1、概述
当前人民和国家对食品安全十分重视,但商家为了保证食品长时间储存,味道鲜美,在食品中添加超量或对人有严重危害得食品添加剂,严重危害到人民的安全,我们以方便面为例,一包方便面最多可有25种食品添加剂,常见的有谷氨酸钠、焦糖色、柠檬酸、特丁基对苯二酚等。儿童长期食用含柠檬酸的产品,可能导致低钙血症。所以在选择食品时,尽量选择优质、信誉好的大厂家生产的食品。并且要学会看食品配料表,尽量买食品添加剂少的食品。

我就当前热点话题,对食品配料识别进行了研究和实现,目前调研常用的几个开源的OCR识别模型主要有几个如下表所示,简单说一下各个模型的优缺点,paddleocr用起来很方便是国产识别模型(baidu搞得),只需要用python安装对应模块即可,而且识别速度和效果是这几个中最好的(个人感觉),而且可以更换不同级别的模型,例如服务器级别的chinese_ocr_db_crnn_server、和手机端级别的chinese_ocr_db_crnn_mobile等。chineseocr_lite也是一个轻量级的识别模型但是相对比于paddleocr来说再复杂的识别场景下识别速度和效果没有paddleocr好其他的就不提了。
| 名称 | 地址 |
| paddleocr | PaddleHub一键OCR中文识别(超轻量8.1M模型,火爆) - 飞桨AI Studio |
| chineseocr_lite | GitHub - DayBreak-u/chineseocr_lite: 超轻量级中文ocr,支持竖排文字识别, 支持ncnn、mnn、tnn推理 ( dbnet(1.8M) + crnn(2.5M) + anglenet(378KB)) 总模型仅4.7M |
| chineseocr | GitHub - chineseocr/chineseocr: yolo3+ocr |
| easyocr | pip install easyocr |
传统OCR模型识别流程主要就是两个步骤:文字位置识别+文字识别,传统识别模型使用ctpn文本检测+crnn文本识别,在chineseocr_lite模型中使用yolov3+crnn实现。

2、Docker+Flask搭建PaddleOCR识别环境
- 基础环境搭建
# docker安装python
docker pull python:3.8.12
# 安装后创建服务环境
docker run -dit -p 13000:5000 docker.io/python:3.8.12 --name api_server
# 进入环境
docker exec -it 5eba0c1402bc /bin/bash
- 相关模块搭建
# 安装编译环境
apt-get update && apt-get install libgl1
apt install vim
# 安装paddleOCR
pip install paddlehub -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install shapely -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pyclipper -i https://pypi.tuna.tsinghua.edu.cn/simple
- 搭建Falsk服务
# coding:utf-8
from flask import Flask
from flask import jsonify
from flask import request
import paddlehub as hub
import cv2
import numpy as np
import base64
app = Flask(__name__)
@app.route("/api/ocr",methods=["POST"])
def ocr():
try:
image_str = request.json.get("image")
image_np = np.fromstring(base64.b64decode(image_str.split(';base64,')[1]), dtype=np.uint8)
image_array = cv2.imdecode(image_np, cv2.IMREAD_COLOR)
result = []
#if is_blurry(image_array):
#print("chpp")
result = chpp_ocr.recognize_text(images=[image_array], box_thresh= 0.1, text_thresh= 0.1, angle_classification_thresh=0.9, det_db_unclip_ratio=1.5)
#else:
#print("mobile")
#result = mobile_ocr.recognize_text(images=[image_array], box_thresh= 0.1, text_thresh= 0.1, angle_classification_thresh=0.9)
data = [i["text"] for i in result[0]["data"]]
return jsonify({"code":200,"data":data})
except Exception as e:
return jsonify({"code":400,"data":str(e)})
def is_blurry(image_array):
gray = cv2.cvtColor(image_array, cv2.COLOR_BGR2GRAY)
fm = cv2.Laplacian(gray, cv2.CV_64F).var()
print("blurry:" + str(fm))
return fm < 550
if __name__ == '__main__':
global mobile_ocr
global chpp_ocr
mobile_ocr = hub.Module(name="chinese_ocr_db_crnn_mobile")
print("加载mobile模型完成")
chpp_ocr = hub.Module(name="ch_pp-ocrv3")
print("加载chpp模型完成")
app.config['JSON_AS_ASCII'] = False
app.run(host="0.0.0.0", port=5000)- 运行服务
创建一个服务启动脚本如下使用nohup进行启动
nohup python api_server.py > log.log 2>&1 &
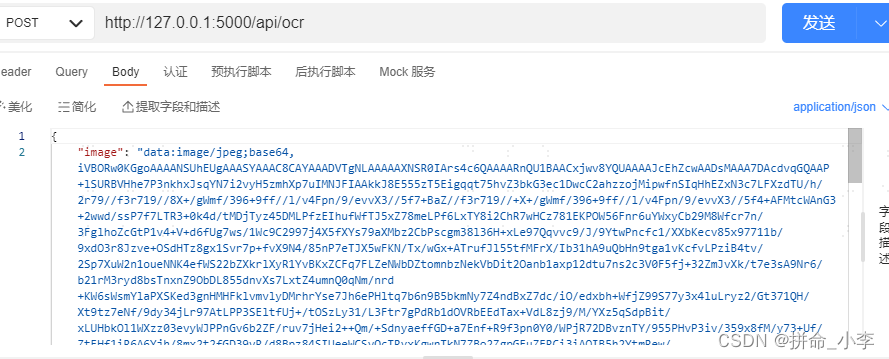
- 接口测试
使用apipost测试软件进行接口测试,发送数据类型是json字符串,传入image的base64字符即可。