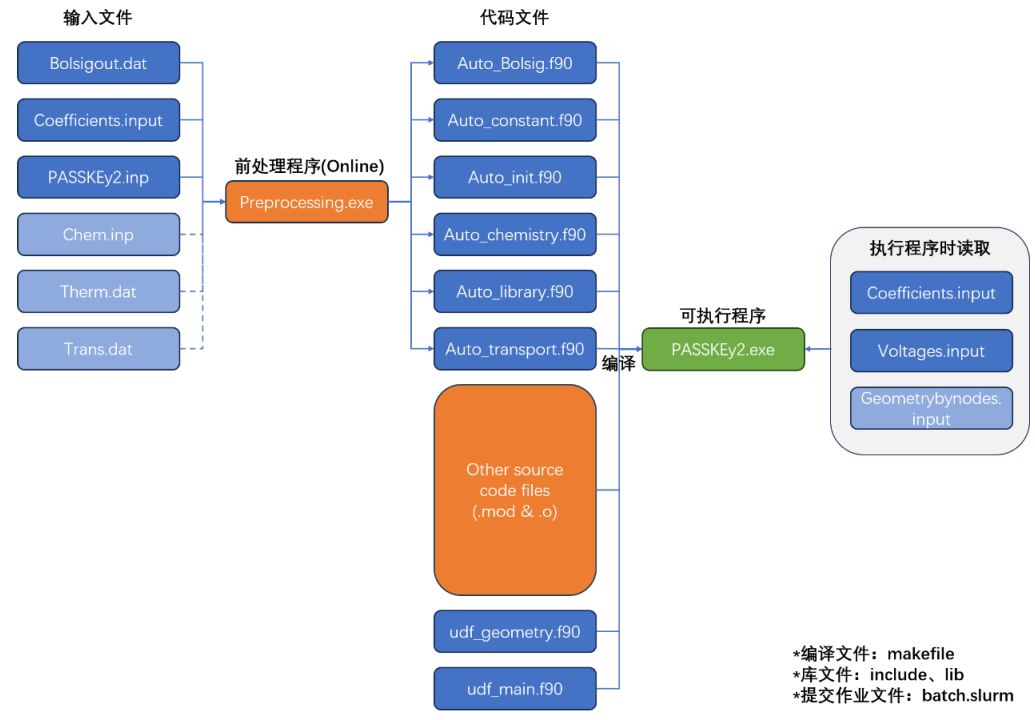
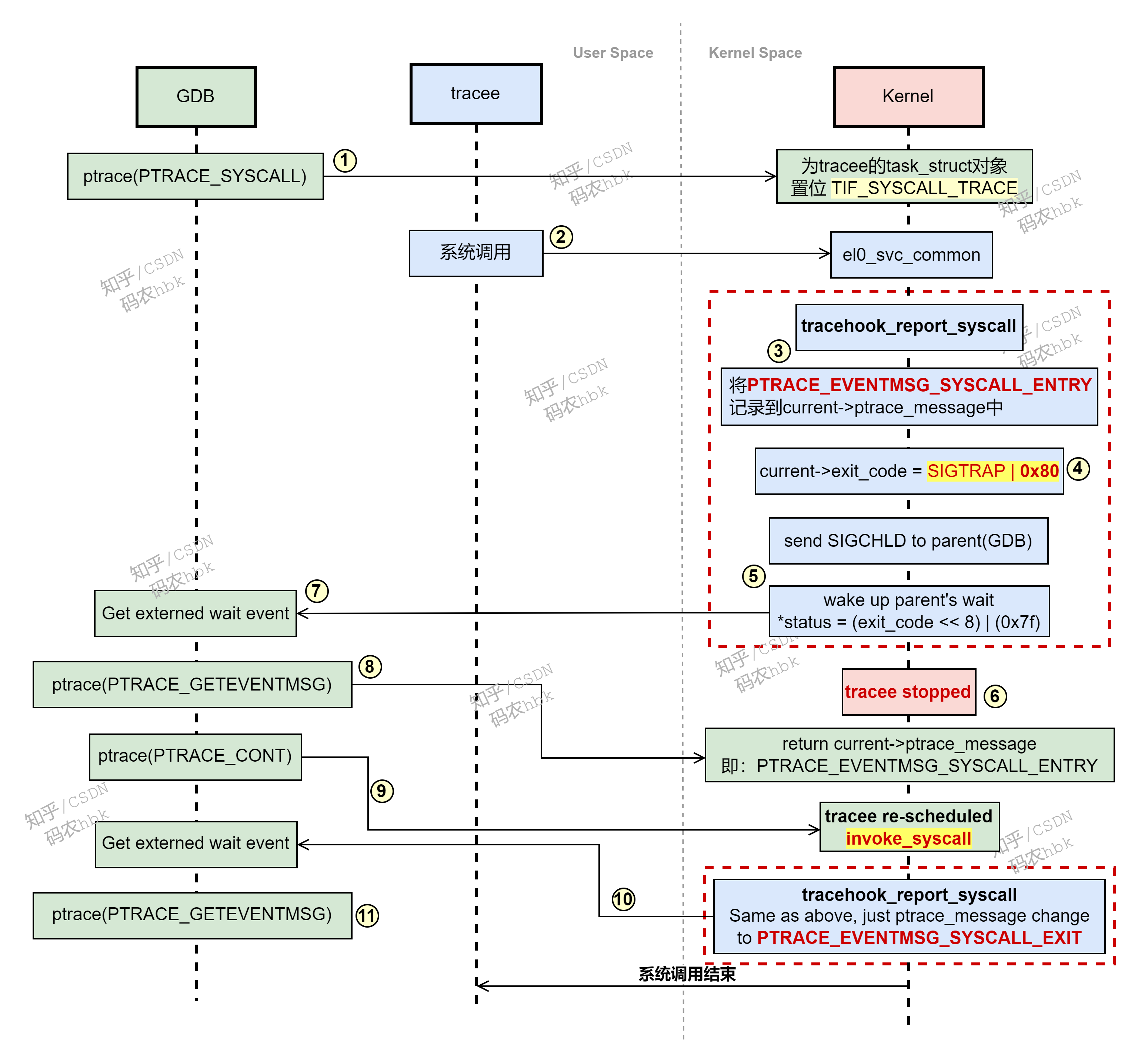
下面介绍下基于 Hugging Face Transformers 库中 tokenizer(分词器)的主要用法和常用方法,帮助你了解如何在各种场景下处理文本。这里以 AutoTokenizer 为例,但大多数模型对应的 tokenizer 用法大同小异。
─────────────────────────────
- 加载 Tokenizer
• 自动加载(AutoTokenizer)
使用 AutoTokenizer 可以根据模型名称或本地路径快速加载对应的分词器:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(“模型名称或者本地路径”)
例如:
tokenizer = AutoTokenizer.from_pretrained(“bert-base-uncased”)
或加载本地模型目录:
tokenizer = AutoTokenizer.from_pretrained(“/home/zhangchenlong.8/resources/qwen2.53b”)
• 指定参数
加载时可以传入一些参数,如是否返回 fast 版本(更高效的C++实现),是否下载缓存等。
tokenizer = AutoTokenizer.from_pretrained(“模型名称”, use_fast=True)
─────────────────────────────
2. 基本编码方法(encode / call)
• 单条文本编码为 token id 列表
token_ids = tokenizer.encode(“Hello world”, add_special_tokens=True)
注意:add_special_tokens 参数控制是否在结果中加入模型所需的特殊 token(例如 [CLS], [SEP])
• 编码多条文本(Batch Encoding)
encoded = tokenizer([“Hello world”, “How are you?”], padding=True, truncation=True, return_tensors=“pt”)
返回结果通常是一个字典,包含 input_ids, attention_mask 等(当 return_tensors 指定返回 tensor 时)
如果只需要 id 列表,可以不指定返回 tensor:
encoded = tokenizer([“Hello world”, “How are you?”], padding=True, truncation=True)
• call 方法
由于 tokenizer 类实现了 call 方法,因此直接传入文本也可以:
result = tokenizer(“Hello world”, add_special_tokens=True)
