计算机网络【HTTP协议】
- 🍎一.HTTP协议概述
- 🍒1.什么是HTTP协议
- 🍒1.2 Fiddler(抓包工具)
- 🍎二.HTTP协议格式
- 🍒2.1HTTP请求
- 🍉2.1.1 HTTP请求格式
- 🍉2.1.2 HTTP请求格式URL
- 🍉2.1.3 HTTP请求格式方法
- 🍉2.1.4 GET与POST区别(面试题)
- 🍉2.1.5HTTP请求报头
- 🍉2.1.6HTTP请求正文(body)
- 🍒2.2HTTP响应
- 🍉2.2.1HTTP响应格式
- 🍉2.2.2HTTP响应状态码
🍎一.HTTP协议概述
🍒1.什么是HTTP协议
HTTP/HTTPS协议是应用层的网路协议
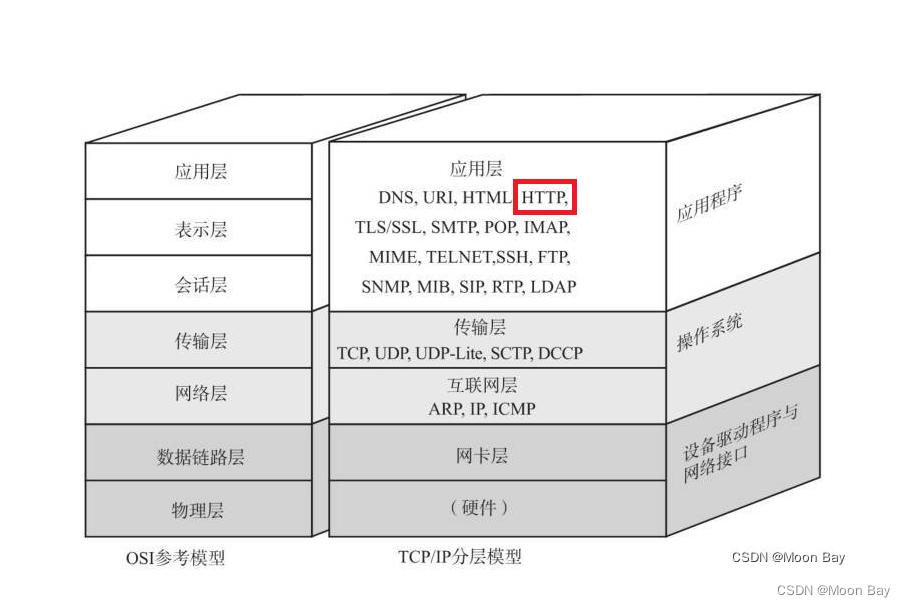
目前大多数情况HTTP在传输层是基于TCP(HTTP1/2 是基于TCP,最新的HTTP协议是基于UDP协议,但是我们目前常用的HTTP应用层协议是HTTP1.0)
应用层协议很多时候都是程序员自己定制的,需要根据具体的场景来制定应用层协议,但是由于程序员水平参差不齐,大佬设计的协议很好用,菜鸟设计的协议一言难尽,于是有一些大佬就发明了很好用的协议,直接让大家照搬,HTTP就是其中的一个典型代表,HTTP虽然已经设计好了,但是它的扩展性极强,可以根据需要让程序员自定义数据信息
当我们在浏览器中输入一个 “网址”, 此时浏览器就会给对应的服务器发送一个 HTTP 请求. 对方服务器收
到这个请求之后, 经过计算处理, 就会返回一个 HTTP 响应
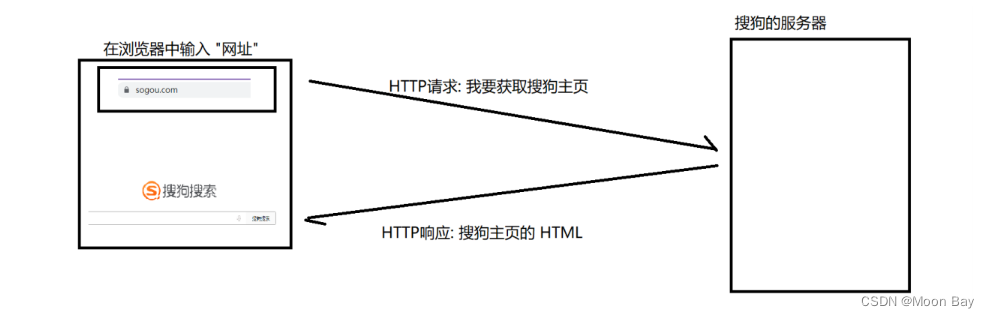
HTTP是一种超文本传输协议,是互联网上应用最为广泛的一种网络协议,那如何才能看到HTTP的报文格式或信息,这就需要对HTTP进行抓包(获取到请求和响应的相关数据),下面介绍一下如何进行HTTP的抓包
🍒1.2 Fiddler(抓包工具)
Fiddler 下载地址: https://www.telerik.com/fiddler/
● 下载之后就正常点击安装就可以
● 安装完成后双击打开,我们先更改设置这样我们就能够捕捉到HTTPS协议的包,点击左上角Tools->点击Options->
