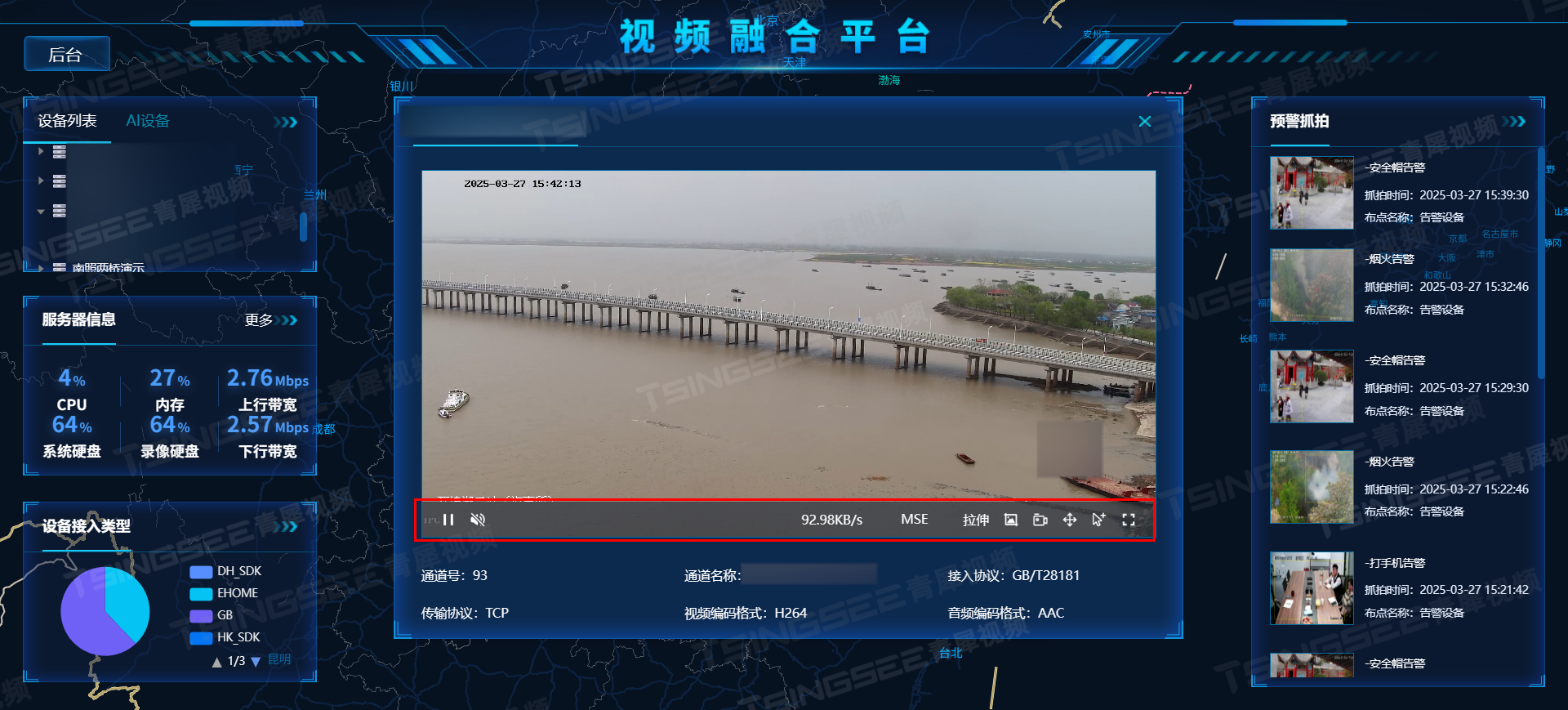
核心六步
一、数据准备
二、模型构建
三、模型训练
四、模型验证
五、模型优化
六、模型推理
一、数据准备:深度学习的基石
数据是模型的“燃料”,其质量直接决定模型上限。核心步骤包括:
1. 数据收集与标注
- 来源:公开数据集(如ImageNet、MNIST)、网络爬取、传感器采集、人工标注(如图片分类标签、文本情感标注)。
- 标注要求:标签准确性(避免噪声)、标注一致性(多人标注需校准)、标注完整性(覆盖所有目标类别)。
- 数据形态:结构化数据(表格、数值)、非结构化数据(图像、文本、音频、视频),需根据任务类型(分类、回归、生成、NLP等)适配。
2. 数据清洗
- 去噪:删除重复样本、处理缺失值(插值、删除)、过滤异常值(统计方法或算法检测)。
- 格式统一:图像尺寸归一化(如224x224)、文本分词与序列化(如BERT的Tokenization)、音频采样率统一。
- 平衡处理:解决类别不平衡(过采样SMOTE、欠采样、生成少数类样本)。
3. 数据预处理
- 特征工程(针对结构化数据):归一化(Min-Max)、标准化(Z-Score)、独热编码(One-Hot)、特征选择(相关性分析、PCA降维)。
- 模态处理(针对非结构化数据):
- 图像:灰度化、缩放、通道转换(RGB转BGR)、添加噪声/模糊增强泛化性。
- 文本:词嵌入(Word2Vec、GloVe)、位置编码(Transformer)、截断/填充(固定序列长度)。
- 音频:梅尔频谱转换、MFCC特征提取。
4. 数据增强(关键提效手段)
- 图像增强:翻转、旋转、裁剪、亮度/对比度调整、MixUp/CutOut数据合成。
- 文本增强:同义词替换、随机删除/插入、回译(机器翻译增强)。
- 目的:扩大数据集规模、减少过拟合、增强模型鲁棒性。
5. 数据集划分
- 训练集(60-80%):用于模型参数学习。
- 验证集(10-20%):训练中评估模型,调整超参数(避免用测试集调参导致数据泄漏)。
- 测试集(10-20%):最终评估模型泛化能力,需与训练集独立同分布(i.i.d.)。
二、模型构建:架构设计与组件选择
根据任务目标设计网络结构,核心要素包括:
1. 模型架构选择
- 经典范式:
- CV领域:CNN(LeNet、ResNet残差网络、ViT视觉Transformer)。
- NLP领域:RNN/LSTM(序列建模)、Transformer(自注意力机制,BERT/GPT基础)。
- 生成任务:GAN(生成对抗网络)、VAE(变分自编码器)。
- 多模态:跨模态融合模型(如CLIP图文对齐)。
- 设计原则:复杂度匹配数据规模(避免小数据用大模型导致过拟合)、计算资源适配(移动端用轻量模型如MobileNet)。
2. 网络层设计
- 基础层:输入层(适配数据维度)、输出层(分类用Softmax,回归用Linear)。
- 功能层:
- 卷积层(CNN提取空间特征)、池化层(降维)、全连接层(特征映射)。
- 注意力层(Self-Attention捕捉长距离依赖)、归一化层(Batch Normalization稳定训练)。
- 激活层(ReLU/Sigmoid/Tanh引入非线性)。
- 正则化层:Dropout(随机失活防过拟合)、权重衰减(L2正则化)。
3. 损失函数与优化目标
