学习自李宏毅老师的课https://www.youtube.com/watch?v=e0aKI2GGZNg
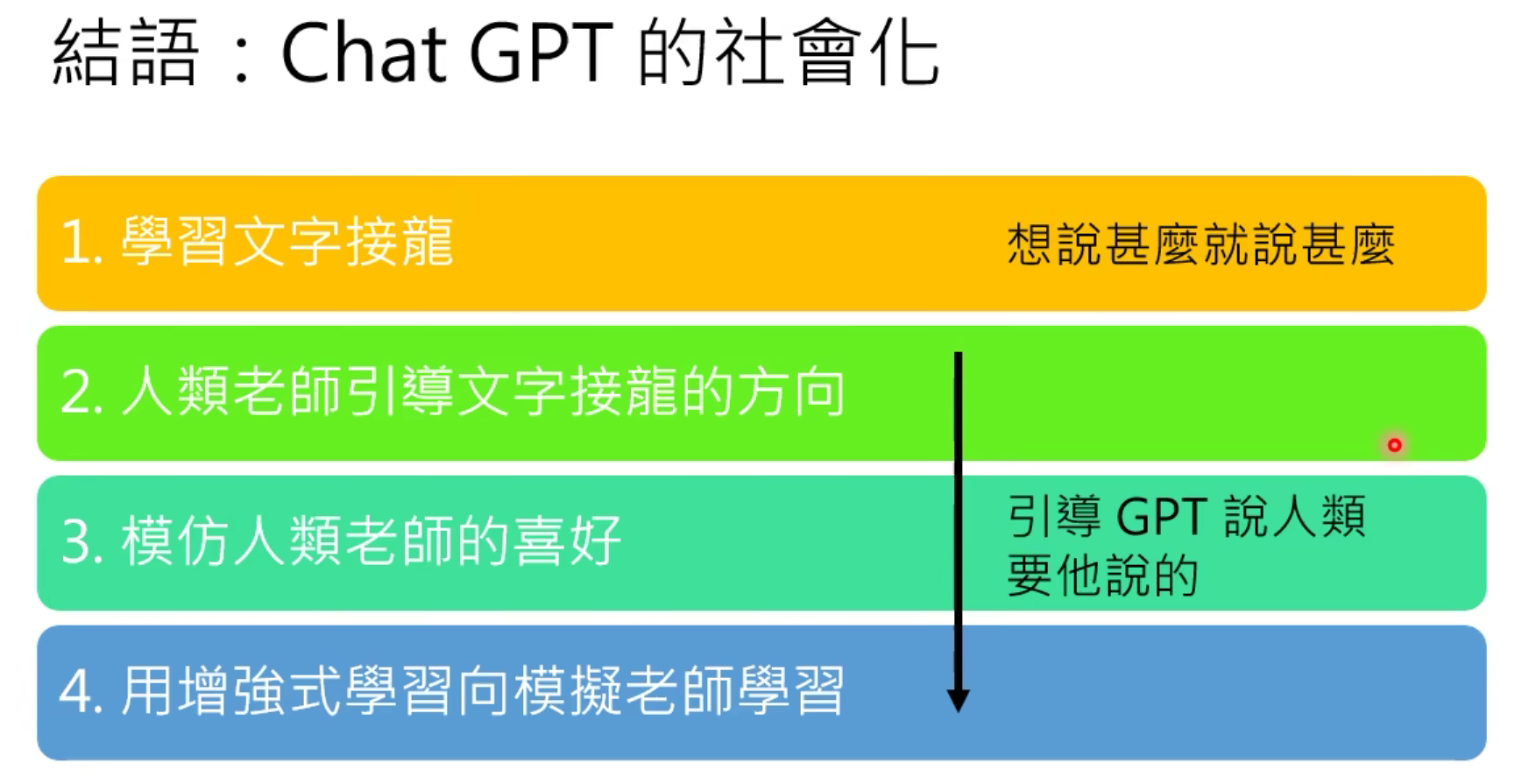
1.学习文字接龙
学习方式
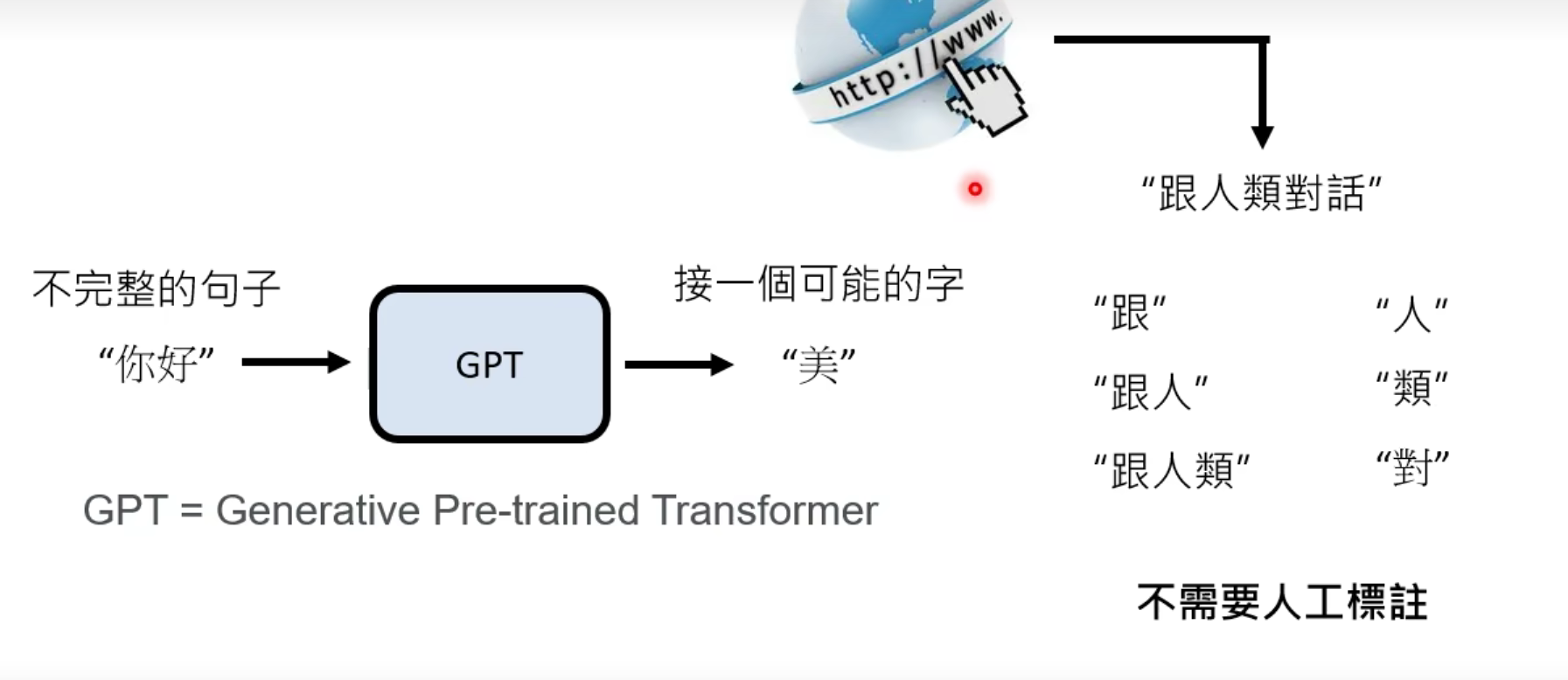
GPT只需要在网上阅读大量的句子,不需要人工标注即可学习到大量句子接龙的知识
然而实际上,“你好”后面可以接的字有很多。实际上,GPT学的就是一个“概率分布”。