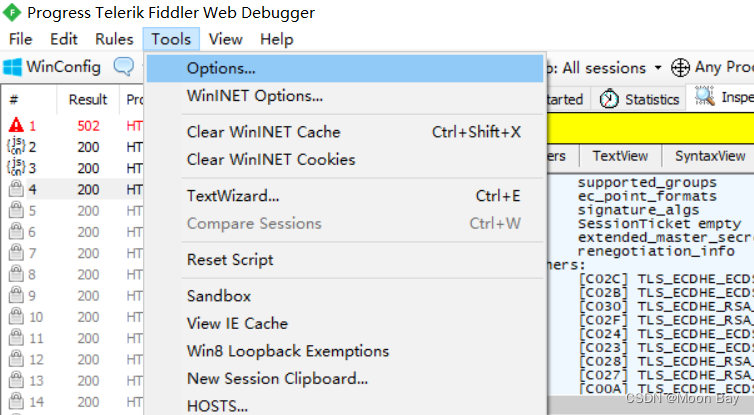
● 点击HTTPS将里面的内容全部勾选
● 勾选点击OK后会弹出,我们点击YES 后 再点击再单击 ”是“ 再点击”同意安装“,这个一定要安装,这个是Fiddler抓包工具的证书,没有安装证书是不会获取到HTTPS协议的包
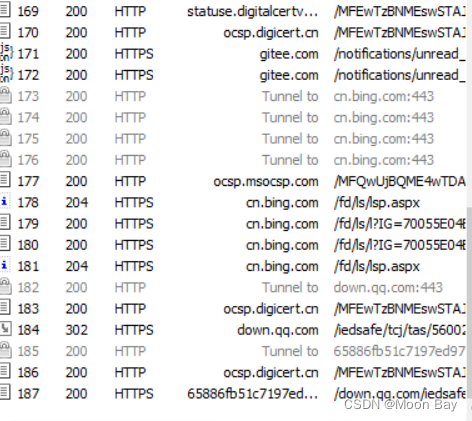
● 安装好整数之后我们点击左边就可以看到我们获取到的HTTP和HTTPS协议的包
 \
\
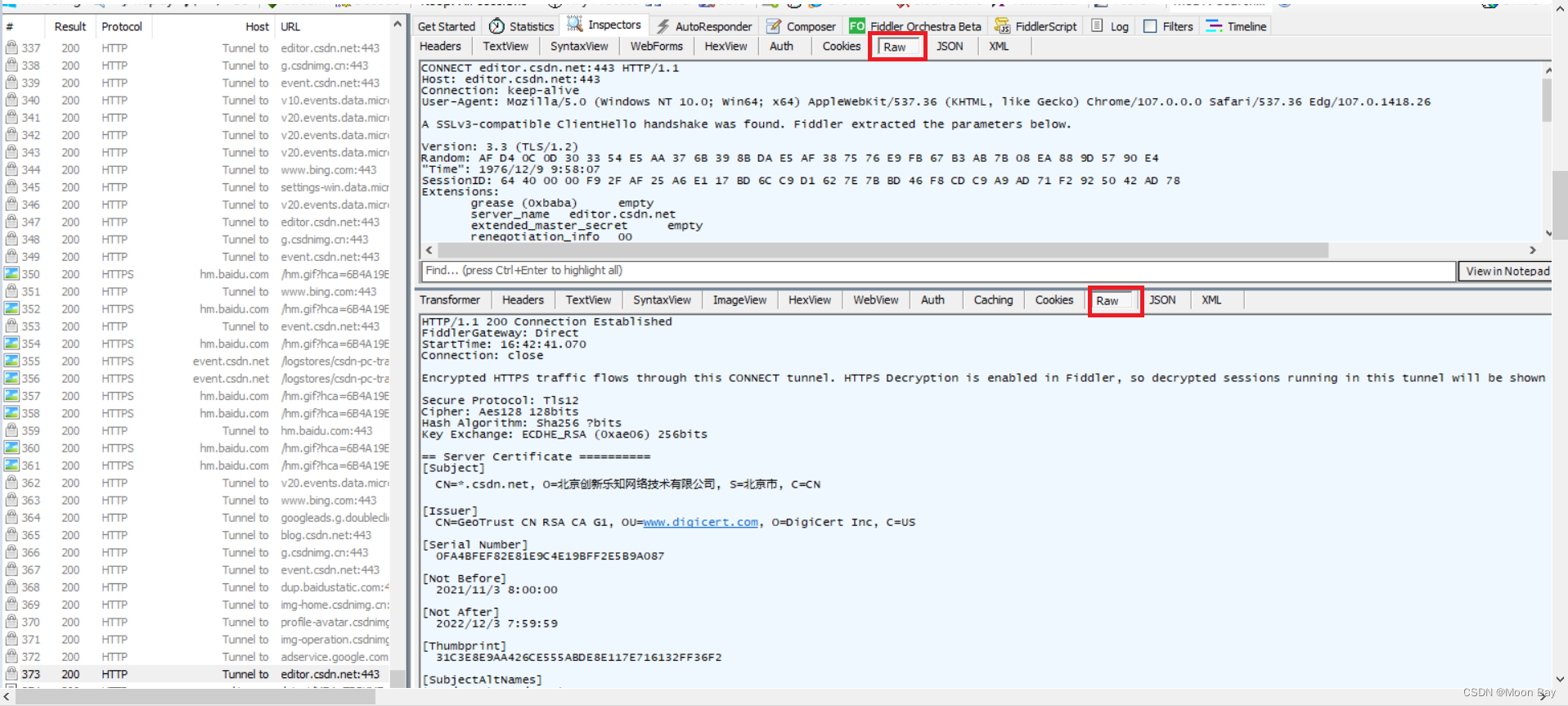
● 我们双击一个获取的协议包,在点击Raw就可以在右边看到包里的请求和相应内容
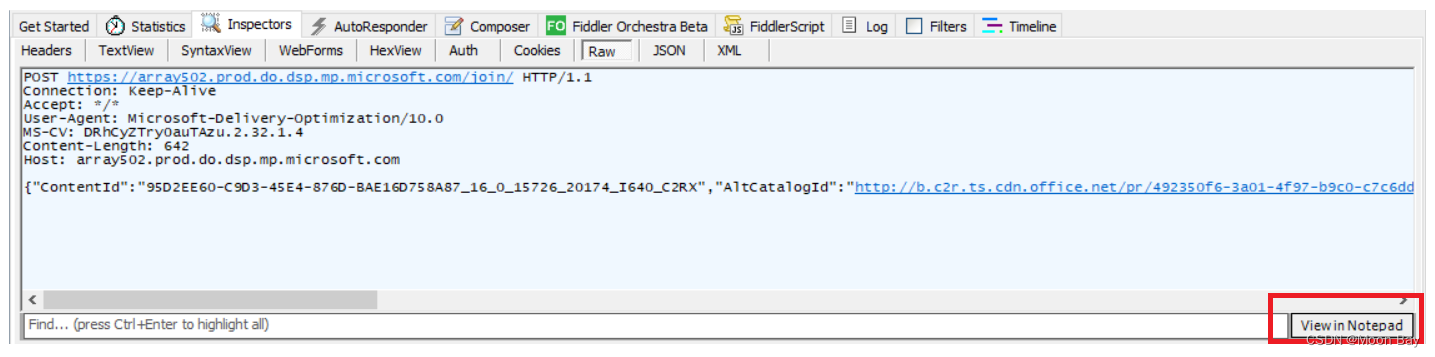
● 点击View in Noyepad 就可以看到文本内容
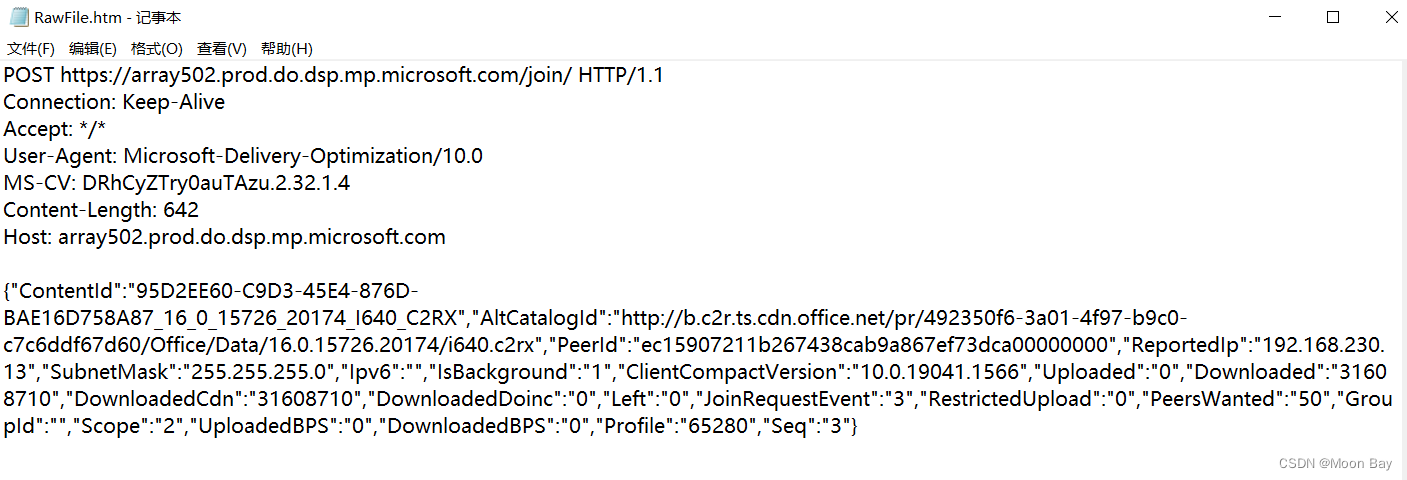
● 如果我们看到乱码不要担心是系统BUG,这其实是在传输过程中数据压缩之后的结果
以上就是我们根据抓包工具就可以在我们开发的过程中进行调试来解决BUG
🍎二.HTTP协议格式
🍒2.1HTTP请求
🍉2.1.1 HTTP请求格式
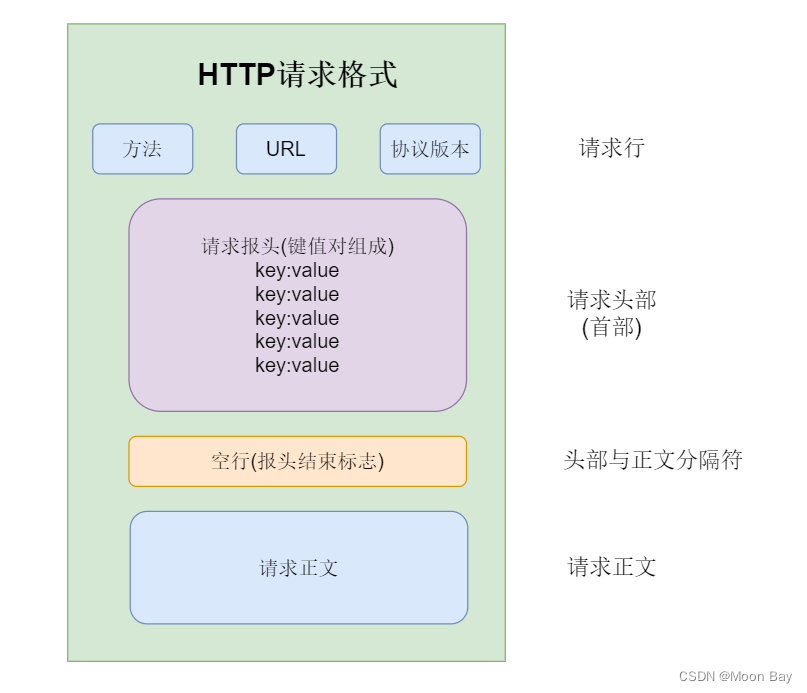
一.请求行(首行),包含三个部分
● HTTP方法:大概描述了这个请求想要干什么
● URL:描述了想要访问的网络资源具体在哪
● 版本号,HTTP/1.1表示当前使用 HTTP1.1版本
二.请求报头
● 包含很多行,每一行都有一个键值对,键值对之间用空格来分割
三.空行
● 相当于结束标记,类使于链表的null
四.请求正文(body)
● 可选的,不一定每个HTTP协议都有
我们就拿Fiddler(抓包工具)来进行逐步了解


🍉2.1.2 HTTP请求格式URL
URL:含义就是”网络上唯一的资源地址符“

协议方案名:必选项,使用 http 或https等协议方案名获取访问资源时要指定协议类型。不区分字母大小写,最后附一个冒号:,使用//与后面的字段分隔。
也可使用 jdbc:mysql:// 或 javascript: //这类jdbc程序或脚本程序的方案名。
