一、字符串概念
用于保存字符信息的数据模型(容器)。
1、只能存放一个值
2、不可变类型
3、有序,索引从0开始顺序访问
字符串语法格式:
str1 = “字符串信息”
str2 = '字符串信息'
str3 = '' '' ''字符串信息'' '' ''
str4 = ''' 字符串信息 '''
二、字符串常用操作
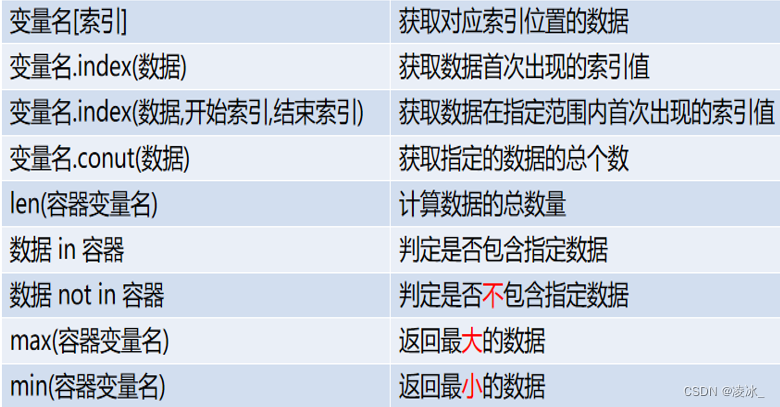
1、字符串判定
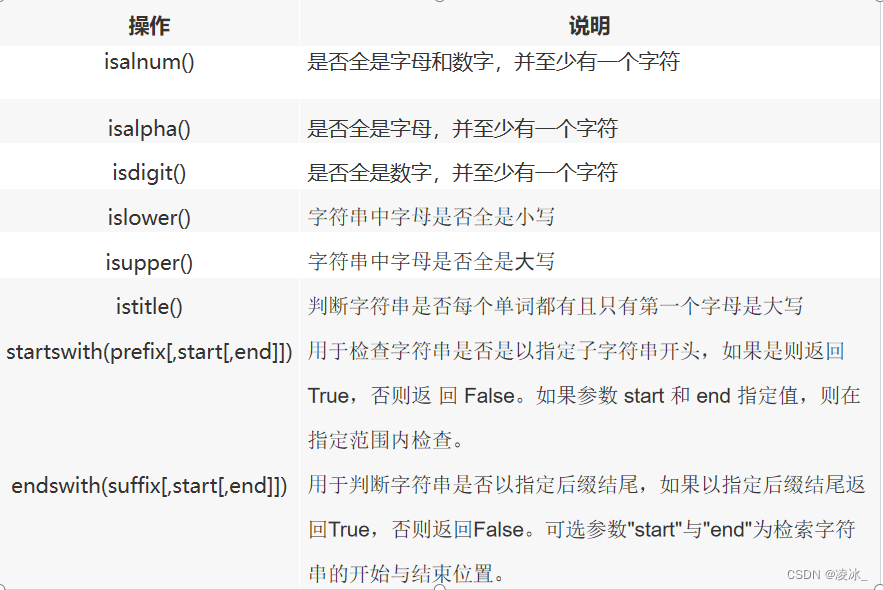
2、字符串查找和替换

3、字符串拆分与连接

4、 字符串数据转换
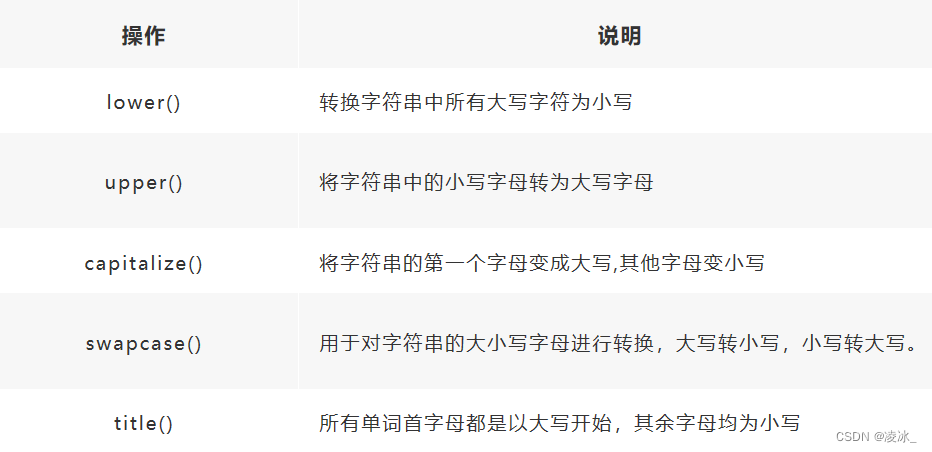
5、字符串格式转换

6、字符串切片

三、字符串应用
1、 输入字符串"https://blog.51cto.com/u_12139097/2573782",输出以下结果:
1) 字符串中字母t出现的次数。
2) 字符中"com"子串出现的位置。
3) 将字符串中所有的"."替换为"-"。
4) 提取"log"使用正向和"to"反向取两个子串。
5) 将字符串中的字母全变为大写。
6) 输出字符串的总字符个数。
7) 在字符串后拼接子串"/yes"
'''
1. 输入字符串"https://blog.51cto.com/u_12139097/2573782",输出以下结果:
1) 字符串中字母t出现的次数。
2) 字符中"com"子串出现的位置。
3) 将字符串中所有的"."替换为"-"。
4) 提取"log"使用正向和"to"反向取两个子串。
5) 将字符串中的字母全变为大写。
6) 输出字符串的总字符个数。
7) 在字符串后拼接子串"/yes"
:return:
'''
ss='https://blog.51cto.com/u_12139097/2573782'
# 1) 字符串中字母t出现的次数。
print(ss.count('t'))
# 2) 字符中"com"子串出现的位置。
print(ss.find('com'))
# 3) 将字符串中所有的"."替换为"-"。
print(ss.replace('.','-'))
# 4) 提取"log"使用正向和"to"反向取两个子串。
print(ss[9:12],ss[-26:-23])
# 5) 将字符串中的字母全变为大写。
print(ss.upper())
# 6) 输出字符串的总字符个数。
print(len(ss))
# 7) 在字符串后拼接子串"/yes"
print(ss+'/yes')

