文章目录
- 前言
- 翻译到en
- 生成"伪"的、到英语的数据文件
- 把每一个zs语言对翻译到en
- 从fairseq-generate生成的文件中,抽取纯en文件
- 把en数据和所有zs语言对的tgt数据形成平行语料,然后做预处理
- 形成en到tgt的平行语料
- 预处理
- 在en到tgt语言的"伪"平行语料上评估pivot zs translation的性能
- direct zs translation VS pivot-based zs translation
前言
由于any2en和en2any的同时训练,一方面,encoder端将不同语种编码成国际语(靠近英语?);另一方面,decoder具备把encoder输出翻译成任意一种语言的能力,因此,multilingual translation model具备any2any的翻译能力。由于实际并没有使用除了以英语为中心以外的平行语料进行训练,这种翻译又被称为zero-shot translation。
multilingual translation model做zero-shot translation主要有两种方式:
- direct zs translation:即直接把要翻译的tgt语种告诉decoder,直接生成(会出现严重的off-target问题)
- pivot-based zs translation:即先把src翻译成en,再把en翻译成tgt(一个强zs translation baseline)
本文记录使用fairseq工具,完成pivot-based zs translation的代码步骤。考虑de-fr的pivot-based zero-shot translation,主要分为以下三步:
- 把de的语料翻译成en
- 对翻译得到的en做预处理,并和fr的语料组成平行语料
- 在en-fr的"伪"平行语料上评估zs translation的性能
本文使用opus100,考虑的zs语言对为:ar-de ar-fr ar-nl ar-ru ar-zh de-fr de-nl de-ru de-zh fr-nl fr-ru fr-zh nl-ru nl-zh ru-zh de-ar fr-ar nl-ar ru-ar zh-ar fr-de nl-de ru-de zh-de nl-fr ru-fr zh-fr ru-nl zh-nl zh-ru。
假设我们已经对zs的数据进行了bpe-encode,binarize(fairseq-preprocess)等操作,即,已经有zs数据的data-bin文件:
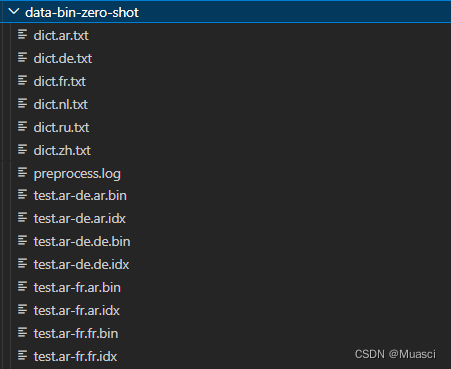
下面开始!
翻译到en
生成"伪"的、到英语的数据文件
我们首先使用上述的data-bin-zero-shot文件夹,对于每一个语言对(如ar-de),来生成一个"伪"的、到英语的数据文件(对应为ar-en)。
具体运行如下代码:
# general_scripts/opus100/create_pivot_data.py
import argparse
import os
import json
import shutil
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--zero-shot-data-bin', type=str, default="data/opus-100-corpus/v1.0/data-bin-zero-shot")
parser.add_argument('--save-path', type=str, default="data/opus-100-corpus/v1.0/fake-to-en-data-bin-zero-shot")
parser.add_argument('--zero-shot-langs', type=str, default="ar,de,fr,nl,ru,zh")
return parser.parse_known_args()[0]
def main():
opts = parse_opt()
zero_shot_data_bin = opts.zero_shot_data_bin
zero_shot_langs = opts.zero_shot_langs.split(",")
save_path = opts.save_path
for src in zero_shot_langs:
for tgt in zero_shot_langs:
if src == tgt:
continue
st_src, st_tgt = sorted([src, tgt])
lang_pair = f"{src}-{tgt}"
lang_pair_dir = os.path.join(save_path, lang_pair)
os.makedirs(lang_pair_dir, exist_ok = True)
# dict
old_path = os.path.join(zero_shot_data_bin, f"dict.{src}.txt")
new_path = os.path.join(save_path, lang_pair, f"dict.{src}.txt")
shutil.copyfile(old_path, new_path)
shutil.copyfile(new_path, os.path.join(save_path, lang_pair, f"dict.en.txt")) # fake