登录信息:可选项,这是很早时期上网的时候,在这里会体现出账号与密码,现在基本上没有了,使用@符号与后面的字段分隔。
服务器地址:必选项,可以使用域名和IP地址来表示,使用:与端口号分隔。
端口号:可选项,表示访问主机上哪一个应用程序,该字段为空,浏览器会分配默认的端口号,http是80,https是443。
文件路径:必选项,描述访问服务器的资源是什么,最简单的路径就是一个/,你访问很多网站的首页的时候,最后都会有一个/,使用?与查询字符串分隔。
查询字符串:可选项,表示浏览器或者客户端传给服务器自定义的信息,对获取的资源提出进一步的要求,一般是程序员自定义,所以如果不是你自己写的,大概率看不懂,使用&进行查询字符串分割,使用#与片段标识符分隔。
片段标识符:可选项,表示访问页面的子位置,能够控制浏览器滚动到某一位置。
HTTP 协议使用 URI 定位互联网上的资源。正是因为 URI 的特定功能,在互联网上任意位置的资源都能访问到。
URL:小结
● IP地址
● 端口号(可有)
● 带层次结构的路径
● query string 查询字符串
URL encode / decode
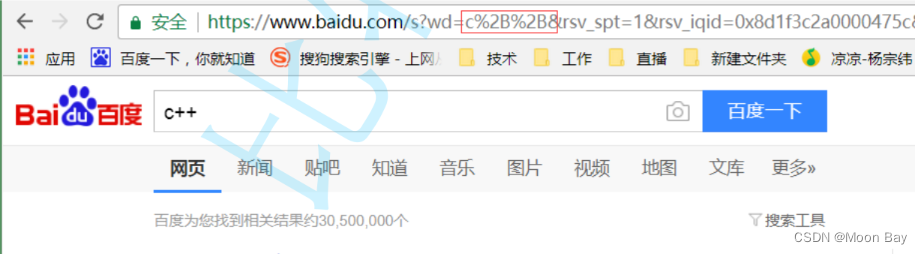
如果查询字符串(query string)的内容包含一些具有特定含义的字符需要进行转义,如/,?,&等,如果含有这些字符,会将这些字符替换为%+字符的ASCII码,这个过程就是encode,反过来将这些转义的字符串解析为原来的字符,这个过程就是decode,不仅仅是特殊符号,也有可能是汉字
比如,你在浏览器上搜索C++,在URL上就会得到C%2B%2B这样的字符串
🍉2.1.3 HTTP请求格式方法
请求行里面的方法完整地说应该叫做告知服务器意图的 HTTP 方法,这里的方法与java里面的方法不同,引入这些方法的初衷就是为了表示不同的语义,比如GET表示获取资源,POST表示上传资源,但是大多数人写代码就是GET/POST一把梭,基本上就没有考虑各种方法的语义。
在http/1.1版本中,我们最常使用的方法有GET,POST,还有其他方法,引谢灵运的话来说才高八斗,就是指GET占八斗,POST占一斗,其他方法分剩下的一斗来表示GET和POST方法的常用