- 分类任务:交叉熵损失(Cross-Entropy,多分类用Softmax+CE,二分类用BCELoss)。
- 回归任务:均方误差(MSE)、平均绝对误差(MAE)。
- 生成任务:对抗损失(GAN)、重构损失(VAE)。
- 多任务学习:联合损失加权求和(如分类+回归的混合损失)。
4. 优化器配置
- 经典算法:SGD(随机梯度下降)、Adam(自适应学习率,结合动量和RMSprop)、RMSprop(处理非平稳目标)。
- 超参数:学习率(需衰减策略,如余弦退火)、批次大小(Batch Size,影响训练稳定性)、动量参数(加速收敛)。
三、模型训练:参数学习与过程控制
将数据输入模型,通过优化算法更新参数,核心流程如下:
1. 训练循环(Training Loop)
- 前向传播:输入数据经网络计算输出预测值( y ^ \hat{y} y^)。
- 损失计算:对比预测值与真实标签( y y y),得到损失函数值( L L L)。
- 反向传播:利用链式法则计算损失对各层参数的梯度( ∇ L \nabla L ∇L)。
- 参数更新:优化器根据梯度调整参数(如 w ← w − η ∇ w w \leftarrow w - \eta \nabla w w←w−η∇w, η \eta η为学习率)。
2. 批量处理(Batch Processing)
- 小批量梯度下降(Mini-Batch SGD):每次处理一个Batch(如32/64/128样本),平衡计算效率与梯度稳定性。
- 数据加载:使用数据加载器(DataLoader)异步读取数据,支持并行处理(如PyTorch的Dataloader)。
3. 过拟合与欠拟合处理
- 过拟合(高方差):训练损失低但验证损失高。
- 解决方案:增加数据增强、早停(Early Stopping)、正则化(Dropout/L2)、模型简化(减小网络规模)。
- 欠拟合(高偏差):训练损失高,模型未学到关键特征。
- 解决方案:复杂模型(更深网络)、调整超参数(增大学习率)、检查数据质量(是否标注错误)。
4. 训练监控与日志
- 指标记录:训练/验证损失、准确率、F1值、AUC-ROC等。
- 可视化工具:TensorBoard(记录曲线)、W&B(Weights & Biases,追踪超参数与结果)。
- 异常检测:梯度爆炸/消失(用梯度裁剪、权重初始化改进,如Xavier初始化)。
四、模型验证:评估泛化能力与调优
通过独立数据集检验模型效果,核心步骤:
1. 验证集评估
- 单次划分:固定训练/验证/测试集,适用于数据充足场景。
- 交叉验证(Cross-Validation):
- K折交叉验证(K-Fold):将数据分为K份,每次用K-1份训练,1份验证,降低随机性影响。
- 留一法(Leave-One-Out):极端K折(K=N,N为样本数),计算成本高,适用于小数据集。
2. 评估指标(依任务类型选择)
- 分类任务:准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1-Score、混淆矩阵、AUC-ROC。
- 回归任务:MSE、MAE、R²分数(拟合度)。
- 生成任务:Inception Score(IS,图像质量与多样性)、Frechet Inception Distance(FID,生成分布与真实分布的距离)。
- NLP任务:BLEU分数(机器翻译)、ROUGE(文本摘要)、困惑度(Perplexity,语言模型)。
