基本介绍
DataX 是阿里云 DataWorks数据集成的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台,它是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。
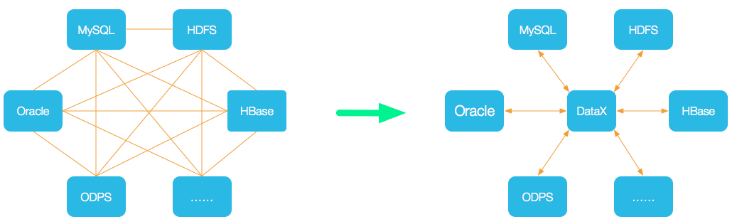
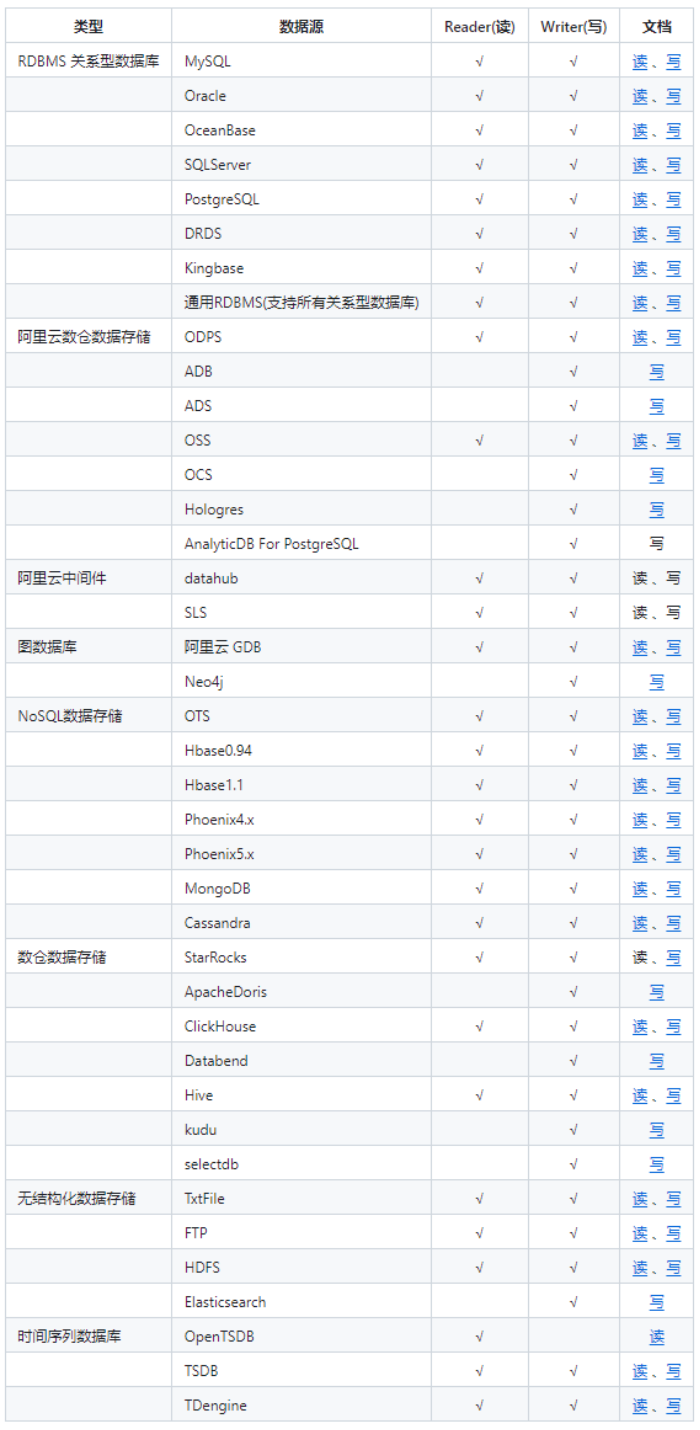
当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入。DataX支持目前市面上几乎所有的数据库类型,如下图所示:
ataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB。而阿里云最新开源全新版本DataX3.0,有了更多更强大的功能和更好的使用体验。

作为离线数据同步框架,采用Framework + plugin架构。将数据源读取、写入抽象成为Reader/Writer插件,纳入到整个同步框架:
Reader:数据采集模块,采集数据源的数据,将数据发送给FrameworkWriter: 数据写入模块,不断向Framework取数据,并将数据写入到目的端Framework:连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术
安装目录文件
安装文件目录
![]()
bin下 (datax.py是主要的执行工具,使用python执行)
![]()
plugin下有多个reader和wreter的输入模版


任务提交及模版生成
任务提交命令:用户需要根据同步数据的数据源和目的地选择相应的Reader和Writer,并将Reader和Writer的信息配置在一个json文件中,然后执行命令提交数据同步任务即可,
即:python datax.py youPath/job.json
配置文件格式:查看DataX配置文件模板可以通过以下命令,如将mysql中的数据同步到hdfs中可以使用: python datax.py -r mysqlreader -w hdfswriter
执行以上代码后会输出对应模版
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": "",
"where": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [],
"compress": "",
"defaultFS": "",
"fieldDelimiter": "",
"fileName": "",
"fileType": "",