各方法功能如下:
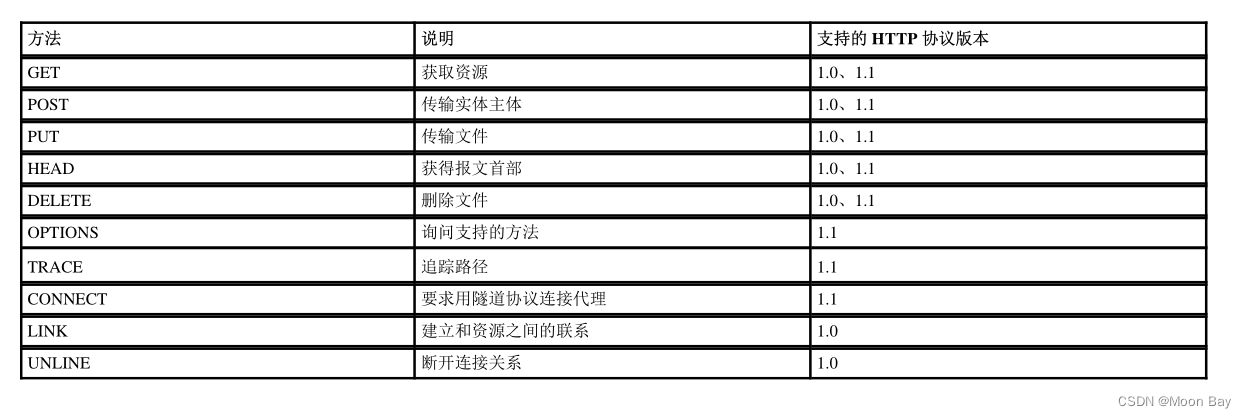
● GET 方法
GET 是最常用的 HTTP 方法. 常用于获取服务器上的某个资源.在浏览器中直接输入 URL, 此时浏览器就会发送出一个 GET 请求.另外, HTML 中的 link, img, script 等标签, 也会触发 GET 请求.
*后面我们还会学习, 使用 JavaScript 中的 ajax 也能构造 GET 请求.
● GET 请求的特点:
● 首行的第一部分为 GET
● URL 的 query string 可以为空, 也可以不为空.
● header 部分有若干个键值对结构.
● body 部分为空.
● POST 方法
POST 方法也是一种常见的方法. 多用于提交用户输入的数据给服务器(例如登陆页面).
通过 HTML 中的 form 标签可以构造 POST 请求, 或者使用 JavaScript 的 ajax 也可以构造 POST 请求.
●POST 请求的特点
●首行的第一部分为 POST
●URL 的 query string 一般为空 (也可以不为空)
●header 部分有若干个键值对结构.
●body 部分一般不为空. body 内的数据格式通过 header 中的 Content-Type 指定. body 的长度由
●header 中的 Content-Length 指定
🍉2.1.4 GET与POST区别(面试题)
● 语义上区别:GET通常用来获取数据,POST通常用来上传数据
● 大多数情况下:GET没有body,GET通过query string向服务器传递数据;POST是有body的,POST通过body向服务器传递数据,但是POST没有query string
● GET请求是幂等,POST请求一般是不幂等(幂等是每次相同的输入,得到输出结果是确定的;不幂等:每当你相同的输入,得到的结果不正确)
● GET可以被缓存,POST不能被缓存(幂等和能不能被缓存是有关联的)
补充说明:
● 关于语义: GET 完全可以用于提交数据, POST 也完全可以用于获取数据.