3. 超参数调优
- 搜索策略:
- 网格搜索(Grid Search,穷举指定范围,精度高但耗时)。
- 随机搜索(Random Search,高效探索重要超参数,如学习率)。
- 贝叶斯优化(Bayesian Optimization,动态调整搜索方向,适合高成本任务)。
- 关键超参数:网络层数/神经元数、学习率、Batch Size、Dropout率、正则化系数。
4. 模型选择与集成
- 单模型优化:选择验证集表现最佳的模型版本(如保存最低验证损失的Checkpoint)。
- 模型集成:提升效果(如Bagging、Boosting、Stacking,多模型预测结果融合)。
五、模型优化:从训练到部署的桥梁
在验证后对模型进行针对性改进,提升实用性:
1. 模型压缩(针对部署场景)
- 参数剪枝:删除低重要性连接(如L1正则化筛选权重,结构化剪枝裁剪整个神经元/层)。
- 量化:降低参数精度(32位浮点→16位/8位整数,甚至二值化,减少计算量)。
- 知识蒸馏(Knowledge Distillation):用教师模型(大模型)输出软标签指导学生模型(小模型)训练,保留知识。
2. 硬件适配优化
- 算子优化:针对GPU/TPU/NPU等硬件加速库(如TensorRT、ONNX Runtime)优化计算图。
- 模型轻量化:设计高效架构(MobileNet的深度可分离卷积、ShuffleNet通道洗牌)。
3. 鲁棒性增强
- 对抗训练:在输入中添加对抗扰动(如FGSM攻击生成样本),提升模型抗干扰能力。
- 领域适应:迁移学习(预训练模型微调)解决训练/测试数据分布差异(如跨域图像分类)。
六、模型推理:从部署到实际应用
将训练好的模型转化为可服务的系统,核心步骤:
1. 模型保存与加载
- 格式:PyTorch的.pth/.pt、TensorFlow的SavedModel/Checkpoint、通用格式ONNX(跨框架兼容)。
- 权重与架构:保存完整模型(含架构)或仅权重(需代码重建架构,更轻量)。
2. 输入处理
- 预处理适配:与训练时一致(如图像归一化、文本Tokenization),确保输入维度匹配模型预期。
- 批处理支持:支持批量推理提升吞吐量(如一次处理多个样本)。
3. 推理服务部署
- 部署形态:
- 服务器端:REST API(Flask/FastAPI)、gRPC(高性能RPC)、模型服务框架(TensorFlow Serving、TorchServe)。
- 移动端/边缘端:转换为ONNX/TFLite/NNAPI格式,适配手机/嵌入式设备(如iOS Core ML、Android NNAPI)。
- 性能优化:
- 延迟(Latency):优化计算图(去除冗余节点)、并行计算。
- 吞吐量(Throughput):增大Batch Size、模型并行/数据并行。
4. 输出后处理
- 结果解析:分类任务映射标签名称、生成任务解码(如NLP的Token转文本)。
- 置信度过滤:设定阈值过滤低置信度预测(如目标检测过滤低分数边界框)。
5. 实时监控与迭代
- 在线指标:推理延迟、吞吐量、错误率、真实场景准确率(A/B测试)。
- 持续迭代:收集新数据重新训练(增量学习),更新模型以适应数据分布变化。
核心环节总结与关键挑战
| 环节 | 核心目标 | 关键技术/挑战 |
|---|---|---|
