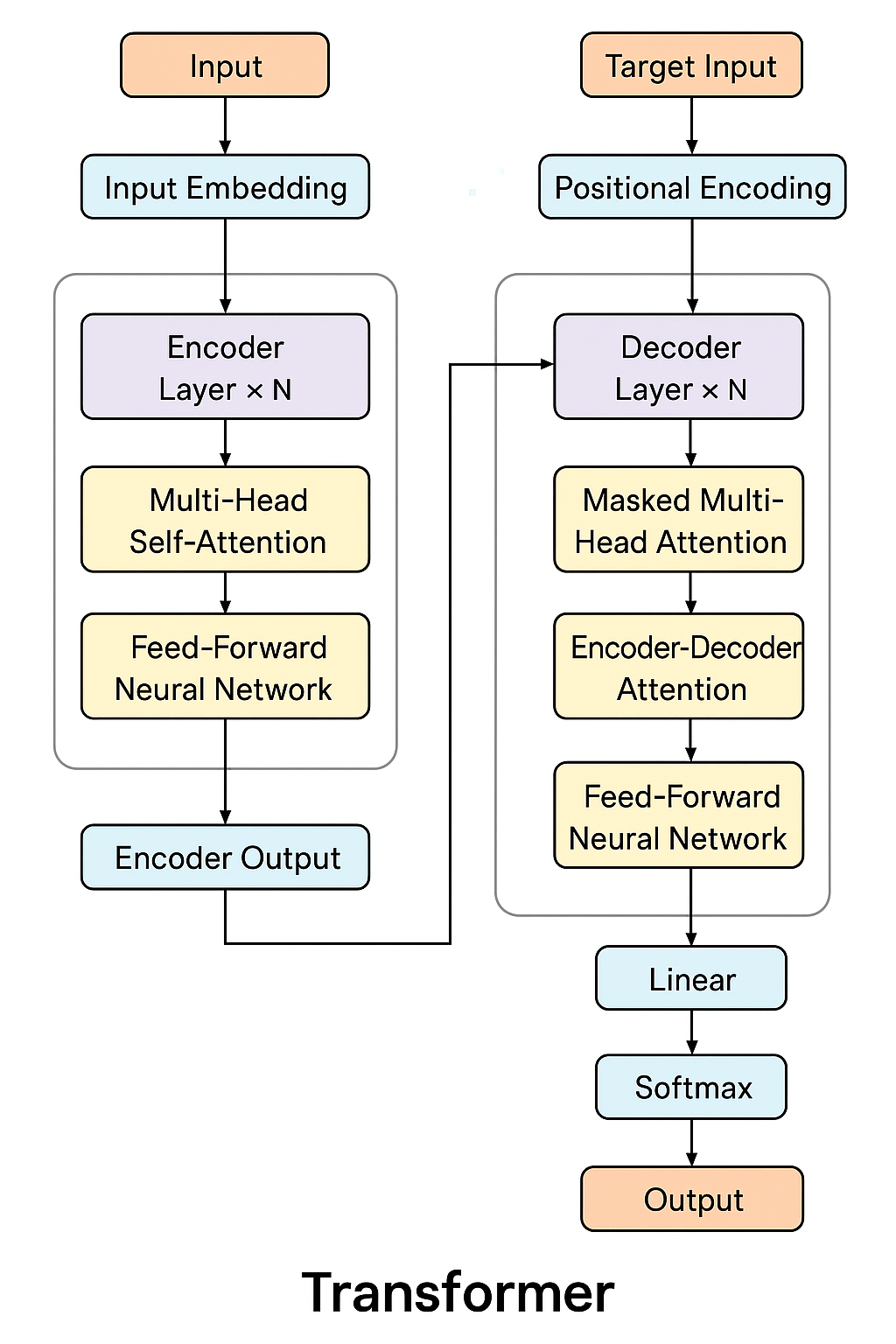
一、RAG 系统简介
在当今信息爆炸的时代,如何高效地从海量数据中获取有价值的信息并生成准确、自然的回答,成为了人工智能领域的重要课题。检索增强生成(Retrieval-Augmented Generation,RAG)系统应运而生,它结合了信息检索(IR)和自然语言生成(NLG)技术,能够在生成回答时利用外部知识库的信息,显著提高回答的准确性和可靠性。
RAG 系统的核心思想是:首先通过检索模块从知识库中查找与用户问题相关的文档或段落,然后将这些检索到的信息输入到生成模型中,生成最终的回答。这种方法避免了传统生成模型仅依赖内部参数知识的局限性,能够处理更专业、更实时的问题。
二、LangChain 概述

LangChain是一个用于构建端到端应用程序的框架,特别适用于涉及语言模型(LLM)的应用。它提供了一系列工具和组件,方便开发者连接不同的数据源、整合多种工具,并构建复杂的工作流。在 RAG 系统中,LangChain 可以帮助我们高效地管理检索模块和生成模型之间的交互,简化开发流程。
三、准备工作
(一)安装依赖
首先,我们需要安装必要的 Python 库,包括 LangChain、Hugging Face 的 Transformers 和 Datasets、以及用于向量存储的 FAISS 等。可以通过以下命令进行安装:
| pip install langchain transformers datasets faiss-cpu |
(二)准备知识库
我们需要一个包含相关领域知识的数据集来构建知识库。这里以维基百科的部分数据为例,使用 Hugging Face 的 Datasets 加载数据:
| from datasets import load_dataset dataset = load_dataset("wikipedia", "20220301.en", split="train") |
接下来,对数据进行预处理,包括文本清洗、分句、分词等操作。为了便于检索,我们通常会将文本分割成较小的段落或句子,并为每个段落生成向量表示。
四、构建 RAG 系统
(一)加载语言模型
我们使用 Hugging Face 的 Transformers 加载一个预训练的语言模型,例如 T5:
| from transformers import T5Tokenizer, T5ForConditionalGeneration tokenizer = T5Tokenizer.from_pretrained("t5-base") model = T5ForConditionalGeneration.from_pretrained("t5-base") |
