课程链接:深入浅出计算机组成原理_组成原理_计算机基础-极客时间
一、虚拟内存和内存保护
日常使用的操作系统下,程序不能直接访问物理内存。内存需要被分成固定大小的页(Page),再通过虚拟内存地址(Virtual Address)到物理内存地址(Physical Address)的地址转换(Address Translation),才能到达实际存放数据的物理内存位置。而程序看到的内存地址,都是虚拟内存地址。
(一)简单页表
想要把虚拟内存地址映射到物理内存地址,最直观的办法就是来建一张映射表。这个映射表,能够实现虚拟内存里面的页到物理内存里面的页的一 一映射。这个映射表,在计算机里面,就叫作页表(Page Table)。页表会把一个内存地址分成页号(Directory)和偏移量(Offset)两个部分。
做地址转换的页表,只需要保留虚拟内存地址的页号和物理内存地址的页号之间的映射关系就可以了。同一个页里面的内存,在物理层面是连续的。
对于一个内存地址转换,其实就是这样三个步骤:
- 把虚拟内存地址,切分成页号和偏移量的组合;
- 从页表里查询出虚拟页号对应的物理页号;
- 拿物理页号加上前面的偏移量,得到物理内存地址。
每一个进程,都有属于自己独立的虚拟内存地址空间,也就意味着,每一个进程都需要这样一个页表。
(二)多级页表
在整个进程的内存地址空间,通常是“两头实、中间空”。在程序运行的时候,内存地址从顶部往下,不断分配占用的栈的空间。而堆的空间,内存地址则是从底部往上,是不断分配占用的。
所以,在一个实际的程序进程里面,虚拟内存占用的地址空间,通常是两段连续的空间。而不是完全散落的随机的内存地址。而多级页表,就特别适合这样的内存地址分布。
以一个 4 级的多级页表为例,同样一个虚拟内存地址,偏移量的部分和简单页表一样不变,但是页号部分拆成四段,从高到低,分成 4 级到 1 级这样 4 个页表索引。
对应的,一个进程会有一个 4 级页表。 4 级页表里面存放的是每张 3 级页表所在的位置。3级表指向二级表,二级表指向一级表。

我们可能有很多张 1 级页表、2 级页表,乃至 3 级页表。但是,因为实际的虚拟内存空间通常是连续的,所以可能只需要很少的 2 级页表,甚至只需要 1 张 3 级页表就够了。
事实上,多级页表就像一个多叉树的数据结构,所以我们常常称它为页表树(Page Table Tree)。因为虚拟内存地址分布的连续性,树的第一层节点的指针,很多就是空的,也就不需要有对应的子树了。所谓不需要子树,其实就是不需要对应的 2 级、3 级的页表。找到最终的物理页号,就好像通过一个特定的访问路径,走到树最底层的叶子节点。
大部分进程所占用的内存是有限的,需要的页也自然是很有限的,只需要去存那些用到的页之间的映射关系就好了。
多级页表虽然节约了存储空间,却带来了时间上的开销,所以它其实是一个“以时间换空间”的策略。原本进行一次地址转换,只需要访问一次内存就能找到物理页号,算出物理内存地址。但是,用了 4 级页表,就需要访问 4 次内存,才能找到物理页号了。
二、解析TLB和内存保护
(一)加速地址转换:TLB
机器指令里面的内存地址都是虚拟内存地址。程序里面的每一个进程,都有一个属于自己的虚拟内存地址空间。可以通过地址转换来获得最终的实际物理地址。每一个指令和数据都存放在内存里面因此,“地址转换”是一个非常高频的动作,“地址转换”的性能至关重要。
从虚拟内存地址到物理内存地址的转换通过页表来处理。为了节约页表的内存存储空间,我们会使用多级页表数据结构。这就需要多次访问内存,然而,内存访问比 Cache 要慢很多,为了提高性能,可以采用加个"加个缓存"的方法。
程序使用的指令,存放和执行都是顺序进行的。也就是说,对于指令地址的访问,存在“空间局部性”和“时间局部性”,而需要访问的数据也是一样的。连续执行的几条指令通常存放在同一个"虚拟页"里,转换的结果自然也就是同一个物理页号。那就可以用“加个缓存”的办法把之前的内存转换地址缓存下来。这样就不用反复去访问内存来进行内存地址转换了。
于是,计算机工程师们专门在 CPU 里放了一块缓存芯片。这块缓存芯片我们称之为 TLB,全称是地址变换高速缓冲(Translation-Lookaside Buffer)。这块缓存存放了之前已经进行过地址转换的查询结果。这样,当同样的虚拟地址需要进行地址转换的时候,就可以直接在 TLB 里面查询结果了。
TLB 和我们前面讲的 CPU 的高速缓存类似,可以分成指令的 TLB 和数据的 TLB,也就是 ITLB 和 DTLB。同样的,也可以根据大小对它进行分级,变成 L1、L2 这样多层的 TLB。
除此之外,和 CPU 里的高速缓存一样,它也需要用脏标记这样的标记位,来实现“写回”缓存管理策略。
