运行命令:
hadoop jar ./jar包名字 class对象路径 输入路径 输出路径
linux内部jar包测试
cd 到以下目录,创建以下文件夹
[root@reagan180 ~]# cd /opt/soft/hadoop313/share/hadoop/mapreduce/
创建文件夹(读取路径)
[root@reagan180 mapreduce]# hdfs dfs -mkdir /inpath
创建文本文件,内容随意编写
[root@reagan180 mapreduce]# vim aa.txt
移动文件到读取路径
[root@reagan180 mapreduce]# hdfs dfs -put ./aa.txt /inpath
然后运行命令:写入路径会自己创建,但是如果存在,会报错,修改路径即可
[root@reagan180 mapreduce]# hadoop jar ./hadoop-mapreduce-examples-3.1.3.jar wordcount /inpath /outpath
创建jar包
方法1:打开ideal,找到需要导成Jar包的driver类
先编译 点击complie:

然后打包 点击 package:

打包成功后,jar会生成在target目录下
将jar包放在linux里的opt目录下
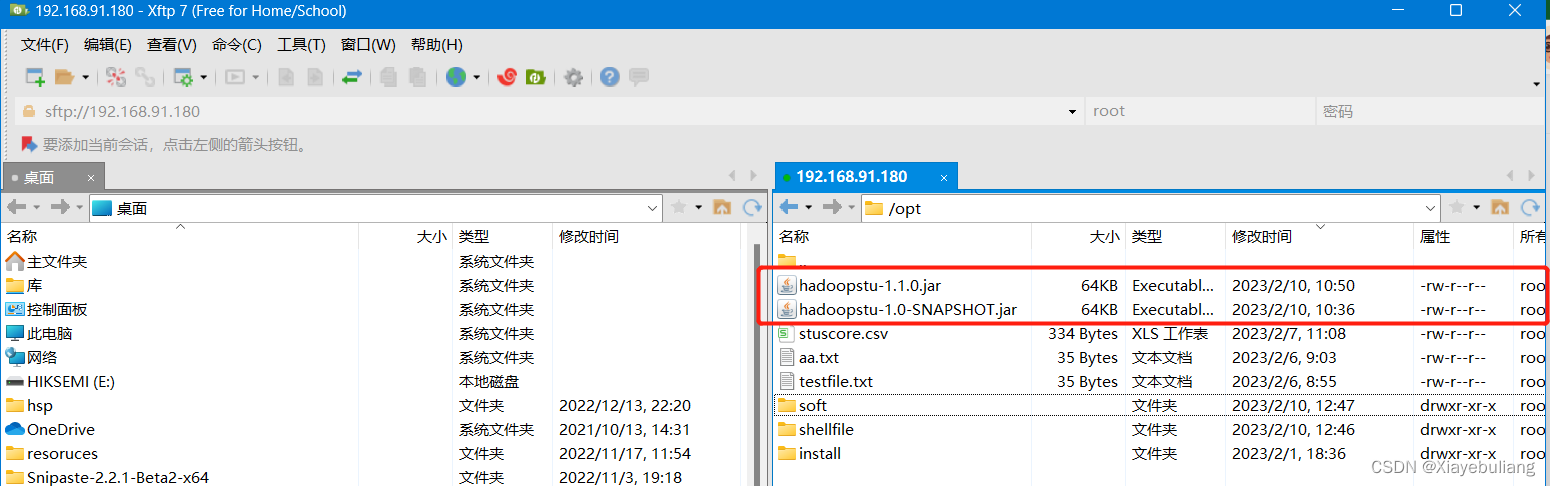
然后输入命令运行:因为读取和写入路径已经写在class对象,此处可省略:
class对象路径:右击对象名