| 数据准备 | 高质量、适配任务的数据 | 标注成本、数据不平衡、隐私合规(如GDPR) |
| 模型构建 | 设计高效架构与目标函数 | 架构创新(如Transformer)、损失函数设计 |
| 模型训练 | 高效稳定地学习参数 | 梯度消失/爆炸、过拟合、训练效率(分布式训练) |
| 模型验证 | 评估泛化能力与调优 | 评估指标合理性、超参数搜索复杂度 |
| 模型优化 | 提升实用性与部署适配 | 压缩算法效率、硬件算子优化 |
| 模型推理 | 可靠高效的实际应用 | 部署兼容性、实时性要求、安全攻击(对抗样本) |
深度学习的核心环节是一个闭环系统,每个步骤都需要结合任务特性、数据规模、计算资源进行精细化调整。从学术研究到工业落地,关键在于平衡模型性能、效率与实用性,而持续的迭代优化(如结合实时反馈更新模型)是保持模型生命力的关键。
深度学习一般流程框架概览
一、问题定义与目标明确(10%)
1. 任务类型定位
- 基础任务分类:
- 监督学习:分类(二分类/多分类,Softmax输出)、回归(连续值预测,MSE损失)
- 无监督学习:聚类(K-means)、降维(Autoencoder)、生成(GAN/VAE)
- 半监督学习:结合少量标注数据+大量无标注数据(伪标签技术)
- 强化学习:序列决策(AlphaGo,状态-动作空间建模)
- 领域特定任务:
- 计算机视觉:图像分类/检测/分割(YOLO/FCN)、视频理解(3D CNN)
- 自然语言处理:文本分类/生成(Transformer)、机器翻译(Seq2Seq)、NER命名实体识别
- 语音处理:语音识别(CTC损失)、语音合成(Tacotron)
- 结构化数据:推荐系统(矩阵分解+DNN)、金融风控(逻辑回归+Embedding)
2. 评估指标设计
- 分类任务:准确率/精确率/召回率/F1-score、AUC-ROC(不平衡数据)
- 回归任务:MSE/MAE/R2-score、RMSE(量纲敏感)
- 生成任务:IS(Inception Score)、FID(Frechet Inception Distance)、人工审美评估
- 时序任务:时序交叉验证、动态时间规整(DTW)距离
- 多目标优化:帕累托最优解(Pareto Front),加权损失函数设计
3. 可行性分析
- 数据可行性:标注成本(医疗影像需专家标注)、数据规模(小数据用迁移学习,大数据用原生模型)
- 计算资源:GPU显存需求(大模型需32GB+显存,分布式训练规划)
- 业务约束:延迟要求(实时推荐需<100ms,离线训练可放宽)、合规性(GDPR数据隐私)
二、数据工程(25%)
1. 数据收集与标注
- 数据来源:
- 公开数据集(ImageNet/CIFAR-100)、网络爬取(需注意版权)、传感器采集(IoT设备)
- 数据增强生成(GAN合成数据,用于数据稀缺场景)
- 标注流程:
- 标注工具:CVAT(图像标注)、Label Studio(多模态标注)、Prodigy(主动学习标注)
- 质量控制:多人标注一致性检查(Kappa系数)、标注错误清洗(异常样本检测)
2. 数据预处理
- 结构化数据:
- 缺失值处理:删除(高缺失率)、插值(均值/中位数/回归插值)
- 特征工程:独热编码(One-Hot,低基数类别)、嵌入编码(Embedding,高基数类别)
