vector是我接触的第一个容器,好好对待,好好珍惜!
目录
文章目录
前言
二、vector如何实现
二、vector的迭代器(原生指针)
三、vector的数据结构
图解:
四、vector的构造及内存管理
1.push_back()
代码如下:
2.pop_back()
代码如下:
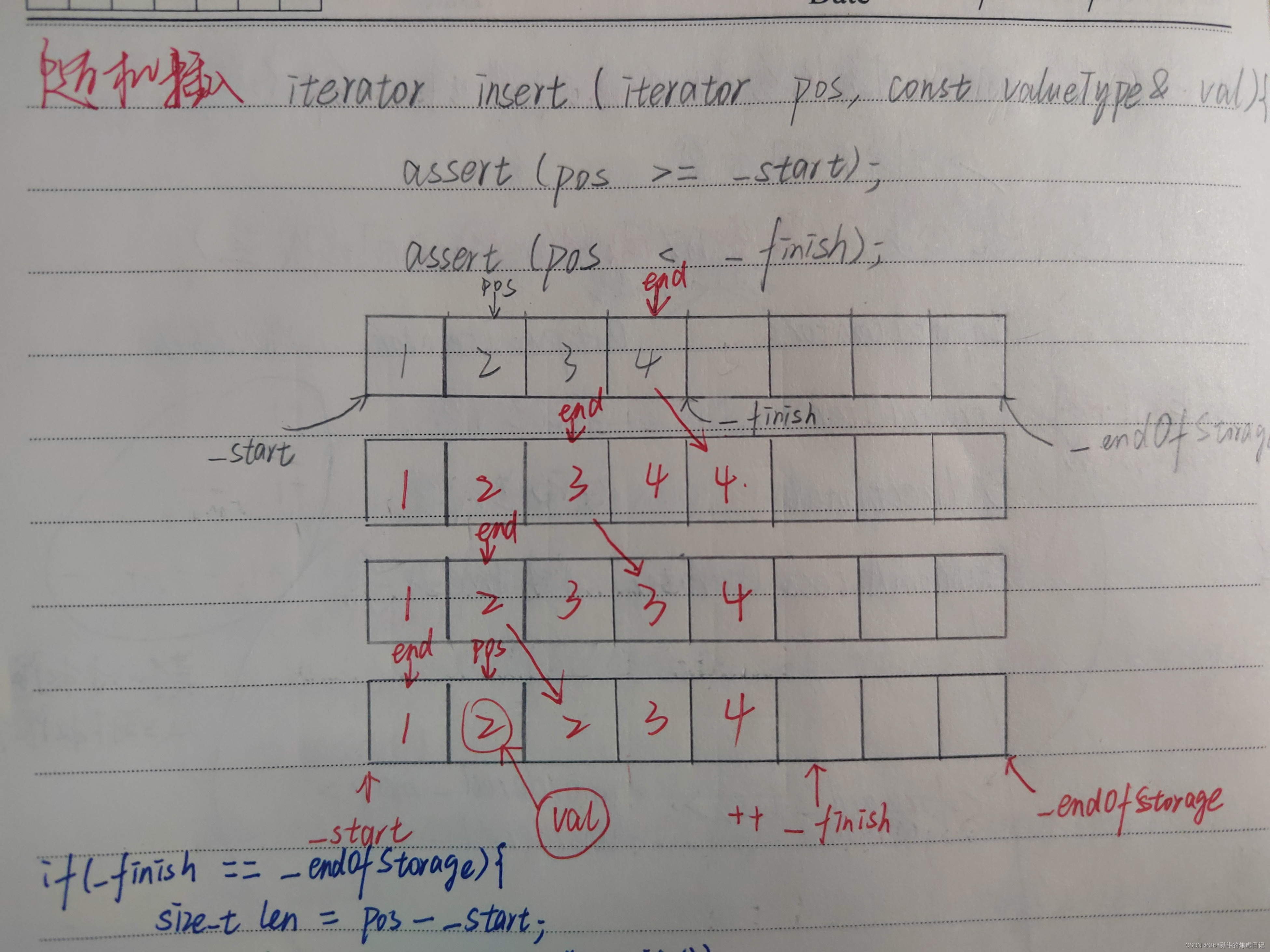
3.insert()
图解:
代码如下:
需要注意的是insert()迭代器失效问题:
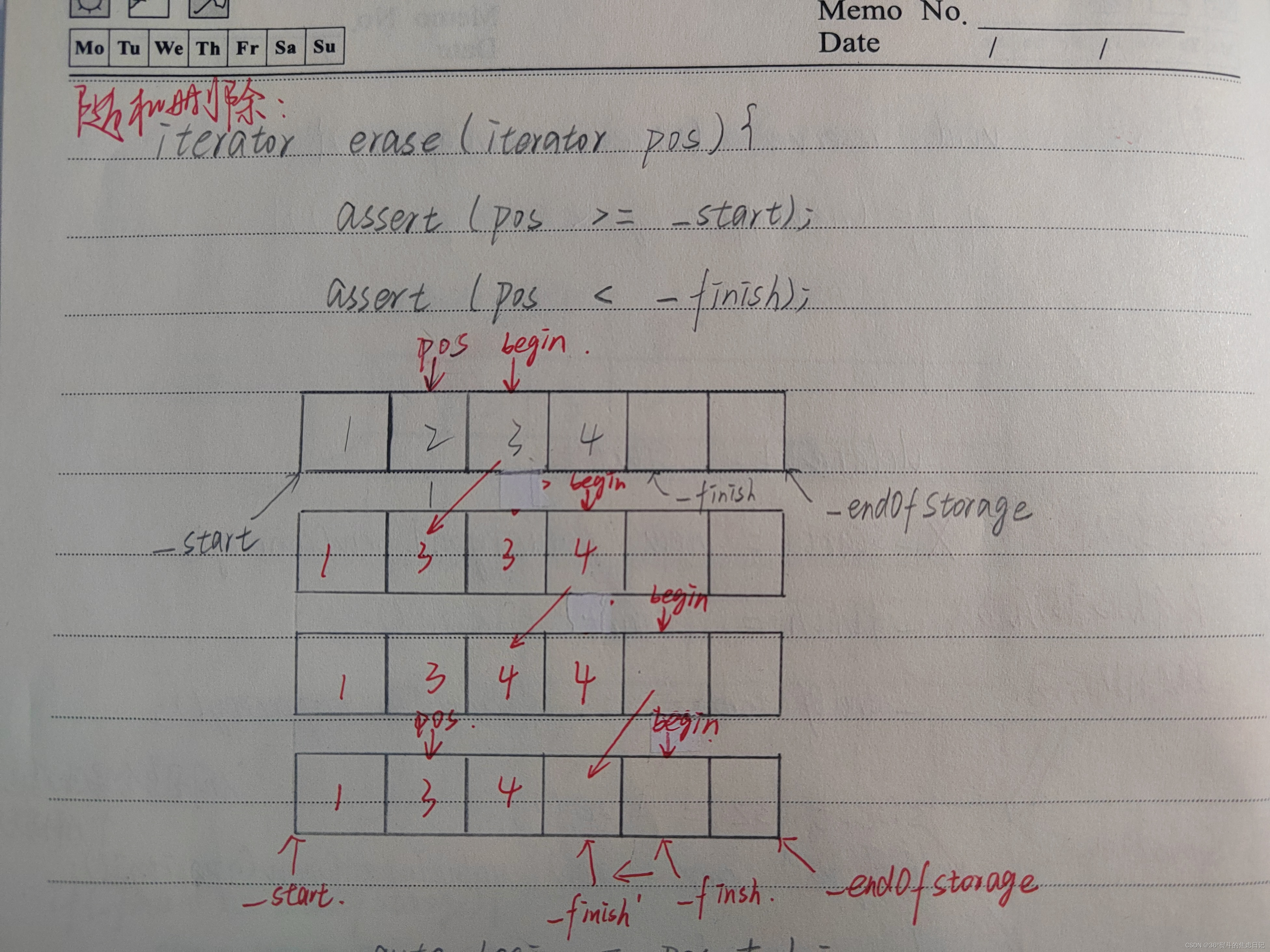
4.erase()
图解:
代码如下:
需要注意的是erase()的迭代器失效问题:
给出三种验证的例子:
图解:
五、vector的reserve与resize
1.reserve()
代码如下:
需要注意的是memcpy()的浅拷贝问题:
改进版:
代码如下:
2.resize()
代码如下:
六、vector类的基本成员函数
1.default构造
代码如下:
2.copy构造
1)传统写法
代码如下:
需要注意的仍然是memcpy()的浅拷贝:
改进版:
2)现代写法
代码如下:
3.用迭代器区间的copy构造函数
4.析构
代码如下:
七、其他的一些函数
1.获取size
代码如下:
2.获取capacity
代码如下:
3.访问元素
代码如下:
4.迭代器 -> 使用范围for
代码如下:
5.赋值重载
1)传统写法
需要注意的仍然是memcpy()的浅拷贝:
