之前看很多网上大佬的防丢失的文章,文章中理论知识偏多,所以自己想着实践一下,实践过程中也踩了一些坑,因此写出了这篇文章。如果文章有误人子弟的地方,望在评论区指出。
导致消息出现丢失的原因

-
发送时失败,指发送端发送完消息准备到达消息队列的过程中,因网络波动、消息队列服务宕机等,消息队列服务无法接收消息,所以导致了丢失。
-
到达时宕机,消息队列服务接收到消息之后,如果没有开启持久化,消息会存储在内存中(当然内存吃紧的话,也会转入磁盘,缓解内存),如果这个时候服务挂了,那么内存中的消息就会丢失。
-
发送到消费端失败,消费端接收到了消息的时候,消费端服务挂了,而rabbitmq默认自动ack,也就是说rabbitmq发送到消费端,一旦认定了消费端接收了,无论有无消费成功,rabbitmq都认为是发送成功。
下面我们以这三种情况进行实践。
环境
jdk1.8 Spring boot 2.3.7.RELEASE Spring-boot-starter-amqp 2.3.7.RELEASE Rabbitmq 3.7.7
准备工作
我事先准备了好了交换机以及队列
-
交换机:message.log.test.exchange和message.log.test2.exchange
-
队列:message.loss.test.queue
其中message.loss.test.queue和message.log.test.exchange是绑定关系,而 message.log.test2.exchange没有绑定队列
1.发送时失败
发送时失败,rabbitmq有两种情况是属于发送时失败。
-
消息未到rabbitmq的交换机(exchange)
-
消息到达了rabbitmq的交换机(exchange),但是没有到达队列(queue)
第一种的解决方式是使用confirm机制。第二种解决方式则是使用return机制。
使用confirm机制
模拟场景
confirm机制是当发送端的消息没有到达rabbitmq的交换机(exchange)时,会触发confirm方法,告诉发送端该消息没有到达rabbitmq,需要做业务处理。 这里我们发送消息到rabbitmq不存在的交换机上,就可以模拟上述场景。
实现RabbitTemplate.ConfirmCallback接口
/**
* 当消息没有到达Rabbitmq的交换机时触发该方法(当然到达了也会触发,)
*/
@Component
public class ConfirmCallBack implements RabbitTemplate.ConfirmCallback {
@Resource
private RabbitTemplate rabbitTemplate;
@PostConstruct
public void init(){
rabbitTemplate.setConfirmCallback(this);
}
/**
*
* @param correlationData 消息属性体
* @param ack 是否成功,成功到达true,没有到达,false
* @param cause rabbitmq自身给的信息
*/
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
//第一个坑,如果发送端发送消息时没有对correlationData进行处理,conirm方法接收到的对象都会是null
//当接收失败并且correlationData对象为null,证明目前已经无法追溯回业务,可以做业务日志处理
if(!ack&&correlationData==null){
System.out.println(cause);
//日志处理。。。
return;
}
//如果接收失败
if(!ack){
System.out.println("消息Id:"+correlationData.getId());
Message message=correlationData.getReturnedMessage();
System.out.println("消息体:"+new String(message.getBody()));
//这里可以持久化业务消息体到数据库,然后定时去进行补偿处理或者重试等等
return;
}
//处理完成
}
}发送端代码
/**
* 消息的推送
* @return
*/
@PostMapping("push")
public boolean push(){
TestMessage testMessage=new TestMessage();
testMessage.setName("mq名称");
testMessage.setBusinessId("业务Id");
//定义CorrelationData对象以及消息属性。不然comfirm方法无论失败还是成功,CorrelationData参数永远是null
CorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString());
//传递业务数据
correlationData.setReturnedMessage(new Message(JSONObject.toJSON(testMessage).toString().getBytes(StandardCharsets.UTF_8),new MessageProperties()));
//发送消息(这里发送给了message.log.test.exchange11交换机,但实际rabbitmq并不存在)template.convertAndSend("message.log.test.exchange11","message_loss_test",testMessage,correlationData);
return true;
}这里是我踩的第一个坑,如果发送端不定义correlationData,那么confirm接收到的correlationData对象参数 都会是null
实现效果