# bin
old_path = os.path.join(zero_shot_data_bin, f"test.{st_src}-{st_tgt}.{src}.bin")
new_path = os.path.join(save_path, lang_pair, f"test.{src}-en.{src}.bin")
shutil.copyfile(old_path, new_path)
shutil.copyfile(new_path, os.path.join(save_path, lang_pair, f"test.{src}-en.en.bin")) # fake
# idx
old_path = os.path.join(zero_shot_data_bin, f"test.{st_src}-{st_tgt}.{src}.idx")
new_path = os.path.join(save_path, lang_pair, f"test.{src}-en.{src}.idx")
shutil.copyfile(old_path, new_path)
shutil.copyfile(new_path, os.path.join(save_path, lang_pair, f"test.{src}-en.en.idx")) # fake
if __name__ == "__main__":
main()
还是以ar-de这个语言对为例,它对应、"伪"的、到英语的数据文件应有:dict.ar.txt, dict.en.txt, test.ar-en.ar.bin, test.ar-en.ar.idx, test.ar-en.en.bin, test.ar-en.en.idx,而从上述代码可以看到,里面的dict.ar.txt, test.ar-en.ar.bin, test.ar-en.ar.idx是从data-bin-zero-shot文件夹复制过来的真实的文件,关于en的文件则分别从ar的这三个文件直接copy过来,是伪数据。
后续我们使用fairseq-generate来生成en数据时,只会使用ar的数据dict.ar.txt, test.ar-en.ar.bin, test.ar-en.ar.idx来做实际的生成(我们需要),而en的伪数据dict.en.txt,test.ar-en.en.bin, test.ar-en.en.idx被用于打分(我们并不需要)。
得到的结果如下:
把每一个zs语言对翻译到en
上一步得到的fake-to-en-data-bin-zero-shot被用于这一步的生成,具体的生成使用的是fairseq-generate。
具体代码如下:
# evaluate_commond/generate_pivot_to_en.sh
for lang_pair in ar-de ar-fr ar-nl ar-ru ar-zh de-fr de-nl de-ru de-zh fr-nl fr-ru fr-zh nl-ru nl-zh ru-zh de-ar fr-ar nl-ar ru-ar zh-ar fr-de nl-de ru-de zh-de nl-fr ru-fr zh-fr ru-nl zh-nl zh-ru; do
src_tgt=($(echo $lang_pair | tr "-" "\n"))
src=${src_tgt[0]}
tgt=${src_tgt[1]}
CUDA_VISIBLE_DEVICES=0 python3 evaluate_commond/evaluate.py --config evaluate_commond/evaluate_zero_shot.yml \
--lang-pairs ${src}-en \
--data-bin ../../data/opus-100-corpus/v1.0/fake-en-centrial-data-bin-zero-shot/${src}-${tgt} \
--true-lang-pair ${src}-${tgt} \
--pivot
done
# evaluate_commond/evaluate.py 略
上面关键的参数为:
- lang-pairs:对于所有语言对,都是把这个语言对的src语言,翻译到en(实际的翻译方向)
- true-lang-pair:这个只是用来创建结果文件夹,保存翻译的结果
得到的翻译结果如下:
从fairseq-generate生成的文件中,抽取纯en文件
以上述pivot_results/ar-de/generate_ar-en.log为例,里面的内容如下:
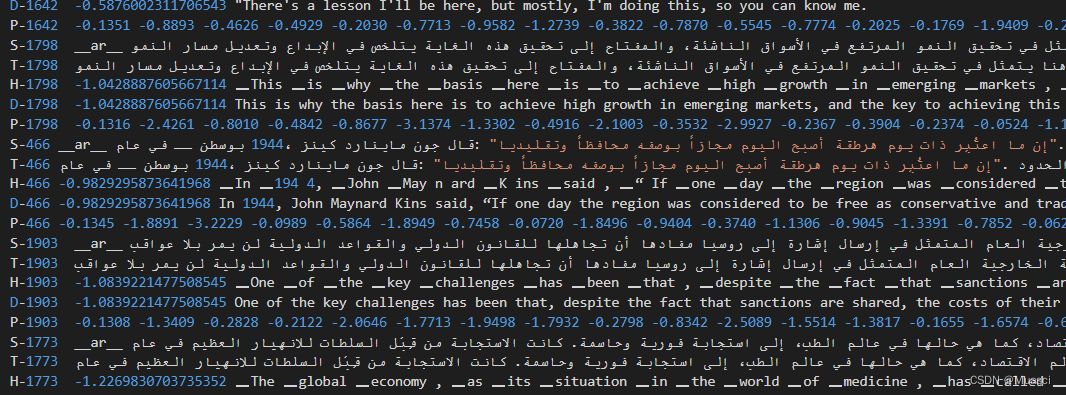
我们需要从中抽取D开头的纯en文本。具体使用的代码如下:
# general_scripts/opus100/extract_puretext_pivot.sh
#!/usr/bin/env bash
path="$1"
direction="$2"
for lang_pair in ar-de ar-fr ar-nl ar-ru ar-zh de-fr de-nl de-ru de-zh fr-nl fr-ru fr-zh nl-ru nl-zh ru-zh de-ar fr-ar nl-ar ru-ar zh-ar fr-de nl-de ru-de zh-de nl-fr ru-fr zh-fr ru-nl zh-nl zh-ru; do
echo ${lang_pair}
src_tgt=($(echo $lang_pair | tr "-" "\n"))
tmp1=${src_tgt[0]}
tmp2=${src_tgt[1]}
lp1=${tmp1}-${tmp2}