● 关于幂等性: 标准建议 GET 实现为幂等的. 实际开发中 GET 也不必完全遵守这个规则(主流网站都有 “猜你喜欢” 功能, 会根据用户的历史行为实时更新现有的结果.
● 关于安全性: 有些资料上说 “POST 比 GET 请安全”. 这样的说法是不科学的. 是否安全取决于前端在传输密码等敏感信息时是否进行加密, 和 GET POST 无关.
● 关于传输数据量: 有的资料上说 “GET 传输的数据量小, POST 传输数据量大”. 这个也是不科学的, 标准没有规定 GET 的 URL 的长度, 也没有规定 POST 的 body 的长度. 传输数据量多少,完全取决于不同浏览器和不同服务器之间的实现区别.
● 关于传输数据类型: 有的资料上说 “GET 只能传输文本数据, POST 可以传输二进制数据”. 这个也是不科学的. GET 的 query string 虽然无法直接传输二进制数据, 但是可以针对二进制数据进行 url encode.
🍉2.1.5HTTP请求报头
● Host
表示服务器主机的地址和端口

● Content-Type
表示请求的 body 中的数据格式
常见选项:
1.application/x-www-form-urlencoded: form 表单提交的数据格式. 此时 body 的格式
title=test&content=hello
2.multipart/form-data: form 表单提交的数据格式(在 form 标签中加上enctyped=“multipart/form-data” . 通常用于提交图片/文件. body 格式)
Content-Type:multipart/form-data; boundary=----
WebKitFormBoundaryrGKCBY7qhFd3TrwA
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name="text"
title
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name="file"; filename="chrome.png"
Content-Type: image/png
PNG ... content of chrome.png ...