改进版:
2)现代写法
代码如下:
6.swap()
代码如下:
总结
前言
vector实现时最难想的是赋值重载时的现代写法,很妙,最有趣的是两种迭代器的失效问题。与数组相同,但又多少有点不同。
一、vector是什么?
vector是一个序列式容器(其中的元素都可序(ordered),但是未必有序(sorted)),本质上是可变数组,尾插尾删效率较高。

二、vector如何实现
源代码中vector的实现使用到了alloc(空间配置器),但是鉴于自身技术水平,个人只在本文中阐述如何实现无alloc版本的vector。
二、vector的迭代器(原生指针)
因为vector是一段连续的物理存储空间,实现增删查改时,需要对位置进行++、--、+、-、+=、-=、->,这些都是普通指针就具备的能力,所以vector提供的是Random Access Iterators。
代码如下(示例):
template<typename T>
class vector
{
public:
typedef T valueType;
typedef T* iterator;
private:
iterator _start;
iterator _finish;
iterator _endOfStorage;
}三、vector的数据结构
vector是一段连续的物理空间,其中SGI版本使用了三个指针去管理这个变长数组、使用了两个unsigned int变量去标识有效字符与容量。
图解:

四、vector的构造及内存管理
与之前学习数据结构实现的动态顺序表内存管理其实大同小异:一开始有一块默认大小的内存;
增:
①内存不够再存新元素:扩容,一般扩至原capacity的2倍;
②内存够:直接存。
删:
①减少元素个数但是不缩容(大部分版本)。
1.push_back()
代码如下:
void push_back(const valueType& x)
{
// 增容
if (_finish == _endOfStorage)
{
reserve((capacity() == 0) ? 4 : capacity() * 2);
}
// 尾插
*_finish = x;
++_finish;
}2.pop_back()
代码如下:
// 尾删
void pop_back()
{
assert(_finish > _start);
--_finish;
}3.insert()
原stl给出的模板中,insert()是返回了一个迭代器,指向插入元素的位置。
目的:若迭代器已经失效,尽管在增容操作中更新迭代器的值进行规避风险,但是调用时的迭代器仍为野指针(失效状态),若后续操作需要使用插入元素位置,那就会在此出现问题,所以可以再用这个迭代器接受insert()的返回值来进行更新。
图解:
代码如下:
// 随机插入
iterator insert(iterator pos, const valueType& val)
{
// 最小在头插,最大在尾插
assert(pos >= _start);