"path": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}json最外层是一个job,job包含setting和content两部分,其中setting用于对整个job进行配置,content用户配置数据源和目的地。Reader和Writer的具体参数参考官方文档
https://github.com/alibaba/DataX/blob/master/README.md
README.md · Gitee 极速下载/alibaba datax - Gitee.com
读取MySQL中的数据存放到HDFS
MySQLReader具有两种模式,分别是TableMode和QuerySQLMode,前者使用table,column,where等属性声明需要同步的数据;后者使用一条SQL查询语句声明需要同步的数据。
MySQLReader之TableMode
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"name",
"age"
],
"where": "name ='Alice'",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://XXXX:3306/test"
],
"table": [
"stud"
]
}
],
"password": "",
"splitPk": "",
"username": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "name",
"type": "string"
},
{
"name": "age",
"type": "int"
},
],
"compress": "gzip",
"defaultFS": "hdfs://XXXX:8020",
"fieldDelimiter": "\t",
"fileName": "stud_datax",
"fileType": "text",
"path": "/XXXX/",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}MySQLReader之QuerySQLMode
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://XXXX:3306/ds_test"
],
"querySql": [
"select name,age from stud where name = 'Alice'"
]
}
],
"password": "",
"username": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "name",
"type": "string"
},
{
"name": "age",
"type": "int"
},
],
"compress": "gzip",