------WebKitFormBoundaryrGKCBY7qhFd3TrwA--
3.application/json: 数据为 json 格式. body 格式
{"username":"123456789",(密码加密,因为博客规定所以不显示了,大家可以在Fedeeler去看):"xxxx","code":"jw7l","uuid":"d110a05ccde64b16a861fa2bddfdcd15"}
补充说明:
为什么我们登陆时使用的方法是POST而不是GET,因为使用GET方法中大部分是没有body,所以我们只能通过URL中的查询字符串来进行传递操作(query string)这样我们就会在链接上看到很长一条所以这影响用户体验的,这个时候我们就可以通过POST方法中的body来进行数据传输了,这样还可以例如在用户输入密码的时候保留在body中而不是显示在URL中
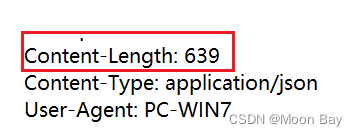
● Content-Length
表示 body 中的数据长度.
因为HTTP协议是基于TCP协议,所以我们也是有可能会沾包问题,所以我们可以需要通过分隔符,和空格,还有长度来进行辨别这个包是否已经传输结束了
当多个POST进入TCP缓冲区中,这个时候哦就可以通过body当读到空格后可以通过 Content-Length来进行识别还需要继续多多少字节就完整的传输包了
● User-Agent (简称 UA)
表示当前用户通过什么设备,那个浏览器来上网

● Referer
表示这个页面是从哪个页面跳转过来的
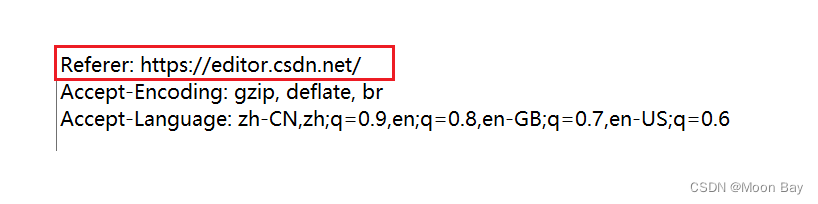
如果直接在浏览器中输入URL, 或者直接通过收藏夹访问页面时是没有 Referer 的.
● Cookie
Cookie 中存储了一个字符串, 这个数据可能是客户端(网页)自行通过 JS 写入的, 也可能来自于服务器(服务器在 HTTP 响应的 header 中通过 Set-Cookie 字段给浏览器返回数据).往往可以通过这个字段实现 “身份标识” 的功能.
每个不同的域名下都可以有不同的 Cookie, 不同网站之间的 Cookie 并不冲突.
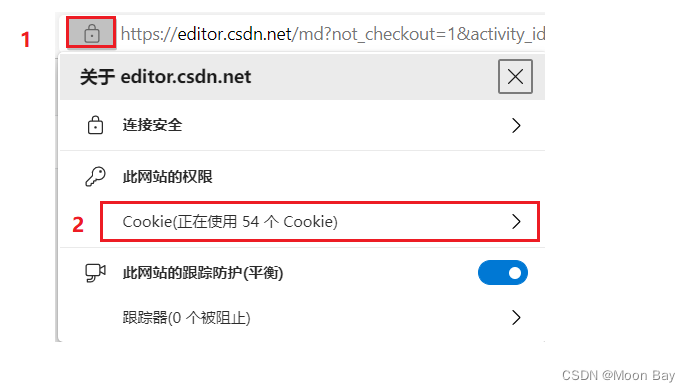
我们可以通过登陆过的博客来查看Cookie
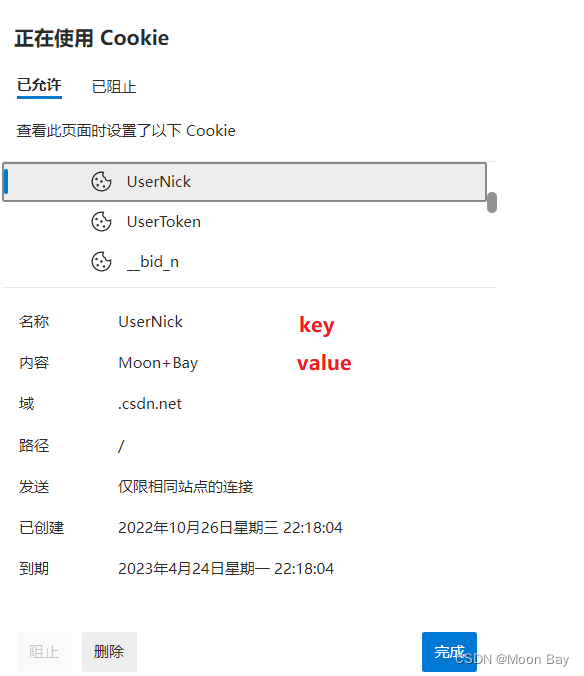
因为HTTP是一种无状态的协议,它无法对之前的发生过的请求和响应状态进行记忆,如果遇到需要登录的页面,登录之后,再刷新,是需要重新进行登录的,这个就非常的难受,为了解决这个问题,引入了Cookie机制
但是也有好处,可以减少服务器的 CPU 及内存资源的消耗。
Cookie是浏览器为页面提供的一种持久化储存数据的机制,即就是将数据存储磁盘上,不会因为浏览器或者电脑重启而导致数据丢失。
Cookie会按照域名来进行分类并组织,针对每一个域名,都会分配一个“小房间”(一块独立的储存空间),这些小房间之间是相互独立的,在每个“小房间”里面会按照键值对的方式储存数据(值),每个键值对之间使用&来进行分隔。
那Cookie的数据从哪里来?其实是从服务器返回给客户端的,服务器完成客户端的身份认证之后会通过的头部字段Set-Cookie来给客户端响应信息
Cookie的作用其实就像医院里面的就诊卡一样,就诊卡里面有就诊人的基本信息,刷卡之后会根据这些基本信息可以查出在当前医院里面的历史就诊记录等更加详细的信息,这张就诊卡就相当于Cookie,而根据就诊卡信息获得的详细记录叫做session,每个session里面记录了就诊用户的许多关键信息,例如历史就诊记录,要做的检测等等,每一个session都有对应的sessionId,即会话标识,服务器返回给客户端的Cookie响应就有这个会话标识,然后访问后续页面的,根据这个会话标识就能从服务器找到对应的信息进行登录,这样刷新页面就不用在重复登录了
下图所圈的部分就有可能就是一种sessionId

🍉2.1.6HTTP请求正文(body)
正文中的内容格式和 header 中的 Content-Type 密切相关. 上面也罗列了三种常见的情况.