然后按照概率分布,选一个字出来。比如下图中,“美”的出现概率就很高。
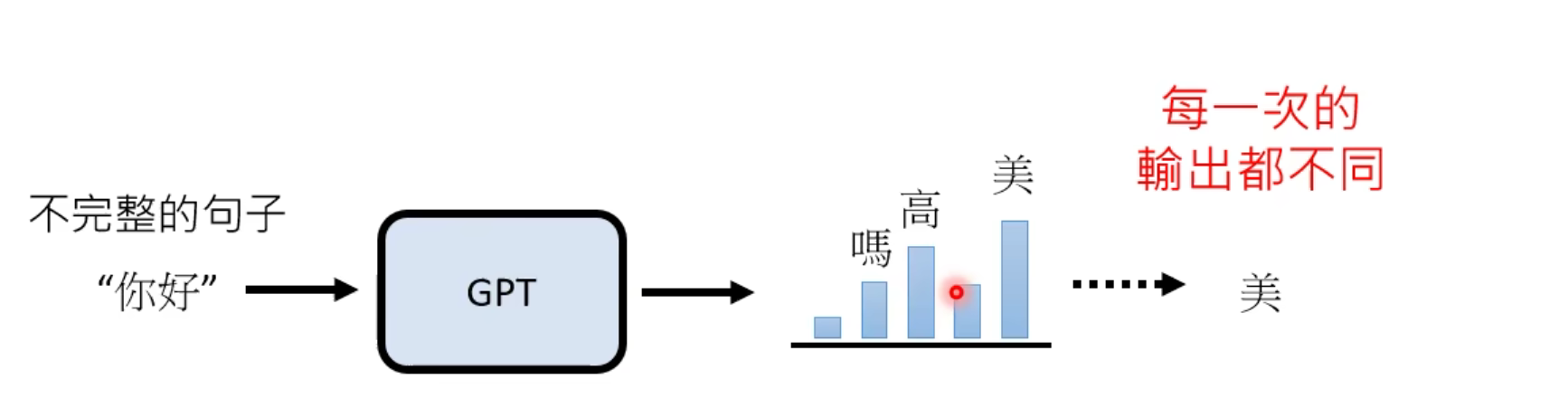
句子接龙的作用
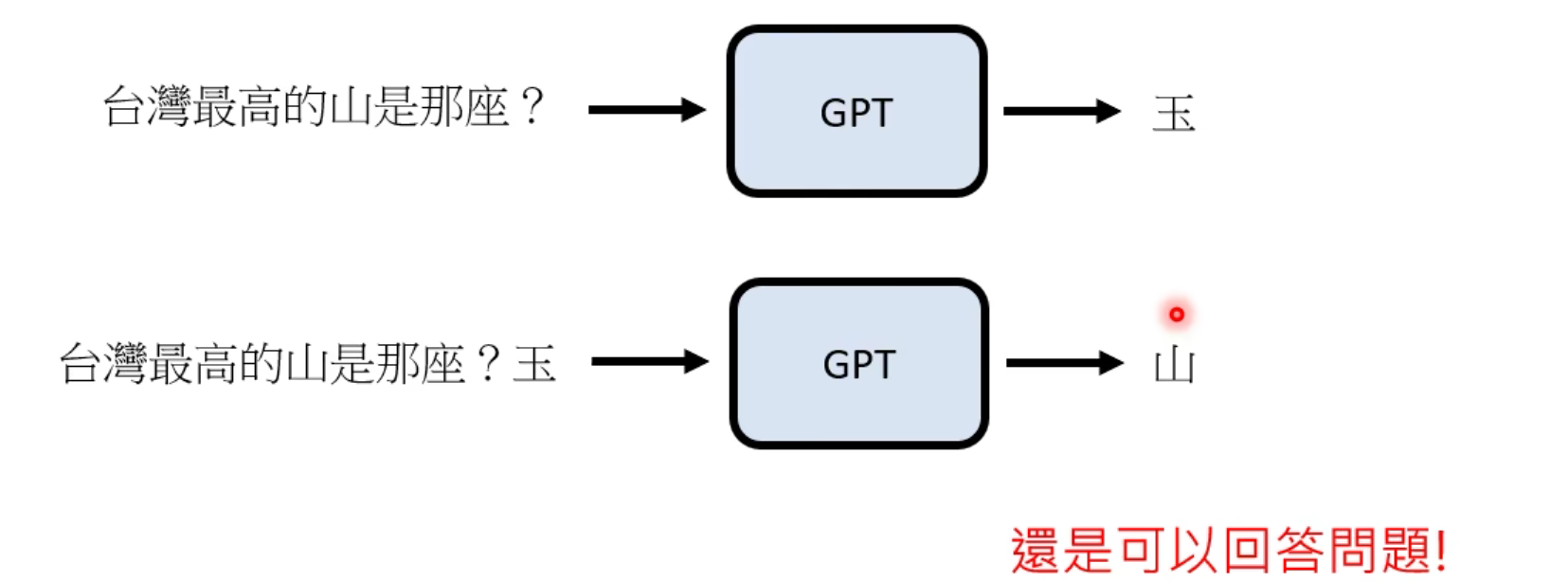
实际上,学会了句子接龙,就可以回答一些问题。
比如下面这个问题,就可以变成“台湾最高的山是”,这个空缺的句子,然后让GPT去接龙。
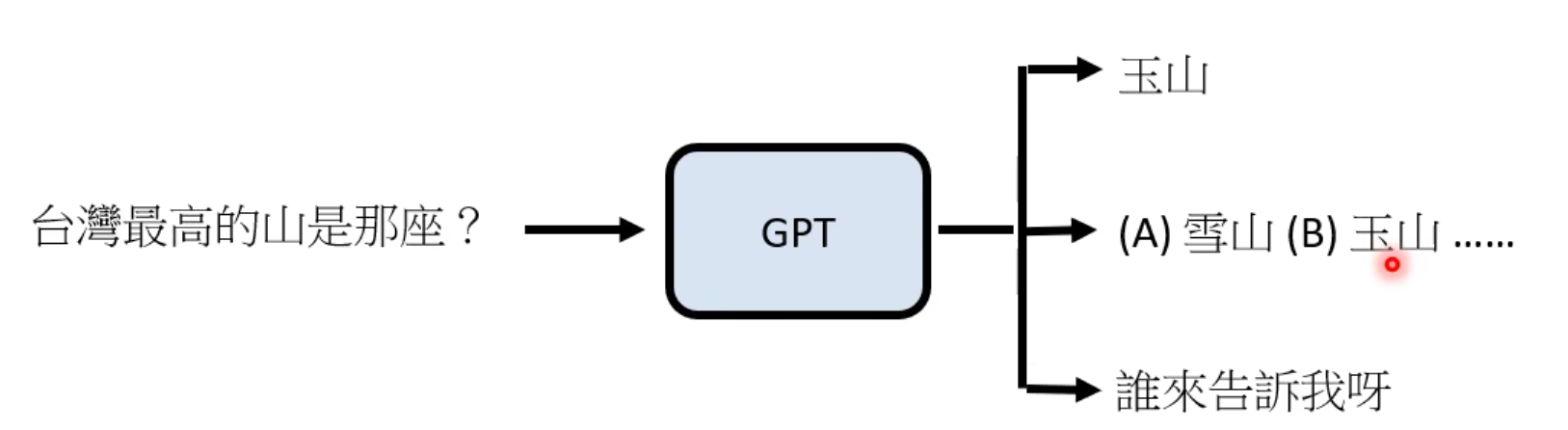