[root@reagan180 opt]#hadoop jar ./hadoopstu-1.0-SNAPSHOT.jar nj.zb.kb21.demo4.StudentDriver
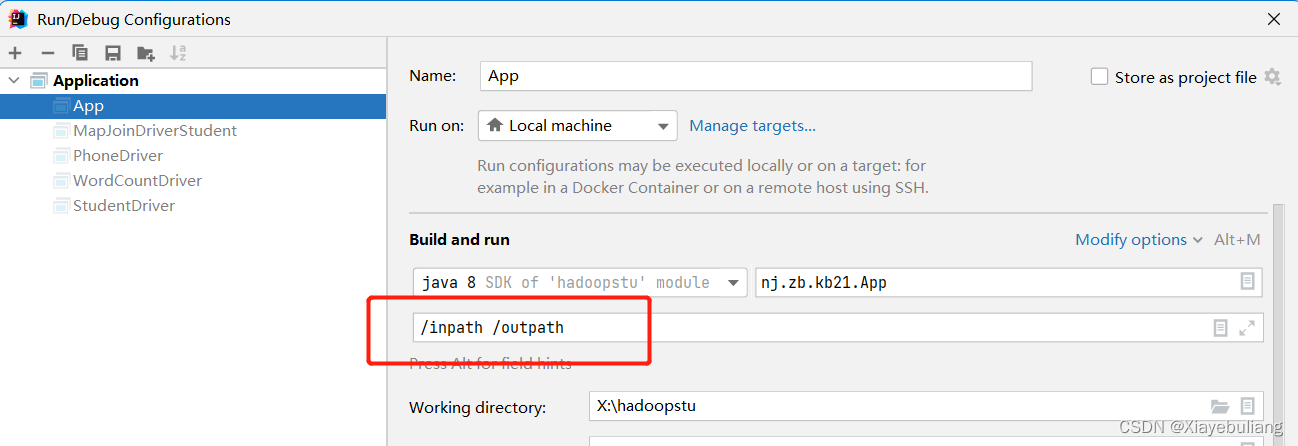
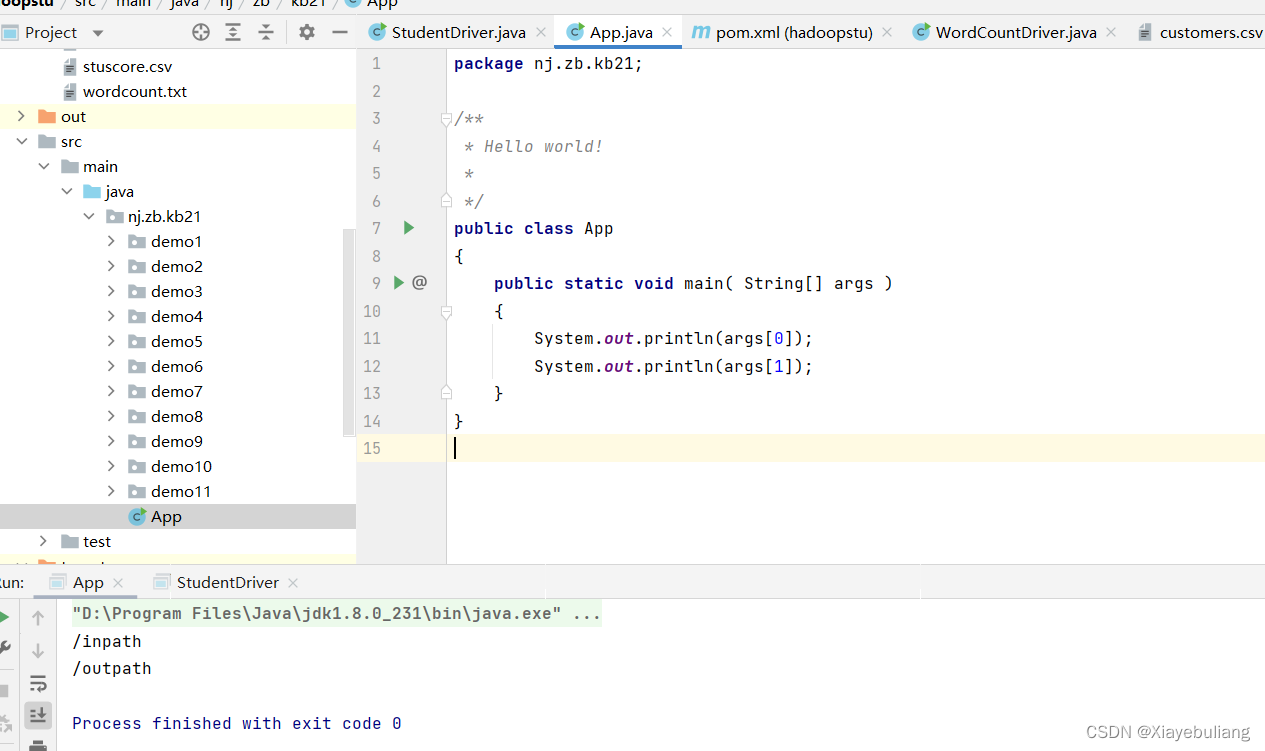
路径:方法2 采用psvm 里的arg[ ] 集合元素 更加灵活
设置元素为: /inpath /outpath
重复上面打成jar包操作
命令需要做个调整,加上读取和输入路径:
[root@reagan180 opt]#hadoop jar ./hadoopstu-1.0-SNAPSHOT.jar nj.zb.kb21.demo4.StudentDriver /bigdata/in/demo2/stuscore.csv /bigdata/out4.2
补充:启动 JobHistoryServer命令 :
mr-jobhistory-daemon.sh start historyserver :