下面可以通过抓包来观察这几种情况:
● application/x-www-form-urlencoded
● multipart/form-data(文件/照片)
● application/json(界面)
🍒2.2HTTP响应
🍉2.2.1HTTP响应格式
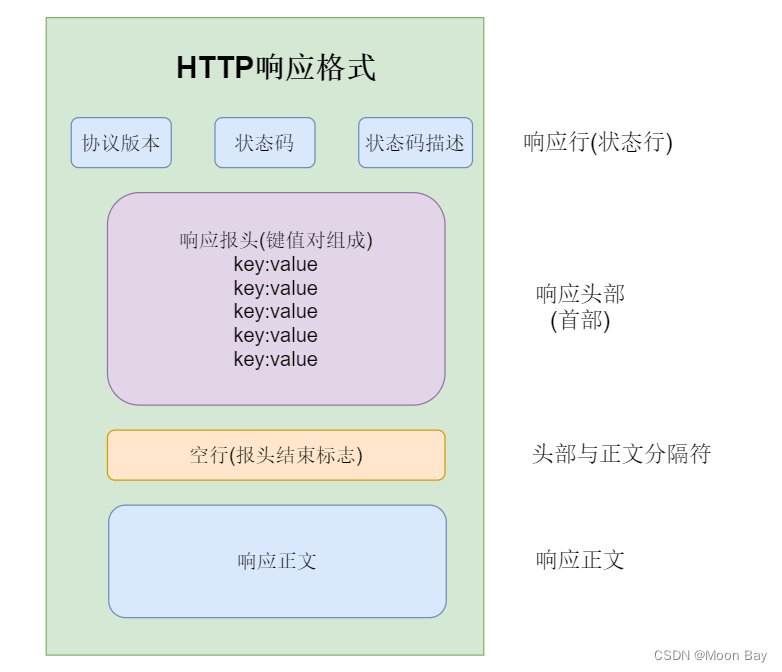
一.响应行(首行),包含三个部分
● 版本号,HTTP/1.1表示当前使用 HTTP1.1版本
● 状态码:200,描述这个响应,是表示”成功的“还是”失败的“,以及不同的状态码,来描述了失败的原因
● 状态码描述:OK 描述了当前状态码的含义
二.响应报头
● 包含很多行,每一行都有一个键值对,键值对之间用空格来分割,不同键值对有不同的含义
三.空行
● 相当于结束标记,类使于链表的null
四.请求正文(body)
● 服务器返回个客户端的具体数据,类似于假如我们访问一个网页我们就可以获得到该网页给我们响应的html