lp2=${tmp2}-${tmp1}
outprefix=${path}/${lp1}
genpath=${outprefix}/generate_${tmp1}-en.log
hyppath=${outprefix}/en
grep -P "^D" ${genpath} | LC_ALL=C sort -V | cut -f 3- > ${hyppath}
done
需要注意的是,fairseq-generate得到的generate_xxx-en.log文件中,结果是按照句子长度排序的,所以需要使用LC_ALL=C sort -V来按照D后面的sample-id来把它恢复到原来的顺序。如下文件:

至此,我们完成了第一步骤。
把en数据和所有zs语言对的tgt数据形成平行语料,然后做预处理
我们拿到了上面的pivot_results文件夹,该文件夹的下一级文件夹以zs语言对为命名,每一个zs语言对文件夹里面的en文件,为这个zs语言对的src数据,翻译过来的en纯文本数据。
对于每一个语言对,我们接下来需要把en纯文本数据和这个语言对的tgt端数据形成平行语料,然后做预处理。
形成en到tgt的平行语料
具体使用如下代码:
# data/opus-100-corpus/v1.0/create_en_to_pivot_data.py
import argparse
import os
import json
import shutil
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--zero-shot-path', type=str, default="zero-shot")
parser.add_argument('--generated-en-path', type=str, default="pivot_results")
parser.add_argument('--save-path', type=str, default="en_to_pivot_data")
parser.add_argument('--zero-shot-langs', type=str, default="ar,de,fr,nl,ru,zh")
return parser.parse_known_args()[0]
def main():
opts = parse_opt()
zero_shot_path = opts.zero_shot_path
generated_en_path = opts.generated_en_path
zero_shot_langs = opts.zero_shot_langs.split(",")
save_path = opts.save_path
for src in zero_shot_langs:
for tgt in zero_shot_langs:
if src == tgt:
continue
st_src, st_tgt = sorted([src, tgt])
lang_pair = f"{src}-{tgt}"
lang_pair_dir = os.path.join(save_path, lang_pair)
os.makedirs(lang_pair_dir, exist_ok = True)
# en
old_path = os.path.join(generated_en_path, lang_pair, "en")
new_path = os.path.join(lang_pair_dir, f"opus.en-{tgt}-test.en")
shutil.copyfile(old_path, new_path)
# tgt
old_path = os.path.join(zero_shot_path, f"{st_src}-{st_tgt}", f"opus.{st_src}-{st_tgt}-test.{tgt}")
new_path = os.path.join(lang_pair_dir, f"opus.en-{tgt}-test.{tgt}")
shutil.copyfile(old_path, new_path)
if __name__ == "__main__":
main()
从而得到平行语料:
预处理
就是正常做bpe-encode和binarize,使用代码如下:
# data/opus-100-corpus/v1.0/encode-spm-pivot.sh
bpe=bpe-pivot
tmp=tmp
rm -r $bpe
mkdir -p $bpe
# apply bpe
for file_name in ar-de ar-fr ar-nl ar-ru ar-zh de-fr de-nl de-ru de-zh fr-nl fr-ru fr-zh nl-ru nl-zh ru-zh de-ar fr-ar nl-ar ru-ar zh-ar fr-de nl-de ru-de zh-de nl-fr ru-fr zh-fr ru-nl zh-nl zh-ru;do
echo ${file_name}
src_tgt=($(echo $file_name | tr "-" "\n"))
src=${src_tgt[0]}
tgt=${src_tgt[1]}
mkdir ${bpe}/${file_name}
python fairseq/scripts/spm_encode.py \
--model ${tmp}/spm.bpe.model \
--output_format=piece \