然而这样是有缺陷的,比如它在网上恰好看到了一个地理试卷…
那么“GPT给你出了一道地理题”这种情况也是有可能发生的。
2.人类老师引导文字接龙方向
由人类来标注这些接龙的可能答案,以及限定GPT读取网上的内容。
不需要穷举标注所有答案,只需要告诉GPT人类的希望它生成的答案类型。

3.模仿人类老师的喜好
openAI开放了它的GPT API,所有人都可以直接调用。而GPT对问题的答案具有随机性,这时调用它的用户就充当了人类老师的作用。通过用户的反馈,openAI就知道人类更希望它产生那个答案。


比如点击上图的那个“Regenerate response”,就相当于告诉它人类对此类回答不满意。
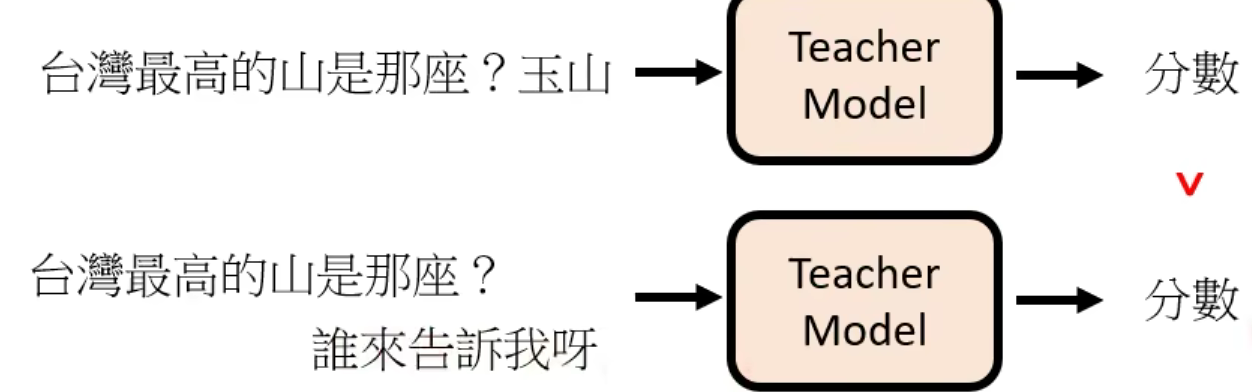
接下来用这些数据训练一个“模仿人类老师”的模型Teacher Model,用这个模型来给chatGPT的回答打分。
4.用增强学习像模拟老师学习
