注:本文为 “TCP 协议” 相关文章合辑。
原文为繁体,注意术语描述差异。
略作重排,如有内容异常,请看原文。
作者在不同的文章中互相引用其不同文章,一并汇总于此。
可从本文右侧目录直达本文主题相关的部分,
- TCP 流量控制(Flow Control)
- TCP 傻瓜视窗症候群
- TCP 错误控制
- TCP 壅塞控制
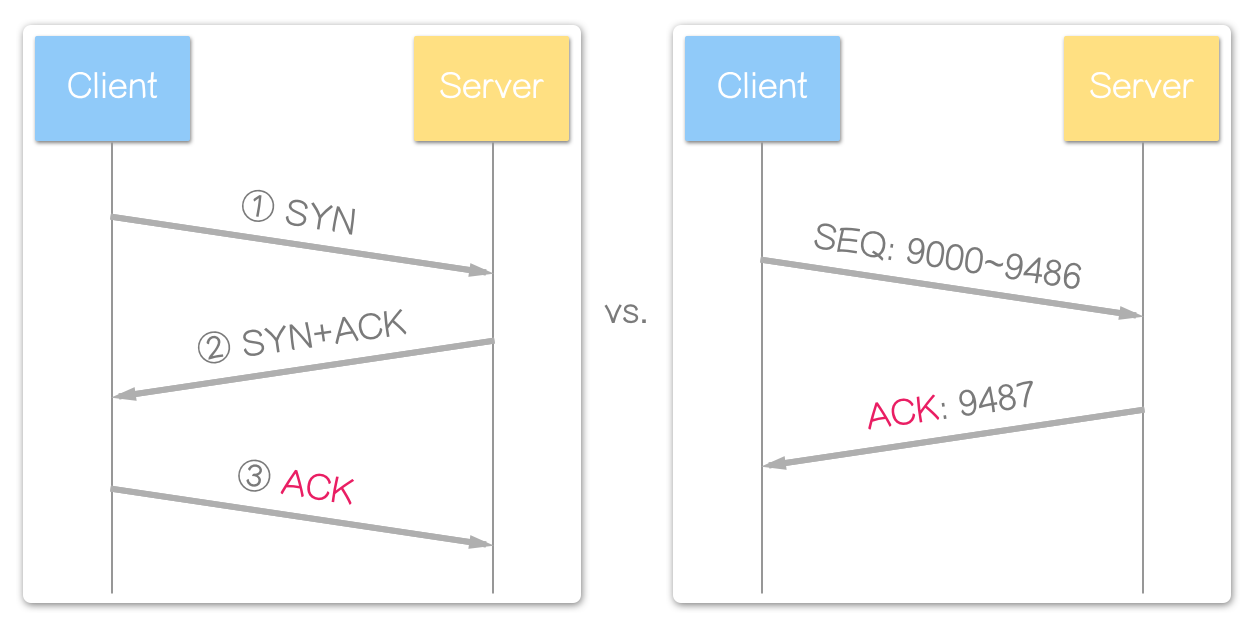
TCP 三向交握 (Three-way Handshake)
2016-12-21 郑中胜
传输控制协议 (Transmission Control Protocol, TCP) 是一种连接导向 (connection-oriented) 的通讯协议,与用户数据报协议 (UDP) 不同。TCP 通过三向交握 (Three-way Handshake) 建立虚拟连接。
三向交握又称为三向式握手或三路交握,其实质是三次消息的交换过程。
三向交握 (Three-way Handshake)
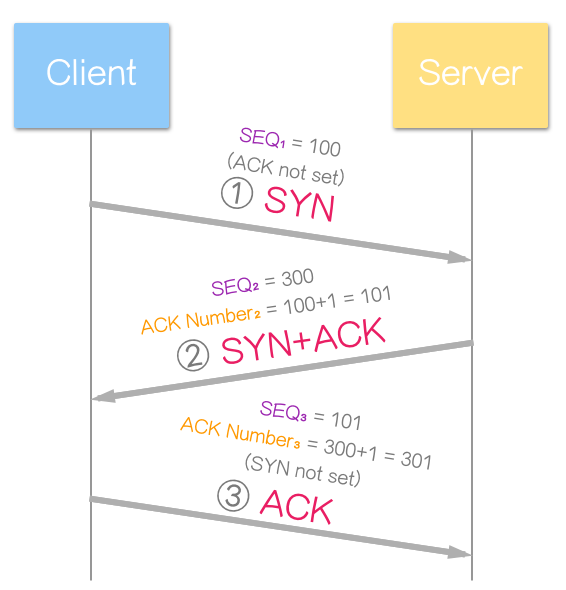
三向交握的过程通常表示为:
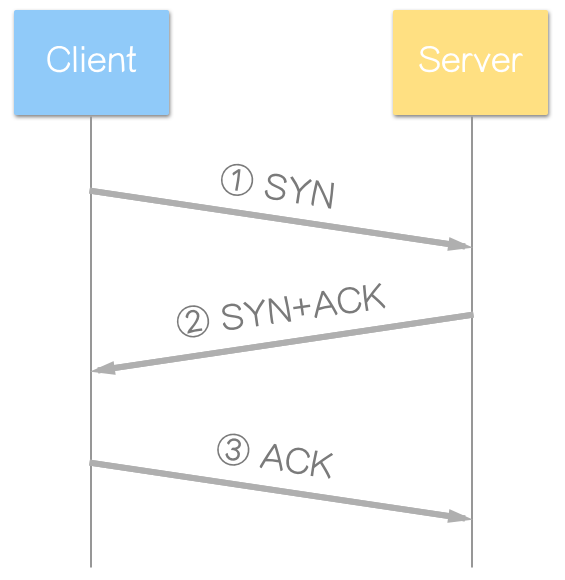
其中,SYN 和 ACK 是 TCP 数据包中的控制位元 (Control Bits)。
过程中省略了其他封包内容,例如:
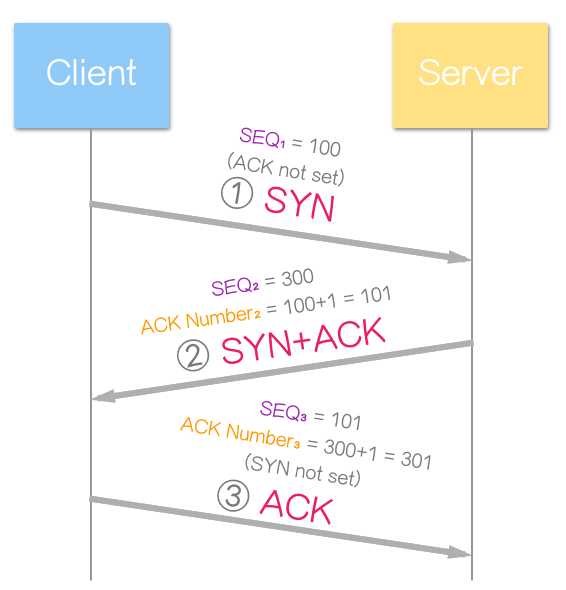
(数值只为范例,不代表实际情形,为避免争议,使用的是官方的范例数值)
以下是三向交握过程中各步骤的详细说明:
范例说明
以生活化的例子解释上述原理(颜色对应上方图示):
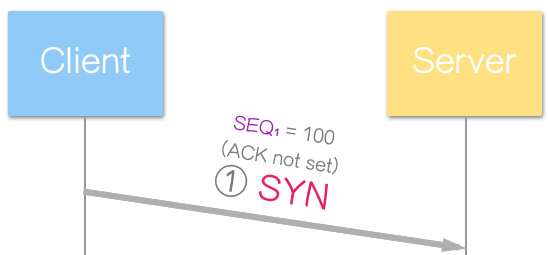
Alice 想与远方的好友 Bob 交换动漫,但他们担心快递不可靠(遗失或滞留等)。因此,他们约定先交换三次“封面”(通常不包含实际数据),以确保安全的合作方式(建立连接)。
-
Alice: “嘿,Bob,我想跟你交换动漫(SYN),我寄给你《火影》第 100 话封面。”
-
Bob: “好的,给你看《海贼》第 300 话封面,我确认收到(ACK)《火影》100 话封面了,我期待收到《火影》101(100+1)话封面,我也想进行交换(SYN)。”

-
Alice: “好的,给你《火影》第 101 话封面,我确认收到(ACK)《海贼》300 话封面了,我期待收到《海贼》301(300+1)话封面。”

完成这三步后,连接便建立完成。
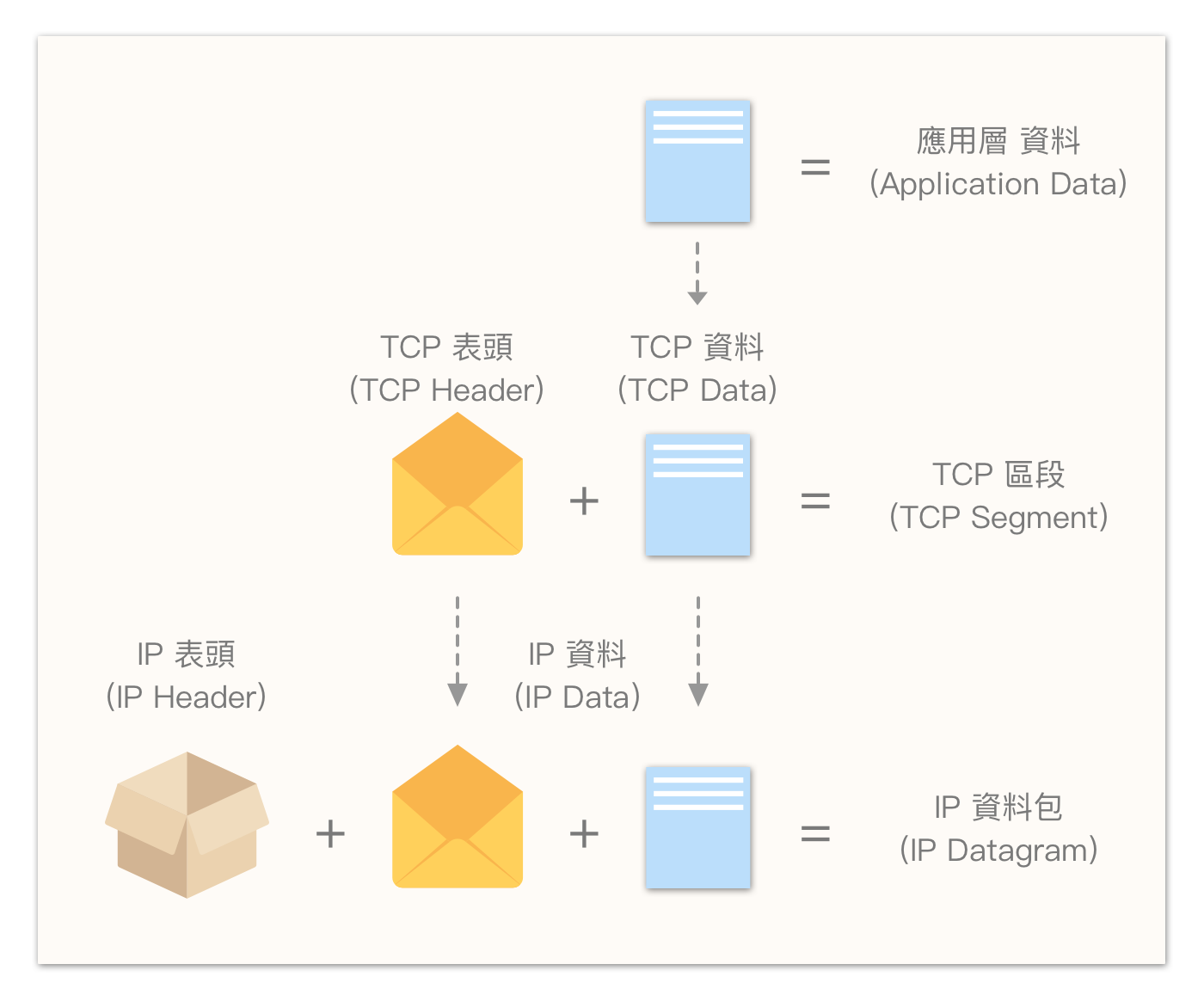
TCP 表头格式 (TCP Header Format)
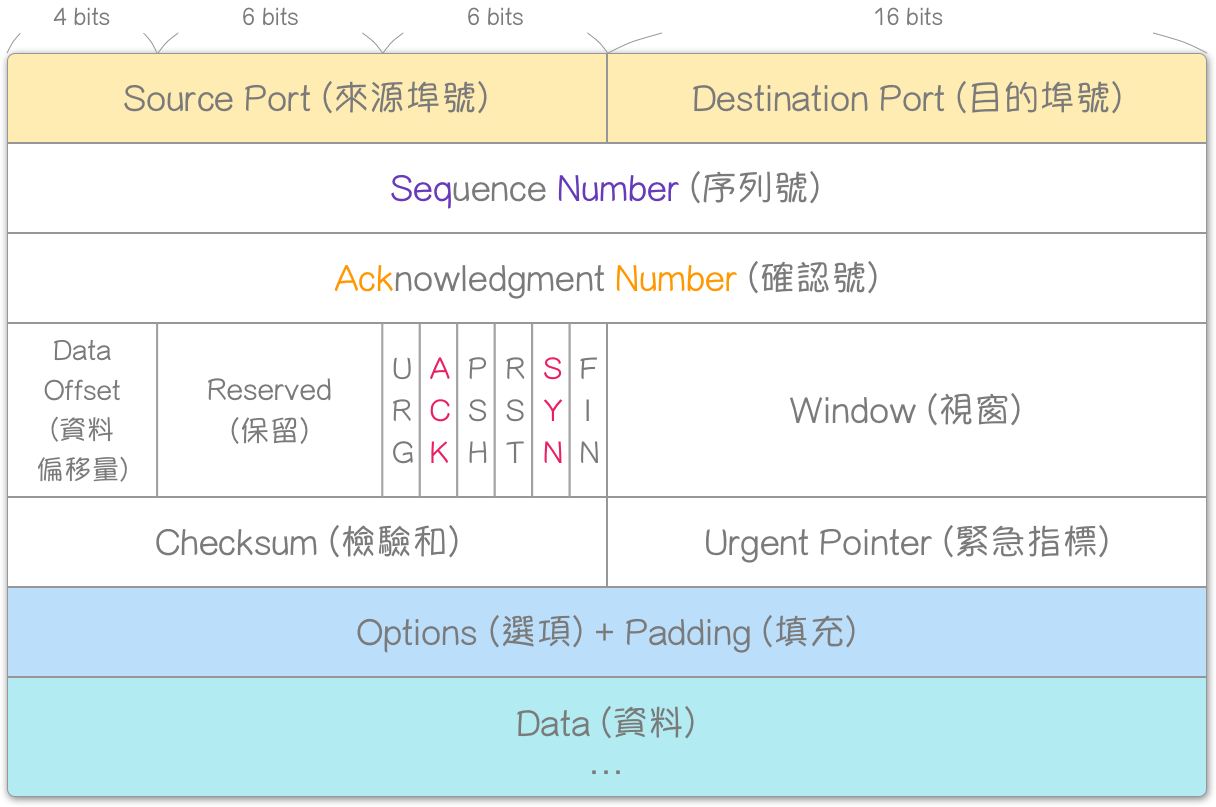
在了解三向交握后,我们再来看 TCP 的数据包格式,以便更好地理解其机制。
控制位元 (Control Bits)
控制位元 (Control Bits) 不过是 0 与 1 的切换。
- SYN (Synchronize sequence numbers):如果设置,则发出连接请求,用于同步序列号。
- ACK (Acknowledgment field significant):如果设置,则使确认号字段有效。
序列号 (Sequence Number)
序列号相当于上述例子中的漫画“集数”:
- 如果 SYN 控制位未设置,则为该数据段第一个数据字节的序列号。
- 如果 SYN 控制位已设置,则此为初始序列号 (initial sequence number, ISN),第一个数据字节的序列号为 ISN + 1。
- 每个通过 TCP 连接传输的数据字节都有一个序列号。
更多介绍详见 TCP 序列号 (Sequence Number, SEQ)_。
确认号 (Acknowledgment Number)
- 当确认连接后(已设置 ACK),该字段存放期望接收的序列号。
- 一旦连接建立,则每次都需发送。
更多介绍详见 TCP 错误控制 (Error Control)_。
数据区段 (Segment)
值得注意的是,许多人误解了三向交握中的确认号 (ACK Number),以为它就是对方序列号 (Sequence Number) 加 1,而忽略了 TCP 数据区段 (Segment) 的数据长度 (Len)。
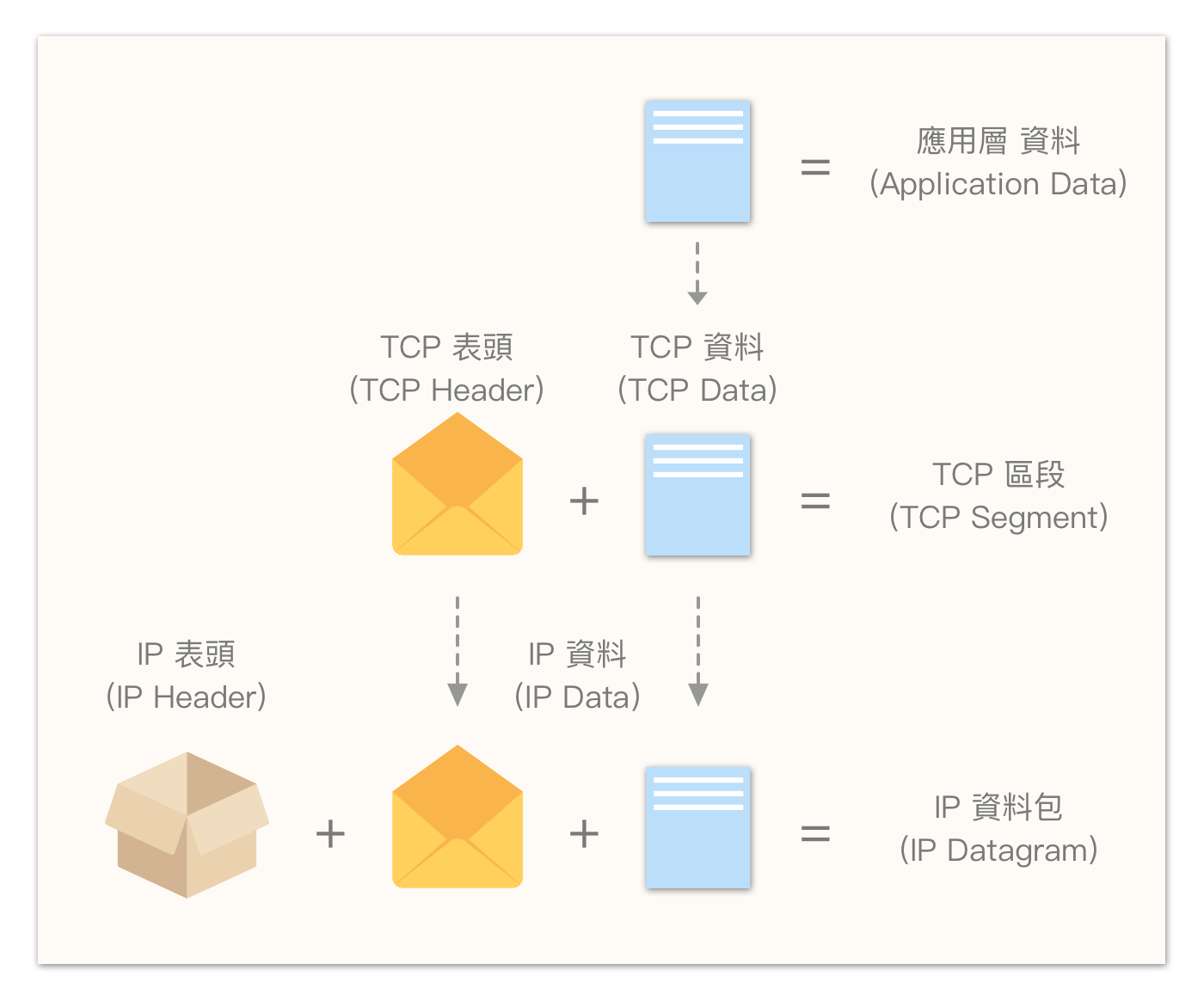
TCP 数据区段 (Segment) 是指“应用层的数据放入 TCP 表头后的整段数据”,通常为了方便沟通,直接称为 TCP 数据包。
在建立连接的过程中,通常还没有应用层的数据,因此数据长度 (Segment Len) 为 0,确认号 (ACK Number) 自然等于对方序列号 (SEQ) 加 1。若有数据传输,则通常确认号 (ACK Number) 为对方的“SEQ + 数据长度 (Segment Len)”。
例如:
- 客户端请求:SEQ4 = 101, Segment Len4 = 87, ACK Number4 = 301
- 服务器端应回复:SEQ5 = 301, Segment Len5 = XXX, ACK Number5 = 101 + 87
详见 RFC793。
阵列 (Array) 简介
發表於 2017-01-29 鄭 中勝
阵列 (Array),又称数组,是一种资料结构 (Data Structure),用于储存一群“相同资料型态 [注1] 的元素 (element)”之串列。通常占用连续的 (consecutive) 内存位置 (memory location)。
每个元素都有一个类似编号的东西,与之循序对映 (sequential mapping),称为索引 (index)。
[1]: 相同资料型态,又称为同质的 homogeneous [͵homəˋdʒinɪəs]。
随机存取 (Random Access)
不同于循序存取 (sequential access) 的链接串列 (Linked List):
“(单向) 链接串列”其元素通常散落于不连续内存位置,且 A 元素只认识 B 元素,B 元素只认识 C 元素…,要找到 Z 元素便只能一一寻访 (A->B->C…>Z),时间复杂度:O(n)。
而阵列 (Array) 置于连续的内存位置,借由其索引们 (indices) 的计算,可得出任一元素的所在位址 (address),以达成随机存取 (Random Access),使其存取元素的时间复杂度为 O(1)!(当然,也支援循序存取)
例如,一个储存“颜色”的阵列,将其命名为 a:
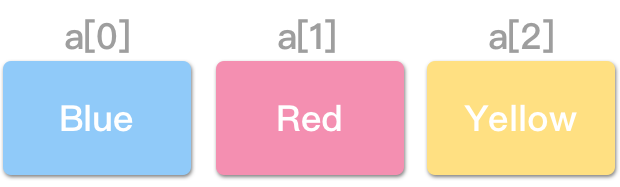
其储存于“连续的内存位置”中(假设每个 Color 大小为 4 bytes):
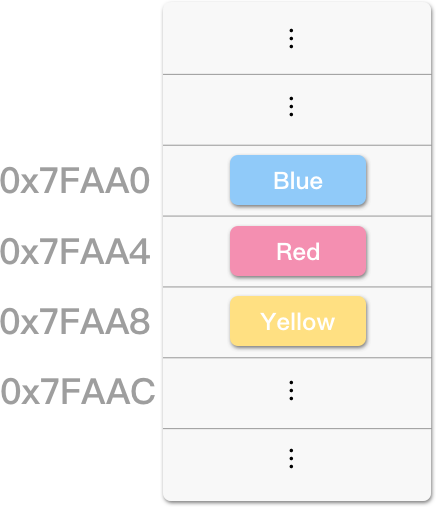
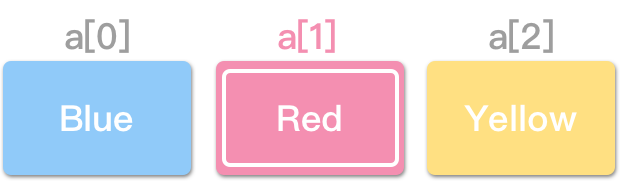
借由计算“索引 (Index)”来存取元素,而不需一个一个地寻访。想取得“Red”,只要透过索引值“1”即可:
存取原理
已知 a[0] 位址为 0x7FAA0,则 a[1] 为 0x7FAA0 + 4 = 0x7FAA4(假设每个 Color 大小为 4 bytes),透过该位址,即可取得该元素。
由此可知,计算阵列的内存位址 (address) 尤其重要,将于后几节提及。我们常说的 RAM (随机存取内存 Random Access Memory) 即是类似的概念。
许多人认为索引很不直觉,为何第一个元素的索引为“0”,而不是“1”?
索引 (Index),可想成是阵列的偏移量/差量 (offset),“第一个元素”自然没有偏移啰!这也是为何,索引通常皆为无号整数 (非负整数)。
插入 & 删除 (Insertion & Deletion)
然而,相较于其他资结(e.g.,链接串列),阵列若想插入、删除一个元素,较不方便。因为需挪移其他元素,插入/删除时间复杂度为 O(n)。
例如,欲插入 (Insert) 一元素“绿色”至 a[1]。
得把“红色”、“黄色”往后移动,还得考虑是否已超过阵列大小,否则,可能会导致“阵列索引值超出范围例外 (Array Index Out Of Bounds Exception)”。
反之,若想删除某元素,得把其他元素往前挪动:
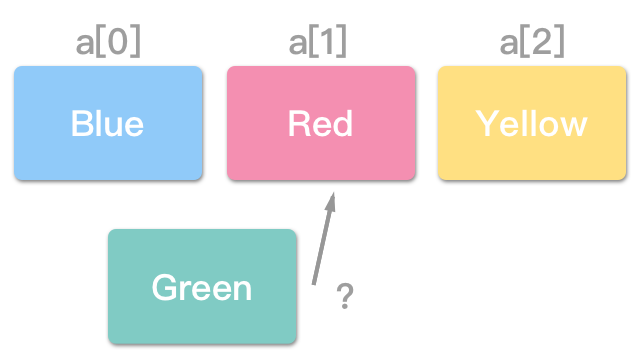
一维阵列 (One-dimensional Array)
阵列可以是一维、二维…多维(维度 Dimension)阵列,维度是指定某点(物)所需的最小座标数,也就是我们常说的“点”、“线”、“面”。分别对应零维、一维、二维。
上述范例中,如“颜色”阵列般的线性资料,即是一维阵列。
位址计算
前面提及了,计算阵列内存位址的重要性,一维阵列的计算公式如下:
一阵列 A(L:μ),有 n 个元素,其初始索引为 L [注2],阵列的基底位址为 L₀,每个元素大小为 d,则 A[i] 之位址 = L₀ + (i - L) * d,其中,n = μ - L + 1。
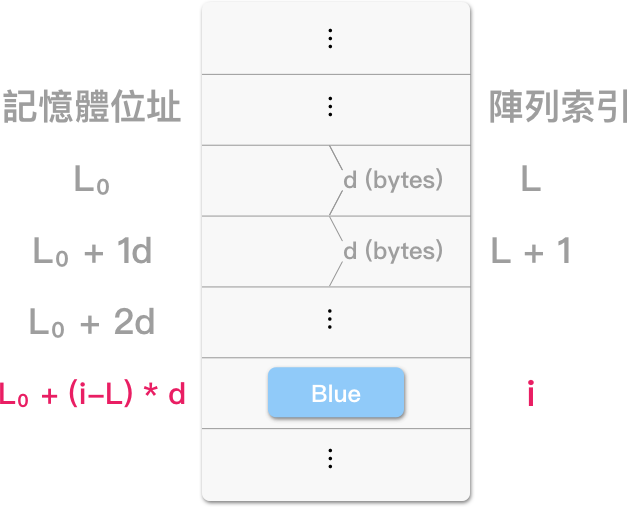
例:
有一 int 阵列 A,有 200 个元素,其初始索引为 10,基底位址为 9007,每个元素大小为 4 bytes,求 A[130] 之位址?
Ans:
A[130] 之位址 = 9007 + (130 - 10) * 4 = 9487
[2]: 考题不一定会给初始索引,且有些预设为“0”,有些为“1”,需多加注意!
二维阵列 (Two-dimensional Array)
二维阵列,即是借由行与列的方式,将资料循序存取到连续内存中。
由于多了一个维度,其需用两个索引值,来对映一个元素,这也使得相较于一维,二维阵列能够处理更多“面向”的问题。
例如,某一维阵列 a,存有班上三位同学的成绩:

若有 3 个班级呢?
二维阵列就派上用场啦!欲存取乙班、1 号同学的成绩,即可透过 a[“乙班”][1] 的方式!