使用return机制
模拟场景
当消息到达了rabbitmq的交换机的时候,但是又没有到达队列,那么就会触发return方法。 下面我们定义一个没有绑定队列的交换机,然后发送消息到交换机,就可以模拟上述场景
实现RabbitTemplate.ReturnCallback
/**
* 当消息没有到达Rabbitmq的队列时就会触发该方法
*/
@Component
public class ReturnCallBack implements RabbitTemplate.ReturnCallback {
@Resource
private RabbitTemplate rabbitTemplate;
@PostConstruct
public void init() {
rabbitTemplate.setReturnCallback(this);
}
/**
* @param message 消息体
* @param replyCode 返回代码
* @param replyText 返回文本
* @param exchange 交换机
* @param routingKey 发送方定义的路由key
*/
@Override
public void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) {
System.out.println("消息标识:" + message.getMessageProperties().getDeliveryTag());
String messageBody = null;
try {
messageBody = new String(message.getBody(), "UTF-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
System.out.println("消息:" + messageBody);
System.out.println(replyCode);
System.out.println(replyText);
System.out.println(exchange);
System.out.println(routingKey);
}
}发送端代码
/**
* 消息的推送
* @return
*/
@PostMapping("push2")
public boolean push2(){
TestMessage testMessage=new TestMessage();
testMessage.setName("mq名称2");
testMessage.setBusinessId("业务Id");
template.convertAndSend("message.log.test2.exchange","message_loss_test",JSONObject.toJSON(testMessage).toString());
return true;
}这里需注意消息体需要JSON序列化,不然returnedMessage方法接收的消息body会是乱码
实现效果

2.rabbitmq服务挂了,造成内存的消息丢失。
这个开启rabbitmq的持久化机制就好了,开启之后消息到达rabbitmq服务,会实时转入磁盘。这里怎么设置就不多说了,网上挺多文章可以解答。
不过即使开启了还是会有一种情况会造成消息丢失,那就是消息即将要持久化到磁盘的那一刻,服务挂了,就会造成丢失,不过这种情况我也不知道怎么模拟,所以就暂不实践了。
3.发送到消费端消费失败
上面提到默认情况下rabbitmq使用的是自动ack的方式,我们将它改成手动ack的方式,就可以解决这个问题。
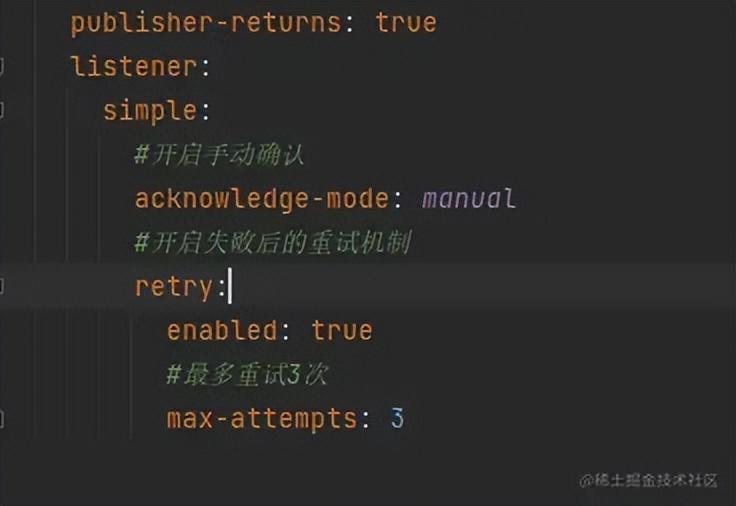
修改application.yml配置文件
rabbitmq:
listener:
simple:
#开启手动确认
acknowledge-mode: manual
#开启失败后的重试机制
retry:
enabled: true
#最多重试3次
max-attempts: 3效果

效果流程:
-
第一次用Postman请求之后,控制台显示了消息被消费的信号。
-
然后去查看rabbitmq后台管理刚刚被消费的消息以及变为Unacked
-
停止程序后(关闭消费端),过一阵子,后台管理显示消息变回了Ready,也就是说重新回到了队列。
-
重新启动程序(开启消费段),消息被重新消费。
总而言之,如果消费端没有做手动确认的操作,那么在消费端还没关闭之前,消息会变成Unacked,不会再次被消费,但一旦消费端关闭了,消息会重新回到队列,让消费端消费。
2.消费过程中,触发了未知异常,代码没有try catch
/**
* 消费
* @param testmessage 消息体
* @param message 消息属性
* @param channel mq通道对象
*/
@RabbitListener(queues = {"message.loss.test.queue"})
public void test(TestMessage testmessage, Message message, Channel channel) throws IOException {
System.out.println("消费testmessage消息:"+testmessage.getName());
//故意触发异常
if(!StringUtils.isEmpty(testmessage.getName())){
throw new RuntimeException("11211");
}
channel.basicAck(message.getMessageProperties().getDeliveryTag(),false);
}效果1

上面的效果图显示,我在触发了异常之后,消息重试了三次,也就是我在application.yml 配置的重试三次
如果我去掉重试机制会是什么效果。
效果2

效果和忘记做ack操作的效果一样,消息没有ack后,消息会变成Unacked状态,消费端关闭后消息会重新回到队列,然后重新链接的时候,就会再消费一次。