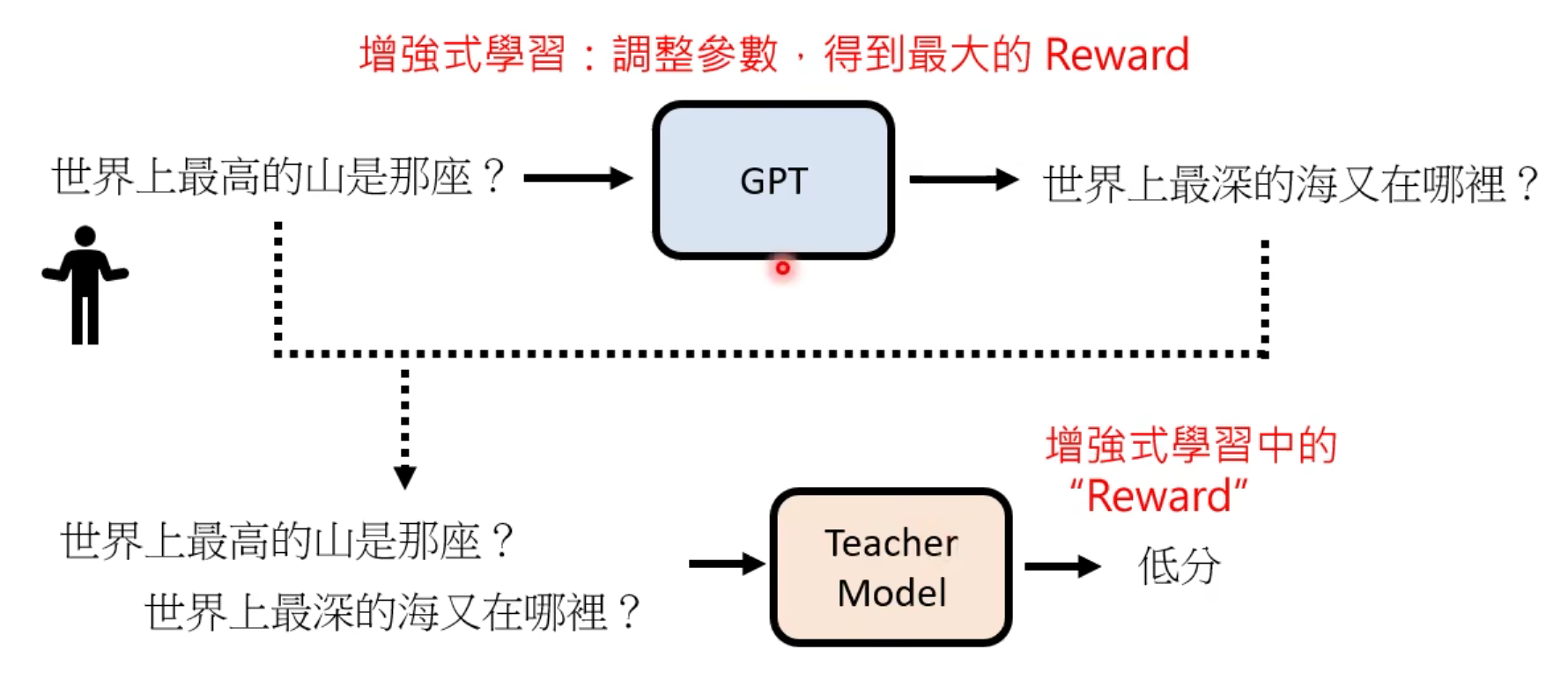
当有人问出“世界上最高的山是那座?”的时候,GPT可能生成了一个“世界上最深的海又在哪里?”。这对于句子接龙来说,显然是个非常好的结果,但是对于问问题的人来说显然并不是:(。那么GPT会先把这个结果送给Teacher Model来打分。
那么理想情况下Teacher Model应该会给低分,这个低分就相当于增强学习中的Reward。这时就根据增强学习技术,去调整GPT生成回答的参数,以此尽量来获得高分。