例:一个储存“动物”的二维阵列,将其命名为 a:
想存取小鸡鸡,可以使用 a[1][1],想存取小猪猪,可以使用 a[2][0]。
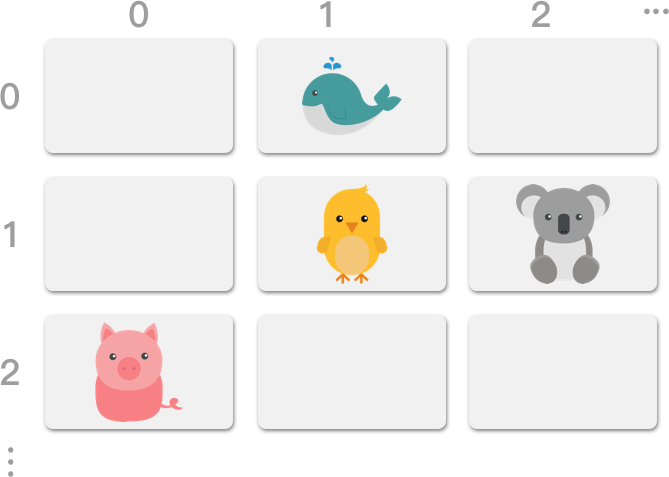
位址计算
计算二维(多维)阵列位址,普遍的两种方式:
- 以列为主(Row-major)
- 以行为主(Column-major)
其实,皆只是将二维阵列转换为一维阵列的方式,C、C++、C#…等程式语言主要(没有一定)采用 Row-major 的对应方式,Fortran、OpenGL…等,多采用 Column-major。
Row-major
以 Row-major 为例,顾名思义,透过一列一列的方式,将二维阵列循序存入内存中,Column-major 反之,不再累述。
一阵列 A(L₁:μ₁,L₂:μ₂),有 m 列、n 行,阵列的基底位址为 L₀,每个元素大小为 d,则 A[i] [j] 之位址 = L₀ + (i - L₁) * (n * d) + (j - L₂) * d,其中,m = μ₁ - L₁ + 1,n = μ₂ - L₂ + 1。
(i - L₁) 用来算出所有的列数(A[i] [j] 此列不算),(n * d) = n 行 * d (bytes),也就是此二维阵列中,一列的 bytes 大小,(j - L₂) 算出 A[i] [j] 此元素以左的行数。
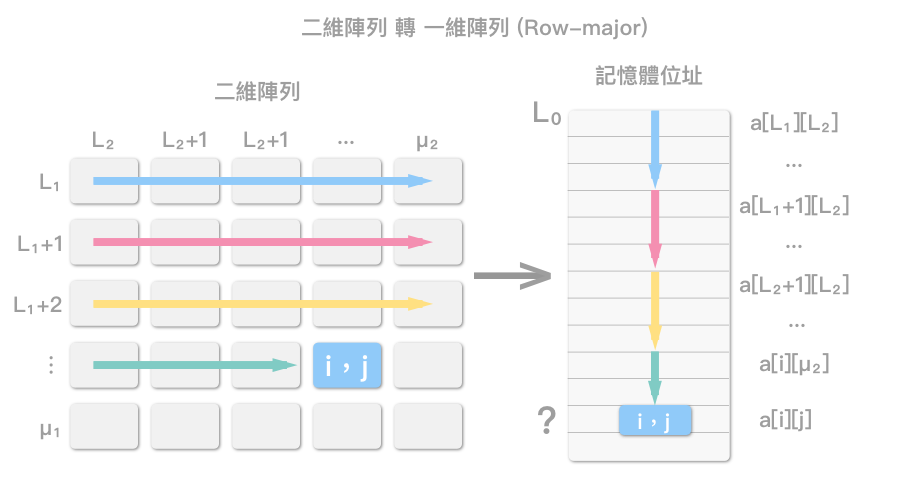
但是,为何要转为一维阵列呢?
如上述图示:
我们可将内存视为一个很大的一维字节 (bytes) 阵列!每一字节,皆有其位址 (address),称为 byte addressing。
当二维阵列放入内存,便需要计算其位址,以供存取阵列元素。
Java 没有多维阵列!
至于 Java 提供的二维阵列,是使用 Row-major 还是 Column-major 呢?
两者皆非
∵ Java 并没有二维(多维)阵列!
你可能会认为:“下方不就是标准的 Java 二维阵列吗?”
Java 宣告二维阵列:
int[][] a = {
{3, 3, 0},
{9, 5, 2, 7}
};
对不起,我标题杀人,一般来说,这的确称二维阵列。然而,严格来看,Java 只有一维阵列无误!
事实上不只 Java,许多语言的二维(多维)阵列,并非“连续”的内存位置,而是“阵列中的阵列”之概念。
也就是:
由多个一维阵列所组成
例:下图范例中,一 Java 二维阵列,命名为 a,a[0] 存有指向一维阵列 {3, 3, 0} 的参照 (reference),a[1] 存有指向一维阵列 {9, 5, 2, 7} 的参照。
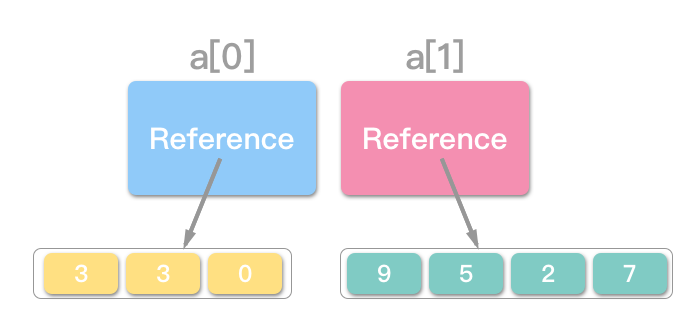
有趣的是,Java 这样的宣告方式,允许子阵列的长度不相等:一维阵列 {3, 3, 0} 长度为 3;一维阵列 {9, 5, 2, 7} 长度为 4。
透过索引:a[0][0] 可取得 3,a[0][1] 可取得 3,a[0][2] 可取得 0,a[0][3] 将抛出“阵列索引值超出范围例外 (Array Index Out Of Bounds Exception)”。
这在 C 语言中(以下的宣告方式),并不被允许,其严格的规范子阵列的长度(当然,也能自行实践“阵列 in 阵列”)。
例如:
int a[2][4] = {
{3, 3, 0},
{9, 5, 2, 7}
};
由于子阵列的长度会固定,透过索引 a[0][3] 将会取得预设值 0,而非抛出例外。
许多人认为:“连续的内存”只是阵列最常见的作法,(因此,本文最上方介绍“连续”时,用了“通常”二字)并不能说“阵列的阵列”就不是多维阵列。
其实,平常沟通听得懂就好啦!若要严格讨论实作方式,才加以区别。
总结
阵列可说是最简单、也最重要的资料结构,它可用来表示方程式、矩阵等,也时常做为其他资结的构成基础(e.g., 堆叠、伫列、完整二元树)。
碍于篇幅,本篇不进一步探讨,未来再补充阵列的使用与实作。
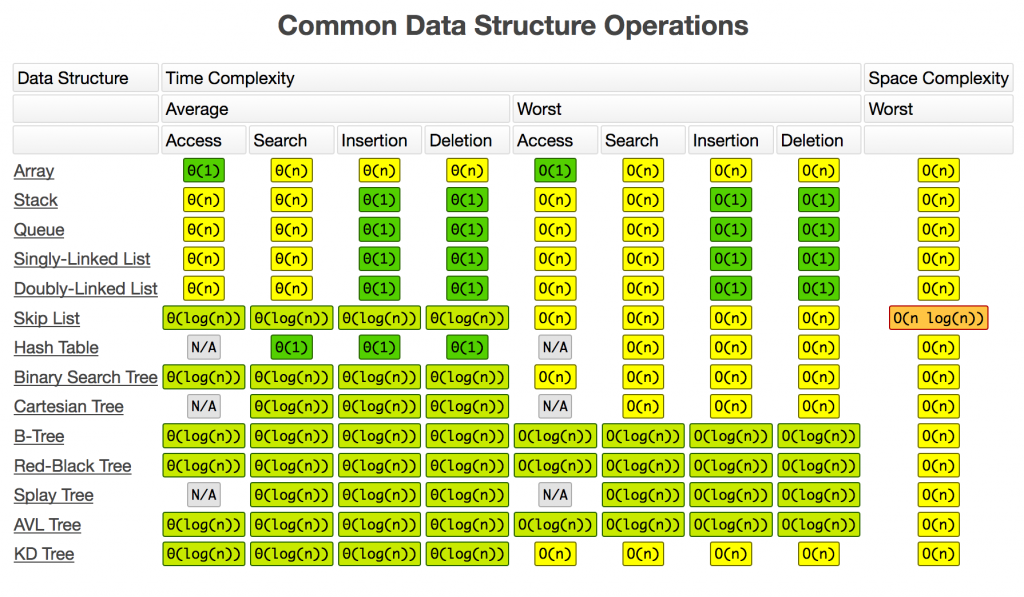
最后,附上 bigocheatsheet 的复杂度分析表:
位元储存范围
发表于 2017-02-04,郑中胜
不同的 字组、架构、资料型态等,各有其位元数,例如:8 位元、16 位元、32 位元、64 位元等,这对计算机领域的发展产生了深远影响。
本篇将超简短地说明位元储存范围的计算方式。
1 个位元,会有 2 = 2 1 2 = 2^1 2=21 种状态:‘0’、‘1’。

所以,2 个位元,会有 4 = 2 2 4 = 2^2 4=22 种状态: 0 10 ∼ 3 10 0_{10} \sim 3_{10} 010∼310 。
8 位元,会有 256 = 2 8 256 = 2^8 256=28 种状态: 0 10 ∼ 25 5 10 0_{10} \sim 255_{10} 010∼25510 。
16 位元,会有 65536 = 2 16 65536 = 2^{16} 65536=216 种状态: 0 10 ∼ 6553 5 10 0_{10} \sim 65535_{10} 010∼6553510 。
32 位元,会有 4294967296 = 2 32 4294967296 = 2^{32} 4294967296=232 种状态: 0 10 ∼ 429496729 5 10 0_{10} \sim 4294967295_{10} 010∼429496729510 。
…
因此, N N N 位元能表示 0 0 0 至 2 N − 1 2^N - 1 2N−1 的 2 N 2^N 2N 个正数。
例如,2 位元能表示 0、1、2、3(十进制),其最大值为 ‘3’,共有‘4’个数( 2 2 2^2 22)。
然而,以上是讨论纯二进制的状况,应用于不同领域(例如:有号数的表示),其‘数值范围’所代表的意义不尽相同。
例:许多语言中,int 时常以 32 位元储存:
#include <stdio.h>
#include <limits.h>
int main(void) {
printf("The size of int: %lu bytes.\n", sizeof(int));
printf("The minimum value of INT = %d\n", INT_MIN);
printf("The maximum value of INT = %d\n", INT_MAX);
return 0;
}
/*
* Result:
* The size of int: 4 bytes.
* The minimum value of INT = -2147483648
* The maximum value of INT = 2147483647
*/
总共有 4294967296 = 2 32 4294967296 = 2^{32} 4294967296=232 种状态没错,表示的概念却是 − 2147483648 ( − 2 31 ) ∼ 2147483647 ( 2 31 − 1 ) -2147483648 (-2^{31}) \sim 2147483647 (2^{31}-1) −2147483648(−231)∼2147483647(231−1) !
字节顺序 (Byte Order or Endianness) — big-endian vs. little-endian
2017-02-12 郑中胜
我们通常以从左到右、从上到下的方式书写,例如数字“九千四百八十七”,通常写作“9487”,而不是“7849”(尽管有些国家或族群的习惯可能是后者)。你不能说后者是错误的,因为这只是习惯的不同。
字节顺序 (Byte Order),或称端序 (Endianness),是指字节的排列顺序。不同的硬件架构、网络协议等在用法上不尽相同,没有绝对的好坏,只有是否适合。

端 (Endian)
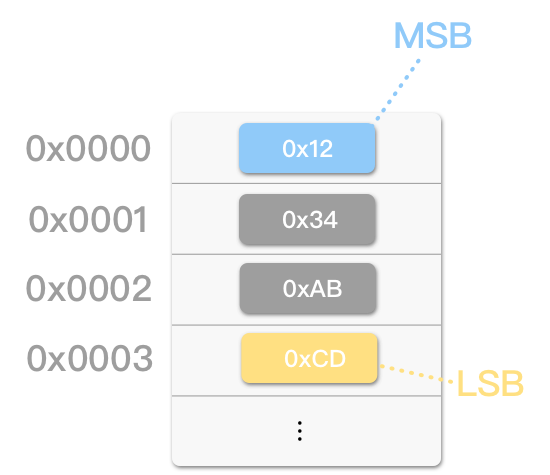
以 最高有效字节 (Most Significant Byte, MSB)_ 逐一存储字节的方式称为大端序 (big-endian)。
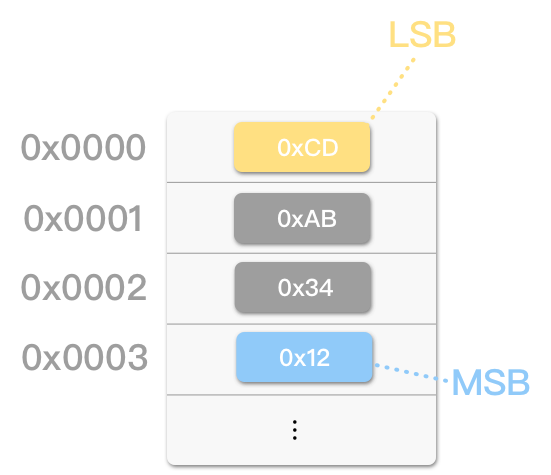
反之,以 最低有效字节 (Least Significant Byte, LSB)_ 逐一存储字节的方式称为小端序 (little-endian)。
以存储 0x1234ABCD 为例
大端序 (big-endian):
小端序 (little-endian):
(还有 Middle-endian,此处不再赘述)
由来
“endian”一词来源于十八世纪爱尔兰作家乔纳森·斯威夫特(Jonathan Swift)的小说《格列佛游记》(Gulliver’s Travels)。小说中,小人国为水煮蛋该从大的一端(Big-End)剥开还是小的一端(Little-End)剥开而争论,争论的双方分别被称为“大头派”和“小头派”。 —— 维基百科
主机字节顺序 (Host Byte Order)
大端序 (big-endian)
每台计算机根据其指令集架构 (Instruction Set Architecture, ISA),其字组定址 (word addressing) 和字节顺序 (Byte Order) 不尽相同。早期的 MIPS 架构就是大端序阵营的代表。
大端序适合人类习惯,逐字节内存转储 (Memory dump) 时非常方便阅读,且在许多情况下(如数值排序、估计值、符号判断等),直接检索最高有效字节非常有用。
小端序 (little-endian)
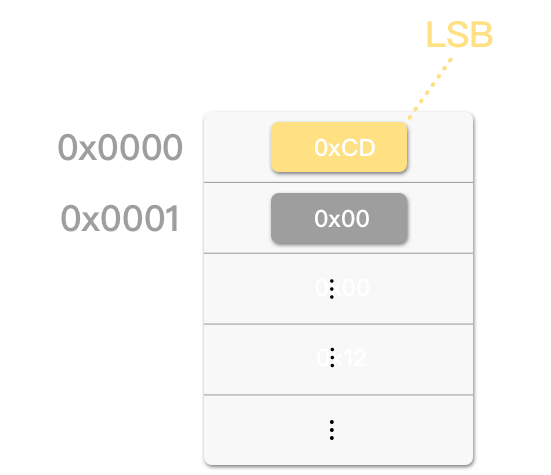
最广为人知的小端序架构当属 Intel x86 和 x86-64 处理器。
尽管大端序更为直观,但小端序也有其优势。一个常见的观点是:在小端序中,一个值无论是用 8 位、16 位、32 位等方式存储,都可以通过相同的基地址访问,简化了硬件设计并实现向下兼容。
例如:
- 8 位数据:0xCD
- 16 位数据:0x00CD
- 32 位数据:0x000000CD
都可以通过相同的地址 0x0000 访问。
检测
以下提供一些检测本机“默认”字节顺序的方法:
C 语言
通过指针类型转换和间接运算符 (*) 实现:
#include <stdio.h>
int main() {
int i = 1;
char *c = (char *) &i;
if (*c)
printf("LITTLE_ENDIAN\n");
else
printf("BIG_ENDIAN\n");
return 0;
}
或者通过观察地址变化:
#include <stdio.h>
int main() {
int num = 0x1234ABCD;
char *ptrNum = (char *) #
for (int i = 0; i < 4; i++)
printf("%p: %02x \n", (void *) ptrNum, (unsigned char) *ptrNum++);
return 0;
}
Java
使用 ByteOrder 类:
import java.nio.ByteOrder;
public class Main {
public static void main(String[] args) {
System.out.println(ByteOrder.nativeOrder());
}
}
C#
使用 BitConverter 类:
Console.WriteLine("IsLittleEndian: {0}", BitConverter.IsLittleEndian);
PHP
使用 pack 方法:
<?php
$result = "BIG_ENDIAN";
$i = 0x12345678;
$uLong = pack('L', $i);
if ($i === current(unpack('V', $uLong))) {
$result = "LITTLE_ENDIAN";
}
echo $result;
?>
我目前使用的 MacBook Pro (Retina, 13-inch, Early 2015) 的执行结果为:
LITTLE_ENDIAN
双端序 (bi-endianness)
为了提高性能和兼容性,许多现代架构(如 PowerPC、MIPS、ARM、IA-64 等)可以通过“切换”方式支持 big 和 little 两种顺序,即双端序 (bi-endianness)。
这也是为什么上述内容提到的是检测“默认”字节顺序(许多个人电脑默认为 little-endian)。
网络字节顺序 (Network Byte Order)
由于不同主机架构的字节顺序不尽相同,网络传输时需要统一的顺序规范,以确保 IP 地址、端口、数据包等能够通用。这种统一的顺序规范就是网络字节顺序 (Network Byte Order)。
大部分网络协议(如 TCP、UDP、IPv4、IPv6 等)都使用大端序 (big-endian),因此两者通常被视为等价。
转换
例如,十进制数字 80( 5016,十六进制的 50)在小端序( little-endian)中可能表示为:
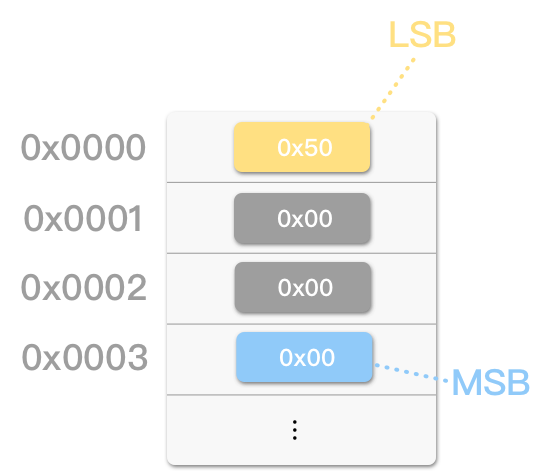
而在大端序(big-endian)中则表示为:
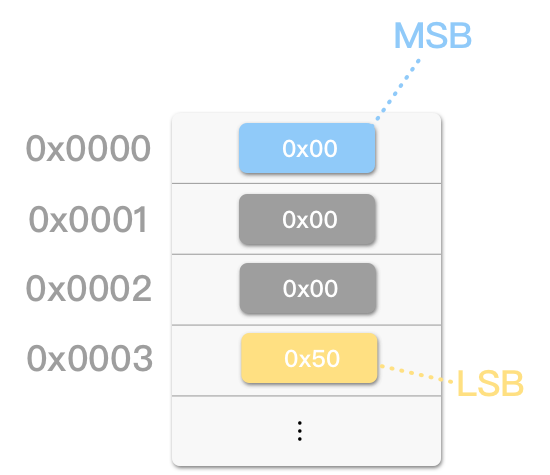
即小端序中的 1342177280。
幸运的是,Berkeley Socket 定义了一组函数(通常是宏),用于在主机字节顺序和网络字节顺序之间进行转换。这些函数包括:
-
htons:Return host_uint16 converted to network byte order
将主机的 16 位无符号整数转换为网络字节顺序 -
htonl:Return host_uint32 converted to network byte order
将主机的 32 位无符号整数转换为网络字节顺序 -
ntohs:Return net_uint16 converted to host byte order
将网络的 16 位无符号整数转换为主机字节顺序 -
ntohl:Return net_uint32 converted to host byte order
将网络的 32 位无符号整数转换为主机字节顺序
注:
-
h 表示主机 (host)
n 表示网络 (network)
u 表示无符号 (unsigned)
s 表示短整数 (short integer)
l 表示长整数 (long integer) -
需要注意的是,这是函数“原型”的命名方式。早期多数系统中,短整数和长整数分别是 16 位和 32 位,但如今长整数通常已不再是 32 位。
许多 socket 程序中都可以看到这些函数的使用。以下是一个使用示例:
#include <stdio.h>
#include <stdlib.h>
#include <arpa/inet.h>
#include <memory.h>
int main(int argc, char **argv) {
struct sockaddr_in svaddr;
char *address = "127.0.0.1";
int port_num = 9527;
/* Clear structure */
memset(&svaddr, 0, sizeof(struct sockaddr_in));
svaddr.sin_family = AF_INET;
// 将 port 由 本机字节顺序 转换为 网络字节顺序
svaddr.sin_port = htons(port_num);
printf("--------(1)--------\n");
printf("欲转换 port: %i\n", port_num);
printf("-------Result-------\n");
printf("htons: %i\n", svaddr.sin_port);
printf("\n\n");
// 将 address 由 本机字节顺序 转换为 网络字节顺序
if (inet_pton(AF_INET, address, &svaddr.sin_addr) <= 0) {
printf("inet_pton failed for address %s\n", address);
exit(EXIT_FAILURE);
}
printf("--------(2)--------\n");
printf("欲转换位址: %s\n", address);
printf("-------Result-------\n");
printf("inet_pton: %p\n", svaddr.sin_addr);
return 0;
}
/*
* Result:
*
* --------(1)--------
* 欲转换 port: 9527
* -------Result-------
* htons: 14117
*
* --------(2)--------
* 欲转换位址: 127.0.0.1
* -------Result-------
* inet_pton: 0x100007f
*/
中间还有一个重要的函数 —— inet_pton,用于取代传统的 inet_aton、inet_addr 等函数。它可以将 IPv4 和 IPv6 地址转换为网络字节顺序,其中 p 表示表示式 (presentation),n 表示网络。
Q: 如果本机是 big-endian,是否就不需用这些函数?
是的,但考虑到程序的可移植性,仍应使用这些函数,避免不必要的问题。
总结
除了 IP 地址和端口号,数据格式本身也必须定义字节顺序、编组或序列化格式等,如数据帧 (frame)、远程过程调用 (RPC) 的外部数据表示方式 (XDR)、XML 等。
因此,无论是跨网络还是存储设备的数据传输,字节顺序 (Byte Order) 都是编程中需要注意的细节。使用错误的顺序会导致文件损坏或异常错误。
范例原始档
有号数字表示法 — 2 的补数、1 的补数与符号大小
2017-02-25 郑中胜
在 进制简介. 中,我们简单介绍了进制的概念,包括进制的 转换.、负数与运算。这有助于我们使用熟悉的十进制 (Decimal) 或十六进制 (Hex),而无需记忆长串的二进制数(如“10010100001111…”),从而更好地理解计算机组织、汇编语言等,并提高编程效率。
有号数字及无号数字 (Signed and Unsigned Numbers)
在数学领域中,整数 (Integer) 包括正整数和 0,
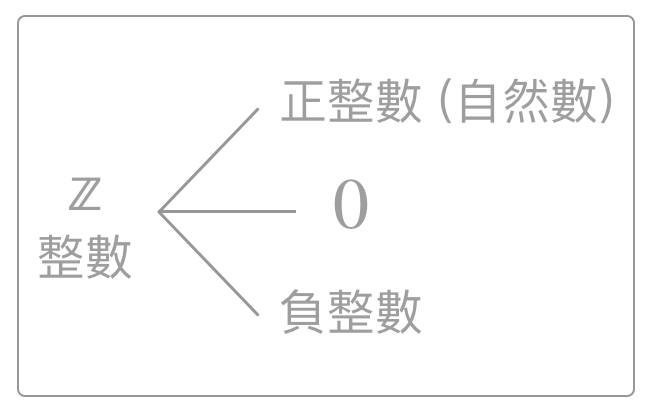
可以通过 进制转换. 转换为计算机使用的二进制,这种表示法称为“无号”数字 (Unsigned Numbers),因为它们没有“+”和“-”符号。
例如,在 C 语言中,有以下无号整数类型:
_Bool (since C99), unsigned char, unsigned short,
unsigned int, unsigned long, unsigned long long (since C99)
数据库中也常见到如下字段属性:
- UNSIGNED
- UNSIGNED ZEROFILL
在计算机组织中,无号数字常用于表示内存地址。
然而,负数该如何表示呢?在数学中,我们可以通过添加“-”符号来表示负数(例如 -1),但计算机硬件使用的是二进制(0 和 1),无法理解负“-”符号。因此,我们需要找到一种方法来表示正数 (+) 和负数 (-),即“有号”数字 (Signed Numbers) 的表示法。
有号数字表示法 (Signed Number Representations)
常见的有号数字表示法有四种:
- 符号大小 (Sign and Magnitude)
- 1 的补数 (Ones’ Complement)
- 2 的补数 (Two’s Complement)
- 偏移表示法 (Biased Notation)
前三种表示法中,大于等于 0 的正数与普通二进制没有区别,区别在于“负数”的表示。
在详细介绍这些表示法之前,需要了解“普通二进制”与“计算机二进制”的差异。
在十进制中, 0000000 … 0087 0000000\ldots0087 0000000…0087 等于 87,真实的数字可以有无限多个位数,通常会省略多余的 0。然而,计算机存储的字组大小是固定的,这意味着:
- “数”的存储范围有限。
- “数”的存储必须遵循某种格式。
- 与普通二进制的转换可能没有意义(例如,1111 可能表示 -1,而非 15)。
- 两个数的运算结果可能会超出范围,导致溢出 (overflow)。
这也是为什么我们在书写时可能会这样表示:
[87_{10} = 1010111_2]
或者:
[87_{10} = 101\ 0111_2]
符号大小 (Sign and Magnitude)
符号大小 (Sign and Magnitude),又称原码,是最直观的表示法,即:
使用一个位元 (bit) 来表示正 (+) 和负 (-) 。
例如,“0”表示正数,“1”表示负数。这个位元称为符号位元 (sign bit),通常位于最高有效位元 (MSB)。
计算机字组使用固定大小,假设用 8 位元表示一个数字,去掉“符号位元”后,用于表示数值的部分剩下 7 位元:

同理,使用 n n n 位元表示一个整数,去掉“符号位元”后,用于表示数值的部分剩下 n − 1 n-1 n−1 位元。
| 十进制 | 符号大小 |
|---|---|
| + 2 n − 1 − 1 +2^{n-1}-1 +2n−1−1 | 0111 1111 1111 …. 1111 |
| . . | . . |
| + 2 | 0000 0000 0000 …. 0010 |
| + 1 | 0000 0000 0000 …. 0001 |
| + 0 | 0000 0000 0000 …. 0000 |
| – 0 | 1000 0000 0000 …. 0000 |
| – 1 | 1000 0000 0000 …. 0001 |
| – 2 | 1000 0000 0000 …. 0010 |
| . . | . . |
| − 2 n − 1 − 1 -2^{n-1}-1 −2n−1−1 | 1111 1111 1111 …. 1111 |
正数表达范围: + 0 ∼ + 2 n − 1 − 1 +0 \sim +2^{n-1}-1 +0∼+2n−1−1,负数表达范围: − 0 ∼ − 2 n − 1 − 1 -0 \sim -2^{n-1}-1 −0∼−2n−1−1
值得注意的是:
符号大小 (Sign and Magnitude) 表示法的 +0 和 -0 是不同的!
当执行加法运算时,无法预知结果的正负,加法器可能需要额外的步骤来设置符号。
尽管这些因素使得符号大小 (Sign and Magnitude) 不适合用于整数表示和加法器实现,但它适合用于浮点数的表示,这将在后续内容中提及。
1 的补数 (Ones’ Complement)
1 的补数 (Ones’ Complement),又称反码,计算负值的方法是:
反转/反向 (inverse) 每一个位元,原本是‘1’就变成‘0’,‘0’就变成‘1’。
或者:
2 n – x – 1 2^n – x – 1 2n–x–1 ( n n n 为位元数, x x x 为欲转换正数)
例如(4 位元的 1 的补数):
- ‘3’表示为:0011
- ‘-3’表示为:1100
正数的最大值为:0111 1111 1111 … 1111,负数的最大值为:1000 0000 0000 … 0000。
| 十进制 | 1 的补数 |
|---|---|
| + 2 n − 1 − 1 +2^{n-1}-1 +2n−1−1 | 0111 1111 1111 …. 1111 |
| . . | . . |
| + 2 | 0000 0000 0000 …. 0010 |
| + 1 | 0000 0000 0000 …. 0001 |
| + 0 | 0000 0000 0000 …. 0000 |
| – 0 | 1111 1111 1111 …. 1111 |
| – 1 | 1111 1111 1111 …. 1110 |
| – 2 | 1111 1111 1111 …. 1101 |
| . . | . . |
| − 2 n − 1 − 1 -2^{n-1}-1 −2n−1−1 | 1000 0000 0000 …. 0000 |
正数表达范围: + 0 ∼ + 2 n − 1 – 1 +0 \sim +2^{n-1} – 1 +0∼+2n−1–1,负数表达范围: − 0 ∼ − 2 n − 1 – 1 -0 \sim -2^{n-1} – 1 −0∼−2n−1–1
0 依然有两种表示法:+0 和 -0。
1 的补数和 (Ones’ Complement Sum)
使用 1 的补数进行加法运算的结果称为 1 的补数和。减法可以通过加上一个“负数”来完成。
例如,3 – 2 的运算可以通过 3 + (-2) 来完成。
- ‘3’表示为:0011
- ‘+’表示 1 的补数加法(常表示为:{+1s} 或 +’)
- ‘-2’表示为:1101(4 位元)
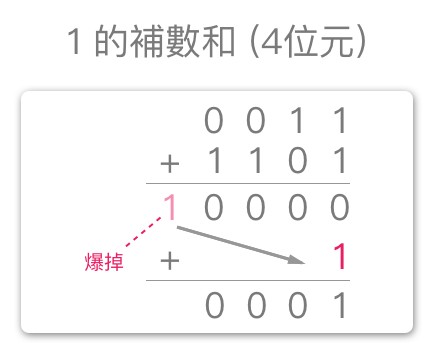
如果有溢出的位数,需要将其加回,称为端回进位 (end around carry),即把溢出的最高有效位元加回到最低有效位元。这是 1 的补数的重要特性。
这种特性使得 1 的补数 (Ones’ Complement) 实现了字节顺序独立 (Byte Order Independence),即重新排序的输出等价于重新排序的输入。
例如,计算字节 A, B, C, D, …, Y, Z 的 1 的补数和:
- 大端序:[A,B] +’ [C,D] +’ … +’ [Y,Z]
- 小端序:[B,A] +’ [D,C] +’ … +’ [Z,Y]
计算结果在交换后将会相同。
由于字节顺序独立的特性,多字节的加法可以以相同的形式进行跨字节的进位,而无需考虑主机字节顺序。
1 的补数 (Ones’ Complement) 广泛应用于网络通信协议中的 检验和 计算,甚至常作为反向运算的代名词。
实际上:
有号数表示和加法器实现等主要还是以 2 的补数为主,1 的补数仅作为一种“通用的”计算机制。
2 的补数 (Two’s Complement)
然而,1 的补数仍然存在两个 0(+0 和 -0),并且加法器在做减法时通常需要一个额外的步骤来进行端回进位。
2 的补数 (Two’s Complement) 可以避免这些问题,因此在程序语言的整数表示和加法器实现中几乎都采用 2 的补数表示法。
2 的补数,或称补码:
与符号大小和 1 的补数一样,大于等于 0 的正数与普通二进制没有区别,区别在于“负数”的表示。
2 的补数的“负数”实际上是 1 的补数加 1,或者:
2 n – x 2^n – x 2n–x ( n n n 为位元数, x x x 为欲转换正数)
例如:
- ‘3’表示为:0011
- ‘-3’的 1 的补数表示为:1100
- ‘-3’的 2 的补数表示为:1101
正数的最大值为:0111 1111 1111 … 1111,负数的最大值为:1000 0000 0000 … 0000。
| 十进制 | 2 的补数 |
|---|---|
| + 2 n − 1 − 1 +2^{n-1}-1 +2n−1−1 | 0111 1111 1111 …. 1111 |
| . . | . . |
| + 2 | 0000 0000 0000 …. 0010 |
| + 1 | 0000 0000 0000 …. 0001 |
| 0 | 0000 0000 0000 …. 0000 |
| – 1 | 1111 1111 1111 …. 1111 |
| – 2 | 1111 1111 1111 …. 1110 |
| – 3 | 1111 1111 1111 …. 1101 |
| . . | . . |
| − 2 n − 1 -2^{n-1} −2n−1 | 1000 0000 0000 …. 0000 |
正数表达范围: 0 ∼ + 2 n − 1 − 1 0 \sim +2^{n-1} - 1 0∼+2n−1−1,负数表达范围: − 1 ∼ − 2 n − 1 -1 \sim -2^{n-1} −1∼−2n−1,有一个没有对应正值的负数 − 2 n − 1 -2^{n-1} −2n−1。
0 只有一种表示法:0000 0000 … 0000,并且所有负数的最高有效位元均为 1。
减法同样可以通过加上一个“负数”来完成。
例如,3 – 2 的运算可以通过 3 + (-2) 来完成。
- ‘3’表示为:0011
- ‘+’表示 2 的补数加法(常表示为:{+2s})
- ‘-2’表示为:1110(4 位元)

如果有溢出的位数,不需要进行端回进位 (end around carry)。
偏移表示法 (Biased Notation)
尽管 2 的补数表示法在有号数表示和加法器实现等方面具有绝对优势,但其负数在真实二进制中看起来像是一个很大的正数,排序上并不直观。例如:
2's 补数: 1000 = 负数 -8
一般二进制: 1000 = 正数 8
偏移表示法 (Biased Notation),又称移码 excess-N,是通过将原数的 2 的补数加上一个偏移值来实现的。
例如,在二进制浮点数算术标准 (IEEE 754) 中,单精度浮点数的偏移值为 127。
-
‘-1’的 2’s 补数:1111 1111₂
-
偏移值 127 的偏移表示法:-1 + 127 = 126 = 0111 1110₂
-
‘1’的 2’s 补数:0000 0001₂
-
偏移值 127 的偏移表示法:1 + 127 = 128 = 1000 0000₂
偏移表示法广泛应用于浮点数表示法中的指数字段。
总结
好的设计需要有好的折衷 (Good design demands good compromises)。
这几种表示法没有绝对的优劣之分,只有是否适合特定应用场景。例如:
- 浮点数表示法标准:符号大小、偏移表示法
- 网络通信协议的检验和:1 的补数
- 程序语言的整数表示和加法器实现:2 的补数
学习有号数字表示法有助于深入理解计算机和通信协议的许多知识。
TCP 检验和 (TCP Checksum)
2017-02-26 郑中胜
在 TCP 三向交握 (Three-way Handshake)_ 中,我们介绍了 TCP 建立连接的方式,并提到了数据段 (Segment) 的概念。TCP 使用错误控制 (Error Control) 机制来确保传输的可靠性,其中最常见的是检验和 (checksum)、确认 (acknowledgement) 和超时 (time-out)。
本篇将详细说明 TCP 检验和 (TCP Checksum) 的工作原理。
检验和 (Checksum)
检验和 (Checksum) 提供了一种计算方式,用于检测数据段 (segment) 是否受损。
- 发送方:在发送 TCP 数据段之前,计算 Checksum 值,并将其存储在 Checksum 字段中。
- 接收方:接收数据段后,使用相同的计算方式计算 Checksum 值,并与收到的数据段中的 Checksum 字段值进行比较。如果两者不相等,接收方将丢弃该数据段,并将其视为丢失的数据段。
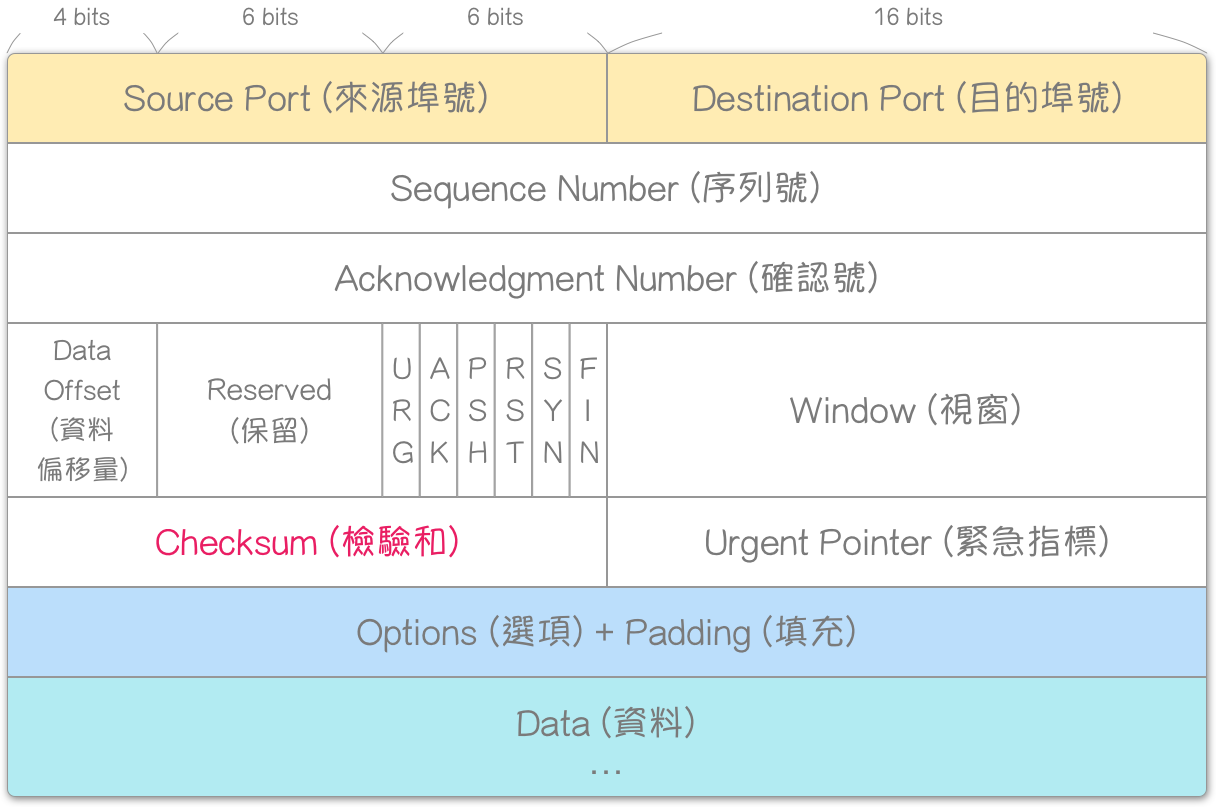
虚拟表头 (Pseudo-Header) — IPv4
在介绍计算方式之前,需要先了解虚拟表头 (Pseudo-Header) 的概念。
如上图所示,TCP 本身不包含地址信息,这可能导致数据段被错误路由 (misrouted)。因此,需要提供足够的信息以便检验和能够检测路由错误,这些信息就是虚拟表头 (Pseudo-Header)。虚拟表头总共有 12 个字节 (octet),即 96 位元。
之所以称为“虚拟”(Pseudo),是因为它仅用于检验和计算,并不实际传输(地址字段来自 IP 表头)。

虚拟表头的组成部分如下:
- 来源地址 (Source Address):32 位元的来源 IPv4 地址
- 目的地址 (Destination Address):32 位元的目的 IPv4 地址
- Zero:顾名思义,值为 00000000
- PTCL:通讯协议 (protocol) 的缩写,用于指示使用的通讯协议的代号。TCP 为 6,UDP 为 17。
- TCP Length:TCP 数据段的长度(表头 + 数据),不包括虚拟表头的 12 个字节。
虚拟表头 (Pseudo-Header) — IPv6
如果使用的是 128 位元的 IPv6 地址而不是 32 位元的 IPv4 地址,虚拟表头也会有所不同。

- 来源地址 (Source Address) 和 目的地址 (Destination Address):不再是 IPv4 的 32 位元(4 字节),而是 IPv6 的 128 位元(16 字节)
- Zero:顾名思义,值为 00000000 00000000 00000000(3 字节)
- PTCL:与 IPv4 相同,TCP 为 6,UDP 为 17(1 字节)
- TCP Length:TCP 数据段的长度(表头 + 数据),不包括虚拟表头的 40 个字节(4 字节)
TCP/IPv4 虚拟表头为 12 个字节 (octet),TCP/IPv6 虚拟表头为 40 个字节 (16+16+3+1+4)。
计算方式 — 发送方
- 清空 Checksum 字段:在发送方,必须先清空 Checksum 字段,以生成 Checksum 值。
- 配对字节:将要计算检验和的相邻字节配对为 16 位整数,包括虚拟表头 (Pseudo-Header)、TCP 数据段(表头 + 数据),当然也包括 Checksum 字段(发送方会先清空)。如果数据长度为奇数,则暂时填补一个全部为 0 的字节。
- 计算 1 的补数和:形成这些 16 位整数的 1 的补数和 (1’s complement sum)_。
- 计算最终 Checksum 值:将此“1 的补数和”经过“1 的补数”运算后,放入 Checksum 字段中。
简单来说:
Checksum 字段是所有 16 位字在表头和文本中的 1 的补数和的 1 的补数。
计算方式 — 接收方
接收方的计算方式与发送方相同,唯一的区别是不需要清空收到的 Checksum 字段(因为需要通过它来进行检查)。
如果计算出的“1 的补数和”为 1111 1111 … 1111,或者 Checksum 值为 0000 0000 … 0000,则表示验证成功,反之则失败。
至于为什么计算出的值会是 0000…,假设发送方经过步骤‘1’、‘2’、‘3’:
利用“1 的补数和”计算包含虚拟表头 (Pseudo-Header) 和 TCP 数据段(表头 + 数据),其值为:‘0111’(实际上,当然不是 4 位元,仅为理解用)。
TCP 数据段 (TCP Segment):