(二)创建检索器
使用 LangChain 的 FAISS 向量存储来创建检索器。首先,将预处理后的文本转换为向量,并存储到 FAISS 索引中:
| from langchain.vectorstores import FAISS from langchain.embeddings import HuggingFaceEmbeddings embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2") vectorstore = FAISS.from_texts(dataset["text"], embeddings) retriever = vectorstore.as_retriever() |
(三)构建 RAG 链
使用 LangChain 的 RagChain 类来组合检索器和生成模型。RagChain 会自动处理检索和生成的流程,将检索到的相关文本作为上下文输入到生成模型中:
| from langchain.chains import RetrievalQA rag_chain = RetrievalQA.from_chain_type( llm=model, chain_type="stuff", retriever=retriever, input_key="question" ) |
五、测试与优化
(一)进行问答测试
准备一些测试问题,例如 "Who is the author of the Harry Potter series?",然后使用 RAG 系统进行回答:
| question = "Who is the author of the Harry Potter series?" answer = rag_chain.run(question) print(answer) |
(二)优化检索和生成效果
如果回答效果不理想,可以从以下几个方面进行优化:
- 调整检索参数:例如设置检索的相关度阈值、返回的文档数量等。
- 改进文本预处理:优化文本分割策略、增加文本清洗的规则等。
- 选择更合适的模型:尝试不同的语言模型或嵌入模型,提高检索和生成的准确性。
- 增强知识库:增加更多的训练数据,或者对现有数据进行更精细的标注。
六、总结
通过 LangChain,我们可以快速地搭建一个 RAG 系统,实现基于外部知识库的问答功能。本文只是一个简单的示例,实际应用中还需要考虑更多的因素,例如处理长文本、支持多模态输入输出、提高系统的效率和可扩展性等。