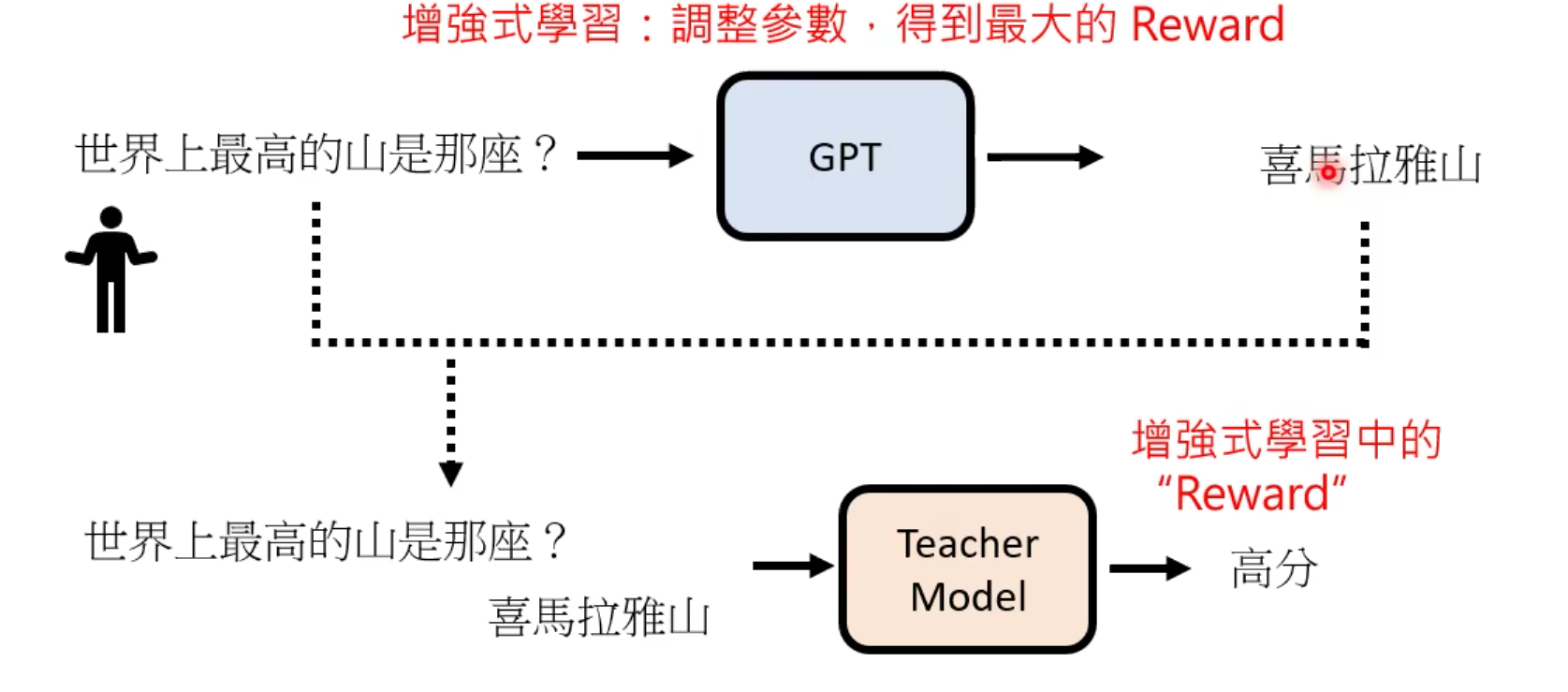
经过多次调整后,GPT就会大概率生成人类想要它输出的答案了
GPT的缺陷
如何找到GPT的缺陷?
比如说问一些没用的问题,此类问题缺少人类老师的引导,那么GPT就有很大的可能性会答错。
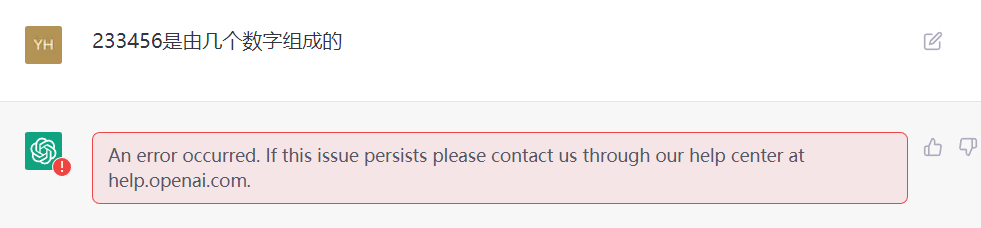
比如这下直接给GPT干懵了:)。
总结
chatGPT就是GPT的社会化!