接着,经过步骤‘4’:
经过“1 的补数”运算后,计算出 Checksum 字段为:‘1000’。
如果数据段没有问题,接收方经过‘1’、‘2’、‘3’步骤,计算出的 1 的补数和将是:‘0111’ + ‘1000’ = ‘1111’。
最后,经过步骤‘4’:
经过“1 的补数”运算‘1111’后,结果自然是:‘0000’。
协定资料单元 — 区段(Segment)、资料包(Datagram)、讯框(Frame)
发表于 2017-02-27,郑中胜
网络协定(networking protocol)由许多层级(layer)组成,每一层所使用的资料结构则统称为协定资料单元(PDU)。
其中包含了控制与位址资讯的表头/标头(header),与实际乘载的资料(data)。
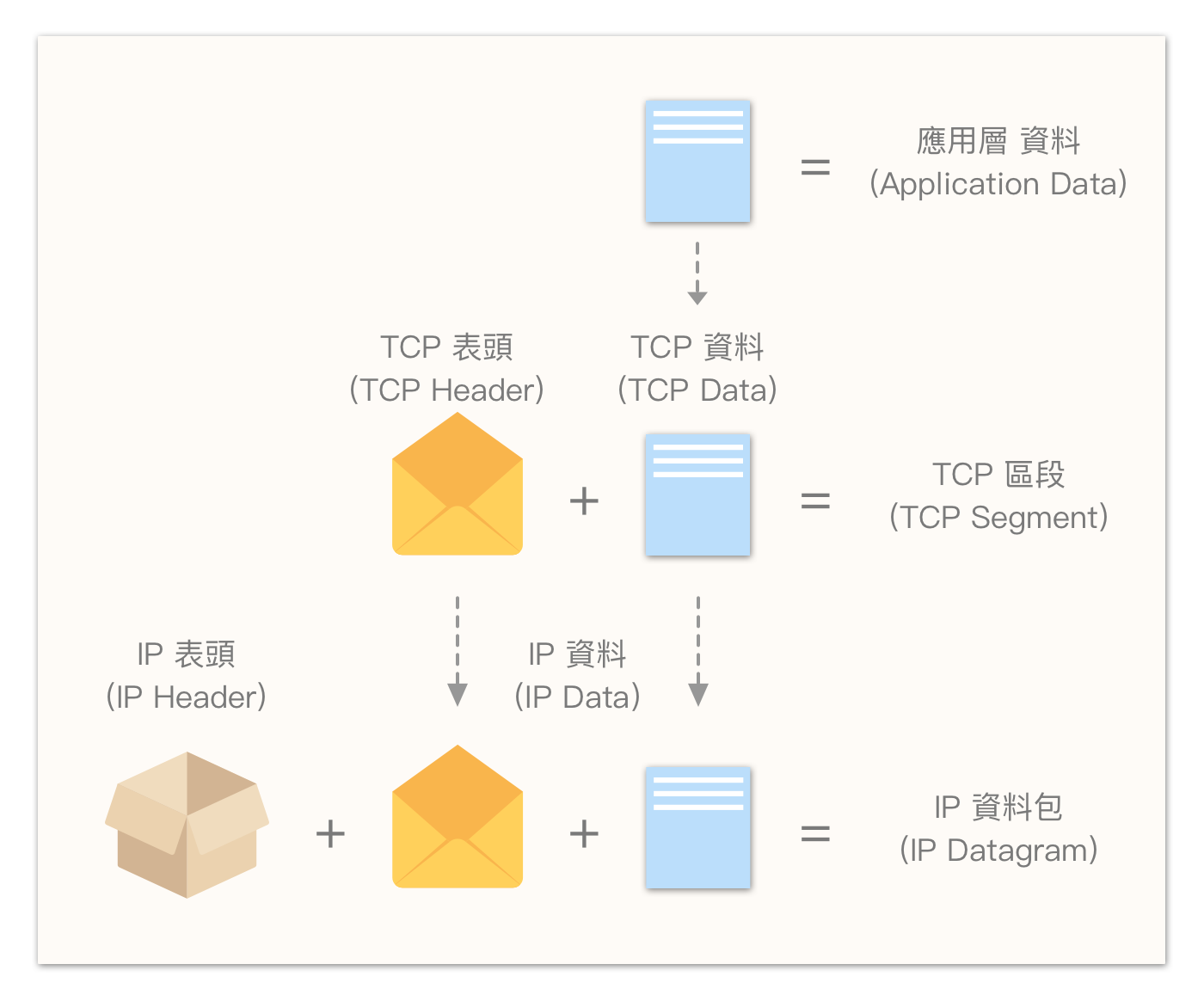
封装与拆装(Encapsulation & Decapsulation)
先来个简单的示意图:
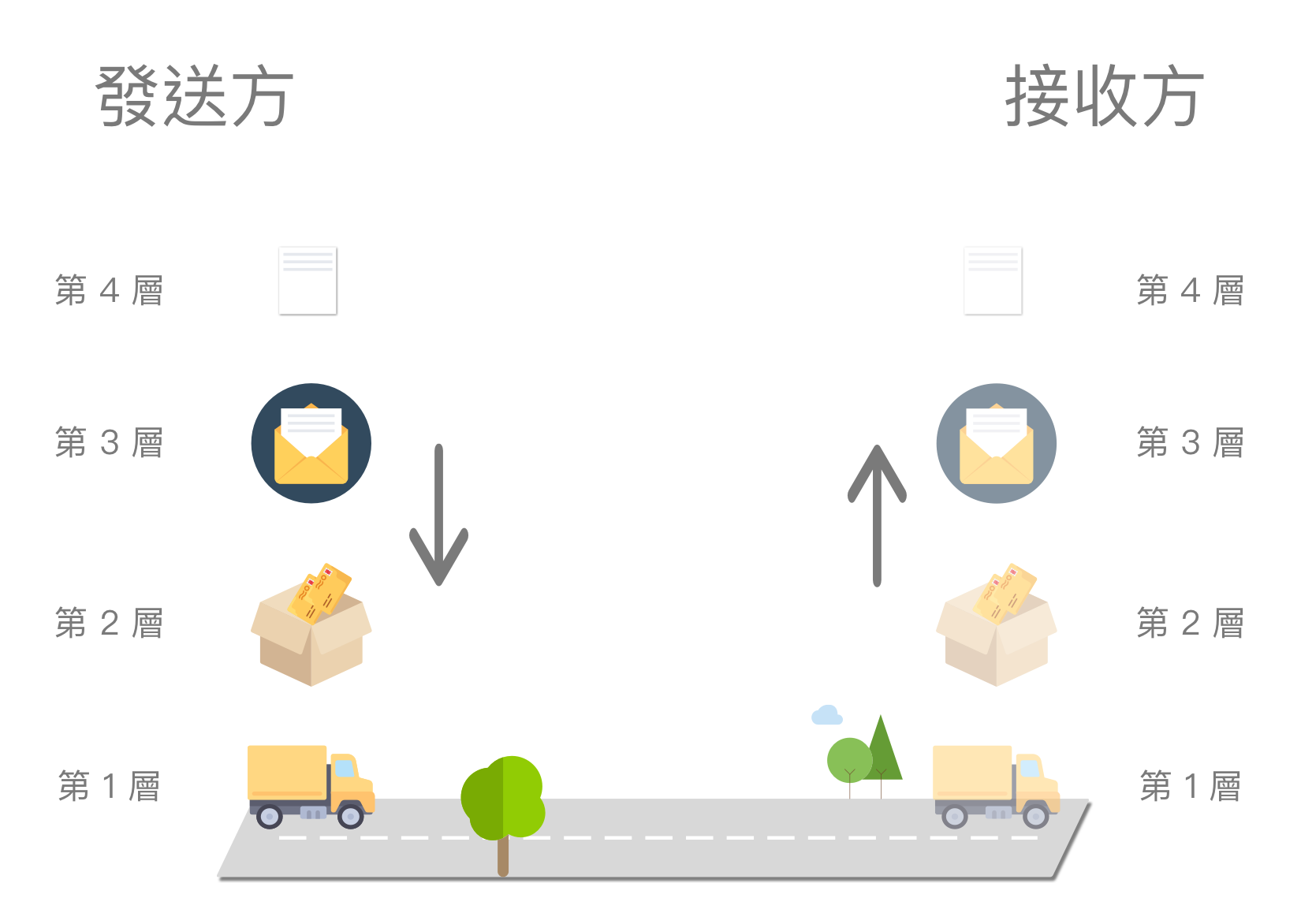
发送方写好了信纸(第 4 层),将其放入信封,并写上收件人、地址等后,成为了信件(第 3 层),接着将多封信件封箱,成为了包裹(第 2 层),最后交由卡车将其运输给接收方(第 1 层)。
这种在资料/封包在传递到下一层以前,新增此层的表头(header)或其他元资料的动作,称为封装。
反之,拆装,或称解封装、解包(unpack),是资料/封包从底层传递到上层前,去除表头的行为。
封装(Encapsulation)与拆装(Decapsulation),抽象出每层的资料结构,使底层无需知道上层的具体细节,以增加酬载(payload)的扩充性与弹性。
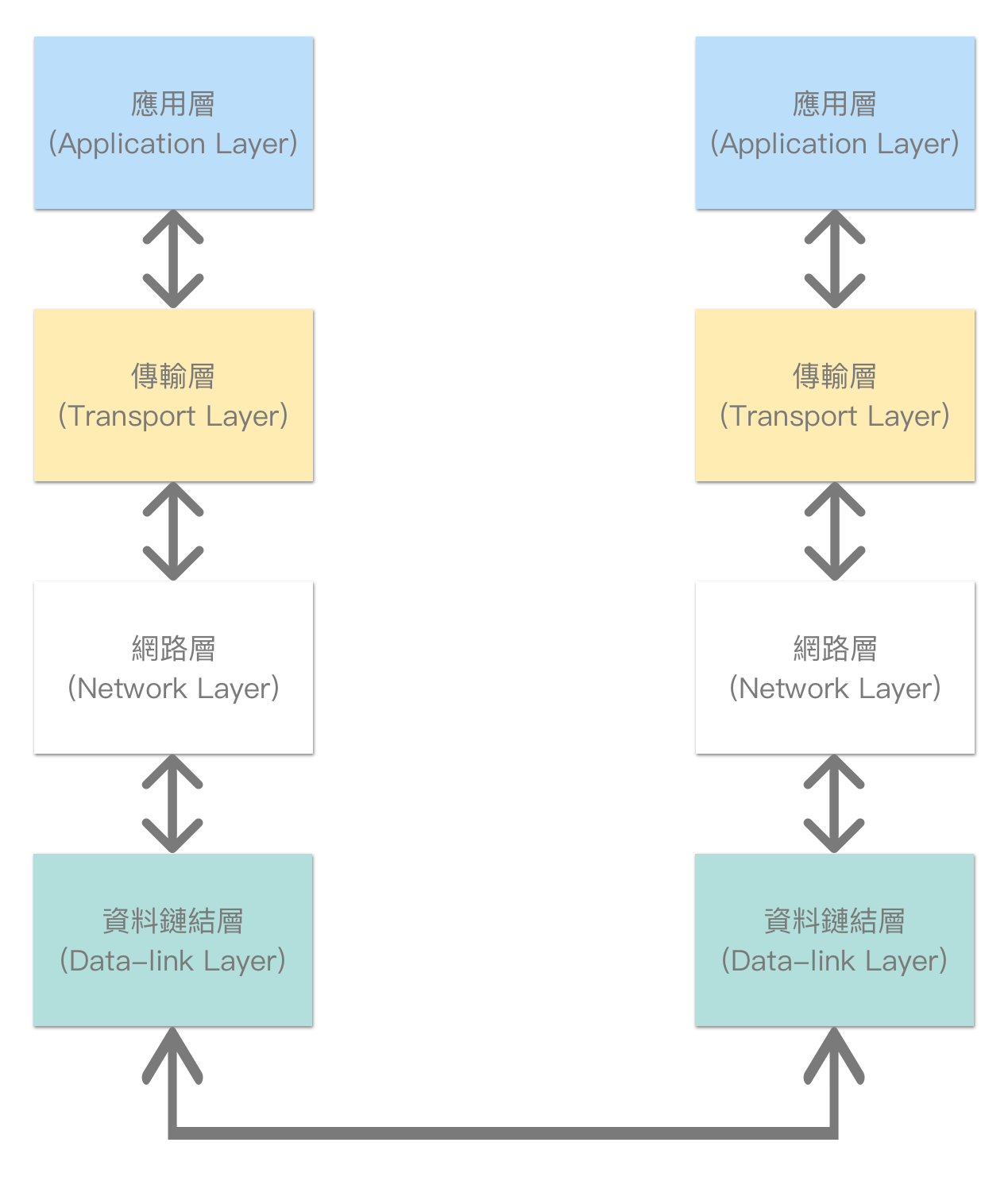
TCP/IP Model
相同的观念,应用在常见的 TCP/IP Model 中:
以 TCP/IP 为例,就像信纸 + 信封,称为信件:
- TCP 表头 + 资料,称为 TCP 区段(TCP Segment);
- IP 表头 + 资料,称为 IP 资料包(IP Datagram)或更常见的名称 — 封包(packet);
- 资料链接层表头 + 资料 + 表尾(如果有的话),则称作讯框(Frame)。
另外,若传输层使用 UDP,则称为 UDP 资料包(UDP Datagram),应用层也可能自我(或结合其他应用)进行封装。
而他们有个更通用的名字:协议资料单元(Protocol Data Unit, PDU)。
最大传输单元(Maximum Transmission Unit, MTU)
发表于 2017-02-27,郑中胜
封装与拆装 一文,提及了区段(Segment)、资料包(Datagram)、讯框(Frame)、封包(Packet)的概念。
应用层的资料,经由逐层的封装(Encapsulation),最后成为资料链接层(Data-Link Layer)的讯框(Frame)并传送。
但是,讯框(Frame)太大会发生什么事?
- 传输需耗损大量的缓冲区(buffer)大小;
- 传输媒介可能被某一传送端独占,造成堵塞;
- …
因此,资料链接层(Data-Link)规范了讯框(Frame)的大小上限,也就是 — — 最大传输单元(Maximum Transmission Unit, MTU),如果没有这些缺点,MTU 当然越大越好!
最大传输单元(MTU)
不同的资料链接层,有不同的 MTU。
如:
- 以太网(Ethernet)的 1500 个字节;
- IEEE 802.3/802.2 的 1492 个字节;
- 光纤分散式数据界面(FDDI)的 4352 个字节…。
以以太网(Ethernet)为例:
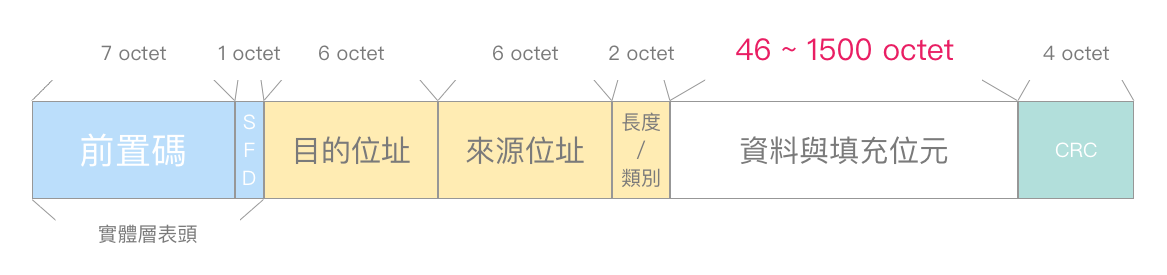
一个以太网讯框(Frame),最大的长度为 1518 字节(octet),去掉表头与尾端资讯后,酬载的最大资料长度则为 1500 octet,且资料最小长度需为 46 octet,不足的话就用填充位元(padding)填满至 46 为止。
使用指令:
netstat -i
可显示系统网络界面资讯(含 MTU)

IP 分段 (IP Fragmentation)
网络层的 IPv4 与 IPv6,其封包大小上限,分别为 65535 与 65575 字节(octet),并提供较大的封包选项 — — 巨型封包(jumbograms)。
远远超出了许多资料链接层的讯框大小!
IP 分段(IP Fragmentation)即是其中一种解法:
IP 会将封包切割成多个较小的(小于 MTU)片段(fragment),使其能透过资料链接层传输 ,目的端接收完所有片段后,再将片段(fragment)进行重组。
分段(fragmentation),可能由传输路径中的任何一台路由器来做(含来源主机),且被分段的封包 — — 片段(fragment)可能经由不同路由方式,只要最终达到相同的目的地即可。(IPv6 只有来源端可以做分段)
将 IP 资料包(IP Datagram)分段的主机或路由器,会复制必要字段到各个片段中,并更改旗标、片段偏移量、(封包)总长度,与重新计算各个分段的 检验和_。(IP 检验和,不含虚拟表头)
最后,目的端接收完所有片段后,再将片段(fragment)进行重组:
Path MTU Discovery
如果 IP Fragmentation 任一片段遗失、毁损呢?
答案是:目的端将无法重组这个封包。
更重要的是:网络层的 IP 并不会处理重送。
这对有重送机制的传输层(Ex:TCP),降低了传输效率(无法只重送一个片段);对没有重送机制的传输层(Ex:UDP),增加了资料的遗失率。
Path MTU Discovery 技术,有效的避免 IP Fragmentation:
找出来源与目的端路径中,所有资料链接层里的最小 MTU。(通常,为以太网的 1500 octet)
许多可靠的传输层(如:TCP),会以此值做为参考,调整最大区段长度(Maximum Segment Size, MSS)。
最简单的算法:
MSS = MTU - 20 octet (TCP 固定表头) - 20 octet (IP 固定表头)
或其他动态调整算法,常见的 MSS 有 1460、1400、1380…。
而没有此机制的传输层(如:UDP),则是选择适当的资料包(Datagram)大小,确保传输的 IP 封包,会小于 IPv4 的最小可重组缓冲区大小(576 octet),避免 IP Fragmentation。
TCP 流量控制(Flow Control)
发表于 2017-03-08,郑中胜
TCP 流量控制(Flow Control), 用于平衡传送端与接收端的流量, 避免高速传送端瘫痪了低速接收端。
接收缓冲区(Receiving Buffers)
满了的信箱,继续塞信会如何?—— 爆掉。

信与食物的补充,与‘消化’速度并不相等!它们需要‘消化’,才能继续装新东西,信箱或胃,这种用来储存、待消化的空间,即是 — — 接收缓冲区(Receiving Buffers)概念。
同理,维护应用层资料的 — — 传输控制协定(Transmission Control Protocol, TCP) ,由于发送者(Sender)与接收者(Recipient)传输、读取的速率不相等,接收端会将资料暂存在接收缓冲区(Receiving Buffers),并等待应用层读取后(消化),再从接收缓冲区中清除。
TCP 每次发送与接收单位为:TCP 区段(TCP Segment),每个区段的大小不尽相同,有可能数百~数万 个字节。
TCP/IP 的网络层 — — IP 协定,不保证资料会照发送顺序抵达接收端,接收端可利用表头中的 序列号(Sequence Number, SEQ) 字段进行排序、消除重复(eliminate duplicates),以保证资料接收的正确顺序,并以字节串流(byte-stream)的方式,传递给应用层。
接收视窗(Receive Window)
接收缓冲区(Receiving Buffers),实际上就是一段内存位址,时常使用 环状伫列(circular queue) 资料结构来实作,使空间有效率的复用,并避免大量资料的搬移。