--inputs en_to_pivot_data/${file_name}/opus.en-${tgt}-test.en en_to_pivot_data/${file_name}/opus.en-${tgt}-test.${tgt} \
--outputs ${bpe}/${file_name}/test.en-${tgt}.bpe.en ${bpe}/${file_name}/test.en-${tgt}.bpe.${tgt}
done
# data/opus-100-corpus/v1.0/binarize-pivot.sh
#!/usr/bin/env bash
# create share dict
path=data-bin-pivot
rm -r $path
mkdir -p $path
#for lang in ar de es fa he it nl pl en; do
# cp $path/dict.txt $path/dict.${lang}.txt
#done
#be nb km mt ur sv es lt rw gu pt tk or ml da mr eo sq id ro oc et uk fa br zu vi dz pl yi ig tt af yo lv hu sh el mk ga te ta de ky fy se bs fr kn hy nn pa as mg it zh fi mn li ne am ug uz ru ja bn ku eu hi sr my kk xh cy cs ka sk is hr ps az ko no tg he si gd an wa ha th sl ms ar ca bg gl nl; do
for lang_pair in ar-de ar-fr ar-nl ar-ru ar-zh de-fr de-nl de-ru de-zh fr-nl fr-ru fr-zh nl-ru nl-zh ru-zh de-ar fr-ar nl-ar ru-ar zh-ar fr-de nl-de ru-de zh-de nl-fr ru-fr zh-fr ru-nl zh-nl zh-ru; do
echo ${lang_pair}
mkdir $path/${lang_pair}
src_tgt=($(echo $lang_pair | tr "-" "\n"))
src=${src_tgt[0]}
tgt=${src_tgt[1]}
fairseq-preprocess \
--source-lang en --target-lang $tgt \
--testpref bpe-pivot/${lang_pair}/test.en-${tgt}.bpe \
--destdir $path/${lang_pair} \
--srcdict data-bin/dict.txt \
--tgtdict data-bin/dict.txt
done
从而得到了第三步需要用的到,从en到tgt语言的data-bin文件夹:
在en到tgt语言的"伪"平行语料上评估pivot zs translation的性能
这一步和第一步的“ 把每一个zs语言对翻译到en”类似,我们使用如下代码:
# evaluate_commond/evaluate_pivot.sh
for lang_pair in ar-de ar-fr ar-nl ar-ru ar-zh de-fr de-nl de-ru de-zh fr-nl fr-ru fr-zh nl-ru nl-zh ru-zh de-ar fr-ar nl-ar ru-ar zh-ar fr-de nl-de ru-de zh-de nl-fr ru-fr zh-fr ru-nl zh-nl zh-ru; do
src_tgt=($(echo $lang_pair | tr "-" "\n"))
src=${src_tgt[0]}
tgt=${src_tgt[1]}
CUDA_VISIBLE_DEVICES=0 python3 evaluate_commond/evaluate.py --config evaluate_commond/evaluate_zero_shot.yml \
--lang-pairs en-$tgt \
--data-bin ../../data/opus-100-corpus/v1.0/fake-en-to-data-bin-zero-shot/${src}-${tgt} \
--true-lang-pair ${src}-${tgt} \
--pivot
done
# evaluate_commond/evaluate.py 略
至此,我们得到了pivot based zs translation的最终结果文件,如下图中的"generate_en-de.log":
direct zs translation VS pivot-based zs translation
最终,我们比较了用multilingual translation model来1. direct zs translation;2. pivot-based zs translation的结果对比:
- direct:BLEU:4.52 | LANG_ACC:28.85%
- pivot:BLEU:14.61| LANG_ACC:87.76%
可以看到,pivot-based zs translation是一个强baseline。





![[MySQL]-删库后恢复](https://img-blog.csdnimg.cn/d21f7d1a889d48ae96b3a0bc06be62a0.png#pic_center)