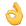大模型如何作为reranker?
作者:爱工作的小小酥
原文地址:https://zhuanlan.zhihu.com/p/31805674335
只为了感动自己而去做一些事情纯属浪费时间。 ————爱工作的小小酥
引言
用于检索的模型中,我们最熟悉的就是单塔和双塔了,双塔经常用于召回阶段,单塔用于排序阶段。并且,其往往都是Encoder 结构的模型,例如BERT。
进入大模型时代后,模型结构大多只以deocder构成。当大模型在各个领域任务上表现出出色的能力,其在检索任务中是否也能超越以前的模型呢?
在之前的文章「爱工作的小小酥:大模型时代如何得到更好的embedding表征?」中,我们介绍了LLM如何用于编码embedding,以用于召回阶段。
我们这次再来看一下生成式模型——大模型如何用于排序阶段。
在检索任务的排序阶段,我们为了query和document的特征可以深度交互,要把query和document进行拼接输入模型,最后得到匹配分数。那么,对于以decoder结构为主的大模型来说,主要有以下需要解决的问题点:
-
如何得到分数值?
-
采用什么样的训练损失训练模型?
如何得到分数值?
LLM作为一种生成模型,需要一步步解码token得到所有结果。而对于reranker模型来说,不需要生成token,而只需要一个相似度值。在现有的研究中,主要分为3种情况:使用固定的token的特征的logits、直接让模型输出顺序「不再需要输出分数」、使用query中的词对应的logits。
使用固定的token
生成式模型,一步解码后得到的是在所有词表上的分布,我们往往通过选择在这个词表上最大的词作为此步解码token。因此,在这个过程中,我们可以得到当前步词表上所有token的logits,其实选择其中任何一个都可以用于计算分数,只是通过设置不同的prompt,可能有些token会更有意义一些。
(1)模型生成Yes,No。
当构造的prompt中,让模型输出Yes或者No时,此时选择Yes token对应的概率作为分数就会更有意义。

相对应的,也可以设置为True或者False,当然也要在prompt中做出相应更改。具体计算分数的时候有的会直接在所有词表上进行softmax,有的直接使用yes token的logits,有的只在Yes和No之间进行softmax「感觉这个更合理一些」。
具体使用方法参考论文:The Expando-Mono-Duo Design Pattern for Text Ranking with Pretrained Sequence-to-Sequence Models
(2)模型第一个输出token中的特殊token
如果设置的prompt中没有明确输出指令,常常会指定「特殊的token」作为计算分数的特征,例如<extra_id_10>或者。此时,一般使用一个linear层直接将logits转化为分数「对应下面的Dense」。
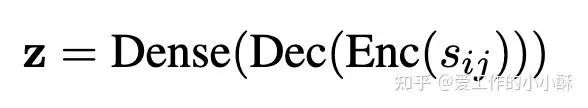
具体参考论文:
RankT5: Fine-Tuning T5 for Text Ranking with Ranking Losses
Fine-Tuning LLaMA for Multi-Stage Text Retrieval
直接输出顺序
问答作为目前大模型最直观的使用方式,我们其实也可以直接让大模型排序,而不是输出分数后,最后再排序。例如,使用如下的prompt,就可以实现对document排序。

这种方法会有一个问题,模型接受的长度有限,而候选文档的个数一般都很多。目前现有的方法是采用「滑动窗口」的方式进行排序,有点类似冒泡排序。

参考论文:
Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents
RankVicuna: Zero-Shot Listwise Document Reranking with Open-Source Large Language Models
Zero-Shot Listwise Document Reranking with a Large Language Model
使用query的logits平均计算
还有一种用的人比较少的计算分数的方式,不按照常规构建rerank模型数据方式,而是只使用document,计算其生成label query的概率,这个作为query和document匹配的概率。
例如,使用下面的prompt,让模型生成对应的query。