2、学号#姓名#分数,如字符串: "1001#张帆#75-1002#羽田#90-1003#李鑫#85",
提取学生信息存放于列表中,并按照成绩对学生降序排序。
'''
学号#姓名#分数,如字符串: "1001#张帆#75-1002#羽田#90-1003#李鑫#85",
提取学生信息存放于列表中,并按照成绩对学生降序排序。
:return:
'''
data = "1001#张帆#75-1002#羽田#90-1003#李鑫#85"
stu_list = []
for info in data.split('-'):
stu = info.split("#")
print(stu)
#添加到列表中
stu_list.append(dict(zip(["学号", "姓名", "分数"], stu)))
#降序排序
stu_list.sort(reverse=True, key=lambda x: x["分数"])
print(stu_list)
3、 随机产生验证码 (数字+字母组合 6个)
如:A8VPai
'''
# 随机产生验证码 (数字+字母组合 6个)
# 如:A8VPai
:return:
'''
#大小字母组合
s=string.ascii_letters
# 保存产生的随机数
save_code =''
#循环6个
for i in range(6):
# 随机产生(0-5)6个数
num=random.randint(0,5)
#判断不等,就随机产生字母
if i!=num:
tmp=random.choice(s) #产生字母
else:
tmp=random.randint(0,9) #产生数字
#保存生成数据
save_code += str(tmp)
else:
print(save_code) 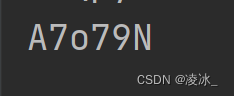
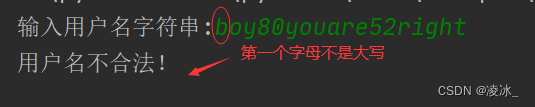
4、输入用户名是否合法,用户名必须有数字和字母组成,并且第一个字符是大写字母
例如,输入:boy80youare52right,输出 不合法! 输入:Boy80youare, 输出 合法!
'''
输入用户名是否合法,用户名必须有数字和字母组成,并且第一个字符是大写字母
例如,输入:boy80youare52right,输出 不合法! 输入:Boy80youare, 输出 合法!
:return:
'''
s = input('输入用户名字符串:')
#统计个数
s_letter=0
s_number=0
#判断第一个字符是大写字母
if s[0].isupper():
# 循环
for i in s:
# 判断
if i in string.ascii_letters:
s_letter += 1
elif i in string.digits:
s_number += 1
#判断是否是数子和字母组合
if s_number==0 or s_letter+s_number!=len(s):
print('用户名不合法!')
else:
print('合法!')
else:
print('用户名不合法!')

5、输入字符串,并获取字符串中汉字的个数。
例如:输入:hello展示有几个few汉字 输出:hello展示有几个few汉字的汉字个数:7
提示:汉字在这个范围内(大于等于\u4e00,小于等于\u9fa5)
'''
输入字符串,获取字符串中汉字的个数;
例如:输入:hello展示有几个few汉字 输出:hello展示有几个few汉字的汉字个数:7
提示:汉字在这个范围内(大于等于\u4e00,小于等于\u9fa5)
:return:
'''
info=input('输入字符串:')
c=0 #统计个数
#循环
for i in info:
#判断
if i >='\u4e00'and i<='\u9fa5':
c+=1 #累计次数
print(f'{info}的汉字个数:{c}')

6、 输入一句英文字符串,单词之间以空格为分隔符, 并且不包含,和.>;统计每个单词重复的单词出现的次数
输入: “hello java hello python”
输出:
hello 2
java 1
python 1
'''
输入一句英文字符串,单词之间以空格为分隔符, 并且不包含,和.>;统计每个单词重复的单词出现的次数
输入: “hello java hello python”
输出:
hello 2
java 1
python 1
'''
strs=input('输入一句英文句子:')
#字符串空格分割
ll=strs.split(" ")
#空字典
word={}
#循环
for i in ll:
# print(i)
#判断不在字典中
if i not in word:
word[i]=1
else: #存入加1
word[i]+=1
# print(word)
for k,v in word.items():
print(k,v)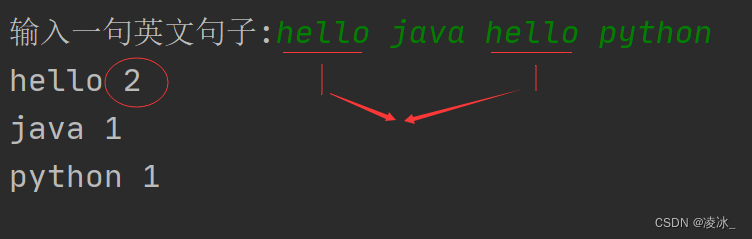



![[go学习笔记.第十六章.TCP编程] 3.项目-海量用户即时通讯系统-redis介入,用户登录,注册](https://img-blog.csdnimg.cn/ff1b037b8de9466799bc68a142bfe6d3.png)



![一天快速掌握Mybaits[一]](https://img-blog.csdnimg.cn/7f05fcbf919e43a995f797cfc438d945.png)