‘环状’仅为概念上的表示,实际仍为线性资料,因此更常表示为:
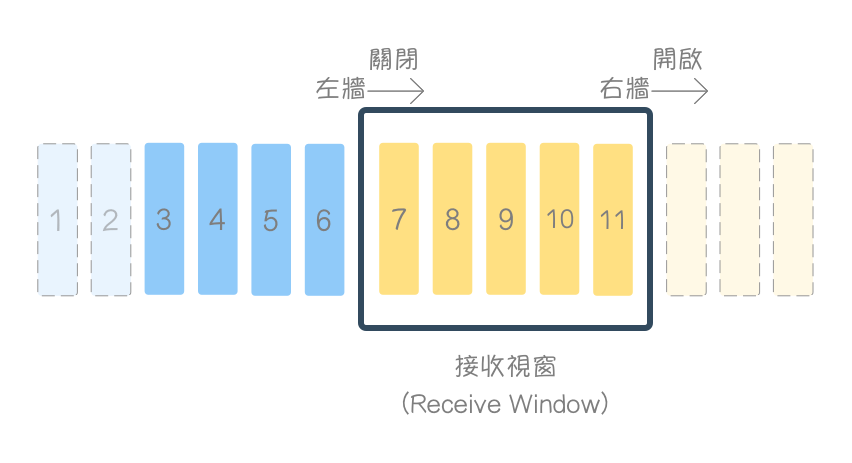
(仅为示意,实际大小通常为数万个以上之字节)
- 1、2 ,为应用层已读取,并从接收缓冲区清除之字节。
- 3、4、5、6 为已接收并确认(acknowledged)收到,应用层尚未读取(消化)之字节。
- 在接收视窗内的 7、8、9、10、11 为等待接收资料的空的缓冲区,3、4、5、6、7、8、9、10、11 合计就是接收缓冲区大小 !
- 超出接收视窗大小(Receive Window Size, rwnd)的部分则无法接收。
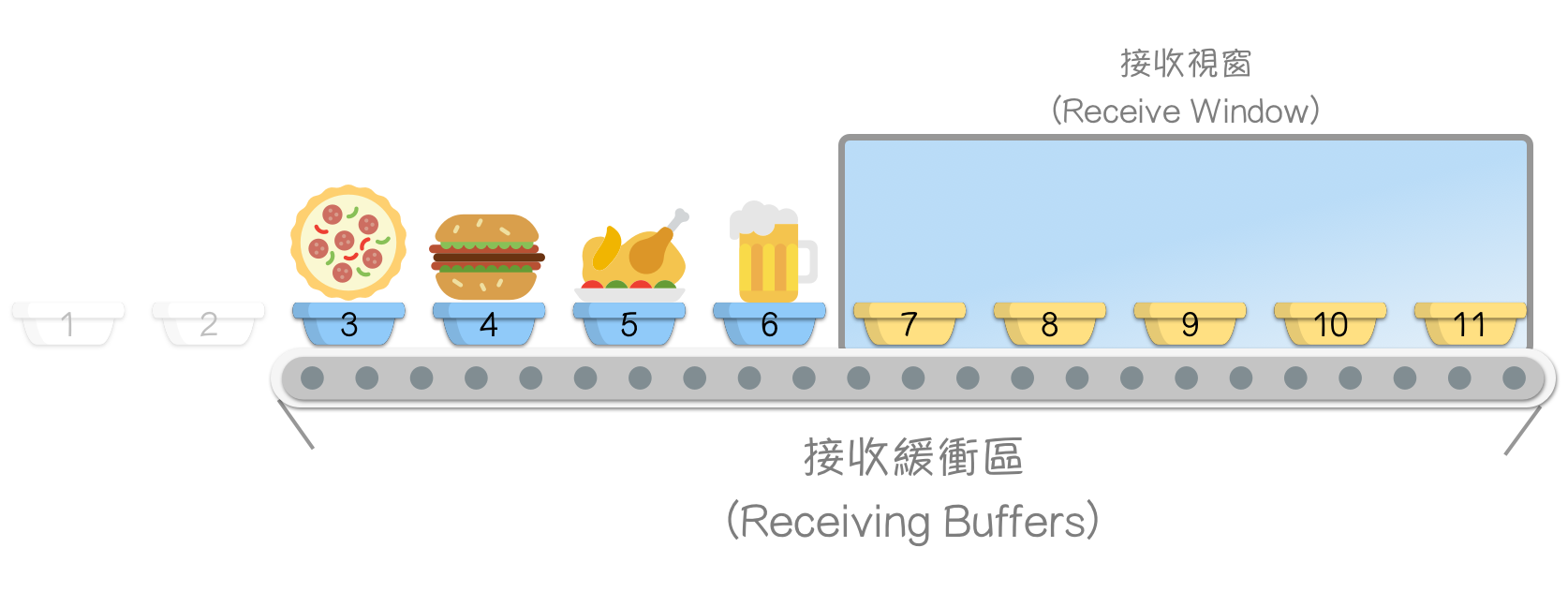
接收视窗(Receive Window),是 TCP 用来计算接收缓冲区的机制,一般称接收视窗大小(Receive Window Size)为 — — rwnd,
r w n d = 接收缓冲区大小–等待被应用层接收之字节大小 rwnd = 接收缓冲区大小 – 等待被应用层接收之字节大小 rwnd=接收缓冲区大小–等待被应用层接收之字节大小
公式推导(参考上图):
盘子 7、8、9、10、11 = 接收缓冲区大小 - (披萨 + 汉堡 + 鸡腿 + 啤酒) (咦?)
=> 5 = 9 - 4
- 当接收端收到资料,并回复确认(acknowledgment)收到,接收视窗会关闭(Close)(左墙 往右移)。
- 当接收段应用层读取资料 (消化)时,资料会被清除,接收视窗会开启(Open)(右墙 往右移)。
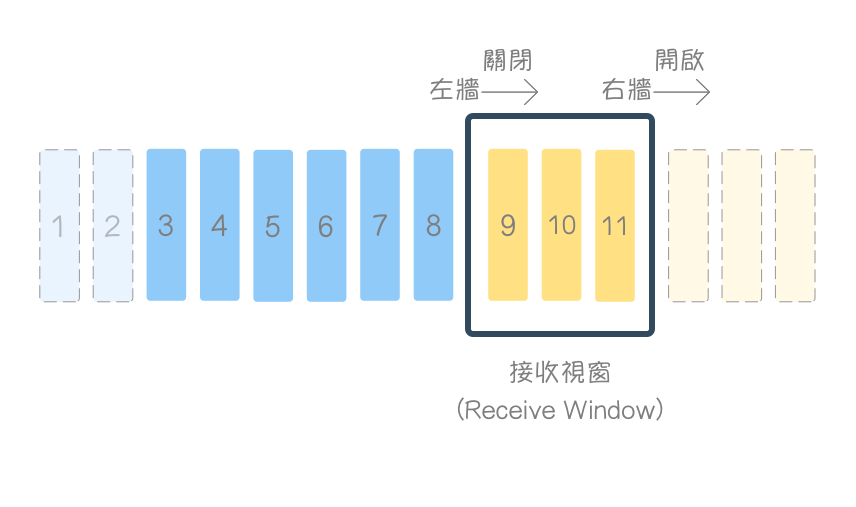
范例
延续上述例子,这时收到了 7、8 字节,并回复确认(acknowledgment),接收视窗关闭(Close)(左墙 往右移),rwnd = 3
接着,应用层读取了 3、4、5 字节,其自接收缓冲区中清除,接收视窗开启(Open)(右墙 往右移),rwnd = 6
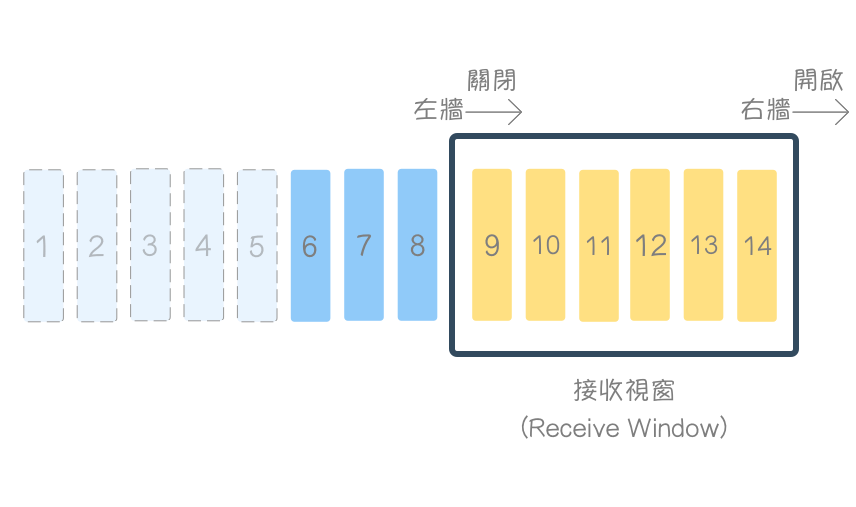
再次提醒:实际上不可能传输这么小的区段,仅为帮助理解用。
发送缓冲区(Sending Buffers)
发送者将待发送的数据放置在发送缓冲区(Sending Buffers)并送出。如同接收缓冲区在数据被“消化”(应用层接收数据)后才清除数据一样,发送缓冲区在数据送出后,需等待接收者回复确认(acknowledgment)收到,才会将数据从发送缓冲区中清除。无论是发送缓冲区还是接收缓冲区,其空间都会被回收并重复利用,这也是缓冲区常采用“环状”数据结构实现的原因。
发送视窗(Send Window)
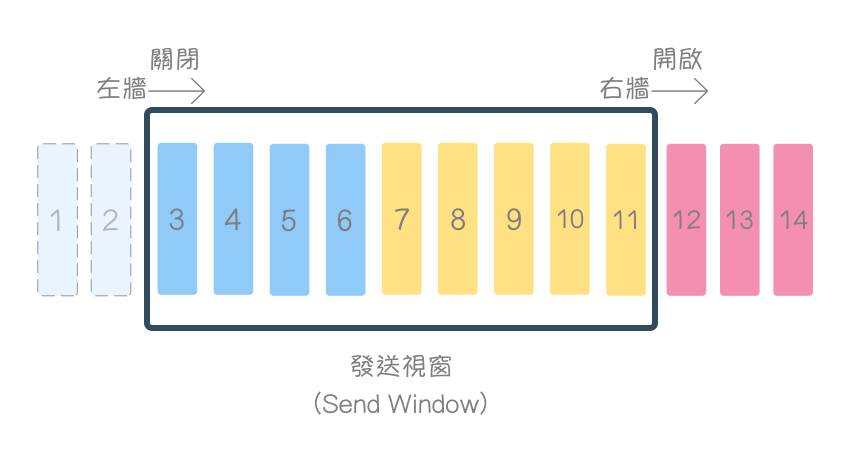
- 1、2 为已传送并收到接收端确认(acknowledgment),且已从发送缓冲区清除的字节。
- 位于发送视窗内的 3、4、5、6 为已传送但未被确认(unacknowledged),等待接收者回复确认的字节。
- 位于发送视窗内的 7、8、9、10、11 为准备传送的字节。
- 超出发送视窗外的 12、13、14 为等待放置待传送数据的空闲缓冲区,3、4、5、6、7、8、9、10、11、12、13、14 的总和即为发送缓冲区大小。
TCP 通过错误控制(Error Control)机制确保传输的可靠性(reliable),其中常见的手段包括检验和(checksum)、确认(acknowledgment)、重传(retransmission) 。TCP 会为每个连接启动一个超时重传(Retransmission Time - out, RTO)计时器,当计时到期且尚未收到接收端的确认(acknowledgment)回复时,将视该区段损坏(遗失、延迟),并重新传输该区段。这就是发送完的数据需等待接收者确认后才从队列中清除的原因。
接收视窗 vs. 发送视窗
若不考虑已清除及无法接收的部分,接收缓冲区包含两种数据空间:
- 已接收并确认(acknowledged)收到,但应用层尚未读取(消化)的字节。
- 等待接收数据的空闲缓冲区。
而发送缓冲区包含三种数据空间:
- 已传送但未被确认(unacknowledged),等待接收者回复确认的字节。
- 等待放置待传送数据的空闲缓冲区。
- 准备传送的字节。
并且,接收缓冲区的空闲缓冲区在接收视窗内,而发送缓冲区的空闲缓冲区在发送视窗外。
- 当接收端收到数据并回复确认(acknowledgment)收到时,发送视窗会关闭(Close)(左墙右移)。
- 当收到接收端的接收视窗大小(rwnd)大于发送视窗大小时,发送视窗会开启(Open)(右墙右移)。
范例
延续上述例子,当收到接收端确认号(acknowledgment number)为 7 与接收视窗大小(rwnd)为 5 时(表示 3、4、5、6 已确认收到,对方还能接收 5 个字节),发送视窗关闭(Close)(左墙右移)。
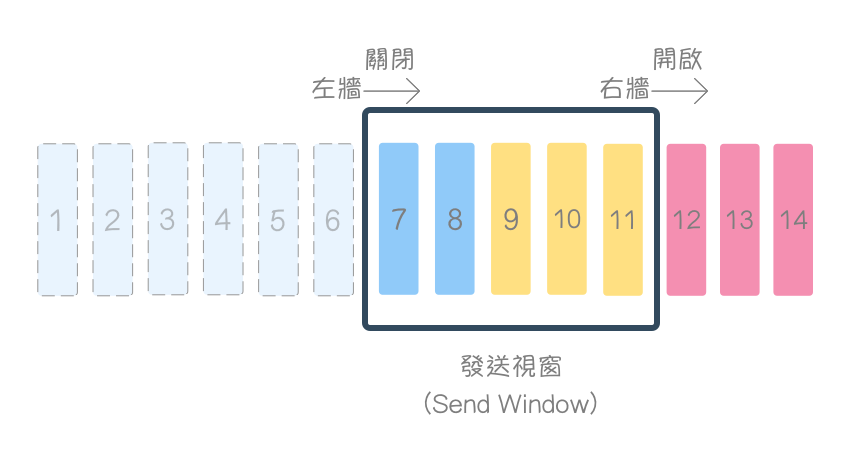
接着,收到接收端确认号(acknowledgment number)为 9 与接收视窗大小(rwnd)为 6 时(表示 7、8 已确认收到,对方还能接收 6 个字节),发送视窗先关闭(Close)(左墙右移),再开启(Open)(右墙右移)。
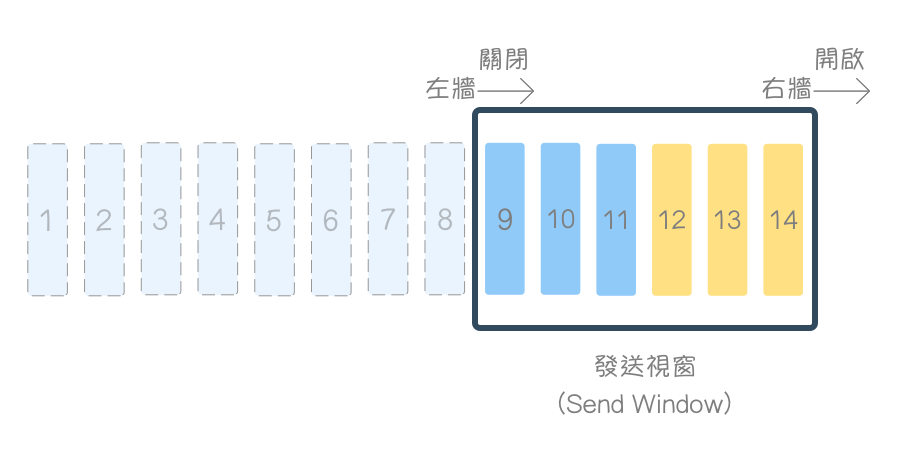
TCP 流量控制 (TCP Flow Control)
为何接收视窗可以自行计算视窗大小,而发送视窗却取决于接收端?这正是流量控制(Flow Control)的体现。TCP 流量控制(TCP Flow Control)通过反馈(feedback)机制,即接收端告知传送端当前能够接收的数据量,来平衡传送端与接收端的流量,避免高速传送端瘫痪低速接收端。
在不考虑拥塞控制(congestion control)的情况下,TCP 的发送视窗大小主要由接收端维护,接收端每次回报确认时,都会告知传送端接收视窗(rwnd)大小 。这种通过动态调整视窗大小实现流量控制的方式,就是著名的滑动窗口(Sliding Window)机制。
如果接收缓冲区已满,传送端继续传送数据,接收端将丢弃该区段。正常情况下,接收端可能因某些因素发送 rwnd = 0,此时传送端会停止传送(而非收缩发送视窗),直到接收端发送不为 0 的 rwnd 。尽管 TCP 是可靠的传输协议,具备重传(retransmission)机制,但仍应使用 TCP 流量控制(TCP Flow Control)来改善传输效率,并预防数据丢失。
误解
存在一个常见的误解,即认为“传送端 = 客户端,接收端 = 伺服端”,这种观点是错误的。TCP 是全双工(Full - Duplex, FDX)协议,每个端点在同一时间内数据可双向流动,因此每个端点都拥有各自的发送缓冲区与接收缓冲区。
TCP 傻瓜视窗症候群(Silly Window Syndrome, SWS)
发表于 2017-03-10,郑中胜
在 TCP 流量控制(TCP Flow Control) 一文中,介绍了滑动窗口(Sliding Window)的概念,说明了通过反馈(feedback)机制调整视窗大小以改善传输效率。然而,在某些情况下,滑动窗口的运行会引发严重问题,这就是傻瓜视窗症候群(Silly Window Syndrome, SWS),本文将介绍该症状及其解决方案。
傻瓜视窗症候群 (Silly Window Syndrome, SWS)
对于一家餐厅而言,换桌率至关重要。最糟糕的情况是客人进食或厨师上菜速度极慢,而更可怕的是两者同时发生。在传输控制协议(Transmission Control Protocol, TCP)中,由于发送者(Sender)与接收者(Recipient)传输、读取速率不相等,接收端会将数据暂存在接收缓冲区(Receiving Buffers),并等待应用层读取后(消化),再从接收缓冲区中清除。可以将餐桌类比为接收缓冲区,客人进食相当于应用层读取(消化),厨师做菜则如同传送端产生数据。当“接收端的应用程序读取(消化)”或“传送端产生数据”的速度过慢,导致网络效率低下的情况,就被称为傻瓜视窗症候群(Silly Window Syndrome, SWS),也称作糊涂窗口综合症。
传送端 SWS
典型的传送端 SWS 表现为“传送端应用程序产生数据速度很慢”,最极端的情况是一次仅传送 1 byte 的数据。例如,许多 Telnet 键盘操作会产生 1 byte 的数据并立即发送。需要注意的是,TCP 每次发送与接收的单位是 TCP 区段(TCP Segment),仅加上 TCP 表头(Header)可能就有 40 bytes ,再加上 1 byte 数据,总共 41 bytes ,这种低效率的情况也被称为小封包问题(small packet problem)。
Nagle 算法(Nagle’s Algorithm)
TCP 只是应用层使用的服务,因此对于传送端数据产生速度慢的问题,没有根本的解决方法。John Nagle 提出了一种折衷方案:尽量避免低效的区段浪费带宽。
最简单的 Nagle 算法(实际应用中有多种实现变化)如下:
- 传送端应用程序的第一笔数据,即使只有 1 byte,也直接传送。
- 后续的新数据在发送缓冲区中累积、等待,直到数据累积到最大区段长度(Maximum Segment Size, MSS),或者接收到接收端的回应确认(ACK),再将区段送出。
大致的代码实现如下:
public Nagle(ApplicationData data) {
策略 strategy;
if (data.is第一笔资料())
strategy = new 策略1();
else
strategy = new 策略2();
strategy.处理资料(data);
}
public class 策略1 implements 策略 {
@Override
public void 处理资料(ApplicationData data) {
存入发送缓冲区(data);
送出区段(data);
}
}
public class 策略2 implements 策略 {
@Override
public void 处理资料(ApplicationData data) {
存入发送缓冲区(data);
if (data.length >= 最大区段长度 || is接收端回应确认ACK())
送出区段(data);
}
}
最大区段长度(Maximum Segment Size, MSS)在双方建立连接时确定,且在连接运行期间保持不变。若其中一方未定义,则使用预设值 536 bytes 。需要注意的是,MSS 定义的是所能接收“数据”的最大长度,而非区段长度。
Nagle 算法简单实用,同时考虑了应用程序数据产生速度与接收端回应速度。然而,许多 TCP 实现为了减轻负载和减少传输量,采用延迟确认(Delayed ACK)机制,这会使数据产生速度较低的传送端等待约 100 - 200 毫秒(ms) 。因此,若能确保数据产生速度稳定(尤其是 Web Server),建议停用 Nagle 算法,以避免 200 毫秒的延迟(NGINX 默认为关闭)。大部分关闭方式使用 TCP_NODELAY 选项,以下是不同语言的关闭示例:
- C Socket:
setsockopt(sockfd, IPPROTO_TCP, TCP_NODELAY, &optval, sizeof(optval));
- Java Socket:
public void setTcpNoDelay(boolean on) throws SocketException {
if (isClosed())
throw new SocketException("Socket is closed");
getImpl().setOption(SocketOptions.TCP_NODELAY, Boolean.valueOf(on));
}
- NGINX:
http {
tcp_nodelay on;
...略
}
接收端 SWS
接收端 SWS 是指“接收端应用程序消耗数据太慢”,导致接收视窗大小(rwnd)饱和,进而间接引发小封包问题(small packet problem)。常见的解决方案有以下两种:
- Clark 方案(Clark’s Solution)
- 延迟确认(Delayed ACK)
Clark 方案 (Clark’s Solution)
Clark 方案在 TCP 流量控制(TCP Flow Control) 一文中已提及。接收端收到数据后,立即发送接收视窗大小(rwnd) = 0 的回应,直到接收缓冲区能够容纳一个最大区段长度(Maximum Segment Size, MSS)(或自定义大小),再向传送端回复不为 0 的 rwnd 。传送端收到 rwnd = 0 时,会停止传送(而非收缩发送视窗),直到接收端发送不为 0 的 rwnd 。
延迟确认(Delayed ACK)
延迟确认(Delayed ACK)即“拖延战术”。当接收端收到一个区段时,不立即回应,而是尽量等到接收缓冲区有足够空间后再发送回应,这样接收视窗大小(rwnd)就有机会增加。延迟回应的时间通常为 100 - 200 毫秒(ms),最长可达 500 毫秒(ms),具体取决于设置。因此,接收端很可能将多个回应与数据合并,并携带(piggyback)确认(ACK),从而减少网络中的封包数量,降低两端主机的负载和传输量。
然而,除了上述与 Nagle 算法共用时存在的问题外,在某些情况下,延迟确认甚至会使传送端误解,导致其重传(retransmission)未收到确认的区段。所以,在不适当的时候使用延迟确认只会弊大于利。尽管如此,若接收端收到的区段顺序正确,且先前的区段都已回应,同时没有数据要传送,仍应使用延迟确认,直到有新区段到达 [注1] 或超过“尽量”的时限 。否则,应立即传送 ACK 区段,以防止不必要的延迟和重传。
[注1]:接收端在任何时候,不应存在两个以上顺序正确且未被回应的区段。
TCP 序列号(Sequence Number, SEQ)
发表于 2017-03-12,郑中胜
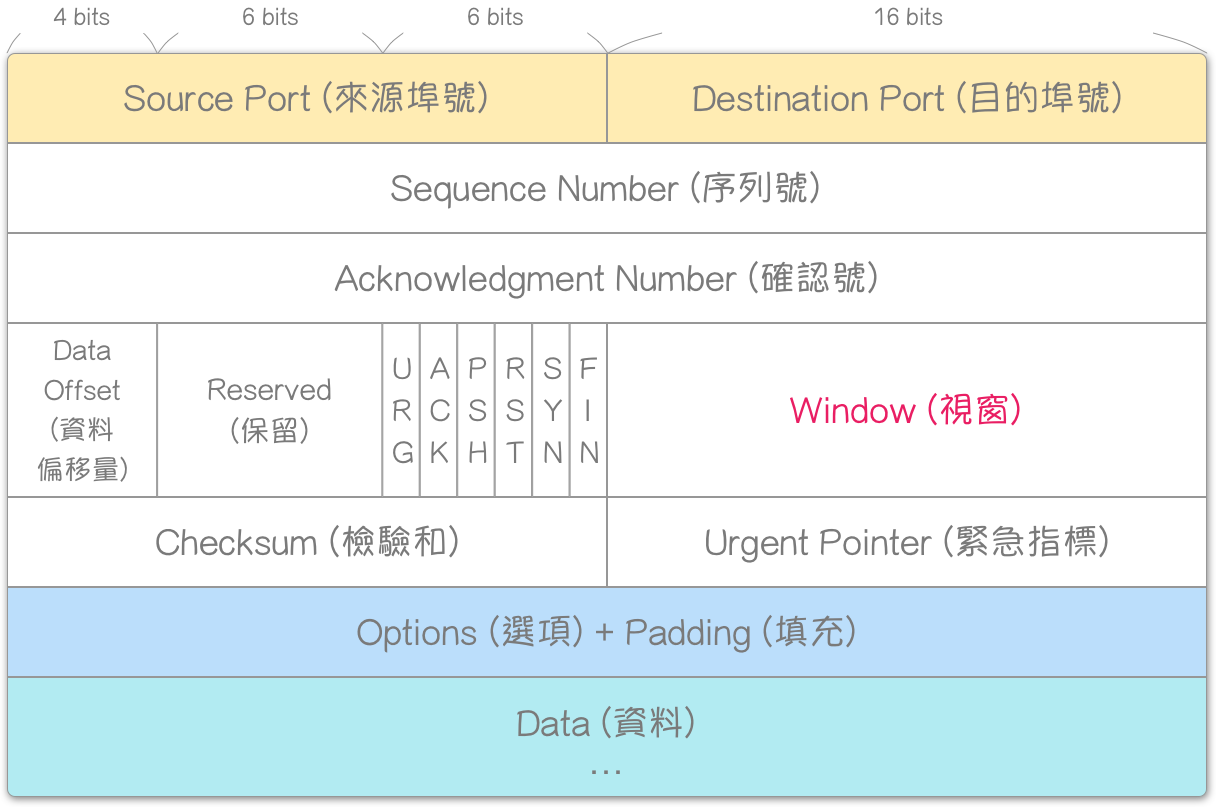
序列号(Sequence Number, SEQ)是 TCP 表头的字段之一,字段大小为 32 bits,因此其 数值范围 为 0 ∼ 2 32 − 1 0 \sim 2^{32} - 1 0∼232−1,是 TCP 设计的根本概念,几乎所有功能都依赖此字段完成。
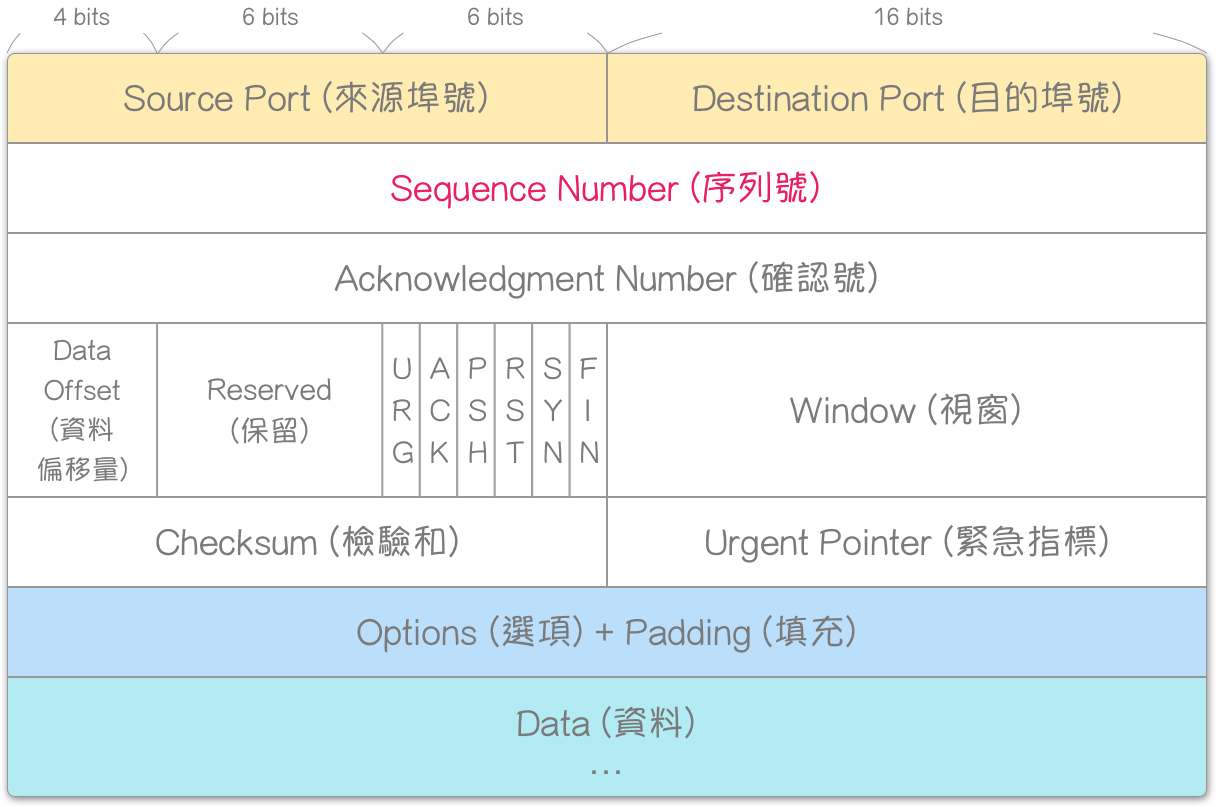 TCP 表头格式
TCP 表头格式
可靠性(Reliability)
TCP 流量控制(Flow Control)中提过,TCP 每次发送与接收单位为: TCP 区段(TCP Segment),每个区段的大小不尽相同,有可能数百~数万 个字节。
就像最大区段长度(Maximum Segment Size, MSS),指的是所能接收 ‘资料’的最大长度,而非区段。
TCP 会为每条连线发送的资料字节(octet of data)分配序列号,而序列号(Sequence Number, SEQ)字段,放的是该区段资料字节的第一个序列号(除非无携带资料)。

TCP/IP 的网络层 —— IP 协定,不保证资料会照发送顺序抵达接收端,接收端可利用表头中的序列号(Sequence Number, SEQ)字段进行排序、消除重复(eliminate duplicates),以保证资料接收的正确顺序,并以字节串流(byte-stream)的方式,传递给应用层。
TCP 使用确认号(Acknowledgment Number)字段,指出下一个期望接收的序列号(Sequence Number, SEQ)(表示编号小于此值的字节,皆已正确接收)。
需要再次强调:
- 序列号(Sequence Number, SEQ),并不是区段的 id 或编号。
- 它不代表一个唯一的区段,且不同于数据库的主键,其值有可能重复。