assert(pos < _finish);
//增容,会使迭代器失效
if (_finish == _endOfStorage)
{
// 更新迭代器的值
size_t len = pos - _start;
reserve((capacity() == 0) ? 4 : capacity() * 2);
pos = _start + len;
}
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
--end;
}
*pos = val;
// 元素个数+1,_finish+1
++_finish;
return pos;
}需要注意的是insert()迭代器失效问题:
当插入时,vector进行了扩容操作,这一步会:
①使用一块新的、够大的tmp空间去拷贝原来_start指向的数据
②将原来的_start指向的空间释放
③把tmp的空间给_start
但是此时,传进来的、想要插入数据的迭代器仍然指向原来的_start空间,这个迭代器就变成了野指针,再下一步对这个迭代器指向位置进行操作时就会非法访问,所以需要在进行扩容操作是对于迭代器也进行相应的更新,尽量避免失效问题。
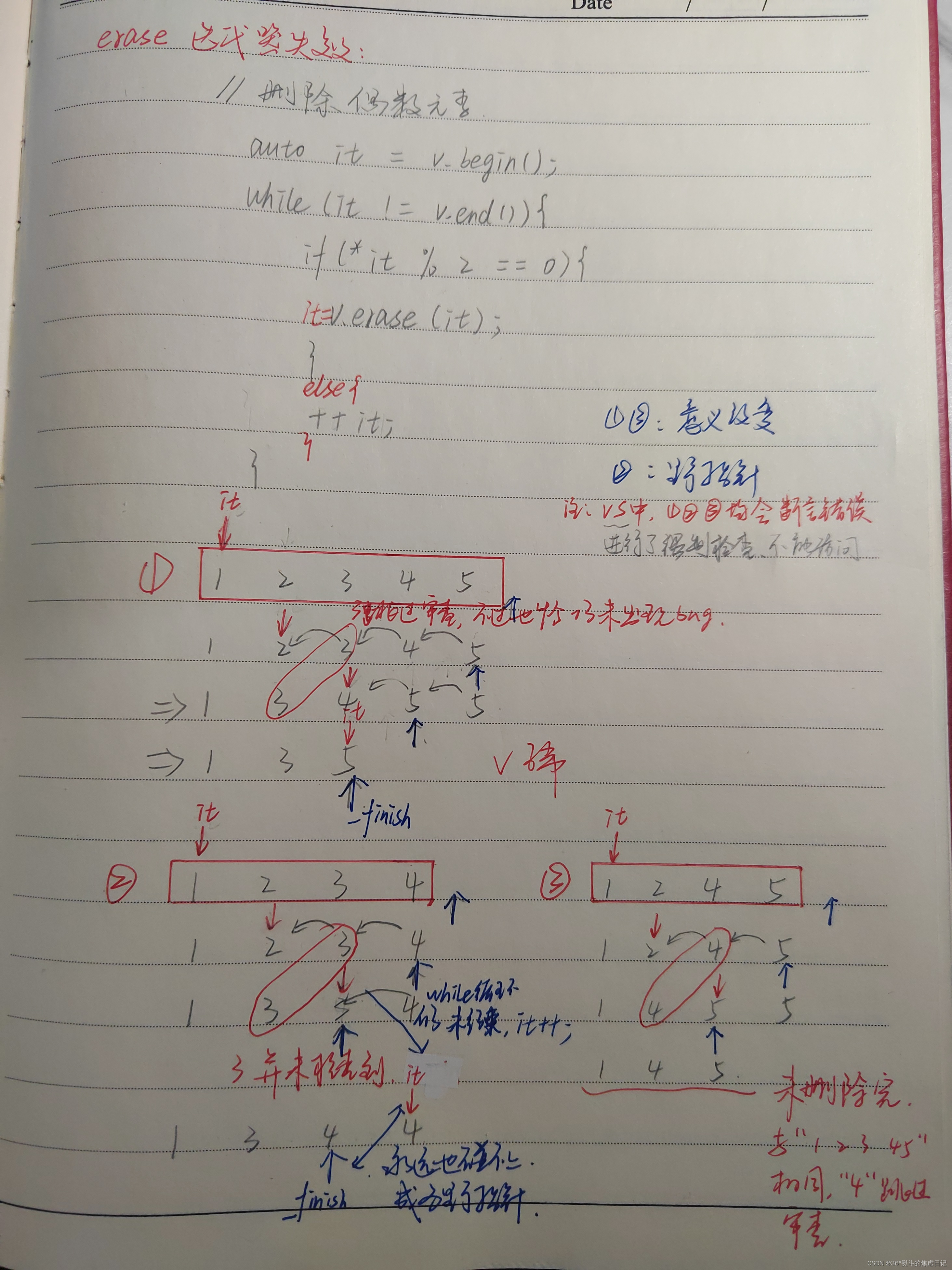
4.erase()
原stl给出的模板中,erase()是返回了一个迭代器,指向删除元素的位置的下一个位置。
目的:同insert()相同。
Q:为什么指向的是操作位置的下一个位置?