- 标准化:Z-score(特征均值方差归一化)、归一化(Min-Max缩放到[0,1])
- 非结构化数据:
- 图像:Resize/Crop(保持长宽比)、灰度化(RGB转单通道)、通道标准化(减均值除标准差)
- 文本:分词(BPE子词分割)、序列填充(Padding到固定长度)、词向量生成(Word2Vec/GloVe)
- 音频:梅尔频谱图转换(MFCC特征)、降噪(谱减法)、重采样(统一采样率)
3. 数据划分与增强
- 数据集划分:
- 标准划分:训练集(60%)+验证集(20%)+测试集(20%)
- 时序数据:时间序列划分(按时间顺序,避免随机划分)
- 分层抽样:保持类别分布一致(适用于不平衡数据)
- 数据增强技术:
- 图像:翻转/旋转/缩放、CutOut(随机遮挡)、MixUp(样本混合)、AutoAugment(自动搜索增强策略)
- 文本:同义词替换、随机删除/插入、EDA(Easy Data Augmentation)
- 通用:对抗样本生成(FGSM对抗训练,提升鲁棒性)
三、模型架构设计(20%)
1. 基础网络组件
- 核心层类型:
- 卷积层:2D Conv(图像)、3D Conv(视频)、转置卷积(上采样)
- 循环层:LSTM/GRU(解决梯度消失)、双向RNN(捕捉双向依赖)
- 注意力层:Self-Attention(Transformer核心)、多头注意力(Multi-Head)、全局注意力(Global Attention)
- 归一化层:BatchNorm(训练阶段用批量统计量)、LayerNorm(逐层归一化,适合NLP)、InstanceNorm(图像生成)
- 激活函数:ReLU(避免梯度饱和)、Swish(自门控激活)、GELU(平滑ReLU变体)
- 网络范式:
- CNN家族:ResNet(残差连接解决梯度退化)、DenseNet(密集连接加强特征流动)、EfficientNet(复合缩放优化)
- RNN家族:Transformer(位置编码替代循环结构)、LSTM-CRF(序列标注任务)、Temporal Convolution Network(TCN,因果卷积处理时序数据)
- 生成模型:GAN(生成器+判别器对抗训练)、VAE(变分下界优化)、Diffusion Model(去噪扩散过程)
- 多模态模型:ViT(图像Transformer)、CLIP(图文对比学习)、多模态融合(早期融合/晚期融合架构)
2. 架构设计策略
- 迁移学习:
- 冻结预训练层:仅训练分类头(小数据场景)
- 微调全模型:在目标任务上更新所有参数(数据充足时)
- 预训练范式:自监督学习(SimCLR对比学习)、掩码语言模型(BERT)
- 模型变体选择:
- 轻量模型:MobileNet(深度可分离卷积)、ShuffleNet(通道洗牌降低计算量)
- 分布式架构:数据并行(多卡复制模型,同步/异步梯度更新)、模型并行(分层拆分模型到不同设备)
- 自动化设计:
- 神经架构搜索(NAS):强化学习/进化算法搜索最优网络结构
- 超参数优化:网格搜索(全枚举)、贝叶斯优化(高斯过程建模)、随机搜索(高效处理高维空间)
四、训练配置与优化(15%)
1. 训练参数设置
- 优化器选择:
- 基础优化器:SGD(带动量)、Adam(自适应学习率)、RMSprop(均方根传播)
- 改进版本:AdamW(权重衰减解耦)、AdaFactor(内存高效,适合大模型)
- 损失函数设计:
- 分类:交叉熵损失(CE)、焦点损失(Focal Loss,难例挖掘)
- 回归:L1/L2损失、Huber损失(鲁棒回归,结合L1/L2)
- 度量学习:三元组损失(Triplet Loss,样本间距约束)
- 多任务:硬参数共享(底层共享,顶层任务特定)、动态权重平衡(梯度归一化)
- 超参数空间:
- 网络参数:层数/通道数/隐藏单元数
- 训练参数:Batch Size(大batch需更大学习率)、Epoch数、学习率调度(余弦退火/阶梯衰减)
- 正则化:Dropout(随机失活神经元)、Weight Decay(L2正则)、Early Stopping(验证集早停)
2. 训练过程实现
- 正向传播:输入经网络计算得到logits/预测值,关键在于计算图构建(静态图TF vs 动态图PyTorch)
- 反向传播:自动微分(Autograd)计算梯度,注意梯度裁剪(防止爆炸)、混合精度训练(FP16减少显存占用)
- 分布式训练:
- 数据并行:DP(单卡控制) vs DDP(多卡独立计算,梯度同步)
- 模型并行:跨设备拆分模型层(适合超大模型,如GPT-3的MoE架构)
- 训练监控:
- 指标可视化:TensorBoard(损失/准确率曲线)、Weights & Biases(W&B,实验跟踪)
- 异常检测:梯度消失(接近0的梯度)、梯度爆炸(NaN/inf值)、训练-验证损失倒挂(过拟合信号)
五、模型评估与调试(10%)
1. 评估协议
- 标准流程:
- 在验证集调参(避免测试集数据泄漏)
- 最终在测试集报告泛化性能
- 交叉验证:K折交叉(小数据增强评估稳定性)
- 特殊场景处理:
- 不平衡数据:分层抽样+类别加权损失
- 时序数据:滚动预测(Rolling Forecast)评估长期预测能力
- 多标签分类:汉明损失、Jaccard系数
2. 深度分析技术
- 可视化工具:
- 图像:类激活图(CAM)、梯度加权类激活图(Grad-CAM)定位关键区域
- 文本:注意力热力图(Transformer层可视化)、词重要性排序(SHAP值/梯度权重)
- 结构化数据:特征重要性分析(Permutation Importance)、SHAP/LIME模型解释
- 误差分析:
- 混淆矩阵:识别易混淆类别(如“狗”误判“猫”)
- 错误样本集:手动标注错误类型(数据噪声/模型偏差/边界情况)
- 对抗样本测试:评估模型鲁棒性(FGSM/PGD攻击下的准确率下降幅度)
六、优化迭代(10%)
1. 模型优化策略
- 超参数调优:
- 贝叶斯优化:适用于非凸空间,利用历史数据减少评估次数
- 随机搜索:在高维空间效率优于网格搜索,重点搜索关键参数
- 自动化工具:Optuna(支持分布式调优)、Ray Tune(大规模并行)
- 架构调整:
- 增加容量:深层网络(解决欠拟合)、增大通道数/添加残差连接
- 减少过拟合:更强的数据增强、更大Dropout率、知识蒸馏(Teacher-Student模型)
- 跨模态融合:引入辅助任务(多任务学习提升主任务性能)
- 数据优化:
- 难例挖掘:主动学习(查询模型不确定样本进行标注)
- 数据清洗:识别并删除离群样本(基于马氏距离/孤立森林)
- 增量学习:处理概念漂移(在线学习+模型更新策略)
2. 重训练策略
- 热启动:加载历史最佳模型参数继续训练(避免从头开始)
- 课程学习:从简单样本逐步过渡到复杂样本(提升训练稳定性)
