百度飞桨(paddlepaddle)是百度的开源深度学习平台,今天就利用paddle来编写入门级的手写数字模型.
一,准备数据
-
下载数据集,这里我们使用的是MNIST数据集
# 下载原始的 MNIST 数据集并进行解压 wget https://paddle-imagenet-models-name.bj.bcebos.com/data/mnist.tar tar -xf mnist.tar数据集的目录格式如下:
mnist. ├── train │ └── imgs │ ├── 0 │ ├── 1 │ ├── 2 │ ├── 3 │ ├── 4 │ ├── 5 │ ├── 6 │ ├── 7 │ ├── 8 │ └── 9 └── val └── imgs ├── 0 ├── 1 ├── 2 ├── 3 ├── 4 ├── 5 ├── 6 ├── 7 ├── 8 └── 9train和val目录下均有一个标签文件label.txt
- 定义数据加载模块,这里使用百度paddle提供paddle.io.Dataset来实现自定义的MyDataSet:
class MyDataSet(Dataset): def __init__(self, data_dir, label_path, tansform=None): super(MyDataSet, self).__init__() self.data_list = [] with open(label_path, encoding='utf-8') as f: for line in f.readlines(): image_path, label = line.split('\t') image_path = os.path.join(data_dir, image_path) self.data_list.append([image_path, label]) self.tansform = tansform def __getitem__(self, index): image_path, label = self.data_list[index] image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE) image = image.astype('float32') # 应用图像变换 if self.tansform is not None: self.tansform(image) label = int(label) return image, label def __len__(self): return len(self.data_list)
二,模型实现
这里我们参照LeNet进行实现,下面看一下LeNet的网络结构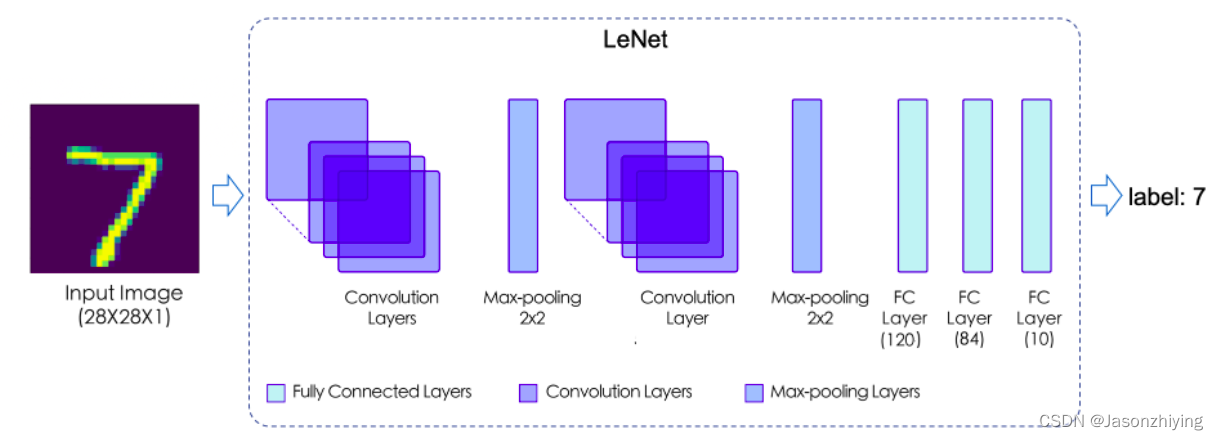
定义一个MyNet:
class MyNet(nn.Layer):
def __init__(self, num_classes=10):
super().__init__()
self.num_classes = num_classes
# 定义
self.conv1 = nn.Conv2D(1, 6, 3, stride=1, padding=1)
self.conv2 = nn.Conv2D(6, 16, 5, stride=1, padding=0)
self.relu = nn.ReLU()
self.features = nn.Sequential(
self.conv1,
self.relu,
nn.MaxPool2D(2, 2),
self.conv2,
self.relu,
nn.MaxPool2D(2, 2))
if num_classes > 0:
self.linear = nn.Sequential(
nn.Linear(400, 120),
nn.Linear(120, 84),
nn.Linear(84, num_classes)
)
def forward(self, x):
x = self.features(x)
if self.num_classes > 0:
x = paddle.flatten(x, 1)
x = self.linear(x)
return x
三,模型训练
# 定义一个网络
model = MyNet()
# 可视化模型组网结构和参数
params_info = paddle.summary(model, (1, 1, 28, 28))
print(params_info)这里定义一个MyNet的网络,然后查看网络的结构,下面开始进行模型训练