最终返回字典形式:{“input_ids”: […], “attention_mask”: […]},有时还会包含其他信息比如 “token_type_ids”、“offset_mapping”(用于对齐)等。
─────────────────────────────
3. 编码参数详解
在调用 encode、batch_encode_plus 或 call 方法时,可以传入的常用参数有:
• add_special_tokens: 是否在编码时加入特殊标记,如 [CLS] 或 [SEP]
• padding: 是否对输出进行补齐(填充)。例如 padding=True 会补齐到当前 batch 内最大长度;可以传入 “max_length” 强制到固定长度。
• truncation: 是否截断超过指定最大长度的文本。
• max_length: 最大长度
• return_tensors: 指定返回类型,如 “pt”(PyTorch tensor)、“tf” 或 “np”(NumPy 数组)
• return_attention_mask: 是否返回 attention mask 信息
• return_token_type_ids: 是否返回 token type ids
• verbose: 控制消息显示
• add_prefix_space: 一些基于字节对编码(BPE)的 tokenizer 可能需要(如 GPT-2)
─────────────────────────────
4. 解码(decode)
转换 token id 序列回文本:
text = tokenizer.decode(token_ids, skip_special_tokens=True)
参数 skip_special_tokens=True 可以过滤掉 [CLS]、[SEP] 等特殊 token,使输出更纯净。
如果需要对一批 token 序列进行解码,可以使用 decode 方法配合循环,或使用 batch_decode 方法:
texts = tokenizer.batch_decode(list_of_token_ids, skip_special_tokens=True)
将 prefix_tokens 转换为 tokens
prefix_tokens_str = tokenizer.convert_ids_to_tokens(prefix_tokens)
─────────────────────────────
5. 高阶功能
• 获取词汇表
可以通过 tokenizer.vocab 访问词典(部分 tokenizer 不支持此属性);或使用 tokenizer.get_vocab() 方法:
vocab = tokenizer.get_vocab()
返回字典形式:{token: id, …}
• 分词(Tokenization)
有时只需要知道文本被划分成哪些 token(通常是字符串),用 tokenizer.tokenize():