无携带资料
有些区段并不会携带资料,自然不存在资料字节,如:
- 建立、结束连线;
- 无携带资料之确认区段;
- …
尽管其值无效,该 区段仍需使用一个序列号(Sequence Number, SEQ)。
初始序列号(Initial Sequence Number, ISN)
为了避免与先前连线的区段混淆,当次连线建立时,序列号并非从 0 开始,两端会使用 ISN 产生器,产生各自的初始序列号(Initial Sequence Number, ISN),通常两者并不相等,且如本篇开头所述,数值范围 为 0 ∼ 2 32 − 1 0 \sim 2^{32} - 1 0∼232−1。
连线建立时,透过控制位元(Control Bits)中的 SYN,让两端的 TCP 必须进行 ISN 的交换(同步)。
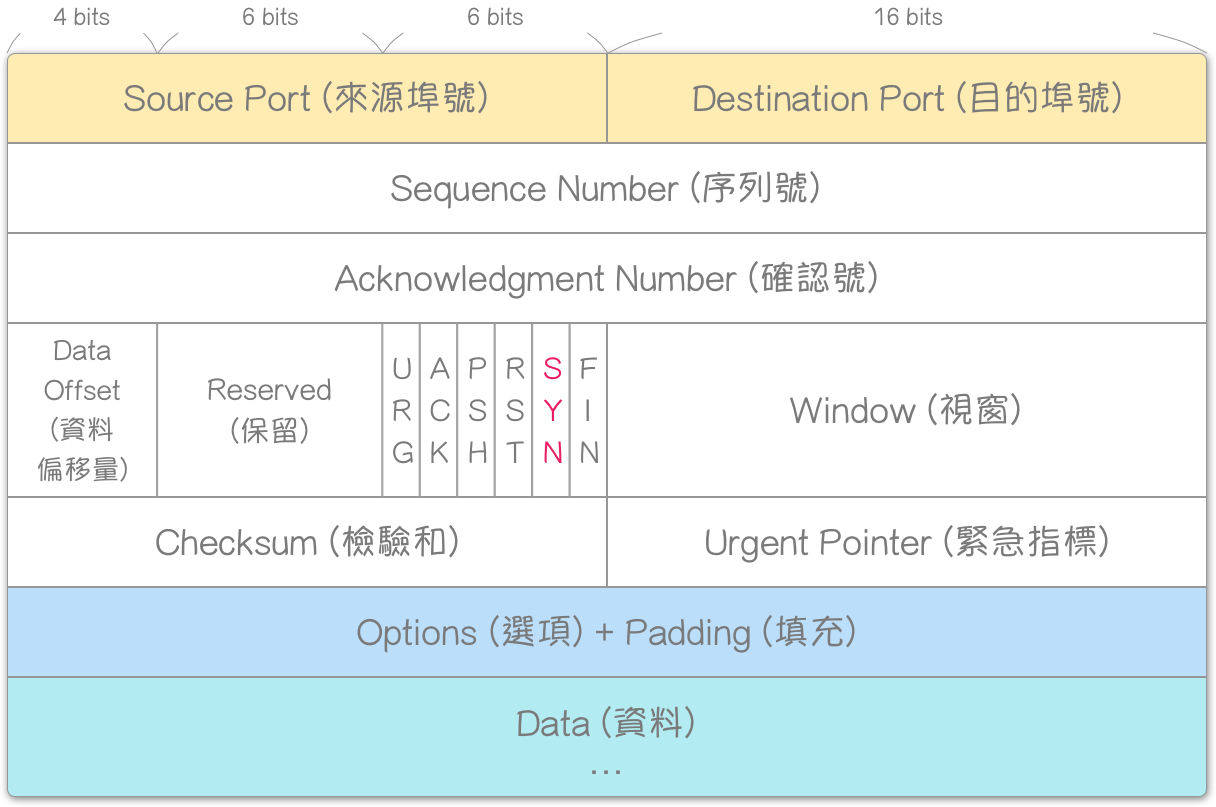
- SYN 全名同步序列号(Synchronize sequence numbers),使用 SYN,代表目前区段的序列号为初始序列号,而非资料字节的第一个序列号。
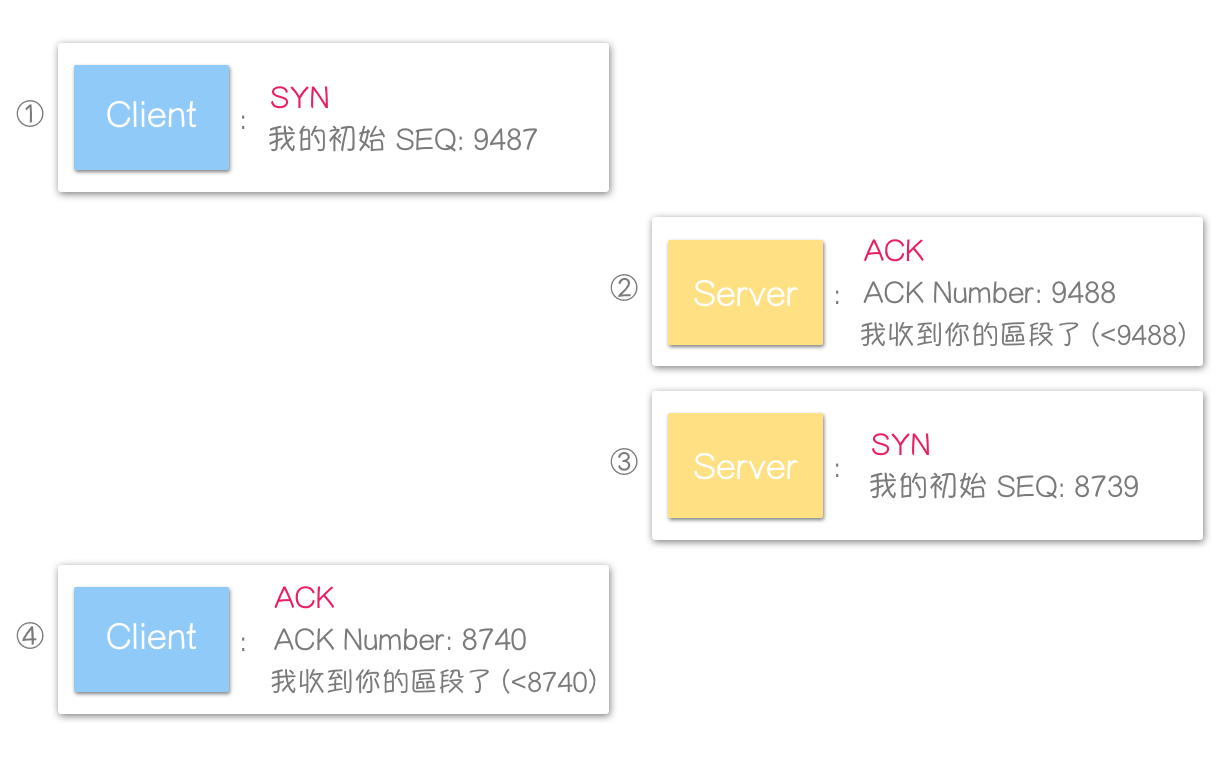
这就是 TCP 连线的建立方式,且 2 和 3,可以组合为单一讯息,即大名鼎鼎的 —— TCP 三向交握(Three Way Handshake)_。
例如:
而第三个区段(Client ——> Server),其 SEQ 为第一个区段的值 + 1(ISN + 1)。
相对序列号(Relative Sequence Number)
如果使用 Wireshark 之类的封包分析软件,可能会以为 “ISN 就是 0 啊,根本不是乱数 ”。
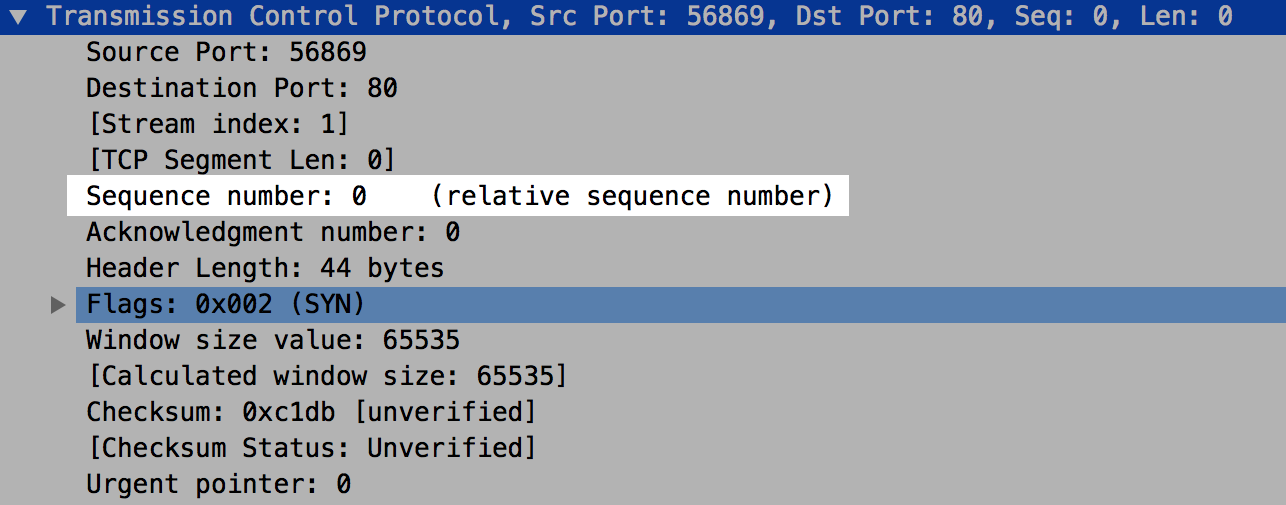
那不是真的 SEQ,而是相对 SEQ,真正的值可能很大很难看,为了方便观察,大部分工具都会提供相对 SEQ(将 ISN 做为基底值)。
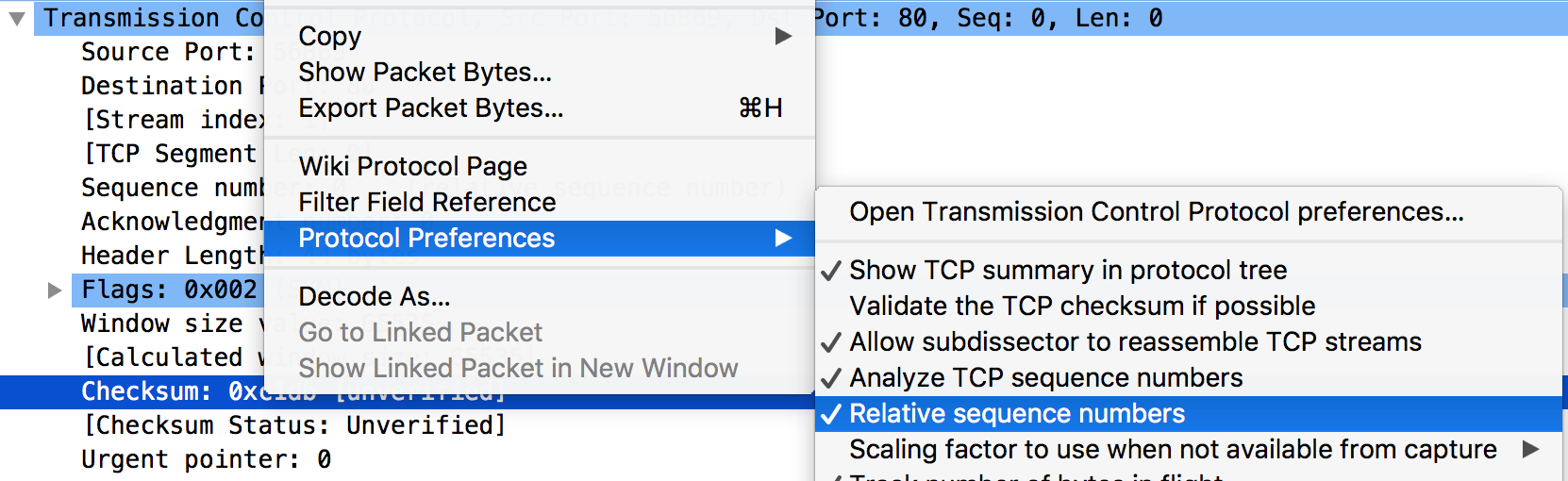
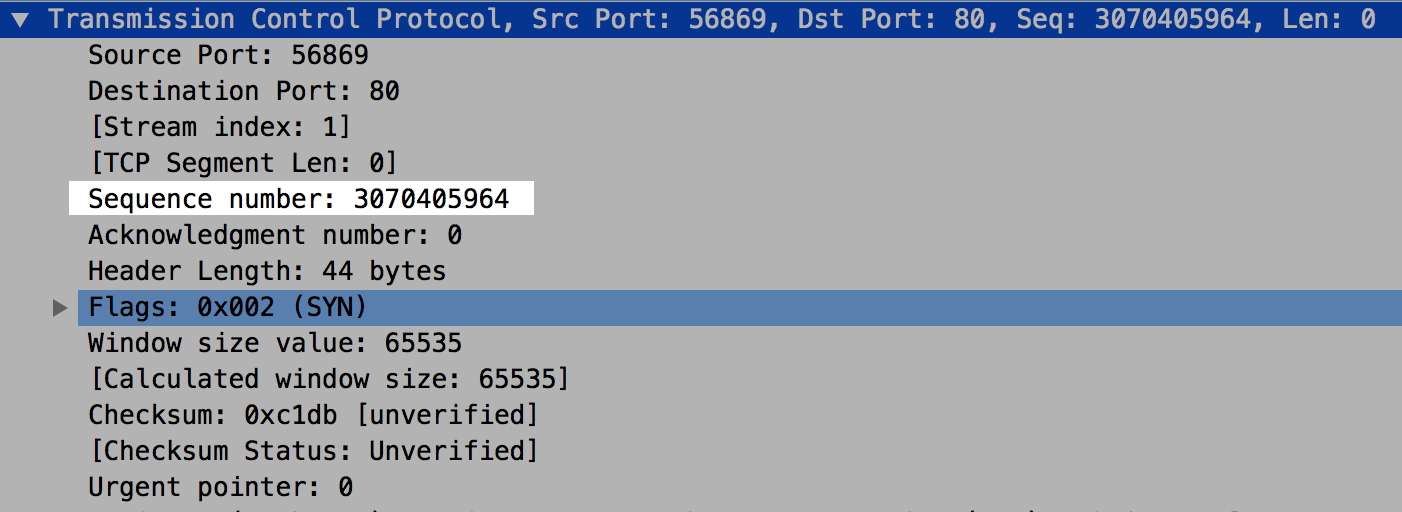
要取消可以按右键设定,接着,就可以看到真实的数值。
无携带资料之确认区段
大部分 TCP 实作,对无携带资料之确认(ACK)区段,视为序列号无效,并且不消耗任何序列号。
- 也就是:序列号(SEQ)将重复使用,直到区段携带资料。
范例
承上述范例,第三个区段(Client ——> Server)的 SEQ 为 101(此时连线建立完成),第四个区段,送出携带资料的区段(Client ——> Server),SEQ 将同样为 101,而非 102(101 + 1)(因为第三个区段是无携带资料之确认区段,序列号将重复使用)。
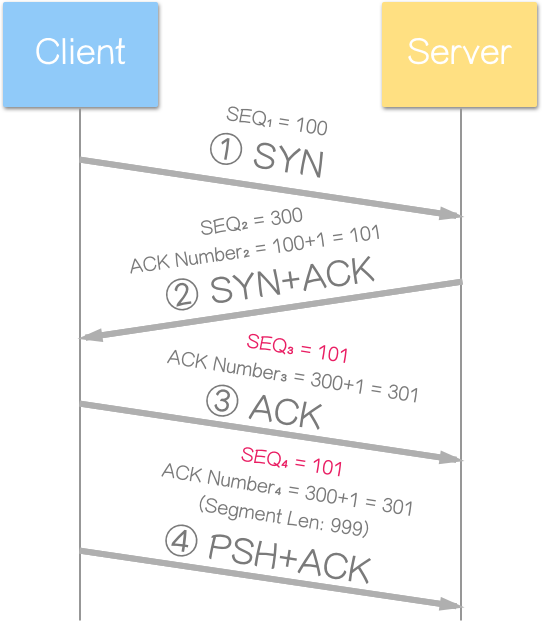
别忘记了,区段长度(Segment Len)是个不太准确的命名,指的是资料长度,而非区段。Segment Len: 999 代表“含序列号 101 的资料,共有 999 个资料字节”(101、102、103、…、…、1098、1099)。
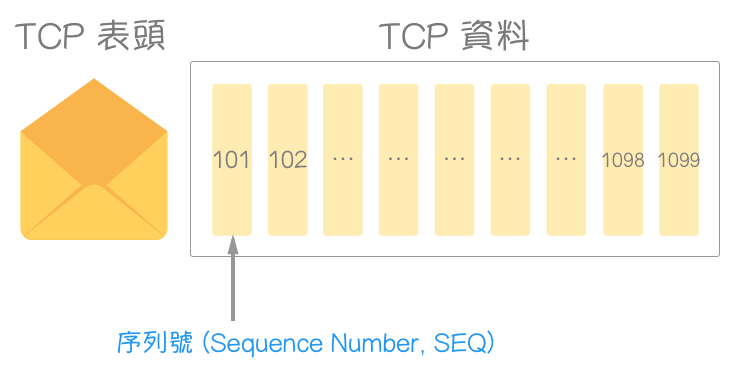
假设成功送达 Server,且区段没有毁损,第五个区段确认号(Acknowledgment Number)将设为 1100(表示编号小于 1100 的字节,皆已正确接收)。
第六与第七个区段(Client <—— Server),Server 送出携带 1440(字节)资料的区段,由于尚未收到 Client 回复,“期望收到的序列号” = 确认号(ACK Number),与第五个区段一样为 1100。

第八个区段(Client ——> Server),一样是无携带资料之确认区段 区段。
因此,如果有第九个区段(Client <—— Server)(懒得画了),Server 之确认号(ACK Number)将一样为 1100。
第十个区段(Client ——> Server),Client 之序列号,也将维持 1100 不变,直到其携带资料。
- 总结来说,无携带资料之确认区段,其序列号(SEQ)将重复使用,直到区段携带资料或拆除连线。
TCP 错误控制 (Error Control)
发表于 2017-03-23 郑 中胜
TCP 错误控制 (Error Control) 确保了传输的可靠性 (reliable),其中最常见的是:检验和 (checksum)、确认 (Acknowledgment)、重送 (retransmission)。
可靠性 (Reliability)
了解 TCP 错误控制 (Error Control) 前,需先明确何谓 — 错误 (Error)。
错误 (Error) 是指那些传递于互联网通讯系统中,毁损 (damaged)、遗失 (lost)、延迟 (delayed)、重复 (duplicated) 或 乱序 (out of order) 的 区段 (Segment)。
错误控制 (Error Control) 并非指 TCP 不会有错误,而是当错误发生时,侦测并修正这些问题,借此让 TCP 拥有可靠性 (Reliability)。
- 关键在于:为每个送出的资料之字节 (octet),分配 序列号 (Sequence Number)。

TCP/IP 的网络层 — IP 协定,不保证资料会依发送顺序抵达接收端,接收端可利用表头中的序列号 (Sequence Number, SEQ) 字段进行排序、消除重复,以保证资料接收的正确顺序,并以字节串流 (byte-stream) 的方式,传递给应用层。
TCP 接收端需透过确认号 (Acknowledgment Number),回应传送端资料是否已正确收到,若超出限定时间,传送端仍未收到接收端的确认号,则视为区段遗失 (毁损、延迟),并重送该区段。

