= 2;
}
ps->arr[ps->top] = x;
ps->top++;
}
bool StackEmpty(ST* ps) {
assert(ps);
return ps->top == 0;
}
void StackPop(ST* ps) {
assert(ps);
assert(!StackEmpty(ps));
ps->top--;
}
STDatatype StackTop(ST* ps) {
assert(ps);
assert(!StackEmpty(ps));
return ps->arr[ps->top - 1];
}
int StackSize(ST* ps) {
assert(ps);
return ps->top;
}
排序算法实现
Sort.h
#pragma once
#include<stdio.h>
void PrintArray(int* a, int n);
void InsertSort(int* a, int n);
void ShellSort(int* a, int n);
void SelectSort(int* a, int n);
void HeapSort(int* a, int n);
void BubbleSort(int* a, int n);
void QuickSort(int* a, int begin, int end);
int PartSort1(int* a, int begin, int end);
int PartSort2(int* a, int begin, int end);
int PartSort3(int* a, int begin, int end);
void QuickSortNonR(int* a, int begin, int end);
void MergeSort(int* a, int n);
void MergeSortNonR(int* a, int n);
Sort.c
#include"Sort.h"
#include"Stack.h"
void PrintArray(int* a, int n) {
for (int i = 0; i < n; i++) {
printf("%d ", a[i]);
}
printf("\n");
}
void Swap(int* p1, int* p2) {
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void AdjustDown(int* a, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n) {
if (child + 1 < n && a[child + 1] > a[child]) {
++child;
}
if (a[child] > a[parent]) {
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else {
break;
}
}
}
int GetMidIndex(int* a, int begin, int end) {
int mid = (begin + end) / 2;
if (a[begin] < a[mid]) {
if (a[mid] < a[end]) {
return mid;
}
else if (a[begin] > a[end]) {
return begin;
}
else {
return end;
}
}
else {
if (a[mid] > a[end]) {
return mid;
}
else if (a[begin] < a[end]) {
return begin;
}
else {
return end;
}
}
}
void InsertSort(int* a, int n) {
for (int i = 0; i < n-1; i++) {
int end = i;
int tmp = a[end + 1];
while (end >= 0) {
if (tmp < a[end]) {
a[end + 1] = a[end];
end--;
}
else {
break;
}
}
a[end + 1] = tmp;
}
}
void ShellSort(int* a, int n) {
int gap = n;
while (gap > 1){
gap = gap / 3 + 1;
for (int i = 0; i < n - gap; i++) {
int end = i;
int tmp = a[end + gap];
while (end >= 0) {
if (tmp < a[end]) {
a[end + gap] = a[end];
end -= gap;
}
else {
break;
}
}
a[end + gap] = tmp;
}
PrintArray(a, n);
}
}
void SelectSort(int* a, int n) {
int begin = 0, end = n - 1;
while (begin<end){
int mini = begin, maxi = begin;
for (int i = begin + 1; i <= end; i++) {
if (a[i] < a[mini]) {
mini = i;
}
if (a[i] > a[maxi]) {
maxi = i;
}
}
Swap(&a[begin], &a[mini]);
if (maxi == begin) {
maxi = mini;
}
Swap(&a[end], &a[maxi]);
begin++;
end--;
}
}
void HeapSort(int* a, int n){
for (int i = (n - 1 - 1) / 2; i >= 0; --i){
AdjustDown(a, n, i);
}
int end = n - 1;
while (end > 0){
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
--end;
}
}
void BubbleSort(int* a, int n) {
for (int j = 0; j < n; j++) {
int exchange = 0;
for (int i = 1; i < n - j; i++) {
if (a[i - 1] > a[i]) {
Swap(&a[i - 1], &a[i]);
exchange = 1;
}
if (exchange == 0) {
break;
}
}
}
}
int PartSort1(int* a, int begin, int end) {
int mid = GetMidIndex(a, begin, end);
Swap(&a[begin], &a[mid]);
int left = begin, right = end;
int keyi = left;
while (left < right) {