A:因为删除操作本质上是对数据的覆盖,这样一来,从操作位置开始向后的数据向前挪动也相当于操作位置向后移动了一位(指向了下一个位置)。
图解:
代码如下:
// 随机删除
iterator erase(iterator pos)
{
// 最小头删,最大尾删
assert(pos >= _start);
assert(pos < _finish);
auto begin = pos + 1;
while (begin != _finish)
{
*begin = *(begin + 1);
++begin;
}
// 删除一个元素,_finish向前移动
--_finish;
// 返回的是删除元素的下一个元素
return pos;
}需要注意的是erase()的迭代器失效问题:
erase()的迭代器失效主要是因为迭代器的意义改变,当然,也有野指针的问题。
ps:但是这个无法通过我们改变erase()实现去规避。
①意义改变:当数据向前挪动时,这个迭代器已经不再是我们想要的迭代器了,他一次性向后跳了两个位置。
②野指针:当数据向前挪动时,迭代器可能跳过了_finish(当第一次与_finish相遇时,begin++的操作还在继续进行),从而继续向后移动,宛如脱缰野马,永远不可能再停下(与_finish相遇才会结束)。
给出三种验证的例子:
均是删除给定数据中的偶数元素:
1 2 3 4 5 - > 迭代器意义改变,但是刚好这个bug没有使结果出现问题
1 2 3 4 - > 迭代器
1 2 4 5 - > 4被跳过(迭代器每次相当于向后移动2位),未删除
图解:
五、vector的reserve与resize
1.reserve()
改变的是容器的容量,需要进行开辟空间、释放空间、拷贝数据的操作,效率不是很高,也正因为扩容的效率不高,所以才有了_endofStorage和_finish去标识容量与元素个数。
代码如下:
void reserve(size_t newCapacity)
{
// 扩容
valueType* tmp = new valueType[newCapacity]();
size_t sz = size();
// 如果有数据,需拷贝到新空间
if (_start)
{
memcpy(tmp, _start, sizeof(valueType) * size());
}
// 释放旧空间
delete[] _start;
_start = tmp;
_finish = _start + sz;
_endOfStorage = _start + newCapacity;
}需要注意的是memcpy()的浅拷贝问题:
因为memcpy()进行的是位操作,如果copy的是内置类型(int、char等)那么直接使用memcpy()会效率很高很方便;但是牵扯到指针,这会导致内存错误:
当两个指针的内容相同,那就意味着它们指向了同一块空间,如果一个指针释放,另一个指针仍对其进行操作就会使得内存发生错误。
改进版:
使用for循环自己一个元素一个元素进行拷贝。
代码如下:
void reserve(size_t newCapacity)
{
// 扩容
valueType* tmp = new valueType[newCapacity]();
size_t sz = size();
// 如果有数据,需拷贝到新空间
if (_start)
{
//memcpy(tmp, _start, sizeof(valueType) * size());
for (size_t i = 0; i < sz; i++)
{
tmp[i] = _start[i];
}
}
// 释放旧空间
delete[] _start;