此外,TCP 使用 检验和 (Checksum) 的计算机制,检查区段是否毁损,传送端将每个送出的区段进行检验和计算,并将结果置于 TCP 表头的 Checksum 字段中,接收端会进行相同的计算,若与表头中的 Checksum 值不同,则视为毁损 (遗失、延迟),并丢弃该区段。
确认 (Acknowledgment)
确认 (Acknowledgment),又称承认、回报、回应,是一种侦错机制。主要是透过:确认号 (Acknowledgment Number) 与 ACK 两个 TCP 表头字段。前者,字段大小为 32 bits,因此其 数值范围_ 为 0 ~ 2 32 − 1 2^{32} - 1 232−1;后者,字段大小为 1 bit,是控制位元 (Control Bits) [注1] 其一,意指:使“确认号字段”有效 (Acknowledgment field significant)。
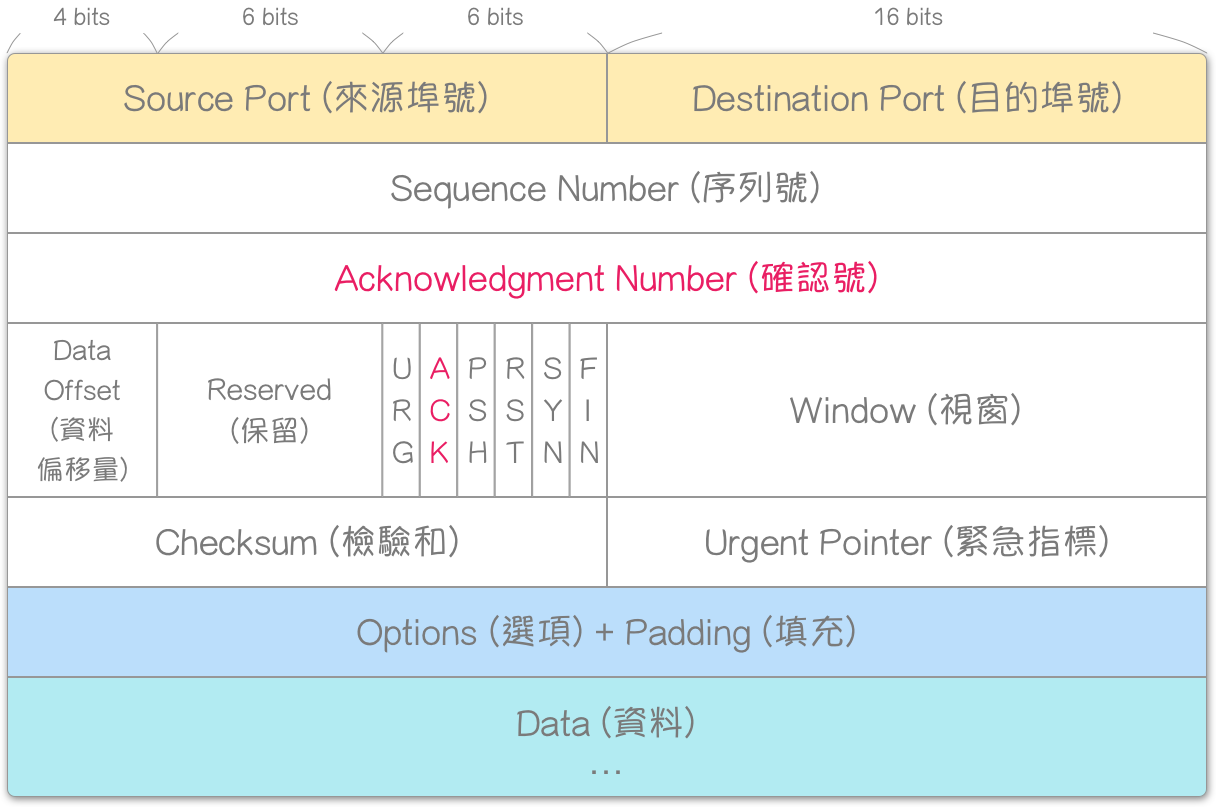
TCP 表头格式
确认号 (Acknowledgment Number) 用于:
- 告知传送端,下个预期接收的 序列号 (Sequence Number)。
- 告知传送端,小于此值的资料字节,皆已正确接收。(这种确认方式称为:“累计式确认 (Comulative ACK)”)
也就是(若传输正确):
确认号 = 所收到区段的最后一个字节之序号 + 1
例如:
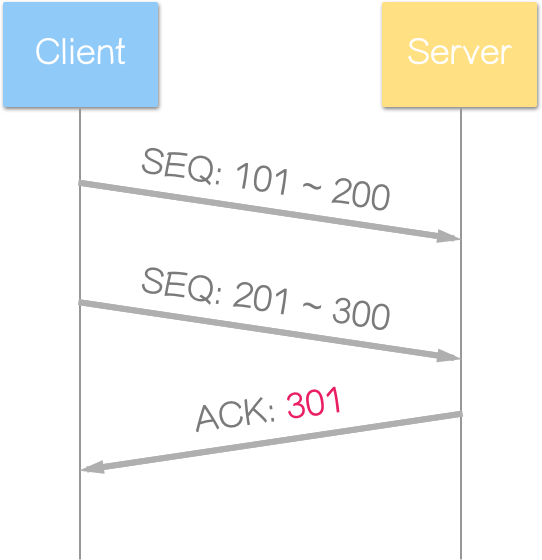
代表 Server:
- 下次期望收到序列号 301 之区段。
- 小于 301 之区段,皆已正确接收。(这里用 101 ~ 200 这样的序列号表示法,仅为方便示意,实际上序列号只有一个值)
一旦连线建立,不管是 Client 还是 Server,所有送出的区段,都需包含确认号,并设置 ACK。
上述 Client-Server 的例子中,可看出一个重要的事实:
TCP 区段,并非一个传送对应一个接收。
许多人将一些应用程序:“一个请求一个回应”的习惯,加附在 TCP,进而产生误解。
[注1]:
控制位元 (Control Bits),又称旗标,大小皆为 1 个 bit (0 或 1),0 表关闭 (未设置 Not Set),1 表启用 (设置 Set),许多实作的控制位元为 8 个(剩下 2 个在保留字段)。
[注2]:
许多人为求方便,表示上会将确认号与 ACK 视为相等(缩写),图形若只写 ACK,通常代表 ACK 控制位元,若后方加上某个数值,指的是确认号。
延迟确认 (Delayed ACK)
TCP 接收端可能不会立即发送确认 (ACK),而是等待看看,是否有其他讯息,并将多个回应结合为一,如此便能减少网络中的封包数量,降低两端主机的负载、传输量,称为 —— 延迟确认 (Delayed ACK)。
若接收端收到的区段顺序正确,且先前的区段皆已回应 + 已没有资料要传送,应使用延迟确认,直到有新的区段抵达或超过“尽量”的时限。
新的区段抵达:
接收端在任何时间下,不该有两个以上“正确顺序的区段未被回应”。
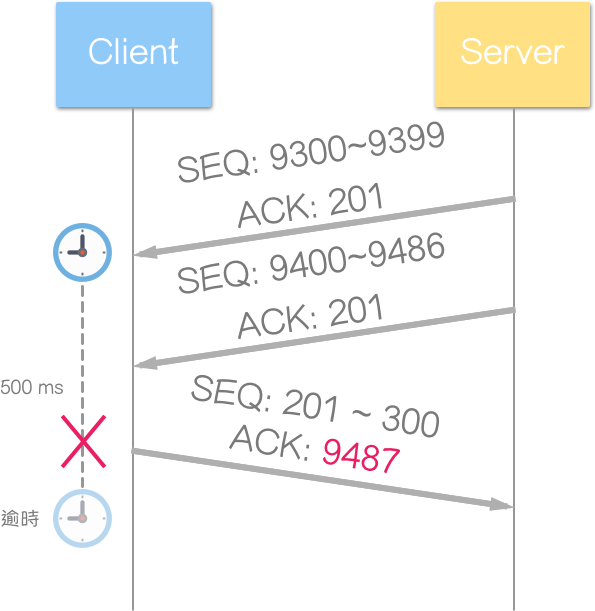
接收端使用延迟确认 (Delayed ACK),等待看看,是否有其他讯息:
有!接收到了新的区段 (SEQ: 9400~9486),且先前的区段尚未回应 (SEQ: 9300~9399),虽尚未逾时,仍应立即送回一个确认 (ACK) 区段。
超过延迟确认时限:
“尽量”的延迟回应时间,通常是 100~200 毫秒 (ms),至多为 500 毫秒 (ms),因设定而异。然而,若在不当时机,使用延迟确认只会弊大于利,TCP 傻瓜视窗症候群 (Silly Window Syndrome, SWS) 一文有更多介绍。
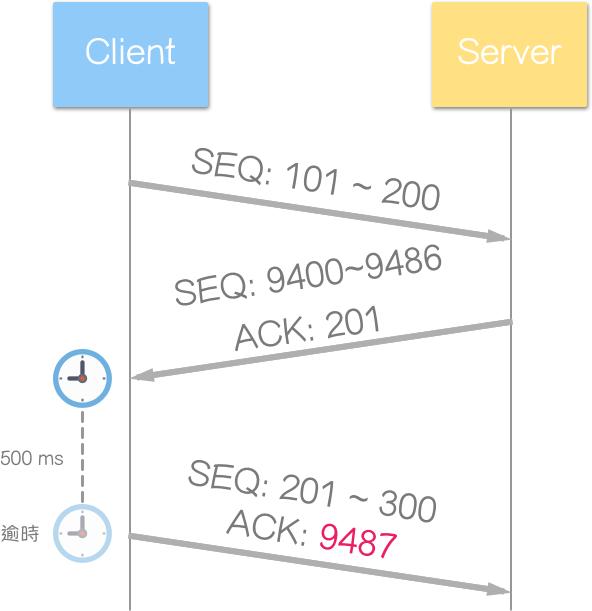
接收端使用延迟确认 (Delayed ACK),等待看看,是否有其他讯息:
没有,接收端超出延迟确认时限后,送回确认 (ACK) 区段。
重送 (Retransmission)
一旦 连线建立 ,TCP 以 区段 (segment) 的交换来传递资料。如开头所述,接收端可能因“检验和测试失败”,认定区段毁损并丢弃,或网络壅塞等因素,而遗失区段,TCP 使用重送 (Retransmission) 机制,确保每个区段的传递。大部分的 TCP 实作,将区段的 — 毁损 (damaged)、遗失 (lost)、延迟 (delayed) 视为相同情况,差别在于毁损的区段由接收端丢弃,而遗失的区段由网络的某处丢弃。常见的重送机制有两种:
- 逾时重送 (Retransmission Timeout, RTO)
- 快速重送 (Fast Retransmit)
事实上:
TCP 传输错误的比例很低,当区段遗失时,TCP 假设遗失是壅塞所造成。因此,重送机制,常作为侦测壅塞的具体方式。
逾时重送 (Retransmission Timeout, RTO)
如 TCP 流量控制 (Flow Control ) 中提到:
TCP 会为每个连线启动一个逾时重送 (Retransmission Timeout, RTO) 计时器,当时间到期,尚未收到接收端的确认 (acknowledgment) 回复,则视同区段毁损 (遗失、延迟),并重送该区段 (Segment),这便是为何发送完的资料,会等到接收者回复确认后,才从伫列中清除。
逾时重送 (Retransmission Timeout, RTO),在大部分文章(献)都直称重送 (Retransmission),本篇为直觉地与快速重送做出区隔,故命之。由于 TCP 连线与互联网的多变性,TCP 会根据往返时间 (Round Trip Time, RTT),动态调整逾时重送 (Retransmission Timeout, RTO) 时间,往返时间 (Round Trip Time, RTT),是测量送出区段,到接收确认 (ACK) 的时间而得,RTO 简易的计算方式,可以参考 RFC 793、RFC 1122、RFC 6298。
遗失 (Lost)
以遗失资料区段为例:
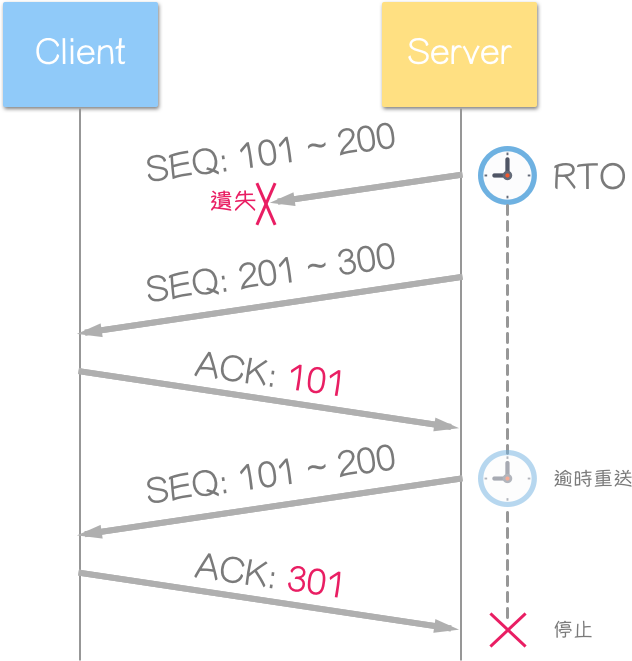
Server 送来两个区段,第一个区段遗失了 (SEQ: 101~200),Client 只知道收到一个乱序的区段 (SEQ: 201~300),Client 仍预期接收序列号 101 的区段。并且:
TCP 应保证资料的顺序,在空缺的部分补齐之前,接收端不应将空缺之后的资料,传递给应用层。
当超出逾时重送 (Retransmission Timeout, RTO) 计时器时间,Server 仍未收到第一个区段的确认 (ACK) 回复,因此,视区段毁损 (遗失、延迟),并重送该区段。注意:
确认 (ACK) 是累计式的,尽管第二个区段 (SEQ: 201~300) 传输正确,第三个区段不能回应 (ACK: 301),因这样代表序列号小于 301 之区段皆传输正确。
以遗失 ACK 区段为例:
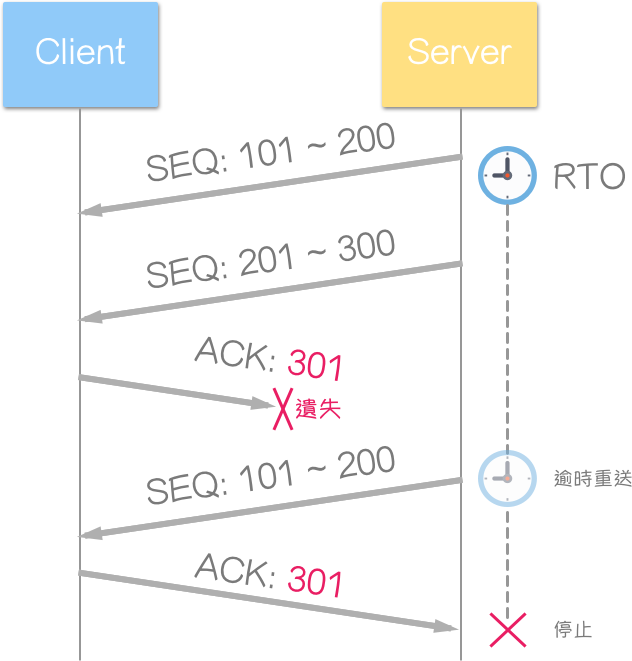
Server 送来两个区段,Client 送回的 ACK 区段却遗失了。当超出逾时重送 (Retransmission Timeout, RTO) 计时器时间,Server 仍未收到第一/二个区段的确认 (ACK) 回复,因此,视区段毁损 (遗失、延迟),并重送该区段 (Segment)。Client 会丢弃接收到的重复区段,并回应预期接收的序列号 (ACK)。
以遗失 ACK 区段为例 (二):
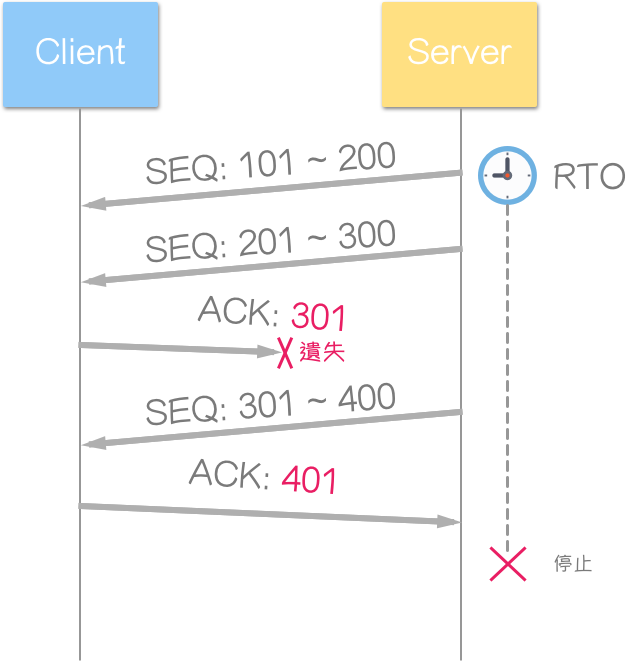
Server 送来两个区段,Client 送回的 ACK 区段却遗失了。这时 Server 仍持续送出区段 (SEQ: 301 ~ 400),且尚未超过 RTO 时限,Client 回复新的 ACK 区段(甚至未察觉上个 ACK 区段遗失),因为是累计式确认 (Comulative ACK),连带修正了“遗失 ACK 区段”问题。
快速重送 (Fast Retransmit)
快速重送 (Fast Retransmit),是另一重送机制,并非取代逾时重送,而是结合并加大 RTO 逾时时间,让遗失的区段不需等到重送计时器 (retransmission timer) 逾时才重送,增加了传输效率。
接收端
某区段遗失,代表后续接收的区段顺序错误,因此,不应使用延迟确认 (Delayed ACK),而是立即确认 (immediate ACK)。
目的是为了让传送端知道:
- 接收到的是乱序 (out of order) 的区段
- 预期接收的序列号
传送端:
当接收到 3 个重复的确认 (duplicate ACK),则立即重送该区段,而非等到重送计时器逾时。
传送端一开始并不清楚“重复的确认”的原因(这可能由多种网络问题),若收到 1 ~ 2 个重复确认,传送端会假设是网络对区段的重新排序或复制所引起,而收到 3 个或更多的重复确认,则明显地指示区段已遗失,于是 TCP 立即重送“似乎是”遗失的区段,而非等到计时器逾时。
范例:
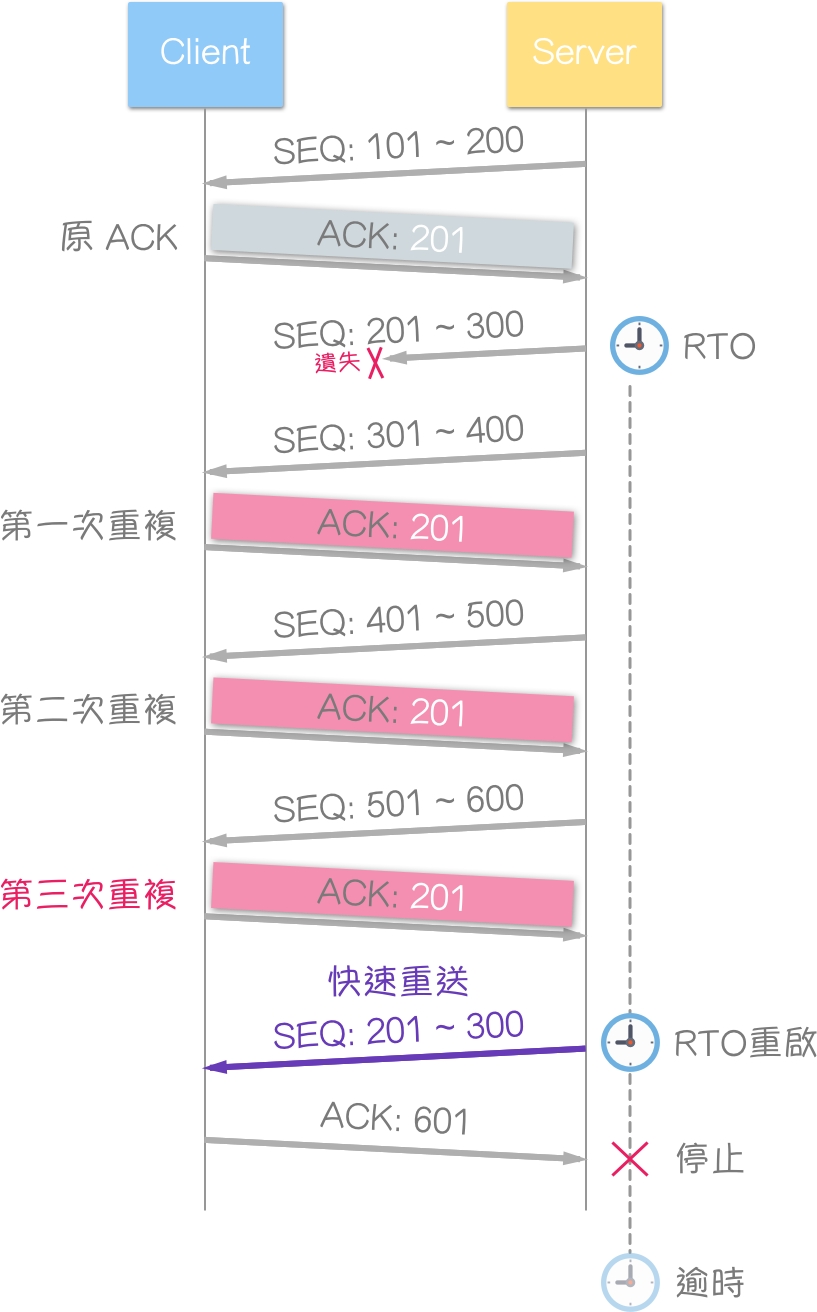
原始的 ACK,再加上 3 个重复的 ACK,合计共有 4 个相同的确认号 (acknowledgment number),区段重送之后,计时器会重新启动。
选择式确认 (Selective Acknowledgment, SACK)
累计式确认 (Comulative ACK) 的缺点显而易见,其提供的讯息相当有限:
TCP 传送端在每个往返时间 (RTT),只能知道单个遗失的封包。
因此,当有多个区段的遗失,将为 TCP 带来灾难性的影响,选择式确认 (SACK) 即是解决“多个丢弃区段”时的策略。许多 TCP 实作,使用选择式确认 (Selective Acknowledgment, SACK) 来加速传输效率,SACK 并非取代 ACK,而是附加乱序、重复的资讯,到 TCP 表头中的选项 (Options) 字段,使传送端能直接重送遗失的区段。而不使用 SACK 的 TCP,通常使用部分式确认 (Partial Acknowledgment) 来触发重送。
允许 SACK 选项 (SACK-permitted Option)
TCP 在建立连线时,可告知对方允许使用 SACK,方法很简单,在选项表头字段加入允许 SACK 选项 (04 02):
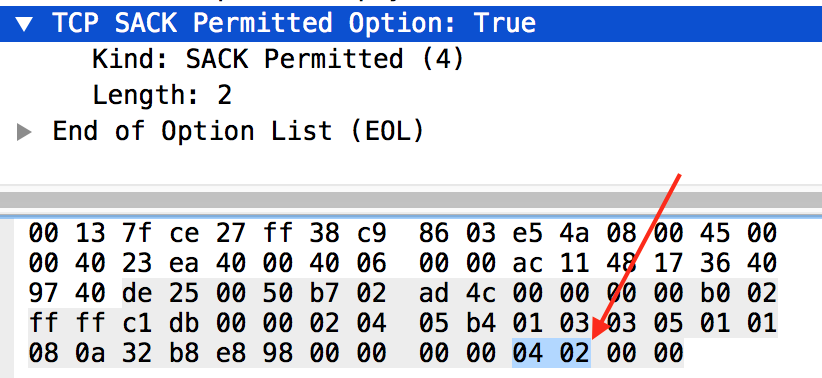
意指:
选项种类 (tcp.option_kind) 为 4 (SACK-permitted),长度 (tcp.option_len) 为 2 (选项共占 2 字节)。