为了性能,整个内存转换过程都由硬件来执行。 CPU 芯片里封装了内存管理单元(MMU,Memory Management Unit)芯片,用来完成地址转换。和 TLB 的访问和交互,都是由这个 MMU 控制的。
(二)安全性与内存保护
指令、数据都存放在内存里,如果被人修改了内存里的内容, CPU 就可能会去执行计划之外的指令。这个指令可能是破坏服务器里面的数据,也可能是被人获取到服务器里面的敏感信息。
虽然现代的操作系统和 CPU已经做了各种权限的管控。正常情况下,已经通过虚拟内存地址和物理内存地址的区分,隔离了各个进程。但是难免还是存在一些漏洞。在对于内存的管理里面,计算机有一些最底层的安全保护机制。这些机制统称为内存保护(Memory Protection)。
内存层面的安全保护核心策略,是在可能有漏洞的情况下进行安全预防。
1、可执行空间保护
可执行空间保护(Executable Space Protection)是说,对于一个进程使用的内存,只把其中指令部分设置成“可执行”的,对于其他部分,比如数据部分,不给予“可执行”的权限。因为无论是指令,还是数据,在 CPU 看来,都是二进制的数据,直接把数据部分拿给 CPU,如果这些数据解码后,也能变成一条合理的指令,那也是可执行的。
对进程里内存空间的执行权限进行控制,可以使得 CPU 只能执行指令区域的代码。对于数据区域的内容,即使找到了其他漏洞想要加载成指令来执行,也会因为没有权限而被阻挡掉。
2、地址空间布局随机化
地址空间布局随机化(Address Space Layout Randomization)。原先一个进程的内存布局空间是固定的,所以第三方很容易知道指令在哪里,程序栈在哪里,数据在哪里,堆又在哪里。而地址空间布局随机化这个机制,就是让这些区域的位置不再固定,在内存空间随机去分配这些进程里不同部分所在的内存空间地址,让破坏者猜不出来。猜不出来呢,就没法找到想要修改的内容的位置。如果只是随便做点修改,程序只会 crash 掉,而不会去执行计划之外的代码。
三、总线
(一)总线的设计思路
计算机里其实有很多不同的硬件设备,除了 CPU 和内存之外,还有大量的输入输出设备。可以说,计算机上的每一个接口,键盘、鼠标、显示器、硬盘,乃至通过 USB 接口连接的各种外部设备,都对应了一个设备或者模块。
如果各个设备间的通信,都是单独进行的,每一个设备或者功能电路模块,都要和其他 N−1 个设备去通信,那么, N 个不同的设备,系统复杂度就会变成 ![]() 。总线是为了简化复杂度而引入的,它把
。总线是为了简化复杂度而引入的,它把 ![]() 的复杂度,变成了 N 。
的复杂度,变成了 N 。
对应的设计思路,在软件开发中也是非常常见的,譬如事件总线(Event Bus)的设计模式。
【延申阅读】设计模式:事件总线 - DZone
在事件总线这个设计模式里,各个模块触发对应的事件,并把事件对象发送到总线上。也就是说,每个模块都是一个发布者(Publisher)。而各个模块也会把自己注册到总线上,去监听总线上的事件,并根据事件的对象类型或者是对象内容,来决定自己是否要进行特定的处理或者响应。
这样的设计下,注册在总线上的各个模块就是松耦合的。模块互相之间并没有依赖关系。无论代码的维护,还是未来的扩展,都会很方便。
(二)三种线路和多总线架构
现代的 Intel CPU 的体系结构里面,通常有好几条总线。
首先,CPU 和内存以及高速缓存通信的总线,这里面通常有两种总线。这种方式,叫作双独立总线(Dual Independent Bus,缩写为 DIB)。CPU 里,有一个高速的本地总线(Local Bus),也叫后端总线(Back-side Bus),是用来和高速缓存通信的;还有一个速度相对较慢的前端总线(Front-side Bus),处理器总线(Processor Bus)、内存总线(Memory Bus),是用来和主内存以及输入输出设备通信的。
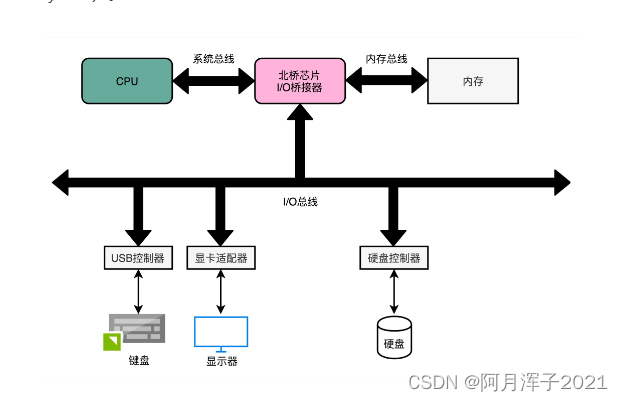
前端总线其实就是系统总线。CPU 里面的内存接口,直接和系统总线通信,然后系统总线再接入一个 I/O 桥接器(I/O Bridge)。 I/O 桥接器的另一边接入内存总线,使CPU 和内存通信。
在物理层面,其实完全可以把总线看作一组“电线”。这些电线之间是有分工的,通常有三类线路:
- 数据线(Data Bus),用来传输实际的数据信息。
- 地址线(Address Bus),用来确定到底把数据传输到哪里去,是内存的某个位置,还是某一个 I/O 设备。
- 控制线(Control Bus),用来控制对于总线的访问。
总线减少了设备之间的耦合,也降低了系统设计的复杂度,但同时也带来了一个新问题,那就是总线不能同时给多个设备提供通信功能。
课程链接:深入浅出计算机组成原理_组成原理_计算机基础-极客时间