- 模型融合:
- 集成方法:Bagging(降低方差)、Boosting(提升偏差)、Stacking(多层模型组合)
- 模型平均:加权平均(验证集表现加权)、Snapshot Ensembles(不同训练轨迹模型平均)
七、部署与生产化(5%)
1. 模型转换与优化
- 格式转换:
- PyTorch转ONNX(跨框架兼容)、TensorFlow转TensorRT(GPU推理加速)
- 量化技术:FP32→FP16→INT8(减少显存占用,提升推理速度)
- 推理优化:
- 图优化:常量折叠(Constant Folding)、算子融合(Operator Fusion)
- 硬件适配:GPU优化(CUDA核融合)、TPU专用算子(Google Edge TPU)
- 轻量化:模型剪枝(结构化剪枝/非结构化剪枝)、知识蒸馏(Student模型部署)
2. 部署架构设计
- 服务化部署:
- 框架选择:TensorFlow Serving(高性能)、Flask/FastAPI(灵活定制)、TorchServe(PyTorch原生支持)
- 容器化:Docker镜像打包(环境一致性)、Kubernetes集群管理(弹性扩缩容)
- 端侧部署:
- 移动端:Core ML(iOS)、NNAPI(Android)、TensorFlow Lite(跨平台)
- 嵌入式:NCNN/MNN(轻量级推理框架,低内存占用)
- 监控体系:
- 性能监控:延迟/吞吐量/显存占用(Prometheus+Grafana)
- 数据监控:输入数据分布漂移(KS检验)、概念漂移检测(模型预测概率分布变化)
- 异常处理:熔断机制(过载保护)、灰度发布(A/B测试新旧版本)
八、持续迭代(5%)
1. 模型生命周期管理
- 版本控制:DVC(数据版本控制)+模型注册表(MLflow Model Registry)
- 再训练策略:定时再训练(按周期)vs 触发式再训练(漂移检测到阈值)
- 伦理考量:
- 公平性:检测预测偏差(不同群体的准确率差异)、对抗偏见算法(Reweighting样本)
- 可解释性:满足医疗/金融等领域的可解释性要求(SHAP/LIME强制解释)
- 隐私保护:联邦学习(本地训练,参数聚合)、差分隐私(数据扰动保护个体隐私)
2. 工程化工具链
- 实验管理:Weights & Biases(跟踪超参数/指标/代码版本)
- 自动化ML:AutoKeras(自动化模型开发)、H2O.ai(低代码AI平台)
- MLOps实践:CI/CD流水线(模型训练→评估→部署自动化)、模型监控报警(Slack/DingTalk通知)
知识体系图谱
深度学习流程
├─ 问题定义(任务/指标/可行性)
├─ 数据工程(收集/清洗/增强/划分)
├─ 模型设计(组件/架构/迁移学习)
├─ 训练配置(优化器/损失/超参数)
├─ 训练过程(正向/反向/分布式)
├─ 模型评估(协议/分析/可视化)
├─ 优化迭代(调优/架构/数据优化)
├─ 部署上线(转换/推理/监控体系)
└─ 持续迭代(版本/伦理/工程化)
上述流程涵盖从问题建模到生产部署的全生命周期,包括经典算法(CNN/RNN/Transformer)、训练技巧(正则化/数据增强/优化器)、工程实践(分布式训练/模型量化/部署框架)、前沿技术(自监督学习/神经架构搜索/联邦学习),并涉及数据偏差、可解释性等现代挑战。