范例:
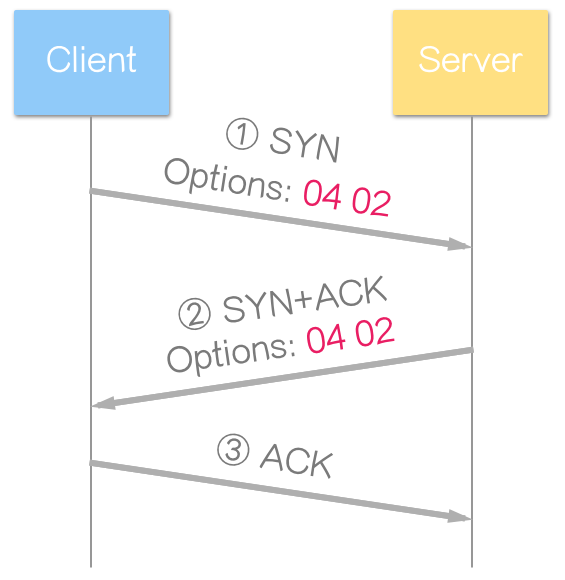
资料传输阶段,则不允许使用“允许 SACK 选项” (SACK-permitted Option)。
SACK 选项 (SACK Option)
若 TCP 双方建立连线时,皆送出 SACK-permitted Option (允许使用 SACK),即可使用 SACK Option (SACK 选项) 附加乱序、重复的资讯。
其选项种类为 5 (SACK),长度为需计算的变量 (8*n + 2)。(左右边界合计 8 字节,选项种类、长度字段合计 2 字节)
紧接着:
第一个乱序/重复区块的开始序列号 – 左边界 (Left Edge of 1st Block),
第一个乱序/重复区块的结束序列号 – 右边界 (Right Edge of 1st Block),
…
第 n 个乱序/重复区块的结束序列号 – 右边界 (Right Edge of nth Block)。
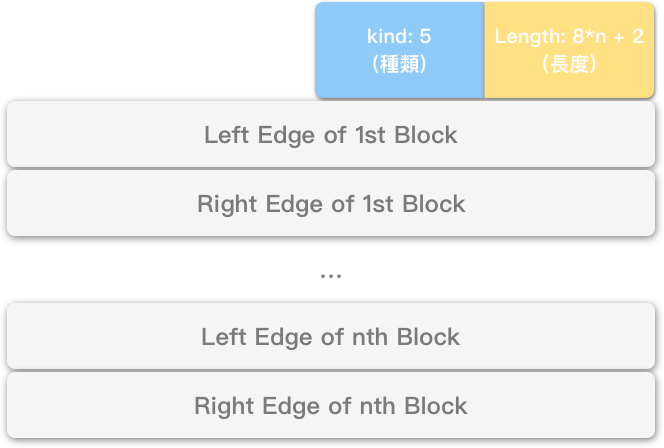
TCP 选项至多为 40 字节,因此一个 SACK 选项,最多能包含 4 个区块 (8*4 + 2 = 36)。
TCP 壅塞控制(Congestion Control)
发表于 2017-04-07,郑中胜
TCP 流量控制(Flow Control)旨在避免高速传送端致使低速接收端瘫痪。而 TCP 壅塞控制(Congestion Control)则用于防止高速传送端使网络陷入瘫痪状态。
本篇主要介绍 TCP 壅塞控制常见的四种基本算法:
- 慢启动(Slow Start)
- 壅塞避免(Congestion Avoidance)
- 快速重送(Fast Retransmit)
- 快速恢复(Fast Recovery)
同时,为实现这些算法,为每个 TCP 连接新增了两个状态变量:
- 壅塞视窗(Congestion Window, cwnd)
- 慢启动门槛(Slow Start Threshold, ssthresh)
尽管这些算法逐渐被认为不合时宜,但仍可作为借鉴,助力了解其他解决方案。
壅塞侦测(Congestion Detection)
任何壅塞控制算法都需解决的问题是:网络缺乏获取“给定连线的可用带宽”的机制。因此,TCP 壅塞控制(Congestion Control)必须通过某种方式,得出关于“在任何给定时间内可发送资料量”的结论,从而将传送速率调整至最佳效能,避免网络瘫痪。
1. 基于遗失(Loss - based)
互联网(Internet)通过交换器、路由器等多种设备,将全球数亿的装置与网络连接编织在一起。路由器(Router)利用伫列来存储封包,并进行 拆装、封装_、确定最佳路径以及转送封包等操作。
然而,伫列(缓冲区)并非无限大。若缓冲区满溢,后续送来的封包很可能会被丢弃。许多传输层协定(包括 TCP)具备重送(Retransmission)机制,封包丢弃不仅不会减少网络上的封包数量,反而可能增加,进而造成严重的效能损耗(如今,不丢弃封包产生的损耗可能更大)。
传统 TCP 利用封包遗失这一现象,将其视为壅塞的征兆,以此调整传输速率:当 TCP 区段遗失时,判别接收端采用的重送机制(逾时重送(Retransmission Timeout)或快速重送(Fast Retransmission)),并执行相应策略。这是因为在互联网平稳运行时,TCP 传输错误的比例较低,当区段遗失时,TCP 假设遗失是由壅塞导致的。
- 当接收端使用逾时重送(Retransmission Timeout)时,意味着接收端在逾时之前未收到 3 个区段或送回的确认(ACK)遗失,这是壅塞严重的征兆。
- 当接收端使用[快速重送(Fast Retransmit)时,表明接收端在逾时之前已收到 3 个区段,这是壅塞轻微的征兆。
缓冲区膨胀(bufferbloat)
自 20 世纪 80 年代起,基于遗失(Loss - based)的方法一直作为壅塞控制算法的标准,并沿用至今(例如慢启动、壅塞避免、快速重送/恢复)。为使壅塞控制正常运作,必须及时反馈封包遗失的信息,以便传送端选择合适的传输速率。
随着科技的进步和内存价格的下降,网络设备中普遍配备了大型缓冲区,这给基于遗失的壅塞控制算法带来了巨大挑战。大型缓冲区使得封包不易被丢弃,而是在伫列中缓慢等待,TCP 传送端无法察觉壅塞的发生,仍持续提高传输速率,从而导致网络出现高延迟、吞吐量下降的恶性循环,这就是臭名昭著的缓冲区膨胀(bufferbloat)。正如 Bufferbloat.net 所言:“Bloated buffers lead to network - crippling latency spikes.”
2. 其他
在当今的互联网环境下,尽管 TCP CUBIC 等基于遗失(Loss - based)的壅塞控制方案表现较好,但仍会导致严重的缓冲区膨胀(bufferbloat)。因此,各种不同的壅塞侦测方法应运而生,例如基于延迟(Delay - based)的 TCP Vegas、FAST TCP、LEDBAT 等,以及基于壅塞(Congestion - based)的瓶颈带宽与往返时间(Bottleneck Bandwidth and RTT, BBR)算法(有人认为 BBR 仍是基于延迟或基于带宽延迟乘积 BDP)。
然而,不同版本的算法之间可能会产生诸多问题,例如很多人认为 BBR 封包遗失会导致 CUBIC 饿死等,统一版本更是困难重重。基于遗失的壅塞控制方法逐渐被认为不合时宜,但它是否会被完全取代,目前仍不确定。
最大传输单元 vs. 最大区段长度(MTU vs. MSS)
在介绍壅塞控制算法之前,需要先了解最大区段长度(MSS)。根据 TCP 傻瓜视窗症候群 (Silly Window Syndrome, SWS) 一文,最大区段长度(Maximum Segment Size, MSS)是在连线建立时由双方确定的,并且在连线运作期间保持不变。若其中一方未定义该值,则使用预设值 536 字节。需要注意的是,MSS 定义的是所能接收“资料”的最大长度,而非区段(即不包含 TCP 表头 + 选项)。
在 最大传输单元 (Maximum Transmission Unit, MTU) 中,介绍了 MTU 与 MSS 的关系。不同的资料链接/实体层具有不同的 MTU 大小,其中以太网路(Ethernet)的 MTU 大小通常为 1500 字节。TCP 通过路径 MTU 探索(Path MTU Discovery)、其他算法或经验法则来调整最大区段长度(Maximum Segment Size, MSS)。最简单的计算方法为:
M S S = M T U − 20 octet (TCP 固定表头) − 20 octet (IP 固定表头) MSS = MTU - 20\text{ octet (TCP 固定表头)} - 20\text{ octet (IP 固定表头)} MSS=MTU−20 octet (TCP 固定表头)−20 octet (IP 固定表头)
以以太网路 MTU 为 1500 为例,常见的 MSS 值有 1460、1400、1380 等。
资料的限制传送量
遗憾的是,很多人对 MSS 的认识仅止于此。实际上,MSS 不仅用于“预防 IP 分段”,还是壅塞控制计算“资料的限制传送量”的重要单位。
以 MSS 为 1460 为例
若“资料的限制传送量”为 1460 × 3 = 4380 1460\times3 = 4380 1460×3=4380 字节,则表示传送端在接收到 ACK 之前,一次最多可传输 3 个区段。
下面是后续会用到的术语:
- SMSS 表示传送端 MSS(SENDER MAXIMUM SEGMENT SIZE)
- RMSS 表示接收端 MSS(RECEIVER MAXIMUM SEGMENT SIZE)
- 飞行大小(FLIGHT SIZE)指网络中的未完成资料量,可形象地理解为资料在“飞行”中
- 全尺寸区段(FULL - SIZED SEGMENT)指资料大小为 SMSS 的区段
未完成资料(outstanding data)是指已发送但尚未被确认(ACK)的区段。
壅塞视窗(Congestion Window, cwnd)
前文提到的“资料的限制传送量”,即著名的壅塞视窗(Congestion Window, cwnd),它是指在接收到确认(ACK)区段之前,传送端能够传输的最大资料总量。从概念上讲,cwnd 通常以 MSS 作为自然单位(许多 TCP 实现则以字节(byte)作为实际单位)。
传送端 MSS(SENDER MSS, SMSS)的值可能受到 MTU、Path MTU Discovery、接收端(RMSS)或其他因素的影响。本篇将参照规范 [RFC 5681],以 SMSS 作为主要单位。
流量控制中的接收视窗 (rwnd) 是指接收未完成资料量的接收端限制,而壅塞视窗(cwnd)是指在收到确认(ACK)之前,可以发送到网络中的资料量的传送端限制。这是学习“传统”壅塞控制算法(Congestion Control Algorithms)的关键,其主要原理在于 TCP 在不同状态下,cwnd 如何进行增加、减少或限制操作。
发送视窗(Send Window)
根据 流量控制. 的相关内容,TCP 的发送视窗大小主要由接收端维护,接收端每次回报确认(ACK)时,都会告知传送端接收视窗(rwnd)的大小。但实际上,这只考虑了部分情况(未考虑壅塞控制),真正的发送视窗大小为:
发送视窗大小 = min ( RCV.rwnd , cwnd ) \text{发送视窗大小} = \min(\text{RCV.rwnd}, \text{cwnd}) 发送视窗大小=min(RCV.rwnd,cwnd)
即传送端可传送的资料量为“接收端的接收视窗”与“壅塞视窗”两者之中的较小值。若接收端接收视窗小于壅塞视窗,表明接收端接收缓冲区不足;反之,若接收端接收视窗大于壅塞视窗,则表明网络此时处于壅塞状态。
需要提醒的是,表头字段中的视窗(Window)指的是接收视窗(rwnd),而非发送或壅塞视窗。
初始视窗(Initial Window, IW)
初始视窗(Initial Window, IW)是 TCP 建立连线(三向交握.)后,传送端使用的壅塞视窗(cwnd)大小。其上限设置遵循以下准则 [RFC 3390]:
IW
=
{
2
×
SMSS
,
if SMSS
>
2190
字节
3
×
SMSS
,
if
1095
字节
<
SMSS
≤
2190
字节
4
×
SMSS
,
if SMSS
≤
1095
字节
\text{IW} = \begin{cases} 2\times\text{SMSS}, & \text{if } \text{SMSS} > 2190\text{ 字节} \\ 3\times\text{SMSS}, & \text{if } 1095\text{ 字节} < \text{SMSS} \leq 2190\text{ 字节} \\ 4\times\text{SMSS}, & \text{if } \text{SMSS} \leq 1095\text{ 字节} \end{cases}
IW=⎩
⎨
⎧2×SMSS,3×SMSS,4×SMSS,if SMSS>2190 字节if 1095 字节<SMSS≤2190 字节if SMSS≤1095 字节
建立连线时的 SYN/ACK 及其 ACK 区段不会增加壅塞视窗(cwnd)的大小。若其中一个区段遗失,在正确传输 SYN 区段后,初始视窗(IW)最多只能为 SMSS 组成的一个区段。
当 IW 具有多个 MSS 大小时,若通过路径 MTU 探索(Path MTU Discovery)发现 MSS 值过大,应减小壅塞视窗(cwnd)的大小,以避免出现许多分段小区段的突发 (bursts)情况。
传统 TCP 通常将 IW 设定为 1,许多教科书为了便于解释,也多采用
1
×
SMSS
1\times\text{SMSS}
1×SMSS。
1999 年的 [RFC 2581] 将 IW 上限设为
2
×
SMSS
2\times\text{SMSS}
2×SMSS。
2002 年的 [RFC 3390] 将其调整为 2 - 4 个,这是目前的标准。
2013 年的 [RFC 6928] 进行实验,将 IW 设为
10
SMSS
10\text{ SMSS}
10 SMSS(上限约 14600 字节),表示为 IW10。
壅塞控制算法(Congestion Control Algorithms)
壅塞控制算法(Congestion Control Algorithms),也称为壅塞策略,标准的基于遗失的算法包括:
- 慢启动(Slow Start)
- 壅塞避免(Congestion Avoidance)
- 快速重送(Fast Retransmit)
- 快速恢复(Fast Recovery)
此外,Google 人员新推出了基于壅塞/BDP 的瓶颈带宽与往返时间(Bottleneck Bandwidth and RTT, BBR)算法。
在某些情况下,TCP 传送端可以比壅塞控制算法限制的资料传送量更加保守,但不应比算法更为激进。由于不同环境、操作系统等存在不同的 TCP 实现、变体或版本,本篇以 [RFC 5681]: TCP Congestion Control 为标准。值得注意的是,BBR 与其他壅塞控制算法不同,它并非主要使用壅塞视窗来控制输出流量。
慢启动(Slow Start)
当 TCP 开始向未知条件的网络进行传输时,需要缓慢地探测网络,以确定可用容量,避免因不恰当的大量数据并发导致网络壅塞。TCP 传送端通过慢启动和壅塞避免来控制注入网络的未完成资料量。
实际上,慢启动并不“慢”,其 cwnd 的增长速度非常快,呈现指数增长(exponential growth)。
连线建立后,cwnd 大小为初始视窗(Initial Window, IW),TCP 进入慢启动阶段。在这个阶段,TCP 每次接收并确认(ACK)新资料时,会增加至多 1 × SMSS 1\times\text{SMSS} 1×SMSS 字节的壅塞视窗(cwnd)大小。建议的做法是,每次接收到新资料的确认(ACK)区段时:
cwnd + = min ( N , SMSS ) \text{cwnd} += \min(N, \text{SMSS}) cwnd+=min(N,SMSS)
其中, N N N 为收到 ACK 时“之前尚未被确认的资料”的位数。这样做是为了防止一些不良接收端采用分段确认(ACK Division)的方式,例如明明可以回应一个区段 ACK: 10,却故意回应两个区段 ACK: 5、ACK: 10,从而诱使传送端增加壅塞视窗(cwnd)。
以初始视窗(IW) = 2 为例
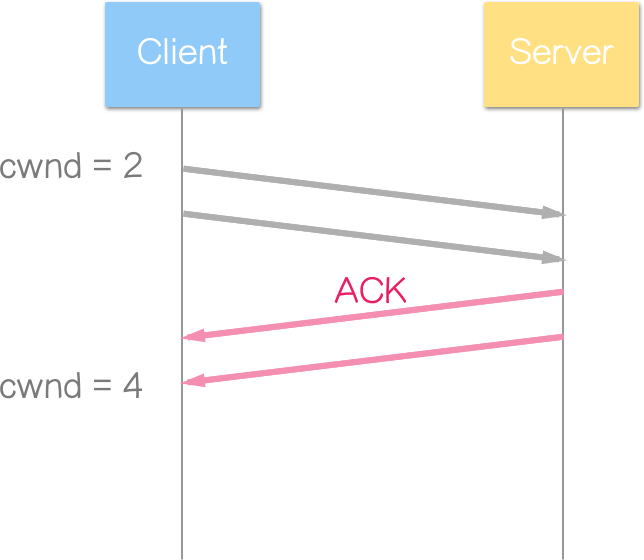
Client 发送 2 个区段,Server 也回应 2 个 ACK(暂不考虑延迟确认)。由于每次收到 ACK 都会使 cwnd 增加将近 1,所以 cwnd 变为 2 + 1 + 1 = 4 2 + 1 + 1 = 4 2+1+1=4(收到一个 ACK 加 1,共收到两个 ACK)。
需要注意的是,许多应用程序的性能往往受到往返时间(RTT)的限制。例如,HTTP 为每个请求建立的 TCP 连线都要经过慢启动阶段,无法立即使用链接的最大带宽容量和速度,这限制了可用带宽的吞吐量,可能对小型传输的性能产生不利影响,因此连线管理显得尤为重要。
慢启动门槛(Slow Start Threshold, ssthresh)
慢启动不能无限制地增加壅塞视窗(cwnd)的大小,否则就失去了壅塞“控制”的意义。慢启动门槛(ssthresh)是 TCP 的另一个状态变量,也称为慢启动门阀、门槛值、阈值。当 cwnd 达到此门槛或观察到壅塞时,就会停止指数增长的慢启动,进入线性增长的壅塞避免阶段:
- 当 cwnd < ssthresh \text{cwnd} < \text{ssthresh} cwnd<ssthresh 时,使用慢启动(Slow Start);
- 当 cwnd > ssthresh \text{cwnd} > \text{ssthresh} cwnd>ssthresh 时,使用壅塞避免(Congestion Avoidance);
- 当 cwnd = ssthresh \text{cwnd} = \text{ssthresh} cwnd=ssthresh 时,传送端可任选其一。
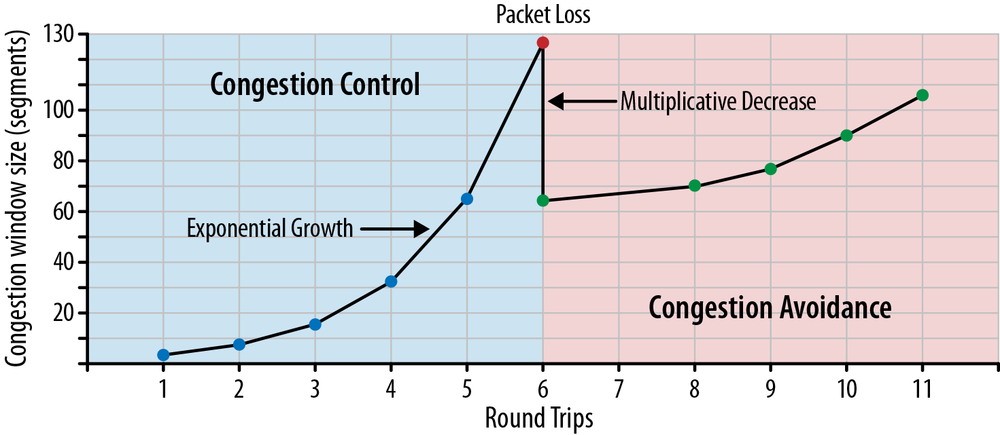
Photo by O’REILLY
ssthresh 的初始值可以是任意大小(例如,一些实现使用接收视窗大小),但仍应根据网络情况减小壅塞视窗(cwnd),以应对壅塞情况。慢启动(Slow Start)适用于“资料开始传输”时、“修复由重送定时器检测到的遗失区段”后,以及“启动 TCP 传送端的 ACK 时钟”的情况。
壅塞避免(Congestion Avoidance)
在壅塞避免期间,每个往返时间(RTT),壅塞视窗(cwnd)大约增加 1 个 SMSS 大小,且不应超过该值,尽管某些规范尝试突破这一限制(例如 [RFC 3465])。壅塞避免过程会持续到检测到壅塞为止。
在每个往返时间(RTT),TCP 会增加至多 1 × SMSS 1\times\text{SMSS} 1×SMSS 字节的壅塞视窗(cwnd)大小。建议的做法是,每次接收到新资料的确认(ACK)区段时:
cwnd + = SMSS × SMSS cwnd \text{cwnd} += \frac{\text{SMSS}\times\text{SMSS}}{\text{cwnd}} cwnd+=cwndSMSS×SMSS
需要注意的是,一些传统的实现会在公式中附加额外常数,这是不正确的,甚至可能导致性能下降 [RFC 2525]。
以初始视窗(IW) = 2 为例
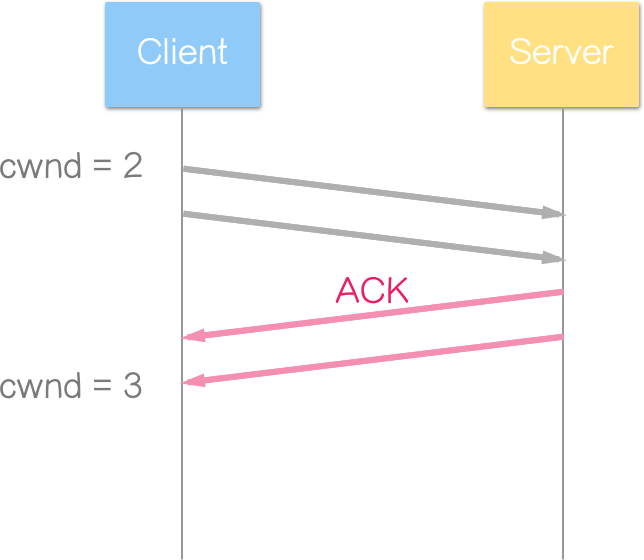
Client 发送 2 个区段,Server 也回应 2 个 ACK(暂不考虑延迟确认)。由于每次增加的量约为 1 × 1 / cwnd 1\times1/\text{cwnd} 1×1/cwnd,所以 cwnd 变为 2 + 0.5 + 0.5 = 3 2 + 0.5 + 0.5 = 3 2+0.5+0.5=3,相当于每个往返时间(RTT),cwnd 增加 1 个 SMSS。
区段遗失
当 TCP 传送端使用重送计时器(retransmission timer)检测到区段遗失,且重送计时器尚未重送该区段时,慢启动门槛(ssthresh)不应超过:
ssthresh = max ( FlightSize 2 , 2 × SMSS ) \text{ssthresh} = \max\left(\frac{\text{FlightSize}}{2}, 2\times\text{SMSS}\right) ssthresh=max(2FlightSize,2×SMSS)
其中,飞行大小(FlightSize)是网络中未完成的资料数量。然而,许多实现中错误地将 FlightSize 替换为 cwnd,这可能导致门槛超出接收缓冲区(rwnd)的大小。

此外,当重送计时器逾时,壅塞视窗(cwnd)不得超过 1 个 SMSS 的大小,这一限制称为遗失视窗(Lost Window, LW)。
因此,TCP 传送端在重送丢弃的区段后,会使用慢启动算法,将视窗从 1 个 SMSS 增加到新的 ssthresh 值,然后继续进入壅塞避免阶段。
另一方面,若 TCP 传送端使用重送计时器检测到区段遗失,但重送计时器已至少重送一次,则慢启动门槛(ssthresh)保持不变。
快速重送(Fast Retransmit)
在 TCP 错误控制 (Error Control ) 一文中,初次介绍了快速重送的概念。
接收端
当某区段遗失时,后续接收的区段顺序会出错,因此接收端不应使用延迟确认(Delayed ACK),而应立即确认(immediate ACK),目的是让传送端知道接收到的是乱序(out of order)的区段以及预期接收的序列号。
传送端
当传送端接收到 3 个重复的确认(duplicate ACK)时,会立即重送该区段,而不是等到重送计时器逾时。传送端一开始并不清楚“重复的确认”的原因(可能由多种网络问题导致)。若收到 1 - 2 个重复确认,传送端会假设是网络对区段的重新排序或复制所引起;而收到 3 个或更多的重复确认,则明显表明区段已遗失,此时 TCP 会立即重送“似乎是”遗失的区段,而无需等待计时器逾时。
范例
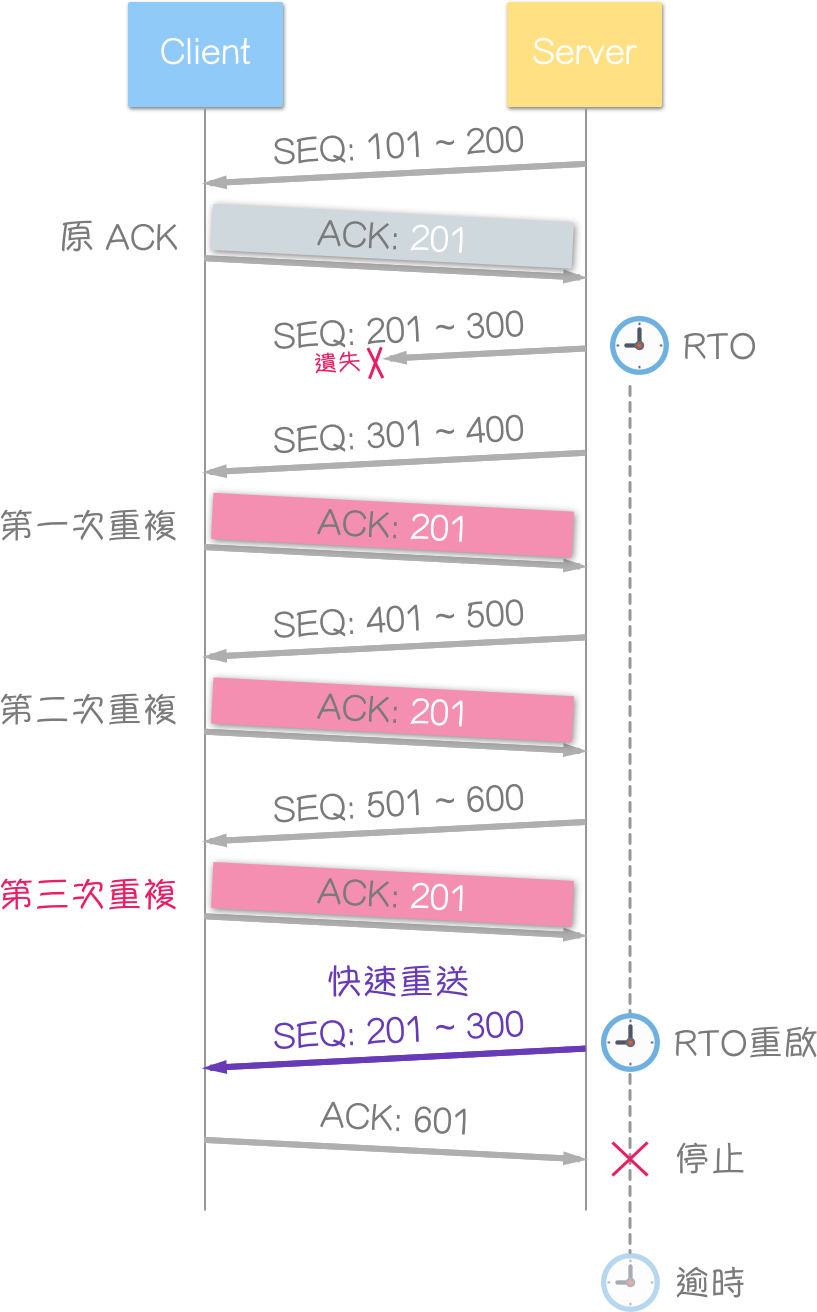
原始的 ACK 加上 3 个重复的 ACK,总共会有 4 个相同的确认号(acknowledgment number)。区段重送之后,计时器会重新启动。
有限传输算法(Limited Transmit Algorithm)
考虑这样一个问题:当传送端的壅塞视窗(cwnd)大小为 3 × SMSS 3\times\text{SMSS} 3×SMSS,传送端发送了 3 个区段,但其中一个区段被网络丢弃(遗失)时,会发生什么情况?答案是,接收端最多只能送回 2 个重复确认(duplicate ACK)区段,而快速重送需要 3 个重复确认来触发,因此传送端只能等待成本高昂的逾时重送,才能重送该遗失的区段。
TCP 研究者发现,当 TCP 壅塞视窗(cwnd)较小时,许多遗失恢复策略(loss recovery strategies)可能会因资料发送有限、接收视窗的限制或视窗内资料大量遗失等原因而无法有效运作。有限传输算法(Limited Transmit Algorithm)使得传送端在接收到连续两个重复确认(duplicate ACK)时,只要满足以下条件,就可以传输新数据(快速恢复阶段会再次提及):
- 接收端的接收视窗(rwnd)允许区段的传输。
- 未完成的资料数量 ≤ \leq ≤ 壅塞视窗(cwnd) + 2 × SMSS 2\times\text{SMSS} 2×SMSS。
换句话说,当发送量超过壅塞视窗(cwnd)时,传送端只能再传输两个区段,并且在传输这些新区段时,不得更改壅塞视窗(cwnd)。有限传输算法可以与 SACK 结合使用,也可以独立使用,它增加了快速重送恢复单个遗失区段的概率,避免了使用成本高昂的逾时重送。
快速恢复(Fast Recovery)
当快速重送送出“似乎是”遗失的区段后,TCP 进入快速恢复算法阶段,直到收到非重复的确认(ACK)区段。不执行慢启动的原因是,重复的确认区段不仅是区段遗失的迹象,还往往意味着该区段已离开网络,不再消耗网络资源。
快速重送/快速恢复算法通过以下几个方面实现:
1. 传送端接收到 1 - 2 个重复确认(duplicate ACK)时
若接收端接收视窗允许,传送端可以继续发送先前未发送过的区段。总飞行大小(FilghtSize)应满足:
FilghtSize ≤ cwnd + 2 × SMSS \text{FilghtSize} \leq \text{cwnd} + 2\times\text{SMSS} FilghtSize≤cwnd+2×SMSS
并且在传输这些新区段时,不得更改壅塞视窗(cwnd),这实际上就是前面提到的有限传输算法(Limited Transmit Algorithm)。此外,使用 SACK [RFC 2018] 的传送端,除非传入的重复确认包含新的 SACK 信息,否则不得发送新数据。
2. 接收到 3 个重复确认(duplicate ACK)时
如前文“区段遗失”所述,慢启动门槛(ssthresh)不应超过:
ssthresh = max ( FlightSize 2 , 2 × SMSS ) \text{ssthresh} = \max\left(\frac{\text{FlightSize}}{2}, 2\times\text{SMSS}\right) ssthresh=max(2FlightSize,2×SMSS)
若使用了有限传输算法(Limited Transmit Algorithm),通过该算法传输的新数据不应计入此计算。
3. 传送端重送尚未被确认的资料时
这表明至少有 3 个区段(Segment)已离开网络并被接收端缓冲,TCP 进入快速恢复算法阶段,直到收到非重复的确认(ACK)区段。此时,需要将壅塞视窗设置为:
cwnd = ssthresh + 3 × SMSS \text{cwnd} = \text{ssthresh} + 3\times\text{SMSS} cwnd=ssthresh+3×SMSS
这也是快速恢复与慢启动的最大区别。其中, 3 × SMSS 3\times\text{SMSS} 3×SMSS 中的 3 表示已离开网络且被接收端缓冲的 3 个区段。
4. 若传送端仍持续接收到重复确认(3 个以上)
TCP 继续保持快速恢复阶段,并且对于每个重复确认(duplicate ACK),以 1 × SMSS 1\times\text{SMSS} 1×SMSS 增加壅塞视窗(cwnd)的大小。这样扩充壅塞视窗(cwnd)是为了反映那些已离开网络的额外区段,它们不再消耗网络资源。
5. 当接收端接收视窗允许时
当先前未传送的资料有效,并且接收端接收视窗(rwnd)允许传送端当前的壅塞视窗(cwnd)时,TCP 传送端应发送 1 × SMSS 1\times\text{SMSS} 1×SMSS 的未传送资料。
6. 当“先前未被确认的资料”的 ACK 抵达时
TCP 必须将壅塞视窗(cwnd)设置为慢启动门槛(ssthresh),这被称为(视窗的)deflating,即:
ssthresh = max ( FlightSize 2 , 2 × SMSS ) \text{ssthresh} = \max\left(\frac{\text{FlightSize}}{2}, 2\times\text{SMSS}\right) ssthresh=max(2FlightSize,2×SMSS)
TCP 的这四种基本壅塞控制算法相互配合,使得 TCP 能够在复杂的网络环境中,根据网络的拥塞情况动态地调整发送数据的速率,保证数据的可靠传输和网络的稳定性。虽然这些算法在现代网络中逐渐被认为存在一些局限性,但它们为后续更先进的壅塞控制算法的发展奠定了基础
via:
-
TCP 三向交握 (Three-way Handshake) - 發表於 2016-12-21 鄭 中勝
https://notfalse.net/7/three-way-handshake -
陣列 (Array) 簡介 - 發表於 2017-01-29 鄭 中勝
https://notfalse.net/15/array-intro -
位元組順序 (Byte Order or Endianness) - big-endian vs. little-endian - 發表於 2017-02-12 鄭 中勝
https://notfalse.net/19/byte-order -
位元 儲存範圍 - 發表於 2017-02-04 鄭 中勝
https://notfalse.net/18/range-of-bits -
有號數字表示法 - 2 的補數、1 的補數 與 符號大小 - 發表於 2017-02-25 鄭 中勝
https://notfalse.net/20/signed-number-representations -
TCP 檢驗和 (TCP Checksum) - 發表於 2017-02-26 鄭 中勝
https://notfalse.net/21/tcp-checksum -
協定資料單元 - 區段 (Segment)、資料包 (Datagram)、訊框 (Frame) - 發表於 2017-02-27 鄭 中勝
https://notfalse.net/22/network-encapsulation -
最大傳輸單元 (Maximum Transmission Unit, MTU) - 發表於 2017-02-27 鄭 中勝
https://notfalse.net/23/mtu -
TCP 流量控制 (Flow Control) - 發表於 2017-03-08 鄭 中勝
https://notfalse.net/24/tcp-flow-control -
TCP 傻瓜視窗症候群 (Silly Window Syndrome, SWS) - 發表於 2017-03-10 鄭 中勝
https://notfalse.net/25/tcp-sws -
TCP 序列號 (Sequence Number, SEQ) - 發表於 2017-03-12 鄭 中勝
https://notfalse.net/26/tcp-seq -
TCP 錯誤控制 (Error Control) - 發表於 2017-03-23 鄭 中勝
https://notfalse.net/27/tcp-error-control -
TCP 壅塞控制 (Congestion Control) - 發表於 2017-04-07 鄭 中勝
https://notfalse.net/28/tcp-congestion-control