_start = tmp;
_finish = _start + sz;
_endOfStorage = _start + newCapacity;
}2.resize()
改变的是元素的个数(size)。
①如果newSize比size小,那么就发生了删除,直接改变_finish即可,但是不缩容(以防后续操作频繁删除增容、频繁向操作系统申请、释放内存造成抖动)。
②如果newSize比size大,那么就可能发生了扩容(需检查)。
1.若给出初始化的值,那么根据给出的值进行初始化
2.若无给出的值,默认是空,在模板中是const vaueType& val = valueType(),构造了空的对象进行缺省参数的赋值。
代码如下:
void resize(size_t newSize, const valueType& x = valueType())
{
// newSize比size短,截断
// 但是容量不变
if (_finish + newSize < _endOfStorage)
{
_finish = _start + newSize;
}
// 长,增长并初始化
else
{
reserve(newSize);
while (_finish != _start + newSize)
{
*_finish = x;
_finish++;
}
}
}六、vector类的基本成员函数
1.default构造
三个原生指针,初始化为空指针即可。
代码如下:
// 构造
vector()
:_start(nullptr)
, _finish(nullptr)
, _endOfStorage(nullptr)
{}2.copy构造
1)传统写法
传统写法就是自己一步一步实现深拷贝的过程。
代码如下:
// copy构造
// 传统写法
vector(const vector<valueType>& obj)
{
_start = new valueType[obj.size()];
_finish = _start + obj.size();
_endOfStorage = _start + obj.capacity();
memcpy(_start, obj._start, obj.size() * sizeof(valueType));
}需要注意的仍然是memcpy()的浅拷贝:
我们应该使用for循环去自己实现深拷贝避免内存问题。
改进版:
// 传统写法
vector(const vector<valueType>& obj)
{
_start = new valueType[obj.size()];
_finish = _start + obj.size();
_endOfStorage = _start + obj.capacity();
//memcpy(_start, obj._start, obj.size() * sizeof(valueType));
for (size_t i = 0; i < size(); i++)
{
_start[i] = obj._start[i];
}
}2)现代写法
使用tmp变量,让其使用构造函数构造出我们想要copy的对象,然后将tmp和我们将要copy的对象进行交换,从而帮助我们实现copy构造。
swap(tmp, *this)这一点就是将*this中的垃圾扔给了tmp,tmp还把自己有用的数据全部交给了*this,就好比是外卖员替你送了外卖还得帮你扔垃圾。
但是很明显的是:已有的构造函数并不能根据传进来的obj对tmp进行构造。我们需要重载实现一个支持用迭代器区间的copy构造函数(stl本来也支持这样的方式构造)。(见下一点)
ps:copy构造也是构造,别忘了初始化!