然后,基于下面的公式,求取所有query token对应的概率。
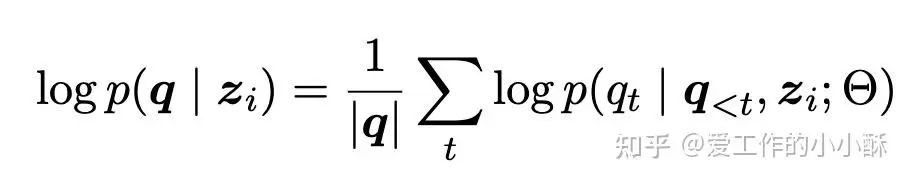
参考论文:Improving Passage Retrieval with Zero-Shot Question Generation
采用什么样的训练损失训练模型?
Pointwise Ranking Loss
Pointwise loss只需要匹配query和一个document之间的相似度关系,在三种损失里面是相对容易数据的一种训练方法,通常情况下,只需要对每个query,选择出困难负样本即可,具体可以参考bge的官方训练代码。
https://github.com/FlagOpen/FlagEmbedding/tree/master
这里将每个query、对应的正样本、对应的负样本作为一个组,每个组内部使用交叉熵损失计算loss。有点类似组内的INfoNCE,没有in batch negative。
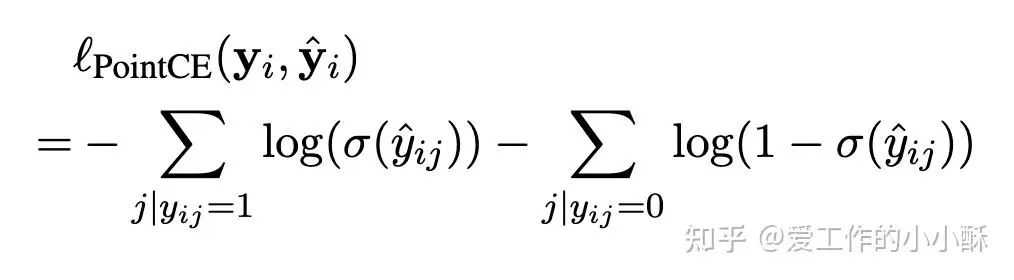
参考论文:
Fine-Tuning LLaMA for Multi-Stage Text Retrieval
The Expando-Mono-Duo Design Pattern for Text Ranking with Pretrained Sequence-to-Sequence Models
RankT5: Fine-Tuning T5 for Text Ranking with Ranking Losses
Pairwise Ranking Loss
Pairwise 训练的样本为三元组,<query, 正样本,负样本>, 模型输出query是否和第一个样本更加匹配。最终需要根据相应的算法将两两顺序转化为最终的顺序。目前最常采用的损失函数为RankNet loss。
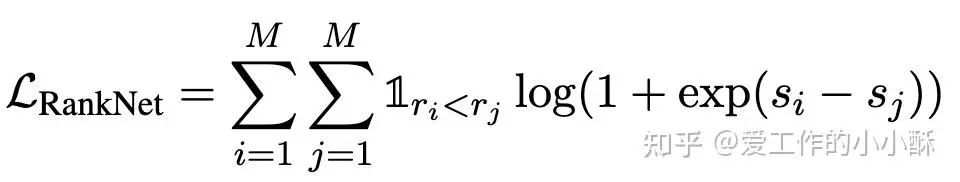
这种损失函数构造样本就会更加复杂一些,需要得到query和所有候选的顺序。有的会直接使用更大的模型得到顺序,例如chatgpt。有的直接随机采样负样本,忽略负样本之间的顺序,只保证正样本在负样本前面即可。
最后,可以采用以下累积分数的方式得到每个document的得分:
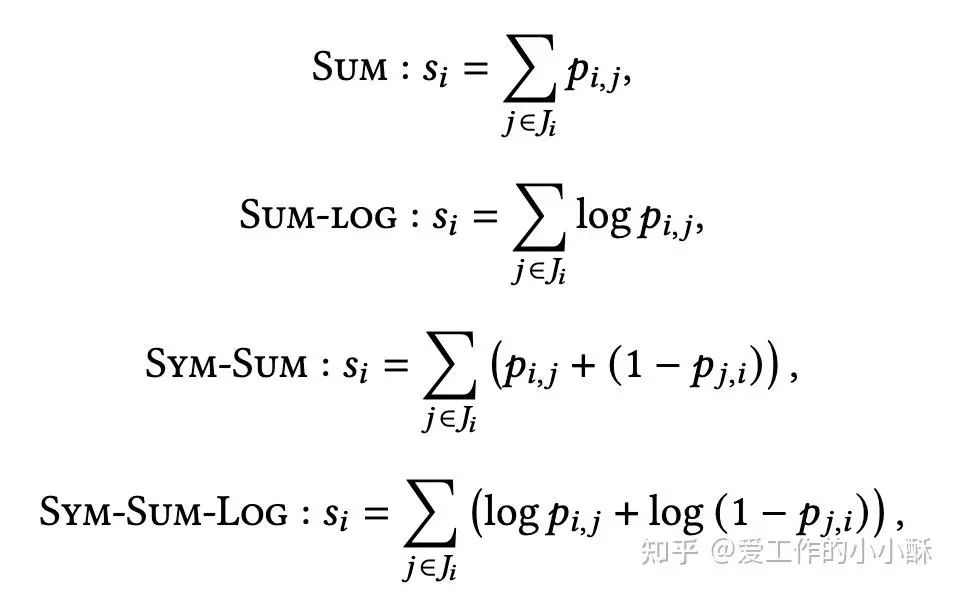
参考论文:
Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents
The Expando-Mono-Duo Design Pattern for Text Ranking with Pretrained Sequence-to-Sequence Models
RankT5: Fine-Tuning T5 for Text Ranking with Ranking Losses
Listwise Ranking Loss
Listwise loss是对整个序列顺序计算损失,因此,这个损失函数要求知道数据的真实顺序。构造数据的方法类似上述的Pairwise Ranking Loss。
目前经常采用的损失函数包括ListNet softmax 版本和PolyLoss。
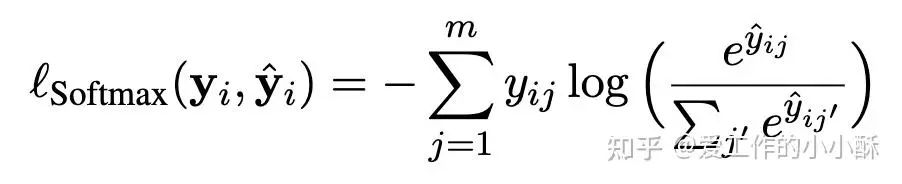
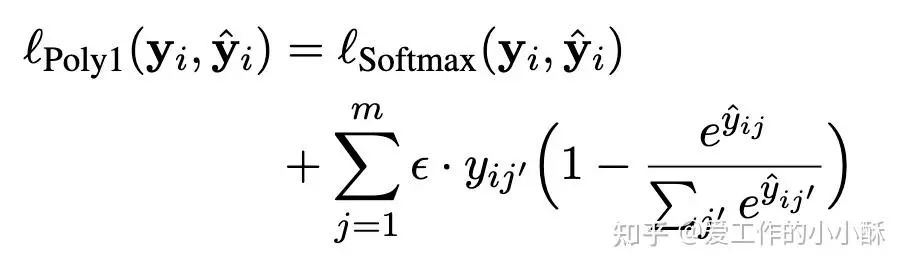
在RankT5论文中,验证listwise的损失效果最好,但目前看使用这个损失的模型也比较少,可能比较难构造数据。
参考论文:RankT5: Fine-Tuning T5 for Text Ranking with Ranking Losses
总结
生成式模型不像之前的BERT,其多出了一个decoder结构,如何借助decoder本身的能力得到一个更加有意义的相似度分数成为关键,在现有的方法中主要通过更改prompt或者直接增大特殊token实现。除此之外,还可以直接利用大模型本身的能力,使其对候选文档直接排序。而在训练方式和,和之前的小模型相差不大,都是选用Pointwise Ranking Loss、Pairwise Ranking Loss或者Listwise Ranking Loss。





![[AI Workflow] 基于多语种知识库的 Dify Workflow 构建与优化实践](https://i-blog.csdnimg.cn/direct/eac05b1a65434545bc7367a6633b4d20.png)