total_epoch = 5
batch_size = 16
# transform = F.normalize(mean=[127.5], std=[127.5], data_format=['CHW'])
transform = Normalize(mean=[127.5], std=[127.5], data_format=['CHW'])
# 训练集
data_dir_train = './mnist/train'
label_path_train = './mnist/train/label.txt'
# 加载数据
train_dataset = MyDataSet(data_dir_train, label_path_train, transform)
val_dataset = MyDataSet(data_dir_val, label_path_val, transform)
print(f'训练图片张数:{len(train_dataset)} 测试集图张数:{len(val_dataset)}')
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
optim = paddle.optimizer.Adam(parameters=model.parameters())
# 设置损失函数
loss_fn = paddle.nn.CrossEntropyLoss()
for epoch in range(total_epoch):
for batch_id, data in enumerate(train_loader):
x_data = data[0] # 训练数据
y_data = data[1] # 训练数据标签
# print(y_data)
# print(y_data.shape)
# 增加维度
x_data = paddle.unsqueeze(x_data, axis=1)
predicts = model(x_data) # 预测结果
# print(f'predicts:{predicts} predicts.shape={predicts.shape}')
y_data = paddle.unsqueeze(y_data, axis=1)
# 计算损失 等价于 prepare 中loss的设置
loss = loss_fn(predicts, y_data)
# 计算准确率 等价于 prepare 中metrics的设置
acc = paddle.metric.accuracy(predicts, y_data)
# 下面的反向传播、打印训练信息、更新参数、梯度清零都被封装到 Model.fit() 中
# 反向传播
loss.backward()
# print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id + 1, loss.numpy(),
# acc.numpy()))
if (batch_id + 1) % 100 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id + 1, loss.numpy(),
acc.numpy()))
write_to_log("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id + 1, loss.numpy(),
acc.numpy()))
# 更新参数
optim.step()
# 梯度清零
optim.clear_grad()
paddle.save(model.state_dict(), f'./mynet/mynet.ep{epoch}.pdparams')注意输入的数据的维度要与网络结构保持一致
四,模型推理
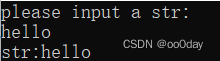
下面来看一下模型的效果:
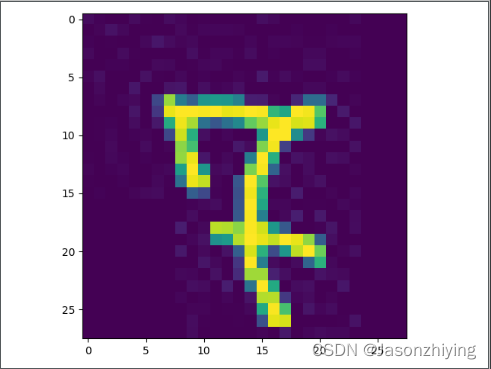
输出结果:


![[ZJCTF 2019]Login--动态调试--详细版](https://img-blog.csdnimg.cn/22e7eb7fe84d47d59ba16429d65c821b.png)

![[02] BLEMotion-Kit 基于QMI8658传感器使用加速度计进行倾斜检测](https://img-blog.csdnimg.cn/53cd452e32644dd3b299af7cc10539cc.gif#pic_center)