代码如下:
// 现代写法
//类模板的成员函数也可以变成函数模板
vector(const vector<valueType>& obj)
:_start(nullptr)
,_finish(nullptr)
,_endOfStorage(nullptr)
{
vector<valueType> tmp(obj.begin(), obj.end());
// “外卖员送饭又倒垃圾的例子”
swap(tmp);
}3.用迭代器区间的copy构造函数
我们实现为了模板函数,这一点是在套娃:
本来就是类模板的成员函数,其可以用函数模板去实现。
目的:
其他的迭代器(string、int、char等)都可以通过迭代器去构造。
// 迭代器版的copy构造
template <class InputIterator>
vector(InputIterator first, InputIterator last)
:_start(nullptr)
, _finish(nullptr)
, _endOfStorage(nullptr)
{
while (first != last)
{
this->push_back(*first);
first++;
}
}4.析构
析构是释放空间,因为三个指针指向的是同一段空间,所以只需要释放_start。
然后将它们置为空。
ps:new时候使用的[],所以delete也需要[]进行释放。
代码如下:
// 析构
~vector()
{
delete[] _start;
_start = _finish = _endOfStorage = nullptr;
}七、其他的一些函数
1.获取size
回想我们之前的结构:
size就是_finish与_start之间的距离,使用两个指针相减即可得到。
代码如下:
size_t size() const
{
return _finish - _start;
}2.获取capacity
同size()。
代码如下:
size_t capacity() const
{
return _endOfStorage - _start;
}ps:但是需要注意的是这两个成员函数最好实现为const成员函数,因为在copy构造与的default构造时传的参数均使用了const。(常对象与非常对象都可以用const)
3.访问元素
数组可以通过下标访问。
代码如下:
const valueType& operator[](size_t i)
{
return _start[i];
}4.迭代器 -> 使用范围for
实现为const,原理同size()、capacity()。
代码如下:
// 迭代器
// 必须是begin与end(同名)才能使用范围for
iterator begin() const
{
return _start;
}
iterator end() const
{
return _finish;
}5.赋值重载
赋值重载与copy构造总是很相像:
①赋值重载是相对于两个已经存在的对象之间的操作。
②copy构造是相对于一个即将创建一个已经存在的对象之间的操作。
但是它们最终要达到的目标都是相同的:让两个对象相等。
所以在实现过程上也大同小异。
实现赋值重载需要注意的点是:
①判断是否给自己赋值
②需要传引用返回,减少拷贝
③传进来的函数参数需要是const的引用,防止修改+减少拷贝。
④返回值是*this
1)传统写法
与copy构造相同的是,它也要实现:释放旧空间、开辟新空间、拷贝数据。
// 传统写法
vector<valueType>& operator=(const vector<valueType>& obj)
{
// 判断是否给自己赋值
if (this == &obj)
{
return *this;
}
delete[] _start;
//_start = (valueType*)calloc(obj.capacity(), sizeof(valueType));
_start = new valueType[obj.capacity()];
_finish = _start + obj.size();
_endOfStorage = _start + obj.capacity();
memcpy(_start, obj._start, sizeof(obj) * obj.size());
return *this;
}需要注意的仍然是memcpy()的浅拷贝:
我们使用for循环自己进行深拷贝。
改进版:
// 传统写法
vector<valueType>& operator=(const vector<valueType>& obj)
{
// 判断是否给自己赋值
if (this == &obj)
{
return *this;
}
delete[] _start;
//_start = (valueType*)calloc(obj.capacity(), sizeof(valueType));
_start = new valueType[obj.capacity()];
_finish = _start + obj.size();
_endOfStorage = _start + obj.capacity();
//memcpy(_start, obj._start, sizeof(obj) * obj.size());
for (size_t i = 0; i < obj.size(); i++)
{
_start[i] = obj._start[i];
}
return *this;
}2)现代写法
这种写法很巧妙地使用了传值传参需要进行拷贝构造的特点,利用这一点在传参的时候就可以深拷贝出来一个obj,这样进行交换的时候就不会把原来的obj更改。
代码如下:
/ 赋值重载 v2 = v1
// 现代写法
vector<valueType>& operator=(vector<valueType> obj)
{
swap(obj);
return *this;
}6.swap()
由于copy构造与赋值重载都使用了交换,所以将它实现为了函数。
代码如下:
void swap(vector<valueType>& tmp)
{
std::swap(tmp._start, _start);
std::swap(tmp._finish, _finish);
std::swap(tmp._endOfStorage, _endOfStorage);
}总结
vector的实现是对于stl源码的一次深入理解,但是仍然没有学会alloc,只学习了一部分,自己模拟实现vector,不在于造一个更好的轮子,但是可以帮助我更好的了解它、使用它。