while (left < right && a[right] >= a[keyi]) {
right--;
}
while (left < right && a[left] <= a[keyi]) {
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[left], &a[keyi]);
keyi = left;
return keyi;
}
int PartSort2(int* a, int begin, int end) {
int mid = GetMidIndex(a, begin, end);
Swap(&a[begin], &a[mid]);
int left = begin, right = end;
int key = a[left];
int hole = left;
while (left < right) {
while (left < right && a[right] >= key) {
right--;
}
a[hole] = a[right];
hole = right;
while (left < right && a[left] <= key){
left++;
}
a[hole] = a[left];
hole = left;
}
a[hole] = key;
return hole;
}
int PartSort3(int* a, int begin, int end){
int mid = GetMidIndex(a, begin, end);
Swap(&a[begin], &a[mid]);
int keyi = begin;
int prev = begin, cur = begin + 1;
while (cur <= end){
if (a[cur] < a[keyi] && ++prev != cur)
Swap(&a[prev], &a[cur]);
cur++;
}
Swap(&a[prev], &a[keyi]);
keyi = prev;
return keyi;
}
void QuickSort(int* a, int begin, int end) {
if (begin >= end) {
return;
}
if ((end - begin + 1) < 15) {
InsertSort(a + begin, end - begin + 1);
}
else {
int keyi = PartSort3(a, begin, end);
QuickSort(a, begin, keyi - 1);
QuickSort(a, keyi + 1, end);
}
}
void QuickSortNonR(int* a, int begin, int end){
ST st;
StackInit(&st);
StackPush(&st, begin);
StackPush(&st, end);
while (!StackEmpty(&st)){
int right = StackTop(&st);
StackPop(&st);
int left = StackTop(&st);
StackPop(&st);
int keyi = PartSort3(a, left, right);
if (keyi + 1 < right){
StackPush(&st, keyi + 1);
StackPush(&st, right);
}
if (left < keyi - 1){
StackPush(&st, left);
StackPush(&st, keyi - 1);
}
}
StackDestroy(&st);
}
void _MergeSort(int* a, int begin, int end, int* tmp){
if (begin >= end)
return;
int mid = (begin + end) / 2;
_MergeSort(a, begin, mid, tmp);
_MergeSort(a, mid + 1, end, tmp);
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
int i = begin;
while (begin1 <= end1 && begin2 <= end2){
if (a[begin1] <= a[begin2]){
tmp[i++] = a[begin1++];
}
else{
tmp[i++] = a[begin2++];
}
}
while (begin1 <= end1){
tmp[i++] = a[begin1++];
}
while (begin2 <= end2){
tmp[i++] = a[begin2++];
}
memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1));
}
void MergeSort(int* a, int n) {
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL) {
perror("malloc failed");
exit(-1);
}
_MergeSort(a, 0, n - 1, tmp);
free(tmp);
tmp = NULL;
}
void MergeSortNonR(int* a, int n){
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL){
perror("malloc failed\n");
exit(-1);
}
int rangeN = 1;
while (rangeN < n){
for (int i = 0; i < n; i += 2 * rangeN){
int begin1 = i, end1 = i + rangeN - 1;
int begin2 = i + rangeN, end2 = i + 2 * rangeN - 1;
int j = i;
if (end1 >= n){
end1 = n - 1;
begin2 = n;
end2 = n - 1;
}
else if (begin2 >= n){
begin2 = n;
end2 = n - 1;
}
else if (end2 >= n){
end2 = n - 1;
}
while (begin1 <= end1 && begin2 <= end2){
if (a[begin1] <= a[begin2]){
tmp[j++] = a[begin1++];
}
else{
tmp[j++] = a[begin2++];
}
}
while (begin1 <= end1){
tmp[j++] = a[begin1++];
}
while (begin2 <= end2){
tmp[j++] = a[begin2++];
}
}
memcpy(a, tmp, sizeof(int) * (n));
rangeN *= 2;
}
free(tmp);
tmp = NULL;
}