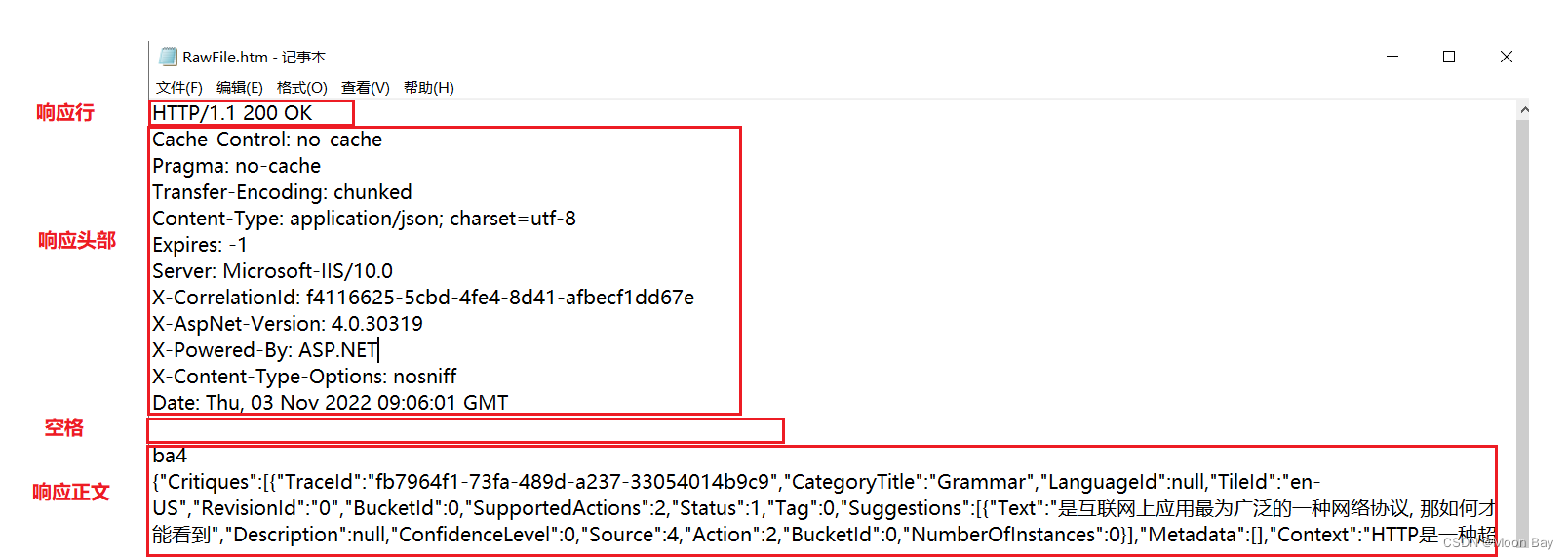
🍉2.2.2HTTP响应状态码

这是我们经常见到的状态码
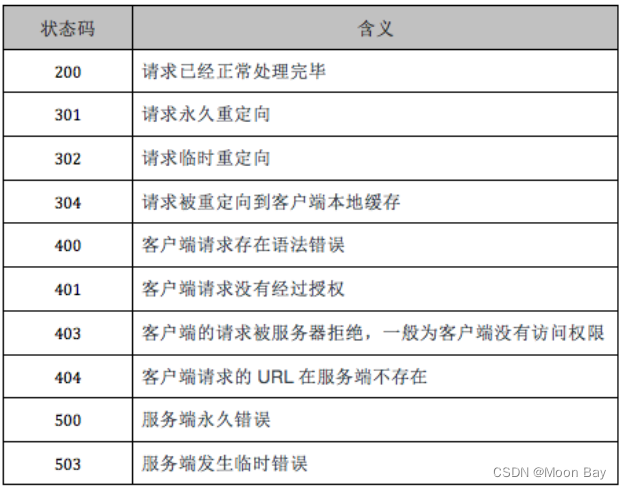
● 200 OK :表示浏览器很顺利的获取到想要的内容
● 302 Move temporarily 重定向(例如呼叫转移,知道下一步要去哪里)

● 403 Forbidden 虽然有资源但是没有权限进行访问(丑拒)
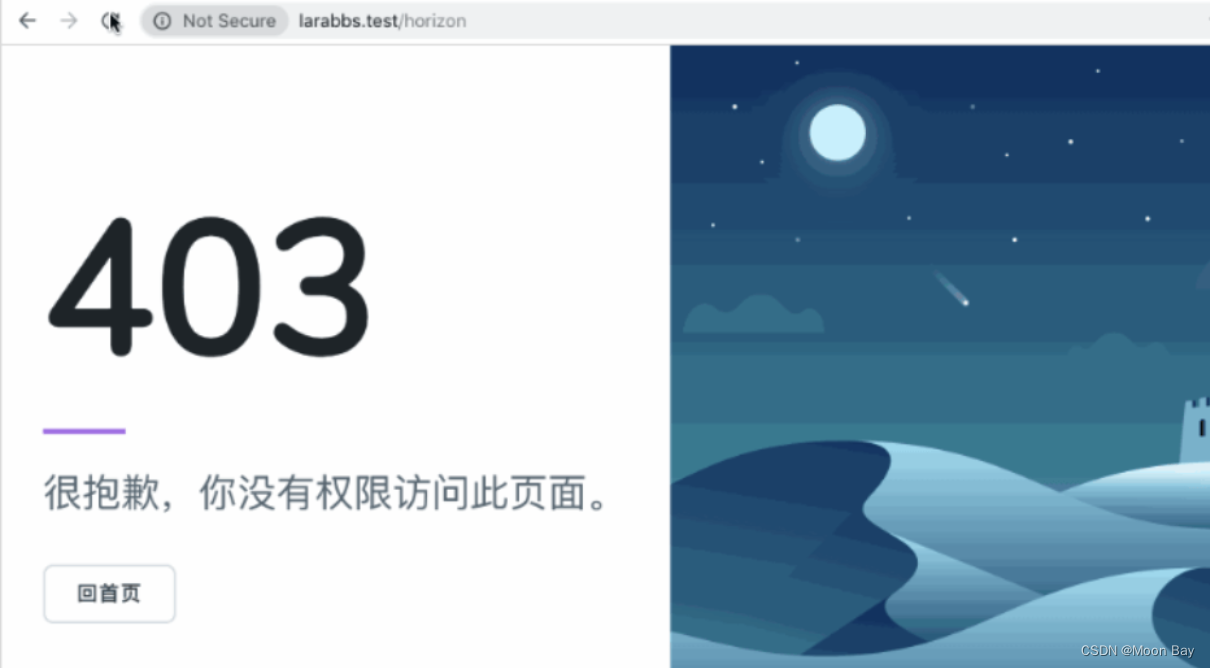
● 404 Not Found 要访问的资源不在

● 405 Method Not Allowed 很少遇见,就是假如你通过GET方法进行访问,但是人家网站只支持POST方法进行访问
● 500 Internal Severe Erro 服务器自己出现问题r
● 504 Gateway Timeout 服务器繁忙