"defaultFS": "hdfs://XXXX:8020",
"fieldDelimiter": "\t",
"fileName": "stud_datax",
"fileType": "text",
"path": "/XXXX/",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}两个区别就是在connection,是通过匹配字段进行查询还是直接编写sql进行查询,其他都一样
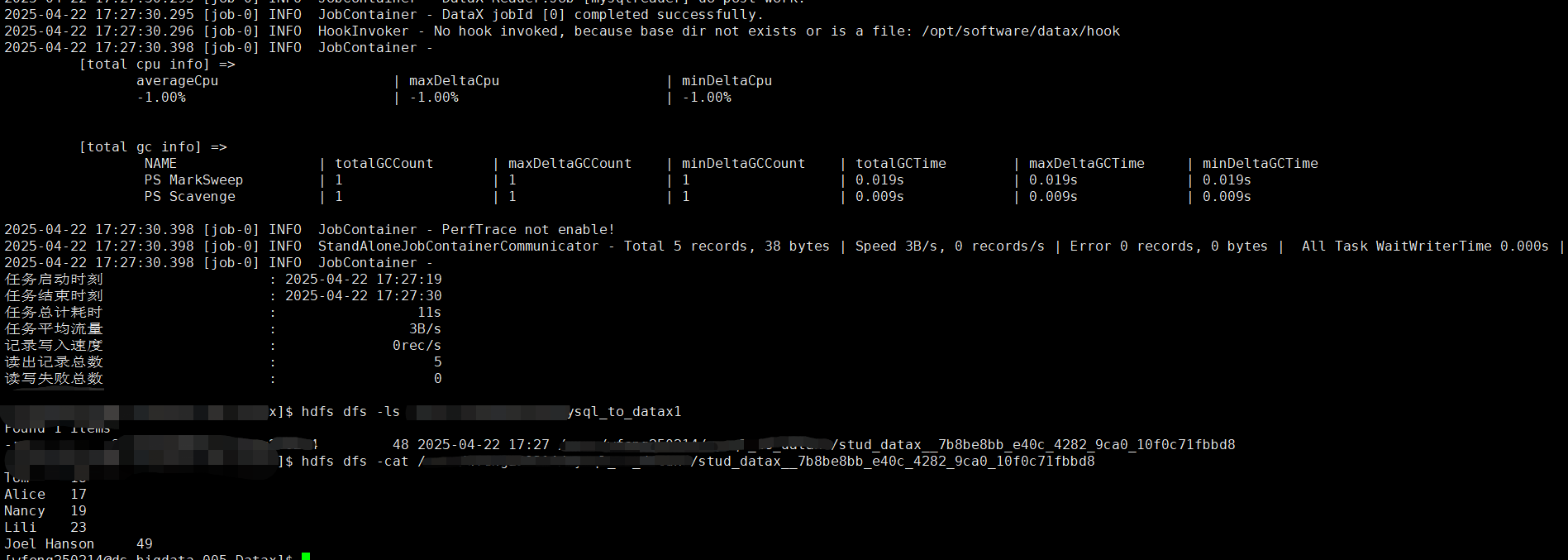
执行完成后出现以下界面,代表同步成功
DataX的性能优化
速度控制
DataX3.0提供了包括通道(并发)、记录流、字节流三种流控模式,可以随意控制作业速度,让作业在数据库可承受的范围内达到最佳的同步速度
关键优化参数
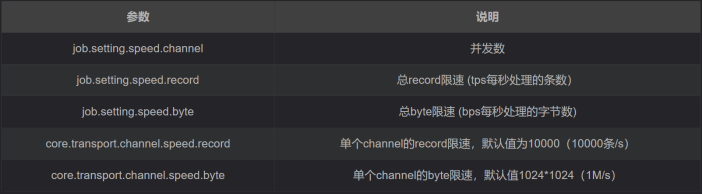
注意事项:
1、若配置了总record限速,则必须配置单个channel的record限速
2、若配置了总byte限速,则必须配置单个channe的byte限速
3、若配置了总record限速和总byte限速,channel并发数参数就会失效。因为配置了总record限速和总byte限速之后,实际channel并发数是通过计算得到的,计算公式为如下:
| min(总byte限速/单个channel的byte限速,总record限速/单个channel的record限速) |
配置实例
{
"core": {
"transport": {
"channel": {
"speed": {
"byte": 1048576 //单个channel byte限速1M/s
}
}
}
},
"job": {
"setting": {
"speed": {
"byte" : 5242880 //总byte限速5M/s
}
},
...
}
}内存调整
当提升DataX Job内Channel并发数时,内存的占用会显著增加,因为DataX作为数据交换通道,在内存中会缓存较多的数据。例如Channel中会有一个Buffer,作为临时的数据交换的缓冲区,而在部分Reader和Writer的中,也会存在一些Buffer,为了防止OOM等错误,需调大JVM的堆内存。
建议将内存设置为4G或者8G,这个也可以根据实际情况来调整。
调整JVM xms xmx参数的两种方式:一种是直接更改datax.py脚本;另一种是在启动的时候,加上对应的参数,如下:
| python datax.py --jvm="-Xms8G -Xmx8G" yourPath/job.json |






![[java八股文][Java基础面试篇]I/O](https://i-blog.csdnimg.cn/img_convert/bdebae7b7209480e531afc360f0c597d.png)