tokens = tokenizer.tokenize(“Hello world”)
有的是基于 subword 或 SentencePiece 实现,返回结果可能包含 ## 或前置空格,取决于模型设计。
• 映射与偏移信息
有时需要知道每个 token 在原字符文本中的位置,可传入参数 return_offsets_mapping:
encoded = tokenizer(“Hello world”, return_offsets_mapping=True)
encoded[“offset_mapping”] 即是每个 token 对应的 (start, end) 位置信息。
• 处理特殊场景
– 对于长文本自动截断和溢出(overflow tokens),可以用参数 return_overflowing_tokens=True
– 对于分词后需要中英文对齐信息,也可以查看 tokenizer 的高级用法和文档说明。
─────────────────────────────
6. Tokenizer 的用途
• 数据预处理
在模型训练前,将原始文本转换为模型所需的 token id 序列。
• 后处理(解码)
将模型输出的 id 序列转换回可读文本。
• 调试和分析
通过 tokenization 可以检查是不是特殊字符没有正确处理,或测试不同 tokenizer 对同一文本的分词效果。
• 自定义处理
可以基于现有 tokenizer 进行修改,如添加自定义的 token(tokenizer.add_tokens([“新词”])),从而扩展词汇表,此时可调用 tokenizer.resize_token_embeddings(model) 更新模型嵌入层。
─────────────────────────────
7. 注意事项
• 模型预训练时通常使用了特定的 tokenizer,使用时最好保证加载相同版本,确保 token id 对应关系一致。
• 有的 tokenizer 有 fast 版本(基于 Rust 的 tokenizers 库实现),具备更高效率和更多功能,如 offset mapping、动态 padding 等。
• 部分 tokenizer 对空格、标点等处理与我们直觉可能不同(比如 GPT-2 在 token 开头会有空格提示),需要熟悉模本的使用说明。
• 当用于多语言或特殊场景时,有时需要调整 tokenizer 的参数(例如 normalization、pre-tokenization、post-processing)。
─────────────────────────────
总结
以上即介绍了 Hugging Face 中 tokenizer 的加载、编码、解码、参数设置以及进阶功能。具体应用时建议参阅官方文档(https://huggingface.co/transformers/main_classes/tokenizer.html),结合你使用的模型的特点,来调试和完善你的文本处理流程。